Einleitung
Im Herzen Datenwissenschaft Das ist die Statistik, die es schon seit Jahrhunderten gibt und die im heutigen digitalen Zeitalter nach wie vor von grundlegender Bedeutung ist. Warum? Denn grundlegende Statistikkonzepte sind das Rückgrat von Datenanalyse, Dadurch können wir die riesigen Datenmengen, die täglich generiert werden, sinnvoll nutzen. Es ist wie eine Konversation mit Daten, bei der Statistiken uns helfen, die richtigen Fragen zu stellen und die Geschichten zu verstehen, die Daten zu erzählen versuchen.
Von der Vorhersage zukünftiger Trends und der Entscheidungsfindung auf der Grundlage von Daten bis hin zum Testen von Hypothesen und der Leistungsmessung ist Statistik das Werkzeug, das die Erkenntnisse hinter datengesteuerten Entscheidungen liefert. Es ist die Brücke zwischen Rohdaten und umsetzbaren Erkenntnissen und damit ein unverzichtbarer Bestandteil der Datenwissenschaft.
In diesem Artikel habe ich die 15 wichtigsten Statistikkonzepte zusammengestellt, die jeder Data-Science-Anfänger kennen sollte!

Inhaltsverzeichnis
1. Statistische Stichprobenziehung und Datenerfassung
Wir werden einige grundlegende Statistikkonzepte erlernen, aber bevor wir tief in den Ozean der Daten eintauchen, ist es wichtig zu verstehen, woher unsere Daten kommen und wie wir sie sammeln. Hier kommen Populationen, Stichproben und verschiedene Stichprobentechniken ins Spiel.
Stellen Sie sich vor, wir möchten die durchschnittliche Körpergröße der Menschen in einer Stadt wissen. Da es praktisch ist, alle zu messen, nehmen wir eine kleinere Gruppe (Stichprobe), die die größere Bevölkerung repräsentiert. Der Trick liegt darin, wie wir diese Stichprobe auswählen. Techniken wie zufällige, geschichtete oder Cluster-Stichproben stellen sicher, dass unsere Stichprobe gut repräsentiert ist, wodurch Verzerrungen minimiert und unsere Ergebnisse zuverlässiger werden.
Durch das Verständnis von Populationen und Stichproben können wir unsere Erkenntnisse aus der Stichprobe sicher auf die gesamte Population übertragen und fundierte Entscheidungen treffen, ohne jeden befragen zu müssen.
2. Datentypen und Messskalen
Daten gibt es in verschiedenen Formen und die Kenntnis der Art der Daten, mit denen Sie es zu tun haben, ist für die Auswahl der richtigen statistischen Tools und Techniken von entscheidender Bedeutung.
Quantitative und qualitative Daten
- Quantitative Daten: Bei dieser Art von Daten dreht sich alles um Zahlen. Es ist messbar und kann für mathematische Berechnungen verwendet werden. Quantitative Daten sagen uns „wie viel“ oder „wie viele“, wie die Anzahl der Benutzer, die eine Website besuchen, oder die Temperatur in einer Stadt. Es ist unkompliziert und objektiv und liefert durch numerische Werte ein klares Bild.
- Qualitative Daten: Umgekehrt geht es bei qualitativen Daten um Merkmale und Beschreibungen. Es geht um „welcher Typ“ oder „welche Kategorie“. Stellen Sie sich darunter Daten vor, die Qualitäten oder Attribute beschreiben, etwa die Farbe eines Autos oder das Genre eines Buches. Diese Daten sind subjektiv und basieren eher auf Beobachtungen als auf Messungen.
Vier Messskalen
- Nominalskala: Dies ist die einfachste Form der Messung zur Kategorisierung von Daten ohne bestimmte Reihenfolge. Beispiele hierfür sind Küchenarten, Blutgruppen oder Nationalität. Es geht um eine Kennzeichnung ohne quantitativen Wert.
- Ordnungsskala: Daten können hier geordnet oder geordnet werden, die Intervalle zwischen den Werten sind jedoch nicht definiert. Stellen Sie sich eine Zufriedenheitsumfrage mit Optionen wie „zufrieden“, „neutral“ und „unzufrieden“ vor. Es verrät uns die Reihenfolge, aber nicht den Abstand zwischen den Ranglisten.
