المُقدّمة
الإجهاد هو استجابة طبيعية للجسم والعقل لموقف صعب أو صعب. إنها طريقة الجسم للتفاعل مع الضغوط الخارجية أو الأفكار والمشاعر الداخلية. يمكن أن ينجم التوتر عن مجموعة متنوعة من العوامل ، مثل الضغط المرتبط بالعمل ، أو الصعوبات المالية ، أو مشاكل العلاقات ، أو المشكلات الصحية ، أو الأحداث الحياتية الكبرى. تهدف رؤى اكتشاف الإجهاد ، المدفوعة بعلوم البيانات والتعلم الآلي ، إلى التنبؤ بمستويات الإجهاد لدى الأفراد أو السكان. من خلال تحليل مجموعة متنوعة من مصادر البيانات ، مثل القياسات الفسيولوجية والبيانات السلوكية والعوامل البيئية ، يمكن للنماذج التنبؤية تحديد الأنماط وعوامل الخطر المرتبطة بالإجهاد.

يتيح هذا النهج الاستباقي التدخل في الوقت المناسب والدعم المخصص. يحمل التنبؤ بالإجهاد إمكانات في الرعاية الصحية للكشف المبكر والتدخل الشخصي وكذلك في البيئات المهنية لتحسين بيئات العمل. ويمكنه أيضًا إعلام مبادرات الصحة العامة وقرارات السياسة. مع القدرة على التنبؤ بالإجهاد ، توفر هذه النماذج رؤى قيمة لتحسين الرفاهية وزيادة المرونة في الأفراد والمجتمعات.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
نظرة عامة على اكتشاف الإجهاد باستخدام التعلم الآلي
يتضمن اكتشاف الإجهاد باستخدام التعلم الآلي جمع البيانات وتنظيفها ومعالجتها مسبقًا. يتم تطبيق تقنيات هندسة المعالم لاستخراج معلومات مفيدة أو إنشاء ميزات جديدة يمكنها التقاط الأنماط المتعلقة بالتوتر. قد يشمل ذلك استخراج المقاييس الإحصائية أو تحليل مجال التردد أو تحليل السلاسل الزمنية لالتقاط المؤشرات الفسيولوجية أو السلوكية للإجهاد. يتم استخراج الميزات ذات الصلة أو هندستها لتحسين الأداء.

يقوم الباحثون بتدريب نماذج التعلم الآلي مثل الانحدار اللوجستي أو SVM أو أشجار القرار أو الغابات العشوائية أو الشبكات العصبية من خلال استخدام البيانات المصنفة لتصنيف مستويات الإجهاد. يقومون بتقييم أداء النماذج باستخدام مقاييس مثل الدقة والدقة والتذكر ودرجة F1. يتيح دمج النموذج المدرَّب في تطبيقات العالم الحقيقي مراقبة الإجهاد في الوقت الفعلي. المراقبة المستمرة والتحديثات وتعليقات المستخدمين ضرورية لتحسين الدقة.
من الأهمية بمكان مراعاة القضايا الأخلاقية ومخاوف الخصوصية عند التعامل مع البيانات الشخصية الحساسة المتعلقة بالتوتر. يجب اتباع الموافقة المستنيرة المناسبة وإخفاء هوية البيانات وإجراءات تخزين البيانات الآمنة لحماية خصوصية الأفراد وحقوقهم. تعتبر الاعتبارات الأخلاقية والخصوصية وأمن البيانات مهمة خلال العملية بأكملها. يتيح اكتشاف الإجهاد المستند إلى التعلم الآلي التدخل المبكر وإدارة الضغوط الشخصية وتحسين الرفاهية.
بيانات الوصف
تحتوي مجموعة بيانات "الإجهاد" على معلومات تتعلق بمستويات التوتر. بدون البنية والأعمدة المحددة لمجموعة البيانات ، يمكنني تقديم نظرة عامة عامة على الشكل الذي قد يبدو عليه وصف بيانات النسبة المئوية.
قد تحتوي مجموعة البيانات على متغيرات عددية تمثل القياسات الكمية ، مثل العمر أو ضغط الدم أو معدل ضربات القلب أو مستويات الإجهاد التي يتم قياسها على مقياس. وقد تشمل أيضًا المتغيرات الفئوية التي تمثل الخصائص النوعية ، مثل الجنس أو فئات المهنة أو مستويات الإجهاد المصنفة في فئات مختلفة (منخفضة ، متوسطة ، عالية).
