Die neue, formale Definition von „Agency“ gibt klare Prinzipien für die kausale Modellierung von KI-Agenten und die Anreize, denen sie ausgesetzt sind.
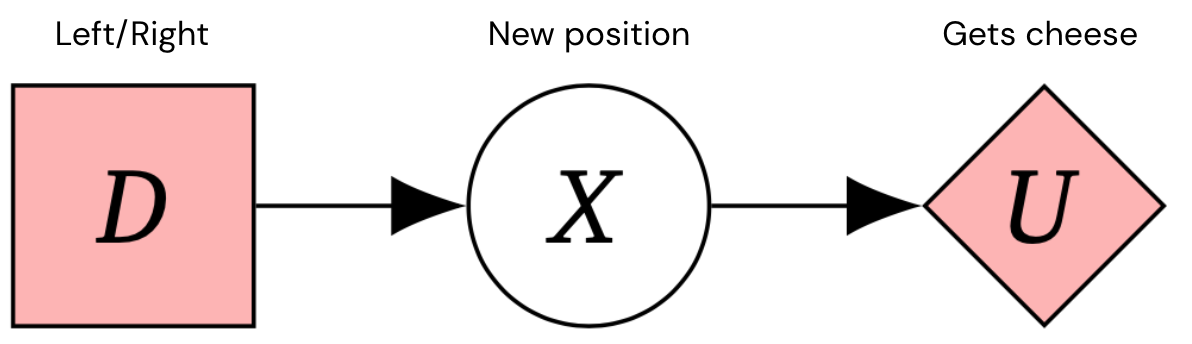
Wir wollen sichere, abgestimmte Systeme der künstlichen allgemeinen Intelligenz (AGI) bauen, die die beabsichtigten Ziele ihrer Entwickler verfolgen. Diagramme kausaler Einflüsse (CIDs) sind eine Möglichkeit, Entscheidungssituationen zu modellieren, die es uns ermöglichen, darüber nachzudenken Anreize für Agenten. Hier ist zum Beispiel ein CID für einen 1-stufigen Markov-Entscheidungsprozess – ein typisches Framework für Entscheidungsprobleme.

Indem Schulungsaufbauten mit den Anreizen in Beziehung gesetzt werden, die das Agentenverhalten prägen, helfen CIDs dabei, potenzielle Risiken vor der Schulung eines Agenten aufzuzeigen, und können zu besseren Agentendesigns anregen. Aber woher wissen wir, ob ein CID ein genaues Modell eines Trainingsaufbaus ist?
Unser neues Papier, Agenten entdecken, führt neue Wege zur Lösung dieser Probleme ein, darunter:
- Die erste formale kausale Definition von Agenten: Agenten sind Systeme, die ihre Politik anpassen würden, wenn ihre Handlungen die Welt auf andere Weise beeinflussen würden
- Ein Algorithmus zur Entdeckung von Agenten aus empirischen Daten
- Eine Übersetzung zwischen kausalen Modellen und CIDs
- Auflösung früherer Verwirrungen durch falsche kausale Modellierung von Agenten
Zusammen bieten diese Ergebnisse eine zusätzliche Sicherheit, dass kein Modellierungsfehler gemacht wurde, was bedeutet, dass CIDs verwendet werden können, um die Anreize und Sicherheitseigenschaften eines Agenten mit größerer Zuverlässigkeit zu analysieren.
Beispiel: Maus als Agent modellieren
Um unsere Methode zu veranschaulichen, stellen Sie sich das folgende Beispiel vor, das aus einer Welt besteht, die drei Quadrate enthält, wobei eine Maus im mittleren Quadrat beginnt und sich entscheidet, nach links oder rechts zu gehen, zur nächsten Position zu gelangen und dann möglicherweise etwas Käse zu bekommen. Der Boden ist vereist, sodass die Maus ausrutschen könnte. Mal ist der Käse rechts, mal links.

