هذه مشاركة ضيف تمت كتابتها بالاشتراك مع فريق Meta's PyTorch وهي استمرار لـ جزء 1 من هذه السلسلة، حيث نعرض أداء وسهولة تشغيل PyTorch 2.0 على AWS.
أثبتت أبحاث التعلم الآلي (ML) أن نماذج اللغات الكبيرة (LLMs) التي تم تدريبها باستخدام مجموعات بيانات كبيرة بشكل كبير تؤدي إلى تحسين جودة النموذج. وفي السنوات القليلة الماضية، زاد حجم نماذج الجيل الحالي بشكل كبير، وهي تتطلب أدوات وبنية تحتية حديثة ليتم تدريبها بكفاءة وعلى نطاق واسع. تساعد تقنية PyTorch Distributed Data Parallelism (DDP) على معالجة البيانات على نطاق واسع بطريقة بسيطة وقوية، ولكنها تتطلب أن يتناسب النموذج مع وحدة معالجة رسومات واحدة. تكسر مكتبة PyTorch Fully Sharded Data Parallel (FSDP) هذا الحاجز من خلال تمكين مشاركة النماذج لتدريب نماذج كبيرة عبر العاملين المتوازيين للبيانات.
يتطلب التدريب النموذجي الموزع مجموعة من العقد العاملة التي يمكن توسيع نطاقها. خدمة أمازون مطاطا Kubernetes (Amazon EKS) هي خدمة شائعة متوافقة مع Kubernetes تعمل على تبسيط عملية تشغيل أعباء عمل AI/ML إلى حد كبير، مما يجعلها أكثر قابلية للإدارة وأقل استهلاكًا للوقت.
في منشور المدونة هذا، تتعاون AWS مع فريق Meta's PyTorch لمناقشة كيفية استخدام مكتبة PyTorch FSDP لتحقيق التوسع الخطي لنماذج التعلم العميق على AWS بسلاسة باستخدام Amazon EKS و حاويات AWS Deep Learning (المحتوى القابل للتنزيل). نوضح ذلك من خلال التنفيذ خطوة بخطوة لنماذج التدريب 7B و13B و70B Llama2 باستخدام Amazon EKS مع 16 الأمازون الحوسبة المرنة السحابية (أمازون EC2) p4de.24xlarge مثيلات (كل منها مزود بـ 8 وحدات معالجة رسوميات NVIDIA A100 Tensor Core وكل وحدة معالجة رسومات مزودة بذاكرة HBM80e سعة 2 جيجابايت) أو 16 EC2 تكبير مثيلات (تحتوي كل منها على 8 وحدات معالجة رسوميات NVIDIA H100 Tensor Core وكل وحدة معالجة رسومات تحتوي على ذاكرة HBM80 سعة 3 جيجابايت)، مما يحقق مقياسًا خطيًا تقريبًا في الإنتاجية ويتيح في النهاية وقت تدريب أسرع.
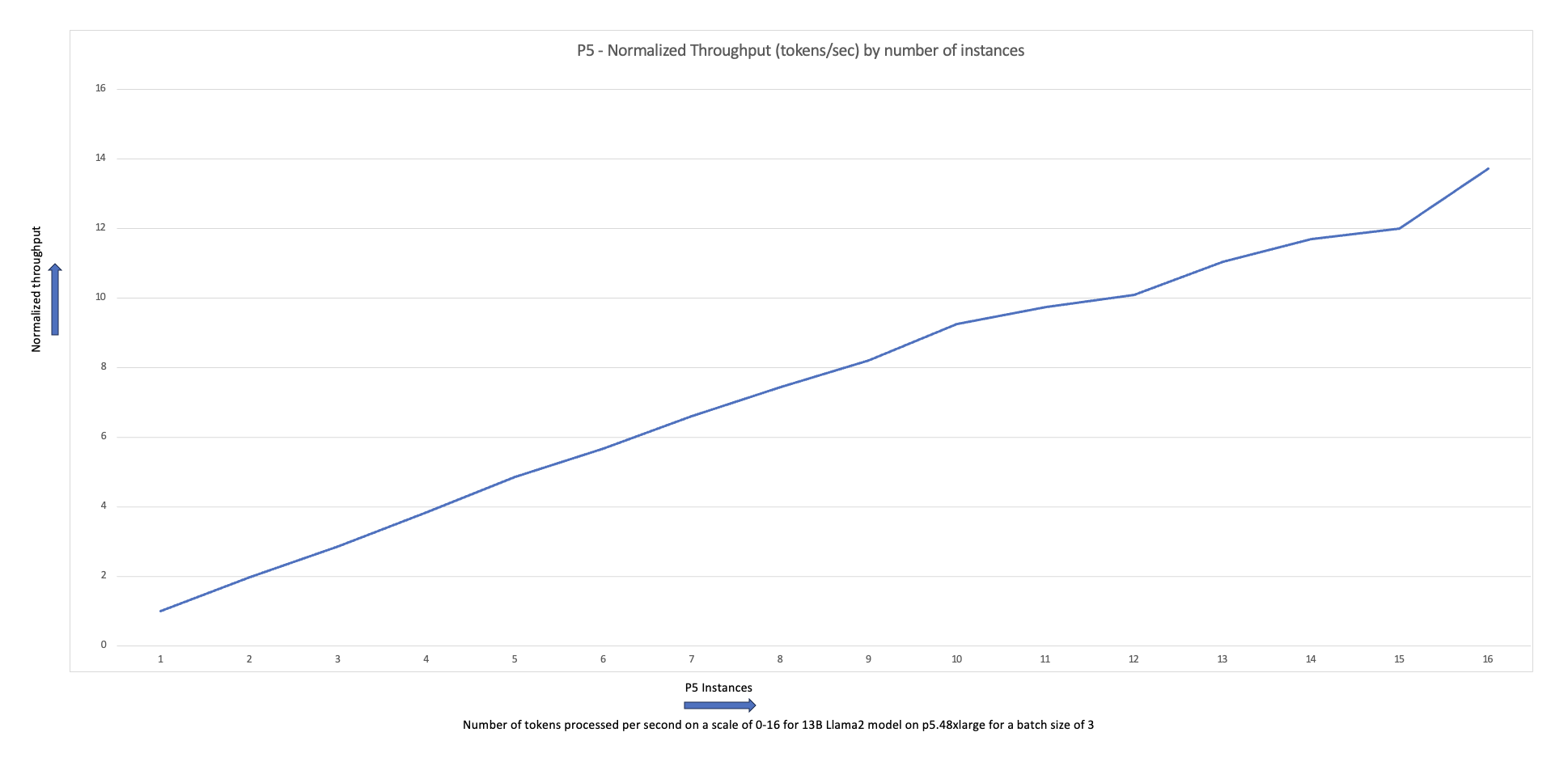
يوضح مخطط القياس التالي أن مثيلات p5.48xlarge توفر كفاءة قياس بنسبة 87% مع الضبط الدقيق لـ FSDP Llama2 في تكوين مجموعة مكون من 16 عقدة.
