
Bild vom Autor
Einer der Bereiche, die der Datenwissenschaft zugrunde liegen, ist maschinelles Lernen. Wenn Sie also in die Datenwissenschaft einsteigen möchten, ist das Verständnis von maschinellem Lernen einer der ersten Schritte, die Sie unternehmen müssen.
Aber wo fängt man an? Sie beginnen damit, den Unterschied zwischen den beiden Haupttypen von Algorithmen für maschinelles Lernen zu verstehen. Erst danach können wir über einzelne Algorithmen sprechen, die auf Ihrer Prioritätenliste für das Erlernen als Anfänger stehen sollten.
Der Hauptunterschied zwischen den Algorithmen basiert auf der Art und Weise, wie sie lernen.

Bild vom Autor
Überwachte Lernalgorithmen werden auf a ausgebildet beschrifteter Datensatz. Dieser Datensatz dient als Lernhilfe (daher der Name), da einige darin enthaltene Daten bereits als richtige Antwort gekennzeichnet sind. Basierend auf dieser Eingabe kann der Algorithmus lernen und dieses Lernen auf den Rest der Daten anwenden.
Auf der anderen Seite, unbeaufsichtigte Lernalgorithmen lerne auf einem unbeschrifteter DatensatzDas heißt, sie beschäftigen sich damit, Muster in Daten zu finden, ohne dass Menschen ihnen Anweisungen geben.
Sie können mehr darüber lesen Algorithmen für maschinelles Lernen und Arten des Lernens.
Es gibt auch einige andere Arten des maschinellen Lernens, allerdings nicht für Anfänger.
Algorithmen werden eingesetzt, um zwei unterschiedliche Hauptprobleme innerhalb jeder Art des maschinellen Lernens zu lösen.
Auch hier gibt es einige weitere Aufgaben, diese sind jedoch nichts für Anfänger.

Bild vom Autor
Überwachte Lernaufgaben
Regression ist die Aufgabe, a vorherzusagen numerischer Wert, Rief kontinuierliche Ergebnisvariable oder abhängige Variable. Die Vorhersage basiert auf der/den Prädiktorvariablen oder unabhängigen Variablen.
Denken Sie an die Vorhersage von Ölpreisen oder Lufttemperaturen.
Klassifikation wird verwendet, um das vorherzusagen Kategorie (Klasse) der Eingabedaten. Der Ergebnisvariable hier ist kategorisch oder diskret.
Denken Sie darüber nach, vorherzusagen, ob es sich bei der E-Mail um Spam handelt oder nicht, oder ob der Patient eine bestimmte Krankheit bekommen wird oder nicht.
Unbeaufsichtigte Lernaufgaben
Clustering Mittel Aufteilen von Daten in Teilmengen oder Cluster. Ziel ist es, Daten so natürlich wie möglich zu gruppieren. Das bedeutet, dass Datenpunkte innerhalb desselben Clusters einander ähnlicher sind als Datenpunkte aus anderen Clustern.
Dimensionsreduzierung bezieht sich auf die Reduzierung der Anzahl der Eingabevariablen in einem Datensatz. Es bedeutet im Grunde Reduzieren des Datensatzes auf sehr wenige Variablen und gleichzeitiges Erfassen seines Wesens.
Hier ist eine Übersicht über die Algorithmen, die ich behandeln werde.
