Einleitung
Retrieval Augmented-Generation (RAG) hat seit seiner Einführung die Welt im Sturm erobert. RAG ist erforderlich, damit die Large Language Models (LLMs) genaue und sachliche Antworten liefern oder generieren können. Wir lösen die Faktizität von LLMs durch RAG, wobei wir versuchen, dem LLM einen Kontext zu geben, der der Benutzeranfrage kontextuell ähnlich ist, damit das LLM mit diesem Kontext arbeitet und eine sachlich korrekte Antwort generiert. Dies erreichen wir, indem wir unsere Daten und Benutzerabfragen in Form von Vektoreinbettungen darstellen und eine Kosinusähnlichkeit durchführen. Das Problem besteht jedoch darin, dass alle herkömmlichen Ansätze die Daten in einer einzigen Einbettung darstellen, was möglicherweise nicht unbedingt ideal ist Retrieval-Systeme. In diesem Leitfaden befassen wir uns mit ColBERT, das den Abruf mit höherer Genauigkeit durchführt als herkömmliche Bi-Encoder-Modelle.
Lernziele
- Verstehen Sie, wie das Abrufen in RAG auf hohem Niveau funktioniert.
- Verstehen Sie die Einschränkungen bei der Einbettung einzelner Daten beim Abruf.
- Verbessern Sie den Abrufkontext mit den Token-Einbettungen von ColBERT.
- Erfahren Sie, wie die späte Interaktion von ColBERT das Abrufen verbessert.
- Erfahren Sie, wie Sie mit ColBERT für eine genaue Recherche arbeiten.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Was ist RAG?
Obwohl LLMs in der Lage sind, sowohl bedeutungsvollen als auch grammatikalisch korrekten Text zu generieren, leiden sie unter einem Problem namens Halluzination. Halluzination bei LLMs ist das Konzept, bei dem die LLMs selbstbewusst falsche Antworten generieren, das heißt, sie erfinden falsche Antworten auf eine Weise, die uns glauben lässt, dass sie wahr sind. Dies ist seit der Einführung der LLMs ein großes Problem. Diese Halluzinationen führen zu falschen und sachlich falschen Antworten. Daher wurde Retrieval Augmented Generation eingeführt.
In RAG nehmen wir eine Liste von Dokumenten/Dokumentenblöcken und kodieren diese Textdokumente in eine numerische Darstellung namens Vektoreinbettungen, wobei eine einzelne Vektoreinbettung einen einzelnen Dokumentblock darstellt und sie in einer Datenbank namens „ Vektorspeicher. Die zum Codieren dieser Chunks in Einbettungen erforderlichen Modelle werden Codierungsmodelle oder Bi-Encoder genannt. Diese Encoder werden auf einem großen Datenkorpus trainiert und sind daher leistungsstark genug, um die Dokumentblöcke in einer einzigen Vektoreinbettungsdarstellung zu codieren.
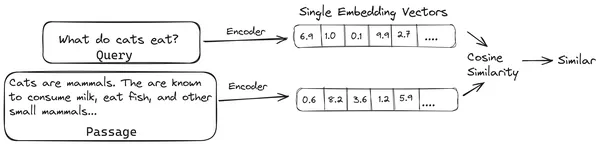
Wenn nun ein Benutzer eine Anfrage an das LLM stellt, übergeben wir diese Anfrage an denselben Encoder, um eine einzelne Vektoreinbettung zu erzeugen. Diese Einbettung wird dann verwendet, um den Ähnlichkeitswert mit verschiedenen anderen Vektoreinbettungen der Dokumentteile zu berechnen, um den relevantesten Teil des Dokuments zu erhalten. Der relevanteste Block oder eine Liste der relevantesten Blöcke werden zusammen mit der Benutzeranfrage an das LLM übergeben. Das LLM empfängt dann diese zusätzlichen Kontextinformationen und generiert dann eine Antwort, die auf den Kontext abgestimmt ist, der von der Benutzeranfrage erhalten wurde. Dadurch wird sichergestellt, dass die vom LLM generierten Inhalte sachlich sind und bei Bedarf nachvollzogen werden können.
