المُقدّمة
عندما نسمع علم البيانات، أول ما يتبادر إلى ذهننا هو بناء نموذج على دفاتر الملاحظات وتدريب البيانات. لكن هذا ليس هو الوضع في علم البيانات في العالم الحقيقي. في العالم الحقيقي، يقوم علماء البيانات ببناء النماذج ووضعها في مرحلة الإنتاج. تحتوي بيئة الإنتاج على فجوة بين تطوير النموذج ونشره وموثوقيته وتسهيل العمليات الفعالة والقابلة للتطوير. هذا هو المكان الذي يستخدمه علماء البيانات MLOps (عمليات التعلم الآلي) لبناء ونشر تطبيقات تعلم الآلة في بيئة الإنتاج. في هذه المقالة، سنقوم ببناء ونشر مشروع للتنبؤ بتراجع العملاء باستخدام MLOps.

أهداف التعلم
في هذه المقالة سوف تتعلم:
- نظرة عامة على المشروع
- سوف نقدم أساسيات ZenML وMLOPS.
- تعرف على كيفية نشر النموذج محليًا للتنبؤ
- ادخل في المعالجة المسبقة للبيانات والهندسة والتدريب وتقييم النموذج
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
نظرة عامة على المشروع
بادئ ذي بدء، علينا أن نفهم ما هو مشروعنا. بالنسبة لهذا المشروع، لدينا مجموعة بيانات من شركة اتصالات. الآن، لبناء نموذج للتنبؤ بما إذا كان من المحتمل أن يستمر المستخدم في خدمة الشركة أم لا. سنقوم ببناء تطبيق ML هذا باستخدام مساعدة ZenmML و MLFlow. هذا هو سير العمل لمشروعنا.
سير العمل في مشروعنا
- جمع البيانات
- معالجة البيانات
- نموذج التدريب
- تقييم النموذج
- قابل للفتح
ما هو MLOps؟
MLOps عبارة عن دورة حياة شاملة للتعلم الآلي، بدءًا من التطوير وحتى النشر والصيانة المستمرة. MLOps هي ممارسة لتبسيط وأتمتة دورة الحياة الكاملة لنماذج التعلم الآلي، كل ذلك مع ضمان قابلية التوسع والموثوقية والكفاءة.
دعونا نشرح ذلك بمثال بسيط:
تخيل أنك تقوم ببناء ناطحة سحاب في مدينتك. تم الانتهاء من تشييد المبنى. ولكنها تفتقر إلى الكهرباء والمياه ونظام الصرف الصحي، وما إلى ذلك. وستكون ناطحة السحاب غير عاملة وغير عملية.
الأمر نفسه ينطبق على نماذج التعلم الآلي. إذا تم تصميم هذه النماذج دون الأخذ في الاعتبار نشر النموذج وقابلية التوسع والصيانة طويلة المدى، فقد تصبح غير فعالة وغير عملية. يشكل هذا عقبة كبيرة أمام علماء البيانات عند إنشاء نماذج التعلم الآلي لاستخدامها في بيئات الإنتاج.
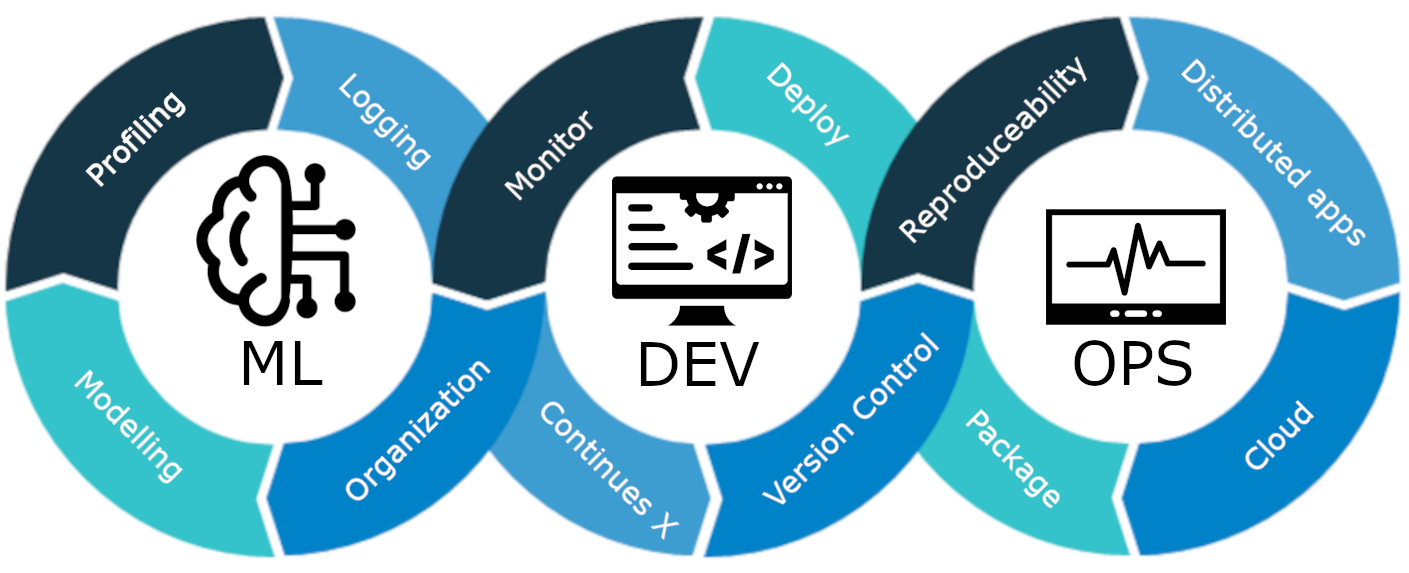
MLOps عبارة عن مجموعة من أفضل الممارسات والاستراتيجيات التي توجه إنتاج نماذج التعلم الآلي ونشرها وصيانتها على المدى الطويل. فهو يضمن أن هذه النماذج لا تقدم تنبؤات دقيقة فحسب، بل تظل أيضًا أصولًا قوية وقابلة للتطوير وقيمة للشركات. لذلك، بدون MLOps، سيكون القيام بكل هذه المهام بكفاءة بمثابة كابوس، وهو أمر يمثل تحديًا. في هذا المشروع، سنشرح كيفية عمل MLOps، والمراحل المختلفة، ومشروعًا شاملاً حول كيفية بناء العميل. التنبؤ بالمخضبة نموذج.
تقديم ZenML
ZenML هو إطار عمل MLOPS مفتوح المصدر يساعد في إنشاء خطوط أنابيب محمولة وجاهزة للإنتاج. سيساعدنا إطار عمل ZenML على تنفيذ هذا المشروع باستخدام MLOPS.
⚠️ إذا كنت من مستخدمي Windows، فحاول تثبيت wsl على جهاز الكمبيوتر. Zenml غير مدعوم في نظام التشغيل Windows.
