نحن نعيش في عصر بلغ فيه نموذج التعلم الآلي ذروته. بالمقارنة مع العقود الماضية، لم يكن معظم الناس قد سمعوا أبدًا عن ChatGPT أو الذكاء الاصطناعي. ومع ذلك، هذه هي المواضيع التي يستمر الناس في الحديث عنها. لماذا؟ لأن القيم المقدمة مهمة جدًا مقارنة بالجهد المبذول.
يمكن أن يُعزى التقدم الذي حققه الذكاء الاصطناعي في السنوات الأخيرة إلى أشياء كثيرة، ولكن أحدها هو نموذج اللغة الكبير (LLM). يتم تشغيل العديد من الأشخاص الذين يستخدمون الذكاء الاصطناعي لإنشاء النصوص بواسطة نموذج LLM؛ على سبيل المثال، يستخدم ChatGPT نموذج GPT الخاص به. بما أن LLM موضوع مهم، فيجب أن نتعلم عنه.
ستناقش هذه المقالة نماذج اللغات الكبيرة في ثلاثة مستويات صعوبة، ولكننا سنتطرق فقط إلى بعض جوانب LLMs. سوف نختلف فقط بالطريقة التي تسمح لكل قارئ بفهم ماهية LLM. مع أخذ ذلك في الاعتبار، دعونا ندخل في ذلك.
في المستوى الأول، نفترض أن القارئ لا يعرف شيئًا عن LLM وقد يعرف القليل عن مجال علم البيانات/التعلم الآلي. لذا، أود أن أقدم باختصار الذكاء الاصطناعي والتعلم الآلي قبل الانتقال إلى ماجستير إدارة الأعمال.
الذكاء الاصطناعي هو علم تطوير برامج الكمبيوتر الذكية. الغرض منه هو أن يقوم البرنامج بمهام ذكية يمكن للبشر القيام بها ولكن ليس لديه قيود على الاحتياجات البيولوجية البشرية. تعلم الآلة هو مجال في الذكاء الاصطناعي يركز على دراسات تعميم البيانات باستخدام الخوارزميات الإحصائية. بطريقة ما، يحاول التعلم الآلي تحقيق الذكاء الاصطناعي من خلال دراسة البيانات حتى يتمكن البرنامج من أداء مهام الذكاء دون تعليمات.
تاريخيًا، يُطلق على المجال الذي يتقاطع بين علوم الكمبيوتر واللغويات اسم "الطبيعي". معالجة اللغة مجال. يتعلق هذا المجال بشكل أساسي بأي نشاط معالجة آلية للنص البشري، مثل المستندات النصية. في السابق، كان هذا المجال يقتصر فقط على النظام القائم على القواعد ولكنه أصبح أكثر مع إدخال خوارزميات متقدمة شبه خاضعة للإشراف وغير خاضعة للإشراف والتي تسمح للنموذج بالتعلم دون أي اتجاه. أحد النماذج المتقدمة للقيام بذلك هو نموذج اللغة.
اللغة نموذج هو نموذج البرمجة اللغوية العصبية الاحتمالية لأداء العديد من المهام البشرية مثل الترجمة وتصحيح القواعد وإنشاء النص. يستخدم الشكل القديم لنموذج اللغة أساليب إحصائية بحتة مثل طريقة n-gram، حيث يكون الافتراض هو أن احتمالية الكلمة التالية تعتمد فقط على البيانات ذات الحجم الثابت للكلمة السابقة.
ومع ذلك ، فإن إدخال الشبكة العصبية لقد خلع النهج السابق. الشبكة العصبية الاصطناعية، أو NN، هي برنامج كمبيوتر يحاكي بنية الخلايا العصبية في الدماغ البشري. يعد أسلوب الشبكة العصبية مفيدًا للاستخدام لأنه يمكنه التعامل مع التعرف على الأنماط المعقدة من البيانات النصية والتعامل مع البيانات المتسلسلة مثل النص. ولهذا السبب يعتمد نموذج اللغة الحالي عادةً على NN.