Das Problem mit herkömmlichen Bi-Encodern
Das Problem mit herkömmlichen Encoder-Modellen wie dem All-MiniLM, OpenAI Das Einbettungsmodell und andere Encodermodelle bestehen darin, dass sie den gesamten Text in eine einzige Vektoreinbettungsdarstellung komprimieren. Diese Einzelvektor-Einbettungsdarstellungen sind nützlich, da sie beim effizienten und schnellen Auffinden ähnlicher Dokumente helfen. Das Problem liegt jedoch in der Kontextualität zwischen der Anfrage und dem Dokument. Die Einbettung eines einzelnen Vektors reicht möglicherweise nicht aus, um die Kontextinformationen eines Dokumentblocks zu speichern, wodurch ein Informationsengpass entsteht.
Stellen Sie sich vor, dass 500 Wörter auf einen einzigen Vektor der Größe 782 komprimiert werden. Es reicht möglicherweise nicht aus, einen solchen Teil mit der Einbettung eines einzelnen Vektors darzustellen, was in den meisten Fällen zu unterdurchschnittlichen Ergebnissen beim Abruf führt. Die Einzelvektordarstellung kann auch bei komplexen Abfragen oder Dokumenten fehlschlagen. Eine solche Lösung wäre, den Dokumentblock oder eine Abfrage als Liste von Einbettungsvektoren anstelle eines einzelnen Einbettungsvektors darzustellen. Hier kommt ColBERT ins Spiel.
Was ist ColBERT?
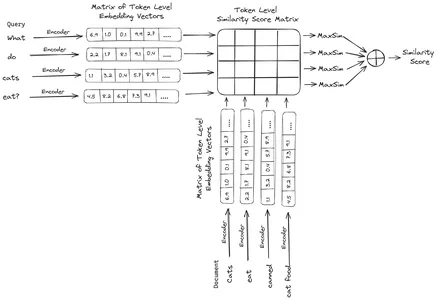
ColBERT (Contextual Late Interactions BERT) ist ein Bi-Encoder, der Text in einer Multi-Vektor-Einbettungsdarstellung darstellt. Es nimmt eine Abfrage oder einen Teil eines Dokuments/ein kleines Dokument auf und erstellt Vektoreinbettungen auf Token-Ebene. Das heißt, jedes Token erhält seine eigene Vektoreinbettung und die Abfrage/das Dokument wird in eine Liste von Vektoreinbettungen auf Token-Ebene codiert. Die Einbettungen auf Token-Ebene werden aus einem vorab trainierten generiert BERT Modell, daher der Name BERT.
Diese werden dann in der Vektordatenbank gespeichert. Wenn nun eine Anfrage eingeht, wird für sie eine Liste von Einbettungen auf Token-Ebene erstellt und dann eine Matrixmultiplikation zwischen der Benutzeranfrage und jedem Dokument durchgeführt, wodurch eine Matrix mit Ähnlichkeitswerten entsteht. Die Gesamtähnlichkeit wird erreicht, indem für jedes Abfragetoken die Summe der maximalen Ähnlichkeit der Dokumenttokens ermittelt wird. Die Formel hierfür ist im folgenden Bild zu sehen:
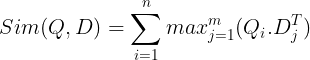
Hier in der obigen Gleichung sehen wir, dass wir ein Skalarprodukt zwischen der Abfrage-Token-Matrix (die N Vektoreinbettungen auf Token-Ebene enthält) und der Transpose of Document Tokens-Matrix (die M Vektor-Einbettungen auf Token-Ebene enthält) erstellen und dann die maximale Ähnlichkeit ermitteln Kreuzen Sie die Dokumenttoken für jedes Abfragetoken an. Dann bilden wir die Summe aller dieser maximalen Ähnlichkeiten, was uns den endgültigen Ähnlichkeitswert zwischen dem Dokument und der Abfrage ergibt. Der Grund, warum dies zu einem effektiven und genauen Abruf führt, liegt darin, dass es sich hier um eine Interaktion auf Token-Ebene handelt, die Raum für ein besseres kontextbezogenes Verständnis zwischen der Abfrage und dem Dokument bietet.