قبل أن ننتقل إلى المشاريع.
المفاهيم الأساسية لـ MLOPS
- خطوات: الخطوات عبارة عن وحدات فردية من المهام في المسار أو سير العمل. تمثل كل خطوة إجراءً أو عملية محددة يجب تنفيذها لتطوير سير عمل التعلم الآلي. على سبيل المثال، يعد تنظيف البيانات، والمعالجة المسبقة للبيانات، ونماذج التدريب، وما إلى ذلك، خطوات معينة في تطوير نموذج التعلم الآلي.
- خطوط الأنابيب: يربطون خطوات متعددة معًا لإنشاء عملية منظمة ومؤتمتة لمهام التعلم الآلي. على سبيل المثال، خط أنابيب معالجة البيانات، وخط أنابيب تقييم النموذج، وخط أنابيب التدريب النموذجي.
كيف تبدأ
إنشاء بيئة افتراضية للمشروع:
conda create -n churn_prediction python=3.9ثم قم بتثبيت هذه المكتبات:
pip install numpy pandas matplotlib scikit-learnبعد تثبيت هذا، قم بتثبيت ZenML:
pip install zenml["server"]ثم قم بتهيئة مستودع ZenML.
zenml init
سوف تحصل على علامة خضراء للمضي قدمًا إذا أظهرت شاشتك ذلك. بعد تهيئة المجلد، سيتم إنشاء .zenml في الدليل الخاص بك.
إنشاء مجلد للبيانات في الدليل. الحصول على البيانات في هذا الصفحة :
قم بإنشاء مجلدات وفقًا لهذا الهيكل.
جمع البيانات
في هذه الخطوة، سنقوم باستيراد البيانات من ملف CSV الخاص بنا. سيتم استخدام هذه البيانات لتدريب النموذج بعد التنظيف والتشفير.
قم بإنشاء ملف ingest_data.py داخل المجلد سلم.
import pandas as pd
import numpy as np
import logging
from zenml import step class IngestData: """ Ingesting data to the workflow. """ def __init__(self, path:str) -> None: """ Args: data_path(str): path of the datafile """ self.path = path def get_data(self): df = pd.read_csv(self.path) logging.info("Reading csv file successfully completed.") return df @step(enable_cache = False)
def ingest_df(data_path:str) -> pd.DataFrame: """ ZenML step for ingesting data from a CSV file. """ try: #Creating an instance of IngestData class and ingest the data ingest_data = IngestData(data_path) df = ingest_data.get_data() logging.info("Ingesting data completed") return df except Exception as e: #Log an error message if data ingestion fails and raise the exception logging.error("Error while ingesting data") raise eهنا هو المشروع الصفحة .
في هذا الكود، قمنا أولاً بإنشاء فئة IngestData لتغليف منطق استيعاب البيانات. ثم أنشأنا أ زينML خطوة، ingest_df، وهي وحدة فردية من خط أنابيب جمع البيانات.
إنشاء ملف Training_pipeline.py داخل مسار المجلد.
اكتب الكود
from zenml import pipeline from steps.ingest_data import ingest_df #Define a ZenML pipeline called training_pipeline. @pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' df = ingest_df(data_path=data_path)نقوم هنا بإنشاء مسار تدريب لتدريب نموذج التعلم الآلي باستخدام سلسلة من الخطوات.
ثم قم بإنشاء ملف بإسم run_pipeline.py في الدليل الأساسي لتشغيل خط أنابيب.
from pipelines.training_pipeline import train_pipeline if __name__ == '__main__': #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")يستخدم هذا الرمز لتشغيل خط الأنابيب.
لقد انتهينا الآن من مسار استيعاب البيانات. دعونا تشغيله.
قم بتشغيل الأمر في جهازك الطرفي:
python run_pipeline.py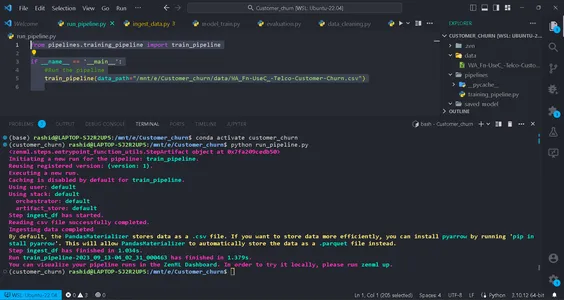
بعد ذلك، يمكنك رؤية الأوامر التي تشير إلى أن Training_pipeline قد اكتمل بنجاح.
معالجة البيانات
في هذه الخطوة، سنقوم بإنشاء استراتيجيات مختلفة لتنظيف البيانات. يتم إسقاط الأعمدة غير المرغوب فيها، وسيتم ترميز الأعمدة الفئوية باستخدام ترميز التسمية. وأخيرًا، سيتم تقسيم البيانات إلى بيانات تدريب واختبار.
قم بإنشاء ملف يسمى clean_data.py في مجلد src.
في هذا الملف، سنقوم بإنشاء فئات من الاستراتيجيات لتنظيف البيانات.
import pandas as pd
import numpy as np
import logging
from sklearn.model_selection import train_test_split
from abc import abstractmethod, ABC
from typing import Union
from sklearn.preprocessing import LabelEncoder class DataStrategy(ABC): @abstractmethod def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame,pd.Series]: pass # Data Preprocessing strategy
class DataPreprocessing(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df['TotalCharges'] = df['TotalCharges'].replace(' ', 0).astype(float) df.drop('customerID', axis=1, inplace=True) df['Churn'] = df['Churn'].replace({'Yes': 1, 'No': 0}).astype(int) service = ['PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] for col in service: df[col] = df[col].replace({'No phone service': 'No', 'No internet service': 'No'}) logging.info("Length of df: ", len(df.columns)) return df except Exception as e: logging.error("Error in Preprocessing", e) raise e # Feature Encoding Strategy
class LabelEncoding(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df_cat = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] lencod = LabelEncoder() for col in df_cat: df[col] = lencod.fit_transform(df[col]) logging.info(df.head()) return df except Exception as e: logging.error(e) raise e # Data splitting Strategy
class DataDivideStrategy(DataStrategy): def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: X = df.drop('Churn', axis=1) y = df['Churn'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) return X_train, X_test, y_train, y_test except Exception as e: logging.error("Error in DataDividing", e) raise e
يطبق هذا الكود خط أنابيب معياري لمعالجة البيانات للتعلم الآلي. ويتضمن استراتيجيات المعالجة المسبقة للبيانات، وترميز الميزات، وخطوات تشفير البيانات لتنظيف البيانات من أجل النمذجة التنبؤية.
1. المعالجة المسبقة للبيانات: هذه الفئة مسؤولة عن إزالة الأعمدة غير المرغوب فيها ومعالجة القيم المفقودة (قيم NA) في مجموعة البيانات.