تحديات تدريب LLMs
تتبنى الشركات بشكل متزايد LLMs لمجموعة من المهام، بما في ذلك المساعدين الافتراضيين، والترجمة، وإنشاء المحتوى، ورؤية الكمبيوتر، لتعزيز الكفاءة والدقة في مجموعة متنوعة من التطبيقات.
ومع ذلك، يتطلب تدريب هذه النماذج الكبيرة أو تحسينها لحالة استخدام مخصصة كمية كبيرة من البيانات وقوة الحوسبة، مما يزيد من التعقيد الهندسي العام لمكدس تعلم الآلة. ويرجع ذلك أيضًا إلى محدودية الذاكرة المتوفرة على وحدة معالجة رسومات واحدة، مما يحد من حجم النموذج الذي يمكن تدريبه، ويحد أيضًا من حجم الدفعة لكل وحدة معالجة رسومات المستخدمة أثناء التدريب.
ولمواجهة هذا التحدي، تم استخدام تقنيات التوازي النموذجية المختلفة مثل DeepSpeed ZeRO و باي تورش FSDP تم إنشاؤها للسماح لك بالتغلب على هذا الحاجز المتمثل في ذاكرة GPU المحدودة. ويتم ذلك من خلال اعتماد تقنية متوازية للبيانات المجزأة، حيث يحمل كل مسرع شريحة فقط (أ قشرة) من نسخة متماثلة للنموذج بدلاً من النسخة المتماثلة للنموذج بالكامل، مما يقلل بشكل كبير من أثر الذاكرة لمهمة التدريب.
يوضح هذا المنشور كيف يمكنك استخدام PyTorch FSDP لضبط نموذج Llama2 باستخدام Amazon EKS. نحن نحقق ذلك من خلال توسيع نطاق سعة الحوسبة ووحدة معالجة الرسومات لتلبية متطلبات النموذج.
نظرة عامة على FSDP
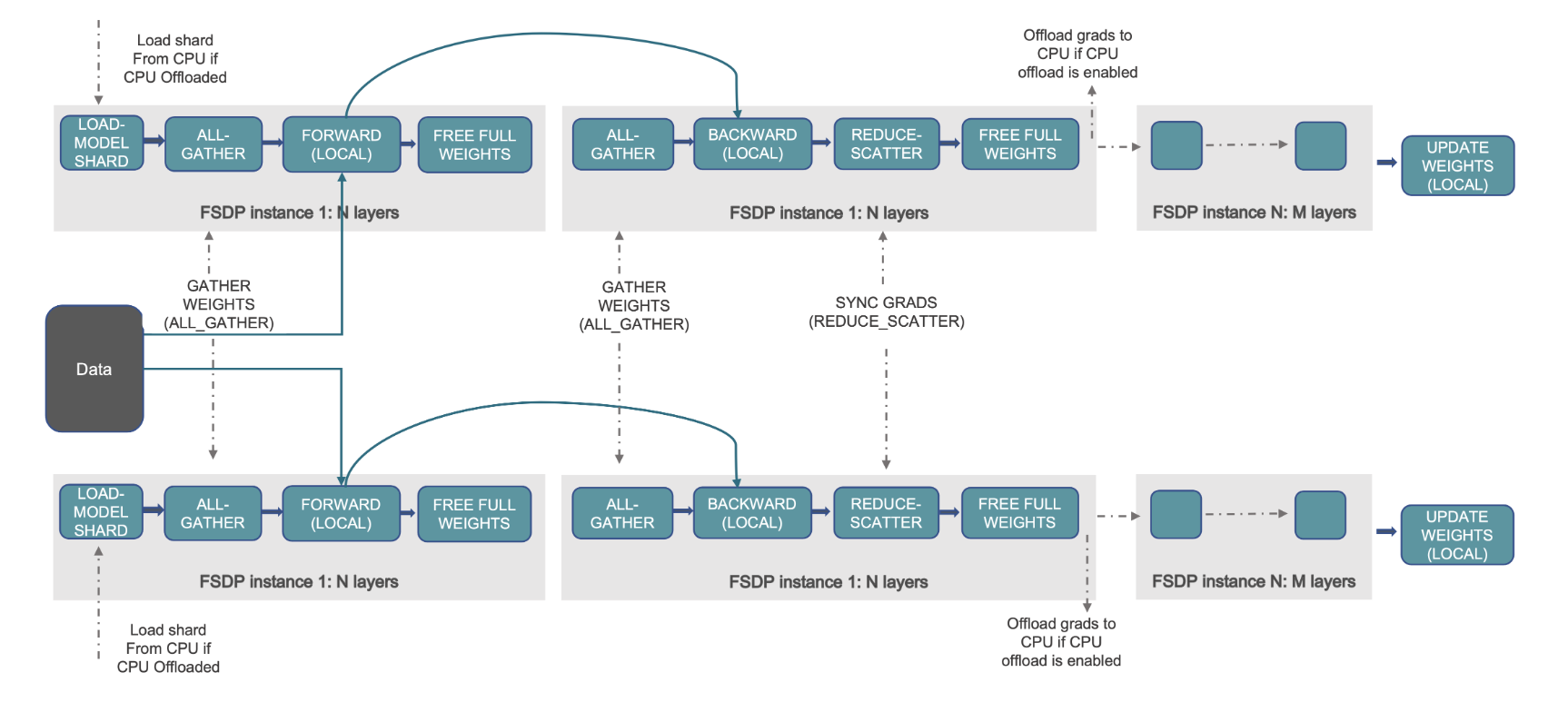
في تدريب PyTorch DDP، كل وحدة معالجة رسومات (يشار إليها باسم عامل في سياق PyTorch) يحمل نسخة كاملة من النموذج، بما في ذلك أوزان النموذج والتدرجات وحالات المُحسِّن. يقوم كل عامل بمعالجة مجموعة من البيانات، وفي نهاية التمريرة الخلفية، يستخدم كل الحد عملية لمزامنة التدرجات عبر مختلف العمال.
