Einleitung
Das Aufkommen von KI und maschinellem Lernen hat die Art und Weise, wie wir mit Informationen interagieren, revolutioniert und es einfacher gemacht, sie abzurufen, zu verstehen und zu nutzen. In diesem praktischen Leitfaden erkunden wir die Erstellung eines anspruchsvollen Frage-und-Antwort-Assistenten auf Basis von LLamA2 und LLamAIndex, der modernste Sprachmodelle und Indexierungs-Frameworks nutzt, um mühelos durch eine Flut von PDF-Dokumenten zu navigieren. Dieses Tutorial soll Entwicklern, Datenwissenschaftlern und Technikbegeisterten die Werkzeuge und das Wissen vermitteln, um ein Retrieval-Augmented Generation (RAG)-System aufzubauen, das auf den Schultern von Giganten im NLP-Bereich steht.
In unserem Bestreben, die Entwicklung eines KI-gesteuerten Frage-und-Antwort-Assistenten zu entmystifizieren, schlägt dieser Leitfaden eine Brücke zwischen komplexen theoretischen Konzepten und ihrer praktischen Anwendung in realen Szenarien. Durch die Integration des fortgeschrittenen Sprachverständnisses von LLamA2 mit den effizienten Informationsabruffunktionen von LLamAIndex möchten wir ein System aufbauen, das Fragen präzise beantwortet und unser Verständnis für das Potenzial und die Herausforderungen im Bereich NLP vertieft. Dieser Artikel dient als umfassende Roadmap für Enthusiasten und Profis und hebt die Synergie zwischen modernsten Modellen und den sich ständig weiterentwickelnden Anforderungen der Informationstechnologie hervor.

Lernziele
- Entwickeln Sie ein RAG-System mit dem LLamA2-Modell von Hugging Face.
- Integrieren Sie mehrere PDF-Dokumente.
- Indexieren Sie Dokumente für eine effiziente Suche.
- Erstellen Sie ein Abfragesystem.
- Erstellen Sie einen robusten Assistenten, der verschiedene Fragen beantworten kann.
- Konzentrieren Sie sich auf die praktische Umsetzung und nicht nur auf theoretische Aspekte.
- Beteiligen Sie sich an praktischer Programmierung und realen Anwendungen.
- Machen Sie die komplexe Welt des NLP zugänglich und ansprechend.
Inhaltsverzeichnis
LLamA2-Modell
LLamA2 ist ein Leuchtturm der Innovation in der Verarbeitung natürlicher Sprache und verschiebt die Grenzen dessen, was mit Sprachmodellen möglich ist. Seine sowohl auf Effizienz als auch Effektivität ausgelegte Architektur ermöglicht ein beispielloses Verständnis und die Erstellung menschenähnlicher Texte. Im Gegensatz zu seinen Vorgängern wie BERT und GPT bietet LLamA2 einen differenzierteren Ansatz zur Sprachverarbeitung, wodurch es sich besonders gut für Aufgaben eignet, die ein tiefes Verständnis erfordern, wie etwa die Beantwortung von Fragen. Sein Nutzen bei verschiedenen NLP-Aufgaben, von der Zusammenfassung bis zur Übersetzung, zeigt seine Vielseitigkeit und Fähigkeit bei der Bewältigung komplexer sprachlicher Herausforderungen.

LLamAIndex verstehen
Die Indizierung ist das Rückgrat jedes effizienten Informationsabrufsystems. LLamAIndex, ein Framework für die Indexierung und Abfrage von Dokumenten, zeichnet sich durch eine nahtlose Möglichkeit zur Verwaltung großer Dokumentensammlungen aus. Es geht nicht nur um das Speichern von Informationen; Es geht darum, es im Handumdrehen zugänglich und abrufbar zu machen.

Die Bedeutung von LLamAIndex kann nicht hoch genug eingeschätzt werden, da es die Verarbeitung von Abfragen in umfangreichen Datenbanken in Echtzeit ermöglicht und sicherstellt, dass unser Q&A-Assistent schnelle und genaue Antworten auf der Grundlage einer umfassenden Wissensdatenbank liefern kann.