2. ترميز التسمية: تم تصميم فئة LabelEncoding لتشفير المتغيرات الفئوية في تنسيق رقمي يمكن لخوارزميات التعلم الآلي العمل معه بفعالية. يقوم بتحويل الفئات المستندة إلى النص إلى قيم رقمية.
3. استراتيجية تقسيم البيانات: تفصل هذه الفئة مجموعة البيانات إلى متغيرات مستقلة (X) ومتغيرات تابعة (y). ثم يقوم بتقسيم البيانات إلى مجموعات تدريب واختبار.
سنقوم بتنفيذها خطوة بخطوة لإعداد بياناتنا لمهام التعلم الآلي.
تضمن هذه الاستراتيجيات تنظيم البيانات وتنسيقها بشكل صحيح للتدريب النموذجي والتقييم.
إنشاء data_cleaning.py في ال سلم المجلد.
import pandas as pd
import numpy as np
from src.clean_data import DataPreprocessing, DataDivideStrategy, LabelEncoding
import logging
from typing_extensions import Annotated
from typing import Tuple
from zenml import step # Define a ZenML step for cleaning and preprocessing data
@step(enable_cache=False)
def cleaning_data(df: pd.DataFrame) -> Tuple[ Annotated[pd.DataFrame, "X_train"], Annotated[pd.DataFrame, "X_test"], Annotated[pd.Series, "y_train"], Annotated[pd.Series, "y_test"],
]: try: # Instantiate the DataPreprocessing strategy data_preprocessing = DataPreprocessing() # Apply data preprocessing to the input DataFrame data = data_preprocessing.handle_data(df) # Instantiate the LabelEncoding strategy feature_encode = LabelEncoding() # Apply label encoding to the preprocessed data df_encoded = feature_encode.handle_data(data) # Log information about the DataFrame columns logging.info(df_encoded.columns) logging.info("Columns:", len(df_encoded)) # Instantiate the DataDivideStrategy strategy split_data = DataDivideStrategy() # Split the encoded data into training and testing sets X_train, X_test, y_train, y_test = split_data.handle_data(df_encoded) # Return the split data as a tuple return X_train, X_test, y_train, y_test except Exception as e: # Handle and log any errors that occur during data cleaning logging.error("Error in step cleaning data", e) raise eفي هذه الخطوة، قمنا بتنفيذ الاستراتيجيات التي أنشأناها clean_data.py
دعونا ننفذ هذا . in Training_pipeline.py
from zenml import pipeline #importing steps from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df)هذا كل شيء؛ لقد أكملنا خطوة المعالجة المسبقة للبيانات في مسار التدريب.
تدريب نموذجي
الآن، سنقوم ببناء النموذج لهذا المشروع. هنا، نحن نتوقع مشكلة التصنيف الثنائي. يمكننا ان نستخدم الانحدار اللوجستي. لن يكون تركيزنا على دقة النموذج. وسوف يعتمد على جزء MLOps.
بالنسبة لأولئك الذين لا يعرفون عن الانحدار اللوجستي، يمكنك أن تقرأ عنه هنا. سنقوم بتنفيذ نفس الخطوات التي قمنا بها في خطوة المعالجة المسبقة للبيانات. أولا سنقوم بإنشاء ملف Training_model.py في ال SRC المجلد.
import pandas as pd
from sklearn.linear_model import LogisticRegression
from abc import ABC, abstractmethod
import logging #Abstract model
class Model(ABC): @abstractmethod def train(self,X_train:pd.DataFrame,y_train:pd.Series): """ Trains the model on given data """ pass class LogisticReg(Model): """ Implementing the Logistic Regression model. """ def train(self, X_train: pd.DataFrame, y_train: pd.Series): """ Training the model Args: X_train: pd.DataFrame, y_train: pd.Series """ logistic_reg = LogisticRegression() logistic_reg.fit(X_train,y_train) return logistic_regنحدد فئة نموذج مجردة باستخدام طريقة "التدريب" التي يجب على جميع النماذج تنفيذها. فئة LogisticReg عبارة عن تطبيق محدد يستخدم الانحدار اللوجستي. تتضمن الخطوة التالية تكوين ملف يسمى config.py في مجلد الخطوات. قم بإنشاء ملف باسم config.py في مجلد الخطوات.
تكوين معلمات النموذج
from zenml.steps import BaseParameters """
This file is used for used for configuring
and specifying various parameters related to your machine learning models and training process """ class ModelName(BaseParameters): """ Model configurations """ model_name: str = "logistic regression"في الملف المسمى التكوين.py, داخل سلم المجلد، فإنك تقوم بتكوين المعلمات المتعلقة بنموذج التعلم الآلي الخاص بك. يمكنك إنشاء فئة ModelName التي ترث من المعلمات الأساسية لتحديد اسم النموذج. وهذا يجعل من السهل تغيير نوع النموذج.
import logging import pandas as pd
from src.training_model import LogisticReg
from zenml import step
from .config import ModelName #Define a step called train_model
@step(enable_cache=False)
def train_model(X_train:pd.DataFrame,y_train:pd.Series,config:ModelName): """ Trains the data based on the configured model """ try: model = None if config == "logistic regression": model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) return trained_model except Exception as e: logging.error("Error in step training model",e) raise eفي الملف المسمى model_train.py الموجود في مجلد الخطوات، حدد خطوة تسمى Train_model باستخدام ZenML. الغرض من هذه الخطوة هو تدريب نموذج التعلم الآلي بناءً على اسم النموذج الموجود اسم النموذج.
في برنامج
تحقق من اسم النموذج الذي تم تكوينه. إذا كان "الانحدار اللوجستي"، فقد أنشأنا مثيلًا لنموذج LogisticReg وقمنا بتدريبه باستخدام بيانات التدريب المتوفرة (X_train وy_train). إذا كان اسم النموذج غير مدعوم، فإنك تظهر خطأ. يتم تسجيل أية أخطاء أثناء هذه العملية، ويتم ظهور الخطأ.
بعد ذلك، سنقوم بتنفيذ هذه الخطوة Training_pipeline.py
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train)لقد قمنا الآن بتنفيذ خطوة Train_model قيد التنفيذ. وبذلك تكون قد اكتملت خطوة model_train.py.
نموذج التقييم
في هذه الخطوة، سنقوم بتقييم مدى كفاءة نموذجنا. ومن أجل ذلك، سوف نتحقق من درجة الدقة في التنبؤ ببيانات الاختبار. لذا، أولاً، سنقوم بإنشاء الاستراتيجيات التي سنستخدمها في خط الأنابيب.