- Intervall-Skala: Intervallskalen ordnen Daten und quantifizieren die Differenz zwischen Einträgen. Allerdings gibt es keinen wirklichen Nullpunkt. Ein gutes Beispiel ist die Temperatur in Celsius; Der Unterschied zwischen 10 °C und 20 °C ist derselbe wie zwischen 20 °C und 30 °C, aber 0 °C bedeutet nicht, dass es keine Temperatur gibt.
- Verhältnisskala: Die aussagekräftigste Skala verfügt über alle Eigenschaften einer Intervallskala sowie einen aussagekräftigen Nullpunkt, der einen genauen Größenvergleich ermöglicht. Beispiele hierfür sind Gewicht, Größe und Einkommen. Hier können wir sagen, dass etwas doppelt so viel ist wie ein anderes.
3. Beschreibende Statistik
Imagine beschreibende Statistik als Ihr erstes Date mit Ihren Daten. Es geht darum, die Grundlagen kennenzulernen, die groben Striche, die beschreiben, was vor Ihnen liegt. Es gibt zwei Haupttypen der deskriptiven Statistik: zentrale Tendenz- und Variabilitätsmaße.
Maße der zentralen Tendenz: Diese sind sozusagen der Schwerpunkt der Daten. Sie geben uns einen einzelnen Wert, der typisch oder repräsentativ für unseren Datensatz ist.
Bedeuten: Der Durchschnitt wird berechnet, indem alle Werte addiert und durch die Anzahl der Werte dividiert werden. Es ist wie die Gesamtbewertung eines Restaurants basierend auf allen Bewertungen. Die mathematische Formel für den Durchschnitt ist unten angegeben:

Median: Der mittlere Wert, wenn die Daten vom kleinsten zum größten sortiert sind. Wenn die Anzahl der Beobachtungen gerade ist, handelt es sich um den Durchschnitt der beiden mittleren Zahlen. Es wird verwendet, um den Mittelpunkt einer Brücke zu finden.
Wenn n gerade ist, ist der Median der Durchschnitt der beiden zentralen Zahlen.
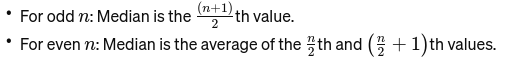
Modus: Es ist die am häufigsten vorkommender Wert in einem Datensatz. Betrachten Sie es als das beliebteste Gericht in einem Restaurant.
Variabilitätsmaße: Während Maße der zentralen Tendenz uns in die Mitte bringen, geben uns Maße der Variabilität Aufschluss über die Ausbreitung oder Streuung.
Reichweite: Der Unterschied zwischen dem höchsten und dem niedrigsten Wert. Es vermittelt einen grundlegenden Überblick über die Ausbreitung.
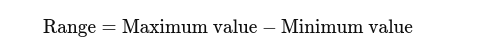
Abweichung: Misst, wie weit jede Zahl in der Menge vom Mittelwert und damit von jeder anderen Zahl in der Menge entfernt ist. Als Beispiel wird es wie folgt berechnet:
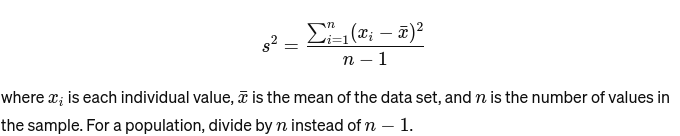
Standardabweichung: Die Quadratwurzel der Varianz liefert ein Maß für den durchschnittlichen Abstand vom Mittelwert. Es ist, als würde man die Konsistenz der Kuchengrößen eines Bäckers beurteilen. Es wird dargestellt als:
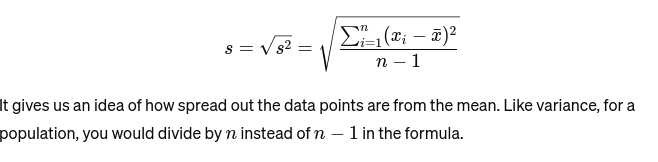
Bevor wir zum nächsten grundlegenden Statistikkonzept übergehen, hier ein Anfängerleitfaden zur statistischen Analyse für Sie!
