ChatGPT هو GPT (Gمنشط Pإعادة تدريب Transformer) أداة التعلم الآلي (ML) التي فاجأت العالم. قدراته المذهلة تثير إعجاب المستخدمين العاديين والمحترفين والباحثين وحتى المبدعين الخاصين. علاوة على ذلك ، فإن قدرتها على أن تكون نموذجًا للتعلم الآلي مدربًا على المهام العامة وأداء جيدًا في المواقف الخاصة بالمجال أمر مثير للإعجاب. أنا باحث ، وتهتمني بقدرته على تحليل المشاعر (SA).
إذا سألت ChatGPT سؤال البحث هذا - وهو عنوان هذه المقالة - فسوف يعطيك إجابة متواضعة (تابع ، جربه). لكن ، يا عزيزي القارئ ، عادةً لا أفسد هذا من أجلك ، لكن ليس لديك أي فكرة عن مدى تواضع إجابة ChatGPT هذه ...
ومع ذلك ، بصفتي باحثًا في الذكاء الاصطناعي ، ومتخصصًا في الصناعة ، وهواة ، فقد اعتدت على ضبط أدوات التعلم الآلي للغة البرمجة اللغوية العصبية للمجال العام (على سبيل المثال ، GloVe) للاستخدام في المهام الخاصة بالمجال. هذا هو الحال لأنه كان من غير المألوف بالنسبة لمعظم المجالات العثور على حل خارج الصندوق يمكن أن يعمل بشكل جيد بما فيه الكفاية دون بعض الضبط الدقيق. سأريكم كيف لم يعد هذا هو الحال.
في هذا النص ، أقارن ChatGPT بنموذج ML الخاص بالمجال من خلال مناقشة الموضوعات التالية:
SemEval 2017 المهمة 5 - تحدي خاص بالمجال
استخدام ChatGPT API لتسمية مجموعة بيانات بأمثلة من التعليمات البرمجية
الحكم ونتائج المقارنة مع تفاصيل التكاثر
مناقشة الخلاصة والنتائج
المكافأة: كيف يمكن إجراء هذه المقارنة في سيناريو مطبق
ملاحظات 1: هذه مجرد تجربة عملية بسيطة تلقي بعض الضوء على الموضوع ، لا تحقيق علمي شامل.
ملاحظات 2: جميع الصور ما لم يذكر خلاف ذلك من قبل المؤلف.
1. SemEval 2017 المهمة 5 - تحدي خاص بالمجال
سيميفال (بدونسلوك غريب وحدة التقييمuation) هي ورشة عمل مشهورة في البرمجة اللغوية العصبية حيث تتنافس فرق البحث علميًا في تحليل المشاعر وتشابه النص ومهام الإجابة على الأسئلة. يوفر المنظمون بيانات نصية ومجموعات بيانات قياسية ذهبية أنشأها المعلقون (متخصصون في المجال) واللغويون لتقييم الحلول الحديثة لكل مهمة.
على وجه الخصوص ، SemEval المهمة 5 من طبعة 2017 طلب من الباحثين تسجيل المدونات المالية الصغيرة وعناوين الأخبار لتحليل المشاعر على مقياس -1 (الأكثر سلبية) إلى 1 (الأكثر إيجابية). سنستخدم مجموعة البيانات ذات المعيار الذهبي من SemEval لذلك العام لاختبار أداء ChatGPT في مهمة خاصة بالمجال. تحتوي مجموعة بيانات المهمة الفرعية 2 (عناوين الأخبار) على مجموعتين من الجمل (بحد أقصى 30 كلمة لكل منهما): مجموعات التدريب (1,142 جملة) والاختبار (491 جملة).
بالنظر إلى هذه المجموعات ، يتم عرض توزيع بيانات درجات المشاعر والجمل النصية أدناه. توضح المؤامرة أدناه توزيعات ثنائية النسق في كل من مجموعات التدريب والاختبار. علاوة على ذلك ، يشير الرسم البياني إلى أكثر من الجمل السلبية في مجموعة البيانات. ستكون هذه معلومة مفيدة في قسم التقييم.
