عند تشغيل تطبيقات Apache Flink خدمة أمازون المُدارة لـ Apache Flink، لديك الميزة الفريدة المتمثلة في الاستفادة من طبيعتها التي لا تحتوي على خادم. وهذا يعني أن عمليات تحسين التكلفة يمكن أن تتم في أي وقت، ولم تعد هناك حاجة إلى إجرائها في مرحلة التخطيط. باستخدام الخدمة المُدارة لـ Apache Flink، يمكنك إضافة الحوسبة وإزالتها بنقرة زر واحدة.
Apache Flink هو إطار عمل مفتوح المصدر لمعالجة التدفق تستخدمه مئات الشركات في تطبيقات الأعمال المهمة، ويستخدمه آلاف المطورين الذين لديهم احتياجات معالجة التدفق لأعباء العمل الخاصة بهم. إنه متوفر بدرجة كبيرة وقابل للتطوير، ويوفر إنتاجية عالية وزمن وصول منخفض لتطبيقات معالجة التدفق الأكثر تطلبًا. يمكن أن تكون هذه الخصائص القابلة للتطوير لـ Apache Flink أساسية لتحسين التكلفة في السحابة.
الخدمة المُدارة لـ Apache Flink هي خدمة مُدارة بالكامل تقلل من تعقيد إنشاء تطبيقات Apache Flink وإدارتها. تدير الخدمة المُدارة لـ Apache Flink البنية التحتية الأساسية ومكونات Apache Flink التي توفر حالة تطبيق متينة ومقاييس وسجلات والمزيد.
في هذا المنشور، يمكنك التعرف على نموذج تكلفة الخدمة المُدارة لـ Apache Flink، والمناطق التي يمكنك توفير التكلفة فيها في تطبيقات Apache Flink، والحصول بشكل عام على فهم أفضل لخطوط معالجة البيانات الخاصة بك. نحن نتعمق في فهم تكاليفك، وفهم ما إذا كان تطبيقك مزودًا بشكل زائد، وكيفية التفكير في التوسع تلقائيًا، وطرق تحسين تطبيقات Apache Flink الخاصة بك لتوفير التكلفة. وأخيرًا، نطرح أسئلة مهمة حول عبء العمل الخاص بك لتحديد ما إذا كانت Apache Flink هي التقنية المناسبة لحالة الاستخدام الخاصة بك.
كيفية حساب التكاليف على الخدمة المُدارة لـ Apache Flink
لتحسين التكاليف فيما يتعلق بالخدمة المُدارة لتطبيق Apache Flink، قد يكون من المفيد الحصول على فكرة جيدة عما يدور في تسعير الخدمة المُدارة.
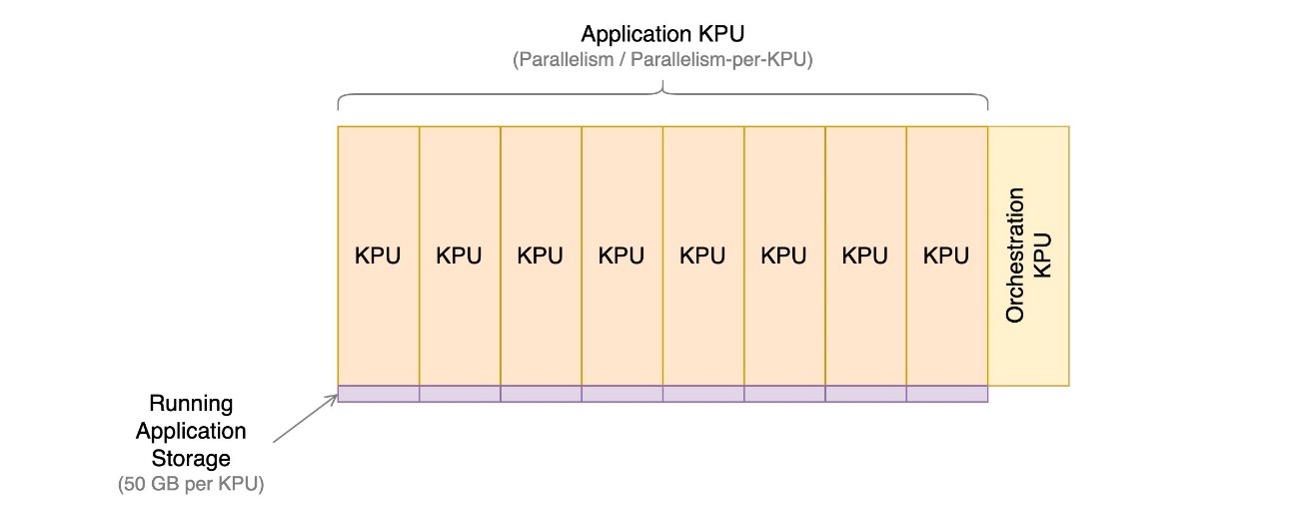
تتكون الخدمة المُدارة لتطبيقات Apache Flink من وحدات معالجة Kinesis (KPUs)، وهي عبارة عن مثيلات حسابية تتكون من وحدة معالجة مركزية افتراضية واحدة وذاكرة سعة 1 جيجابايت. يتم تحديد العدد الإجمالي لوحدات KPU المعينة للتطبيق عن طريق ضرب معلمتين تتحكم فيهما مباشرة:
- تماثل – مستوى المعالجة المتوازية في تطبيق Apache Flink
- التوازي لكل KPU – عدد الموارد المخصصة لكل موازية
يتم تحديد عدد وحدات KPU بواسطة صيغة بسيطة: KPU = Parallelism / ParallelismPerKPU، مقربًا إلى العدد الصحيح التالي.