إنشاء ملف اسمه Evaluation_model.py في المجلد SRC.
import logging
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from abc import ABC, abstractmethod
import numpy as np # Abstract class for model evaluation
class Evaluate(ABC): @abstractmethod def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Abstract method to evaluate a machine learning model's performance. Args: y_true (np.ndarray): True labels. y_pred (np.ndarray): Predicted labels. Returns: float: Evaluation result. """ pass #Class to calculate accuracy score
class Accuracy_score(Evaluate): """ Calculates and returns the accuracy score for a model's predictions. """ def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: try: accuracy_scr = accuracy_score(y_true=y_true, y_pred=y_pred) * 100 logging.info("Accuracy_score:", accuracy_scr) return accuracy_scr except Exception as e: logging.error("Error in evaluating the accuracy of the model",e) raise e
#Class to calculate Precision score
class Precision_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Generates and returns a precision score for a model's predictions. """ try: precision = precision_score(y_true=y_true,y_pred=y_pred) logging.info("Precision score: ",precision) return float(precision) except Exception as e: logging.error("Error in calculation of precision_score",e) raise e class F1_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray): """ Generates and returns an F1 score for a model's predictions. """ try: f1_scr = f1_score(y_pred=y_pred, y_true=y_true) logging.info("F1 score: ", f1_scr) return f1_scr except Exception as e: logging.error("Error in calculating F1 score", e) raise e الآن بعد أن قمنا ببناء استراتيجيات التقييم، سوف نستخدمها لتقييم النموذج. دعونا ننفذ الكود في خطوة تقييم_model.py في مجلد الخطوات هنا، درجة الاستدعاء ودرجة الدقة ودرجة الدقة هي الاستراتيجيات التي نستخدمها كمقاييس لتقييم النموذج.
دعونا ننفذ هذه الخطوات. قم بإنشاء ملف باسم تقييم.py في خطوات:
import logging
import pandas as pd
import numpy as np
from zenml import step
from src.evaluate_model import ClassificationReport, ConfusionMatrix, Accuracy_score
from typing import Tuple
from typing_extensions import Annotated
from sklearn.base import ClassifierMixin @step(enable_cache=False)
def evaluate_model( model: ClassifierMixin, X_test: pd.DataFrame, y_test: pd.Series
) -> Tuple[ Annotated[np.ndarray,"confusion_matix"], Annotated[str,"classification_report"], Annotated[float,"accuracy_score"], Annotated[float,"precision_score"], Annotated[float,"recall_score"] ]: """ Evaluate a machine learning model's performance using common metrics. """ try: y_pred = model.predict(X_test) precision_score_class = Precision_Score() precision_score = precision_score_class.evaluate_model(y_pred=y_pred,y_true=y_test) mlflow.log_metric("Precision_score ",precision_score) accuracy_score_class = Accuracy_score() accuracy_score = accuracy_score_class.evaluate_model(y_true=y_test, y_pred=y_pred) logging.info("accuracy_score:",accuracy_score) return accuracy_score, precision_score except Exception as e: logging.error("Error in evaluating model",e) raise eالآن، دعونا ننفذ هذه الخطوة في خط الأنابيب. تحديث Training_pipeline.py:
يحدد هذا الرمز Evaluate_model خطوة في خط أنابيب التعلم الآلي. يتطلب الأمر نموذج تصنيف مدربًا (نموذجًا) وبيانات اختبار مستقلة (X_test)، والتسميات الحقيقية لبيانات الاختبار (y_test) كمدخل. ثم يقوم بتقييم أداء النموذج باستخدام مقاييس التصنيف الشائعة وإرجاع النتائج، مثل Precision_Score، و Precision_Score.
الآن، دعونا ننفذ هذه الخطوة في خط الأنابيب. تحديث Training_pipeline.py:
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
from steps.evaluation import evaluate_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train) #Evaluation metrics of data accuracy_score, precision_score = evaluate_model(model=model,X_test=X_test, y_test=y_test)هذا كل شيء. الآن، أكملنا خط أنابيب التدريب. يجري
python run_pipeline.py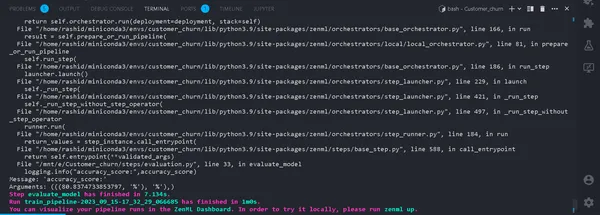
في المحطة. إذا تم تشغيله بنجاح. الآن بعد أن انتهينا من تشغيل مسار التدريب محليًا، سيبدو الأمر كما يلي:
ما هو متتبع التجربة؟
أداة تعقب التجربة هي أداة في التعلم الآلي تُستخدم لتسجيل التجارب المختلفة ومراقبتها وإدارتها في عملية تطوير التعلم الآلي.
يقوم علماء البيانات بتجربة نماذج مختلفة للحصول على أفضل النتائج. لذا، عليهم الاستمرار في تتبع البيانات واستخدام نماذج مختلفة. سيكون الأمر صعبًا للغاية بالنسبة لهم إذا قاموا بتسجيله يدويًا باستخدام ورقة Excel.
MLflow
تعد MLflow أداة قيمة لتتبع التجارب في التعلم الآلي وإدارتها بكفاءة. يقوم بأتمتة تتبع التجربة ومراقبة تكرارات النموذج والبيانات المرتبطة بها. يؤدي ذلك إلى تبسيط عملية تطوير النموذج وتوفير واجهة سهلة الاستخدام لتصور النتائج.
يؤدي دمج MLflow مع ZenML إلى تعزيز قوة التجربة وإدارتها ضمن إطار عمليات التعلم الآلي.
لإعداد MLflow مع ZenML، اتبع الخطوات التالية:
- تثبيت تكامل MLflow:
- استخدم الأمر التالي لتثبيت تكامل MLflow:
zenml integration install mlflow -y2. قم بتسجيل متتبع تجربة MLflow:
قم بتسجيل متتبع التجربة في MLflow باستخدام هذا الأمر:
zenml experiment-tracker register mlflow_tracker --flavor=mlflow3. تسجيل المكدس:
في ZenML، المكدس عبارة عن مجموعة من المكونات التي تحدد المهام ضمن سير عمل ML لديك. فهو يساعد على تنظيم وإدارة خطوات خط أنابيب ML بكفاءة. قم بتسجيل المكدس باستخدام:
يمكنك العثور على مزيد من التفاصيل في توثيق.
zenml model-deployer register mlflow --flavor=mlflow
zenml stack register mlflow_stack -a default -o default -d mlflow -e mlflow_tracker --setيؤدي هذا إلى ربط المكدس الخاص بك بإعدادات محددة لتخزين العناصر والمنسقين وأهداف النشر وتتبع التجربة.
4. عرض تفاصيل المكدس:
يمكنك عرض مكونات المكدس الخاص بك باستخدام:
zenml stack describeيعرض هذا المكونات المرتبطة بمكدس "mlflow_tracker".
الآن، دعونا نطبق متتبع التجربة في نموذج التدريب ونقوم بتقييم النموذج:
يمكنك رؤية اسم المكونات كـ mlflow_tracker.