يؤدي وجود نسخة طبق الأصل من النموذج على كل وحدة معالجة رسومات إلى تقييد حجم النموذج الذي يمكن استيعابه في سير عمل DDP. يساعد FSDP في التغلب على هذا القيد من خلال مشاركة معلمات النموذج وحالات المُحسِّن والتدرجات عبر العاملين المتوازيين للبيانات مع الحفاظ على بساطة توازي البيانات.
يتم توضيح ذلك في الرسم البياني التالي، حيث في حالة DDP، تحتفظ كل وحدة معالجة رسومات بنسخة كاملة من حالة النموذج، بما في ذلك حالة المحسن (OS)، والتدرجات (G)، والمعلمات (P): M(OS + G) + ف). في FSDP، تحتفظ كل وحدة معالجة رسومات (GPU) فقط بشريحة من حالة النموذج، بما في ذلك حالة المحسن (OS)، والتدرجات (G)، والمعلمات (P): M (نظام التشغيل + جي + ف). يؤدي استخدام FSDP إلى بصمة ذاكرة GPU أصغر بكثير مقارنة بـ DDP عبر جميع العاملين، مما يتيح تدريب نماذج كبيرة جدًا أو استخدام أحجام دفعات أكبر لمهام التدريب.

ومع ذلك، يأتي هذا على حساب زيادة حمل الاتصالات، والذي يتم تخفيفه من خلال تحسينات FSDP مثل عمليات الاتصال والحساب المتداخلة مع ميزات مثل الجلب المسبق. لمزيد من المعلومات التفصيلية، راجع البدء باستخدام البيانات المتوازية بالكامل (FSDP).
يقدم FSDP العديد من المعلمات التي تسمح لك بضبط أداء وكفاءة وظائف التدريب الخاصة بك. تتضمن بعض الميزات والقدرات الرئيسية لـ FSDP ما يلي:
- سياسة تغليف المحولات
- دقة مختلطة مرنة
- تفعيل نقاط التفتيش
- استراتيجيات تقسيم مختلفة لتناسب سرعات الشبكة المختلفة وطوبولوجيات المجموعة:
- FULL_SHARD - معلمات نموذج Shard والتدرجات وحالات المُحسّن
- HYBRID_SHARD - جزء كامل داخل عقدة DDP عبر العقد؛ يدعم مجموعة مشاركة مرنة لنسخة طبق الأصل كاملة من النموذج (HSDP)
- SHARD_GRAD_OP - Shard التدرجات وحالات المحسن فقط
- NO_SHARD – على غرار DDP
لمزيد من المعلومات حول FSDP، راجع تدريب فعال واسع النطاق باستخدام Pytorch FSDP وAWS.
يوضح الشكل التالي كيفية عمل FSDP لعمليتين متوازيتين للبيانات.
