ومع الاعتماد السريع لتطبيقات الذكاء الاصطناعي التوليدية، هناك حاجة إلى استجابة هذه التطبيقات في الوقت المناسب لتقليل زمن الوصول المتصور مع إنتاجية أعلى. غالبًا ما يتم تدريب النماذج الأساسية (FMs) مسبقًا على مجموعة كبيرة من البيانات بمعلمات تتراوح في حجمها من الملايين إلى المليارات وما بعدها. نماذج اللغات الكبيرة (LLMs) هي نوع من FM يقوم بإنشاء نص كاستجابة لاستدلال المستخدم. قد يؤدي استنتاج هذه النماذج بتكوينات مختلفة لمعلمات الاستدلال إلى فترات استجابة غير متناسقة. قد يكون سبب عدم الاتساق هو العدد المتفاوت من رموز الاستجابة التي تتوقعها من النموذج أو نوع المسرع الذي يتم نشر النموذج عليه.
في كلتا الحالتين، بدلاً من انتظار الاستجابة الكاملة، يمكنك اعتماد أسلوب تدفق الاستجابة لاستدلالاتك، والذي يرسل أجزاء من المعلومات بمجرد إنشائها. يؤدي هذا إلى إنشاء تجربة تفاعلية من خلال السماح لك برؤية الاستجابات الجزئية المتدفقة في الوقت الفعلي بدلاً من الاستجابة الكاملة المؤجلة.
مع الإعلان الرسمي عن ذلك يدعم الاستدلال في الوقت الفعلي من Amazon SageMaker الآن تدفق الاستجابة، يمكنك الآن دفق استجابات الاستدلال بشكل مستمر إلى العميل عند الاستخدام الأمازون SageMaker الاستدلال في الوقت الحقيقي مع تدفق الاستجابة سيساعدك هذا الحل على بناء تجارب تفاعلية لمختلف تطبيقات الذكاء الاصطناعي التوليدية مثل برامج الدردشة الآلية والمساعدين الافتراضيين ومولدات الموسيقى. يوضح لك هذا المنشور كيفية تحقيق أوقات استجابة أسرع في شكل Time to First Byte (TTFB) وتقليل زمن الوصول الإجمالي المتصور أثناء استنتاج نماذج Llama 2.
لتنفيذ الحل، نستخدم SageMaker، وهي خدمة مُدارة بالكامل لإعداد البيانات وإنشاء نماذج التعلم الآلي (ML) وتدريبها ونشرها لأي حالة استخدام مع بنية أساسية وأدوات ومسارات عمل مُدارة بالكامل. لمزيد من المعلومات حول خيارات النشر المتنوعة التي يوفرها SageMaker، راجع الأسئلة الشائعة حول استضافة نموذج Amazon SageMaker. دعونا نفهم كيف يمكننا معالجة مشكلات زمن الوصول باستخدام الاستدلال في الوقت الفعلي مع تدفق الاستجابة.
حل نظرة عامة
نظرًا لأننا نريد معالجة زمن الاستجابة المذكور أعلاه المرتبط بالاستدلال في الوقت الفعلي مع LLMs، فلنفهم أولاً كيف يمكننا استخدام دعم تدفق الاستجابة للاستدلال في الوقت الفعلي لـ Llama 2. ومع ذلك، يمكن لأي LLM الاستفادة من دعم تدفق الاستجابة مع حقيقي -الاستدلال بالوقت.
Llama 2 عبارة عن مجموعة من نماذج النصوص التوليدية المدربة مسبقًا والمضبوطة بدقة والتي يتراوح حجمها من 7 مليار إلى 70 مليار معلمة. نماذج Llama 2 هي نماذج انحدار ذاتي مع بنية وحدة فك التشفير فقط. عند تزويدها بمعلمات المطالبة والاستدلال، تكون نماذج Llama 2 قادرة على إنشاء استجابات نصية. يمكن استخدام هذه النماذج للترجمة والتلخيص والإجابة على الأسئلة والدردشة.
في هذا المنشور، قمنا بنشر نموذج Llama 2 Chat meta-llama/Llama-2-13b-chat-hf على SageMaker للاستدلال في الوقت الفعلي من خلال تدفق الاستجابة.