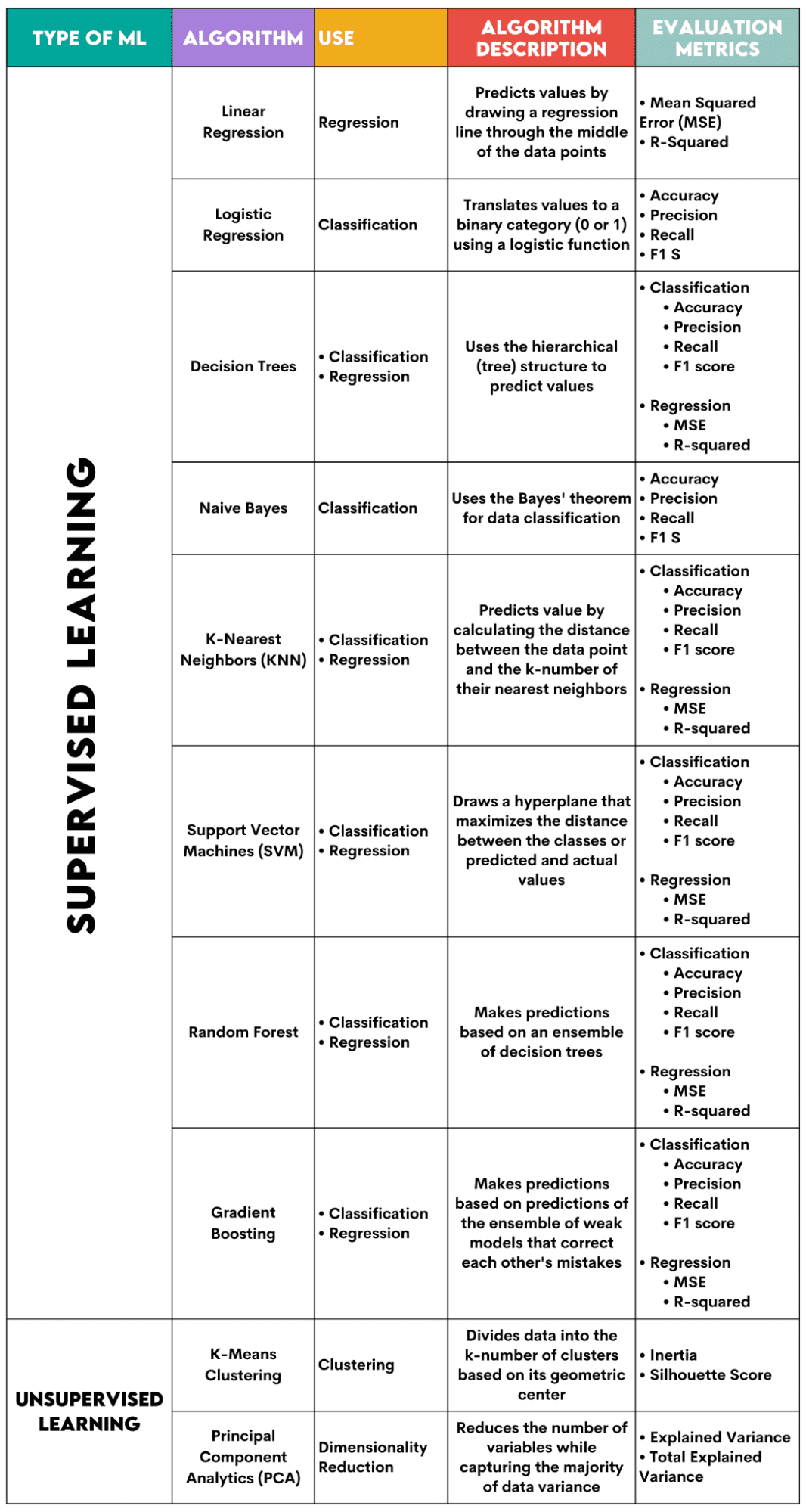
Bild vom Autor
Überwachte Lernalgorithmen
Bei der Auswahl des Algorithmus für Ihr Problem ist es wichtig zu wissen, für welche Aufgabe der Algorithmus verwendet wird.
Als Datenwissenschaftler werden Sie diese Algorithmen wahrscheinlich mithilfe von in Python anwenden scikit-learn-Bibliothek. Obwohl es (fast) alles für Sie erledigt, ist es ratsam, dass Sie zumindest die allgemeinen Prinzipien des Innenlebens jedes Algorithmus kennen.
Nachdem der Algorithmus trainiert wurde, sollten Sie schließlich bewerten, wie gut er funktioniert. Zu diesem Zweck verfügt jeder Algorithmus über einige Standardmetriken.
1. Lineare Regression
Benutzt für: Regression
Beschreibung: Die lineare Regression zeichnet eine gerade Linie wird als Regressionsgerade zwischen den Variablen bezeichnet. Diese Linie verläuft ungefähr durch die Mitte der Datenpunkte und minimiert so den Schätzfehler. Es zeigt den vorhergesagten Wert der abhängigen Variablen basierend auf dem Wert der unabhängigen Variablen.
Bewertungsmetriken:
- Mittlerer quadratischer Fehler (MSE): Stellt den Durchschnitt des quadratischen Fehlers dar, wobei der Fehler die Differenz zwischen tatsächlichen und vorhergesagten Werten ist. Je niedriger der Wert, desto besser ist die Leistung des Algorithmus.