SemEval 2017 المهمة 5 Subtask 2 (عناوين الأخبار) درجة مشاعر توزيع البيانات مع الأخذ في الاعتبار مجموعات التدريب (اليسار - 1,142 جملة) والاختبار (يمين - 491 جملة).
بالنسبة لهذه المهمة الفرعية ، قام فريق البحث الفائز (أي الذي حصل على الترتيب الأفضل في مجموعة الاختبار) بتسمية بنية ML الخاصة بهم فورتيا-FBK. مستوحاة من اكتشافات هذه المسابقة ، قمت أنا وبعض الزملاء بعمل مقال بحثي (تقييم تقنيات تحليل المشاعر القائمة على الانحدار في النصوص المالية) حيث قمنا بتطبيق إصدار Fortia-FBK الخاص بنا وقمنا بتقييم طرق تحسين هذه البنية.
أيضًا ، قمنا بالتحقيق في العوامل التي جعلت هذه العمارة هي الفائز. وهكذا فإن تنفيذنا (الكود هنا) من هذه العمارة الفائزة (أي Fortia-FBK) للمقارنة مع ChatGPT. الهندسة المعمارية (CNN + GloVe + Vader) المستخدمة هي الموضحة أدناه.
إذا كان هذا المحتوى التعليمي التفصيلي مفيدًا لك ، اشترك في قائمتنا البريدية AI ليتم تنبيهنا عندما نصدر مادة جديدة.
2. استخدام ChatGPT API لتسمية مجموعة بيانات
تمت مناقشة استخدام ChatGPT API بالفعل هنا على Medium لتجميع البيانات. أيضًا ، يمكنك العثور على أمثلة على تسمية المشاعر في ملف قسم عينات كود ChatGPT API (لاحظ أن استخدام API ليس مجانيًا). بالنسبة لمثال التعليمات البرمجية هذا ، ضع في اعتبارك مجموعة بيانات SemEval's 2017 Task ذات المعايير الذهبية التي يمكنك القيام بها إلى هنا.
بعد ذلك ، لاستخدام واجهة برمجة التطبيقات لتصنيف عدة جمل في وقت واحد ، استخدم رمزًا على هذا النحو ، حيث أقوم بإعداد موجه كامل مع جمل من إطار بيانات مع مجموعة بيانات المعيار الذهبي مع الجملة المراد تصنيفها والشركة المستهدفة التي تم الشعور بها. يشير.
def prepare_long_prompt(df): initial_txt = "Classify the sentiment in these sentences between brackets regarding only the company specified in double-quotes. The response should be in one line with format company name in normal case followed by upper cased sentiment category in sequence separated by a semicolon:nn" prompt = """ + df['company'] + """ + " [" + df['title'] + ")]" return initial_txt + 'n'.join(prompt.tolist())
ثم ، قم باستدعاء API للملف نص- دافينشي -003محرك (إصدار GPT-3). لقد أجريت هنا بعض التعديلات على الكود لحساب الحد الأقصى لعدد الأحرف الإجمالية في الموجه بالإضافة إلى الإجابة ، والتي يجب ألا تزيد عن 4097 حرفًا.
def call_chatgpt_api(prompt): # getting the maxium amount of tokens allowed to the response, based on the # api Max of 4097, and considering the length of the prompt text prompt_length = len(prompt) max_tokens = 4097 - prompt_length # this rule of dividing by 10 is just a empirical estimation and is not a precise rule if max_tokens < (prompt_length / 10): raise ValueError(f'Max allowed token for response is dangerously low {max_tokens} and might not be enough, try reducing the prompt size') response = openai.Completion.create( model="text-davinci-003", prompt=prompt, temperature=0, max_tokens=max_tokens, top_p=1, frequency_penalty=0, presence_penalty=0 ) return response.choices[0]['text'] long_prompt = prepare_long_prompt(df)
call_chatgpt_api(long_prompt)
في النهاية ، عند القيام بذلك لما مجموعه 1633 جملة (تدريب + مجموعات اختبار) في مجموعة البيانات ذات المعيار الذهبي وستحصل على النتائج التالية باستخدام ملصقات ChatGPT API.
