
Dieser Artikel wurde ursprünglich auf der Website des Autors veröffentlicht Blog und mit Genehmigung des Autors erneut auf TOPBOTS veröffentlicht.
Große Sprachmodelle wie ChatGPT verarbeiten und generieren Textsequenzen, indem sie den Text zunächst in kleinere Einheiten namens „aufteilen“. Token. Im Bild unten stellt jeder farbige Block einen eindeutigen Token dar. Kurze oder gebräuchliche Wörter wie „du“, „sagen“, „laut“ und „immer“ sind ein eigenes Zeichen, während längere oder weniger gebräuchliche Wörter wie „atrocious“, „precocious“ und „supercalifragilisticexpialidocious“ gebrochen werden kleinere Unterwörter.
Dieser Prozess von Tokenisierung ist in allen Sprachen nicht einheitlich, was zu Unterschieden in der Anzahl der für äquivalente Ausdrücke in verschiedenen Sprachen erstellten Token führt. Zum Beispiel, Für einen Satz auf Burmesisch oder Amharisch sind möglicherweise zehnmal mehr Token erforderlich als für eine ähnliche Nachricht auf Englisch.

Ein Beispiel für dieselbe Nachricht, übersetzt in fünf Sprachen, und die entsprechende Anzahl von Token, die zum Tokenisieren dieser Nachricht erforderlich sind (mithilfe des Tokenizers von OpenAI). Der Text stammt von Der RIESIGE Datensatz von Amazon.
In diesem Artikel untersuche ich den Tokenisierungsprozess und wie er sich in verschiedenen Sprachen unterscheidet:
- Analyse der Token-Verteilungen in einem parallelen Datensatz von Kurznachrichten, die in 52 verschiedene Sprachen übersetzt wurden
- Für einige Sprachen wie Armenisch oder Burmesisch ist eine Angabe erforderlich 9 bis 10 Mal mehr Token als Englisch um vergleichbare Nachrichten zu tokenisieren
- Die Auswirkungen dieser Sprachunterschiede
- Dieses Phänomen ist für die KI nicht neu – Dies steht im Einklang mit dem, was wir beim Morsecode und bei Computerschriftarten beobachten
Versuch es selber!
Probieren Sie das von mir erstellte explorative Dashboard aus, das auf HuggingFace-Bereichen verfügbar ist. Hier können Sie die Tokenlängen für verschiedene Sprachen und für verschiedene Tokenizer vergleichen (was in diesem Artikel nicht näher erläutert wurde, ich aber den Lesern die Möglichkeit gebe, dies selbst zu tun).
MASSIVE ist ein paralleler Datensatz von Amazon eingeführt bestehend aus 1 Million realistischen, parallelen Kurztexten, übersetzt in 52 Sprachen und 18 Fachgebiete. Ich habe das verwendet dev Aufteilung des Datensatzes, bestehend aus 2033 Texte in jede der Sprachen übersetzt. Der Datensatz ist verfügbar auf HuggingFace und ist lizenziert unter der CC BY 4.0 Lizenz.
Obwohl es viele andere Sprachmodell-Tokenizer gibt, konzentriert sich dieser Artikel hauptsächlich darauf Der Byte Pair Encoding (BPE)-Tokenizer von OpenAI (von ChatGPT und GPT-4 verwendet) aus drei Hauptgründen:
- Erstens Lehnt den Artikel von Linkov ab verglich mehrere Tokenizer und stellte fest, dass der Tokenizer von GPT-2 die größte Token-Längendifferenz zwischen verschiedenen Sprachen aufwies. Dies veranlasste mich, mich auf OpenAI-Modelle zu konzentrieren, einschließlich GPT-2 und seinen Nachfolgern.
- Zweitens: Da wir keinen Einblick in den gesamten Trainingsdatensatz von ChatGPT haben, hilft die Untersuchung der Black-Box-Modelle und Tokenizer von OpenAI, deren Verhalten und Ergebnisse besser zu verstehen.