Warum der Name ColBERT?
Da wir die Liste der Einbettungsvektoren vor sich selbst berechnen und diese MaxSim-Operation (maximale Ähnlichkeit) nur während der Modellinferenz ausführen, was wir als späten Interaktionsschritt bezeichnen, und da wir durch Interaktionen auf Token-Ebene mehr Kontextinformationen erhalten, wird sie als kontextuell bezeichnet späte Interaktionen. Daher der Name „Contextual Late Interactions“. BERT oder ColBERT. Diese Berechnungen können parallel durchgeführt werden und sind daher effizient zu berechnen. Ein Problem ist schließlich der Platzbedarf, d. h. die Speicherung dieser Liste von Vektoreinbettungen auf Token-Ebene erfordert viel Platz. Dieses Problem wurde in ColBERTv2 gelöst, wo die Einbettungen durch die Technik der Restkomprimierung komprimiert werden, wodurch der genutzte Platz optimiert wird.
Praktisches ColBERT mit Beispiel
In diesem Abschnitt werden wir ColBERT praktisch ausprobieren und sogar prüfen, wie es im Vergleich zu einem regulären Einbettungsmodell abschneidet.
Schritt 1: Bibliotheken herunterladen
Wir beginnen mit dem Herunterladen der folgenden Bibliothek:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Mit dieser Bibliothek können wir auf benutzerfreundliche Weise mit modernsten (SOTA) Retrieval-Methoden wie ColBERT arbeiten. Es bietet Optionen zum Erstellen von Indizes für die Datensätze, zum Abfragen dieser Datensätze und ermöglicht es uns sogar, ein ColBERT-Modell auf unseren Daten zu trainieren.
- LangChain: Mit dieser Bibliothek können wir mit den Open-Source-Einbettungsmodellen arbeiten, sodass wir testen können, wie gut die anderen Einbettungsmodelle im Vergleich zu ColBERT funktionieren.
- langchain_openai: Installiert die LangChain Abhängigkeiten für OpenAI. Wir werden sogar mit dem OpenAI Embedding-Modell arbeiten, um seine Leistung mit dem ColBERT zu vergleichen.
- ChromaDB: Mit dieser Bibliothek können wir in unserer Umgebung einen Vektorspeicher erstellen, sodass wir die Einbettungen, die wir in unseren Daten erstellt haben, speichern und später eine semantische Suche zwischen der Abfrage und den gespeicherten Einbettungen durchführen können.
- einops: Diese Bibliothek wird für effiziente Tensormatrixmultiplikationen benötigt.
- Satztransformatoren und dem Tiktoken Die Bibliothek wird benötigt, damit die Open-Source-Einbettungsmodelle ordnungsgemäß funktionieren.
Schritt 2: Laden Sie das vorab trainierte Modell herunter
Im nächsten Schritt laden wir das vorab trainierte ColBERT-Modell herunter. Dafür wird der Code sein
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Wir importieren zunächst die RAGPretrainedModel-Klasse aus der RAGatouille-Bibliothek.
- Dann rufen wir .from_pretrained() auf und geben den Modellnamen an, z. B. „colbert-ir/colbertv2.0“.
Durch Ausführen des obigen Codes wird ein ColBERT RAG-Modell instanziiert. Laden wir nun eine Wikipedia-Seite herunter und führen Sie den Abruf daraus durch. Der Code dafür lautet:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])Das RAGatouille verfügt über eine praktische Funktion namens get_wikipedia_page, die einen String aufnimmt und die entsprechende Wikipedia-Seite abruft. Hier laden wir den Wikipedia-Inhalt zu Elon Musk herunter und speichern ihn im variablen Dokument. Lassen Sie uns die Anzahl der im Dokument vorhandenen Wörter und die ersten paar Zeilen des Dokuments ausdrucken.