Tokenisierung und Einbettungen
Der erste Schritt zum Verständnis von Sprachmodellen besteht darin, Text in überschaubare Teile zu zerlegen, ein Prozess, der als Tokenisierung bezeichnet wird. Diese grundlegende Aufgabe ist von entscheidender Bedeutung für die Vorbereitung von Daten für die weitere Verarbeitung. Nach der Tokenisierung kommt das Konzept der Einbettungen ins Spiel, bei dem Wörter und Sätze in numerische Vektoren übersetzt werden.
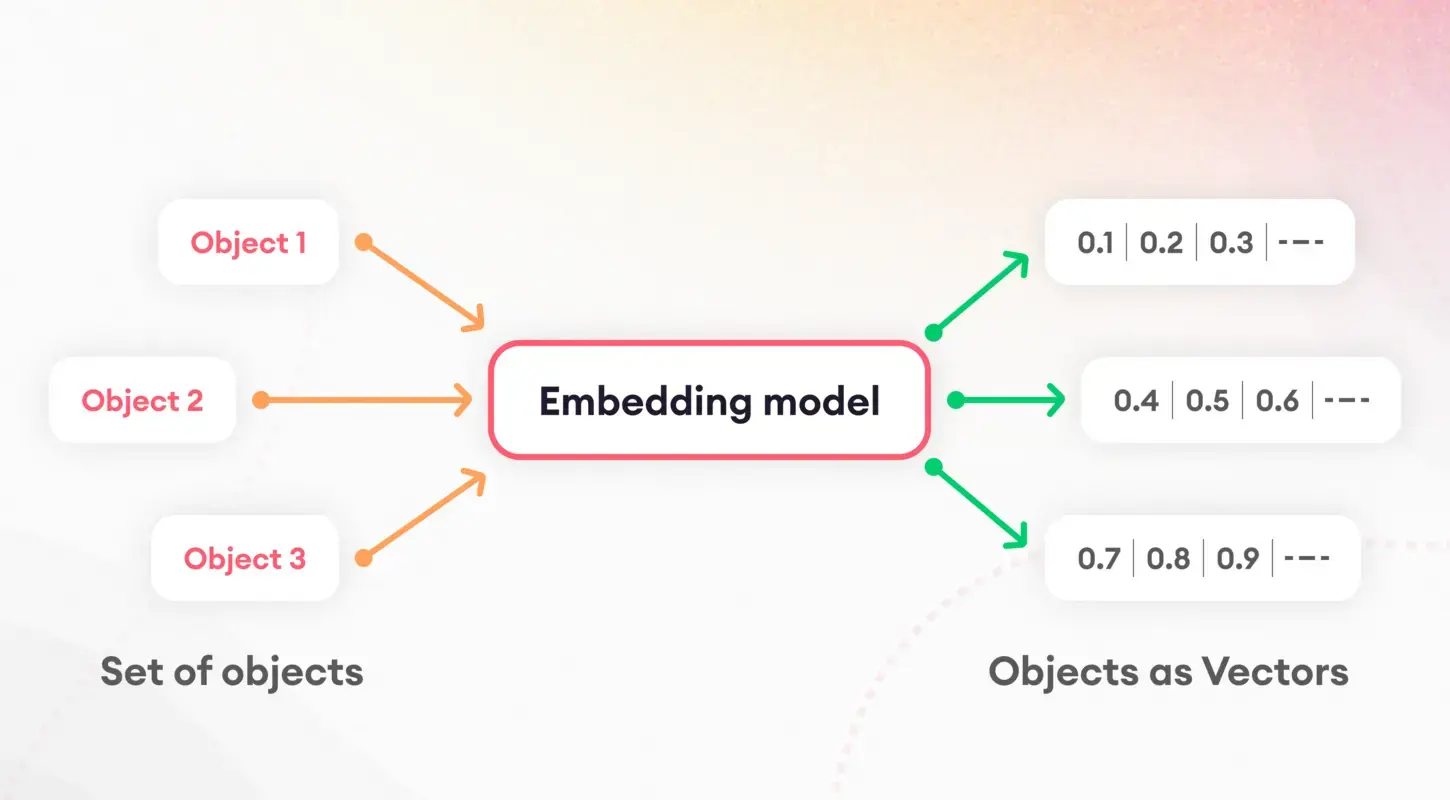
Diese Einbettungen erfassen die Essenz sprachlicher Merkmale und ermöglichen es Modellen, die zugrunde liegenden semantischen Eigenschaften von Texten zu erkennen und zu nutzen. Satzeinbettungen spielen insbesondere bei Aufgaben wie Dokumentähnlichkeit und -abruf eine entscheidende Rolle und bilden die Grundlage unserer Indexierungsstrategie.