- Schließlich ist die weit verbreitete Einführung von ChatGPT in verschiedenen Anwendungen (von Sprachlernplattformen wie Duolingo zu Social-Media-Apps wie Snapchat) unterstreicht, wie wichtig es ist, die Nuancen der Tokenisierung zu verstehen, um eine gleichberechtigte Sprachverarbeitung in verschiedenen Sprachgemeinschaften sicherzustellen.
Um die Anzahl der Token zu berechnen, die ein Text enthält, verwende ich die cl100k_base Tokenizer verfügbar auf Tiktoken, der BPE-Tokenizer, der von den ChatGPT-Modellen von OpenAI („gpt-3.5-turbo“ und „gpt-4“) verwendet wird.
Einige Sprachen tokenisieren konsequent auf längere Längen
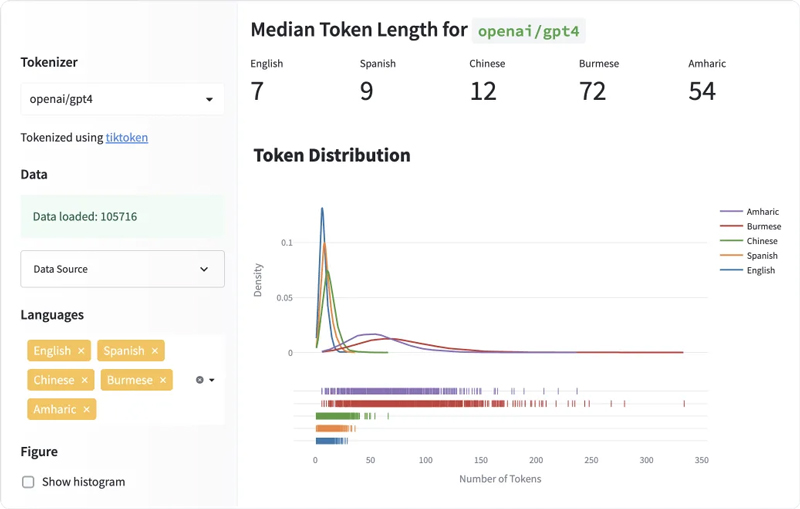
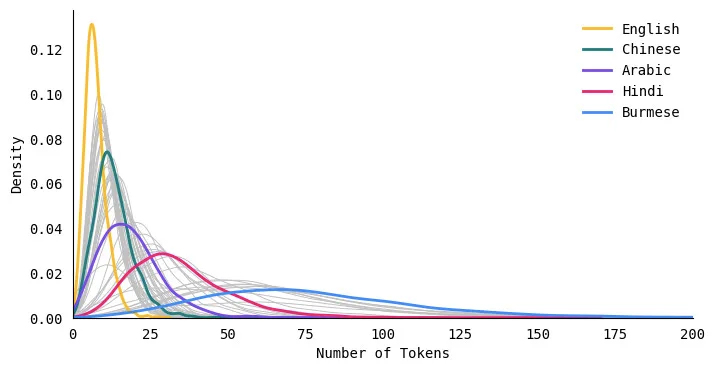
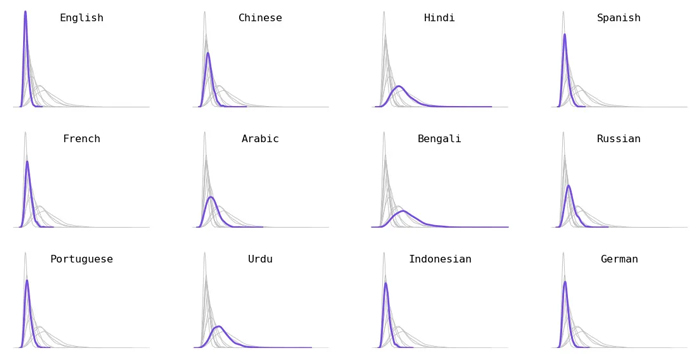
Das folgende Verteilungsdiagramm vergleicht die Verteilung der Tokenlängen für fünf Sprachen. Die Kurve für Englisch ist hoch und schmal, was bedeutet, dass englische Texte durchweg auf eine kleinere Anzahl von Tokens tokenisiert werden. Andererseits ist die Kurve für Sprachen wie Hindi und Burmesisch kurz und breit, was bedeutet, dass diese Sprachen Texte in viel mehr Tokens umwandeln.