4. Datenvisualisierung
Datenvisualisierung ist die Kunst und Wissenschaft, mit Daten Geschichten zu erzählen. Es macht komplexe Ergebnisse unserer Analyse greifbar und verständlich. Dies ist von entscheidender Bedeutung für die explorative Datenanalyse, bei der das Ziel darin besteht, Muster, Korrelationen und Erkenntnisse aus Daten aufzudecken, ohne noch formale Schlussfolgerungen zu ziehen.
- Diagramme und Grafiken: Beginnend mit den Grundlagen bieten Balkendiagramme, Liniendiagramme und Kreisdiagramme grundlegende Einblicke in die Daten. Sie sind das ABC der Datenvisualisierung und für jeden Daten-Storyteller unerlässlich.
Unten sehen Sie ein Beispiel für ein Balkendiagramm (links) und ein Liniendiagramm (rechts).
- Erweiterte Visualisierungen: Je tiefer wir eintauchen, desto differenziertere Analysen ermöglichen Heatmaps, Streudiagramme und Histogramme. Diese Tools helfen bei der Identifizierung von Trends, Verteilungen und Ausreißern.
Unten finden Sie ein Beispiel für ein Streudiagramm und ein Histogramm

Visualisierungen verbinden Rohdaten und menschliche Wahrnehmung und ermöglichen es uns, komplexe Datensätze schnell zu interpretieren und zu verstehen.
5. Grundlagen der Wahrscheinlichkeit
Wahrscheinlichkeit ist die Grammatik der Sprache der Statistik. Es geht um die Wahrscheinlichkeit oder Wahrscheinlichkeit, dass Ereignisse eintreten. Das Verständnis von Wahrscheinlichkeitskonzepten ist für die Interpretation statistischer Ergebnisse und die Erstellung von Vorhersagen von entscheidender Bedeutung.
- Unabhängige und abhängige Ereignisse:
- Unabhängige Veranstaltungen: Der Ausgang eines Ereignisses hat keinen Einfluss auf den Ausgang eines anderen Ereignisses. Genauso wie das Werfen einer Münze ändert das Ergebnis „Kopf“ bei einem Münzwurf nichts an den Chancen für den nächsten Münzwurf.
- Abhängige Ereignisse: Der Ausgang eines Ereignisses beeinflusst das Ergebnis eines anderen. Wenn Sie beispielsweise eine Karte aus einem Stapel ziehen und diese nicht ersetzen, ändern sich Ihre Chancen, eine weitere bestimmte Karte zu ziehen.
Die Wahrscheinlichkeit bildet die Grundlage für Rückschlüsse auf Daten und ist entscheidend für das Verständnis der statistischen Signifikanz und der Hypothesentests.
6. Gemeinsame Wahrscheinlichkeitsverteilungen
Wahrscheinlichkeitsverteilungen sind wie verschiedene Arten im Statistik-Ökosystem, jede an ihre Anwendungsnische angepasst.
- Normalverteilung: Aufgrund ihrer Form wird diese Verteilung oft als Glockenkurve bezeichnet und ist durch ihren Mittelwert und ihre Standardabweichung gekennzeichnet. Dies ist eine gängige Annahme in vielen statistischen Tests, da viele Variablen in der realen Welt natürlicherweise auf diese Weise verteilt sind.
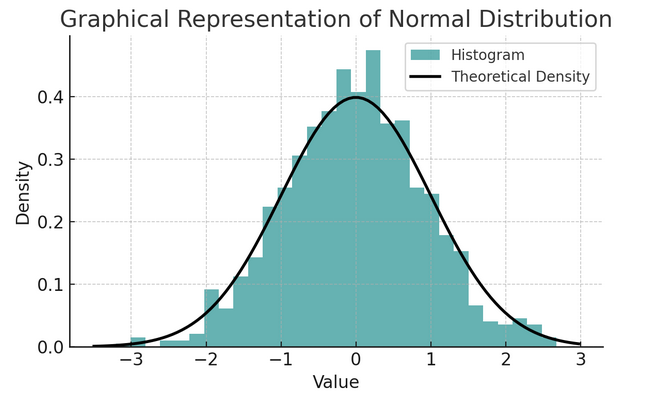
Eine Reihe von Regeln, die als empirische Regel oder 68-95-99.7-Regel bekannt sind, fasst die Merkmale einer Normalverteilung zusammen, die beschreibt, wie Daten um den Mittelwert verteilt sind.