عندما يتعلق الأمر بنشر النماذج على نقاط نهاية SageMaker، يمكنك وضع النماذج في حاويات باستخدام وحدات متخصصة حاوية التعلم العميق من AWS (DLC) متاحة للمكتبات الشهيرة مفتوحة المصدر. نماذج Llama 2 هي نماذج لإنشاء النصوص؛ يمكنك استخدام إما Hugging Face LLM حاويات الاستدلال على SageMaker مدعوم من عناق الوجه استنتاج توليد النص (TGI) أو المحتوى القابل للتنزيل (AWS) لـ الاستدلال النموذجي الكبير (لمي).
في هذا المنشور، نقوم بنشر نموذج Llama 2 13B Chat باستخدام المحتوى القابل للتنزيل (DLC) على استضافة SageMaker للاستدلال في الوقت الفعلي المدعوم بمثيلات G5. مثيلات G5 هي مثيلات تعتمد على وحدة معالجة الرسومات (GPU) عالية الأداء للتطبيقات كثيفة الرسومات واستدلال ML. يمكنك أيضًا استخدام أنواع المثيلات المدعومة p4d، وp3، وg5، وg4dn مع التغييرات المناسبة وفقًا لتكوين المثيل.
المتطلبات الأساسية المسبقة
لتنفيذ هذا الحل يجب أن يكون لديك ما يلي:
- حساب AWS بامتداد إدارة الهوية والوصول AWS دور (IAM) مع أذونات لإدارة الموارد التي تم إنشاؤها كجزء من الحل.
- إذا كانت هذه هي المرة الأولى التي تعمل فيها أمازون ساجميكر ستوديو، تحتاج أولاً إلى إنشاء ملف المجال SageMaker.
- حساب الوجه المعانق. حساب جديد مع بريدك الإلكتروني إذا لم يكن لديك حساب بالفعل.
- للوصول السلس إلى النماذج المتاحة على Hugging Face، وخاصة النماذج المسورة مثل Llama، لأغراض الضبط والاستدلال، يجب أن يكون لديك حساب Hugging Face للحصول على رمز وصول للقراءة. بعد التسجيل للحصول على حساب Hugging Face الخاص بك، بتسجيل الدخول لزيارة https://huggingface.co/settings/tokens لإنشاء رمز وصول للقراءة.
- الوصول إلى Llama 2، باستخدام نفس معرف البريد الإلكتروني الذي استخدمته للتسجيل في Hugging Face.
- نماذج Llama 2 المتوفرة عبر Hugging Face هي نماذج مسورة. يخضع استخدام نموذج Llama لترخيص Meta. لتحميل الأوزان النموذجية والرمز المميز، طلب الوصول إلى اللاما وقبول الترخيص الخاص بهم.
- بعد منحك حق الوصول (عادةً في غضون يومين)، ستتلقى تأكيدًا بالبريد الإلكتروني. في هذا المثال، نستخدم النموذج
Llama-2-13b-chat-hf، ولكن يجب أن تكون قادرًا على الوصول إلى المتغيرات الأخرى أيضًا.
النهج 1: معانقة الوجه TGI
في هذا القسم، نعرض لك كيفية نشر meta-llama/Llama-2-13b-chat-hf نموذج لنقطة نهاية SageMaker في الوقت الفعلي مع تدفق الاستجابة باستخدام Hugging Face TGI. يوضح الجدول التالي مواصفات هذا النشر.
| المواصفات الخاصه | القيم |
| وعاء | معانقة الوجه TGI |
| نموذج الاسم | meta-llama/Llama-2-13b-chat-hf |
| مثيل ML | ml.g5.12xlarge |
| الإستنباط | في الوقت الحقيقي مع تدفق الاستجابة |
انشر النموذج
أولاً، يمكنك استرداد الصورة الأساسية لبرنامج LLM الذي سيتم نشره. ثم تقوم ببناء النموذج على الصورة الأساسية. وأخيرًا، يمكنك نشر النموذج على مثيل ML لاستضافة SageMaker للاستدلال في الوقت الفعلي.