Englisch hat die kürzeste mittlere Tokenlänge
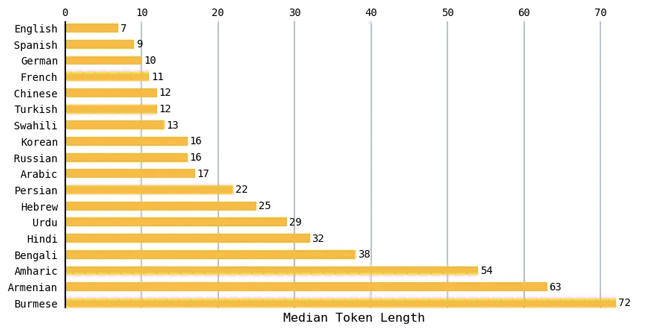
Für jede Sprache habe ich die mittlere Tokenlänge für alle Texte im Datensatz berechnet. Das folgende Diagramm vergleicht eine Teilmenge der Sprachen. Englische Texte hatten die kleinste mittlere Länge von 7 Token und burmesische Texte hatten die größte mittlere Länge von 72 Token. Romanische Sprachen wie Spanisch, Französisch und Portugiesisch führten tendenziell zu einer ähnlichen Anzahl von Token wie Englisch.
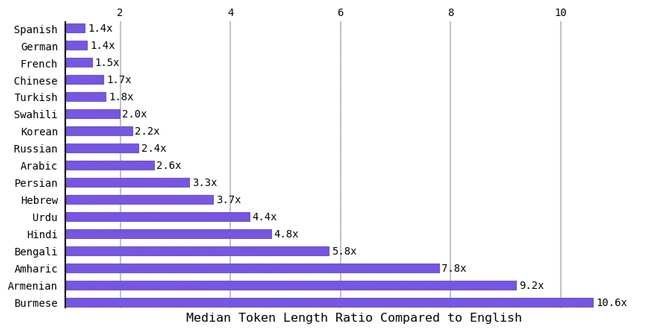
Da Englisch die kürzeste mittlere Tokenlänge hatte, habe ich das Verhältnis der mittleren Tokenlänge der anderen Sprachen zu der des Englischen berechnet. Sprachen wie Hindi und Bengali (über 800 Millionen Menschen sprechen eine dieser Sprachen) führten zu einer durchschnittlichen Tokenlänge, die etwa fünfmal so groß war wie die von Englisch. Das Verhältnis ist neunmal so hoch wie das des Englischen für Armenisch und über zehnmal so hoch wie das des Englischen für Burmesisch. Mit anderen Worten, Um das gleiche Gefühl auszudrücken, benötigen einige Sprachen bis zu zehnmal mehr Token.
Auswirkungen der Ungleichheit der Tokenisierungssprache
Insgesamt bedeutet die Anforderung von mehr Token (um dieselbe Nachricht in einer anderen Sprache zu tokenisieren):
- Sie sind dadurch begrenzt, wie viele Informationen Sie in die Eingabeaufforderung eingeben können (da das Kontextfenster fest ist). Ab März 2023 könnte GPT-3 bis zu 4 Token und GPT-4 bis zu 8 oder 32 Token in seiner Eingabe aufnehmen [1]
- Es kostet mehr Geld
- Die Ausführung dauert länger
Die Modelle von OpenAI werden zunehmend in Ländern eingesetzt, in denen Englisch nicht die dominierende Sprache ist. Laut SimilarWeb.com entfielen im Zeitraum Januar bis März 10 nur 2023 % des an ChatGPT gesendeten Datenverkehrs auf die Vereinigten Staaten.