مثال على SemEval 2017 Task 5 Subtask 2 (عناوين الأخبار) مجموعة بيانات Gold-Standard مع شعور مسمى باستخدام ChatGPT API.
2.1. مشاكل متعلقة بـ ChatGPT وواجهة برمجة تطبيقاتها على نطاق واسع
كما هو الحال مع أي واجهة برمجة تطبيقات أخرى ، هناك بعض المتطلبات النموذجية
حد معدل الطلبات الذي يتطلب تعديلات الاختناق
حد طلب يبلغ 25000 رمز (أي وحدة كلمات فرعية أو ترميز زوج البايت)
الحد الأقصى لطول 4096 رمزًا مميزًا لكل طلب (سريع + استجابة مضمنة)
تكلفة قدرها 0.0200 دولار / 1 ألف توكينز (ملاحظة: لم أنفق أكثر من 2 دولار بعد كل ما فعلته)
ومع ذلك ، فهذه ليست سوى المتطلبات النموذجية عند التعامل مع معظم واجهات برمجة التطبيقات. علاوة على ذلك ، تذكر أنه في هذه المشكلة الخاصة بالمجال ، هناك كيان مستهدف (أي شركة) لكل جملة للمشاعر. لذلك اضطررت إلى اللعب حتى صممت نمطًا سريعًا جعل من الممكن تسمية مشاعر عدة جمل في وقت واحد وجعل من السهل معالجة النتائج بعد ذلك. علاوة على ذلك ، هذه هي القيود الأخرى التي أثرت على الموجه والرمز اللذين أظهرتهما سابقًا. على وجه التحديد ، وجدت مشكلات في استخدام واجهة برمجة التطبيقات النصية هذه لعدة جمل (> 1000).
قابلية اعادة الأنتاج: يمكن أن تتغير تقييمات المشاعر في ChatGPT بشأن المشاعر بشكل كبير مع تغييرات قليلة جدًا على الموجه (على سبيل المثال ، إضافة أو إزالة فاصلة أو نقطة من الجملة).
الاتساق: إذا لم تحدد استجابة النمط بوضوح ، فسيكون ChatGPT مبدعًا (حتى إذا حددت معامل عشوائية منخفضة جدًا) ، مما يجعل معالجة النتائج صعبة. علاوة على ذلك ، حتى عندما تحدد النمط ، فإنه يمكن أن ينتج تنسيقات إخراج غير متناسقة.
عدم التطابق: على الرغم من أنه يمكن تحديد الكيان المستهدف بدقة شديدة (على سبيل المثال ، الشركة) الذي تريد أن يتم تقييم المشاعر في جملة ، إلا أنه يمكن أن يخلط النتائج عند القيام بذلك على نطاق واسع. على سبيل المثال ، افترض أنك مررت 10 جمل لكل منها مع شركة مستهدفة. ومع ذلك ، تظهر بعض الشركات في جمل أخرى أو تتكرر. في هذه الحالة ، يمكن لـ ChatGPT عدم تطابق الأهداف ومشاعر الجملة ، أو تغيير ترتيب تسميات المشاعر أو تقديم أقل من 10 تسميات.
تشير كل هذه المشكلات إلى منحنى تعليمي لاستخدام واجهة برمجة التطبيقات (المتحيزة) بشكل صحيح. تطلب الأمر بعض الضبط الدقيق للحصول على ما أحتاجه. اضطررت أحيانًا إلى إجراء العديد من التجارب حتى وصلت إلى النتيجة المرجوة بأقل قدر من الاتساق.
يجب أن ترسل أكبر عدد ممكن من الجمل دفعة واحدة في وضع مثالي لسببين. أولاً ، تريد الحصول على ملصقاتك بأسرع ما يمكن. ثانيًا ، يتم احتساب الموجه كرموز مميزة في التكلفة ، لذا فإن عدد الطلبات الأقل يعني تكلفة أقل. ومع ذلك ، لدينا حد 4096 توكينز لكل طلب. أيضًا ، نظرًا للمشكلات التي ذكرتها ، يوجد قيد آخر ملحوظ لواجهة برمجة التطبيقات. يؤدي تمرير العديد من الجمل دفعة واحدة إلى زيادة فرصة عدم التطابق وعدم الاتساق. وبالتالي ، فإن الأمر متروك لك لمواصلة زيادة عدد الجمل وتقليله حتى تجد مكانك المناسب للتناسق والتكلفة. إذا لم تفعل ذلك بشكل صحيح ، فستعاني في مرحلة ما بعد معالجة النتائج.