دعونا نلاحظ كيفية تحقيق النشر برمجياً. للإيجاز، تمت مناقشة التعليمات البرمجية التي تساعد في خطوات النشر فقط في هذا القسم. يتوفر كود المصدر الكامل للنشر في دفتر الملاحظات llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
احصل على أحدث المحتوى القابل للتنزيل Hugging Face LLM DLC المدعوم من TGI عبر المحتوى المضمن مسبقًا المحتوى القابل للتنزيل (DLC) لـ SageMaker. يمكنك استخدام هذه الصورة لنشر meta-llama/Llama-2-13b-chat-hf نموذج على SageMaker. انظر الكود التالي:
حدد بيئة النموذج باستخدام معلمات التكوين المحددة على النحو التالي:
استبدل <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> لمعلمة التكوين HUGGING_FACE_HUB_TOKEN بقيمة الرمز المميز الذي تم الحصول عليه من ملفك الشخصي على Hugging Face كما هو مفصل في قسم المتطلبات الأساسية في هذا المنشور. في التكوين، يمكنك تحديد عدد وحدات معالجة الرسومات المستخدمة لكل نسخة متماثلة من النموذج على أنها 4 لـ SM_NUM_GPUS. ثم يمكنك نشر meta-llama/Llama-2-13b-chat-hf نموذج على مثيل ml.g5.12xlarge الذي يأتي مع 4 وحدات معالجة رسوميات.
الآن يمكنك بناء مثيل HuggingFaceModel مع تكوين البيئة المذكورة أعلاه:
أخيرًا، قم بنشر النموذج من خلال توفير الوسائط لأسلوب النشر المتاح في النموذج بقيم معلمات مختلفة مثل endpoint_name, initial_instance_countو instance_type:
نفذ الاستدلال
يأتي محتوى Hugging Face TGI DLC مزودًا بالقدرة على بث الاستجابات دون أي تخصيصات أو تغييرات في التعليمات البرمجية للنموذج. يمكنك استخدام invoc_endpoint_with_response_stream إذا كنت تستخدم Boto3 أو InvocEndpointWithResponseStream عند البرمجة باستخدام SageMaker Python SDK.
• InvokeEndpointWithResponseStream تسمح واجهة برمجة التطبيقات الخاصة بـ SageMaker للمطورين ببث الاستجابات مرة أخرى من نماذج SageMaker، مما يمكن أن يساعد في تحسين رضا العملاء عن طريق تقليل زمن الوصول المتصور. وهذا مهم بشكل خاص للتطبيقات المبنية باستخدام نماذج الذكاء الاصطناعي التوليدية، حيث تكون المعالجة الفورية أكثر أهمية من انتظار الاستجابة بأكملها.
في هذا المثال، نستخدم Boto3 لاستنتاج النموذج واستخدام SageMaker API invoke_endpoint_with_response_stream كما يلي:
الحجة CustomAttributes تم ضبطه على القيمة accept_eula=false. • accept_eula يجب تعيين المعلمة على true للحصول على الاستجابة من نماذج Llama 2 بنجاح. بعد نجاح الاستدعاء باستخدام invoke_endpoint_with_response_stream، ستقوم الطريقة بإرجاع دفق استجابة من البايتات.
يوضح الرسم البياني التالي سير العمل هذا.
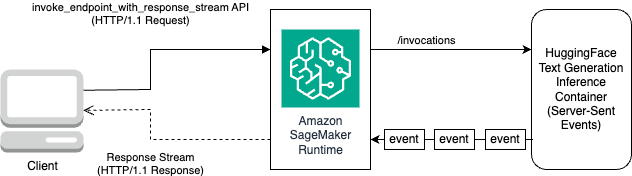
أنت بحاجة إلى مُكرِّر يتكرر عبر تدفق البايتات ويوزعها على نص قابل للقراءة. ال LineIterator يمكن العثور على التنفيذ على llama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py. أنت الآن جاهز لإعداد الموجه والتعليمات لاستخدامها كحمولة أثناء الاستدلال على النموذج.
إعداد موجه والتعليمات
في هذه الخطوة، تقوم بإعداد الموجهات والتعليمات الخاصة بماجستير القانون الخاص بك. لمطالبة Llama 2، يجب أن يكون لديك قالب المطالبة التالي:
يمكنك إنشاء قالب المطالبة المحدد برمجيًا في الطريقة build_llama2_prompt، والذي يتوافق مع قالب المطالبة المذكور أعلاه. ثم تقوم بتحديد التعليمات وفقًا لحالة الاستخدام. في هذه الحالة، نقوم بتوجيه النموذج لإنشاء بريد إلكتروني لحملة تسويقية كما هو موضح في get_instructions طريقة. رمز هذه الأساليب موجود في llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb دفتر. قم ببناء التعليمات مع المهمة التي سيتم تنفيذها كما هو مفصل في user_ask_1 كما يلي:
نقوم بتمرير التعليمات لإنشاء المطالبة وفقًا لقالب المطالبة الذي تم إنشاؤه بواسطة build_llama2_prompt.