نماذج اللغات الكبيرة، أو LLMs، هي نماذج للتعلم الآلي تتعلم من عدد كبير من مستندات البيانات لأداء إنشاء لغة للأغراض العامة. إنها لا تزال نموذجًا لغويًا، لكن العدد الهائل من المعلمات التي تعلمتها NN يجعلها تعتبر كبيرة. من وجهة نظر الشخص العادي، يمكن للنموذج أن ينفذ الطريقة التي يكتب بها البشر من خلال التنبؤ بالكلمات التالية من كلمات الإدخال المحددة بشكل جيد للغاية.
تتضمن أمثلة مهام LLM ترجمة اللغة وروبوتات الدردشة الآلية والإجابة على الأسئلة وغير ذلك الكثير. من أي تسلسل لإدخال البيانات، يمكن للنموذج تحديد العلاقات بين الكلمات وإنشاء مخرجات مناسبة من التعليمات.
تقريبًا جميع منتجات الذكاء الاصطناعي التوليدي التي تفتخر بشيء يستخدم إنشاء النص يتم تشغيلها بواسطة LLMs. تستخدم المنتجات الكبيرة مثل ChatGPT وGoogle's Bard وغيرها الكثير شهادات LLM كأساس لمنتجاتها.
يتمتع القارئ بمعرفة بعلوم البيانات ولكنه يحتاج إلى معرفة المزيد عن LLM في هذا المستوى. على أقل تقدير، يمكن للقارئ فهم المصطلحات المستخدمة في مجال البيانات. في هذا المستوى، سوف نتعمق أكثر في البنية الأساسية.
كما هو موضح سابقًا، LLM هو نموذج شبكة عصبية تم تدريبه على كميات هائلة من البيانات النصية. لفهم هذا المفهوم بشكل أكبر، سيكون من المفيد فهم كيفية عمل الشبكات العصبية والتعلم العميق.
لقد أوضحنا في المستوى السابق أن الخلية العصبية هي نموذج يحاكي البنية العصبية للدماغ البشري. العنصر الرئيسي في الشبكة العصبية هو الخلايا العصبية، والتي تسمى غالبًا بالعقد. لشرح المفهوم بشكل أفضل، راجع بنية الشبكة العصبية النموذجية في الصورة أدناه.
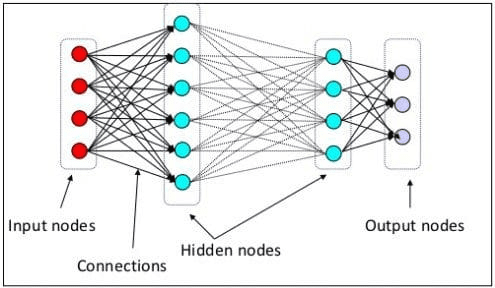
هندسة الشبكات العصبية (مصدر الصورة: KD nuggets)
كما نرى في الصورة أعلاه، تتكون الشبكة العصبية من ثلاث طبقات:
- طبقة الإدخال حيث تتلقى المعلومات وتنقلها إلى العقد الأخرى في الطبقة التالية.
- طبقات العقدة المخفية حيث تتم جميع العمليات الحسابية.
- طبقة عقدة الإخراج حيث توجد المخرجات الحسابية.
يُسمى هذا بالتعلم العميق عندما ندرب نموذج الشبكة العصبية لدينا بطبقتين مخفيتين أو أكثر. يطلق عليه اسم عميق لأنه يستخدم طبقات عديدة بينهما. تتمثل ميزة نماذج التعلم العميق في أنها تتعلم تلقائيًا وتستخرج الميزات من البيانات التي لا تستطيع نماذج التعلم الآلي التقليدية استيعابها.
في نموذج اللغة الكبير، يعد التعلم العميق مهمًا لأن النموذج مبني على معماريات الشبكات العصبية العميقة. فلماذا يطلق عليه LLM؟ ذلك لأنه يتم تدريب مليارات الطبقات على كميات هائلة من البيانات النصية. ستنتج الطبقات معلمات نموذجية تساعد النموذج على تعلم الأنماط المعقدة في اللغة، بما في ذلك القواعد وأسلوب الكتابة وغير ذلك الكثير.