# Array
import numpy as np # Dataframe
import pandas as pd #Visualization
import matplotlib.pyplot as plt
import seaborn as sns # warnings
import warnings
warnings.filterwarnings('ignore') #Data Reading
stress_c= pd.read_csv('/human-stress-prediction/Stress.csv') # Copy
stress=stress_c.copy() # Data
stress.head()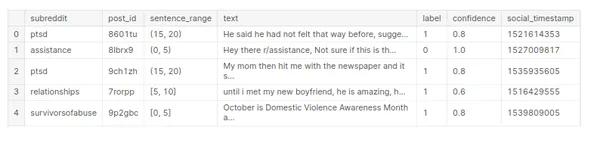
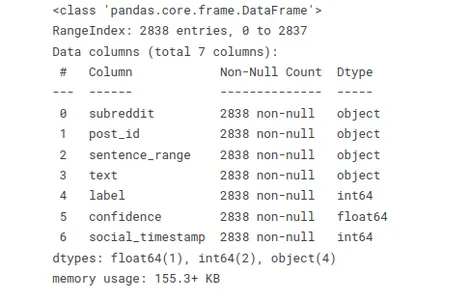
أدناه وظيفة تسمح لك بتقييم أنواع البيانات بسرعة واكتشاف القيم المفقودة أو الفارغة. يفيد هذا الملخص عند العمل مع مجموعات البيانات الكبيرة أو أداء مهام تنظيف البيانات والمعالجة المسبقة.
# Info
stress.info()
استخدم التعليمات البرمجية stress.isnull (). sum () للتحقق من القيم الخالية في مجموعة بيانات "الإجهاد" وحساب مجموع القيم الخالية في كل عمود.
# Checking null values
stress.isnull().sum()

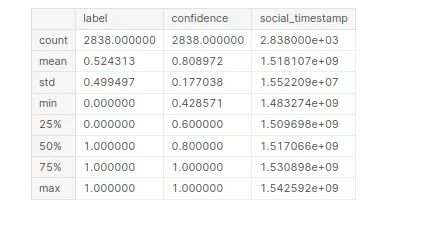
لتوليد معلومات إحصائية حول مجموعة بيانات "الإجهاد". من خلال تجميع هذا الرمز ، ستحصل على ملخص للإحصاءات الوصفية لكل عمود رقمي في مجموعة البيانات.
# Statistical Information
stress.describe()
تحليل البيانات الاستكشافية (EDA)
يعد تحليل البيانات الاستكشافية (EDA) خطوة حاسمة في فهم مجموعة البيانات وتحليلها. يتضمن الاستكشاف المرئي وتلخيص الخصائص والأنماط والعلاقات الرئيسية داخل البيانات
lst=['subreddit','label']
plt.figure(figsize=(15,12))
for i in range(len(lst)): plt.subplot(1,2,i+1) a=stress[lst[i]].value_counts() lbl=a.index plt.title(lst[i]+'_Distribution') plt.pie(x=a,labels=lbl,autopct="%.1f %%") plt.show()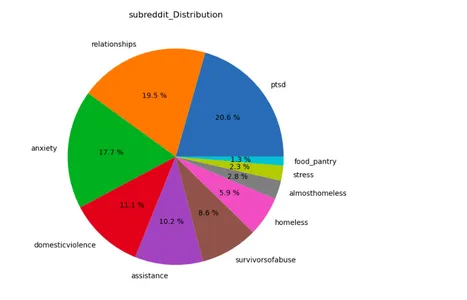
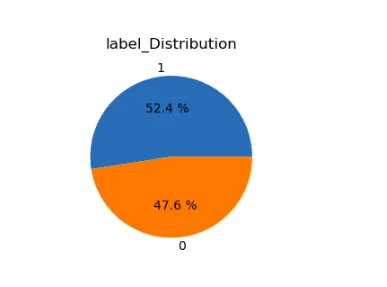
تقوم مكتبات Matplotlib و Seaborn بإنشاء مخطط تعداد لمجموعة بيانات "الإجهاد". إنه يصور عدد حالات التوتر عبر subreddits المختلفة ، مع تمييز تسميات الضغط بألوان مختلفة.