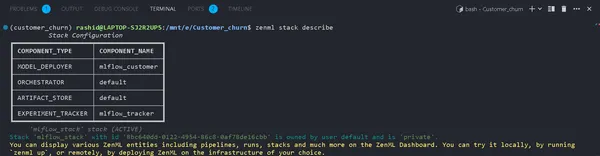
إعداد أداة تعقب تجربة ZenML
أولاً، ابدأ بتحديث Train_model.py:
import logging
import mlflow
import pandas as pd
from src.training_model import LogisticReg
from sklearn.base import ClassifierMixin
from zenml import step
from .config import ModelName
#import from zenml.client import Client # Obtain the active stack's experiment tracker
experiment_tracker = Client().active_stack.experiment_tracker #Define a step called train_model
@step(experiment_tracker = experiment_tracker.name,enable_cache=False)
def train_model( X_train:pd.DataFrame, y_train:pd.Series, config:ModelName ) -> ClassifierMixin: """ Trains the data based on the configured model Args: X_train: pd.DataFrame = Independent training data, y_train: pd.Series = Dependent training data. """ try: model = None if config.model_name == "logistic regression": #Automatically logging scores, model etc.. mlflow.sklearn.autolog() model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) logging.info("Training model completed.") return trained_model except Exception as e: logging.error("Error in step training model",e) raise eفي هذا الكود، قمنا بإعداد أداة تعقب التجربة باستخدام mlflow.sklearn.autolog()، الذي يقوم تلقائيًا بتسجيل جميع التفاصيل حول النموذج، مما يسهل تتبع التجارب وتحليلها.
في مجلة تقييم.py
from zenml.client import Client experiment_tracker = Client().active_stack.experiment_tracker @step(experiment_tracker=experiment_tracker.name, enable_cache = False)تشغيل خط الأنابيب
تحديث الخاص بك run_pipeline.py البرنامج النصي على النحو التالي:
from pipelines.training_pipeline import train_pipeline
from zenml.client import Client
if __name__ == '__main__': #printimg the experiment tracking uri print(Client().active_stack.experiment_tracker.get_tracking_uri()) #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")انسخه والصقه في هذا الأمر.
mlflow ui --backend-store-uri "--uri on the top of "file:/home/ "استكشف تجاربك
انقر فوق الرابط الذي تم إنشاؤه بواسطة الأمر أعلاه لفتح واجهة مستخدم MLflow. ستجد هنا كنزًا من الأفكار:
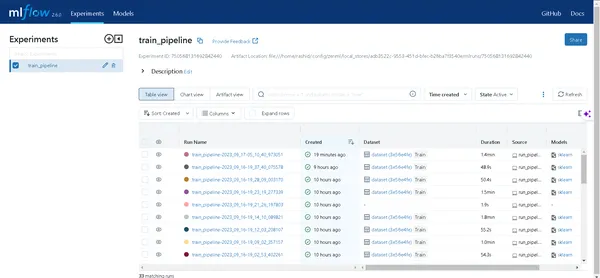
- خطوط الأنابيب: يمكنك الوصول بسهولة إلى جميع خطوط الأنابيب التي قمت بتشغيلها.
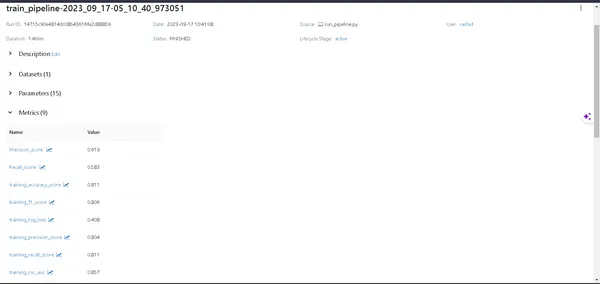
- تفاصيل النموذج: انقر على المسار للكشف عن كل التفاصيل المتعلقة بنموذجك.
- المقاييس: تعمق في قسم المقاييس لتصور أداء النموذج الخاص بك.
الآن، يمكنك التغلب على تتبع تجربة التعلم الآلي باستخدام ZenML وMLflow!
قابل للفتح
في القسم التالي، سنقوم بنشر هذا النموذج. عليك أن تعرف هذه المفاهيم:
أ). خط أنابيب النشر المستمر
سيقوم خط الأنابيب هذا بأتمتة عملية نشر النموذج. بمجرد اجتياز النموذج لمعايير التقييم، يتم نشره تلقائيًا في بيئة الإنتاج. على سبيل المثال، يبدأ الأمر بالمعالجة المسبقة للبيانات، وتنظيف البيانات، وتدريب البيانات، وتقييم النماذج، وما إلى ذلك.
ب). خط أنابيب نشر الاستدلال
يركز Inference Deployment Pipeline على نشر نماذج التعلم الآلي للاستدلال في الوقت الفعلي أو الاستدلال المجمع. يتخصص Inference Deployment Pipeline في نشر النماذج لإجراء التنبؤات في بيئة الإنتاج. على سبيل المثال، يقوم بإعداد نقطة نهاية API حيث يمكن للمستخدمين إرسال النص. فهو يضمن توفر النموذج وقابلية التوسع ويراقب أدائه في الوقت الفعلي. تعتبر خطوط الأنابيب هذه مهمة للحفاظ على كفاءة وفعالية أنظمة التعلم الآلي. الآن، سنقوم بتنفيذ خط الأنابيب المستمر.
قم بإنشاء ملف يسمى Deployment_pipeline.py في مجلد خطوط الأنابيب.
import numpy as np
import json
import logging
import pandas as pd
from zenml import pipeline, step
from zenml.config import DockerSettings
from zenml.constants import DEFAULT_SERVICE_START_STOP_TIMEOUT
from zenml.integrations.constants import MLFLOW
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer,
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
from zenml.steps import BaseParameters, Output
from src.clean_data import FeatureEncoding
from .utils import get_data_for_test
from steps.data_cleaning import cleaning_data
from steps.evaluation import evaluate_model
from steps.ingest_data import ingest_df # Define Docker settings with MLflow integration
docker_settings = DockerSettings(required_integrations = {MLFLOW}) #Define class for deployment pipeline configuration
class DeploymentTriggerConfig(BaseParameters): min_accuracy:float = 0.92 @step def deployment_trigger( accuracy: float, config: DeploymentTriggerConfig,
): """ It trigger the deployment only if accuracy is greater than min accuracy. Args: accuracy: accuracy of the model. config: Minimum accuracy thereshold. """ try: return accuracy >= config.min_accuracy except Exception as e: logging.error("Error in deployment trigger",e) raise e # Define a continuous pipeline
@pipeline(enable_cache=False,settings={"docker":docker_settings})
def continuous_deployment_pipeline( data_path:str, min_accuracy:float = 0.92, workers: int = 1, timeout: int = DEFAULT_SERVICE_START_STOP_TIMEOUT
): df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df) model = train_model(X_train=X_train, y_train=y_train) accuracy_score, precision_score = evaluate_model(model=model, X_test=X_test, y_test=y_test) deployment_decision = deployment_trigger(accuracy=accuracy_score) mlflow_model_deployer_step( model=model, deploy_decision = deployment_decision, workers = workers, timeout = timeout )إطار عمل ZenML لمشروع التعلم الآلي
يحدد هذا الرمز النشر المستمر لمشروع التعلم الآلي باستخدام ZenML Framework.