68-95-99.7 Regel (empirische Regel)
Diese Regel gilt für eine vollkommen normale Verteilung und beschreibt Folgendes:
- 68% der Daten innerhalb einer Standardabweichung (σ) vom Mittelwert (μ) liegen.
- 95% der Daten liegen innerhalb von zwei Standardabweichungen vom Mittelwert.
- ca. 99.7% der Daten liegen innerhalb von drei Standardabweichungen vom Mittelwert.
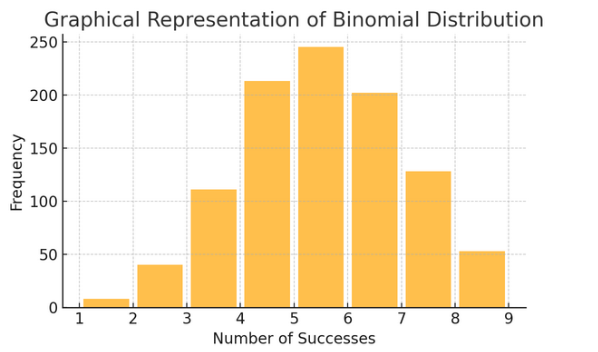
Binomialverteilung: Diese Verteilung gilt für Situationen mit zwei Ergebnissen (wie Erfolg oder Misserfolg), die mehrmals wiederholt werden. Es hilft bei der Modellierung von Ereignissen wie dem Werfen einer Münze oder der Durchführung eines Richtig/Falsch-Tests.
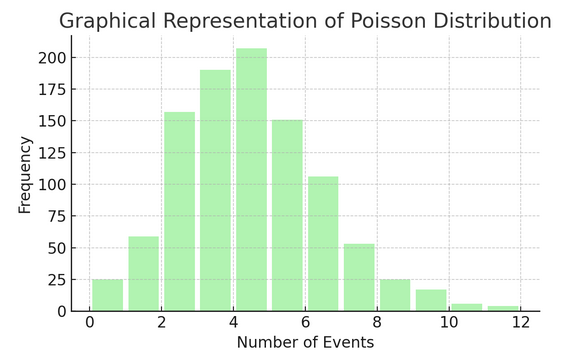
Poisson-Verteilung zählt, wie oft etwas in einem bestimmten Intervall oder Raum passiert. Es ist ideal für Situationen, in denen Ereignisse unabhängig und ständig stattfinden, wie zum Beispiel die täglichen E-Mails, die Sie erhalten.
Jede Verteilung verfügt über eigene Formeln und Merkmale. Die Wahl der richtigen Verteilung hängt von der Art Ihrer Daten und dem, was Sie herausfinden möchten, ab. Das Verständnis dieser Verteilungen ermöglicht es Statistikern und Datenwissenschaftlern, reale Phänomene zu modellieren und zukünftige Ereignisse genau vorherzusagen.
7 . Hypothesentest
Denken Sie an Hypothesentest als Detektivarbeit in der Statistik. Es ist eine Methode, um zu testen, ob eine bestimmte Theorie über unsere Daten wahr sein könnte. Dieser Prozess beginnt mit zwei gegensätzlichen Hypothesen:
- Nullhypothese (H0): Dies ist die Standardannahme, die darauf hindeutet, dass es einen Effekt oder Unterschied gibt. Es heißt: „Hier ist nichts Neues.“
- Al „alternative Hypothese (H1 oder Ha): Dies stellt den Status quo in Frage und schlägt eine Wirkung oder einen Unterschied vor. Darin heißt es: „Es ist etwas Interessantes im Gange.“
Beispiel: Testen, ob ein neues Diätprogramm zu einer Gewichtsabnahme führt, verglichen mit dem Verzicht auf eine Diät.