plt.figure(figsize=(20,12))
plt.title('Subreddit wise stress count')
plt.xlabel('Subreddit')
sns.countplot(data=stress,x='subreddit',hue='label',palette='gist_heat')
plt.show()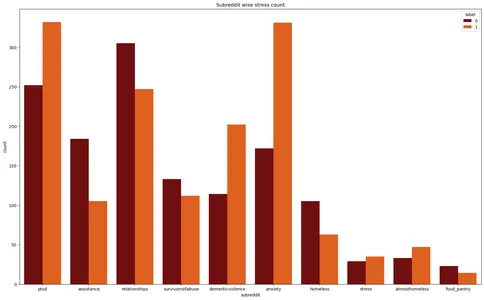
معالجة النص
تشير المعالجة المسبقة للنص إلى عملية تحويل بيانات النص الخام إلى تنسيق أكثر تنظيماً وتنظيماً يناسب مهام التحليل أو النمذجة. يتضمن بشكل خاص سلسلة من الخطوات لإزالة الضوضاء وتطبيع النص واستخراج الميزات ذات الصلة. لقد أضفت هنا جميع المكتبات المتعلقة بمعالجة النص هذه.
# Regular Expression
import re # Handling string
import string # NLP tool
import spacy nlp=spacy.load('en_core_web_sm')
from spacy.lang.en.stop_words import STOP_WORDS # Importing Natural Language Tool Kit for NLP operations
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('omw-1.4') from nltk.stem import WordNetLemmatizer from wordcloud import WordCloud, STOPWORDS
from nltk.corpus import stopwords
from collections import Counter
تتضمن بعض الأساليب الشائعة المستخدمة في المعالجة المسبقة للنص ما يلي:
تنظيف النص
- إزالة الأحرف الخاصة: قم بإزالة علامات الترقيم أو الرموز أو الأحرف غير الأبجدية الرقمية التي لا تساهم في معنى النص.
- إزالة الأرقام: قم بإزالة الأرقام العددية إذا لم تكن ذات صلة بالتحليل.
- أحرف صغيرة: قم بتحويل كل النص إلى أحرف صغيرة لضمان التناسق في مطابقة النص والتحليل.
- إزالة كلمات التوقف: قم بإزالة الكلمات الشائعة التي لا تحمل الكثير من المعلومات ، مثل "a" ، "the" ، "is" ، إلخ.
Tokenization
- تقسيم النص إلى كلمات أو رموز مميزة: قسّم النص إلى كلمات أو رموز منفردة للتحضير لمزيد من التحليل. يمكن للباحثين تحقيق ذلك من خلال استخدام المسافات البيضاء أو تقنيات ترميز أكثر تقدمًا ، مثل استخدام مكتبات مثل NLTK أو spaCy.
تطبيع
- Lemmatization: اختصر الكلمات إلى شكلها الأساسي أو القاموس (lemmas). على سبيل المثال ، تحويل "تشغيل" و "ركض" إلى "تشغيل".
- Stemming: اختصر الكلمات إلى شكلها الأساسي عن طريق إزالة البادئات أو اللواحق. على سبيل المثال ، تحويل "تشغيل" و "ركض" إلى "تشغيل".
- إزالة علامات التشكيل: قم بإزالة علامات التشكيل أو علامات التشكيل الأخرى من الأحرف.
#defining function for preprocessing
def preprocess(text,remove_digits=True): text = re.sub('W+',' ', text) text = re.sub('s+',' ', text) text = re.sub("(?<!w)d+", "", text) text = re.sub("-(?!w)|(?<!w)-", "", text) text=text.lower() nopunc=[char for char in text if char not in string.punctuation] nopunc=''.join(nopunc) nopunc=' '.join([word for word in nopunc.split() if word.lower() not in stopwords.words('english')]) return nopunc
# Defining a function for lemitization
def lemmatize(words): words=nlp(words) lemmas = [] for word in words: lemmas.append(word.lemma_) return lemmas #converting them into string
def listtostring(s): str1=' ' return (str1.join(s)) def clean_text(input): word=preprocess(input) lemmas=lemmatize(word) return listtostring(lemmas)# Creating a feature to store clean texts
stress['clean_text']=stress['text'].apply(clean_text)
stress.head()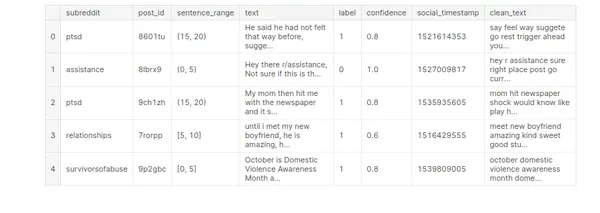
بناء نموذج التعلم الآلي
بناء نموذج التعلم الآلي هو عملية إنشاء تمثيل رياضي أو نموذج يمكنه تعلم الأنماط وإجراء تنبؤات أو قرارات من البيانات. يتضمن تدريب نموذج باستخدام مجموعة بيانات مصنفة ثم استخدام هذا النموذج لعمل تنبؤات بشأن بيانات جديدة غير مرئية.
