بقلم دان يو وهاري فوستر وتوم فيتزباتريك
مرحبًا بكم في عصر EDA 4.0 ، حيث نشهد تحولًا ثوريًا في أتمتة التصميم الإلكتروني مدفوعًا بقوة الذكاء الاصطناعي. يمكن تحديد تاريخ أكاديمية الإمارات الدبلوماسية في فترات مميزة تتميز بالتقدم التكنولوجي الكبير الذي أدى إلى تكرارات التصميم بشكل أسرع ، وتحسين الإنتاجية ، وتعزيز تطوير الأنظمة الإلكترونية المعقدة.
والجدير بالذكر أن ظهور EDA 1.0 كان إيذانا ببدء تقديم SPICE (برنامج محاكاة مع التركيز على الدوائر المتكاملة) في جامعة كاليفورنيا ، بيركلي ، في أوائل السبعينيات ، مما أحدث ثورة في تصميم الدوائر.
في الثمانينيات وأوائل التسعينيات ، ظهر EDA 1980 نتيجة لتطوير خوارزميات المكان والطريق الفعالة. شهدت هذه الفترة ، المعروفة أيضًا باسم عصر RTL ، انتقالًا من التصميم على مستوى البوابة إلى التجريدات ذات المستوى الأعلى ، حيث يتيح تصميم RTL أوصاف الدوائر على مستوى نقل التسجيل ، وبالتالي تحسين أداء المحاكاة. شهدت هذه الفترة علامة بارزة مع إدخال التوليف المنطقي.
كان ظهور تصميمات النظام على الرقاقة (SoC) في أواخر التسعينيات وأوائل العقد الأول من القرن الحادي والعشرين بمثابة لحظة محورية أدت إلى EDA 1990. شهد هذا العصر ظهور اقتصاد تنمية الملكية الفكرية إلى جانب منهجيات إعادة استخدام التصميم. تم تطوير أدوات ومعايير EDA لدعم التصميم والتحقق والتحقق من SoC ، مما يمكّن المهندسين من إدارة التعقيد المتصاعد للتصاميم من فئة SoC.
في العديد من الجوانب ، يتوافق EDA 4.0 مع الاتجاهات الأوسع للثورة الصناعية 4.0 ، والتي تغير بشكل سريع طريقة تصنيع الشركات لمنتجاتها وتحسينها وتوزيعها ، والتي يقودها جزئيًا رقمنة قطاع التصنيع. تم تطوير EDA 4.0 لتسهيل تصميم الأجهزة الذكية والمتصلة ، وتسخير إمكانات الحوسبة السحابية والذكاء الاصطناعي (AI) وقدرات التعلم الآلي (ML).


تتضمن أدوات EDA الآن التعلم الآلي ، والنماذج الأولية الافتراضية ، والتوأم الرقمي ، ومنهجيات التصميم على مستوى النظام لتقديم التحقق السريع ، وسير عمل التحقق الآلي ، وزيادة دقة التحقق لمنتجات EDA. يعد عصر EDA 4.0 بأداء منتج محسن ، وتقليل الوقت اللازم للتسويق ، وعمليات تطوير وتصنيع مبسطة.
في هذه المقالة ، نتعمق في تنفيذ أحدث حلول ML المصممة خصيصًا للتحقق الوظيفي. نستكشف التحديات التي يمكن معالجتها بواسطة ML ونقدم تقنيات وخوارزميات جديدة لها صلة بهذا المجال.
موضوعات ML في التحقق الوظيفي
يلخص الجدول 1 الموضوعات والموضوعات الفرعية التي تنطبق على التحقق الوظيفي عند تضمين جميع موضوعات التحقق الوظيفي في المنظور العام للتحقق من رمز البرمجة. يشير النص المائل إلى الموضوعات الفرعية التي لم يتم استكشافها في منشورات الاستقصاء العامة الأخرى.
الجدول 1: موضوعات تطبيقات ML في التحقق الوظيفي.