1. استيراد المكتبات الضرورية: استيراد المكتبات اللازمة لنشر النموذج.
2. إعدادات عامل الميناء: من خلال تكوين إعدادات Docker لاستخدامها مع MLflow، يساعد Docker في حزم هذه النماذج وتشغيلها بشكل متسق.
3. تكوين مشغل النشر: إنها الفئة التي يتم فيها تكوين الحد الأدنى من الدقة لنشر النموذج.
4. نشر_trigger: سيتم إرجاع هذه الخطوة إذا تجاوزت دقة النموذج الحد الأدنى من الدقة.
5. مستمر_نشر_خط الأنابيب: يتكون خط الأنابيب هذا من عدة خطوات: استيعاب البيانات، وتنظيف البيانات، وتدريب النموذج، وتقييم النموذج. ولن يتم نشر النموذج إلا إذا استوفى الحد الأدنى من الدقة.
بعد ذلك، سنقوم بتنفيذ خط أنابيب الاستدلال في Deploy_pipeline.py
import logging
import pandas as pd
from zenml.steps import BaseParameters, Output
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import MLFlowModelDeployer
from zenml.integrations.mlflow.services import MLFlowDeploymentService class MLFlowDeploymentLoaderStepParameters(BaseParameters): pipeline_name: str step_name: str running: bool = True @step(enable_cache=False)
def dynamic_importer() -> str: data = get_data_for_test() return data @step(enable_cache=False)
def prediction_service_loader( pipeline_name: str, pipeline_step_name: str, running: bool = True, model_name: str = "model",
) -> MLFlowDeploymentService: model_deployer = MLFlowModelDeployer.get_active_model_deployer() existing_services = model_deployer.find_model_server( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, model_name=model_name, running=running, ) if not existing_services: raise RuntimeError( f"No MLflow prediction service deployed by the " f"{pipeline_step_name} step in the {pipeline_name} " f"pipeline for the '{model_name}' model is currently " f"running." ) return existing_services[0] @step
def predictor(service: MLFlowDeploymentService, data: str) -> np.ndarray: service.start(timeout=10) data = json.loads(data) prediction = service.predict(data) return prediction @pipeline(enable_cache=False, settings={"docker": docker_settings})
def inference_pipeline(pipeline_name: str, pipeline_step_name: str): batch_data = dynamic_importer() model_deployment_service = prediction_service_loader( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, running=False, ) prediction = predictor(service=model_deployment_service, data=batch_data) return prediction
يقوم هذا الرمز بإعداد مسار لإجراء التنبؤات باستخدام نموذج التعلم الآلي المنشور من خلال MLflow. فهو يستورد البيانات، ويحمل النموذج المنشور، ويستخدمه لإجراء التنبؤات.
نحن بحاجة إلى إنشاء الوظيفة get_data_for_test() in الاستخدامات في مجلد خطوط الأنابيب. حتى نتمكن من إدارة التعليمات البرمجية لدينا بشكل أكثر كفاءة.
import logging import pandas as pd from src.clean_data import DataPreprocessing, LabelEncoding # Function to get data for testing purposes
def get_data_for_test(): try: df = pd.read_csv('./data/WA_Fn-UseC_-Telco-Customer-Churn.csv') df = df.sample(n=100) data_preprocessing = DataPreprocessing() data = data_preprocessing.handle_data(df) # Instantiate the FeatureEncoding strategy label_encode = LabelEncoding() df_encoded = label_encode.handle_data(data) df_encoded.drop(['Churn'],axis=1,inplace=True) logging.info(df_encoded.columns) result = df_encoded.to_json(orient="split") return result except Exception as e: logging.error("e") raise eالآن، دعونا ننفذ المسار الذي أنشأناه لنشر النموذج والتنبؤ بالنموذج المنشور.
إنشاء run_deployment.py الملف في دليل المشروع:
import click # For handling command-line arguments
import logging from typing import cast
from rich import print # For console output formatting # Import pipelines for deployment and inference
from pipelines.deployment_pipeline import (
continuous_deployment_pipeline, inference_pipeline
)
# Import MLflow utilities and components
from zenml.integrations.mlflow.mlflow_utils import get_tracking_uri
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService # Define constants for different configurations: DEPLOY, PREDICT, DEPLOY_AND_PREDICT
DEPLOY = "deploy"
PREDICT = "predict"
DEPLOY_AND_PREDICT = "deploy_and_predict" # Define a main function that uses Click to handle command-line arguments
@click.command()
@click.option( "--config", "-c", type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]), default=DEPLOY_AND_PREDICT, help="Optionally you can choose to only run the deployment " "pipeline to train and deploy a model (`deploy`), or to " "only run a prediction against the deployed model " "(`predict`). By default both will be run " "(`deploy_and_predict`).",
)
@click.option( "--min-accuracy", default=0.92, help="Minimum accuracy required to deploy the model",
)
def run_main(config:str, min_accuracy:float ): # Get the active MLFlow model deployer component mlflow_model_deployer_component = MLFlowModelDeployer.get_active_model_deployer() # Determine if the user wants to deploy a model (deploy), make predictions (predict), or both (deploy_and_predict) deploy = config == DEPLOY or config == DEPLOY_AND_PREDICT predict = config == PREDICT or config == DEPLOY_AND_PREDICT # If deploying a model is requested: if deploy: continuous_deployment_pipeline( data_path='/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv', min_accuracy=min_accuracy, workers=3, timeout=60 ) # If making predictions is requested: if predict: # Initialize an inference pipeline run inference_pipeline( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", ) # Print instructions for viewing experiment runs in the MLflow UI print( "You can run:n " f"[italic green] mlflow ui --backend-store-uri '{get_tracking_uri()}" "[/italic green]n ...to inspect your experiment runs within the MLflow" " UI.nYou can find your runs tracked within the " "`mlflow_example_pipeline` experiment. There you'll also be able to " "compare two or more runs.nn" ) # Fetch existing services with the same pipeline name, step name, and model name existing_services = mlflow_model_deployer_component.find_model_server( pipeline_name = "continuous_deployment_pipeline", pipeline_step_name = "mlflow_model_deployer_step", ) # Check the status of the prediction server: if existing_services: service = cast(MLFlowDeploymentService, existing_services[0]) if service.is_running: print( f"The MLflow prediciton server is running locally as a daemon" f"process service and accepts inference requests at: n" f" {service.prediction_url}n" f"To stop the service, run" f"[italic green] zenml model-deployer models delete" f"{str(service.uuid)}'[/italic green]." ) elif service.is_failed: print( f"The MLflow prediciton server is in a failed state: n" f" Last state: '{service.status.state.value}'n" f" Last error: '{service.status.last_error}'" ) else: print( "No MLflow prediction server is currently running. The deployment" "pipeline must run first to train a model and deploy it. Execute" "the same command with the '--deploy' argument to deploy a model." ) # Entry point: If this script is executed directly, run the main function
if __name__ == "__main__": run_main()هذا الرمز عبارة عن برنامج نصي لسطر الأوامر لإدارة ونشر نموذج التعلم الآلي باستخدام MLFlow وZenMl.