اختيار أو إنشاء الميزات ذات الصلة من البيانات المتاحة. تهدف هندسة الميزات إلى استخراج معلومات ذات مغزى من البيانات الأولية التي يمكن أن تساعد النموذج في تعلم الأنماط بشكل فعال.
# Vectorization
from sklearn.feature_extraction.text import TfidfVectorizer # Model Building
from sklearn.model_selection import GridSearchCV,StratifiedKFold, KFold,train_test_split,cross_val_score,cross_val_predict
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn import preprocessing
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier,RandomForestClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier #Model Evaluation
from sklearn.metrics import confusion_matrix,classification_report, accuracy_score,f1_score,precision_score
from sklearn.pipeline import Pipeline # Time
from time import time# Defining target & feature for ML model building
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)اختيار خوارزمية تعلم آلي مناسبة أو بنية نموذجية بناءً على طبيعة المشكلة وخصائص البيانات. النماذج المختلفة ، مثل أشجار القرار ، أو آلات ناقلات الدعم ، أو الشبكات العصبية ، لها نقاط قوة وضعف مختلفة.
تدريب النموذج المحدد باستخدام البيانات المسمى. تتضمن هذه الخطوة تغذية بيانات التدريب إلى النموذج والسماح له بمعرفة الأنماط والعلاقات بين الميزات والمتغير المستهدف.
# Self-defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Logistic regression def model_lr_tf(x_train, x_test, y_train, y_test): global acc_lr_tf,f1_lr_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = LogisticRegression() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_lr_tf=accuracy_score(y_test,y_pred) f1_lr_tf=f1_score(y_test,y_pred,average='weighted') print('Time :',time()-t0) print('Accuracy: ',acc_lr_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_lr_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by MultinomialNB def model_nb_tf(x_train, x_test, y_train, y_test): global acc_nb_tf,f1_nb_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = MultinomialNB() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_nb_tf=accuracy_score(y_test,y_pred) f1_nb_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_nb_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_nb_tf # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Decision Tree
def model_dt_tf(x_train, x_test, y_train, y_test): global acc_dt_tf,f1_dt_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = DecisionTreeClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_dt_tf=accuracy_score(y_test,y_pred) f1_dt_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_dt_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_dt_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by KNN def model_knn_tf(x_train, x_test, y_train, y_test): global acc_knn_tf,f1_knn_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = KNeighborsClassifier() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_knn_tf=accuracy_score(y_test,y_pred) f1_knn_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_knn_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Random Forest def model_rf_tf(x_train, x_test, y_train, y_test): global acc_rf_tf,f1_rf_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = RandomForestClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_rf_tf=accuracy_score(y_test,y_pred) f1_rf_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_rf_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Adaptive Boosting def model_ab_tf(x_train, x_test, y_train, y_test): global acc_ab_tf,f1_ab_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = AdaBoostClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_ab_tf=accuracy_score(y_test,y_pred) f1_ab_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_ab_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) تقييم النموذج
تقييم النموذج هو خطوة حاسمة في التعلم الآلي لتقييم أداء وفعالية نموذج مدرب. يتضمن قياس مدى جودة التعميم في النماذج المتعددة للبيانات غير المرئية وما إذا كانت تلبي الأهداف المرجوة. تقييم أداء النموذج المدرب على بيانات الاختبار. احسب مقاييس التقييم مثل الدقة والدقة والتذكر ودرجة F1 لتقييم فعالية النموذج في اكتشاف الإجهاد. يوفر تقييم النموذج رؤى حول نقاط القوة والضعف في النموذج ومدى ملاءمته للمهمة المقصودة.