- Nullhypothese (H0): Das neue Diätprogramm führt nicht zu einer Gewichtsabnahme (kein Unterschied in der Gewichtsabnahme zwischen denen, die das neue Diätprogramm befolgen, und denen, die es nicht tun).
- Alternativhypothese (H1): Das neue Diätprogramm führt zu Gewichtsverlust (ein Unterschied in der Gewichtsabnahme zwischen denen, die es befolgen, und denen, die es nicht befolgen).
Beim Testen von Hypothesen wird auf der Grundlage der Beweise (unserer Daten) zwischen diesen beiden Optionen gewählt.
Fehler- und Signifikanzstufen vom Typ I und II:
- Fehler vom Typ I: Dies geschieht, wenn wir die Nullhypothese fälschlicherweise ablehnen. Es verurteilt eine unschuldige Person.
- Fehler vom Typ II: Dies geschieht, wenn es uns nicht gelingt, eine falsche Nullhypothese abzulehnen. Es lässt einen Schuldigen freikommen.
- Signifikanzniveau (α): Das ist der Schwellenwert für die Entscheidung, wie viele Beweise ausreichen, um die Nullhypothese abzulehnen. Der Wert wird oft auf 5 % (0.05) festgelegt, was auf ein Risiko von 5 % für einen Fehler vom Typ I hinweist.
8. Konfidenzintervalle
Vertrauensintervalle Geben Sie uns einen Wertebereich, innerhalb dessen wir erwarten, dass der gültige Populationsparameter (wie ein Mittelwert oder ein Anteil) mit einem bestimmten Konfidenzniveau (üblicherweise 95 %) liegt. Es ist, als würde man das Endergebnis einer Sportmannschaft mit einer gewissen Fehlerquote vorhersagen; Wir sagen: „Wir sind zu 95 % davon überzeugt, dass der tatsächliche Wert in diesem Bereich liegen wird.“
Die Konstruktion und Interpretation von Konfidenzintervallen hilft uns, die Präzision unserer Schätzungen zu verstehen. Je größer das Intervall, desto ungenauer ist unsere Schätzung und umgekehrt.
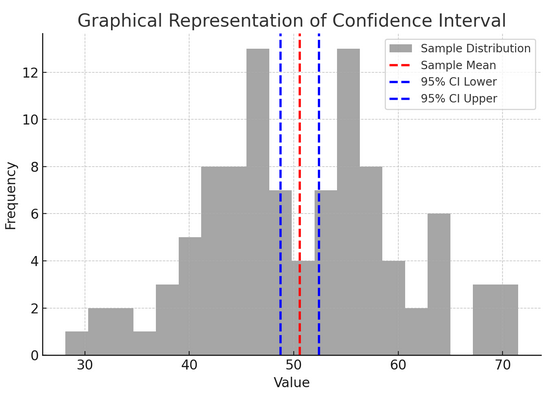
Die obige Abbildung veranschaulicht das Konzept eines Konfidenzintervalls (CI) in der Statistik anhand einer Stichprobenverteilung und ihres 95 %-Konfidenzintervalls um den Stichprobenmittelwert.
Hier ist eine Aufschlüsselung der kritischen Komponenten in der Abbildung:
- Probenverteilung (graues Histogramm): Dies stellt die Verteilung von 100 Datenpunkten dar, die zufällig aus einer Normalverteilung mit einem Mittelwert von 50 und einer Standardabweichung von 10 generiert wurden. Das Histogramm zeigt visuell, wie die Datenpunkte um den Mittelwert verteilt sind.
- Stichprobenmittelwert (rote gestrichelte Linie): Diese Zeile gibt den Mittelwert (Durchschnittswert) der Beispieldaten an. Es dient als Punktschätzung, um die herum wir das Konfidenzintervall konstruieren. In diesem Fall stellt er den Durchschnitt aller Stichprobenwerte dar.
