المُقدّمة
أصبحت قواعد بيانات المتجهات هي المكان الأمثل لتخزين وفهرسة تمثيلات البيانات غير المنظمة والمنظمة. هذه التمثيلات هي التضمينات المتجهة التي تم إنشاؤها بواسطة نماذج التضمين. أصبحت متاجر المتجهات جزءًا لا يتجزأ من تطوير التطبيقات باستخدام نماذج التعلم العميق، وخاصة نماذج اللغات الكبيرة. في مشهد Vector Stores الذي يتطور باستمرار، تعد Qdrant إحدى قواعد بيانات Vector التي تم تقديمها مؤخرًا وهي مليئة بالميزات. دعونا نتعمق ونتعلم المزيد عنها.
أهداف التعلم
- التعرف على مصطلحات Qdrant لفهمها بشكل أفضل
- الغوص في Qdrant Cloud وإنشاء مجموعات
- تعلم كيفية إنشاء تضمينات لمستنداتنا وتخزينها في مجموعات Qdrant
- استكشاف كيفية عمل الاستعلام في Qdrant
- التلاعب بالتصفية في Qdrant للتحقق من كيفية عملها
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
ما هي التضمينات؟
تعد عمليات التضمين المتجه وسيلة للتعبير عن البيانات في شكل رقمي - أي كأرقام في مساحة ذات أبعاد n، أو كمتجه رقمي - بغض النظر عن نوع البيانات - النص والصور والصوت ومقاطع الفيديو وما إلى ذلك. تتيح لنا عمليات التضمين لتجميع البيانات ذات الصلة معًا بهذه الطريقة. يمكن تحويل بعض المدخلات إلى متجهات باستخدام نماذج معينة. يُطلق على نموذج التضمين المعروف الذي أنشأته Google والذي يترجم الكلمات إلى متجهات (المتجهات عبارة عن نقاط ذات أبعاد n) اسم Word2Vec. يحتوي كل نموذج من نماذج اللغة الكبيرة على نموذج تضمين يقوم بإنشاء تضمين لـ LLM.
ما هي التضمينات المستخدمة؟
إحدى ميزات ترجمة الكلمات إلى متجهات هي أنها تسمح بالمقارنة. عند إعطاء كلمتين كمدخلات رقمية، أو تضمينات متجهة، يمكن للكمبيوتر مقارنتها على الرغم من أنه لا يستطيع مقارنتها مباشرة. من الممكن تجميع الكلمات ذات التضمينات المتشابهة معًا. ونظرًا لارتباطها ببعضها البعض، ستظهر مصطلحات الملك والملكة والأمير والأميرة في مجموعة.
وبهذا المعنى، تساعدنا عمليات التضمين في تحديد الكلمات المرتبطة بمصطلح معين. يمكن استخدام هذا في الجمل، حيث نقوم بإدخال جملة، وتقوم البيانات المقدمة بإرجاع الجمل ذات الصلة. يعد هذا بمثابة الأساس للعديد من حالات الاستخدام، بما في ذلك برامج الدردشة الآلية وتشابه الجمل والكشف عن الحالات الشاذة والبحث الدلالي. إن Chatbots التي نطورها للإجابة على الأسئلة بناءً على ملف PDF أو المستند الذي نقدمه تستفيد من فكرة التضمين هذه. يتم استخدام هذه الطريقة بواسطة كافة نماذج اللغات التوليدية الكبيرة للحصول على محتوى مرتبط بشكل مماثل بالاستعلامات التي يتم توفيرها لها.
ما هي قواعد بيانات المتجهات؟
كما تمت مناقشته ، فإن عمليات التضمين هي تمثيلات لأي نوع من البيانات عادةً ، غير المهيكلة في التنسيق العددي في الفضاء ذي البعد n. الآن أين نخزنها؟ لا يمكن استخدام RDMS (أنظمة إدارة قواعد البيانات العلائقية) التقليدية لتخزين هذه الزخارف المتجهية. هذا هو المكان الذي يلعب فيه Vector Store / Vector Dabases. تم تصميم قواعد بيانات المتجهات لتخزين واسترجاع الزخارف المتجهية بطريقة فعالة. هناك العديد من متاجر Vector ، والتي تختلف باختلاف نماذج التضمين التي تدعمها ونوع خوارزمية البحث التي يستخدمونها للحصول على متجهات مماثلة.