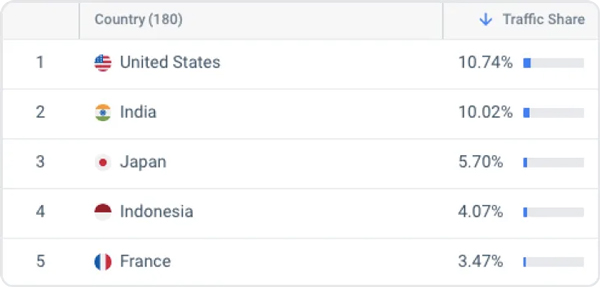
Zusätzlich wurde ChatGPT verwendet in Pakistan, um in einem Fall von Kindesentführung eine Kaution zu gewähren und in Japan für Verwaltungsaufgaben. Da ChatGPT und ähnliche Modelle weltweit zunehmend in Produkte und Dienstleistungen integriert werden, ist es von entscheidender Bedeutung, solche Ungleichheiten zu verstehen und anzugehen.
Sprachunterschiede bei der Verarbeitung natürlicher Sprache
Diese digitale Kluft in der Verarbeitung natürlicher Sprache (NLP) ist ein aktives Forschungsgebiet. 70 % der auf einer Computerlinguistik-Konferenz veröffentlichten Forschungsarbeiten bewerteten nur Englisch.[2] Mehrsprachige Modelle schneiden bei mehreren NLP-Aufgaben in Sprachen mit geringen Ressourcen schlechter ab als in Sprachen mit hohen Ressourcen wie Englisch.[3] Gemäß W3Techs (World Wide Web Technology Surveys) dominiert Englisch mehr als die Hälfte (55.6 %) der Inhalte im Internet.[4]
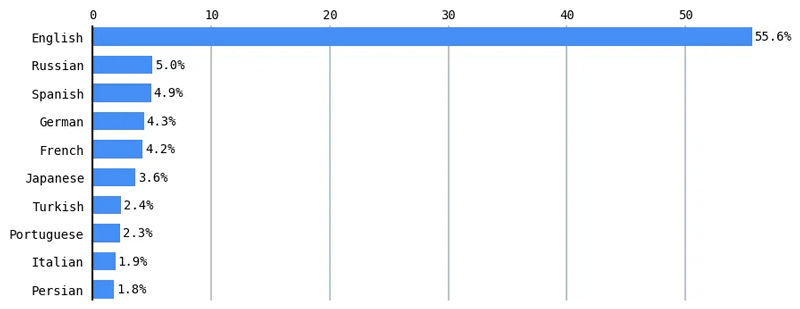
Ebenso macht Englisch Sinn über 46 % des Common Crawl-Korpus (Milliarden Webseiten aus dem Internet kroch über ein Jahrzehnt lang), deren Versionen zum Trainieren vieler großer Sprachen wie Googles T5 und OpenAIs GPT-3 (und wahrscheinlich ChatGPT und GPT-4) verwendet wurden. Common Crawl macht 60 % der GPT-3-Trainingsdaten aus.[5]
Die Überwindung der digitalen Kluft im NLP ist von entscheidender Bedeutung, um eine gerechte Sprachdarstellung und Leistung in KI-gesteuerten Technologien sicherzustellen. Um diese Lücke zu schließen, sind konzertierte Anstrengungen von Forschern, Entwicklern und Linguisten erforderlich, um der Entwicklung ressourcenarmer Sprachen Priorität einzuräumen und in sie zu investieren und so eine integrativere und vielfältigere Sprachlandschaft im Bereich der Verarbeitung natürlicher Sprache zu fördern.
Historisches Beispiel: Darstellung chinesischer Typografie mithilfe des Morsecodes
Eine solche Ungleichheit der technologischen Kosten für verschiedene Sprachen ist weder für die KI noch für die Informatik neu.