نقوم بجمع معلمات الاستدلال مع المطالبة بالمفتاح stream مع القيمة True لتشكيل الحمولة النهائية. أرسل الحمولة إلى get_realtime_response_stream، والتي سيتم استخدامها لاستدعاء نقطة النهاية مع تدفق الاستجابة:
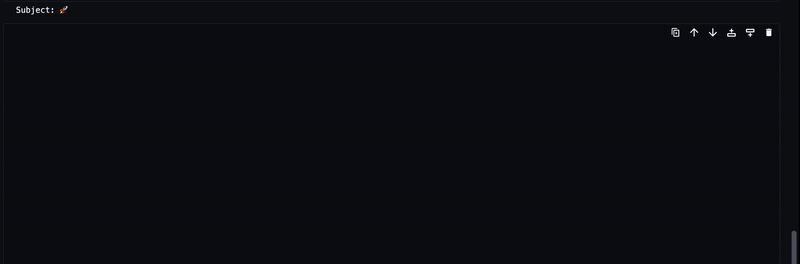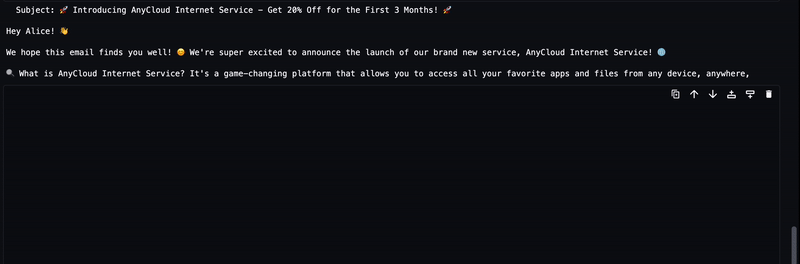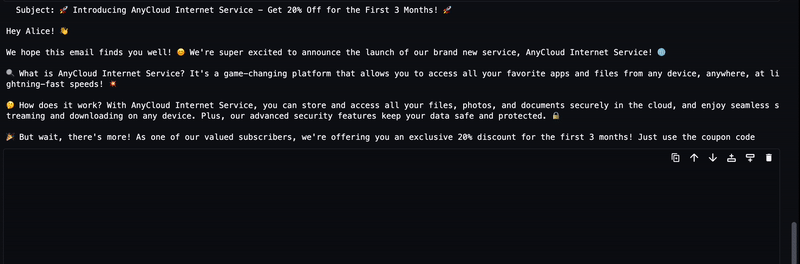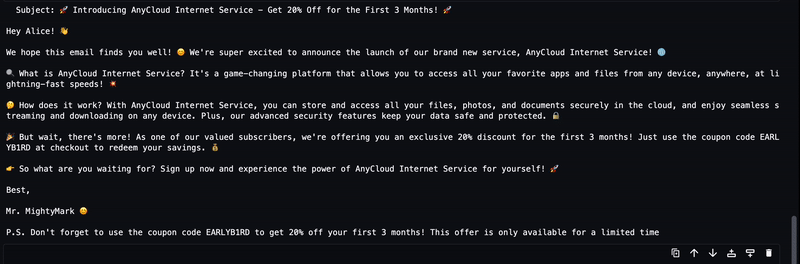
سيتم دفق النص الذي تم إنشاؤه من LLM إلى الإخراج كما هو موضح في الرسم المتحرك التالي.