يتم أيضًا فرض رسوم إضافية على KPU لكل تطبيق مقابل التنسيق ولا يتم استخدامها مباشرة لمعالجة البيانات.
يحدد العدد الإجمالي لوحدات KPU عدد الموارد ووحدة المعالجة المركزية والذاكرة وتخزين التطبيقات المخصصة للتطبيق. بالنسبة لكل وحدة KPU، يتلقى التطبيق وحدة معالجة مركزية افتراضية واحدة و1 جيجابايت من الذاكرة، منها 4 جيجابايت يتم تخصيصها افتراضيًا للتطبيق قيد التشغيل ويتم استخدام 3 جيجابايت المتبقية لإدارة مخزن حالة التطبيق. تأتي كل وحدة KPU أيضًا مع مساحة تخزين تبلغ 1 جيجابايت مرفقة بالتطبيق. يحتفظ Apache Flink بحالة التطبيق في الذاكرة إلى حد قابل للتكوين، ويمتد إلى وحدة التخزين المرفقة.
عنصر التكلفة الثالث هو النسخ الاحتياطية الدائمة للتطبيقات، أو لقطات. يعد هذا أمرًا اختياريًا تمامًا وتأثيره على التكلفة الإجمالية صغير، إلا إذا احتفظت بعدد كبير جدًا من اللقطات.
في وقت كتابة هذا التقرير، كانت تكلفة كل وحدة KPU في منطقة AWS شرق الولايات المتحدة (أوهايو) 0.11 USD في الساعة، وتكلفة تخزين التطبيقات المرفقة 0.10 USD لكل جيجابايت شهريًا. تبلغ تكلفة النسخ الاحتياطي الدائم للتطبيقات (اللقطات) 0.023 USD لكل جيجابايت شهريًا. تشير إلى خدمة أمازون المُدارة لتسعير Apache Flink للحصول على أحدث الأسعار والمناطق المختلفة.
يوضح الرسم البياني التالي النسب النسبية لمكونات التكلفة لتطبيق قيد التشغيل على Managed Service لـ Apache Flink. يمكنك التحكم في عدد وحدات KPU عبر التوازي والتوازي لكل معلمات KPU. لا يتم تمثيل وحدة تخزين النسخ الاحتياطي للتطبيقات الدائمة.
في الأقسام التالية، سنفحص كيفية مراقبة تكاليفك، وتحسين استخدام موارد التطبيق، والعثور على العدد المطلوب من وحدات KPU للتعامل مع ملف تعريف الإنتاجية الخاص بك.
AWS Cost Explorer وفهم فاتورتك
لمعرفة ما تنفقه الخدمة المُدارة الحالية لـ Apache Flink، يمكنك استخدامها مستكشف تكلفة AWS.
في وحدة تحكم Cost Explorer، يمكنك التصفية حسب النطاق الزمني ونوع الاستخدام والخدمة لعزل إنفاقك على الخدمة المُدارة لتطبيقات Apache Flink. تعرض لقطة الشاشة التالية تكلفة الـ 12 شهرًا الماضية مقسمة إلى فئات الأسعار الموضحة في القسم السابق. كانت غالبية الإنفاق في العديد من هذه الأشهر من وحدات KPU التفاعلية من خدمة أمازون المُدارة لـ Apache Flink Studio.