ما هو كيودرانت؟
Qdrant هو محرك بحث تشابه المتجهات الجديد وقاعدة بيانات المتجهات، مما يوفر خدمة جاهزة للإنتاج مبنية في Rust، وهي اللغة المعروفة بسلامتها. يأتي Qdrant مزودًا بواجهة برمجة تطبيقات سهلة الاستخدام مصممة لتخزين النقاط عالية الأبعاد والبحث فيها وإدارتها (النقاط ليست سوى تضمينات متجهة) غنية بالبيانات الوصفية التي تسمى الحمولات. تصبح هذه الحمولات بمثابة معلومات قيمة، مما يؤدي إلى تحسين دقة البحث وتوفير بيانات ثاقبة للمستخدمين. إذا كنت معتادًا على قواعد بيانات المتجهات الأخرى مثل Chroma، فإن Payload يشبه البيانات التعريفية، فهو يحتوي على معلومات حول المتجهات.
إن كتابته بلغة Rust يجعل Qdrant متجر Vectore سريعًا وموثوقًا حتى في ظل الأحمال الثقيلة. ما يميز Qdrant عن قواعد البيانات الأخرى هو عدد واجهات برمجة تطبيقات العميل التي تقدمها. في الوقت الحالي، يدعم Qdrant لغة Python، وTypeSciprt/JavaScript، وRust، وGo. لأنه يأتي مع. يستخدم Qdrant HSNW (الرسم البياني الهرمي للعالم الصغير القابل للملاحة) لفهرسة المتجهات ويأتي مزودًا بالعديد من مقاييس المسافة مثل Cosine وDot وEuclidean. لأنه يأتي مع واجهة برمجة التطبيقات (API) للتوصية خارج الصندوق.
تعرف على مصطلحات Qdrant
للحصول على بداية سلسة مع Qdrant، من الممارسات الجيدة التعرف على المصطلحات/المكونات الرئيسية المستخدمة في قاعدة بيانات Qdrant Vector.
المجموعات
يتم تسمية المجموعات بمجموعات من النقاط، حيث تحتوي كل نقطة على متجه ومعرف اختياري وحمولة. يجب أن تتشارك المتجهات الموجودة في نفس المجموعة في نفس الأبعاد ويتم تقييمها باستخدام مقياس واحد مختار.
مقاييس المسافة
من الضروري قياس مدى قرب المتجهات من بعضها البعض، ويتم تحديد مقاييس المسافة أثناء إنشاء المجموعة. يوفر Qdrant مقاييس المسافة التالية: النقطة وجيب التمام والإقليدية.
النقاط
يتكون الكيان الأساسي داخل Qdrant من تضمين متجه ومعرف اختياري وحمولة مرتبطة، حيث
الرقم: معرف فريد لكل تضمين متجه
المتجه: تمثيل عالي الأبعاد للبيانات، والذي يمكن أن يكون إما تنسيقات منظمة أو غير منظمة مثل الصور والنصوص والمستندات وملفات PDF ومقاطع الفيديو والصوت وما إلى ذلك.
الحمولة: كائن JSON اختياري يحتوي على بيانات مرتبطة بالمتجه. يمكن اعتبار ذلك مشابهًا للبيانات الوصفية ويمكننا العمل مع هذا لتصفية عملية البحث
الخزائن
يوفر Qdrant خيارين للتخزين:
- التخزين داخل الذاكرة: يخزن جميع المتجهات في ذاكرة الوصول العشوائي (RAM)، مما يعمل على تحسين السرعة عن طريق تقليل وصول القرص إلى المهام المستمرة.
- تخزين مماب: ينشئ مساحة عنوان افتراضية مرتبطة بملف على القرص، ويوازن بين متطلبات السرعة والاستمرارية.