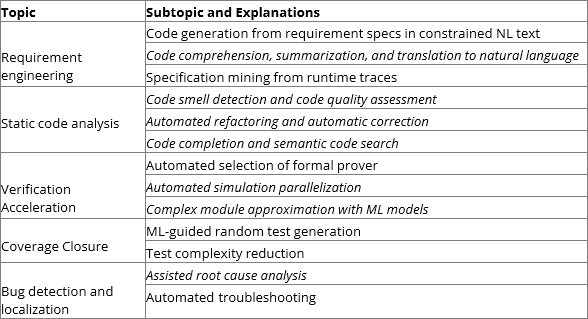
متطلبات الهندسة
هندسة المتطلبات في التحقق الوظيفي هي عملية تحديد متطلبات التحقق وتوثيقها والحفاظ عليها ، وهو أمر بالغ الأهمية لضمان الجودة الممتازة لتصميم IC الأساسي.
يتضمن تعريف المتطلبات ترجمة أهداف التحقق من اللغة الطبيعية الغامضة (NL) إلى مواصفات تحقق بشكل رسمي ودقيق. تملي جودة الترجمة مباشرة صحة التحقق. عادة ما تكون هذه العملية شاقة وتستهلك دورات تصميم كبيرة مع العديد من التكرارات للتدقيق اليدوي لضمان الجودة.
تم اقتراح مجموعتين من الأساليب الكلاسيكية لأتمتة الترجمة. تتمثل إحدى مجموعات الأساليب في إدخال لغة طبيعية مقيدة (CNL) لإضفاء الطابع الرسمي على صياغة المواصفات ، متبوعة بمحرك ترجمة قائم على القوالب. يتطلب هذا النهج استثمارًا كبيرًا مقدمًا في تطوير بناء جملة قوي لـ CNL ونظام مترجم / قالب شامل لضمان أنه قوي بما يكفي لتلبية معظم المتطلبات التي تمت مواجهتها في التحقق الوظيفي. علاوة على ذلك ، فإنه يثقل كاهل المطورين بتعلم لغة إضافية ، مما يمنع الفكرة من أن تصبح مقبولة على نطاق واسع.
تستفيد المجموعة الأخرى من عملية اللغة الطبيعية الكلاسيكية (NLP) لتحليل مواصفات NL واستخراج العناصر الرئيسية ذات الصلة لصياغة المواصفات الرسمية.
أدى تقدم ترجمة ML في مجال NL إلى جعل الترجمة الآلية المؤتمتة بالكامل مجدية تجاريًا وتجاوز أحيانًا أداء المترجمين البشريين العاديين. لقد أشعل الأمل في الاستفادة من نماذج NL المدربة على نطاق واسع مع ما يصل إلى مليارات من المعلمات لترجمة مواصفات NL مباشرة إلى مواصفات التحقق في SystemVerilog Assertions (SVA) أو لغة مواصفات الخاصية (PSL) أو لغات أخرى. لوحظت عدة محاولات للقيام بترجمة شاملة ناجحة ، ولكن لم يتم تجهيز أي منها. العقبة الرئيسية أمام هذا النهج هي ندرة مجموعات البيانات التدريبية المتاحة التي تربط بين مواصفات اللغة الإنجليزية والترجمة الرسمية. تتكون مجموعات البيانات الأكثر شمولاً من حوالي 100 زوج من الجمل. الرقم يتضاءل مقارنة بأقرانهم في NL ، الذين يأتون بشكل روتيني بملايين أو حتى بلايين أزواج الجمل.
على عكس تعريف المتطلبات ، ينظر التلخيص إلى الكود ويترجمه إلى ملخص NL مفهومة من قبل الإنسان. يساعد المطورين في قراءة التعليمات البرمجية الأقل صيانة بشكل مثالي أو فهم المنطق المعقد. يمكن أن يقوم تلخيص التعليمات البرمجية الذي تم تنفيذه بشكل مثالي بإدراج وثائق مضمنة في كتل التعليمات البرمجية أو إنشاء وثائق منفصلة. بفضل مساعدتها ، يمكن تحسين قابلية الصيانة وتوثيق الكود بشكل كبير.