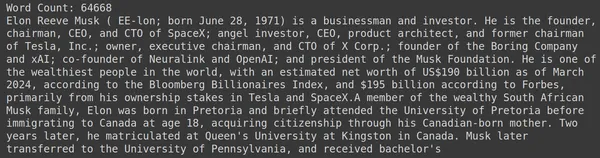
Hier können wir die Ausgabe im Bild sehen. Wir können sehen, dass die Wikipedia-Seite von Elon Musk insgesamt 64,668 Wörter enthält.
Schritt 3: Indizierung
Jetzt erstellen wir einen Index für dieses Dokument.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Hier rufen wir .index() des RAG auf, um unser Dokument zu indizieren. Dazu übergeben wir Folgendes:
- Sammlung: Dies ist eine Liste von Dokumenten, die wir indizieren möchten. Hier haben wir nur ein Dokument, daher eine Liste mit einem einzelnen Dokument.
- document_ids: Jedes Dokument erwartet eine eindeutige Dokument-ID. Hier geben wir ihm den Namen elon_musk, weil es in dem Dokument um Elon Musk geht.
- document_metadata: Zu jedem Dokument gehören Metadaten. Dies ist wiederum eine Liste von Wörterbüchern, wobei jedes Wörterbuch Metadaten eines Schlüssel-Wert-Paares für ein bestimmtes Dokument enthält.
- Indexname: Der Name des Index, den wir erstellen. Nennen wir es Elon2.
- max_document_size: Dies ähnelt der Chunk-Größe. Wir geben an, wie groß jeder Dokumentblock sein soll. Hier geben wir den Wert 256 an. Wenn wir keinen Wert angeben, wird 256 als Standard-Chunk-Größe verwendet.
- split_documents: Es handelt sich um einen booleschen Wert, wobei „True“ angibt, dass wir unser Dokument entsprechend der angegebenen Blockgröße aufteilen möchten, und „False“ angibt, dass wir das gesamte Dokument als einen einzelnen Block speichern möchten.
Durch Ausführen des obigen Codes wird unser Dokument in Größen von 256 pro Block aufgeteilt und diese dann über das ColBERT-Modell eingebettet, das eine Liste von Vektoreinbettungen auf Token-Ebene für jeden Block erstellt und diese schließlich in einem Index speichert. Die Ausführung dieses Schritts nimmt einige Zeit in Anspruch und kann beschleunigt werden, wenn Sie über eine GPU verfügen. Schließlich wird ein Verzeichnis erstellt, in dem unser Index gespeichert ist. Hier lautet das Verzeichnis „.ragatouille/colbert/indexes/Elon2“.
Schritt 4: Allgemeine Abfrage
Jetzt beginnen wir mit der Suche. Dafür wird der Code sein
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Hier rufen wir zunächst die .search()-Methode des RAG-Objekts auf
- Dazu geben wir die Variablen an, die den Abfragenamen, k (Anzahl der abzurufenden Dokumente) und den zu durchsuchenden Indexnamen enthalten
- Hier stellen wir die Abfrage „Welche Unternehmen hat Elon Musk gefunden?“ zur Verfügung. Das erhaltene Ergebnis wird in einer Liste im Wörterbuchformat vorliegen, die Schlüssel wie Inhalt, Punktzahl, Rang, Dokument-ID, Passagen-ID und Dokumentmetadaten enthält
- Daher arbeiten wir mit dem folgenden Code, um die abgerufenen Dokumente ordentlich auszudrucken
- Hier gehen wir die Liste der Wörterbücher durch und drucken den Inhalt der Dokumente aus
Das Ausführen des Codes führt zu folgenden Ergebnissen:
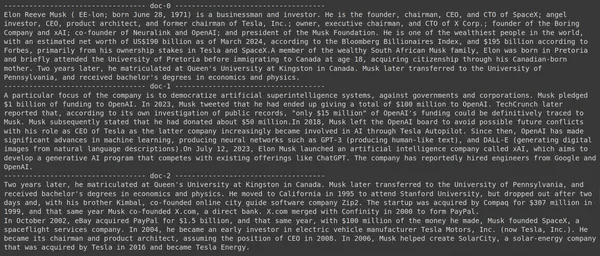
Auf dem Bild können wir sehen, dass das erste und letzte Dokument die verschiedenen von Elon Musk gegründeten Unternehmen vollständig abdeckt. Der ColBERT war in der Lage, die relevanten Blöcke, die zur Beantwortung der Anfrage erforderlich waren, korrekt abzurufen.