باختصار ، إذا كان لديك آلاف الجمل التي يجب معالجتها ، فابدأ بدفعة من بضع ست جمل ولا تزيد عن 10 مطالبات للتحقق من موثوقية الردود. بعد ذلك ، قم بزيادة الرقم ببطء للتحقق من السعة والجودة حتى تجد الموجه الأمثل والمعدل الذي يناسب مهمتك.
3. الحكم ونتائج المقارنة
3.1. تفاصيل المقارنة
لا يمكن لـ ChatGPT ، في إصدار GPT-3 ، أن ينسب المشاعر إلى الجمل النصية باستخدام القيم الرقمية (مهما حاولت). ومع ذلك ، أرجع المتخصصون الدرجات الرقمية إلى مشاعر الجملة في مجموعة البيانات المعيارية الذهبية هذه.
لذلك ، لإجراء مقارنة قابلة للتطبيق ، كان علي:
صنف نقاط مجموعة البيانات إلى إيجابي, متعددالطرق أو سلبي تسميات.
افعل الشيء نفسه مع الدرجات الناتجة من نموذج ML الخاص بالمجال.
حدد نطاقًا من العتبات المحتملة (بخطوات 0.001) لتحديد مكان بداية وتنتهي فئة واحدة. ثم ، بالنظر إلى العتبة TH,عشرات أعلاه +TH مأخوذة في عين الأعتبار إيجابي المشاعر أدناه -TH is نيجاتإيف ، وبينهما متعدد.
كرر مدى العتبات وقم بتقييم دقة كلا النموذجين في كل نقطة.
تحقق من أدائهم بالمجموعات (أي التدريب أو الاختبار) ، بالنظر إلى أن النموذج الخاص بالمجال سيكون له ميزة غير عادلة في مجموعة التدريب.
رمز الخطوة 3 أدناه. والكود الكامل لتكرار المقارنة بأكملها .
3.2 الحكم: نعم ، لا يمكن لـ ChatGPT الفوز بالمنافسة فحسب ، بل أيضًا تحطيمها
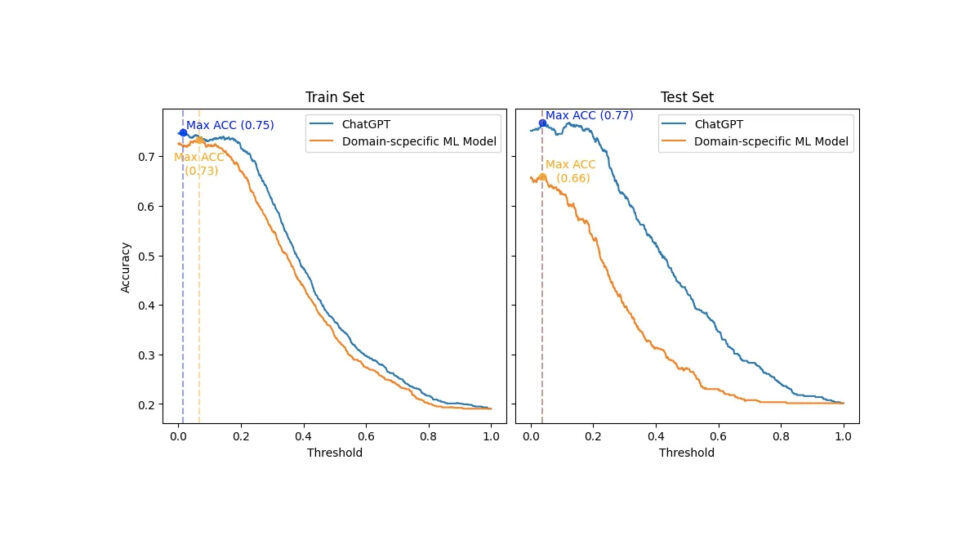
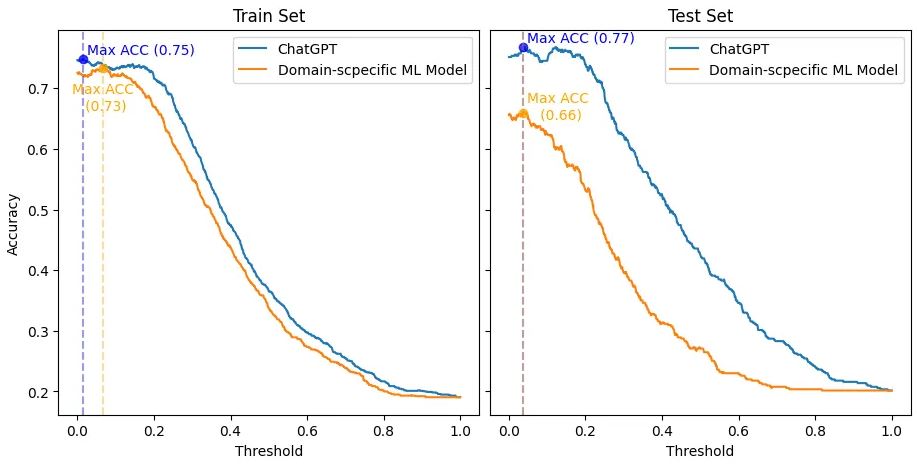