# Evaluating Models print('********************Logistic Regression*********************')
print('n')
model_lr_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
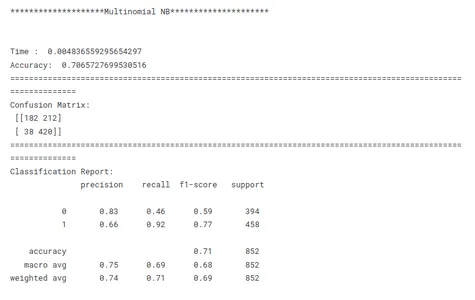
print('********************Multinomial NB*********************')
print('n')
model_nb_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
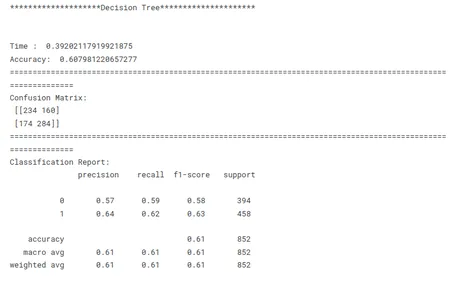
print('********************Decision Tree*********************')
print('n')
model_dt_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
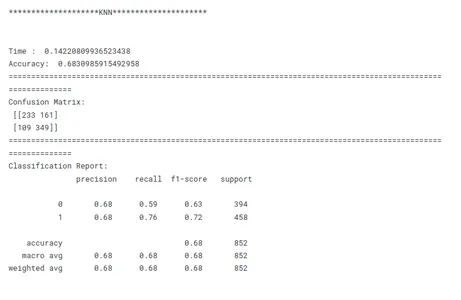
print('********************KNN*********************')
print('n')
model_knn_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
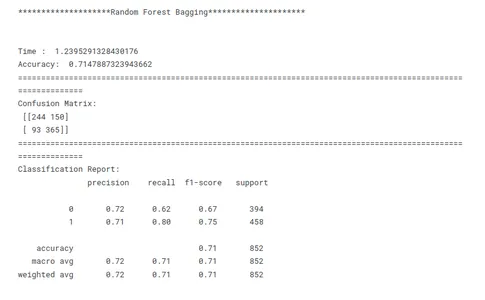
print('********************Random Forest Bagging*********************')
print('n')
model_rf_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
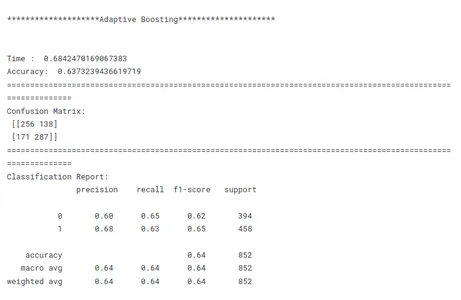
print('********************Adaptive Boosting*********************')
print('n')
model_ab_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')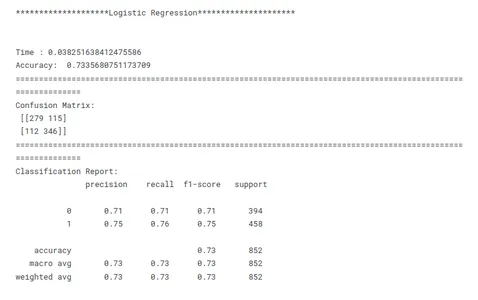
مقارنة أداء النموذج
هذه خطوة حاسمة في التعلم الآلي لتحديد النموذج الأفضل أداءً لمهمة معينة. عند مقارنة النماذج ، من المهم أن يكون لديك هدف واضح في الاعتبار. سواء كان الأمر يتعلق بزيادة الدقة أو تحسين السرعة أو إعطاء الأولوية لقابلية التفسير ، يجب أن تتوافق مقاييس وتقنيات التقييم مع الهدف المحدد.
الاتساق هو المفتاح في مقارنة أداء النموذج. يضمن استخدام مقاييس تقييم متسقة عبر جميع النماذج مقارنة عادلة وذات مغزى. من المهم أيضًا تقسيم البيانات إلى مجموعات تدريب وتحقق واختبار بشكل متسق عبر جميع النماذج. من خلال التأكد من تقييم النماذج على نفس مجموعات البيانات الفرعية ، يتيح الباحثون إجراء مقارنة عادلة لأدائهم.
بالنظر إلى هذه العوامل المذكورة أعلاه ، يمكن للباحثين إجراء مقارنة شاملة وعادلة لأداء النموذج ، والتي ستؤدي إلى قرارات مستنيرة فيما يتعلق باختيار النموذج للمشكلة المحددة المطروحة.