تظهر الصورة أدناه العملية المبسطة للتدريب النموذجي.
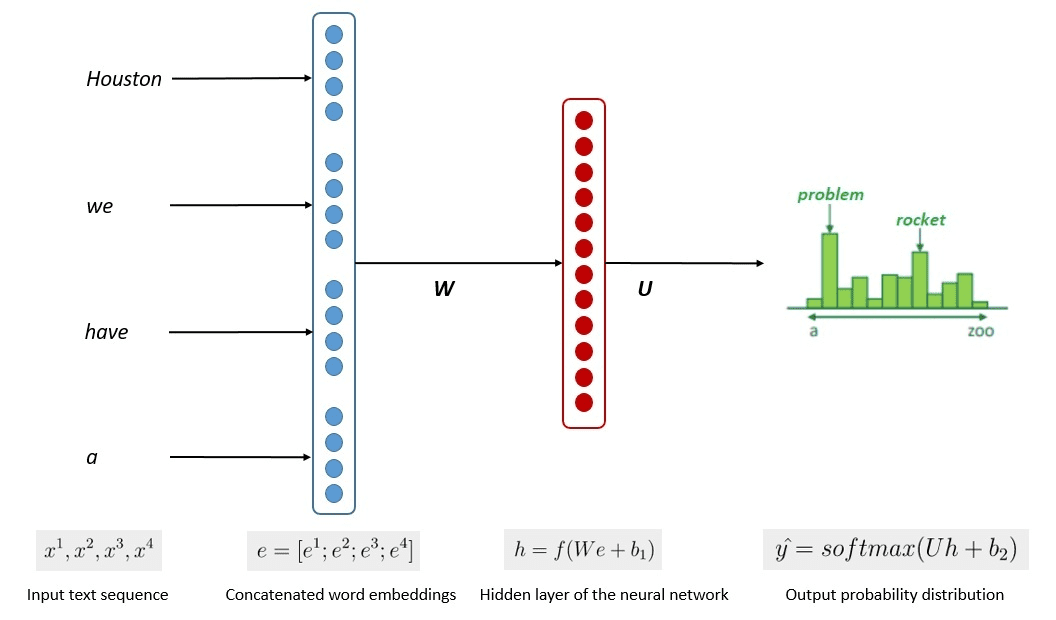
الصورة لكومار تشاندراكانت (المصدر: Baeldung.com)
أظهرت العملية أن النماذج يمكنها إنشاء نص ذي صلة بناءً على احتمالية كل كلمة أو جملة من بيانات الإدخال. في LLMs، يستخدم النهج المتقدم التعلم تحت الإشراف الذاتي و التعلم شبه المشرف لتحقيق القدرة للأغراض العامة.
التعلم الخاضع للإشراف الذاتي هو أسلوب لا نملك فيه تسميات، وبدلاً من ذلك، توفر بيانات التدريب تعليقات التدريب نفسها. يتم استخدامه في عملية التدريب على LLM حيث تفتقر البيانات عادةً إلى التصنيفات. في LLM، يمكن للمرء استخدام السياق المحيط كدليل للتنبؤ بالكلمات التالية. في المقابل، يجمع التعلم شبه الخاضع للإشراف بين مفاهيم التعلم الخاضع للإشراف وغير الخاضع للإشراف مع كمية صغيرة من البيانات المصنفة لإنشاء تسميات جديدة لكمية كبيرة من البيانات غير المسماة. عادةً ما يتم استخدام التعلم شبه الخاضع للإشراف لمجالات LLM ذات السياق أو احتياجات المجال المحددة.
في المستوى الثالث، سنناقش LLM بشكل أكثر عمقًا، وخاصة معالجة هيكل LLM وكيف يمكن أن يحقق قدرة التوليد الشبيهة بالإنسان.
لقد ناقشنا أن LLM يعتمد على نموذج الشبكة العصبية مع تقنيات التعلم العميق. عادةً ما يتم بناء LLM على أساس قائم على المحولات الهندسة المعمارية في السنوات الأخيرة. يعتمد المحول على آلية الانتباه متعدد الرؤوس التي قدمتها فاسواني وآخرون. (2017) وقد تم استخدامه في العديد من LLMs.