حل نظرة عامة
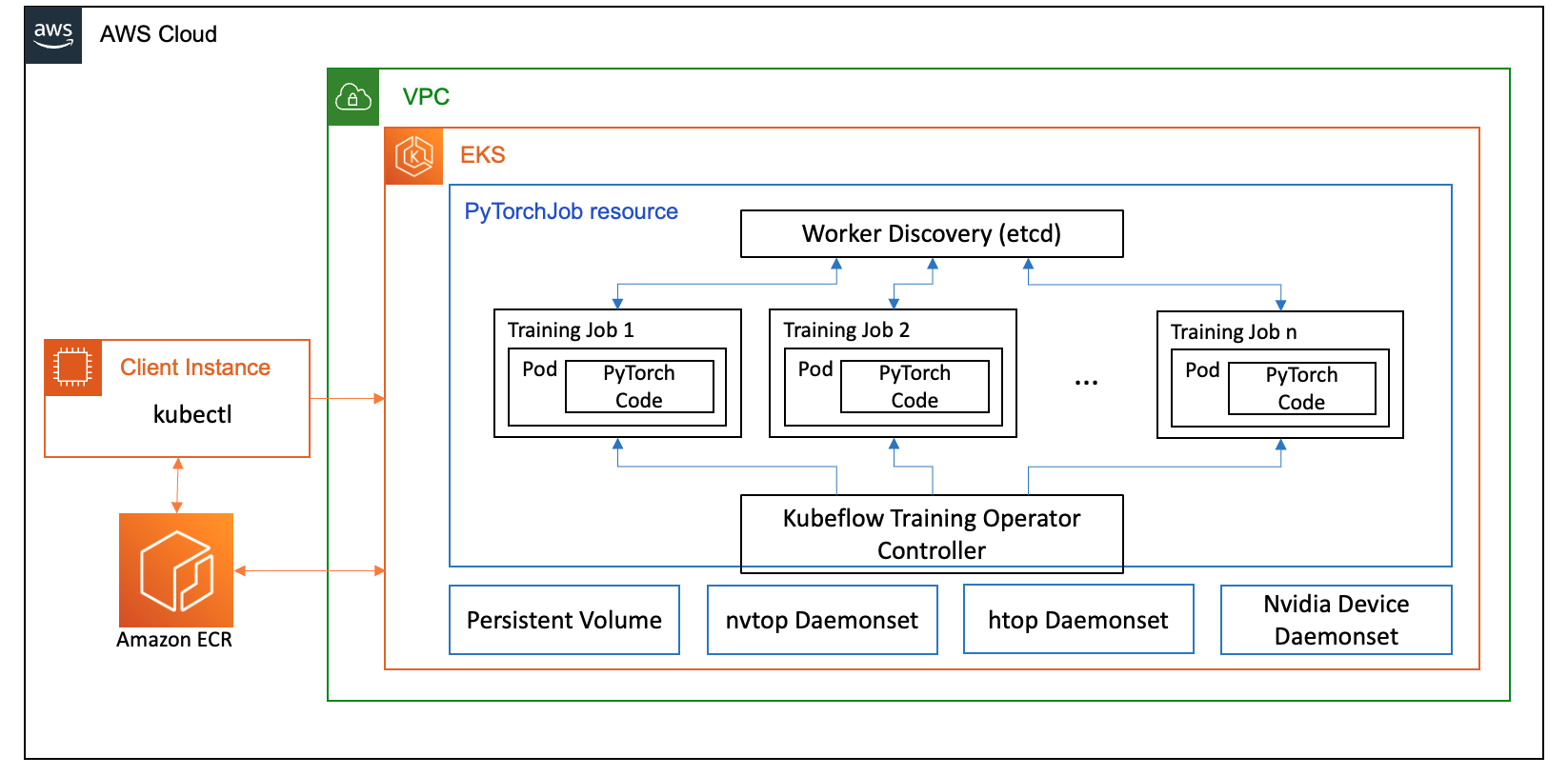
في هذا المنشور، قمنا بإعداد مجموعة حوسبة باستخدام Amazon EKS، وهي خدمة مُدارة لتشغيل Kubernetes في سحابة AWS ومراكز البيانات المحلية. يستخدم العديد من العملاء Amazon EKS لتشغيل أعباء عمل AI/ML المستندة إلى Kubernetes، مع الاستفادة من أدائها وقابلية التوسع والموثوقية والتوافر، بالإضافة إلى تكاملها مع شبكات AWS والأمن والخدمات الأخرى.
بالنسبة لحالة استخدام FSDP الخاصة بنا، نستخدم ملف مشغل تدريب Kubeflow على Amazon EKS، وهو مشروع أصلي من Kubernetes يسهل الضبط الدقيق والتدريب الموزع القابل للتطوير لنماذج تعلم الآلة. وهو يدعم أطر عمل تعلم الآلة المختلفة، بما في ذلك PyTorch، والتي يمكنك استخدامها لنشر وإدارة وظائف تدريب PyTorch على نطاق واسع.
باستخدام مورد PyTorchJob المخصص لمشغل تدريب Kubeflow، نقوم بتشغيل وظائف تدريبية على Kubernetes مع عدد قابل للتكوين من النسخ المتماثلة للعاملين مما يسمح لنا بتحسين استخدام الموارد.
فيما يلي بعض مكونات مشغل التدريب التي تلعب دورًا في حالة استخدام الضبط الدقيق لـ Llama2:
- وحدة تحكم Kubernetes مركزية تعمل على تنسيق وظائف التدريب الموزعة لـ PyTorch.
- PyTorchJob، هو مورد Kubernetes مخصص لـ PyTorch، مقدم من مشغل تدريب Kubeflow، لتحديد ونشر وظائف تدريب Llama2 على Kubernetes.
- إلخ، والذي يتعلق بتنفيذ آلية الالتقاء لتنسيق التدريب الموزع لنماذج PyTorch. هذا
etcdيقوم الخادم، كجزء من عملية الالتقاء، بتسهيل التنسيق والمزامنة بين العاملين المشاركين أثناء التدريب الموزع.
يوضح الرسم البياني التالي بنية الحل.
سيتم تلخيص معظم التفاصيل من خلال البرامج النصية للأتمتة التي نستخدمها لتشغيل مثال Llama2.