# Creating tabular format for better comparison
tbl=pd.DataFrame()
tbl['Model']=pd.Series(['Logistic Regreesion','Multinomial NB', 'Decision Tree','KNN','Random Forest','Adaptive Boosting'])
tbl['Accuracy']=pd.Series([acc_lr_tf,acc_nb_tf,acc_dt_tf,acc_knn_tf, acc_rf_tf,acc_ab_tf])
tbl['F1_Score']=pd.Series([f1_lr_tf,f1_nb_tf,f1_dt_tf,f1_knn_tf, f1_rf_tf,f1_ab_tf])
tbl.set_index('Model')
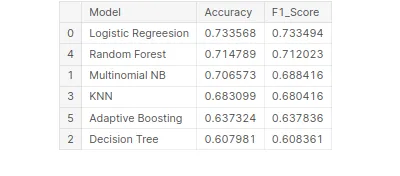
# Best model on the basis of F1 Score
tbl.sort_values('F1_Score',ascending=False)
عبر التحقق من الصحة لتجنب الإفراط في التجهيز
يعد التحقق المتقاطع بالفعل أسلوبًا قيمًا للمساعدة في تجنب التجهيز الزائد عند تدريب نماذج التعلم الآلي. يوفر تقييمًا قويًا لأداء النموذج باستخدام مجموعات فرعية متعددة من البيانات للتدريب والاختبار. يساعد في تقييم قدرة التعميم للنموذج من خلال تقدير أدائه على البيانات غير المرئية.
# Using cross validation method to avoid overfitting
import statistics as st
vector = TfidfVectorizer() x_train_v = vector.fit_transform(x_train)
x_test_v = vector.transform(x_test) # Model building
lr =LogisticRegression()
mnb=MultinomialNB()
dct=DecisionTreeClassifier(random_state=1)
knn=KNeighborsClassifier()
rf=RandomForestClassifier(random_state=1)
ab=AdaBoostClassifier(random_state=1)
m =[lr,mnb,dct,knn,rf,ab]
model_name=['Logistic R','MultiNB','DecTRee','KNN','R forest','Ada Boost'] results, mean_results, p, f1_test=list(),list(),list(),list() #Model fitting,cross-validating and evaluating performance def algor(model): print('n',i) pipe=Pipeline([('model',model)]) pipe.fit(x_train_v,y_train) cv=StratifiedKFold(n_splits=5) n_scores=cross_val_score(pipe,x_train_v,y_train,scoring='f1_weighted', cv=cv,n_jobs=-1,error_score='raise') results.append(n_scores) mean_results.append(st.mean(n_scores)) print('f1-Score(train): mean= (%.3f), min=(%.3f)) ,max= (%.3f), stdev= (%.3f)'%(st.mean(n_scores), min(n_scores), max(n_scores),np.std(n_scores))) y_pred=cross_val_predict(model,x_train_v,y_train,cv=cv) p.append(y_pred) f1=f1_score(y_train,y_pred, average = 'weighted') f1_test.append(f1) print('f1-Score(test): %.4f'%(f1)) for i in m: algor(i) # Model comparison By Visualizing fig=plt.subplots(figsize=(20,15))
plt.title('MODEL EVALUATION BY CROSS VALIDATION METHOD')
plt.xlabel('MODELS')
plt.ylabel('F1 Score')
plt.boxplot(results,labels=model_name,showmeans=True)
plt.show() 
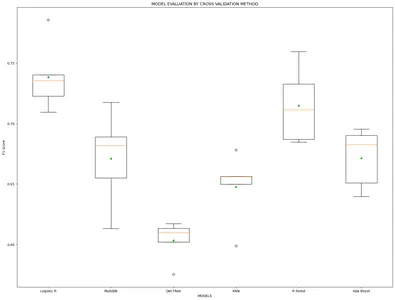
نظرًا لأن نتائج F1 من النماذج تأتي متشابهة تمامًا في كلتا الطريقتين. لذلك نحن الآن نطبق طريقة Leave One Out لبناء النموذج الأفضل أداءً.