المحولات عبارة عن بنية نموذجية تحاول حل المهام المتسلسلة التي تمت مواجهتها مسبقًا في شبكات RNN وLSTMs. كانت الطريقة القديمة لنموذج اللغة هي استخدام RNN وLSTM لمعالجة البيانات بشكل تسلسلي، حيث يستخدم النموذج كل كلمة مخرجة ويعيدها مرة أخرى حتى لا ينساها النموذج. ومع ذلك، لديهم مشاكل مع بيانات التسلسل الطويل بمجرد إدخال المحولات.
قبل أن نتعمق أكثر في المحولات، أريد أن أقدم مفهوم التشفير وفك التشفير الذي تم استخدامه سابقًا في شبكات RNN. تسمح بنية وحدة فك التشفير والتشفير بأن لا يكون نص الإدخال والإخراج بنفس الطول. مثال حالة الاستخدام هو ترجمة اللغة، والتي غالبًا ما يكون لها حجم تسلسل مختلف.
يمكن تقسيم الهيكل إلى قسمين. الجزء الأول يسمى Encoder، وهو الجزء الذي يستقبل تسلسل البيانات ويقوم بإنشاء تمثيل جديد بناءً عليه. سيتم استخدام التمثيل في الجزء الثاني من النموذج، وهو وحدة فك التشفير.
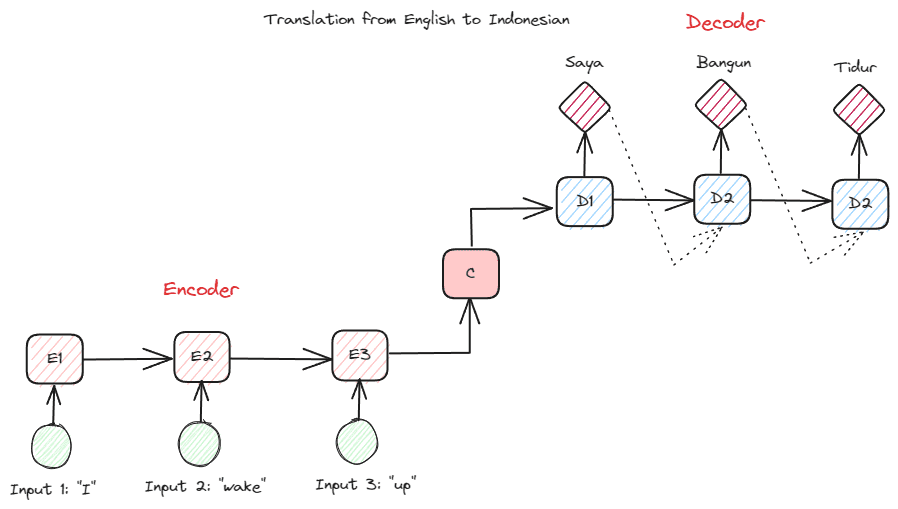
صورة المؤلف
المشكلة في RNN هي أن النموذج قد يحتاج إلى مساعدة في تذكر تسلسلات أطول، حتى مع بنية التشفير وفك التشفير أعلاه. هذا هو المكان الذي يمكن أن تساعد فيه آلية الانتباه في حل المشكلة، وهي طبقة يمكنها حل مشكلات الإدخال الطويلة. تم تقديم آلية الانتباه في الورقة بواسطة بهداناو وآخرون. (2014) لحل شبكات RNN من نوع التشفير وفك التشفير من خلال التركيز على جزء مهم من مدخلات النموذج مع التنبؤ بالإخراج.
هيكل المحول مستوحى من نوع التشفير-فك التشفير وتم بناؤه باستخدام تقنيات آلية الانتباه، لذلك لا يحتاج إلى معالجة البيانات بترتيب تسلسلي. تم تصميم نموذج المحولات الشامل مثل الصورة أدناه.