الآن، دعونا نشر النموذج.
قم بتشغيل هذا الأمر على جهازك الطرفي.
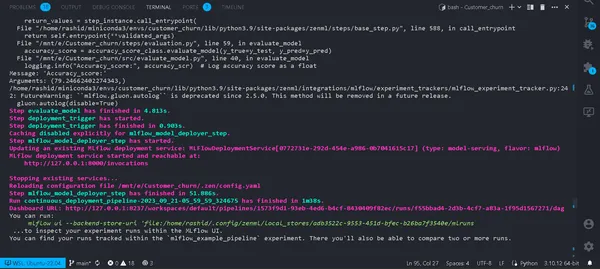
python run_deployment.py --config deploy
الآن، قمنا بنشر نموذجنا. سيتم تشغيل خط الأنابيب الخاص بك بنجاح، ويمكنك مشاهدته في لوحة معلومات zenml.
python run_deployment.py --config predictبدء عملية التنبؤ
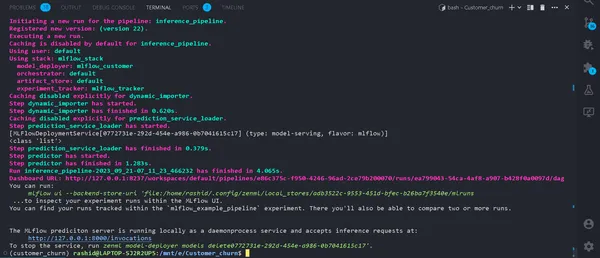
الآن، خادم التنبؤ MLFlow الخاص بنا قيد التشغيل.
نحتاج إلى تطبيق ويب لإدخال البيانات ورؤية النتائج. لا بد أنك تتساءل لماذا يتعين علينا إنشاء تطبيق ويب من الصفر.
ليس حقيقيًا. سنستخدم Streamlit، وهو إطار عمل للواجهة الأمامية مفتوح المصدر يساعد في إنشاء تطبيق ويب للواجهة الأمامية سريع وسهل لنموذج التعلم الآلي الخاص بنا.
قم بتثبيت المكتبة
pip install streamlitقم بإنشاء ملف باسمstreamlit_app.py في دليل المشروع الخاص بك.
import json
import logging
import numpy as np
import pandas as pd
import streamlit as st
from PIL import Image
from pipelines.deployment_pipeline import prediction_service_loader
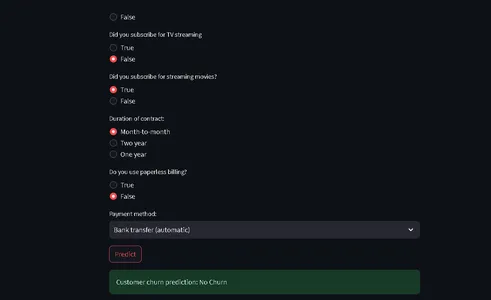
from run_deployment import main def main(): st.title("End to End Customer Satisfaction Pipeline with ZenML") st.markdown( """ #### Problem Statement The objective here is to predict the customer satisfaction score for a given order based on features like order status, price, payment, etc. I will be using [ZenML](https://zenml.io/) to build a production-ready pipeline to predict the customer satisfaction score for the next order or purchase. """ ) st.markdown( """ Above is a figure of the whole pipeline, we first ingest the data, clean it, train the model, and evaluate the model, and if data source changes or any hyperparameter values changes, deployment will be triggered, and (re) trains the model and if the model meets minimum accuracy requirement, the model will be deployed. """ ) st.markdown( """ #### Description of Features This app is designed to predict the customer satisfaction score for a given customer. You can input the features of the product listed below and get the customer satisfaction score. | Models | Description | | ------------- | - | | SeniorCitizen | Indicates whether the customer is a senior citizen. | | tenure | Number of months the customer has been with the company. | | MonthlyCharges | Monthly charges incurred by the customer. | | TotalCharges | Total charges incurred by the customer. | | gender | Gender of the customer (Male: 1, Female: 0). | | Partner | Whether the customer has a partner (Yes: 1, No: 0). | | Dependents | Whether the customer has dependents (Yes: 1, No: 0). | | PhoneService | Whether the customer has dependents (Yes: 1, No: 0). | | MultipleLines | Whether the customer has multiple lines (Yes: 1, No: 0). | | InternetService | Type of internet service (No: 1, Other: 0). | | OnlineSecurity | Whether the customer has online security service (Yes: 1, No: 0). | | OnlineBackup | Whether the customer has online backup service (Yes: 1, No: 0). | | DeviceProtection | Whether the customer has device protection service (Yes: 1, No: 0). | | TechSupport | Whether the customer has tech support service (Yes: 1, No: 0). | | StreamingTV | Whether the customer has streaming TV service (Yes: 1, No: 0). | | StreamingMovies | Whether the customer has streaming movies service (Yes: 1, No: 0). | | Contract | Type of contract (One year: 1, Other: 0). | | PaperlessBilling | Whether the customer has paperless billing (Yes: 1, No: 0). | | PaymentMethod | Payment method (Credit card: 1, Other: 0). | | Churn | Whether the customer has churned (Yes: 1, No: 0). | """ ) payment_options = { 2: "Electronic check", 3: "Mailed check", 1: "Bank transfer (automatic)", 0: "Credit card (automatic)" } contract = { 0: "Month-to-month", 2: "Two year", 1: "One year" } def format_func(PaymentMethod): return payment_options[PaymentMethod] def format_func_contract(Contract): return contract[Contract] display = ("male", "female") options = list(range(len(display))) # Define the data columns with their respective values SeniorCitizen = st.selectbox("Are you senior citizen?", options=[True, False],) tenure = st.number_input("Tenure") MonthlyCharges = st.number_input("Monthly Charges: ") TotalCharges = st.number_input("Total Charges: ") gender = st.radio("gender:", options, format_func=lambda x: display[x]) Partner = st.radio("Do you have a partner? ", options=[True, False]) Dependents = st.radio("Dependents: ", options=[True, False]) PhoneService = st.radio("Do you have phone service? : ", options=[True, False]) MultipleLines = st.radio("Do you Multiplines? ", options=[True, False]) InternetService = st.radio("Did you subscribe for Internet service? ", options=[True, False]) OnlineSecurity = st.radio("Did you subscribe for OnlineSecurity? ", options=[True, False]) OnlineBackup = st.radio("Did you subscribe for Online Backup service? ", options=[True, False]) DeviceProtection = st.radio("Did you subscribe for device protection only?", options=[True, False]) TechSupport =st.radio("Did you subscribe for