نستخدم مراجع التعليمات البرمجية التالية في حالة الاستخدام هذه:
ما هو لاما 2؟
Llama2 هو برنامج LLM تم تدريبه مسبقًا على 2 تريليون رمز من النصوص والتعليمات البرمجية. إنها واحدة من أكبر وأقوى برامج LLM المتاحة اليوم. يمكنك استخدام Llama2 لمجموعة متنوعة من المهام، بما في ذلك معالجة اللغة الطبيعية (NLP)، وإنشاء النصوص، والترجمة. لمزيد من المعلومات، راجع الشروع في العمل مع اللاما.
يتوفر Llama2 بثلاثة أحجام مختلفة للنماذج:
- اللاما2-70ب - هذا هو أكبر نموذج Llama2، مع 70 مليار معلمة. إنه أقوى طراز Llama2 ويمكن استخدامه للمهام الأكثر تطلبًا.
- اللاما2-13ب - هذا نموذج Llama2 متوسط الحجم، به 13 مليار معلمة. إنه توازن جيد بين الأداء والكفاءة، ويمكن استخدامه لمجموعة متنوعة من المهام.
- اللاما2-7ب - هذا هو أصغر نموذج Llama2، مع 7 مليار معلمة. إنه نموذج Llama2 الأكثر كفاءة، ويمكن استخدامه للمهام التي لا تتطلب أعلى مستوى من الأداء.
يمكّنك هذا المنشور من ضبط جميع هذه النماذج على Amazon EKS. لتوفير تجربة بسيطة وقابلة للتكرار لإنشاء مجموعة EKS وتشغيل وظائف FSDP عليها، نستخدم aws-do-eks مشروع. سيعمل المثال أيضًا مع مجموعة EKS الموجودة مسبقًا.
تتوفر إرشادات مكتوبة على GitHub جيثب: لتجربة خارج الصندوق. في الأقسام التالية، نشرح العملية الشاملة بمزيد من التفصيل.
توفير البنية التحتية للحل
بالنسبة للتجارب الموضحة في هذا المنشور، نستخدم مجموعات ذات عقد p4de (A100 GPU) وp5 (H100 GPU).
مجموعة ذات عقد p4de.24xlarge
بالنسبة لمجموعتنا التي تحتوي على عقد p4de، نستخدم ما يلي eks-gpu-p4de-odcr.yaml النصي:
باستخدام eksctl وبيان المجموعة السابق، نقوم بإنشاء مجموعة تحتوي على عقد p4de:
مجموعة ذات عقد p5.48xlarge
يوجد قالب terraform لمجموعة EKS مع عقد P5 فيما يلي جيثب ريبو.
يمكنك تخصيص المجموعة عبر المتغيرات.tf الملف ثم قم بإنشائه عبر Terraform CLI:
يمكنك التحقق من توفر المجموعة عن طريق تشغيل أمر kubectl بسيط:
تكون المجموعة سليمة إذا أظهر ناتج هذا الأمر العدد المتوقع من العقد في حالة الاستعداد.
نشر المتطلبات الأساسية
لتشغيل FSDP على Amazon EKS، نستخدم ملف PyTorchJob الموارد المخصصة. يتطلب إلخ و مشغل تدريب Kubeflow كشروط مسبقة.
انشر etcd بالكود التالي:
قم بنشر مشغل تدريب Kubeflow بالكود التالي:
أنشئ صورة حاوية FSDP وادفعها إلى Amazon ECR
استخدم التعليمة البرمجية التالية لإنشاء صورة حاوية FSDP ودفعها إلى سجل الأمازون المرنة للحاويات (أمازون ECR):
قم بإنشاء بيان FSDP PyTorchJob
أدخل الخاص بك معانقة رمز الوجه في المقتطف التالي قبل تشغيله:
قم بتكوين PyTorchJob الخاص بك باستخدام .env ملف أو مباشرة في متغيرات البيئة الخاصة بك على النحو التالي:
قم بإنشاء بيان PyTorchJob باستخدام ملف قالب fsdp و إنشاء.sh البرنامج النصي أو إنشائه مباشرة باستخدام البرنامج النصي أدناه:
قم بتشغيل PyTorchJob
قم بتشغيل PyTorchJob بالكود التالي:
سترى العدد المحدد من كبسولات عامل FDSP التي تم إنشاؤها، وبعد سحب الصورة، ستدخل في حالة التشغيل.
لمعرفة حالة PyTorchJob، استخدم الكود التالي:
لإيقاف PyTorchJob، استخدم الكود التالي:
بعد اكتمال المهمة، يجب حذفها قبل بدء تشغيل جديد. لقد لاحظنا أيضًا أن حذفetcdيساعد pod والسماح له بإعادة التشغيل قبل بدء وظيفة جديدة على تجنب حدوث خطأ RendezvousClosedError.
مقياس الكتلة
يمكنك تكرار الخطوات السابقة لإنشاء المهام وتشغيلها مع تغيير عدد ونوع مثيل العقد العاملة في المجموعة. يمكّنك هذا من إنتاج مخططات قياس مثل تلك الموضحة مسبقًا. بشكل عام، يجب أن ترى انخفاضًا في مساحة ذاكرة وحدة معالجة الرسومات، وانخفاضًا في وقت العصر، وزيادة في الإنتاجية عند إضافة المزيد من العقد إلى المجموعة. تم إنتاج المخطط السابق من خلال إجراء عدة تجارب باستخدام مجموعة عقدة p5 تتراوح من 1 إلى 16 عقدة في الحجم.