تم تجربة تطبيق ML على تلخيص الكود بلغات الكمبيوتر الأكثر شيوعًا ، مثل Python و JavaScript. جربت عدة مجموعات من الأساليب درجات مختلفة من النجاح. تركز المناهج القائمة على استرجاع المعلومات (IR) على تطبيق البرمجة اللغوية العصبية على كود المصدر والبحث عن كود مشابه مع تلخيص موجود في المكان. تعتمد هذه المجموعة من الأساليب بشكل كبير على جودة الكود الموجود مع الملخصات. يمكن استخدامه فقط داخل مؤسسة قريبة حيث تتوفر العديد من مستودعات الكود الموجودة بسهولة. تحاول المناهج القائمة على الاستدلال بدلاً من ذلك تحديد قواعد محددة بناءً على الاستدلال المحدد في تعريف الوحدة ، على سبيل المثال ، يمكن اعتبار الوحدة التي تحتوي على العديد من الوحدات الفرعية لأسطر أوامر القراءة / الكتابة الأساسية وحدة ذاكرة. لذلك ، يمكن إنشاء ملخص من نمط محدد مسبقًا لوحدة الذاكرة.
في وقت كتابة هذا التقرير ، لم يتم الإبلاغ عن تلخيص الكود في التحقق من تصميم IC في أي أدبيات. من المعقول أن نكون متفائلين بأن نجاح اللغات الأخرى يمكن أن يتحقق في تصميم IC والتحقق ، الأمر الذي لم يؤكده مجتمع البحث بعد. على وجه الخصوص ، قد يساعد التقدم الأخير في النماذج عبر اللغات في نقل المعرفة المكتسبة من لغات البرمجة الأخرى إلى تصميم IC. ومع ذلك ، بالإضافة إلى التحديات العامة التي تواجه ML في تلخيص الكود ، فإن التوازي الزمني الجوهري في تصميم IC ورمز التحقق يمكن أن يمثل تحديات غير شائعة في لغات البرمجة الأخرى.
تعدين المواصفات كان موضوع هندسة برمجيات طويل المدى. كبديل لصياغة المواصفات يدويًا ، فإنه يستخرج المواصفات بشكل غير مباشر من التصميم قيد التنفيذ (DUT). يمكن تطبيق ML على أنماط الألغام المتكررة من آثار المحاكاة. يمكن أن يساعد في أتمتة إغلاق التغطية القائم على المحاكاة أو التحقق الرسمي. من المفترض أن تكون الأنماط المتكررة الشائعة هي السلوك المتوقع لـ DUT. بدلاً من ذلك ، نادرًا ما يحدث نمط حدث في الآثار يمكن اعتباره شذوذًا ؛ لذلك ، يمكن استخدامه لأغراض التشخيص وتصحيح الأخطاء.
تم تطبيق ML في اكتشاف الأنماط واكتشاف الشذوذ عبر العديد من المجالات حيث تتوفر البيانات الزمنية لنظام معقد. عظيم وآخرون اقتراح نهج هندسة البرمجيات العامة حيث يتم استخدام ML لاكتشاف المواصفات الرسمية من مراقبة آثار البروتوكول وإيجاد التنفيذ الإشكالي المحتمل للبروتوكول. ألهمت التجارب الناجحة مشاريع بحثية متابعة مثيرة للاهتمام في التنقيب عن المواصفات باستخدام ML.
تحليل الكود الثابت
مع نمو تكلفة إصلاح الخلل بشكل كبير على طول مراحل تطوير IC ، يوفر تحليل الكود الثابت خيارًا جذابًا لتحسين جودة الكود وقابلية الصيانة في مرحلة مبكرة من تطوير التصميم.
تشير رائحة الكود إلى أنماط التصميم دون المستوى الأمثل في الكود المصدري ، والتي قد تكون صحيحة من الناحية التركيبية والمعنوية ، ولكنها تنتهك أفضل الممارسات ويمكن أن تؤدي إلى ضعف إمكانية صيانة الكود. مثال خاص هو تكرار الكود ، حيث يتم تنفيذ نفس الوظيفة عدة مرات عبر مشروع أو قاعدة التعليمات البرمجية بأكملها. يمكن أن تحتوي بعض النسخ على خطأ معين تم إصلاحه في فترة قصيرة نسبيًا ، بينما يمر الخطأ نفسه دون أن يلاحظه أحد في النسخ الأخرى.