Vor über hundert Jahren war die Telegrafie, eine revolutionäre Technologie ihrer Zeit („das Internet seiner Ära“), mit sprachlichen Ungleichheiten konfrontiert, die denen ähneln, die wir in den heutigen großen Sprachmodellen sehen. Trotz der Versprechen eines offenen Austauschs und einer offenen Zusammenarbeit wies die Telegrafie zwischen den Sprachen Unterschiede in Geschwindigkeit und Kosten auf. Beispielsweise war das Kodieren und Übertragen einer Nachricht auf Chinesisch (im Vergleich zu einer entsprechenden Nachricht auf Englisch) nicht möglich
- 2 mal so teuer
- Dauerte 15–20 Mal länger
Klingt bekannt?
Die Telegrafie sei „in erster Linie entworfen worden für westliche alphabetische Sprachen vor allem Englisch.“[6] Der Morsecode ordnete Punkten und Strichen unterschiedliche Längen und Kosten zu, was zu einem kosteneffizienten System für Englisch führte. Allerdings stand die chinesische Sprache, die auf Ideogrammen basiert, in der Telegrafie vor Herausforderungen. Ein Franzose namens Viguier entwickelte ein System zur Zuordnung chinesischer Schriftzeichen zum Morsecode.
Im Wesentlichen wurde jedem chinesischen Ideogramm ein vierstelliger Code zugeordnet, der dann in Morsecode übersetzt werden musste. Das Nachschlagen der Codes im Codebuch (dem es an aussagekräftigen Korrelationen mangelte) dauerte lange und die Übertragung war teurer (da jedes Zeichen durch vier Ziffern dargestellt wurde und die Übertragung einer einzelnen Ziffer teurer war als die Übertragung eines einzelnen Buchstabens). Diese Praxis benachteiligte die chinesische Sprache im Vergleich zu anderen Sprachen hinsichtlich Telegrafiegeschwindigkeit und Kosten.
Ein weiteres Beispiel: Ungleichheit bei der Darstellung von Schriftarten
Zunächst habe ich versucht, alle 52 Sprachen in einer einzigen Wortwolke zu visualisieren. Am Ende hatte ich so etwas, bei dem die meisten Sprachen nicht richtig wiedergegeben wurden.

Dies führte dazu, dass ich auf der Suche nach einer Schriftart war, die alle Sprachskripte wiedergeben konnte. Ich habe bei Google Fonts nach dieser perfekten Schriftart gesucht und festgestellt, dass es keine gibt. Unten sehen Sie einen Screenshot, der zeigt, wie diese 52 Sprachen in drei verschiedenen Schriftarten von Google Fonts dargestellt würden.

Um die Wortwolke am Anfang dieses Artikels zu erstellen, habe ich (ehm) manuell die 17 Schriftartdateien heruntergeladen, die zum Rendern aller Sprachskripte und der Anzeige der Wörter einzeln erforderlich sind. Obwohl ich den gewünschten Effekt erzielt habe, war es viel aufwändiger, als es beispielsweise gewesen wäre, wenn alle meine Sprachen dieselbe Schrift verwendet hätten (z. B. das lateinische Alphabet).
In diesem Artikel habe ich die Sprachunterschiede in Sprachmodellen untersucht, indem ich untersucht habe, wie sie Text durch Tokenisierung verarbeiten.
- Anhand eines Datensatzes paralleler Texte, die in 52 Sprachen übersetzt wurden, habe ich gezeigt, dass einige Sprachen bis zu zehnmal mehr Token benötigen, um dieselbe Botschaft auf Englisch auszudrücken
- Ich habe ein geteilt Dashboard, in dem Sie verschiedene Sprachen und Tokenizer erkunden können
- Ich habe die Auswirkungen dieser Ungleichheit auf bestimmte Sprachen im Hinblick auf Leistung, monetäre Kosten und Zeit besprochen
- Ich habe gezeigt, dass dieses Muster sprachlich-technologischer Ungleichheit nicht neu ist, indem ich das Phänomen mit dem historischen Fall des chinesischen Morsecodes und der Telegrafie verglichen habe
Sprachunterschiede bei der NLP-Tokenisierung offenbaren ein dringendes Problem in der KI: Gerechtigkeit und Inklusivität. Da Modelle wie ChatGPT überwiegend auf Englisch trainiert sind, stoßen nicht-indogermanische und nicht-lateinische Skriptsprachen aufgrund der unerschwinglichen Tokenisierungskosten auf Hindernisse. Die Beseitigung dieser Ungleichheiten ist von entscheidender Bedeutung, um eine integrativere und zugänglichere Zukunft für künstliche Intelligenz zu gewährleisten, was letztendlich den vielfältigen Sprachgemeinschaften weltweit zugute kommt.
