
"درهم وقاية خير من قنطار علاج" هكذا يقول المثل القديم، الذي يذكرنا بأنه من الأسهل منع حدوث شيء ما في المقام الأول بدلاً من إصلاح الضرر بعد حدوثه.
في عصر الذكاء الاصطناعي (AI)، يؤكد هذا المثل على أهمية تجنب المخاطر المحتملة، مثل الإفراط في التجهيز، من خلال تقنيات مثل التنظيم.
في هذه المقالة، سوف نكتشف التنظيم من خلال البدء بمبادئه الأساسية لتطبيقه باستخدام Sci-kit Learn (التعلم الآلي) و Tensorflow (التعلم العميق) ونشهد قوته التحويلية مع مجموعات البيانات الواقعية من خلال مقارنة هذه النتائج. لنبدأ!
يعد التنظيم مفهومًا بالغ الأهمية في التعلم الآلي والتعلم العميق الذي يهدف إلى منع النماذج من الإفراط في التجهيز.
يحدث التجاوز عندما يتعلم النموذج بيانات التدريب بشكل جيد للغاية. يُظهر الموقف أن نموذجك جيد جدًا لدرجة يصعب تصديقها.
دعونا نرى كيف يبدو التجهيز الزائد.
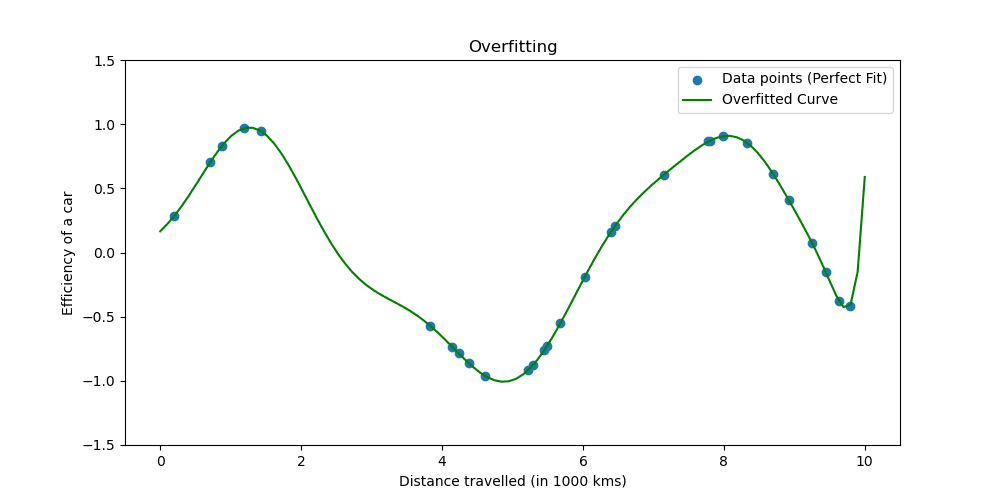
تعمل تقنيات التنظيم على ضبط عملية التعلم لتبسيط النموذج، مما يضمن أداءً جيدًا لبيانات التدريب وتعميمًا جيدًا على البيانات الجديدة. سوف نستكشف طريقتين معروفتين للقيام بذلك.
في التعلم الآلي، غالبًا ما يتم تطبيق التنظيم على النماذج الخطية، مثل الانحدار الخطي واللوجستي. وفي هذا السياق، فإن أكثر أشكال التنظيم شيوعًا هي:
- تسوية L1 (انحدار لاسو)
- تنظيم L2 (انحدار ريدج)
تنظيم لاسو يشجع النموذج على استخدام الميزات الأكثر أهمية فقط من خلال السماح لبعض قيم المعاملات بأن تكون صفرًا تمامًا، وهو ما يمكن أن يكون مفيدًا بشكل خاص لاختيار الميزة.


من ناحية أخرى، تسوية ريدج يثبط المعاملات الهامة عن طريق معاقبة مربع قيمها.