هذه هي المفاهيم الرئيسية التي يجب أن نكون على دراية بها حتى نتمكن من البدء بسرعة باستخدام Qdrant
Qdrant Cloud – إنشاء مجموعتنا الأولى
توفر Qdrant خدمة سحابية قابلة للتطوير لتخزين وإدارة المتجهات. حتى أنه يوفر مجموعة مجانية للأبد بسعة 1 جيجابايت بدون معلومات بطاقة الائتمان. في هذا القسم، سنتناول عملية إنشاء حساب باستخدام Qdrant Cloud وإنشاء مجموعتنا الأولى.
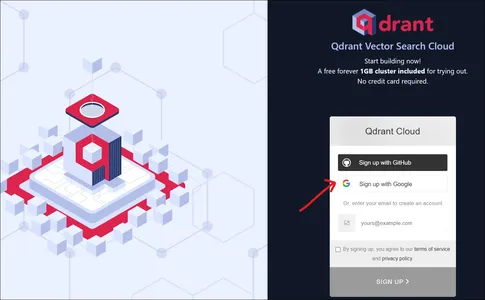
بالذهاب إلى موقع Qdrant، سنجد صفحة مقصودة مثل تلك المذكورة أعلاه. يمكننا التسجيل في Qdrant إما باستخدام حساب Google أو باستخدام حساب GitHub.
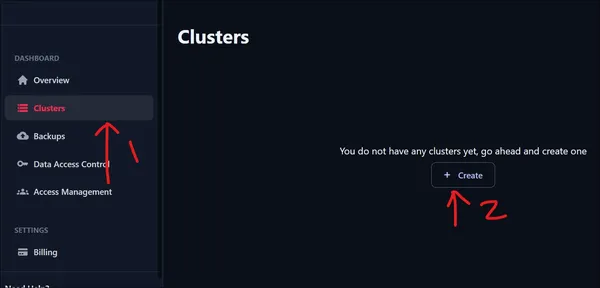
بعد تسجيل الدخول، ستظهر لنا واجهة المستخدم الموضحة أعلاه. لإنشاء مجموعة، انتقل إلى الجزء الأيمن وانقر على خيار المجموعات ضمن لوحة المعلومات. وبما أننا قمنا بتسجيل الدخول للتو، فليس لدينا أي مجموعات. انقر فوق "إنشاء مجموعة" لإنشاء مجموعة جديدة.
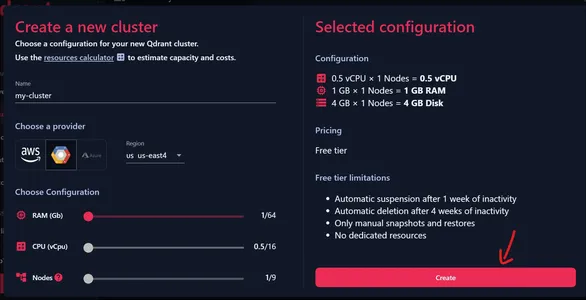
الآن، يمكننا تقديم اسم لمجموعتنا. تأكد من ضبط كافة التكوينات على موضع البداية، لأن هذا يمنحنا مجموعة مجانية. يمكننا اختيار أحد مقدمي الخدمات الموضحين أعلاه واختيار إحدى المناطق المرتبطة به.
تحقق من التكوين الحالي
يمكننا أن نرى على اليسار التكوين الحالي، أي 0.5 vCPU، وذاكرة الوصول العشوائي (RAM) سعة 1 جيجابايت، وتخزين القرص بسعة 4 جيجابايت. انقر فوق "إنشاء" لإنشاء مجموعتنا.
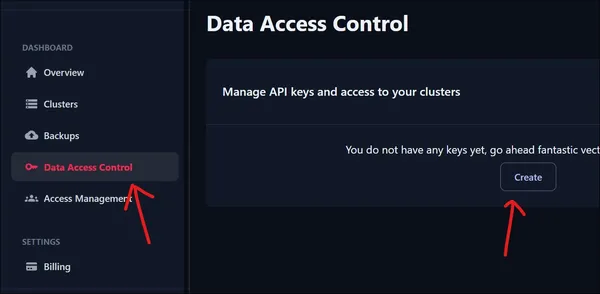
للوصول إلى مجموعتنا المنشأة حديثًا، نحتاج إلى مفتاح API. لإنشاء مفتاح API جديد، توجه إلى التحكم في الوصول إلى البيانات ضمن لوحة المعلومات. انقر فوق الزر "إنشاء" لإنشاء مفتاح API جديد.