Anhang
Tokenisierung der Bytepaar-Kodierung
Im Bereich der Verarbeitung natürlicher Sprache spielen Tokenisierer eine entscheidende Rolle dabei, Sprachmodellen die Verarbeitung und das Verständnis von Text zu ermöglichen. Verschiedene Modelle verwenden unterschiedliche Methoden zur Tokenisierung eines Satzes, z. B. die Aufteilung in Wörter, Zeichen oder Wortteile (auch als Unterwörter bekannt; z. B. Aufteilen von „konstant“ in „konstant“ und „ly“).
Eine gängige Tokenisierung heißt Bytepaar-Kodierung (BPE). Dies ist die von OpenAI für ihre ChatGPT-Modelle verwendete Codierung. BPE soll seltene Wörter in sinnvolle Unterwörter zerlegen und dabei häufig verwendete Wörter intakt lassen. Eine ausführliche Erklärung des BPE-Algorithmus finden Sie auf der HuggingFace Transformers-Kurs.
Tauchen Sie tiefer in die Token-Verteilung für Sprachen ein
Ich habe den MASSIVE-Datensatz von Amazon erweitert, indem ich Informationen zu jeder der 52 Sprachen mithilfe des Infobox-Abschnitts der Wikipedia-Seite dieser Sprache verwendet und Informationen wie die Schreibschrift (z. B. lateinisches, arabisches Alphabet) und die wichtigste geografische Region erhalten habe, in der die Sprache vorherrscht (falls relevant). . Ich verwende zusätzlich Metadaten von Der Weltatlas der Sprachstrukturen um Informationen zu erhalten, z Sprachfamilie (z. B. indoeuropäisch, chinesisch-tibetisch).[7]
Beachten Sie, dass die folgenden Analysen in diesem Artikel die Annahmen von Wikipedia, dem Weltatlas der Sprachstrukturen und dem Amazon MASSIVE-Datensatz bestätigen. Da ich kein Linguistikexperte bin, musste ich davon ausgehen, dass alles, was auf Wikipedia und im Weltatlas steht, in Bezug auf die vorherrschende geografische Region oder Sprachfamilie kanonisch als korrekt akzeptiert wurde.
Außerdem gibt es Debatten darüber, was eine Sprache im Vergleich zu einem Dialekt ausmacht. Obwohl beispielsweise Sprachen wie Chinesisch und Arabisch unterschiedliche Formen haben, die die Menschen möglicherweise nicht verstehen, werden sie dennoch als Einzelsprachen bezeichnet. Andererseits sind Hindi und Urdu sehr ähnlich und werden manchmal als eine Sprache namens Hindustani zusammengefasst. Aufgrund dieser Herausforderungen müssen wir vorsichtig sein, wenn wir entscheiden, was als Sprache oder Dialekt gilt.
Aufschlüsselung nach Sprachen. Ich wählte die 12 am häufigsten gesprochene Sprachen (eine Kombination aus Sprechern der ersten und zweiten Sprache).
Aufschlüsselung nach Sprachfamilie. Indogermanische Sprachen (z. B. Schwedisch, Französisch), austronesische Sprachen (z. B. Indonesisch, Tagalog) und uralische Sprachen (z. B. Ungarisch, Finnisch) führten zu kürzeren Token. Dravidische Sprachen (z. B. Tamil, Kannada) hatten tendenziell längere Zeichen.