- 95 %-Konfidenzintervall (blaue gestrichelte Linien): Diese beiden Linien markieren die Unter- und Obergrenze des 95 %-Konfidenzintervalls um den Stichprobenmittelwert. Das Intervall wird anhand des Standardfehlers des Mittelwerts (SEM) und eines Z-Scores berechnet, der dem gewünschten Konfidenzniveau entspricht (1.96 für 95 % Konfidenz). Das Konfidenzintervall legt nahe, dass wir zu 95 % davon überzeugt sind, dass der Grundgesamtheitsmittelwert innerhalb dieses Bereichs liegt.
9. Korrelation und Kausalität
Korrelation und Kausalität kommen oft durcheinander, sind aber unterschiedlich:
- Korrelation: Zeigt eine Beziehung oder Assoziation zwischen zwei Variablen an. Wenn sich das eine ändert, neigt auch das andere dazu, sich zu ändern. Die Korrelation wird durch einen Korrelationskoeffizienten im Bereich von -1 bis 1 gemessen. Ein Wert näher bei 1 oder -1 weist auf eine starke Beziehung hin, während 0 auf keine Bindung hindeutet.
- Ursache: Dies impliziert, dass Änderungen in einer Variablen direkt Änderungen in einer anderen verursachen. Es handelt sich um eine belastbarere Aussage als die Korrelation und erfordert strenge Tests.
Nur weil zwei Variablen korrelieren, heißt das nicht, dass die eine die andere verursacht. Dies ist ein klassischer Fall dafür, dass „Korrelation“ nicht mit „Kausalität“ verwechselt wird.
10. Einfache lineare Regression
Einfacher lineare Regression ist eine Möglichkeit, die Beziehung zwischen zwei Variablen zu modellieren, indem eine lineare Gleichung an beobachtete Daten angepasst wird. Eine Variable wird als erklärende Variable (unabhängig) betrachtet, die andere als abhängige Variable.
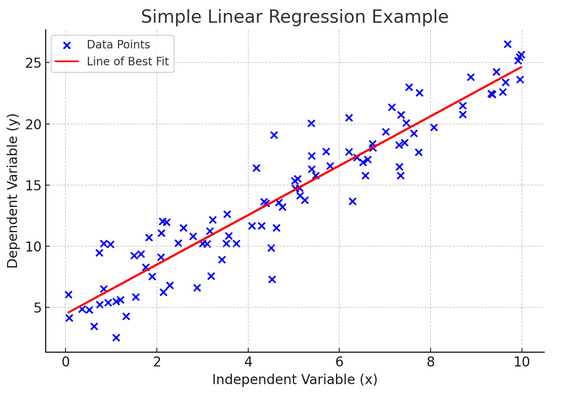
Eine einfache lineare Regression hilft uns zu verstehen, wie sich Änderungen der unabhängigen Variablen auf die abhängige Variable auswirken. Es ist ein leistungsstarkes Werkzeug zur Vorhersage und bildet die Grundlage für viele andere komplexe statistische Modelle. Durch die Analyse der Beziehung zwischen zwei Variablen können wir fundierte Vorhersagen darüber treffen, wie sie interagieren werden.
Die einfache lineare Regression geht von einer linearen Beziehung zwischen der unabhängigen Variablen (erklärenden Variablen) und der abhängigen Variablen aus. Wenn die Beziehung zwischen diesen beiden Variablen nicht linear ist, können die Annahmen der einfachen linearen Regression verletzt werden, was möglicherweise zu ungenauen Vorhersagen oder Interpretationen führt. Daher ist die Überprüfung einer linearen Beziehung in den Daten unerlässlich, bevor eine einfache lineare Regression angewendet wird.
11. Mehrfache lineare Regression
Stellen Sie sich die multiple lineare Regression als eine Erweiterung der einfachen linearen Regression vor. Doch anstatt zu versuchen, das Ergebnis mit einem Ritter in glänzender Rüstung (Vorhersager) vorherzusagen, haben Sie ein ganzes Team. Es ist, als würde man von einem Eins-gegen-eins-Basketballspiel zu einer Mannschaftsleistung aufsteigen, bei der jeder Spieler (Tippgeber) einzigartige Fähigkeiten mitbringt. Die Idee besteht darin, zu sehen, wie mehrere Variablen zusammen ein einzelnes Ergebnis beeinflussen.