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1) vector = TfidfVectorizer()
x_train = vector.fit_transform(x_train)
x_test = vector.transform(x_test)
model_lr_tf=LogisticRegression() model_lr_tf.fit(x_train,y_train)
y_pred=model_lr_tf.predict(x_test)
# Model Evaluation conf=confusion_matrix(y_test,y_pred)
acc_lr=accuracy_score(y_test,y_pred)
f1_lr=f1_score(y_test,y_pred,average='weighted') print('Accuracy: ',acc_lr)
print('F1 Score: ',f1_lr)
print(10*'===========')
print('Confusion Matrix: n',conf)
print(10*'===========')
print('Classification Report: n',classification_report(y_test,y_pred))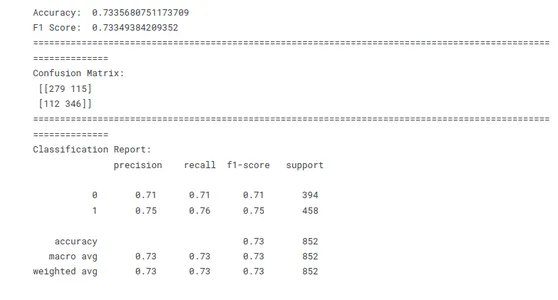
كلمات الغيوم من الكلمات المجهدة وغير المجهدة
تحتوي مجموعة البيانات على رسائل نصية أو مستندات تم تصنيفها على أنها إما مؤكدة أو غير مؤكدة. يتم تكرار الكود عبر التسميتين لإنشاء سحابة كلمات لكل تسمية باستخدام مكتبة WordCloud وعرض تصور سحابة الكلمات. تمثل كل سحابة كلمات الكلمات الأكثر استخدامًا في الفئة المعنية ، مع وجود كلمات أكبر تشير إلى تردد أعلى. يحدد اختيار خريطة الألوان ("الشتاء" ، "الخريف" ، "الصهارة" ، "Viridis" ، "البلازما") نظام الألوان لكلمة السحب. توفر التصورات الناتجة تمثيلًا موجزًا للكلمات الأكثر شيوعًا المرتبطة بالرسائل أو المستندات المجهدة وغير المجهدة.
فيما يلي مجموعة كلمات تمثل كلمات مضغوطة وغير مضغوطة مرتبطة بشكل شائع باكتشاف الإجهاد:
for label, cmap in zip([0,1], ['winter', 'autumn', 'magma', 'viridis', 'plasma']): text = stress.query('label == @label')['text'].str.cat(sep=' ') plt.figure(figsize=(12, 9)) wc = WordCloud(width=1000, height=600, background_color="#f8f8f8", colormap=cmap) wc.generate_from_text(text) plt.imshow(wc) plt.axis("off") plt.title(f"Words Commonly Used in ${label}$ Messages", size=20) plt.show()

تنبؤ
تتم معالجة بيانات الإدخال الجديدة مسبقًا ويتم استخراج الميزات لتتناسب مع توقعات النموذج. ثم يتم استخدام وظيفة التنبؤ لإنشاء تنبؤات بناءً على الميزات المستخرجة. أخيرًا ، تتم طباعة التنبؤات أو استخدامها على النحو المطلوب لمزيد من التحليل أو اتخاذ القرار.
data=["""I don't have the ability to cope with it anymore. I'm trying, but a lot of things are triggering me, and I'm shutting down at work, just finding the place I feel safest, and staying there for an hour or two until I feel like I can do something again. I'm tired of watching my back, tired of traveling to places I don't feel safe, tired of reliving that moment, tired of being triggered, tired of the stress, tired of anxiety and knots in my stomach, tired of irrational thought when triggered, tired of irrational paranoia. I'm exhausted and need a break, but know it won't be enough until I journey the long road through therapy. I'm not suicidal at all, just wishing this pain and misery would end, to have my life back again."""] data=vector.transform(data)
model_lr_tf.predict(data)
data=["""In case this is the first time you're reading this post... We are looking for people who are willing to complete some online questionnaires about employment and well-being which we hope will help us to improve services for assisting people with mental health difficulties to obtain and retain employment. We are developing an employment questionnaire for people with personality disorders; however we are looking for people from all backgrounds to complete it. That means you do not need to have a diagnosis of personality disorder – you just need to have an interest in completing the online questionnaires. The questionnaires will only take about 10 minutes to complete online. For your participation, we’ll donate £1 on your behalf to a mental health charity (Young Minds: Child & Adolescent Mental Health, Mental Health Foundation, or Rethink)"""] data=vector.transform(data)
model_lr_tf.predict(data)
وفي الختام
يوفر تطبيق تقنيات التعلم الآلي في التنبؤ بمستويات التوتر رؤى شخصية للرفاهية العقلية. من خلال تحليل مجموعة متنوعة من العوامل مثل القياسات العددية (ضغط الدم ومعدل ضربات القلب) والخصائص الفئوية (مثل الجنس والوظيفة) ، يمكن لنماذج التعلم الآلي أن تتعلم الأنماط وتضع تنبؤات على مستوى الإجهاد الفردي. من خلال القدرة على اكتشاف مستويات التوتر ومراقبتها بدقة ، يساهم التعلم الآلي في تطوير استراتيجيات وتدخلات استباقية لإدارة وتعزيز الرفاهية العقلية.