يتم عرض النتيجة النهائية في الرسم البياني أدناه ، والذي يوضح كيف تتغير الدقة (المحور الصادي) لكلا النموذجين عند تصنيف مجموعة البيانات القياسية الذهبية ، حيث يتم ضبط العتبة (المحور السيني). أيضًا ، توجد مجموعات التدريب والاختبار على الجانبين الأيسر والأيمن ، على التوالي.
مقارنة بين ChatGPT ونموذج ML الخاص بالمجال الذي يأخذ في الاعتبار التدريب (الجانب الأيسر) والاختبار (الجانب الأيمن) المحددان بشكل منفصل. يقيم هذا التقييم كيف تتغير الدقة (المحور الصادي) فيما يتعلق بالعتبة (المحور السيني) لتصنيف مجموعة البيانات القياسية الذهبية لكلا النموذجين.
أولا ، يجب أن أكون صادقا. لم أكن أتوقع هذه النتيجة الساحقة. وبالتالي ، لكي لا أكون غير عادل مع ChatGPT ، قمت بتكرار إعداد مسابقة SemEval 2017 الأصلي ، حيث سيتم بناء نموذج ML الخاص بالمجال مع مجموعة التدريب. عندئذٍ سيحدث الترتيب والمقارنة الفعليان فقط عبر مجموعة الاختبار.
ومع ذلك ، حتى في مجموعة التدريب ، مع السيناريو الأكثر ملاءمة - عتبة 0.066 مقابل 0.014 لـ ChatGPT - حقق نموذج ML الخاص بالمجال دقة 2pp أسوأ من دقة ChatGPT (0.73 مقابل 0.75). علاوة على ذلك ، أظهر ChatGPT دقة فائقة عبر جميع العتبات مقارنة بنموذج المجال المحدد في كل من مجموعات التدريب والاختبار.
ومن المثير للاهتمام ، أن أفضل عتبة لكلا النموذجين (0.038 و 0.037) كانت قريبة في مجموعة الاختبار. وعند هذا الحد ، حقق ChatGPT دقة أفضل بمقدار 11pp من النموذج المحدد بالنطاق (0.66 مقابل 077). أيضًا ، أظهر ChatGPT اتساقًا أفضل بكثير عبر تغييرات العتبة من النموذج الخاص بالمجال. وبالتالي ، من الواضح أن دقة ChatGPT انخفضت بشكل أقل حدة.