Modellquantisierung
Die Modellquantisierung stellt eine Strategie zur Verbesserung der Leistung und Effizienz unseres Q&A-Assistenten dar. Indem wir die Präzision der numerischen Berechnungen des Modells verringern, können wir seine Größe erheblich verringern und die Inferenzzeiten verkürzen. Obwohl dieser Prozess einen Kompromiss zwischen Präzision und Effizienz mit sich bringt, ist er besonders in ressourcenbeschränkten Umgebungen wie mobilen Geräten oder Webanwendungen wertvoll. Durch sorgfältige Anwendung ermöglicht uns die Quantisierung, ein hohes Maß an Genauigkeit aufrechtzuerhalten und gleichzeitig von reduzierten Latenz- und Speicheranforderungen zu profitieren.
ServiceContext und Abfrage-Engine
Der ServiceContext in LLamAIndex ist ein zentraler Knotenpunkt für die Verwaltung von Ressourcen und Konfigurationen und stellt sicher, dass unser System reibungslos und effizient funktioniert. Der Kleber hält unsere Anwendung zusammen und ermöglicht eine nahtlose Integration zwischen den LLamA2-Modell, den Einbettungsprozess und die indizierten Dokumente. Andererseits ist die Abfrage-Engine das Arbeitstier, das Benutzeranfragen verarbeitet und die indizierten Daten nutzt, um relevante Informationen schnell abzurufen. Dieses duale Setup stellt sicher, dass unser Q&A-Assistent komplexe Anfragen problemlos bearbeiten kann und den Benutzern schnelle und genaue Antworten liefert.
Sytemimplementierung
Lassen Sie uns in die Umsetzung eintauchen. Bitte beachten Sie, dass ich zum Erstellen dieses Projekts Google Colab verwendet habe.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexDiese Befehle bereiten die Bühne, indem sie die erforderlichen Bibliotheken installieren, einschließlich Transformatoren für die Modellinteraktion und Satztransformatoren für Einbettungen. Die Installation von llama_index ist für unser Indexierungs-Framework von entscheidender Bedeutung.
Als Nächstes initialisieren wir unsere Komponenten (stellen Sie sicher, dass Sie im Abschnitt „Dateien“ in Google Colab einen Ordner mit dem Namen „data“ erstellen und laden Sie dann die PDF-Datei in den Ordner hoch):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptNachdem wir unsere Umgebung eingerichtet und die Dokumente gelesen haben, erstellen wir eine Systemaufforderung, um die Antworten des LLamA2-Modells zu steuern. Diese Vorlage trägt entscheidend dazu bei, dass die Ausgabe des Modells unseren Erwartungen an Genauigkeit und Relevanz entspricht.
!huggingface-cli login
Der obige Befehl ist ein Tor zum Zugriff auf das umfangreiche Modellarchiv von Hugging Face. Zur Authentifizierung ist ein Token erforderlich.
Sie müssen den folgenden Link besuchen: Gesicht umarmen (Stellen Sie sicher, dass Sie sich zuerst bei Hugging Face anmelden), erstellen Sie dann ein neues Token, geben Sie einen Namen für das Projekt ein, wählen Sie „Typ“ als „Gelesen“ aus und klicken Sie dann auf „Token generieren“.