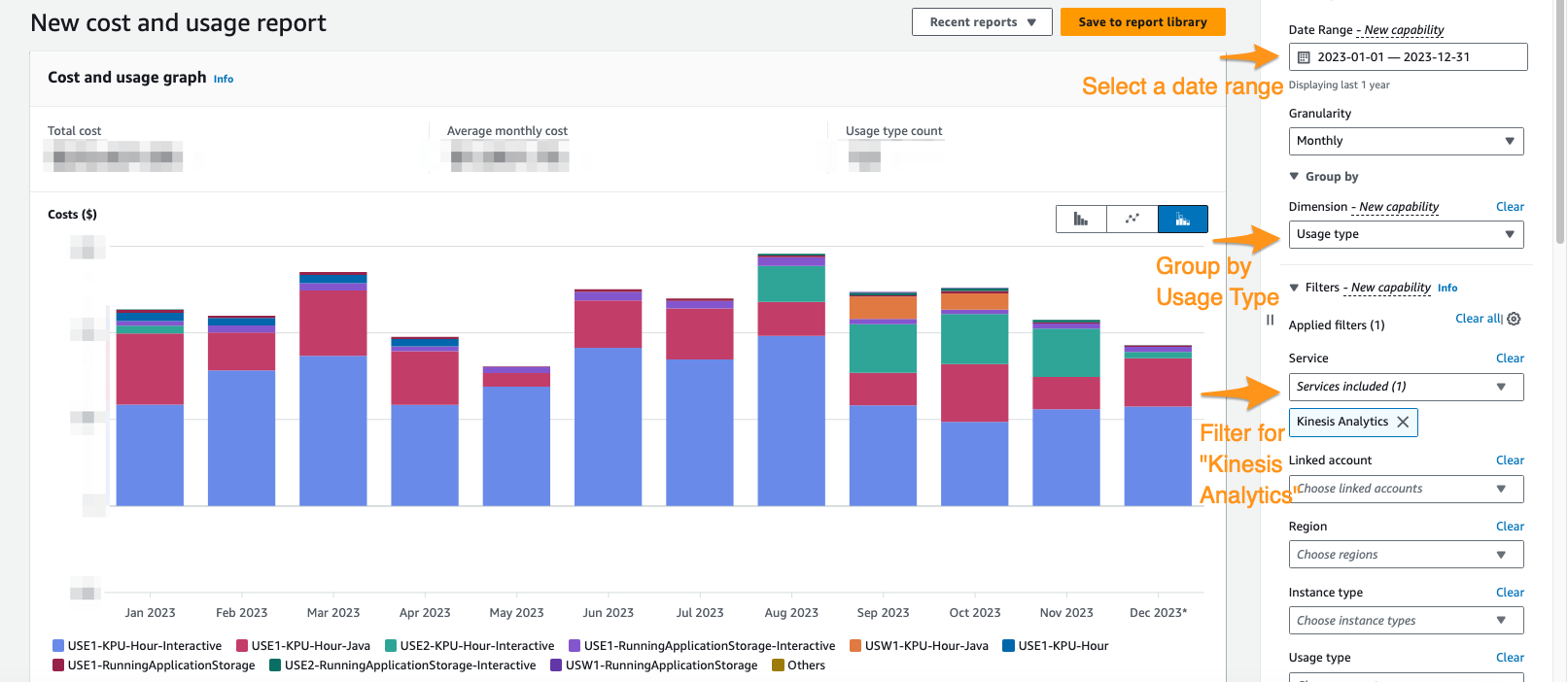
لا يمكن أن يساعدك استخدام Cost Explorer في فهم فاتورتك فحسب، بل يساعد أيضًا في تحسين تطبيقات معينة ربما تكون قد تجاوزت التوقعات تلقائيًا أو بسبب متطلبات الإنتاجية. ومن خلال وضع علامات مناسبة على التطبيقات، يمكنك أيضًا تقسيم هذا الإنفاق حسب التطبيق لمعرفة التطبيقات التي تتحمل التكلفة.
علامات الإفراط في التزويد أو الاستخدام غير الفعال للموارد
لتقليل التكاليف المرتبطة بالخدمة المُدارة لتطبيقات Apache Flink، يتضمن الأسلوب المباشر تقليل عدد وحدات KPU التي تستخدمها تطبيقاتك. ومع ذلك، من المهم أن ندرك أن هذا التخفيض قد يؤثر سلبًا على الأداء إذا لم يتم تقييمه واختباره بشكل شامل. لقياس ما إذا كانت تطبيقاتك قد تم توفيرها بشكل زائد بسرعة، قم بفحص المؤشرات الرئيسية مثل استخدام وحدة المعالجة المركزية والذاكرة ووظائف التطبيق وتوزيع البيانات. ومع ذلك، على الرغم من أن هذه المؤشرات يمكن أن تشير إلى زيادة محتملة في التزويد، فمن الضروري إجراء اختبار الأداء والتحقق من صحة أنماط القياس قبل إجراء أي تعديلات على عدد وحدات KPU.
المقاييس
تحليل مقاييس لتطبيقك on الأمازون CloudWatch يمكن أن يكشف عن إشارات واضحة للإفراط في التزويد. إذا containerCPUUtilization و containerMemoryUtilization تظل المقاييس باستمرار أقل من 20% خلال فترة ذات دلالة إحصائية لأنماط حركة مرور تطبيقك، فقد يكون من الممكن تقليص حجمها وتخصيص المزيد من البيانات لعدد أقل من الأجهزة. بشكل عام، نحن نعتبر التطبيقات ذات الحجم المناسب عندما containerCPUUtilization تتراوح بين 50-75%. بالرغم من containerMemoryUtilization يمكن أن تتقلب على مدار اليوم وتتأثر بتحسين التعليمات البرمجية، وقد تشير القيمة المنخفضة باستمرار لمدة طويلة إلى زيادة محتملة في التزويد.