- R-Quadrat: Stellt den Varianzprozentsatz der abhängigen Variablen dar, der von der unabhängigen Variablen vorhergesagt werden kann. Bei diesem Maß sollten Sie versuchen, so nah wie möglich an 1 heranzukommen.
2. Logistische Regression
Benutzt für: Klassifikation
Beschreibung: Es verwendet a logistische Funktion um die Datenwerte in eine binäre Kategorie zu übersetzen, z. B. 0 oder 1. Dies erfolgt mithilfe des Schwellenwerts, der normalerweise auf 0.5 eingestellt ist. Das binäre Ergebnis macht diesen Algorithmus perfekt für die Vorhersage binärer Ergebnisse wie JA/NEIN, WAHR/FALSCH oder 0/1.
Bewertungsmetriken:
- Genauigkeit: Das Verhältnis zwischen korrekten und vollständigen Vorhersagen. Je näher an 1, desto besser.
- Präzision: Das Maß für die Modellgenauigkeit bei positiven Vorhersagen; wird als Verhältnis zwischen korrekten positiven Vorhersagen und insgesamt erwarteten positiven Ergebnissen angezeigt. Je näher an 1, desto besser.
- Zur Erinnerung: Auch hier wird die Genauigkeit des Modells bei positiven Vorhersagen gemessen. Sie wird als Verhältnis zwischen korrekten positiven Vorhersagen und den gesamten in der Klasse gemachten Beobachtungen ausgedrückt. Erfahren Sie mehr über diese Kennzahlen hier.
- F1-Punktzahl: Das harmonische Mittel der Erinnerung und Präzision des Modells. Je näher an 1, desto besser.
3. Entscheidungsbäume
Benutzt für: Regression und Klassifizierung
Beschreibung: Entscheidungsbäume sind Algorithmen, die die hierarchische oder Baumstruktur verwenden, um einen Wert oder eine Klasse vorherzusagen. Der Wurzelknoten stellt den gesamten Datensatz dar, der dann basierend auf den Variablenwerten in Entscheidungsknoten, Verzweigungen und Blätter verzweigt.
Bewertungsmetriken:
- Genauigkeit, Präzision, Erinnerung und F1-Score -> zur Klassifizierung
- MSE, R-Quadrat -> für Regression
4. Naive Bayes
Benutzt für: Klassifikation
Beschreibung: Dies ist eine Familie von Klassifizierungsalgorithmen, die verwendet werden Satz von Bayes, was bedeutet, dass sie die Unabhängigkeit zwischen Features innerhalb einer Klasse voraussetzen.
Bewertungsmetriken:
- Genauigkeit
- Präzision
- Erinnern
- F1-Punktzahl
5. K-Nächste Nachbarn (KNN)
Benutzt für: Regression und Klassifizierung
Beschreibung: Es berechnet den Abstand zwischen den Testdaten und dem k-Nummer der nächstgelegenen Datenpunkte aus den Trainingsdaten. Die Testdaten gehören zu einer Klasse mit einer höheren Anzahl von „Nachbarn“. Bezüglich der Regression ist der vorhergesagte Wert der Durchschnitt der k ausgewählten Trainingspunkte.
Bewertungsmetriken:
- Genauigkeit, Präzision, Erinnerung und F1-Score -> zur Klassifizierung
- MSE, R-Quadrat -> für Regression
6. Support Vector Machines (SVM)
Benutzt für: Regression und Klassifizierung
Beschreibung: Dieser Algorithmus zeichnet a Hyperebene um verschiedene Datenklassen zu trennen. Es befindet sich im größten Abstand von den nächstgelegenen Punkten jeder Klasse. Je größer der Abstand des Datenpunkts von der Hyperebene ist, desto mehr gehört er zu seiner Klasse. Bei der Regression ist das Prinzip ähnlich: Die Hyperebene maximiert den Abstand zwischen den vorhergesagten und den tatsächlichen Werten.
Bewertungsmetriken:
- Genauigkeit, Präzision, Erinnerung und F1-Score -> zur Klassifizierung
- MSE, R-Quadrat -> für Regression
7. Zufälliger Wald
Benutzt für: Regression und Klassifizierung
Beschreibung: Der Random-Forest-Algorithmus verwendet ein Ensemble von Entscheidungsbäumen, die dann einen Entscheidungswald bilden. Die Vorhersage des Algorithmus basiert auf der Vorhersage vieler Entscheidungsbäume. Die Daten werden der Klasse zugeordnet, die die meisten Stimmen erhält. Bei der Regression ist der vorhergesagte Wert ein Durchschnitt aller vorhergesagten Werte der Bäume.