يعتمد اكتشاف رائحة الشفرة الكلاسيكية على قواعد إرشادية محددة لتحديد الأنماط في الكود المصدري. بدلاً من تطوير هذه القواعد والمقاييس يدويًا في أدوات تحليل الكود الثابت ، يمكن تدريب نهج قائم على ML على كمية كبيرة من كود المصدر المتاح لتحديد روائح الكود. أثبتت الأبحاث أن اكتشاف الرائحة باستخدام ML يمكن أن يؤدي إلى اكتشاف رائحة الكود العالمي وجهود أقل بشكل ملحوظ في تنفيذ الأنماط. يمكن بعد ذلك استخدام درجة الرائحة الناتجة لتقييم جودة الكود ومساعدة المطورين على تحسين جودة المنتج باستمرار. علاوة على ذلك ، قد توفر إعادة هيكلة الكود المستند إلى ML تلميحات مفيدة حول تحسين رائحة الكود أو حتى إجراء بعض التغييرات المرشحة.
لم يكن تطبيق ML في التحقق الوظيفي مرئيًا بعد ، كما أن عدم توفر مجموعات كبيرة من بيانات التدريب منع البحث الحالي من استغلال إمكانات هذا الحل بالكامل.
يمكن للمطورين الذين يعملون على تصميم IC أن يكونوا أكثر إنتاجية عند توفير الأدوات المناسبة. يعد إكمال الكود البسيط ميزة قياسية في بيئة التطوير المتكاملة الحديثة (IDE). ومع ذلك ، تم اقتراح تقنيات أكثر تقدمًا تتضمن التعلم العميق وتنضج بسرعة. أصبح من الممكن الآن تدريب شبكات ANN بمليارات من المعلمات من العديد من مستودعات الأكواد مفتوحة المصدر واسعة النطاق لتقديم توصيات معقولة لمقتطفات التعليمات البرمجية من هدف تنفيذ المطورين أو السياق.
قد يساعد ML أيضًا مطوري IC على البقاء منتجين مع البحث عن الكود الدلالي ، والذي يسمح باسترداد الكود ذي الصلة من خلال استعلامات NL. نظرًا لأن الكود عادةً ما يكون مليئًا بالاختصارات المختلفة والمصطلحات الفنية ، يمكن أن تكون عمليات البحث الدلالية أكثر فاعلية في العثور على مقتطفات التعليمات البرمجية ذات الصلة دون التهجئة الصحيحة للمتغير الرئيسي أو الوظيفة أو أسماء الوحدات النمطية. في حين أن البحث الدلالي يشبه البحث الدلالي في العديد من محركات البحث الحالية ، إلا أن البحث عن الكود الدلالي قادر على المساعدة في العثور على كود مختصر وعالي التقنية بمفاهيم غامضة. يمكن أن يحقق متوسط الترتيب المتبادل لأفضل نموذج بالفعل درجات قابلة للاستخدام تبلغ 70٪.
على الرغم من أنه من الناحية النظرية يمكن تطبيق نفس تقنيات ML المطبقة على لغات البرمجة الأخرى على تصميم IC ، لم يتم نشر أي بحث حتى الآن حول مساعدة الترميز.
تسريع التحقق
تشير الدراسات الاستقصائية الحديثة إلى أن التحقق الوظيفي لا يزال أكثر الخطوات استهلاكا للوقت في تصميم IC ، ولا تزال الأخطاء الوظيفية والمنطقية هي أهم سبب في عملية إعادة الاتصال. أي تحسين في سرعة التحقق الوظيفي سيؤثر بشكل كبير على جودة وإنتاجية تصميم IC. تم استخدام ML في كل من التحقق الرسمي والقائم على المحاكاة لتسريعها.
يستخدم التحقق الرسمي خوارزميات رياضية رسمية لإثبات صحة التصميم. يستخدم تنسيق التحقق الرسمي الحديث خوارزميات رسمية لاستهداف التصاميم ذات الأحجام والأنواع والتعقيدات المختلفة. يمكن أن تساعد الخبرة والاستدلال المطورين على اختيار أنسب الخوارزميات من المكتبة لمشكلة معينة.