في الاستئناف ، تفوقت ChatGPT بشكل كبير على نموذج ML الخاص بالمجال من حيث الدقة. أيضًا ، الفكرة هي أنه يمكن ضبط ChatGPT لمهام محددة. ومن ثم ، تخيل إلى أي مدى يمكن أن يصبح ChatGPT أفضل.
3.3 التحقيق في وضع العلامات على المشاعر في ChatGPT
كنت أنوي دائمًا إجراء تحقيق أكثر دقة من خلال أخذ أمثلة حيث كان ChatGPT غير دقيق ومقارنته بالنموذج الخاص بالنطاق. ومع ذلك ، نظرًا لأن ChatGPT أصبح أفضل بكثير مما كان متوقعًا ، فقد انتقلت إلى التحقيق فقط في الحالات التي فاتها الشعور الصحيح.
في البداية ، أجريت تقييمًا مشابهًا كما كان من قبل ، ولكني الآن أستخدم مجموعة بيانات Gold-Standard الكاملة في وقت واحد. بعد ذلك ، قمت بتحديد العتبة (0.016) لتحويل القيم الرقمية القياسية الذهبية إلى تسميات موجبة ، ومحايدة ، وسالبة والتي حصلت على أفضل دقة في ChatGPT (0.75). ثم قمت بعمل مصفوفة ارتباك. المؤامرات أدناه.
على الجانب الأيسر ، رسم خط لتقييم كيفية تغير دقة ChatGPT (المحور الصادي) فيما يتعلق بالعتبة (المحور السيني) لتصنيف مجموعة البيانات الرقمية الكاملة القياسية الذهبية. توجد مصفوفة الارتباك الخاصة بالتسميات الموجبة والمحايدة والسالبة على الجانب الأيمن ، نظرًا لأن الحد الذي يؤدي إلى أقصى أداء في ChatGPT هو 0.016. أيضًا ، تحتوي مصفوفة الارتباك على النسبة المئوية لعدد مرات الدخول والخسائر في ChatGPT وفقًا للتسميات المحولة.
تذكر أنني أظهرت توزيعًا لجمل البيانات مع درجات إيجابية أكثر من الجمل السلبية في القسم السابق. هنا في مصفوفة الارتباك ، لاحظ أنه بالنظر إلى عتبة 0.016 ، هناك 922 (56.39٪) جملة موجبة ، 649 (39.69٪) سلبية ، و 64 (3.91٪) محايدة.
لاحظ أيضًا أن ChatGPT أقل دقة مع التسميات المحايدة. هذا متوقع ، لأن هذه هي التسميات الأكثر عرضة للتأثر بحدود العتبة. ومن المثير للاهتمام أن ChatGPT تميل إلى تصنيف معظم هذه الجمل المحايدة على أنها إيجابية. ومع ذلك ، نظرًا لأن عددًا أقل من الجمل يعتبر محايدًا ، فقد تكون هذه الظاهرة مرتبطة بمزيد من درجات المشاعر الإيجابية في مجموعة البيانات.
من ناحية أخرى ، عند النظر في التسميات الأخرى ، أظهر ChatGPT القدرة على تحديد 6pp بشكل صحيح فئات إيجابية أكثر من سلبية (78.52٪ مقابل 72.11٪). في هذه الحالة ، لست متأكدًا من أن هذا مرتبط بعدد الجمل في كل مجموعة نقاط. أولاً ، لأن هناك جمل أكثر بكثير من كل نوع فئة. ثانيًا ، لاحظ عدد أخطاء ChatGPT التي ذهبت إلى الملصقات في الاتجاه المعاكس (إيجابي إلى سلبي أو العكس). مرة أخرى ، يرتكب ChatGPT المزيد من مثل هذه الأخطاء مع الفئة السلبية ، والتي هي أقل عددًا بكثير. وبالتالي ، فإن ChatGPT يبدو أكثر انزعاجًا من الجمل السلبية منه مع الجمل الإيجابية.