التوازي في KPU غير مستغل بشكل كافٍ
هناك علامة خفية أخرى تشير إلى أن تطبيقك يتم توفيره بشكل زائد وهو إذا كان تطبيقك مرتبطًا تمامًا بالإدخال/الإخراج، أو يقوم فقط باستدعاءات بسيطة لقواعد البيانات والعمليات غير المكثفة لوحدة المعالجة المركزية. إذا كانت هذه هي الحالة، فيمكنك استخدام التوازي لكل معلمة KPU داخل Managed Service لـ Apache Flink لتحميل المزيد من المهام على وحدة معالجة واحدة.
يمكنك عرض التوازي لكل معلمة KPU كمقياس لكثافة عبء العمل لكل وحدة من موارد الحساب والذاكرة (KPU). زيادة التوازي لكل وحدة KPU أعلى من القيمة الافتراضية 1 تجعل المعالجة أكثر كثافة، وتخصيص المزيد من العمليات المتوازية على وحدة KPU واحدة.
يوضح الرسم البياني التالي كيف أنه من خلال الحفاظ على ثبات توازي التطبيق (على سبيل المثال، 4) وزيادة التوازي لكل وحدة KPU (على سبيل المثال، من 1 إلى 2)، يستخدم تطبيقك موارد أقل بنفس مستوى التشغيل المتوازي.
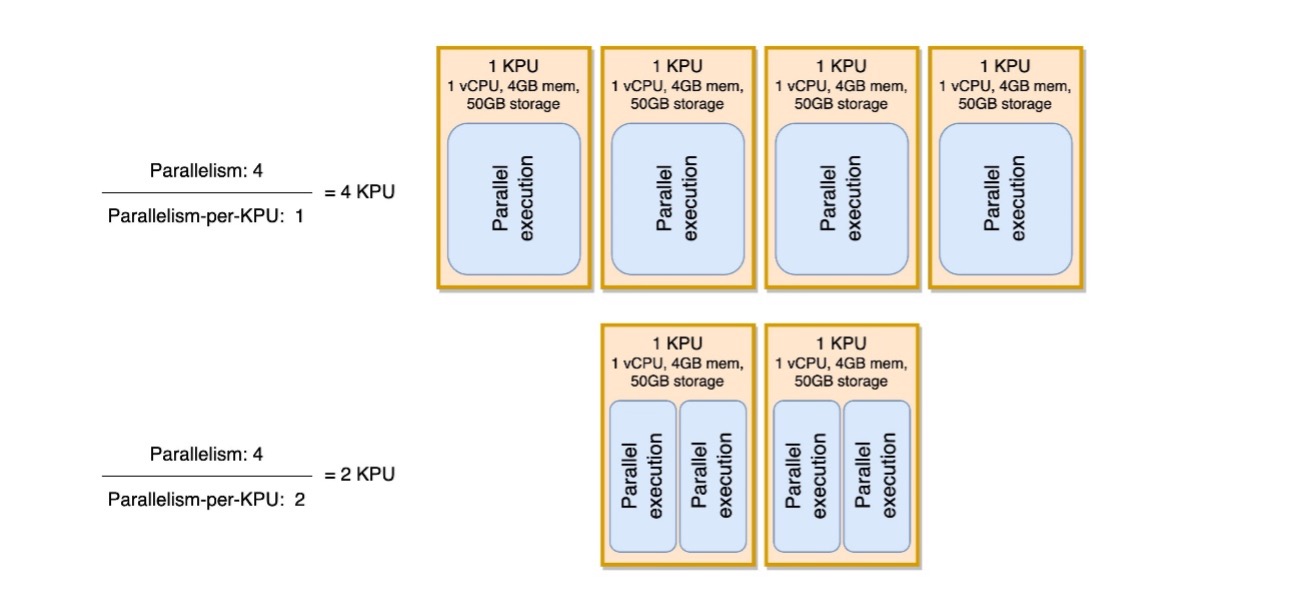
ينبغي اتخاذ قرار زيادة التوازي لكل وحدة KPU، مثل جميع التوصيات الواردة في هذا المنشور، بحذر شديد. يمكن أن تؤدي زيادة التوازي لكل قيمة KPU إلى زيادة العبء على وحدة KPU واحدة، ويجب أن تكون على استعداد لتحمل هذا الحمل. لن تؤدي العمليات المرتبطة بالإدخال/الإخراج إلى زيادة استخدام وحدة المعالجة المركزية أو الذاكرة بأي طريقة ذات معنى، ولكن وظيفة العملية التي تحسب العديد من العمليات المعقدة مقابل البيانات لن تكون عملية مثالية لمقارنتها بوحدة KPU واحدة، لأنها قد تطغى على الموارد. اختبار الأداء وتقييم ما إذا كان هذا خيارًا جيدًا لتطبيقاتك.
كيفية التعامل مع الحجم
قبل أن تقوم بإعداد خدمة مُدارة لتطبيق Apache Flink، قد يكون من الصعب تقدير عدد وحدات KPU التي يجب عليك تخصيصها لتطبيقك. بشكل عام، يجب أن يكون لديك فكرة جيدة عن أنماط حركة المرور الخاصة بك قبل إجراء التقدير. يمكن أن يساعدك فهم أنماط حركة المرور الخاصة بك على أساس معدل الاستيعاب بالميغابايت في الثانية في تقريب نقطة البداية.