Aufschlüsselung nach geografischer Hauptregion. Nicht alle Sprachen waren spezifisch für eine einzelne geografische Region (z. B. Arabisch, Englisch und Spanisch, die über viele Regionen verteilt sind) – diese Sprachen wurden aus diesem Abschnitt entfernt. Sprachen, die hauptsächlich in Europa gesprochen werden, haben tendenziell eine kürzere Token-Länge, während Sprachen, die hauptsächlich im Nahen Osten, in Zentralasien und am Horn von Afrika gesprochen werden, tendenziell eine längere Token-Länge haben.

Aufschlüsselung durch Drehbuchschreiben. Abgesehen vom lateinischen, arabischen und kyrillischen Alphabet verwenden alle anderen Sprachen ihre eigene, einzigartige Schrift. Während Letzteres viele sehr unterschiedliche einzigartige Skripte (wie koreanische, hebräische und georgische Skripte) kombiniert, symbolisieren diese einzigartigen Skripte definitiv längere Werte. Im Vergleich zu lateinischen Skripten, die auf kürzere Werte umstellen.

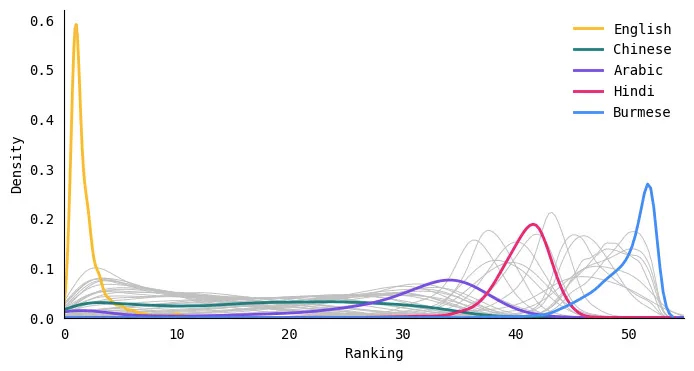
Englisch steht fast immer auf Platz 1
Für jeden Text im Datensatz habe ich alle Sprachen nach der Anzahl der Token eingestuft – die Sprache mit den wenigsten Token wurde auf Platz 1 und die mit den meisten Token auf Platz 52 platziert. Dann habe ich die Verteilung der einzelnen Sprachen aufgezeichnet Rang. Im Wesentlichen sollte dies zeigen, wie die Tokenlänge jeder Sprache im Vergleich zu den anderen Sprachen in diesem Datensatz abschneidet. In der folgenden Abbildung habe ich einige der Sprachen beschriftet (die anderen Sprachen werden als graue Linien im Hintergrund angezeigt).
Während es einige wenige Fälle gab, in denen die Tokens einiger Sprachen geringer waren als die des Englischen (z. B. einige Beispiele in Indonesisch oder Norwegisch), stand Englisch fast immer an erster Stelle. Kommt das für irgendjemanden überraschend? Was mich am meisten überraschte, war, dass es keine klare Nr. 2 oder Nr. 3 gab. Englischsprachige Texte produzieren durchweg die kürzesten Token, und bei anderen Sprachen schwankt die Rangfolge etwas stärker.