Schritt 5: Spezifische Abfrage
Gehen wir nun noch einen Schritt weiter und stellen wir eine konkrete Frage.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])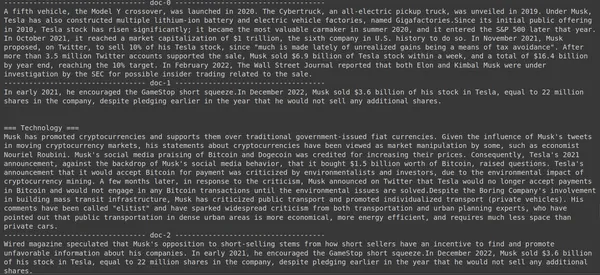
Hier im obigen Code stellen wir eine ganz konkrete Frage dazu, wie viele Tesla Elon-Aktien im Dezember 2022 verkauft wurden. Die Ausgabe können wir hier sehen. Das Dokument 1 enthält die Antwort auf die Frage. Elon hat seine Tesla-Aktien im Wert von 3.6 Milliarden US-Dollar verkauft. Auch hier konnte ColBERT den relevanten Block für die angegebene Abfrage erfolgreich abrufen.
Schritt 6: Andere Modelle testen
Versuchen wir nun die gleiche Frage mit den anderen Open-Source- und geschlossenen Einbettungsmodellen hier:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Wir beginnen damit, dass wir zunächst das Modell über die AutoModel-Klasse aus der Transformers-Bibliothek herunterladen.
- Dann speichern wir den Modellnamen und die Modellkwargs in ihren jeweiligen Variablen.
- Um nun mit diesem Modell in LangChain zu arbeiten, importieren wir die HuggingFaceEmbeddings aus dem LangChain und geben Sie ihm den Modellnamen und die model_kwargs.
Wenn Sie diesen Code ausführen, wird das Jina-Einbettungsmodell heruntergeladen und geladen, damit wir damit arbeiten können
Schritt 7: Einbettungen erstellen
Jetzt müssen wir mit der Aufteilung unseres Dokuments beginnen, daraus Einbettungen erstellen und diese im Chroma-Vektorspeicher speichern. Dazu arbeiten wir mit folgendem Code:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Wir beginnen mit dem Importieren des Chroma und des RecursiveCharacterTextSplitter aus der LangChain-Bibliothek
- Dann instanziieren wir einen text_splitter, indem wir den .from_tiktoken_encoder des RecursiveCharacterTextSplitter aufrufen und ihm chunk_size und chunk_overlap übergeben
- Hier verwenden wir dieselbe chunk_size, die wir dem ColBERT zur Verfügung gestellt haben
- Dann rufen wir die Methode .split_text() dieses Textsplitters auf und geben ihm das Dokument mit Wikipedia-Informationen über Elon Musk. Anschließend wird das Dokument basierend auf der angegebenen Blockgröße aufgeteilt und schließlich wird die Liste der Dokumentblöcke in den variablen Teilungen gespeichert
- Abschließend rufen wir die Funktion .from_texts() der Chroma-Klasse auf, um einen Vektorspeicher zu erstellen. Dieser Funktion geben wir die Aufteilungen, das Einbettungsmodell und den Sammlungsnamen an
- Jetzt erstellen wir daraus einen Retriever, indem wir die Funktion .as_retriever() des Vektorspeicherobjekts aufrufen. Für den k-Wert geben wir 3 an
Wenn Sie diesen Code ausführen, wird unser Dokument in kleinere Dokumente mit einer Größe von 256 pro Block aufgeteilt, diese kleineren Blöcke werden dann mit dem Jina-Einbettungsmodell eingebettet und diese Einbettungsvektoren im Chroma-Vektorspeicher gespeichert.