Dieser Schritt unterstreicht, wie wichtig es ist, Ihre Entwicklungsumgebung zu sichern und zu personalisieren.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)Hier initialisieren wir das LLamA2-Modell mit spezifischen Parametern, die auf unser Q&A-System zugeschnitten sind. Dieser Aufbau unterstreicht die Vielseitigkeit und Fähigkeit des Modells, sich an verschiedene Kontexte und Anwendungen anzupassen.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))Die Wahl des Einbettungsmodells ist entscheidend für die Erfassung der semantischen Essenz unserer Dokumente. Durch den Einsatz von Satztransformatoren stellen wir sicher, dass unser System die Ähnlichkeit und Relevanz von Textinhalten genau einschätzen kann, wodurch die Wirksamkeit des Indexierungsprozesses verbessert wird.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)Der ServiceContext wird mit Standardeinstellungen instanziiert, wodurch unser LLamA2-Modell verknüpft und das Modell in ein zusammenhängendes Framework eingebettet wird. Dieser Schritt stellt sicher, dass alle Systemkomponenten harmonisiert und für Indizierungs- und Abfragevorgänge bereit sind.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()Diese Zeilen markieren den Höhepunkt unseres Einrichtungsprozesses, bei dem wir unsere Dokumente indizieren und die Abfrage-Engine vorbereiten. Dieses Setup ist von entscheidender Bedeutung für die Umstellung der Datenaufbereitung auf umsetzbare Erkenntnisse und ermöglicht es unserem Q&A-Assistenten, auf Anfragen basierend auf den indizierten Inhalten zu antworten.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)Abschließend haben wir unser System getestet, indem wir es nach Zusammenfassungen und Erkenntnissen aus unserer Dokumentensammlung abgefragt haben. Diese Interaktion demonstriert den praktischen Nutzen unseres Q&A-Assistenten und demonstriert die nahtlose Integration von LLamA2, LLamAIndex und dem zugrunde liegenden NLP-Technologien die es möglich machen.
Ausgang:

Ethische und rechtliche Implikationen
Bei der Entwicklung KI-gestützter Q&A-Systeme stehen mehrere ethische und rechtliche Aspekte im Vordergrund. Es ist von entscheidender Bedeutung, potenzielle Verzerrungen in den Trainingsdaten zu beseitigen und Fairness und Neutralität bei den Antworten sicherzustellen. Darüber hinaus ist die Einhaltung der Datenschutzbestimmungen von größter Bedeutung, da diese Systeme häufig vertrauliche Informationen verarbeiten. Entwickler müssen diese Herausforderungen mit Sorgfalt und Integrität meistern und sich dabei zu ethischen Grundsätzen verpflichten, die die Benutzer und die Integrität der bereitgestellten Informationen schützen.
Zukünftige Richtungen und Herausforderungen
Der Bereich der Q&A-Systeme bietet zahlreiche Möglichkeiten für Innovationen, von multimodalen Interaktionen bis hin zu domänenspezifischen Anwendungen. Allerdings bringen diese Fortschritte auch ihre eigenen Herausforderungen mit sich, darunter die Skalierung für große Dokumentensammlungen und die Sicherstellung der Vielfalt bei Benutzeranfragen. Die ständige Weiterentwicklung und Verfeinerung von Modellen wie LLamA2 und Indexierungs-Frameworks wie LLamAIndex ist entscheidend für die Überwindung dieser Hürden und die Erweiterung der Grenzen dessen, was im NLP möglich ist.
Fallstudien und Beispiele
Reale Implementierungen von Frage-und-Antwort-Systemen wie Kundenservice-Bots und Bildungstools unterstreichen die Vielseitigkeit und Wirkung von Technologien wie LLamA2 und LLamAIndex. Diese Fallstudien demonstrieren die praktischen Anwendungen von KI in verschiedenen Branchen, heben die Erfolgsgeschichten und gewonnenen Erkenntnisse hervor und liefern wertvolle Erkenntnisse für zukünftige Entwicklungen.