كقاعدة عامة، يمكنك البدء بوحدة KPU واحدة لكل 1 ميجابايت/ثانية والتي سيعالجها طلبك. على سبيل المثال، إذا كان تطبيقك يعالج 10 ميجابايت/ثانية (في المتوسط)، فستخصص 10 وحدات KPU كنقطة بداية لتطبيقك. ضع في اعتبارك أن هذا تقدير تقريبي عالي المستوى للغاية وقد رأينا فعاليته بالنسبة للتقدير العام. ومع ذلك، تحتاج أيضًا إلى اختبار الأداء وتقييم ما إذا كان هذا الحجم مناسبًا على المدى الطويل أم لا بناءً على المقاييس (وحدة المعالجة المركزية، والذاكرة، وزمن الوصول، والأداء الوظيفي الإجمالي) على مدى فترة طويلة من الزمن.
للعثور على الحجم المناسب لتطبيقك، تحتاج إلى توسيع نطاق تطبيق Apache Flink لأعلى ولأسفل. كما ذكرنا سابقًا، في Managed Service for Apache Flink، لديك عنصري تحكم منفصلين: التوازي والتوازي لكل وحدة KPU. تحدد هذه المعلمات معًا مستوى المعالجة المتوازية داخل التطبيق وموارد الحوسبة والذاكرة والتخزين الإجمالية المتاحة.
تتمثل منهجية الاختبار الموصى بها في تغيير التوازي أو التوازي لكل وحدة KPU بشكل منفصل، أثناء التجربة للعثور على الحجم المناسب. بشكل عام، قم فقط بتغيير التوازي لكل وحدة KPU لزيادة عدد العمليات المرتبطة بالإدخال/الإخراج المتوازية، دون زيادة إجمالي الموارد. بالنسبة لجميع الحالات الأخرى، قم فقط بتغيير التوازي — ستتغير KPU تبعًا لذلك — للعثور على الحجم المناسب لعبء العمل الخاص بك.
بامكانك ايضا ضبط التوازي على مستوى المشغل لتقييد المصادر أو المصارف أو أي مشغل آخر قد يحتاج إلى تقييد ومستقل عن آليات القياس. يمكنك استخدام هذا لتطبيق Apache Flink الذي يقرأ من موضوع Apache Kafka الذي يحتوي على 10 أقسام. مع ال setParallelism() الطريقة، يمكنك تقييد KafkaSource بـ 10، ولكن يمكنك توسيع نطاق الخدمة المُدارة لتطبيق Apache Flink إلى توازي أعلى من 10 دون إنشاء مهام خاملة لمصدر Kafka. يوصى لحالات معالجة البيانات الأخرى بعدم تعيين توازي عامل التشغيل بشكل ثابت على قيمة ثابتة، بل وظيفة توازي التطبيق بحيث يتم قياسه عند قياس التطبيق الإجمالي.
التحجيم والتحجيم التلقائي
في Managed Service for Apache Flink، يعد تعديل التوازي أو التوازي لكل KPU تحديثًا لتكوين التطبيق. يؤدي إلى أن يأخذ التطبيق تلقائيًا ملف لقطة (ما لم يتم تعطيله)، قم بإيقاف التطبيق، وأعد تشغيله بالحجم الجديد، واستعادة الحالة من اللقطة. لا تتسبب عمليات القياس في فقدان البيانات أو عدم تناسقها، ولكنها تؤدي إلى إيقاف معالجة البيانات مؤقتًا لفترة قصيرة من الوقت أثناء إضافة البنية التحتية أو إزالتها. هذا شيء يجب عليك مراعاته عند إعادة القياس في بيئة الإنتاج.
أثناء عملية الاختبار والتحسين، نوصي بالتعطيل التحجيم التلقائي وتعديل التوازي والتوازي لكل KPU للعثور على القيم المثلى. كما ذكرنا سابقًا، يعد القياس اليدوي مجرد تحديث لتكوين التطبيق، ويمكن تشغيله عبر وحدة تحكم إدارة AWS أو API مع إجراء تحديث التطبيق.
عندما تجد الحجم الأمثل، إذا كنت تتوقع أن يختلف معدل النقل الذي تم استيعابه بشكل كبير، فقد تقرر تمكين القياس التلقائي.
في الخدمة المُدارة لـ Apache Flink، يمكنك استخدام أنواع متعددة من القياس التلقائي:
- القياس التلقائي خارج الصندوق – يمكنك تمكين هذا من ضبط توازي التطبيق تلقائيًا بناءً على
containerCPUUtilizationقياس. يتم تمكين القياس التلقائي بشكل افتراضي في التطبيقات الجديدة. للحصول على تفاصيل حول خوارزمية القياس التلقائي، راجع تحجيم تلقائي. - مقياس تلقائي دقيق الحبيبات يعتمد على القياس - وهذا أمر سهل التنفيذ. يمكن أن تعتمد الأتمتة على أي مقاييس تقريبًا، بما في ذلك المقاييس المخصصة يعرض التطبيق الخاص بك.