Allerdings bringt ein größeres Team die Herausforderung mit sich, Beziehungen zu verwalten, was als Multikollinearität bezeichnet wird. Dies geschieht, wenn Prädiktoren zu nahe beieinander liegen und ähnliche Informationen austauschen. Stellen Sie sich zwei Basketballspieler vor, die ständig versuchen, den gleichen Schlag zu machen. sie können sich gegenseitig in die Quere kommen. Die Regression kann es schwierig machen, den individuellen Beitrag jedes Prädiktors zu erkennen, was möglicherweise unser Verständnis davon, welche Variablen von Bedeutung sind, verzerrt.
12. Logistische Regression
Während die lineare Regression kontinuierliche Ergebnisse (wie Temperatur oder Preise) vorhersagt, logistische Regression wird verwendet, wenn das Ergebnis eindeutig ist (z. B. Ja/Nein, Sieg/Niederlage). Stellen Sie sich vor, Sie versuchen anhand verschiedener Faktoren vorherzusagen, ob ein Team gewinnen oder verlieren wird. Logistische Regression ist Ihre bevorzugte Strategie.
Es transformiert die lineare Gleichung so, dass ihre Ausgabe zwischen 0 und 1 liegt und die Wahrscheinlichkeit der Zugehörigkeit zu einer bestimmten Kategorie darstellt. Es ist, als ob man über eine magische Linse verfügt, die kontinuierliche Ergebnisse in eine klare „dieses oder jenes“-Ansicht umwandelt und es uns ermöglicht, kategorische Ergebnisse vorherzusagen.
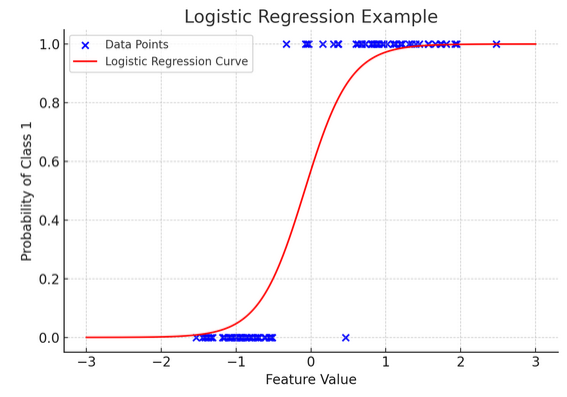
Die grafische Darstellung veranschaulicht ein Beispiel einer logistischen Regression, die auf einen synthetischen binären Klassifizierungsdatensatz angewendet wird. Die blauen Punkte stellen die Datenpunkte dar, wobei ihre Position entlang der x-Achse den Merkmalswert und die y-Achse die Kategorie (0 oder 1) angibt. Die rote Kurve stellt die Vorhersage des logistischen Regressionsmodells über die Wahrscheinlichkeit der Zugehörigkeit zu Klasse 1 (z. B. „Sieg“) für verschiedene Merkmalswerte dar. Wie Sie sehen können, geht die Kurve fließend von der Wahrscheinlichkeit der Klasse 0 zur Klasse 1 über, was die Fähigkeit des Modells demonstriert, kategoriale Ergebnisse basierend auf einem zugrunde liegenden kontinuierlichen Merkmal vorherzusagen.
Die Formel für die logistische Regression lautet:

Diese Formel verwendet die logistische Funktion, um die Ausgabe der linearen Gleichung in eine Wahrscheinlichkeit zwischen 0 und 1 umzuwandeln. Diese Transformation ermöglicht es uns, die Ausgaben als Wahrscheinlichkeiten der Zugehörigkeit zu einer bestimmten Kategorie basierend auf dem Wert der unabhängigen Variablen xx zu interpretieren.
13. ANOVA- und Chi-Quadrat-Tests
ANOVA (Varianzanalyse) und Chi-Quadrat-Tests sind wie Detektive in der Welt der Statistik und helfen uns, verschiedene Rätsel zu lösen. ICHt ermöglicht es uns, Mittelwerte mehrerer Gruppen zu vergleichen, um zu sehen, ob sich mindestens eine statistisch unterscheidet. Stellen Sie sich das so vor, als würden Sie Proben mehrerer Kekschargen probieren, um festzustellen, ob eine Charge deutlich anders schmeckt.