3.4. بعض الحالات المحددة ومقارنتها بمتخصصين بشريين
لقد اخترت بضع جمل مع أكثر الخصائص وضوحًا بين المعيار الذهبي (الدرجات البشرية) و ChatGPT. بعد ذلك ، استخدمت نفس الحد الذي تم تحديده مسبقًا لتحويل الدرجات الرقمية إلى تسميات المشاعر (0.016). علاوة على ذلك، تم بالفعل الإبلاغ عن أن ChatGPT يتفوق على البشر. وهكذا ، قمت بالتحقيق في التناقضات وأصدرت قراري ، والذي وجدته أكثر دقة بالنسبة للبشر أو Chatgpt.
يعرض الجدول أمثلة على الجمل التي بها عدم تطابق بين التسميات القياسية الذهبية (المحولة من درجات المتخصصين البشريين باستخدام عتبات 0.016) و ChatGPT. علاوة على ذلك ، أعطيت حكمي الذي أوافق عليه أفضل.
بدءًا من الحالات التي حكمت فيها لصالح متخصصين بشريين. في حالات الجملتين 3 و 4 ، كان يجب على ChatGPT أن يدرك أن استعادة المدفوعات وتحالفات الشركة تعتبر بشكل عام مفيدة في مجال التمويل. ومع ذلك ، في حالة الجملة 7 ، طلبت منها شرح قرارها ، وهذا ما أجاب عليه ChatGPT:
يتم التعبير عن المشاعر الإيجابية تجاه باركليز من خلال كلمة "سجل" ، مما يدل على إنجاز كبير للشركة في حل المشكلات القانونية بنجاح مع الهيئات التنظيمية.
في حالة هذه الجملة ، لم تدرك ChatGPT أنه على الرغم من أن عقد صفقة قياسية قد يكون جيدًا بشكل عام ، إلا أن SEC هي هيئة تنظيمية. ومن ثم ، فإن إبرام صفقة قياسية مع هيئة الأوراق المالية والبورصات يعني أن بنك باركليز وكريدي سويس كان عليهما دفع قيمة قياسية في الغرامات.
بالانتقال إلى الجملتين 5 و 8 ، كانت هذه نداءات صعبة للغاية. اسمحوا لي أن أكون واضحًا ، لقد كان البشر على صواب في تقييماتهم. ومع ذلك ، فهذه هي الحالة التي لم يكن بإمكان ChatGPT تخمينها. في الجملة 5 ، تطلب الأمر معرفة الموقف في تلك اللحظة الزمنية لفهم أن الجملة تمثل نتيجة جيدة. وبالنسبة للجملة 8 ، هناك حاجة إلى معرفة أن انخفاض سعر النفط يرتبط بانخفاض سعر السهم لتلك الشركة المستهدفة المحددة.
بعد ذلك ، بالنسبة للجملة 6 ، أكثر الجمل حيادية التي يمكن أن تحصل عليها بدون درجة عاطفية ، أوضحت ChatGPT قرارها على النحو التالي:
الجملة إيجابية لأنها تعلن عن تعيين رئيس عمليات جديد لبنك الاستثمار ، وهو خبر سار للشركة.
ومع ذلك ، كانت هذه استجابة عامة وليست ثاقبة للغاية ولم تبرر سبب اعتقاد ChatGPT أن تعيين هذا المدير التنفيذي بعينه كان جيدًا. وهكذا اتفقت مع المختصين من البشر في هذه الحالة.
ومن المثير للاهتمام ، أنني حكمت بشكل إيجابي في الجمل 1 و 2 و 9 و 10 لـ ChatGPT. علاوة على ذلك ، بالنظر بعناية ، يجب أن يولي المتخصصون البشريون مزيدًا من الاهتمام للشركة المستهدفة أو الرسالة العامة. هذا رمز بشكل خاص في الجملة 1 ، حيث كان على المتخصصين أن يدركوا أنه على الرغم من أن المشاعر كانت إيجابية بالنسبة لشركة Glencore ، إلا أن الشركة المستهدفة كانت باركليز ، التي كتبت التقرير للتو. وبهذا المعنى ، كان موقع ChatGPT أفضل في تمييز هدف المشاعر والمعنى في هذه الجمل.