كما هو موضح أعلاه، ستظهر لنا قائمة منسدلة نختار فيها المجموعة التي نحتاجها لإنشاء واجهة برمجة التطبيقات (API) لها. نظرًا لأن لدينا مجموعة واحدة فقط، فإننا نختارها ونضغط على الزر "موافق".
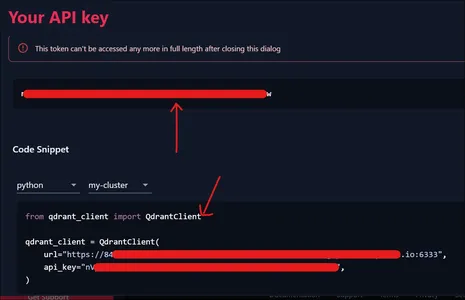
بعد ذلك سيتم تقديم رمز واجهة برمجة التطبيقات (API Token) الموضح أعلاه. أيضًا، إذا رأينا الجزء أدناه من الصورة، فسيتم تزويدنا أيضًا بمقتطف الكود لربط مجموعتنا، والذي سنستخدمه في القسم التالي.
Qdrant - التدريب العملي
في هذا القسم، سنعمل مع قاعدة بيانات Qdrant Vector. أولاً، سنبدأ باستيراد المكتبات اللازمة.
!pip install sentence-transformers
!pip install qdrant_clientيقوم السطر الأول بتثبيت مكتبة بايثون لمحولات الجملة. تُستخدم مكتبة محولات الجملة لإنشاء تضمينات الجملة والنص والصور. يمكننا استخدام هذه المكتبة لاستيراد نماذج التضمين المختلفة لإنشاء عمليات التضمين. يقوم البيان التالي بتثبيت عميل qdrant لـ Python. لنبدأ بإنشاء عميلنا.
from qdrant_client import QdrantClient
client = QdrantClient(
url="YOUR CLUSTER URL",
api_key="YOUR API KEY",
)
QdrantClient
في ما سبق، قمنا بإنشاء مثيل زبون عن طريق استيراد QdrantClient فئة وإعطاء عنوان URL للمجموعة و مفتاح API التي أنشأناها للتو منذ فترة. بعد ذلك، سوف نقوم بإحضار نموذج التضمين الخاص بنا.
# bringing in our embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')في الكود أعلاه استخدمنا محول الجملة فئة وإنشاء مثيل لنموذج. نموذج التضمين الذي اتخذناه هو جميع mpnet-base-v2. هذا هو نموذج تضمين ناقلات للأغراض العامة شائع على نطاق واسع. سيأخذ هذا النموذج النص ويخرج أ 768 الأبعاد المتجه. دعونا نحدد بياناتنا.
# data
documents = [
"""Elephants, the largest land mammals, exhibit remarkable intelligence and
social bonds, relying on their powerful trunks for communication and various
tasks like lifting objects and gathering food.""",
""" Penguins, flightless birds adapted to life in the water, showcase strong
social structures and exceptional parenting skills. Their sleek bodies
enable efficient swimming, and they endure
harsh Antarctic conditions in tightly-knit colonies. """,
"""Cars, versatile modes of transportation, come in various shapes and
sizes, from compact city cars to powerful sports vehicles, offering a
range of features for different preferences and needs.""",
"""Motorbikes, nimble two-wheeled machines, provide a thrilling and
liberating riding experience, appealing to enthusiasts who appreciate
speed, agility, and the open road.""",
"""Tigers, majestic big cats, are solitary hunters with distinctive
striped fur. Their powerful build and stealthy movements make them
formidable predators, but their populations are threatened
due to habitat loss and poaching."""