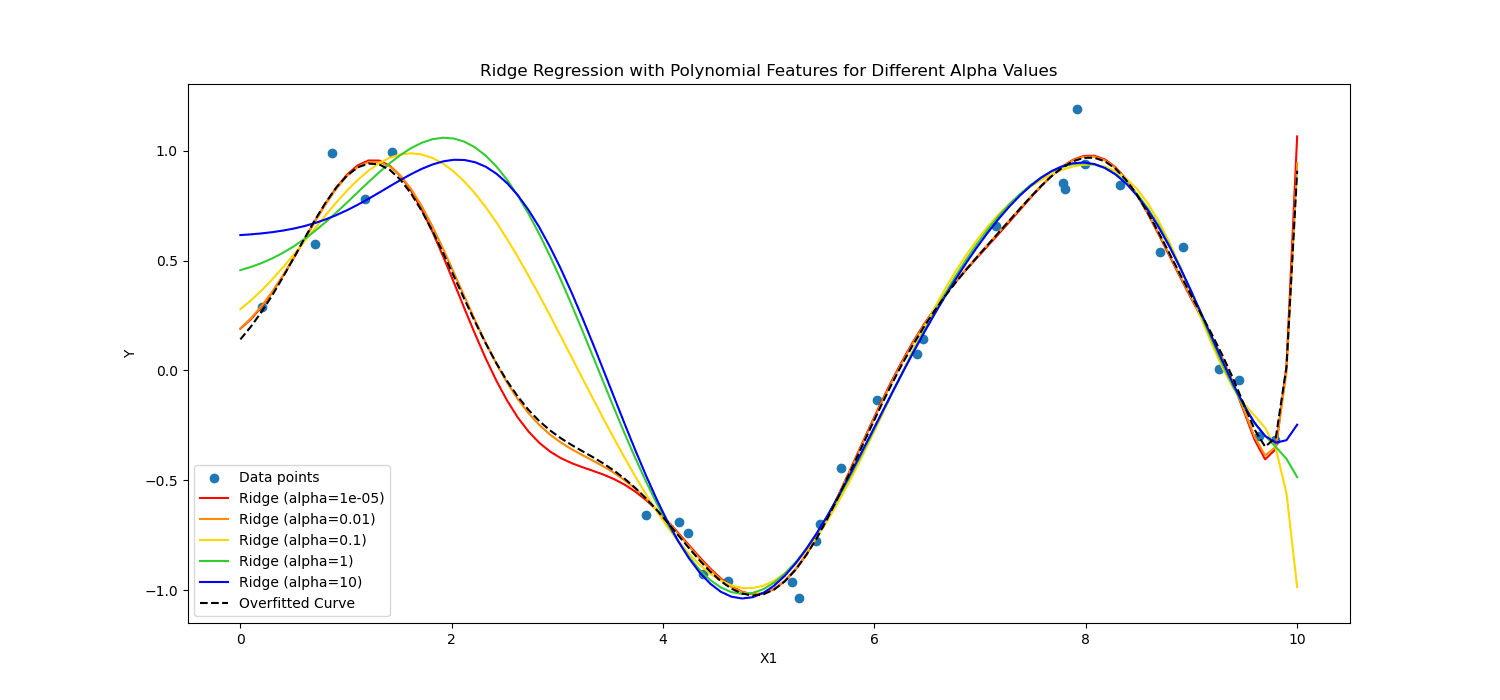
باختصار، لقد حسبوا بشكل مختلف.
دعونا نطبق ذلك على بيانات مرضى القلب لنرى قوتها في التعلم العميق والتعلم الآلي.
الآن، سوف نقوم بتطبيق التنظيم لتحليل بيانات مريض القلب لمعرفة قوة التنظيم. يمكنك الوصول إلى مجموعة البيانات من هنا.
لتطبيق التعلم الآلي، سوف نستخدم Scikit-Learn؛ لتطبيق التعلم العميق، سوف نستخدم TensorFlow. لنبدأ!
التنظيم في تعلم الآلة
Scikit-Learn هي واحدة من الأكثر شعبية مكتبات بايثون للتعلم الآلي الذي يوفر أدوات تحليل ونمذجة بسيطة وفعالة للبيانات.
ويشمل تطبيقات تقنيات التنظيم المختلفة، وخاصة بالنسبة للنماذج الخطية.
