Im Februar sorgte OpenAI mit dem für großes Aufsehen Enthüllung von Sora, ein beeindruckendes KI-Tool, das Textaufforderungen in ansprechende Videos umwandeln kann. Mit Sora können Benutzer ihren Ideen Leben einhauchen und zusehen, wie die KI aus kurzen Texthinweisen dynamische 60-Sekunden-Videos erstellt. Aber ein anderer Player in der Stadt hat im Internet für Aufsehen gesorgt: VideoPoet, ein Tool zur Videogenerierung von Google, das drei Monate zuvor auf den Markt kam.
VideoPoet ist die Idee eines Teams von 31 Forschern bei Google Research und revolutioniert die Welt der Multimedia-Erstellung. Während sich Sora darauf konzentriert, Text in visuelle Geschichten umzuwandeln, verfolgt VideoPoet einen anderen Ansatz. Dank fortschrittlicher Techniken wie autoregressiver Sprachmodellierung und Tokenizern wie MAGVIT V2 und SoundStream eignet es sich hervorragend für die Erstellung realistischer Videos mit Text, Bildern oder sogar vorhandenem Videomaterial. Diese Vielseitigkeit eröffnet eine Welt voller Möglichkeiten für digitale Kunst, Filmproduktion und interaktive Medien.

Quelle: Google Research
Was VideoPoet auszeichnet, ist seine einzigartige Architektur. Während viele Videogenerierungsmodelle auf diffusionsbasierten Methoden basieren, die in diesem Bereich als leistungsstärkste Methoden gelten, ist Google Research einen anderen Weg gegangen. Anstatt das beliebte Stable Diffusion-Modell zu verwenden, entschieden sich die Google-Forscher für ein großes Sprachmodell (LLM), das auf der Transformer-Architektur basiert. Diese Art von KI-Modell, das normalerweise zur Text- und Codegenerierung verwendet wird, wurde für die Generierung von Videos umfunktioniert – ein mutiger Schritt, der VideoPoet von der Masse abhebt.
„Die meisten vorhandenen Modelle verwenden diffusionsbasierte Methoden, die häufig als die derzeit besten Modelle bei der Videogenerierung gelten. „Diese Videomodelle beginnen typischerweise mit einem vorab trainierten Bildmodell wie Stable Diffusion, das hochauflösende Bilder für einzelne Frames erzeugt, und optimieren dann das Modell, um die zeitliche Konsistenz über Videoframes hinweg zu verbessern“, schrieb das Google-Forschungsteam in seinem vorläufigen Beitrag. Rezension Forschungsarbeit.
Was ist VideoPoet und wie funktioniert es?
Im Kern verwendet VideoPoet ein autoregressives Sprachmodell, um aus verschiedenen Modalitäten wie Video, Bild, Audio und Text zu lernen. Dies wird durch den Einsatz mehrerer Tokenizer ermöglicht –MAGVIT V2 für Video und Bild und SoundStream für Audio.
Wenn das Modell Token basierend auf einem bestimmten Kontext generiert, werden diese Token später mithilfe des Decoders des jeweiligen Tokenizers wieder in eine sichtbare Darstellung umgewandelt. Dies ermöglicht eine nahtlose Übersetzung zwischen verschiedenen Medienformen und gewährleistet ein zusammenhängendes und umfassendes Verständnis über alle Modalitäten hinweg. Nachfolgend sind die Komponenten von VideoPoet aufgeführt:
- Vorab trainierte MAGVIT V2- und SoundStream-Tokenizer, die Bilder, Video- und Audioclips in eine Codesequenz übersetzen, die das Modell verstehen kann.
- Ein autoregressives Sprachmodell, das aus verschiedenen Modalitäten – Video, Bild, Audio und Text – lernt, um das nächste Token in der Sequenz vorherzusagen.
- Eine Reihe generativer Lernziele, darunter Text-zu-Video, Text-zu-Bild, Bild-zu-Video und mehr, die es VideoPoet ermöglichen, vielfältige und qualitativ hochwertige Videos zu erstellen.
Revolutionäre Funktionen und Fähigkeiten
Wie Sora und Stable Diffusion verfügt auch VideoPoet über einige revolutionäre Funktionen, die der Videoerstellung eine neue Perspektive verleihen.
High-Motion-Videos mit variabler Länge: Im Gegensatz zu herkömmlichen Modellen erstellt VideoPoet mühelos Videos mit hoher Bewegung und variabler Länge und verschiebt damit die Grenzen dessen, was bei der Videogenerierung möglich ist.
Modalitätsübergreifendes Lernen: Eine der Stärken von VideoPoet liegt in seiner Fähigkeit, über verschiedene Modalitäten hinweg zu lernen. Durch die Überbrückung der Lücke zwischen Text, Bildern, Videos und Audio bietet VideoPoet ein ganzheitliches Verständnis, das den kreativen Prozess bereichert.
Interaktive Bearbeitungsfunktionen: VideoPoet generiert nicht nur Videos – es bietet Benutzern interaktive Bearbeitungsfunktionen. Von der Erweiterung von Eingabevideos über die Steuerung von Bewegungen bis hin zur Anwendung stilisierter Effekte basierend auf Textaufforderungen legt es die kreative Kontrolle in die Hände des Benutzers.