النهج 2: LMI مع خدمة DJL
في هذا القسم، نوضح كيفية نشر meta-llama/Llama-2-13b-chat-hf نموذج لنقطة نهاية SageMaker في الوقت الفعلي مع تدفق الاستجابة باستخدام LMI مع خدمة DJL. يوضح الجدول التالي مواصفات هذا النشر.
| المواصفات الخاصه | القيم |
| وعاء | صورة حاوية LMI مع خدمة DJL |
| نموذج الاسم | meta-llama/Llama-2-13b-chat-hf |
| مثيل ML | ml.g5.12xlarge |
| الإستنباط | في الوقت الحقيقي مع تدفق الاستجابة |
عليك أولاً تنزيل النموذج وتخزينه فيه خدمة تخزين أمازون البسيطة (أمازون إس 3). يمكنك بعد ذلك تحديد S3 URI الذي يشير إلى بادئة S3 للنموذج في ملف serving.properties ملف. بعد ذلك، يمكنك استرداد الصورة الأساسية لبرنامج LLM الذي سيتم نشره. ثم تقوم ببناء النموذج على الصورة الأساسية. وأخيرًا، يمكنك نشر النموذج على مثيل ML لاستضافة SageMaker للاستدلال في الوقت الفعلي.
دعونا نلاحظ كيفية تحقيق خطوات النشر المذكورة أعلاه برمجياً. للإيجاز، تم تفصيل التعليمات البرمجية التي تساعد في خطوات النشر فقط في هذا القسم. يتوفر كود المصدر الكامل لهذا النشر في دفتر الملاحظات llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
قم بتنزيل لقطة النموذج من Hugging Face وقم بتحميل عناصر النموذج على Amazon S3
باستخدام المتطلبات الأساسية المذكورة أعلاه، قم بتنزيل النموذج على مثيل دفتر ملاحظات SageMaker ثم قم بتحميله إلى حاوية S3 لمزيد من النشر:
لاحظ أنه على الرغم من عدم توفير رمز وصول صالح، سيتم تنزيل النموذج. ولكن عند نشر مثل هذا النموذج، لن ينجح عرض النموذج. لذلك، يوصى باستبداله <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> للحجة token بقيمة الرمز المميز الذي تم الحصول عليه من ملفك الشخصي على Hugging Face كما هو مفصل في المتطلبات الأساسية. في هذا المنشور، نحدد اسم الموديل الرسمي لـ Llama 2 كما هو محدد في Hugging Face بالقيمة meta-llama/Llama-2-13b-chat-hf. سيتم تنزيل النموذج غير المضغوط إلى local_model_path نتيجة لتشغيل الكود المذكور.
قم بتحميل الملفات إلى Amazon S3 واحصل على URI، والذي سيتم استخدامه لاحقًا serving.properties.
سوف تقوم بتغليف meta-llama/Llama-2-13b-chat-hf نموذج على صورة حاوية LMI مع خدمة DJL باستخدام التكوين المحدد عبر serving.properties. بعد ذلك، تقوم بنشر النموذج مع عناصر النموذج المجمعة في صورة الحاوية على مثيل SageMaker ML ml.g5.12xlarge. يمكنك بعد ذلك استخدام مثيل ML هذا لاستضافة SageMaker للاستدلال في الوقت الفعلي.
قم بإعداد المصنوعات اليدوية النموذجية لخدمة DJL
قم بإعداد القطع الأثرية النموذجية الخاصة بك عن طريق إنشاء serving.properties ملف الضبط:
نستخدم الإعدادات التالية في ملف التكوين هذا:
- محرك - يحدد هذا محرك وقت التشغيل الذي سيستخدمه DJL. تشمل القيم المحتملة
Python,DeepSpeed,FasterTransformerوMPI. في هذه الحالة، قمنا بتعيينه علىMPI. تعمل عملية توازي النماذج والاستدلال (MPI) على تسهيل تقسيم النموذج عبر جميع وحدات معالجة الرسومات المتاحة وبالتالي تسريع الاستدلال. - option.entryPoint - يحدد هذا الخيار المعالج الذي تقدمه DJL Serving الذي ترغب في استخدامه. القيم المحتملة هي
djl_python.huggingface,djl_python.deepspeedوdjl_python.stable-diffusion. نحن نستخدمdjl_python.huggingfaceلتسريع معانقة الوجه. - option.tensor_parallel_degree - يحدد هذا الخيار عدد الأقسام الموازية الموترية المنفذة على النموذج. يمكنك تعيين عدد أجهزة GPU التي يحتاج Accelerate إلى تقسيم النموذج عليها. تتحكم هذه المعلمة أيضًا في عدد العاملين لكل نموذج والذي سيتم تشغيله عند تشغيل خدمة DJL. على سبيل المثال، إذا كان لدينا جهاز 4 GPU وقمنا بإنشاء أربعة أقسام، فسيكون لدينا عامل واحد لكل نموذج لخدمة الطلبات.