- التحجيم المقرر – قد يكون هذا مفيدًا إذا كنت تتوقع ذروة عبء العمل في أوقات معينة من اليوم أو أيام الأسبوع.
يعد القياس التلقائي الجاهز والقياس القائم على القياس الدقيق متعارضين. لمزيد من التفاصيل حول القياس التلقائي المستند إلى المقاييس الدقيقة والقياس المجدول، ومثال التعليمات البرمجية العامل بالكامل، راجع تمكين القياس المجدول والمعتمد على المقاييس لخدمة Amazon Managed Service لـ Apache Flink.
تحسينات التعليمات البرمجية
هناك طريقة أخرى لتحقيق وفورات في تكاليف الخدمة المُدارة لتطبيقات Apache Flink وهي من خلال تحسين التعليمات البرمجية. سوف تتطلب التعليمات البرمجية غير المحسنة المزيد من الأجهزة لإجراء نفس الحسابات. يمكن أن يسمح تحسين الكود بتقليل الاستخدام الإجمالي للموارد، وهو ما قد يسمح بدوره بتقليص حجمه وتوفير التكاليف وفقًا لذلك.
الخطوة الأولى لفهم أداء التعليمات البرمجية الخاصة بك هي من خلال الأداة المساعدة المضمنة في Apache Flink والتي تسمى الرسوم البيانية اللهب.
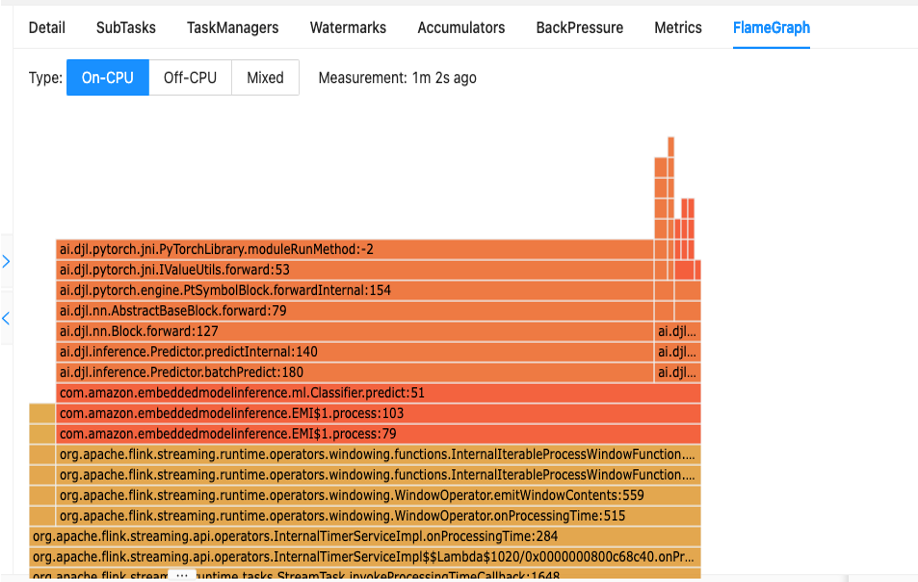
تمنحك Flame Graphs، والتي يمكن الوصول إليها عبر لوحة معلومات Apache Flink، تمثيلاً مرئيًا لتتبع المكدس الخاص بك. في كل مرة يتم فيها استدعاء أسلوب، يصبح الشريط الذي يمثل استدعاء هذا الأسلوب في تتبع المكدس أكبر بما يتناسب مع إجمالي عدد العينات. هذا يعني أنه إذا كان لديك جزء غير فعال من التعليمات البرمجية مع شريط طويل جدًا في الرسم البياني اللهب، فقد يكون هذا سببًا للبحث عن كيفية جعل هذا الرمز أكثر كفاءة. بالإضافة إلى ذلك، يمكنك استخدام ملف تعريف Amazon CodeGuru إلى مراقبة وتحسين تطبيقات Apache Flink التي تعمل على الخدمة المُدارة لـ Apache Flink.
عند تصميم تطبيقاتك، يوصى باستخدام واجهة برمجة التطبيقات ذات المستوى الأعلى المطلوبة لعملية معينة في وقت معين. يقدم Apache Flink أربعة مستويات من دعم واجهة برمجة التطبيقات: Flink SQL، وTable API، Datastream API و ProcessFunction واجهات برمجة التطبيقات، مع مستويات متزايدة من التعقيد والمسؤولية. إذا كان من الممكن كتابة تطبيقك بالكامل في Flink SQL أو Table API، فإن استخدام ذلك يمكن أن يساعد في الاستفادة من إطار عمل Apache Flink بدلاً من إدارة الحالة والحسابات يدويًا.
انحراف البيانات
في لوحة معلومات Apache Flink، يمكنك جمع معلومات مفيدة أخرى حول الخدمة المُدارة الخاصة بمهام Apache Flink.