سنستكشف هنا كيفية تطبيق ضبط L1 (Lasso) وL2 (Ridge).
في التعليمة البرمجية التالية، سوف نقوم بتدريب الانحدار اللوجستي باستخدام تقنيات Ridge(L2) وLasso Regularization (L1). وفي النهاية سنرى التقرير التفصيلي. دعونا نرى الرمز.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
هنا هو الإخراج.
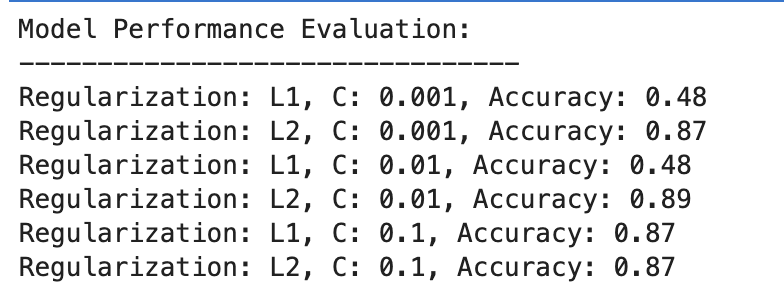
دعونا تقييم النتيجة.
تنظيم L1
- عند C=0.001، تكون الدقة منخفضة بشكل ملحوظ (48%). وهذا يدل على أن النموذج غير مناسب. يظهر الكثير من التنظيم.
- مع زيادة C إلى 0.01، تظل الدقة دون تغيير بالنسبة إلى L1، مما يشير إلى أن النموذج لا يزال يعاني من نقص التجهيز أو أن التنظيم قوي جدًا.
- عند C=0.1، تتحسن الدقة بشكل ملحوظ إلى 87%، مما يوضح أن تقليل قوة التنظيم يسمح للنموذج بالتعلم بشكل أفضل من البيانات.
تنظيم L2
في جميع المجالات، يعمل تنظيم L2 بشكل جيد باستمرار، بدقة تبلغ 87% لـ C=0.001 وأعلى قليلاً عند 89% لـ C=0.01، ثم يستقر عند 87% لـ C=0.1.
يشير هذا إلى أن تنظيم L2 أكثر تسامحًا وفعالية بشكل عام لمجموعة البيانات هذه في نماذج الانحدار اللوجستي، ربما بسبب طبيعتها.
التنظيم في التعلم العميق
يتم استخدام العديد من تقنيات التنظيم في التعلم العميق، بما في ذلك تنظيم L1 (Lasso) وL2 (Ridge)، والتسرب، والتوقف المبكر.
في هذا المثال، لتكرار ما فعلناه في مثال التعلم الآلي من قبل، سنطبق تنظيم L1 وL2. دعونا نحدد قائمة بقيم التنظيم L1 وL2 هذه المرة.
بعد ذلك، بالنسبة لكل هذه القيم، سنقوم بتدريب وتقييم نموذج التعلم العميق الخاص بنا، وفي النهاية، سنقوم بتقييم النتائج.
دعونا نرى الكود.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
هنا هو الإخراج.
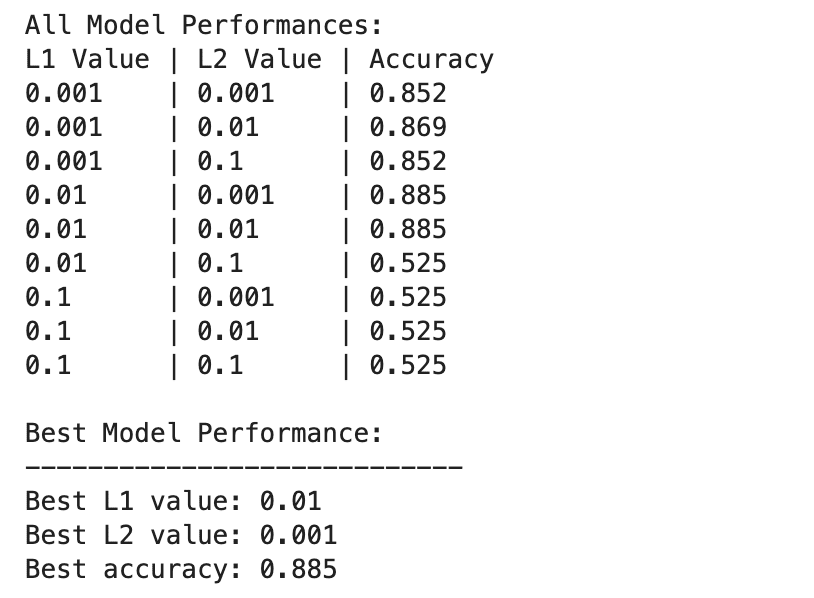
يختلف أداء نموذج التعلم العميق على نطاق أوسع عبر مجموعات مختلفة من قيم التنظيم L1 وL2.