- option.low_cpu_mem_usage – يؤدي هذا إلى تقليل استخدام ذاكرة وحدة المعالجة المركزية عند تحميل النماذج. نوصي بضبط هذا على
TRUE. - option.rolling_batch - يتيح ذلك إمكانية التجميع على مستوى التكرار باستخدام إحدى الاستراتيجيات المدعومة. تشمل القيم
auto,schedulerوlmi-dist. نحن نستخدمlmi-distلتشغيل الدفع المستمر لـ Llama 2. - option.max_rolling_batch_size - وهذا يحد من عدد الطلبات المتزامنة في الدفعة المستمرة. القيمة الافتراضية هي 32.
- option.model_id – يجب عليك استبدال
{{model_id}}بمعرف النموذج الخاص بالنموذج المُدرب مسبقًا والمستضاف داخل ملف مستودع النموذج على معانقة الوجه أو مسار S3 إلى القطع الأثرية النموذجية.
يمكن العثور على المزيد من خيارات التكوين في التكوينات والإعدادات.
نظرًا لأن DJL Serving تتوقع تجميع العناصر النموذجية وتنسيقها في ملف .tar، قم بتشغيل مقتطف التعليمات البرمجية التالي لضغط ملف .tar وتحميله إلى Amazon S3:
استرجع أحدث صورة لحاوية LMI مع خدمة DJL
بعد ذلك، يمكنك استخدام المحتوى القابل للتنزيل (DLC) المتوفر مع SageMaker لـ LMI لنشر النموذج. استرجع URI لصورة SageMaker لـ djl-deepspeed الحاوية برمجياً باستخدام الكود التالي:
يمكنك استخدام الصورة المذكورة أعلاه لنشر meta-llama/Llama-2-13b-chat-hf نموذج على SageMaker. الآن يمكنك المتابعة لإنشاء النموذج.
قم بإنشاء النموذج
يمكنك إنشاء النموذج الذي تم إنشاء حاويته باستخدام ملف inference_image_uri ورمز عرض النموذج الموجود في S3 URI المشار إليه بواسطة s3_code_artifact:
يمكنك الآن إنشاء تكوين النموذج بكل التفاصيل الخاصة بتكوين نقطة النهاية.
إنشاء تكوين النموذج
استخدم الكود التالي لإنشاء تكوين نموذج للنموذج المحدد بواسطة model_name:
يتم تعريف تكوين النموذج لـ ProductionVariants المعلمة InstanceType بالنسبة لمثال تعلم الآلة ml.g5.12xlarge. يمكنك أيضًا توفير ModelName باستخدام نفس الاسم الذي استخدمته لإنشاء النموذج في الخطوة السابقة، وبالتالي إنشاء علاقة بين النموذج وتكوين نقطة النهاية.
الآن بعد أن حددت النموذج وتكوين النموذج، يمكنك إنشاء نقطة نهاية SageMaker.
قم بإنشاء نقطة نهاية SageMaker
قم بإنشاء نقطة النهاية لنشر النموذج باستخدام مقتطف التعليمات البرمجية التالي:
يمكنك عرض تقدم النشر باستخدام مقتطف التعليمات البرمجية التالي:
بعد نجاح النشر، ستكون حالة نقطة النهاية InService. الآن بعد أن أصبحت نقطة النهاية جاهزة، فلنجري الاستدلال من خلال تدفق الاستجابة.
الاستدلال في الوقت الحقيقي مع تدفق الاستجابة
كما تناولنا في النهج السابق لـ Hugging Face TGI، يمكنك استخدام نفس الطريقة get_realtime_response_stream لاستدعاء تدفق الاستجابة من نقطة نهاية SageMaker. رمز الاستدلال باستخدام نهج LMI موجود في ملف llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb دفتر. ال LineIterator يقع التنفيذ في llama-2-lmi/utils/LineIterator.py. نلاحظ أن LineIterator بالنسبة لنموذج Llama 2 Chat الذي تم نشره في حاوية LMI يختلف عن LineIterator تمت الإشارة إليه في قسم Hugging Face TGI. ال LineIterator حلقات عبر دفق البايت من نماذج Llama 2 Chat التي يتم الاستدلال عليها باستخدام حاوية LMI ذات djl-deepspeed الإصدار 0.25.0. ستقوم وظيفة المساعد التالية بتحليل تدفق الاستجابة المستلمة من طلب الاستدلال الذي تم إجراؤه عبر invoke_endpoint_with_response_stream API:
تقوم الطريقة السابقة بطباعة دفق البيانات التي يقرأها الملف LineIterator في شكل يمكن قراءته من قبل الإنسان.