عمارة المحولات (فاسواني وآخرون. (2017))
في البنية أعلاه، تقوم المحولات بتشفير تسلسل متجه البيانات في تضمين الكلمات أثناء استخدام فك التشفير لتحويل البيانات إلى النموذج الأصلي. يمكن أن يخصص التشفير أهمية معينة للإدخال باستخدام آلية الانتباه.
لقد تحدثنا قليلاً عن المحولات التي تشفر ناقل البيانات، ولكن ما هو ناقل البيانات؟ دعونا نناقش ذلك. في نموذج التعلم الآلي، لا يمكننا إدخال بيانات اللغة الطبيعية الخام في النموذج، لذلك نحتاج إلى تحويلها إلى أشكال رقمية. تسمى عملية التحويل بتضمين الكلمات، حيث تتم معالجة كل كلمة إدخال من خلال نموذج تضمين الكلمات للحصول على ناقل البيانات. يمكننا استخدام العديد من التضمينات الأولية للكلمات، مثل Word2vec or قفازلكن العديد من المستخدمين المتقدمين يحاولون تحسينها باستخدام مفرداتهم. في شكل أساسي، يمكن إظهار عملية تضمين الكلمة في الصورة أدناه.
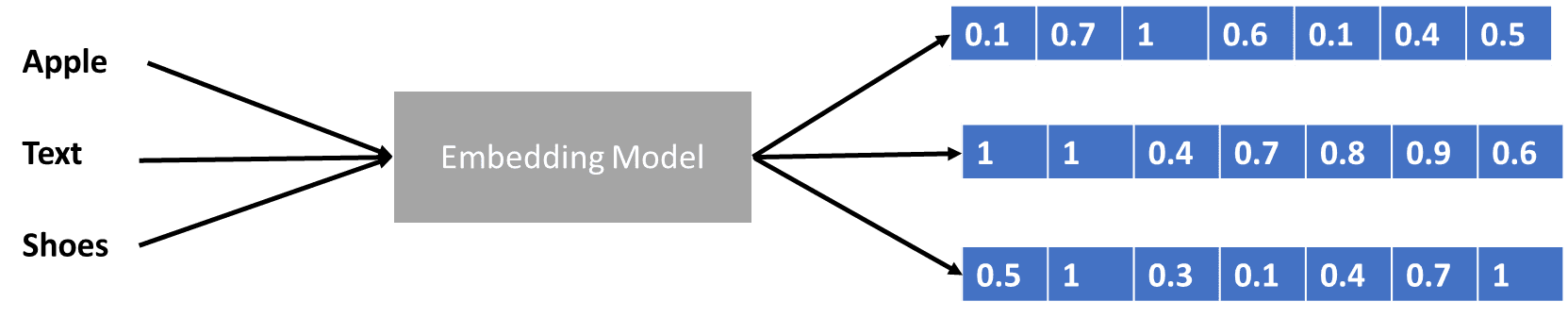
صورة المؤلف
يمكن للمحولات قبول المدخلات وتوفير سياق أكثر صلة من خلال تقديم الكلمات في أشكال رقمية مثل ناقل البيانات أعلاه. في LLMs، عادةً ما تعتمد عمليات تضمين الكلمات على السياق، ويتم تحسينها عمومًا بناءً على حالات الاستخدام والمخرجات المقصودة.
لقد ناقشنا نموذج اللغة الكبير في ثلاثة مستويات صعوبة، من المبتدئ إلى المتقدم. بدءًا من الاستخدام العام لـ LLM وحتى كيفية تنظيمه، يمكنك العثور على شرح يشرح المفهوم بمزيد من التفصيل.
كورنليوس يودا ويجايا هو مدير مساعد لعلوم البيانات وكاتب بيانات. أثناء عمله بدوام كامل في Allianz Indonesia ، يحب مشاركة نصائح حول Python و Data عبر وسائل التواصل الاجتماعي وكتابة الوسائط.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/large-language-models-explained-in-3-levels-of-difficulty?utm_source=rss&utm_medium=rss&utm_campaign=large-language-models-explained-in-3-levels-of-difficulty