تمت ملاحظة أفضل أداء عند L1=0.01 وL2=0.001، بدقة تبلغ 88.5%، مما يشير إلى تنظيم متوازن يمنع التجاوز مع السماح للنموذج بالتقاط الأنماط الأساسية في البيانات.
تؤدي قيم التنظيم الأعلى، خاصة عند L1=0.1 أو L2=0.1، إلى تقليل دقة النموذج بشكل كبير إلى 52.5%، مما يشير إلى أن الكثير من التنظيم يحد بشدة من قدرة التعلم للنموذج.
التعلم الآلي والتعلم العميق في التنظيم
دعونا نقارن النتائج بين التعلم الآلي والتعلم العميق.
فعالية التنظيم: في كل من سياقات التعلم الآلي والتعلم العميق، يساعد التنظيم المناسب على تخفيف التجاوز، ولكن التنظيم المفرط يؤدي إلى عدم التناسب. تختلف قوة التنظيم المثالية، حيث من المحتمل أن تتطلب نماذج التعلم العميق توازنًا أكثر دقة نظرًا لتعقيدها العالي.
الأداء: يحقق نموذج التعلم الآلي الأفضل أداءً (L2 مع C=0.01، دقة 89%) ونموذج التعلم العميق الأفضل أداءً (L1=0.01، L2=0.001، دقة 88.5%) دقة قابلة للمقارنة، مما يوضح أن كلا النهجين يمكن أن يكونا فعالين. تنظيمها لتحقيق الأداء العالي في مجموعة البيانات هذه.
استراتيجية التنظيم: يبدو أن تنظيم L2 أكثر فعالية وأقل حساسية لاختيار C في نماذج الانحدار اللوجستي، في حين أن الجمع بين تنظيم L1 وL2 يوفر أفضل نتيجة في التعلم العميق، مما يوفر توازنًا بين اختيار الميزات وعقوبة الوزن.
يجب ضبط اختيار وقوة التنظيم بعناية لتحقيق التوازن بين تعقيد التعلم وخطر الإفراط في التجهيز أو عدم التناسب.
خلال هذا الاستكشاف، قمنا بإزالة الغموض عن التنظيم، وأظهرنا دوره في منع الإفراط في التخصيص وضمان تعميم نماذجنا بشكل جيد على البيانات غير المرئية.
سيؤدي تطبيق تقنيات التنظيم إلى تقريبك من الكفاءة في التعلم الآلي والتعلم العميق، مما يعزز مجموعة أدوات عالم البيانات لديك.
انتقل إلى مشاريع البيانات وحاول تنظيم بياناتك في سيناريوهات مختلفة، مثل التنبؤ بمدة التسليم. استخدمنا نماذج التعلم الآلي والتعلم العميق في مشروع البيانات هذا. ومع ذلك، في النهاية، ذكرنا أيضًا أنه قد يكون هناك مجال للتحسين. فلماذا لا تحاول التسوية هناك ومعرفة ما إذا كان ذلك مفيدًا؟
نيت روزيدي هو عالم بيانات وفي استراتيجية المنتج. وهو أيضًا أستاذ مساعد يقوم بتدريس التحليلات ، وهو مؤسس ستراتا سكراتش، وهي منصة تساعد علماء البيانات على الاستعداد لمقابلاتهم مع أسئلة مقابلة حقيقية من الشركات الكبرى. تواصل معه تويتر: StrataScratch or لينكدين:.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