]
في ما سبق، لدينا متغير يسمى المستندات ويحتوي على قائمة من 5 سلاسل (لنأخذ كل منها كمستند واحد). ترتبط كل سلسلة من البيانات بموضوع معين. ترتبط بعض البيانات بالعناصر وبعض البيانات تتعلق بالسيارات. لنقم بإنشاء تضمينات للبيانات.
# embedding the data
embeddings = model.encode(documents)
print(embeddings.shape)نستخدم ترميز () وظيفة كائن النموذج لتشفير بياناتنا. للتشفير، نقوم مباشرة بتمرير قائمة المستندات إلى ملف ترميز () وظيفة وتخزين عمليات تضمين المتجهات الناتجة في متغير عمليات التضمين. نحن نقوم أيضًا بطباعة شكل التضمينات، والتي سيتم طباعتها هنا (5، 768). وذلك لأن لدينا 5 نقاط بيانات، أي 5 مستندات ولكل مستند، يتم إنشاء تضمين متجه لـ 768 بُعدًا.
قم بإنشاء مجموعتك
الآن سوف نقوم بإنشاء مجموعتنا.
from qdrant_client.http.models import VectorParams, Distance
client.create_collection(
collection_name = "my-collection",
vectors_config = VectorParams(size=768,distance=Distance.COSINE)
)
- لإنشاء مجموعة، نعمل باستخدام وظيفة create_collection() لكائن العميل، وإلى "Collection_name"، نمرر اسم مجموعتنا، أي "مجموعتي"
- VectorParams: هذه الفئة من qdrant مخصص لتكوين المتجه، مثل ما هو حجم تضمين المتجه، وما هو مقياس المسافة، وما إلى ذلك
- المسافات: هذه الفئة من qdrant الغرض منه هو تحديد مقياس المسافة المطلوب استخدامه للاستعلام عن المتجهات
- الآن إلى Vector_config متغير نمرر التكوين الخاص بنا، وهذا هو حجم تضمينات المتجهات، أي 786، ومقياس المسافة الذي نريد استخدامه، وهو جيب التمام
إضافة التضمينات المتجهات
لقد نجحنا الآن في إنشاء مجموعتنا. سنقوم الآن بإضافة تضمينات المتجهات الخاصة بنا إلى هذه المجموعة.
from qdrant_client.http.models import Batch
client.upsert (
collection_name = "my-collection",
points = Batch(
ids = [1,2,3,4,5],
payloads= [
{"category":"animals"},
{"category":"animals"},
{"category":"automobiles"},
{"category":"automobiles"},
{"category":"animals"}
],
vectors = embeddings.tolist()
)
)
- لإضافة بيانات إلى qdrant نسميها upert () الطريقة وتمرير اسم المجموعة والنقاط. كما تعلمنا أعلاه، أ البوينت يتكون من المتجهات، وفهرس اختياري، والحمولات. ال دفعة يتيح لنا الفصل من qdrant إضافة البيانات على دفعات بدلاً من إضافتها واحدة تلو الأخرى.
- IDS: نحن نعطي وثائقنا بطاقة هوية. في الوقت الحاضر، نعطي نطاقًا من القيم من 1 إلى 5 لأن لدينا 5 مستندات في قائمتنا.
- الحمولات: كما رأينا من قبل، فإن الحمولة يحتوي على معلومات حول المتجهات، مثل البيانات الوصفية. نحن نقدمها في أزواج ذات قيمة رئيسية. لكل وثيقة قدمنا أ الحمولة هنا، نقوم بتعيين معلومات الفئة لكل مستند.
- ناقلات: هذه هي التضمينات المتجهة للمستندات. نقوم بتحويلها إلى قائمة من مصفوفة numpy وإطعامها.