دعنا نستكشف كيفية إعداد الموجه والتعليمات لاستخدامها كحمولة أثناء الاستدلال على النموذج.
نظرًا لأنك تستنتج نفس النموذج في كل من Hugging Face TGI وLMI، فإن عملية إعداد الموجه والتعليمات هي نفسها. لذلك، يمكنك استخدام الأساليب get_instructions و build_llama2_prompt للاستدلال.
• get_instructions تقوم الطريقة بإرجاع التعليمات. قم ببناء التعليمات المدمجة مع المهمة التي سيتم تنفيذها كما هو مفصل في user_ask_2 كما يلي:
قم بتمرير التعليمات لإنشاء المطالبة وفقًا لقالب المطالبة الذي تم إنشاؤه بواسطة build_llama2_prompt:
نحن نجمع معلمات الاستدلال مع المطالبة لتشكيل حمولة نهائية. ثم تقوم بإرسال الحمولة إلى get_realtime_response_stream, والذي يستخدم لاستدعاء نقطة النهاية مع تدفق الاستجابة:
سيتم دفق النص الذي تم إنشاؤه من LLM إلى الإخراج كما هو موضح في الرسم المتحرك التالي.

تنظيف
لتجنب تكبد رسوم غير ضرورية، استخدم وحدة تحكم إدارة AWS لحذف نقاط النهاية والموارد المرتبطة بها التي تم إنشاؤها أثناء تشغيل الأساليب المذكورة في المنشور. بالنسبة لكلا أسلوبي النشر، قم بتنفيذ روتين التنظيف التالي:
استبدل <SageMaker_Real-time_Endpoint_Name> للمتغير endpoint_name مع نقطة النهاية الفعلية.
بالنسبة للطريقة الثانية، قمنا بتخزين عناصر النموذج والتعليمات البرمجية على Amazon S3. يمكنك تنظيف حاوية S3 باستخدام الكود التالي:
وفي الختام
في هذا المنشور، ناقشنا كيف يمكن لعدد متفاوت من رموز الاستجابة أو مجموعة مختلفة من معلمات الاستدلال أن تؤثر على زمن الاستجابة المرتبط بـ LLMs. لقد أظهرنا كيفية معالجة المشكلة بمساعدة تدفق الاستجابة. ثم حددنا طريقتين لنشر نماذج Llama 2 Chat والاستدلال عليها باستخدام محتويات AWS DLC — LMI وHugging Face TGI.
يجب أن تفهم الآن أهمية استجابة البث وكيف يمكن أن تقلل من زمن الاستجابة المتصور. يمكن أن تؤدي الاستجابة المتدفقة إلى تحسين تجربة المستخدم، الأمر الذي قد يجعلك تنتظر حتى تقوم LLM ببناء الاستجابة بأكملها. بالإضافة إلى ذلك، يؤدي نشر نماذج Llama 2 Chat مع تدفق الاستجابة إلى تحسين تجربة المستخدم وإسعاد عملائك.
يمكنك الرجوع إلى عينات aws الرسمية أمازون-sagemaker-llama2-response-streaming-recipes يغطي النشر لمتغيرات طراز Llama 2 الأخرى.