Bewertungsmetriken:
- Genauigkeit, Präzision, Erinnerung und F1-Score -> zur Klassifizierung
- MSE, R-Quadrat -> für Regression
8. Gradientenverstärkung
Benutzt für: Regression und Klassifizierung
Beschreibung: Diese Algorithmen Verwenden Sie ein Ensemble schwacher Modelle, wobei jedes nachfolgende Modell die Fehler des vorherigen Modells erkennt und korrigiert. Dieser Vorgang wird wiederholt, bis der Fehler (Verlustfunktion) minimiert ist.
Bewertungsmetriken:
- Genauigkeit, Präzision, Erinnerung und F1-Score -> zur Klassifizierung
- MSE, R-Quadrat -> für Regression
Unüberwachte Lernalgorithmen
9. K-Means-Clustering
Benutzt für: Clustering
Beschreibung: Der Algorithmus unterteilt den Datensatz in k-zahlige Cluster, die jeweils durch ihre eigenen repräsentiert werden Schwerpunkt oder geometrischer Mittelpunkt. Durch den iterativen Prozess der Aufteilung der Daten in eine k-Anzahl von Clustern besteht das Ziel darin, den Abstand zwischen den Datenpunkten und dem Schwerpunkt ihres Clusters zu minimieren. Andererseits wird auch versucht, den Abstand dieser Datenpunkte vom Schwerpunkt der anderen Cluster zu maximieren. Vereinfacht gesagt sollten die zum selben Cluster gehörenden Daten möglichst ähnlich und möglichst unterschiedlich zu den Daten anderer Cluster sein.
Bewertungsmetriken:
- Trägheit: Die Summe der quadrierten Entfernung jedes Datenpunkts vom nächstgelegenen Clusterschwerpunkt. Je niedriger der Trägheitswert, desto kompakter ist der Cluster.
- Silhouette Score: Er misst den Zusammenhalt (die Ähnlichkeit der Daten innerhalb ihres eigenen Clusters) und die Trennung (den Unterschied der Daten zu anderen Clustern) der Cluster. Der Wert dieser Punktzahl liegt zwischen -1 und +1. Je höher der Wert, desto besser stimmen die Daten mit ihrem Cluster überein und desto schlechter stimmen sie mit anderen Clustern überein.
10. Hauptkomponentenanalyse (PCA)
Benutzt für: Reduzierung der Dimensionalität
Beschreibung: Der Algorithmus Reduziert die Anzahl der verwendeten Variablen durch die Konstruktion neuer Variablen (Hauptkomponenten) und versucht gleichzeitig, die erfasste Varianz der Daten zu maximieren. Mit anderen Worten: Es beschränkt die Daten auf ihre häufigsten Komponenten, ohne dabei das Wesentliche der Daten zu verlieren.
Bewertungsmetriken:
- Erklärte Varianz: Der Prozentsatz der Varianz, der von jeder Hauptkomponente abgedeckt wird.
- Gesamte erklärte Varianz: Der Prozentsatz der Varianz, der von allen Hauptkomponenten abgedeckt wird.
Maschinelles Lernen ist ein wesentlicher Bestandteil der Datenwissenschaft. Mit diesen zehn Algorithmen decken Sie die häufigsten Aufgaben des maschinellen Lernens ab. Natürlich gibt Ihnen dieser Überblick nur einen allgemeinen Überblick über die Funktionsweise der einzelnen Algorithmen. Das ist also nur ein Anfang.
Jetzt müssen Sie lernen, wie Sie diese Algorithmen in Python implementieren und echte Probleme lösen. Dabei empfehle ich die Verwendung von scikit-learn. Nicht nur, weil es sich um eine relativ einfach zu verwendende ML-Bibliothek handelt, sondern auch wegen ihrer umfangreiche Materialien zu ML-Algorithmen.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Top-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Trends auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Data-Science-Projekte vor und behandelt alles rund um SQL.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/a-beginner-guide-to-the-top-10-machine-learning-algorithms?utm_source=rss&utm_medium=rss&utm_campaign=a-beginners-guide-to-the-top-10-machine-learning-algorithms