لذا، بعد تشغيل هذا الكود، تتم إضافة التضمينات المتجهة إلى المجموعة. للتحقق مما إذا تمت إضافتها، يمكننا زيارة لوحة المعلومات السحابية التي توفرها Qdrant Cloud. ومن أجل ذلك نقوم بما يلي:
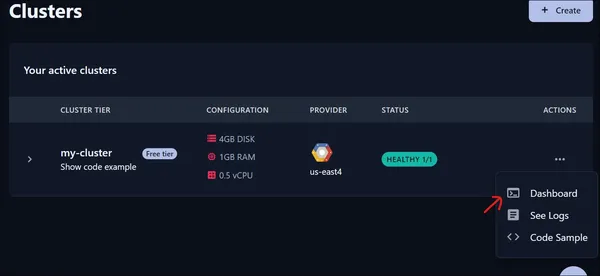
نضغط على لوحة التحكم ثم يتم فتح صفحة جديدة.
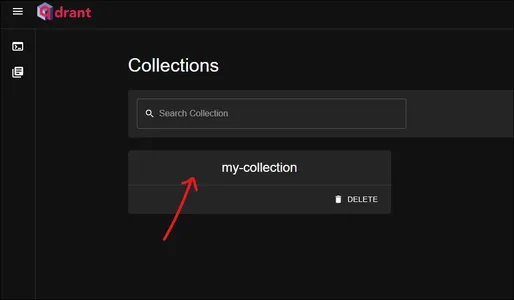
هذه هي لوحة القيادة qdrant. تحقق لدينا "مجموعتي"جمع هنا. اضغط عليها لترى ما بداخلها.

في سحابة Qdrant، نلاحظ أن نقاطنا (المتجهات + الحمولة + المعرفات) تُضاف بالفعل إلى مجموعتنا داخل مجموعتنا. في قسم المتابعة، سوف نتعلم كيفية الاستعلام عن هذه المتجهات.
الاستعلام عن قاعدة بيانات Qdrant Vector
في هذا القسم، سنجري الاستعلام عن قاعدة بيانات المتجهات وسنحاول أيضًا إضافة بعض المرشحات للحصول على نتيجة تمت تصفيتها. للاستعلام عن قاعدة بيانات متجهات qdrant الخاصة بنا، نحتاج أولاً إلى إنشاء متجه استعلام، وهو ما يمكننا القيام به عن طريق:
query = model.encode(['Animals live in the forest'])تضمين الاستعلام
ما يلي سوف يخلق لدينا سؤال التضمين. ثم باستخدام هذا، سوف نقوم بالاستعلام عن متجر المتجهات الخاص بنا للحصول على تضمينات المتجهات الأكثر صلة.
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 4
)
استعلام بحث
للاستعلام نستخدم بحث() طريقة كائن العميل وتمرير ما يلي:
- Collection_name: اسم مجموعتنا
- query_vector: متجه الاستعلام الذي نريد البحث فيه في متجر المتجهات
- قصر: كم عدد نتائج البحث التي نريدها بحث() وظيفة للحد أيضا
سيؤدي تشغيل الكود إلى إنتاج المخرجات التالية:
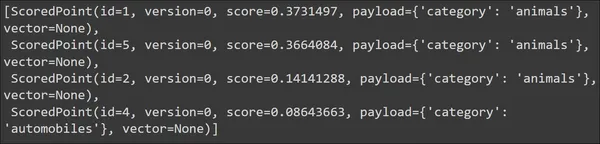
نرى أنه بالنسبة لاستعلامنا، فإن أهم المستندات التي تم استرجاعها هي من فئة الحيوانات. وبهذا يمكننا القول أن البحث فعال. والآن دعونا نجرب ذلك باستخدام استعلام آخر حتى يعطينا نتائج مختلفة. لا يتم عرض/جلب المتجهات بشكل افتراضي، ومن ثم يتم تعيينها على لا شيء.
query = model.encode(['Vehicles are polluting the world'])
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 3
)

الاستعلام المتعلق بالمركبات
هذه المرة قدمنا أ سؤال المتصلة السيارات تمكنت قاعدة بيانات المتجهات من جلب المستندات الخاصة بالفئة ذات الصلة (السيارات) في الأعلى بنجاح. الآن ماذا لو أردنا القيام ببعض التصفية؟ يمكننا القيام بذلك عن طريق:
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
query = model.encode(['Animals live in the forest'])
custom_filter = Filter(
must = [
FieldCondition(
key = "category",
match = MatchValue(
value="animals"
),
)
]
)
- أولاً، نقوم بإنشاء تضمين/ناقل الاستعلام الخاص بنا
- هنا نقوم باستيراد الفرز, FieldConditionو قيمة المباراة دروس من مكتبة qdrant.