tech support? ", options=[True, False]) StreamingTV = st.radio("Did you subscribe for TV streaming", options=[True, False]) StreamingMovies = st.radio("Did you subscribe for streaming movies? ", options=[True, False]) Contract = st.radio("Duration of contract: ", options=list(contract.keys()), format_func=format_func_contract) PaperlessBilling = st.radio("Do you use paperless billing? ", options=[True, False]) PaymentMethod = st.selectbox("Payment method:", options=list(payment_options.keys()), format_func=format_func) # You can use PaymentMethod to get the selected payment method's numeric value if st.button("Predict"): service = prediction_service_loader( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", running=False, ) if service is None: st.write( "No service could be found. The pipeline will be run first to create a service." ) run_main() try: data_point = { 'SeniorCitizen': int(SeniorCitizen), 'tenure': tenure, 'MonthlyCharges': MonthlyCharges, 'TotalCharges': TotalCharges, 'gender': int(gender), 'Partner': int(Partner), 'Dependents': int(Dependents), 'PhoneService': int(PhoneService), 'MultipleLines': int(MultipleLines), 'InternetService': int(InternetService), 'OnlineSecurity': int(OnlineSecurity), 'OnlineBackup': int(OnlineBackup), 'DeviceProtection': int(DeviceProtection), 'TechSupport': int(TechSupport), 'StreamingTV': int(StreamingTV), 'StreamingMovies': int(StreamingMovies), 'Contract': int(Contract), 'PaperlessBilling': int(PaperlessBilling), 'PaymentMethod': int(PaymentMethod) } # Convert the data point to a Series and then to a DataFrame data_point_series = pd.Series(data_point) data_point_df = pd.DataFrame(data_point_series).T # Convert the DataFrame to a JSON list json_list = json.loads(data_point_df.to_json(orient="records")) data = np.array(json_list) for i in range(len(data)): logging.info(data[i]) pred = service.predict(data) logging.info(pred) st.success(f"Customer churn prediction: {'Churn' if pred == 1 else 'No Churn'}") except Exception as e: logging.error(e) raise e if __name__ == "__main__": main()يحدد هذا الرمز أن StreamLit سيوفر واجهة أمامية للتنبؤ بحركة العملاء في شركة اتصالات بناءً على بيانات العميل والتفاصيل الديموغرافية.
يمكن للمستخدمين إدخال معلوماتهم من خلال واجهة سهلة الاستخدام، ويستخدم الكود نموذجًا مدربًا للتعلم الآلي (يتم نشره مع ZenML وMLflow) لإجراء التنبؤات.
ثم يتم عرض النتيجة المتوقعة للمستخدم.
الآن قم بتشغيل هذا الأمر:
⚠️ تأكد من تشغيل نموذج التنبؤ الخاص بك
streamlit run streamlit_app.pyاضغط على الرابط.
هذا كل شيء؛ لقد أكملنا مشروعنا.

هذا كل شيء؛ لقد اختتمنا بنجاح مشروع التعلم الآلي الشامل الخاص بنا، وكيف يتعامل المحترفون مع العملية برمتها.
وفي الختام
في هذا الاستكشاف الشامل لعمليات التعلم الآلي (MLOps) من خلال تطوير ونشر نموذج التنبؤ بتراجع العملاء، شهدنا القوة التحويلية لعمليات التعلم الآلي (MLOps) في تبسيط دورة حياة التعلم الآلي. بدءًا من جمع البيانات والمعالجة المسبقة وحتى التدريب النموذجي والتقييم والنشر، يعرض مشروعنا الدور الأساسي لعمليات MLOps في سد الفجوة بين التطوير والإنتاج. مع اعتماد المؤسسات بشكل متزايد على عملية صنع القرار المستندة إلى البيانات، فإن الممارسات الفعالة والقابلة للتطوير الموضحة هنا تسلط الضوء على الأهمية الحاسمة لعمليات MLOs في ضمان نجاح تطبيقات التعلم الآلي.
الوجبات السريعة الرئيسية
- تعد MLOps (عمليات التعلم الآلي) أمرًا محوريًا في تبسيط دورة حياة التعلم الآلي الشاملة، مما يضمن عمليات فعالة وموثوقة وقابلة للتطوير.
- يعد ZenML وMLflow أطر عمل قوية تسهل تطوير نماذج التعلم الآلي وتتبعها ونشرها في تطبيقات العالم الحقيقي.
- تعد المعالجة المسبقة المناسبة للبيانات، بما في ذلك التنظيف والتشفير والتقسيم، أمرًا أساسيًا لبناء نماذج قوية للتعلم الآلي.
- توفر مقاييس التقييم مثل الدقة والضبط والاستدعاء ودرجة F1 فهمًا شاملاً لأداء النموذج.
- تعمل أدوات تتبع التجارب مثل MLflow على تحسين التعاون وإدارة التجارب في مشاريع علوم البيانات.
- تعد خطوط أنابيب النشر المستمر والاستدلالي أمرًا بالغ الأهمية للحفاظ على كفاءة النموذج وتوافره في بيئات الإنتاج.
الأسئلة المتكررة
يعنيMLOPS أن عمليات التعلم الآلي هي دورة حياة تعلم الآلة الشاملة بدءًا من التطوير وحتى جمع البيانات. إنها مجموعة من الممارسات لتصميم وأتمتة دورة التعلم الآلي بأكملها. وهو يشمل كل مرحلة، بدءًا من تطوير نماذج التعلم الآلي وتدريبها وحتى نشرها ومراقبتها وصيانتها المستمرة. تعد MLOps أمرًا بالغ الأهمية لأنها تضمن قابلية التوسع والموثوقية والكفاءة لتطبيقات التعلم الآلي. فهو يساعد علماء البيانات على إنشاء تطبيقات قوية للتعلم الآلي تقدم تنبؤات دقيقة.
لدى MLOps وDevOps أهداف مماثلة تتمثل في تبسيط العمليات وأتمتتها ضمن المجالات الخاصة بكل منهما. تركز DevOps في المقام الأول على تطوير البرمجيات، وخط أنابيب تسليم البرامج. ويهدف إلى تسريع تطوير البرمجيات وتحسين جودة التعليمات البرمجية وتحسين موثوقية النشر. تلبي MLOps الاحتياجات المتخصصة لمشاريع التعلم الآلي، مما يجعلها ممارسة حاسمة للاستفادة من الذكاء الاصطناعي وعلوم البيانات.
وهذا خطأ شائع ستواجهه في المشروع. فقط اركض
"زنمل أسفل"
then
"قطع اتصال zenml"
قم بتشغيل خط الأنابيب مرة أخرى. سيتم حلها.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/10/a-mlops-enhanced-customer-churn-prediction-project/