VideoPoet von Google ist mehr als nur ein Tool zur Videogenerierung – es ist ein Game-Changer in der Welt der KI. Durch die nahtlose Integration mehrerer Funktionen in ein einziges großes Sprachmodell (LLM) wird die Landschaft der Videogenerierung neu definiert. Seine Vielseitigkeit bei der Verarbeitung von Text, Bildern und Audio macht es für Content-Ersteller und KI-Enthusiasten gleichermaßen unverzichtbar und setzt neue Maßstäbe für Kreativität und Innovation.
Hier finden Sie eine Aufschlüsselung der Funktionen von VideoPoet anhand des Diagramms unten.
Zunächst einmal können Eingabebilder durch Animationen zum Leben erweckt werden, wodurch dynamische Bewegungen im Video erzeugt werden. Darüber hinaus haben Benutzer die Möglichkeit, Videos zu bearbeiten, indem sie bestimmte Bereiche zuschneiden oder maskieren, was nahtlose Inpainting- oder Outpainting-Effekte ermöglicht.
Wenn es um die Stilisierung geht, entfaltet das Modell seine Magie, indem es ein Video analysiert, das Tiefe und optischen Fluss einfängt – im Wesentlichen die Bewegung innerhalb der Szene. Anhand dieser Informationen wendet es stilistische Elemente an, die durch Textansagen gesteuert werden, und steigert so die visuelle Gesamtattraktivität des Videos.
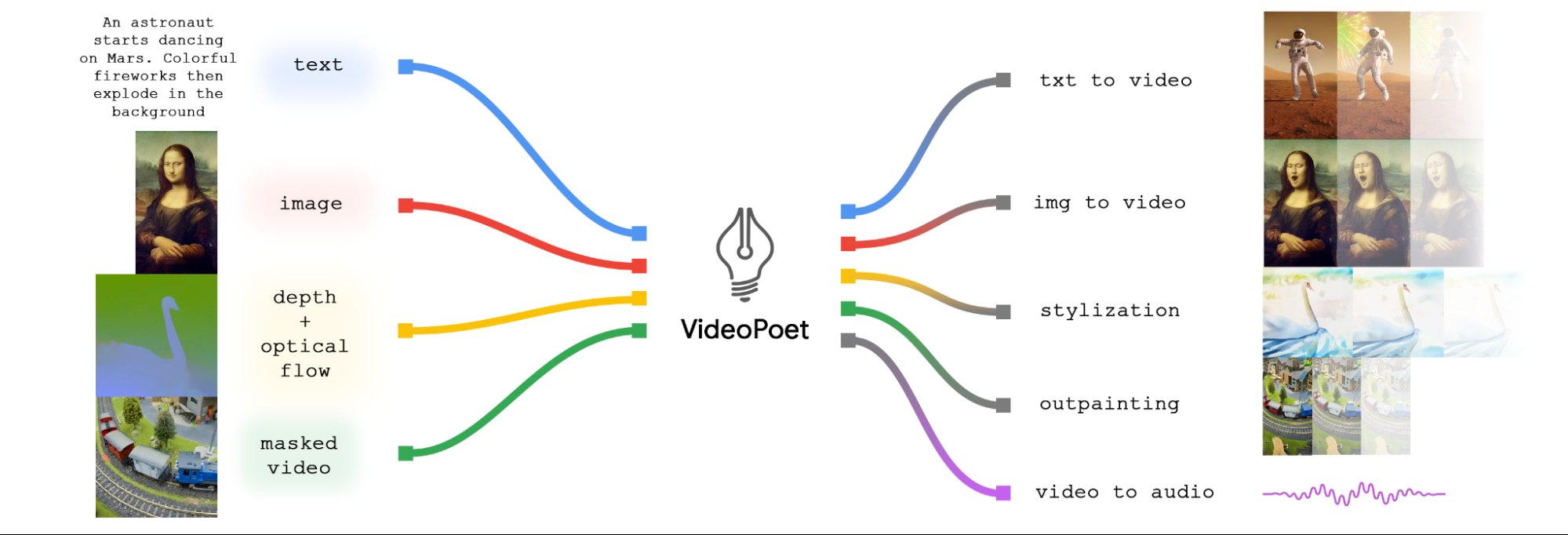
Zum erweitern klicken
Aber genug Fachjargon – reden wir über die Ergebnisse. Um die Fähigkeiten von VideoPoet zu demonstrieren, produzierte das Google Research-Team einen Kurzfilm basierend auf Eingabeaufforderungen von Bard, einer KI zum Geschichtenerzählen. Das Ergebnis? Eine bezaubernde Geschichte über einen reisenden Waschbären, die durch eine Reihe fesselnder Videoclips zum Leben erweckt wird. Es ist ein Beweis für die Macht der KI beim Geschichtenerzählen und ein Blick in die Zukunft der Multimedia-Erstellung.
[Eingebetteten Inhalt]
In einer Welt, in der Inhalte an erster Stelle stehen, verändern Tools wie Sora und VideoPoet die Spielregeln und ermöglichen es Entwicklern, ihre Ideen auf eine noch nie dagewesene Weise zum Leben zu erwecken. Mit ihren fortschrittlichen Funktionen und benutzerfreundlichen Schnittstellen sind diese KI-gesteuerten Tools bereit, die Art und Weise, wie wir Geschichten erzählen und uns durch Videos ausdrücken, zu revolutionieren.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://techstartups.com/2024/04/12/videopoet-google-looks-to-challenge-openai-sora-and-stable-diffusion-for-dominance-in-ai-video-creation/