Schritt 8: Erstellen eines Retrievers
Abschließend erstellen wir daraus einen Retriever. Jetzt führen wir eine Vektorsuche durch und überprüfen die Ergebnisse.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)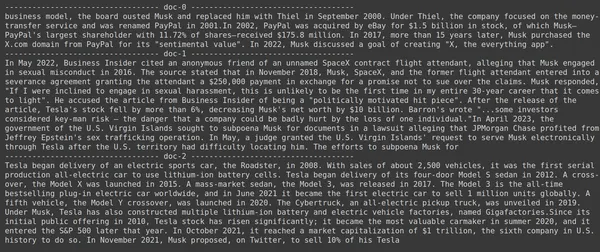
- Wir rufen die Funktion .get_relevent_documents() des Retriever-Objekts auf und geben ihm dieselbe Abfrage.
- Anschließend drucken wir die drei am häufigsten abgerufenen Dokumente sorgfältig aus.
- Auf dem Bild können wir sehen, dass der Jina Embedder, obwohl er ein beliebtes Einbettungsmodell ist, für unsere Abfrage schlecht abrufbar ist. Es war nicht erfolgreich, die richtigen Dokumentblöcke abzurufen.
Wir können den Unterschied zwischen Jina, dem Einbettungsmodell, das jeden Block als einzelne Vektoreinbettung darstellt, und dem ColBERT-Modell, das jeden Block als Liste von Einbettungsvektoren auf Token-Ebene darstellt, deutlich erkennen. Der ColBERT schneidet in diesem Fall deutlich ab.
Schritt 9: Testen des Einbettungsmodells von OpenAI
Versuchen wir nun, ein Closed-Source-Einbettungsmodell wie das OpenAI-Einbettungsmodell zu verwenden.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Hier ist der Code dem, den wir gerade geschrieben haben, sehr ähnlich
- Der einzige Unterschied besteht darin, dass wir den OpenAI-API-Schlüssel übergeben, um die Umgebungsvariable festzulegen.
- Anschließend erstellen wir eine Instanz des OpenAI Embedding-Modells, indem wir es aus LangChain importieren.
- Und beim Erstellen des Sammlungsnamens geben wir einen anderen Sammlungsnamen an, sodass die Einbettungen aus dem OpenAI-Einbettungsmodell in einer anderen Sammlung gespeichert werden.
Wenn Sie diesen Code ausführen, werden unsere Dokumente erneut in kleinere Dokumente der Größe 256 aufgeteilt, sie dann mit dem OpenAI-Einbettungsmodell in eine einzelne Vektor-Einbettungsdarstellung eingebettet und diese Einbettungen schließlich im Chroma Vector Store gespeichert. Versuchen wir nun, die relevanten Dokumente zur anderen Frage abzurufen.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)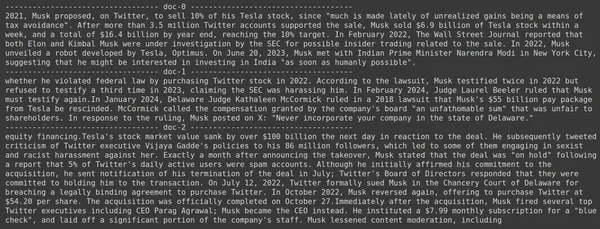
- Wir sehen, dass die erwartete Antwort nicht in den abgerufenen Blöcken gefunden wird.
- Der erste Teil enthält Informationen über Tesla-Aktien im Jahr 2022, spricht jedoch nicht davon, dass Elon sie verkauft.