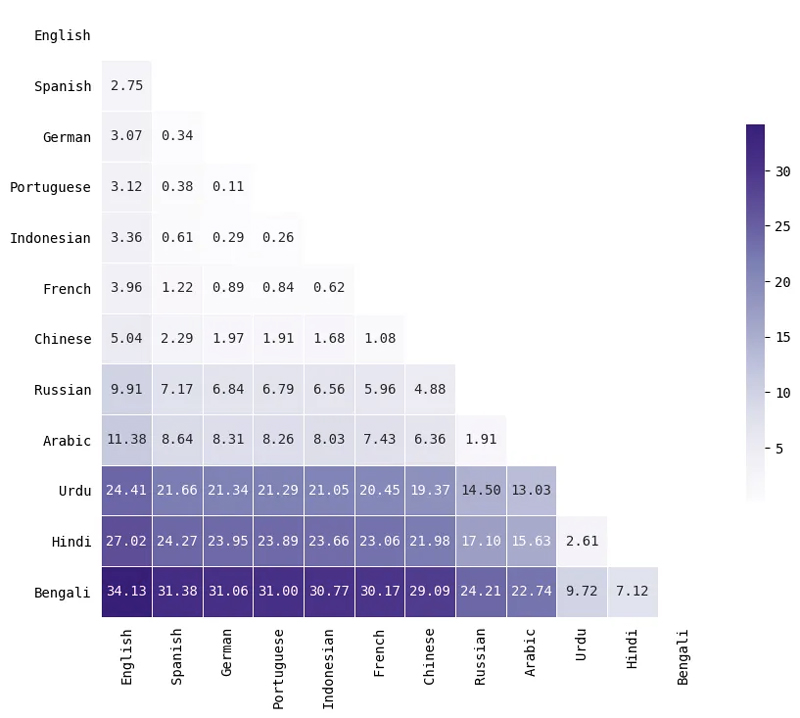
Quantifizierung der Unterschiede in der Token-Verteilung mithilfe der Earth Mover's Distance
Um zu quantifizieren, wie unterschiedlich die Token-Längenverteilung zwischen zwei Sprachen war, habe ich die berechnet Abstand der Erdbewegungsmaschine (Auch bekannt als Wasserstein-Distanz) zwischen zwei Verteilungen. Im Wesentlichen berechnet diese Metrik den minimalen „Arbeitsaufwand“, der erforderlich ist, um eine Verteilung in eine andere umzuwandeln. Größere Werte bedeuten, dass die Verteilungen weiter voneinander entfernt (unterschiedlicher) sind, während kleinere Werte bedeuten, dass die Verteilungen ziemlich ähnlich sind.
Hier ist eine kleine Teilmenge der Sprachen. Beachten Sie, dass der Abstand nichts über die Länge der Token aussagt, sondern nur darüber, wie ähnlich die Verteilung der Tokenlängen für zwei Sprachen ist. Arabisch und Russisch haben beispielsweise ähnliche Verbreitungen, obwohl die Sprachen selbst im sprachlichen Sinne nicht ähnlich sind.
1. OpenAI. „Modelle“. OpenAI-API. Archivierte vom Original am 17. März 2023. Abgerufen am 18. März 2023.
2. Sebastian Ruder, Ivan Vulić und Anders Søgaard. 2022. Square One Bias im NLP: Auf dem Weg zu einer mehrdimensionalen Erforschung der Forschungsvielfalt. in Erkenntnisse der Association for Computational Linguistics: ACL 2022, Seiten 2340–2354, Dublin, Irland. Verein für Computerlinguistik.
3. Shijie Wu und Mark Dredze. 2020. Sind im mehrsprachigen BERT alle Sprachen gleich?. in Vorträge des 5. Workshops zum Repräsentationslernen für NLP, Seiten 120–130, Online. Gesellschaft für Computerlinguistik.
4. Nutzungsstatistiken von Inhaltssprachen für Websites“. Archivierte vom Original am 30. April 2023.
5. Brown, Tom et al. „Sprachmodelle sind Wenig-Schuss-Lernende.“ Fortschritte in neuronalen Informationsverarbeitungssystemen 33 (2020): 1877 – 1901.
6. Jin Tsu. Königreich der Charaktere: Die Sprachrevolution, die China modern machte. New York: Riverhead Books, 2022 (S. 124).
7. Dryer, Matthew S. & Haspelmath, Martin (Hrsg.) 2013. WALS Online (v2020.3) [Datensatz]. Zenodo. https://doi.org/10.5281/zenodo.7385533. Online verfügbar unter https://wals.info, Zugriff am 2023.
Genießen Sie diesen Artikel? Melden Sie sich für weitere AI-Forschungsupdates an.
Wir werden Sie informieren, wenn wir weitere zusammenfassende Artikel wie diesen veröffentlichen.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- EVM-Finanzen. Einheitliche Schnittstelle für dezentrale Finanzen. Hier zugreifen.
- Quantum Media Group. IR/PR verstärkt. Hier zugreifen.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.topbots.com/all-languages-are-not-tokenized-equal/