Andererseits wird der Chi-Quadrat-Test für kategoriale Daten verwendet. Es hilft uns zu verstehen, ob zwischen zwei kategorialen Variablen ein signifikanter Zusammenhang besteht. Gibt es beispielsweise einen Zusammenhang zwischen der Lieblingsmusikgenre einer Person und ihrer Altersgruppe? Der Chi-Quadrat-Test hilft bei der Beantwortung solcher Fragen.
14. Der zentrale Grenzwertsatz und seine Bedeutung in der Datenwissenschaft
Das Zentraler Grenzwertsatz (CLT) ist ein grundlegendes statistisches Prinzip, das sich fast magisch anfühlt. Daraus erfahren wir, dass, wenn Sie einer Grundgesamtheit genügend Stichproben entnehmen und deren Mittelwerte berechnen, diese Mittelwerte eine Normalverteilung (die Glockenkurve) bilden, unabhängig von der ursprünglichen Verteilung der Grundgesamtheit. Das ist unglaublich aussagekräftig, weil es uns ermöglicht, Rückschlüsse auf Populationen zu ziehen, selbst wenn wir ihre genaue Verteilung nicht kennen.
In der Datenwissenschaft liegt die CLT vielen Techniken zugrunde und ermöglicht es uns, Werkzeuge zu verwenden, die für normalverteilte Daten entwickelt wurden, auch wenn unsere Daten diese Kriterien zunächst nicht erfüllen. Es ist, als würde man einen universellen Adapter für statistische Methoden finden, der viele leistungsstarke Tools in mehr Situationen anwendbar macht.
15. Bias-Varianz-Kompromiss
In Vorhersagemodellierung und Maschinelles Lernen, der Bias-Varianz-Kompromiss ist ein entscheidendes Konzept, das die Spannung zwischen zwei Hauptfehlertypen hervorhebt, die dazu führen können, dass unsere Modelle schiefgehen. Bias bezieht sich auf Fehler aufgrund zu einfacher Modelle, die die zugrunde liegenden Trends nicht gut erfassen. Stellen Sie sich vor, Sie versuchen, eine gerade Linie durch eine kurvige Straße zu ziehen. Du wirst das Ziel verfehlen. Umgekehrt erfassen Abweichungen von zu komplexen Modellen das Rauschen in den Daten, als wäre es ein tatsächliches Muster – so als würde man jede Biegung und Wendung auf einem holprigen Weg verfolgen und denken, dass dies der Weg nach vorne sei.
Die Kunst besteht darin, diese beiden auszubalancieren, um den Gesamtfehler zu minimieren und den Sweet Spot zu finden, an dem Ihr Modell genau richtig ist – komplex genug, um die genauen Muster zu erfassen, aber einfach genug, um das zufällige Rauschen zu ignorieren. Es ist, als würde man eine Gitarre stimmen; Es klingt nicht richtig, wenn es zu eng oder zu locker ist. Der Bias-Varianz-Kompromiss Es geht darum, die perfekte Balance zwischen diesen beiden zu finden. Der Bias-Varianz-Kompromiss ist die Essenz der Optimierung unserer statistischen Modelle, um bei der genauen Vorhersage von Ergebnissen die bestmögliche Leistung zu erbringen.
Zusammenfassung
Von der statistischen Stichprobe bis hin zum Bias-Varianz-Kompromiss sind diese Prinzipien keine bloßen akademischen Begriffe, sondern wesentliche Werkzeuge für eine aufschlussreiche Datenanalyse. Sie vermitteln angehenden Datenwissenschaftlern die Fähigkeiten, umfangreiche Daten in umsetzbare Erkenntnisse umzuwandeln, wobei sie Statistiken als Rückgrat datengesteuerter Entscheidungsfindung und Innovation im digitalen Zeitalter hervorheben.
Haben wir ein grundlegendes Statistikkonzept übersehen? Lassen Sie es uns im Kommentarbereich unten wissen.
Entdecken Sie unsere End-to-End-Statistikleitfaden damit sich die Datenwissenschaft mit dem Thema auskennt!
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