Dies kann durch die folgende CID dargestellt werden:
Die Intuition, dass die Maus für unterschiedliche Umgebungseinstellungen (Feisigkeit, Käseverteilung) ein unterschiedliches Verhalten wählen würde, kann durch a erfasst werden mechanisierter kausaler Graph, die für jede Variable (auf Objektebene) auch eine Mechanismusvariable enthält, die bestimmt, wie die Variable von ihren Eltern abhängt. Entscheidend ist, dass wir Verknüpfungen zwischen Mechanismusvariablen zulassen.
Dieses Diagramm enthält zusätzliche Mechanismusknoten in Schwarz, die die Politik der Maus und die Eis- und Käseverteilung darstellen.
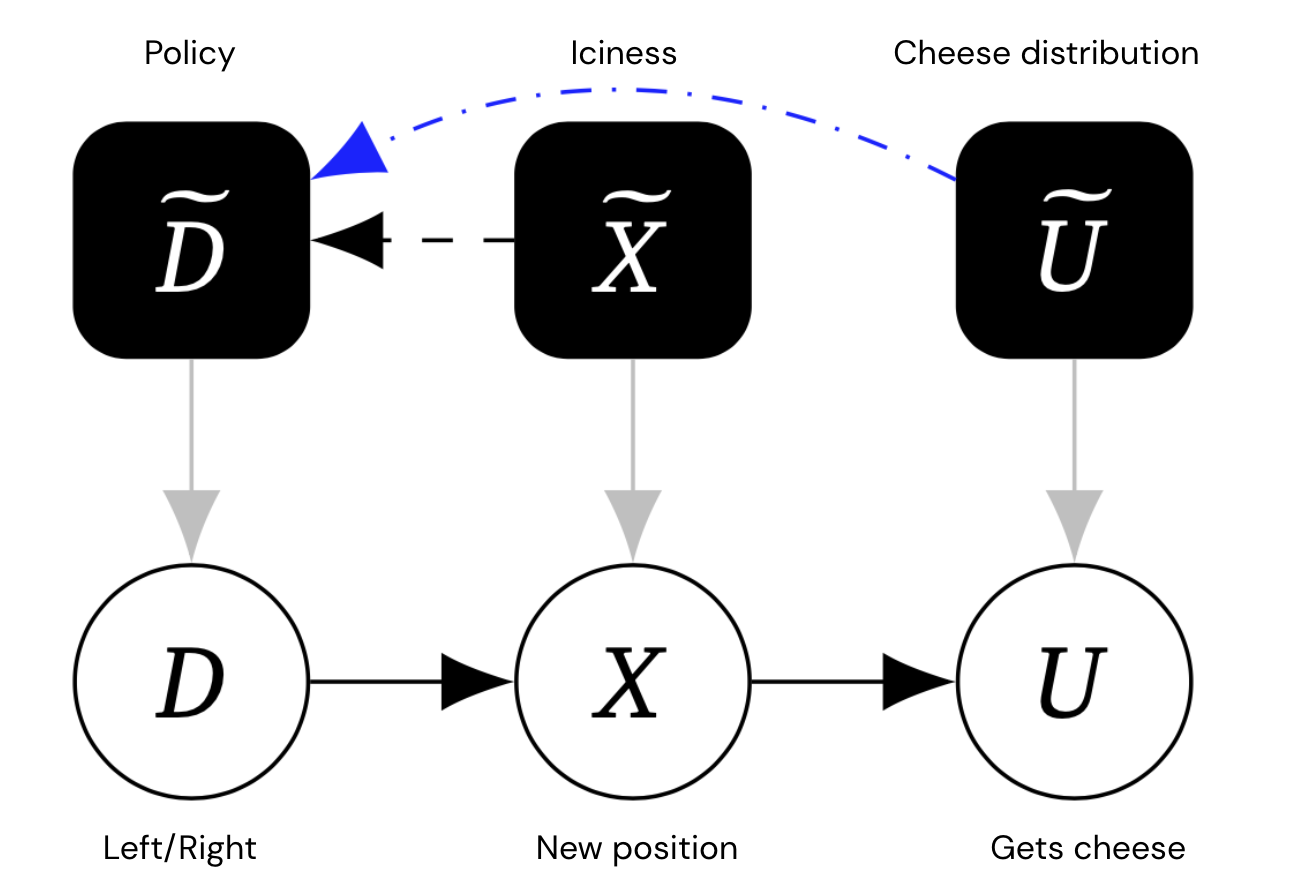
Kanten zwischen Mechanismen repräsentieren einen direkten kausalen Einfluss. Die blauen Ränder sind etwas Besonderes Terminal Kanten – ungefähr Mechanismuskanten A~ → B~, die immer noch da wären, selbst wenn die Variable A auf Objektebene so geändert würde, dass sie keine ausgehenden Kanten hätte.
Da U im obigen Beispiel keine Kinder hat, muss seine Mechanismuskante terminal sein. Aber die Mechanismuskante X~ → D~ ist nicht terminal, denn wenn wir X von seinem Kind U abschneiden, passt die Maus ihre Entscheidung nicht mehr an (weil ihre Position keinen Einfluss darauf hat, ob sie den Käse bekommt).
Kausale Entdeckung von Agenten
Die kausale Entdeckung leitet einen kausalen Graphen aus Experimenten ab, die Interventionen beinhalten. Insbesondere kann man einen Pfeil von einer Variablen A zu einer Variablen B entdecken, indem man experimentell auf A eingreift und prüft, ob B reagiert, selbst wenn alle anderen Variablen fest gehalten werden.
Unser erster Algorithmus verwendet diese Technik, um den mechanisierten kausalen Graphen zu entdecken:
Unser zweiter Algorithmus wandelt diesen mechanisierten Kausalgraphen in einen Spielgraphen um:

Zusammengenommen erlaubt uns Algorithmus 1, gefolgt von Algorithmus 2, Agenten aus kausalen Experimenten zu entdecken, indem wir sie durch CIDs darstellen.
Unser dritter Algorithmus wandelt den Spielgraphen in einen mechanisierten kausalen Graphen um, was es uns ermöglicht, unter einigen zusätzlichen Annahmen zwischen den Darstellungen des Spiels und mechanisierten kausalen Graphen zu übersetzen:

Bessere Sicherheitstools zum Modellieren von KI-Agenten
Wir haben die erste formale kausale Definition von Agenten vorgeschlagen. Basierend auf kausaler Entdeckung ist unsere wichtigste Erkenntnis, dass Agenten Systeme sind, die ihr Verhalten als Reaktion auf Veränderungen in der Art und Weise anpassen, wie ihre Handlungen die Welt beeinflussen. Tatsächlich beschreiben unsere Algorithmen 1 und 2 einen präzisen experimentellen Prozess, der dabei helfen kann zu beurteilen, ob ein System einen Agenten enthält.
Das Interesse an der kausalen Modellierung von KI-Systemen wächst schnell, und unsere Forschung begründet diese Modellierung in kausalen Entdeckungsexperimenten. Unser Papier demonstriert das Potenzial unseres Ansatzes durch die Verbesserung der Sicherheitsanalyse mehrerer beispielhafter KI-Systeme und zeigt, dass die Kausalität ein nützliches Framework ist, um herauszufinden, ob es einen Agenten in einem System gibt – ein zentrales Anliegen bei der Bewertung von Risiken durch AGI.