مراقبة عبء العمل التدريبي FSDP
تعد إمكانية ملاحظة أعباء عمل الذكاء الاصطناعي التوليدي أمرًا مهمًا للسماح برؤية وظائفك الجارية بالإضافة إلى المساعدة في تحقيق أقصى استفادة من موارد الحوسبة لديك. في هذا المنشور، نستخدم عددًا قليلاً من أدوات المراقبة الأصلية والمفتوحة المصدر في Kubernetes لهذا الغرض. تمكنك هذه الأدوات من تتبع الأخطاء والإحصائيات وسلوك النماذج، مما يجعل إمكانية ملاحظة الذكاء الاصطناعي جزءًا مهمًا من أي حالة استخدام تجاري. في هذا القسم، نعرض طرقًا مختلفة لمراقبة وظائف تدريب FSDP.
سجلات جراب العامل
على المستوى الأساسي، يجب أن تكون قادرًا على رؤية سجلات حجرات التدريب الخاصة بك. يمكن القيام بذلك بسهولة باستخدام أوامر Kubernetes الأصلية.
أولاً، قم باسترداد قائمة البودات وحدد اسم البودات التي تريد رؤية سجلاتها:
ثم قم بعرض السجلات الخاصة بالجراب المحدد:

سيقوم سجل جراب عامل واحد فقط (قائد منتخب) بإدراج إحصائيات الوظيفة الإجمالية. يتوفر اسم حجرة القائد المنتخب في بداية كل سجل حجرة عامل، ويتم تحديده بواسطة المفتاح master_addr=.
استخدام وحدة المعالجة المركزية
تتطلب أحمال عمل التدريب الموزعة موارد وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU). لتحسين أعباء العمل هذه، من المهم فهم كيفية استخدام هذه الموارد. لحسن الحظ، تتوفر بعض الأدوات المساعدة الرائعة مفتوحة المصدر التي تساعد في تصور استخدام وحدة المعالجة المركزية ووحدة معالجة الرسومات. لعرض استخدام وحدة المعالجة المركزية، يمكنك استخدامhtop. إذا كانت حجرات العمل الخاصة بك تحتوي على هذه الأداة المساعدة، فيمكنك استخدام الأمر أدناه لفتح غلاف في حجرة ثم تشغيلهاhtop.
وبدلاً من ذلك، يمكنك نشر ملف htopdaemonsetمثل تلك الواردة في ما يلي جيثب ريبو.
•daemonsetسيتم تشغيل جراب htop خفيف الوزن على كل عقدة. يمكنك التنفيذ في أي من هذه القرون وتشغيلhtopأمر:
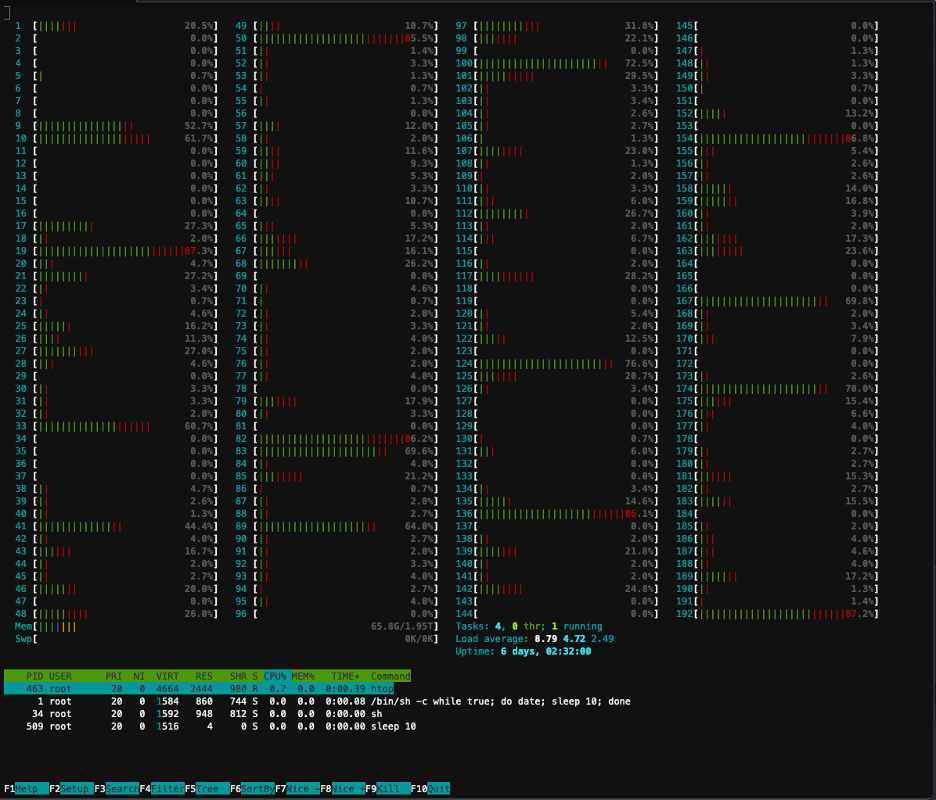
توضح لقطة الشاشة التالية استخدام وحدة المعالجة المركزية (CPU) على إحدى العقد الموجودة في المجموعة. في هذه الحالة، نحن ننظر إلى مثيل P5.48xlarge، الذي يحتوي على 192 وحدة معالجة مركزية افتراضية. تكون نوى المعالج في وضع الخمول أثناء تنزيل أوزان النموذج، ونرى استخدامًا متزايدًا أثناء تحميل أوزان النموذج على ذاكرة وحدة معالجة الرسومات.