Zusammenfassung
Dieser Leitfaden hat die Landschaft der Erstellung eines PDF-basierten Q&A-Assistenten durchquert, von den grundlegenden Konzepten von LLamA2 und LLamAIndex bis hin zu den praktischen Implementierungsschritten. Während wir die Fähigkeiten der KI beim Abrufen und Verarbeiten von Informationen weiter erforschen und erweitern, ist das Potenzial, unsere Interaktion mit Wissen zu verändern, grenzenlos. Ausgestattet mit diesen Tools und Erkenntnissen steht die Reise zu intelligenteren und reaktionsschnelleren Systemen gerade erst am Anfang.
Key Take Away
- Revolutionierung der Informationsinteraktion: Die Integration von KI und maschinellem Lernen, am Beispiel von LLamA2 und LLamAIndex, hat die Art und Weise, wie wir auf Informationen zugreifen und sie nutzen, verändert und den Weg für hochentwickelte Frage-und-Antwort-Assistenten geebnet, die mühelos durch riesige Sammlungen von PDF-Dokumenten navigieren können.
- Praktische Brücke zwischen Theorie und Anwendung: Dieser Leitfaden schließt die Lücke zwischen theoretischen Konzepten und praktischer Umsetzung und befähigt Entwickler und Technikbegeisterte, Retrieval-Augmented Generation (RAG)-Systeme zu erstellen, die modernste NLP-Modelle und Indexierungs-Frameworks nutzen.
- Bedeutung einer effizienten Indizierung: LLamAIndex spielt eine entscheidende Rolle bei der effizienten Informationsbeschaffung durch die Indizierung umfangreicher Dokumentensammlungen. Dies gewährleistet schnelle und genaue Antworten auf Benutzeranfragen und verbessert die Gesamtfunktionalität des Q&A-Assistenten.
- Optimierung für Leistung und Effizienz: Techniken wie die Modellquantisierung verbessern die Leistung und Effizienz von Frage-und-Antwort-Assistenten und ermöglichen eine Reduzierung der Latenz und des Speicherbedarfs ohne Kompromisse bei der Genauigkeit.
- Ethische Überlegungen und zukünftige Richtungen: Die Entwicklung KI-gestützter Frage-und-Antwort-Systeme erfordert die Berücksichtigung ethischer und rechtlicher Implikationen, einschließlich der Voreingenommenheitsminderung und des Datenschutzes. Mit Blick auf die Zukunft bieten Fortschritte bei Q&A-Systemen Chancen für Innovationen, stellen aber auch Herausforderungen hinsichtlich der Skalierbarkeit und Vielfalt der Benutzeranfragen dar
Oft gestellte Frage
Antwort. LLamA2 bietet einen differenzierteren Ansatz zur Sprachverarbeitung und ermöglicht tiefgreifende Verständnisaufgaben wie die Beantwortung von Fragen. Seine Architektur legt Wert auf Effizienz und Effektivität und macht es vielseitig für verschiedene NLP-Aufgaben.
Antwort. LLamAIndex ist ein Framework für die Indizierung und Abfrage von Dokumenten, das die Echtzeit-Abfrageverarbeitung in umfangreichen Datenbanken ermöglicht. Es stellt sicher, dass Q&A-Assistenten schnell relevante Informationen aus umfangreichen Wissensdatenbanken abrufen können.
Antwort. Einbettungen, insbesondere Satzeinbettungen, erfassen die semantische Essenz von Textinhalten und ermöglichen so eine genaue Messung von Ähnlichkeit und Relevanz. Dies erhöht die Effizienz des Indexierungsprozesses und verbessert die Fähigkeit des Assistenten, relevante Antworten zu geben.
Antwort. Die Modellquantisierung optimiert Leistung und Effizienz, indem sie den Umfang numerischer Berechnungen reduziert und dadurch die Latenz und den Speicherbedarf verringert. Obwohl es einen Kompromiss zwischen Präzision und Effizienz mit sich bringt, ist es in Umgebungen mit begrenzten Ressourcen wertvoll.
Antwort. Entwickler müssen potenzielle Verzerrungen in Trainingsdaten ansprechen, Fairness und Neutralität bei den Antworten gewährleisten und Datenschutzbestimmungen einhalten. Durch die Einhaltung ethischer Grundsätze werden Benutzer geschützt und die Integrität der vom Q&A-Assistenten bereitgestellten Informationen gewahrt.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