على لوحة المعلومات، يمكنك فحص المهام الفردية ضمن الرسم البياني لطلب الوظيفة الخاص بك. يمثل كل مربع أزرق مهمة، وتتكون كل مهمة من مهام فرعية، أو وحدات عمل موزعة لتلك المهمة. يمكنك تحديد انحراف البيانات بين المهام الفرعية بهذه الطريقة.
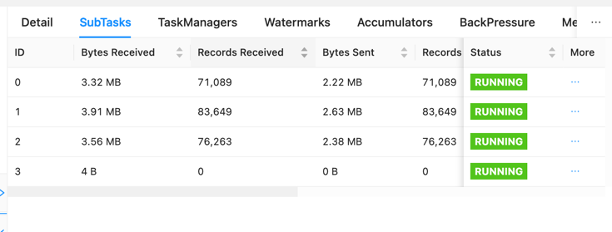
يعد انحراف البيانات مؤشرًا على أنه يتم إرسال المزيد من البيانات إلى مهمة فرعية واحدة أكثر من أخرى، وأن المهمة الفرعية التي تتلقى المزيد من البيانات تقوم بعمل أكثر من الأخرى. إذا كانت لديك أعراض انحراف البيانات هذه، فيمكنك العمل على إزالتها عن طريق تحديد المصدر. على سبيل المثال، أ GroupBy or KeyedStream يمكن أن يكون هناك انحراف في المفتاح. وهذا يعني أن البيانات لا يتم توزيعها بالتساوي بين المفاتيح، مما يؤدي إلى توزيع غير متساوي للعمل عبر مثيلات حساب Apache Flink. تخيل سيناريو حيث يتم التجميع حسب userId، لكن تطبيقك يتلقى بيانات من مستخدم واحد أكثر بكثير من البقية. يمكن أن يؤدي هذا إلى انحراف البيانات. للتخلص من ذلك، يمكنك اختيار مفتاح تجميع مختلف لتوزيع البيانات بالتساوي عبر المهام الفرعية. ضع في اعتبارك أن هذا سيتطلب تعديل الكود لاختيار مفتاح مختلف.
عندما يتم التخلص من انحراف البيانات، يمكنك العودة إلى containerCPUUtilization و containerMemoryUtilization مقاييس لتقليل عدد وحدات KPU.
تتضمن المجالات الأخرى لتحسين التعليمات البرمجية التأكد من وصولك إلى الأنظمة الخارجية عبر واجهة برمجة تطبيقات الإدخال/الإخراج غير المتزامنة أو عبر الانضمام إلى دفق البيانات، لأن الاستعلام المتزامن الصادر إلى مخزن البيانات يمكن أن يؤدي إلى حدوث تباطؤ ومشكلات في نقاط التفتيش. بالإضافة إلى ذلك، راجع استكشاف أخطاء الأداء وإصلاحها للمشكلات التي قد تواجهها مع نقاط التفتيش أو التسجيل البطيء، والتي يمكن أن تسبب ضغطًا رجعيًا على التطبيق.
كيفية تحديد ما إذا كانت Apache Flink هي التقنية المناسبة أم لا
إذا كان تطبيقك لا يستخدم أيًا من الإمكانات القوية الموجودة في إطار عمل Apache Flink والخدمة المُدارة لـ Apache Flink، فمن المحتمل أن تتمكن من توفير التكلفة باستخدام شيء أكثر بساطة.
شعار Apache Flink هو "الحسابات الحالة عبر تدفقات البيانات". الحالة، في هذا السياق، تعني أنك تستخدم بنية حالة Apache Flink. تتيح لك الحالة، في Apache Flink، تذكر الرسائل التي شاهدتها في الماضي لفترات زمنية أطول، مما يجعل أشياء مثل عمليات الانضمام المتدفقة، وإلغاء البيانات المكررة، والمعالجة لمرة واحدة بالضبط، والنوافذ، والتعامل مع البيانات المتأخرة ممكنة. ويتم ذلك عن طريق استخدام مخزن الحالة في الذاكرة. في الخدمة المُدارة لـ Apache Flink، فإنه يستخدم RocksDB للحفاظ على حالتها.
إذا كان تطبيقك لا يتضمن عمليات ذات حالة، فيمكنك التفكير في بدائل مثل AWS لامداأو التطبيقات المعبأة في حاويات أو الأمازون الحوسبة المرنة السحابية (Amazon EC2) يقوم بتشغيل التطبيق الخاص بك. قد لا يكون تعقيد Apache Flink ضروريًا في مثل هذه الحالات. قد تضمن الحسابات ذات الحالة، بما في ذلك البيانات المخزنة مؤقتًا أو إجراءات الإثراء التي تتطلب ذاكرة مستقلة لموضع الدفق، إمكانات Apache Flink ذات الحالة. إذا كان هناك احتمال أن يصبح تطبيقك ذا حالة في المستقبل، سواء من خلال الاحتفاظ بالبيانات لفترات طويلة أو متطلبات أخرى ذات حالة، فقد يكون الاستمرار في استخدام Apache Flink أكثر وضوحًا. قد تفضل المؤسسات التي تركز على Apache Flink لقدرات معالجة التدفق الاستمرار في استخدام Apache Flink للتطبيقات ذات الحالة وعديمة الحالة، بحيث تقوم جميع تطبيقاتها بمعالجة البيانات بنفس الطريقة. يجب عليك أيضًا مراعاة ميزات التنسيق الخاصة به مثل المعالجة لمرة واحدة بالضبط، وإمكانيات التوزيع، والحساب الموزع قبل الانتقال من Apache Flink إلى البدائل.