استخدام GPU
إذا كانnvtopالأداة المساعدة متاحة في حجرتك، ويمكنك تنفيذها باستخدام ما يلي ثم تشغيلهاnvtop.
وبدلاً من ذلك، يمكنك نشر ملف nvtopdaemonsetمثل تلك الواردة في ما يلي جيثب ريبو.
سيتم تشغيل هذاnvtopجراب على كل عقدة. يمكنك التنفيذ في أي من تلك القرون والتشغيلnvtop:
توضح لقطة الشاشة التالية استخدام وحدة معالجة الرسومات (GPU) على إحدى العقد الموجودة في مجموعة التدريب. في هذه الحالة، نحن ننظر إلى مثيل P5.48xlarge، الذي يحتوي على 8 وحدات معالجة رسوميات NVIDIA H100. تكون وحدات معالجة الرسومات في وضع الخمول أثناء تنزيل أوزان النموذج، ثم يزداد استخدام ذاكرة وحدة معالجة الرسومات عندما يتم تحميل أوزان النموذج على وحدة معالجة الرسومات، ويرتفع استخدام وحدة معالجة الرسومات إلى 100% بينما تكون تكرارات التدريب جارية.

لوحة القيادة جرافانا
الآن بعد أن فهمت كيفية عمل نظامك على مستوى الجراب والعقدة، من المهم أيضًا النظر إلى المقاييس على مستوى المجموعة. يمكن جمع مقاييس الاستخدام المجمعة بواسطة NVIDIA DCGM Exporter وPrometheus وتصورها في Grafana.
يتوفر مثال لنشر Prometheus-Grafana في ما يلي جيثب ريبو.
يتوفر مثال لنشر مصدر DCGM فيما يلي جيثب ريبو.
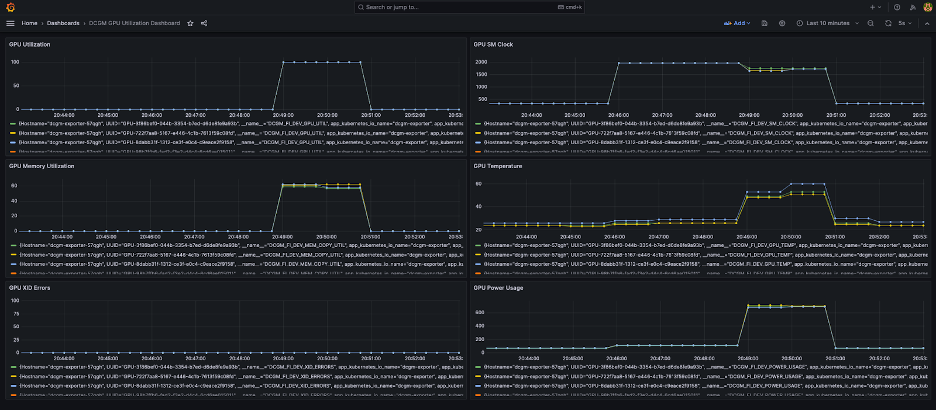
تظهر لوحة معلومات Grafana البسيطة في لقطة الشاشة التالية. تم إنشاؤه عن طريق تحديد مقاييس DCGM التالية: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMPو DCGM_FI_DEV_POWER_USAGE. يمكن استيراد لوحة القيادة إلى Prometheus من GitHub جيثب:.
تعرض لوحة المعلومات التالية تشغيلًا واحدًا لمهمة تدريب Llama2 7b ذات الحقبة الواحدة. توضح الرسوم البيانية أنه مع زيادة ساعة المعالجات المتعددة المتدفقة (SM)، يزداد أيضًا استهلاك الطاقة ودرجة حرارة وحدات معالجة الرسومات، جنبًا إلى جنب مع وحدة معالجة الرسومات واستخدام الذاكرة. يمكنك أيضًا ملاحظة عدم وجود أخطاء XID وأن وحدات معالجة الرسومات كانت سليمة أثناء هذا التشغيل.
منذ مارس 2024، أصبحت إمكانية ملاحظة GPU لـ EKS مدعومة أصلاً في رؤى حاوية CloudWatch. لتمكين هذه الوظيفة، ما عليك سوى نشر الوظيفة الإضافية CloudWatch Observability في مجموعة EKS الخاصة بك. ستتمكن بعد ذلك من تصفح مقاييس مستوى المجموعة والعقدة والمجموعة من خلال لوحات المعلومات المكونة مسبقًا والقابلة للتخصيص في Container Insights.
تنظيف
إذا قمت بإنشاء مجموعتك باستخدام الأمثلة الواردة في هذه المدونة، فيمكنك تنفيذ التعليمات البرمجية التالية لحذف المجموعة وأي موارد مرتبطة بها، بما في ذلك VPC:
بالنسبة إلى إكسكتل:
بالنسبة للتضاريس:
الميزات القادمة
من المتوقع أن يتضمن FSDP ميزة تقسيم لكل معلمة، بهدف تحسين بصمة الذاكرة الخاصة به لكل وحدة معالجة رسومات. بالإضافة إلى ذلك، يهدف التطوير المستمر لدعم FP8 إلى تحسين أداء FSDP على وحدات معالجة الرسوميات H100. وأخيرا، عندما يتم دمج FSDP معtorch.compile، نأمل أن نرى تحسينات إضافية في الأداء وتمكين ميزات مثل فحص التنشيط الانتقائي.