- الفرز: استخدم هذه الفئة لإنشاء كائن تصفية
- FiledCondition: هذه الفئة مخصصة لإنشاء التصفية، مثل ما نريد تصفية بحثنا
- قيمة المباراة: هذه الفئة مخصصة لمعرفة قيمة المفتاح المحدد الذي نريد أن يقوم ناقل qdrant db بتصفيته
لذلك في الكود أعلاه، نقول بشكل أساسي أننا نقوم بإنشاء ملف الفرز الذي يتحقق من FieldCondition أن المفتاح "الفئة"في الحمولة اعواد الكبريت(قيمة المباراة) القيمة "الحيوانات". يبدو هذا كبيرًا بعض الشيء بالنسبة لمرشح بسيط، ولكن هذا النهج سيجعل الكود الخاص بنا أكثر تنظيماً عندما نتعامل مع ملف الحمولة تحتوي على الكثير من المعلومات ونريد تصفيتها على مفاتيح متعددة. الآن دعونا نستخدم الفلتر في بحثنا.
client.search(
collection_name = "my-collection",
query_vector = query[0],
query_filter = custom_filter,
limit = 4
)
Query_filter
هنا، هذه المرة، نحن حتى نستسلم query_filter المتغير الذي يأخذ في تصفية مخصص التي قمنا بتعريفها. لاحظ أننا احتفظنا بحد أقصى 4 لاسترداد أفضل 4 مستندات مطابقة. الاستعلام متعلق بالحيوانات. سيؤدي تشغيل الكود إلى الإخراج التالي:

في الإخراج، تلقينا فقط أعلى 3 مستندات أقرب على الرغم من أن لدينا 5 مستندات. وذلك لأننا قمنا بتعيين مرشحنا لاختيار فئات الحيوانات فقط ولا يوجد سوى 3 مستندات بهذه الفئة. بهذه الطريقة يمكننا تخزين تضمينات المتجهات في سحابة qdrant وإجراء بحث متجه على ناقلات التضمين هذه واسترداد الأقرب منها وحتى تطبيق المرشحات لتصفية المخرجات:
التطبيقات
يمكن للتطبيقات التالية قاعدة بيانات Qdrant Vector:
- أنظمة التوصية: يمكن لـ Qdrant تشغيل محركات التوصيات من خلال مطابقة المتجهات عالية الأبعاد بكفاءة، مما يجعلها مناسبة لتوصيات المحتوى المخصص في منصات مثل خدمات البث أو التجارة الإلكترونية أو وسائل التواصل الاجتماعي.
- استرجاع الصور والوسائط المتعددة: ومن خلال الاستفادة من قدرة Qdrant على التعامل مع المتجهات التي تمثل الصور ومحتوى الوسائط المتعددة، يمكن للتطبيقات تنفيذ وظائف بحث واسترجاع فعالة لقواعد بيانات الصور أو أرشيفات الوسائط المتعددة.
- تطبيقات معالجة اللغات الطبيعية (NLP): إن دعم Qdrant لتضمينات المتجهات يجعلها ذات قيمة لمهام البرمجة اللغوية العصبية (NLP)، مثل البحث الدلالي، ومطابقة تشابه المستندات، وتوصية المحتوى في التطبيقات التي تتعامل مع كميات كبيرة من مجموعات البيانات النصية.
- إكتشاف عيب خلقي: يمكن استخدام بحث المتجهات عالي الأبعاد الخاص بـ Qdrant في أنظمة الكشف عن الحالات الشاذة. من خلال مقارنة المتجهات التي تمثل السلوك الطبيعي مع البيانات الواردة، يمكن تحديد الحالات الشاذة في مجالات، مثل أمن الشبكات أو المراقبة الصناعية.