استكشفنا الرؤى من استخدام التعلم الآلي في التنبؤ بالإجهاد وقدرته على إحداث ثورة في نهجنا لمعالجة هذه المشكلة الحرجة.
- تنبؤات دقيقة: تحلل خوارزميات التعلم الآلي كميات هائلة من البيانات التاريخية للتنبؤ بدقة بحدوث الإجهاد ، مما يوفر رؤى وتوقعات قيمة.
- كشف مبكر: يمكن للتعلم الآلي اكتشاف العلامات التحذيرية في وقت مبكر ، مما يسمح باتخاذ تدابير استباقية والدعم في الوقت المناسب في المناطق المعرضة للخطر.
- تحسين التخطيط وتخصيص الموارد: يتيح التعلم الآلي إمكانية التنبؤ بالنقاط الساخنة والكثافة ، وتحسين تخصيص الموارد مثل خدمات الطوارئ والمرافق الطبية.
- تحسين السلامة العامة: تمكّن التنبيهات والتحذيرات في الوقت المناسب الصادرة من خلال تنبؤات التعلم الآلي الأفراد من اتخاذ الاحتياطات اللازمة ، والحد من تأثير التحذير وتعزيز السلامة العامة.
في الختام ، يوفر تحليل التنبؤ بالإجهاد هذا رؤى قيمة حول مستويات الإجهاد والتنبؤ بها باستخدام التعلم الآلي. استخدم النتائج لتطوير الأدوات والتدخلات لإدارة الإجهاد ، وتعزيز الرفاهية العامة وتحسين نوعية الحياة.
الأسئلة المتكررة
ج: 1. تقييم موضوعي: يوفر نهجًا موضوعيًا يعتمد على البيانات لتقييم مستويات الإجهاد ، والقضاء على التحيزات المحتملة التي قد تنشأ في التقييمات الذاتية.
2. التدرجية: يمكن لخوارزميات التعلم الآلي معالجة كميات كبيرة من البيانات النصية بكفاءة ، مما يجعلها قابلة للتطوير لتحليل مجموعة واسعة من التعبيرات النصية.
3. رصد في الوقت الحقيقي: من خلال أتمتة الكشف عن الإجهاد ، فإنه يتيح المراقبة في الوقت الفعلي لمستويات التوتر ، مما يسمح بالتدخلات والدعم في الوقت المناسب.
4. الرؤى والبحوث: يمكن أن يكشف عن الرؤى والاتجاهات المتعلقة بالإجهاد ، مما يساهم في فهم مسببات الإجهاد والتأثيرات والتدخلات المحتملة.
ج: 1. منشورات مواقع التواصل الاجتماعي: محتوى نصي من منصات مثل Twitter أو Facebook أو المنتديات عبر الإنترنت حيث يعبر الأفراد عن أفكارهم وعواطفهم.
2. سجلات الدردشة: بيانات المحادثة من تطبيقات المراسلة أو أنظمة الدعم عبر الإنترنت أو برامج الدردشة الخاصة بالصحة العقلية.
3. الاستطلاعات أو الاستبيانات عبر الإنترنت: الردود النصية على الأسئلة المتعلقة بالتوتر أو الصحة العقلية.
4. السجلات الصحية الإلكترونية: الملاحظات السريرية أو روايات المرضى التي تحتوي على معلومات ذات صلة بالتجارب المرتبطة بالتوتر.
ج: 1. يمكن أن تختلف التعبيرات النصية للتوتر اختلافًا كبيرًا بين الأفراد ، مما يجعل من الصعب التقاط جميع المؤشرات والأنماط ذات الصلة.
2. يعد فهم السياق أمرًا بالغ الأهمية في اكتشاف الإجهاد ، حيث يمكن قراءة نفس النص بشكل مختلف اعتمادًا على السياق والفرد.
3. يمكن أن يكون الحصول على البيانات المصنفة لتدريب نماذج التعلم الآلي مستهلكًا للوقت ويستهلك الكثير من الموارد ، ويتطلب مدخلات من الخبراء أو أحكامًا ذاتية.
4. يعد ضمان خصوصية البيانات والسرية والمعالجة الأخلاقية لمعلومات الصحة العقلية الحساسة أمرًا بالغ الأهمية عند التعامل مع البيانات النصية المتعلقة بالتوتر.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- تمويل EVM. واجهة موحدة للتمويل اللامركزي. الوصول هنا.
- مجموعة كوانتوم ميديا. تضخيم IR / PR. الوصول هنا.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/06/machine-learning-unlocks-insights-for-stress-detection/