هناك اعتبار آخر وهو متطلبات الكمون الخاصة بك. نظرًا لأن Apache Flink يتفوق في معالجة البيانات في الوقت الفعلي، فإن استخدامه لتطبيق بمتطلبات زمن الوصول لمدة 6 ساعات أو يوم واحد ليس له معنى. توفير التكاليف عن طريق التحول إلى عملية دفعية مؤقتة خدمة تخزين أمازون البسيطة (Amazon S3)، على سبيل المثال، سيكون ذا أهمية كبيرة.
وفي الختام
في هذا المنشور، قمنا بتغطية بعض الجوانب التي يجب مراعاتها عند محاولة اتخاذ تدابير لتوفير التكاليف للخدمة المُدارة لـ Apache Flink. لقد ناقشنا كيفية تحديد إنفاقك الإجمالي على الخدمة المُدارة، وبعض المقاييس المفيدة التي يجب مراقبتها عند تقليص وحدات KPU الخاصة بك، وكيفية تحسين التعليمات البرمجية الخاصة بك لتقليص حجمها، وكيفية تحديد ما إذا كان Apache Flink مناسبًا لحالة الاستخدام الخاصة بك.
إن تنفيذ إستراتيجيات توفير التكلفة هذه لا يؤدي فقط إلى تحسين كفاءة التكلفة، ولكنه يوفر أيضًا نشرًا مبسطًا ومحسنًا لـ Apache Flink. ومن خلال الانتباه إلى إجمالي إنفاقك، واستخدام المقاييس الرئيسية، واتخاذ قرارات مستنيرة بشأن تقليص الموارد، يمكنك تحقيق عملية فعالة من حيث التكلفة دون المساس بالأداء. أثناء تنقلك في مشهد Apache Flink، يصبح التقييم المستمر لمدى توافقه مع حالة الاستخدام المحددة أمرًا محوريًا، حتى تتمكن من تحقيق حل مخصص وفعال لاحتياجات معالجة البيانات الخاصة بك.
إذا كانت أي من التوصيات التي تمت مناقشتها في هذا المنشور تتوافق مع أعباء العمل لديك، فنحن نشجعك على تجربتها. باستخدام المقاييس المحددة والنصائح حول كيفية فهم أعباء العمل بشكل أفضل، يجب أن يكون لديك الآن ما تحتاجه لتحسين أعباء عمل Apache Flink بكفاءة على الخدمة المُدارة لـ Apache Flink. فيما يلي بعض الموارد المفيدة التي يمكنك استخدامها لتكملة هذا المنشور:
حول المؤلف
 جيريمي بير عمل في مجال بيانات القياس عن بعد على مدار السنوات العشر الماضية كمهندس برمجيات، ومهندس تعلم الآلة، ومؤخرًا مهندس بيانات. في AWS، يعمل كمهندس حلول متخصص في البث، حيث يدعم كلاً من Amazon Managed Streaming لـ Apache Kafka (Amazon MSK) وAmazon Managed Service لـ Apache Flink.
جيريمي بير عمل في مجال بيانات القياس عن بعد على مدار السنوات العشر الماضية كمهندس برمجيات، ومهندس تعلم الآلة، ومؤخرًا مهندس بيانات. في AWS، يعمل كمهندس حلول متخصص في البث، حيث يدعم كلاً من Amazon Managed Streaming لـ Apache Kafka (Amazon MSK) وAmazon Managed Service لـ Apache Flink.
 لورينزو نيكورا يعمل كمهندس أول لحلول البث في AWS، حيث يساعد العملاء عبر أوروبا والشرق الأوسط وأفريقيا. لقد قام ببناء أنظمة سحابية محلية كثيفة البيانات لأكثر من 25 عامًا، وعمل في الصناعة المالية من خلال الاستشارات وشركات منتجات FinTech. لقد استفاد من التقنيات مفتوحة المصدر على نطاق واسع وساهم في العديد من المشاريع، بما في ذلك Apache Flink.
لورينزو نيكورا يعمل كمهندس أول لحلول البث في AWS، حيث يساعد العملاء عبر أوروبا والشرق الأوسط وأفريقيا. لقد قام ببناء أنظمة سحابية محلية كثيفة البيانات لأكثر من 25 عامًا، وعمل في الصناعة المالية من خلال الاستشارات وشركات منتجات FinTech. لقد استفاد من التقنيات مفتوحة المصدر على نطاق واسع وساهم في العديد من المشاريع، بما في ذلك Apache Flink.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