- Das Gleiche lässt sich bei den verbleibenden zwei Dokumentenblöcken beobachten, in denen sich die darin enthaltenen Informationen auf Tesla und seine Aktien beziehen, dies sind jedoch nicht die Informationen, die wir erwarten.
- Die oben abgerufenen Blöcke stellen nicht den Kontext bereit, mit dem LLM die von uns bereitgestellte Anfrage beantworten kann.
Auch hier können wir einen deutlichen Unterschied zwischen der Einzelvektor-Einbettungsdarstellung und der Multivektor-Einbettungsdarstellung erkennen. Die mehrfach einbettenden Darstellungen erfassen die komplexen Abfragen deutlich, was zu genaueren Abrufen führt.
Zusammenfassung
Zusammenfassend zeigt ColBERT einen erheblichen Fortschritt in der Abrufleistung gegenüber herkömmlichen Bi-Encoder-Modellen, indem Text als Multi-Vektor-Einbettungen auf Token-Ebene dargestellt wird. Dieser Ansatz ermöglicht ein differenzierteres Kontextverständnis zwischen Abfragen und Dokumenten, was zu genaueren Abrufergebnissen führt und das Problem der bei LLMs häufig beobachteten Halluzinationen mildert.
Key Take Away
- RAG geht das Problem der Halluzinationen bei LLMs an, indem es Kontextinformationen für die Generierung sachlicher Antworten bereitstellt.
- Herkömmliche Bi-Encoder leiden unter einem Informationsengpass, da ganze Texte in einzelne Vektoreinbettungen komprimiert werden, was zu einer unterdurchschnittlichen Abrufgenauigkeit führt.
- ColBERT erleichtert mit seiner Einbettungsdarstellung auf Token-Ebene ein besseres Kontextverständnis zwischen Abfragen und Dokumenten, was zu einer verbesserten Abrufleistung führt.
- Der späte Interaktionsschritt in ColBERT verbessert in Kombination mit Interaktionen auf Token-Ebene die Abrufgenauigkeit durch Berücksichtigung kontextbezogener Nuancen.
- ColBERTv2 optimiert den Speicherplatz durch Restkomprimierung und behält gleichzeitig die Abrufeffektivität bei.
- Praktische Experimente zeigen die Überlegenheit von ColBERT bei der Abrufleistung im Vergleich zu herkömmlichen und Open-Source-Einbettungsmodellen wie Jina und OpenAI Embedding.
Häufig gestellte Fragen
A. Herkömmliche Bi-Encoder komprimieren ganze Texte in einzelne Vektoreinbettungen, wodurch möglicherweise Kontextinformationen verloren gehen. Dies schränkt ihre Effektivität bei Rechercheaufgaben ein, insbesondere bei komplexen Abfragen oder Dokumenten.
A. ColBERT (Contextual Late Interactions BERT) ist ein Bi-Encoder-Modell, das Text mithilfe von Vektoreinbettungen auf Token-Ebene darstellt. Es ermöglicht ein differenzierteres Kontextverständnis zwischen Abfragen und Dokumenten und verbessert so die Abrufgenauigkeit.
A. ColBERT generiert Einbettungen auf Token-Ebene für Abfragen und Dokumente, führt eine Matrixmultiplikation durch, um Ähnlichkeitswerte zu berechnen, und wählt dann die relevantesten Informationen basierend auf der maximalen Ähnlichkeit zwischen Token aus. Dies ermöglicht einen effektiven Abruf mit kontextbezogenem Verständnis.
A. ColBERTv2 optimiert den Speicherplatz durch die Restkomprimierungsmethode und reduziert so den Speicherbedarf für Einbettungen auf Token-Ebene bei gleichzeitiger Beibehaltung der Abrufgenauigkeit.
A. Sie können Bibliotheken wie RAGatouille verwenden, um problemlos mit ColBERT zu arbeiten. Durch die Indizierung von Dokumenten und Abfragen können Sie effiziente Suchaufgaben durchführen und genaue, auf den Kontext abgestimmte Antworten generieren.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