- البحث عن المنتج ومطابقته: في منصات التجارة الإلكترونية، تستطيع Qdrant تحسين قدرات البحث عن المنتج من خلال مطابقة المتجهات التي تمثل ميزات المنتج، وتسهيل توصيات المنتج الدقيقة والفعالة بناءً على تفضيلات المستخدم.
- التصفية على أساس المحتوى في الشبكات الاجتماعية: يمكن تطبيق بحث Qdrant المتجه في الشبكات الاجتماعية للتصفية المستندة إلى المحتوى. يمكن للمستخدمين الحصول على المحتوى ذي الصلة بناءً على تشابه تمثيلات المتجهات، مما يحسن مشاركة المستخدم.
وفي الختام
مع تزايد الطلب على التمثيل الفعال للبيانات، يبرز Qdrant باعتباره محرك بحث تشابه ناقلات مفتوح المصدر ومليء بالميزات، ومكتوب بلغة Rust القوية والمرتكزة على السلامة. يتضمن Qdrant جميع مقاييس المسافة الشائعة ويوفر طريقة قوية لتصفية بحث المتجهات الخاص بنا. بفضل ميزاته الغنية وبنيته السحابية الأصلية ومصطلحاته القوية، يفتح Qdrant الأبواب أمام عصر جديد في تكنولوجيا البحث عن تشابه المتجهات. على الرغم من أنها جديدة في هذا المجال، إلا أنها توفر مكتبات عملاء للعديد من لغات البرمجة وتوفر سحابة تتوسع بكفاءة مع الحجم.
الوجبات السريعة الرئيسية
بعض الوجبات الرئيسية تشمل ما يلي:
- يضمن Qdrant، المصنوع في Rust، السرعة والموثوقية، حتى في ظل الأحمال الثقيلة، مما يجعله الخيار الأفضل لمخازن المتجهات عالية الأداء.
- ما يميز Qdrant هو دعمها لواجهات برمجة تطبيقات العميل، التي تلبي احتياجات المطورين في Python وTypeScript/JavaScript وRust وGo.
- تستفيد Qdrant من خوارزمية HSNW وتوفر مقاييس مختلفة للمسافة، بما في ذلك Dot وCosine وEuclidean، مما يمكّن المطورين من اختيار المقياس الذي يتوافق مع حالات الاستخدام المحددة الخاصة بهم.
- تنتقل Qdrant بسلاسة إلى السحابة من خلال خدمة سحابية قابلة للتطوير، مما يوفر خيارًا مجانيًا للاستكشاف. وتضمن بنيتها السحابية الأصلية الأداء الأمثل، بغض النظر عن حجم البيانات.
الأسئلة المتكررة
ج: Qdrant هو محرك بحث لتشابه المتجهات ومتجر متجهات مكتوب بلغة Rust. ويتميز بسرعته وموثوقيته ودعمه الغني للعملاء، حيث يوفر واجهات برمجة التطبيقات لـ Python وTypeScript/JavaScript وRust وGo.
ج: يستخدم Qdrant خوارزمية HSNW ويعطي مقاييس مسافة مختلفة مثل Dot وCosine وEuclidean. يمكن للمطورين اختيار المقياس الذي يتوافق مع حالات الاستخدام المحددة الخاصة بهم عند إنشاء المجموعات.
ج: تتضمن المكونات المهمة المجموعات ومقاييس المسافة والنقاط (المتجهات والمعرفات الاختيارية والحمولات) وخيارات التخزين (In-Memory وMemmap).
ج: نعم، تتكامل Qdrant بسلاسة مع الخدمات السحابية، مما يوفر حلاً سحابيًا قابلاً للتطوير. تضمن البنية السحابية الأصلية الأداء الأمثل، مما يجعلها تتغير حسب أحجام البيانات والاحتياجات الحسابية المختلفة.
ج: يسمح Qdrant بتصفية معلومات الحمولة. يمكن للمستخدمين تحديد عوامل التصفية باستخدام مكتبة Qdrant، من خلال إعطاء شروط بناءً على مفاتيح الحمولة والقيم لتحسين نتائج البحث.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/11/a-deep-dive-into-qdrant-the-rust-based-vector-database/