وفي الختام
في هذا المنشور، ناقشنا كيف يقلل FSDP من أثر الذاكرة على كل وحدة معالجة رسومات، مما يتيح تدريب النماذج الأكبر بشكل أكثر كفاءة وتحقيق تحجيم خطي تقريبًا في الإنتاجية. لقد أظهرنا ذلك من خلال التنفيذ خطوة بخطوة لتدريب نموذج Llama2 باستخدام Amazon EKS على مثيلات P4de وP5 واستخدمنا أدوات إمكانية المراقبة مثل kubectl وhtop وnvtop وdcgm لمراقبة السجلات، بالإضافة إلى استخدام وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU).
نحن نشجعك على الاستفادة من PyTorch FSDP في وظائف تدريب LLM الخاصة بك. ابدأ في أوس دو fsdp.
حول المؤلف
 كانوالجيت خورمي هو مهندس حلول AI/ML رئيسي في Amazon Web Services. وهو يعمل مع عملاء AWS لتقديم التوجيه والمساعدة الفنية، ومساعدتهم على تحسين قيمة حلول التعلم الآلي الخاصة بهم على AWS. تتخصص Kanwaljit في مساعدة العملاء في تطبيقات الحوسبة الموزعة والحاويات والتعلم العميق.
كانوالجيت خورمي هو مهندس حلول AI/ML رئيسي في Amazon Web Services. وهو يعمل مع عملاء AWS لتقديم التوجيه والمساعدة الفنية، ومساعدتهم على تحسين قيمة حلول التعلم الآلي الخاصة بهم على AWS. تتخصص Kanwaljit في مساعدة العملاء في تطبيقات الحوسبة الموزعة والحاويات والتعلم العميق.
 أليكس يانكولسكي هو مهندس الحلول الرئيسي للتعلم الآلي المُدار ذاتيًا في AWS. إنه مهندس برمجيات وبنية تحتية متكامل يحب القيام بعمل عميق وعملي. في منصبه، يركز على مساعدة العملاء في النقل بالحاويات وتنسيق أعباء عمل تعلم الآلة والذكاء الاصطناعي على خدمات AWS التي تعمل بالحاويات. وهو أيضًا مؤلف المصدر المفتوح تفعل الإطار وكابتن Docker الذي يحب تطبيق تقنيات الحاويات لتسريع وتيرة الابتكار مع حل أكبر التحديات في العالم.
أليكس يانكولسكي هو مهندس الحلول الرئيسي للتعلم الآلي المُدار ذاتيًا في AWS. إنه مهندس برمجيات وبنية تحتية متكامل يحب القيام بعمل عميق وعملي. في منصبه، يركز على مساعدة العملاء في النقل بالحاويات وتنسيق أعباء عمل تعلم الآلة والذكاء الاصطناعي على خدمات AWS التي تعمل بالحاويات. وهو أيضًا مؤلف المصدر المفتوح تفعل الإطار وكابتن Docker الذي يحب تطبيق تقنيات الحاويات لتسريع وتيرة الابتكار مع حل أكبر التحديات في العالم.
 آنا سيموس هو متخصص رئيسي في تعلم الآلة، ML Frameworks في AWS. إنها تدعم العملاء الذين ينشرون الذكاء الاصطناعي والتعلم الآلي والذكاء الاصطناعي التوليدي على نطاق واسع على البنية التحتية للحوسبة عالية الأداء (HPC) في السحابة. تركز Ana على دعم العملاء لتحقيق أداء السعر لأعباء العمل الجديدة وحالات الاستخدام للذكاء الاصطناعي التوليدي والتعلم الآلي.
آنا سيموس هو متخصص رئيسي في تعلم الآلة، ML Frameworks في AWS. إنها تدعم العملاء الذين ينشرون الذكاء الاصطناعي والتعلم الآلي والذكاء الاصطناعي التوليدي على نطاق واسع على البنية التحتية للحوسبة عالية الأداء (HPC) في السحابة. تركز Ana على دعم العملاء لتحقيق أداء السعر لأعباء العمل الجديدة وحالات الاستخدام للذكاء الاصطناعي التوليدي والتعلم الآلي.
 حميد شوجنازيري هو مهندس شريك في PyTorch يعمل على تحسين النماذج مفتوحة المصدر وعالية الأداء والتدريب الموزع (FSDP)، والاستدلال. وهو المؤسس المشارك لـ وصفة اللاما ومساهم في تورش سيرف. اهتمامه الرئيسي هو تحسين فعالية التكلفة، مما يجعل الذكاء الاصطناعي في متناول المجتمع الأوسع.
حميد شوجنازيري هو مهندس شريك في PyTorch يعمل على تحسين النماذج مفتوحة المصدر وعالية الأداء والتدريب الموزع (FSDP)، والاستدلال. وهو المؤسس المشارك لـ وصفة اللاما ومساهم في تورش سيرف. اهتمامه الرئيسي هو تحسين فعالية التكلفة، مما يجعل الذكاء الاصطناعي في متناول المجتمع الأوسع.
 أقل رايت هو مهندس ذكاء اصطناعي/شريك في PyTorch. يعمل على حبات Triton/CUDA (تسريع Dequant مع تحليل العمل SplitK); مُحسِّنات مقسمة إلى صفحات، ومتدفقة، ومُكمَّمة؛ وPyTorch الموزعة (باي تورش FSDP).
أقل رايت هو مهندس ذكاء اصطناعي/شريك في PyTorch. يعمل على حبات Triton/CUDA (تسريع Dequant مع تحليل العمل SplitK); مُحسِّنات مقسمة إلى صفحات، ومتدفقة، ومُكمَّمة؛ وPyTorch الموزعة (باي تورش FSDP).
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