4. خاتمة ونتائج مناقشة
كما هو موضح في الجدول أدناه ، يتطلب تحقيق مثل هذا الأداء الكثير من الموارد المالية والبشرية.
مقارنة بين جوانب النماذج مثل عدد المعلمات ، وحجم تضمين الكلمات المستخدمة ، والتكلفة ، وعدد الباحثين لبنائها ، وأفضل دقة في مجموعة الاختبار ، وما إذا كان قرارها قابلاً للتفسير.
بهذا المعنى ، على الرغم من أن ChatGPT تفوق في الأداء على نموذج المجال المحدد ، فإن المقارنة النهائية ستحتاج إلى ضبط ChatGPT لمهمة خاصة بالمجال. سيساعد القيام بذلك في معالجة ما إذا كانت المكاسب في أداء الضبط الدقيق تفوق تكاليف الجهد.
من ناحية أخرى ، مع شعبية نماذج النصوص التوليدية و LLMs ، فإن البعض إصدارات مفتوحة المصدر يمكن أن تساعد في تجميع مقارنة مستقبلية مثيرة للاهتمام. علاوة على ذلك ، فإن قدرة LLMs مثل ChatGPT على شرح قراراتهم هي إنجاز رائع ، يمكن القول إنه غير متوقع يمكن أن يحدث ثورة في هذا المجال.
5. المكافأة: كيف يمكن إجراء هذه المقارنة في سيناريو مطبق
تحليل المشاعر في المجالات المختلفة هو مسعى علمي قائم بذاته. ومع ذلك ، فإن تطبيق نتائج تحليل المشاعر في سيناريو مناسب يمكن أن يكون مشكلة علمية أخرى. أيضًا ، نظرًا لأننا نفكر في جمل من المجال المالي ، سيكون من الملائم تجربة إضافة ميزات المشاعر إلى نظام ذكي مطبق. هذا بالضبط ما كان يفعله بعض الباحثين ، وأنا أجرب ذلك أيضًا.
في عام 2021 قمت أنا وبعض الزملاء بنشر ملف مقال بحثي حول كيفية توظيف تحليل المشاعر في سيناريو تطبيقي. في هذه المقالة - التي تم تقديمها في المؤتمر الدولي الثاني لـ ACM حول الذكاء الاصطناعي في التمويل (ICAIF'21) - اقترحنا طريقة فعالة لدمج معنويات السوق في هيكل التعلم المعزز. الكود المصدري لتنفيذ هذه البنية هو متوفرة هنا، وجزء من تصميمه العام معروض أدناه.
جزء من مثال معماري لكيفية دمج معنويات السوق في بنية التعلم المعززة للمواقف التطبيقية. المصدرأنظمة التداول الذكية: نهج التعلم المعزز للمشاعر. وقائع المؤتمر الدولي الثاني للـ ACM حول الذكاء الاصطناعي في التمويل (ICAIF '21). ليما بايفا ، إف سي؛ فيليزاردو ، ل. بيانكي ، را د. CB ؛ كوستا ، AHR
تم تصميم هذه البنية للعمل مع درجات المشاعر العددية مثل تلك الموجودة في مجموعة البيانات Gold-Standard. ومع ذلك ، هناك تقنيات (على سبيل المثال ، مؤشر Bullishnex) لتحويل المشاعر الفئوية ، كما تم إنشاؤها بواسطة ChatGPT في القيم العددية المناسبة. إن تطبيق مثل هذا التحويل يجعل من الممكن استخدام المشاعر التي تحمل علامة ChatGPT في مثل هذه البنية. علاوة على ذلك ، هذا مثال على ما يمكنك القيام به في مثل هذه الحالة وهو ما أنوي القيام به في التحليل المستقبلي.
5.1 مقالات أخرى في خط بحثي (NLP ، RL)
ليما بايفا ، إف سي؛ فيليزاردو ، ل. بيانكي ، را د. CB ؛ كوستا ، AHR أنظمة التداول الذكية: نهج التعلم المعزز للمشاعر. وقائع المؤتمر الدولي الثاني للـ ACM حول الذكاء الاصطناعي في التمويل (ICAIF '21).