مراجع حسابات
حول المؤلف
 بافان كومار راو نافولي هو مهندس الحلول في Amazon Web Services. وهو يعمل مع موردي البرامج المستقلين في الهند لمساعدتهم على الابتكار في AWS. وهو مؤلف منشور لكتاب "البدء ببرمجة V". حصل على درجة الماجستير التنفيذي في التكنولوجيا في علوم البيانات من المعهد الهندي للتكنولوجيا (IIT)، حيدر أباد. حصل أيضًا على درجة الماجستير في إدارة الأعمال التنفيذية في تخصص تكنولوجيا المعلومات من المدرسة الهندية لإدارة الأعمال والإدارة، وحصل على بكالوريوس تكنولوجيا في هندسة الإلكترونيات والاتصالات من معهد فاجديفي للتكنولوجيا والعلوم. بافان هو أحد محترفي حلول AWS المعتمدين ويحمل شهادات أخرى مثل تخصص التعلم الآلي المعتمد من AWS، وأخصائي Microsoft المعتمد (MCP)، وأخصائي التكنولوجيا المعتمد من Microsoft (MCTS). وهو أيضًا من عشاق المصادر المفتوحة. في أوقات فراغه، يحب الاستماع إلى الأصوات السحرية الرائعة لـ Sia و Rihanna.
بافان كومار راو نافولي هو مهندس الحلول في Amazon Web Services. وهو يعمل مع موردي البرامج المستقلين في الهند لمساعدتهم على الابتكار في AWS. وهو مؤلف منشور لكتاب "البدء ببرمجة V". حصل على درجة الماجستير التنفيذي في التكنولوجيا في علوم البيانات من المعهد الهندي للتكنولوجيا (IIT)، حيدر أباد. حصل أيضًا على درجة الماجستير في إدارة الأعمال التنفيذية في تخصص تكنولوجيا المعلومات من المدرسة الهندية لإدارة الأعمال والإدارة، وحصل على بكالوريوس تكنولوجيا في هندسة الإلكترونيات والاتصالات من معهد فاجديفي للتكنولوجيا والعلوم. بافان هو أحد محترفي حلول AWS المعتمدين ويحمل شهادات أخرى مثل تخصص التعلم الآلي المعتمد من AWS، وأخصائي Microsoft المعتمد (MCP)، وأخصائي التكنولوجيا المعتمد من Microsoft (MCTS). وهو أيضًا من عشاق المصادر المفتوحة. في أوقات فراغه، يحب الاستماع إلى الأصوات السحرية الرائعة لـ Sia و Rihanna.
 سودهانشو الكراهية هو متخصص رئيسي في الذكاء الاصطناعي/تعلم الآلة في AWS ويعمل مع العملاء لتقديم المشورة لهم بشأن عمليات MLOs الخاصة بهم ورحلة الذكاء الاصطناعي التوليدية. في منصبه السابق قبل شركة أمازون، قام بوضع تصور وإنشاء وقيادة الفرق لبناء منصات الذكاء الاصطناعي والألعاب القائمة على المصادر المفتوحة، ونجح في تسويقها مع أكثر من 100 عميل. يُنسب إلى Sudhanshu بعض براءات الاختراع، وقد كتب كتابين والعديد من الأوراق البحثية والمدونات، وقدم وجهات نظره في المنتديات التقنية المختلفة. لقد كان قائدًا فكريًا ومتحدثًا، ويعمل في هذه الصناعة منذ ما يقرب من 25 عامًا. لقد عمل مع عملاء Fortune 1000 في جميع أنحاء العالم ومؤخرًا مع عملاء رقميين أصليين في الهند.
سودهانشو الكراهية هو متخصص رئيسي في الذكاء الاصطناعي/تعلم الآلة في AWS ويعمل مع العملاء لتقديم المشورة لهم بشأن عمليات MLOs الخاصة بهم ورحلة الذكاء الاصطناعي التوليدية. في منصبه السابق قبل شركة أمازون، قام بوضع تصور وإنشاء وقيادة الفرق لبناء منصات الذكاء الاصطناعي والألعاب القائمة على المصادر المفتوحة، ونجح في تسويقها مع أكثر من 100 عميل. يُنسب إلى Sudhanshu بعض براءات الاختراع، وقد كتب كتابين والعديد من الأوراق البحثية والمدونات، وقدم وجهات نظره في المنتديات التقنية المختلفة. لقد كان قائدًا فكريًا ومتحدثًا، ويعمل في هذه الصناعة منذ ما يقرب من 25 عامًا. لقد عمل مع عملاء Fortune 1000 في جميع أنحاء العالم ومؤخرًا مع عملاء رقميين أصليين في الهند.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/inference-llama-2-models-with-real-time-response-streaming-using-amazon-sagemaker/