كطريقة إحصائية ، لا يمكن لتعلم الآلة معالجة مشاكل التحقق الرسمية بشكل مباشر. ومع ذلك ، فقد ثبت أنه مفيد جدًا في التنسيق الرسمي. من خلال توقع موارد الحوسبة واحتمالية حل مشكلة ما ، من الممكن جدولة المحولين الرسميين لاستخدام هذه الموارد على أفضل وجه لتقصير وقت التحقق من خلال جدولة الحلول الواعدة مع استهلاك أقل لموارد الحوسبة أولاً. يمكن للمصنف القائم على شجرة القرار Ada-boost تحسين نسبة الحالات التي تم حلها من تنسيق خط الأساس من 95٪ إلى 97٪ ، بمتوسط سرعة يصل إلى 1.85. كانت تجربة أخرى قادرة على التنبؤ بمتطلبات الموارد للتحقق الرسمي بمتوسط خطأ يبلغ 32٪. يتم تطبيق هندسة الميزات بشكل متكرر لتحديد الميزات بعناية من DUT والخصائص والقيود الرسمية ، والتي يتم استخدامها بعد ذلك لتدريب نموذج الانحدار الخطي المتعدد للتنبؤ بمتطلبات الموارد.
على عكس التحقق الرسمي ، لا يمكن عادةً أن يضمن التحقق المستند إلى المحاكاة الدقة الكاملة في التصميم. بدلاً من ذلك ، يتم وضع التصميم تحت طاولة اختبار مع تطبيق محفزات إدخال عشوائية أو ثابتة معينة ، بينما تتم مقارنة المخرجات بالمخرجات المرجعية للتحقق مما إذا كان سلوك التصميم متوقعًا أم لا. في حين أن المحاكاة هي الخبز والزبدة للتحقق الوظيفي ، يمكن أن يعاني التحقق القائم على المحاكاة أيضًا من أوقات التحقق الطويلة. ليس من غير المألوف أن يستغرق التحقق من التصميم المعقد أسابيع حتى يكتمل.
هناك فكرة واعدة تتم مناقشتها وتجربتها وهي استخدام ML لنمذجة سلوك نظام معقد والتنبؤ به. تثبت نظرية التقريب العالمية أن المدرك متعدد الطبقات (MLP) ، وهو ANN للتغذية الأمامية بطبقة مخفية واحدة على الأقل ، يمكنه تقريب أي وظيفة مستمرة بدقة عشوائية. في حين أن الشبكات العصبية المتكررة المعايرة (RNNs) ، وهي شكل متخصص من ANN ، ثبت أنها تقارب أي نظام ديناميكي مع الذاكرة. جعلت أجهزة تسريع ML المتقدمة من الممكن أن تقوم شبكات ANN بنمذجة سلوك بعض وحدات تصميم IC لتسريع عمليات المحاكاة الخاصة بهم. يمكن تحقيق تسارع كبير اعتمادًا على قدرة مسرعات الذكاء الاصطناعي وتعقيد نماذج ML.
توليد الاختبار وإغلاق التغطية
إلى جانب أنماط الاختبار المحددة يدويًا ، تشتمل التقنيات القياسية المستخدمة في التحقق القائم على المحاكاة على إنشاء اختبار عشوائي وأتمتة ذكية قائمة على الرسم البياني. نظرًا لطبيعة "الذيل الطويل" لإغلاق التغطية ، يمكن أن يؤدي تحسين الكفاءة الصغير بسهولة إلى تقليل وقت المحاكاة بشكل كبير. ركزت الكثير من الأبحاث حول تطبيق ML على التحقق الوظيفي على هذا المجال.
أظهرت دراسات تعلم الآلة المكثفة أنها يمكن أن تحقق أداءً أفضل من توليد الاختبار العشوائي. تستخدم معظم الأبحاث "نموذج الصندوق الأسود" ، بافتراض أن DUT عبارة عن صندوق أسود يمكن التحكم في مدخلاته ومراقبة مخرجاته. اختياريا ، يمكن ملاحظة بعض نقاط الاختبار. لا يسعى البحث إلى فهم سلوك DUT. بدلاً من ذلك ، يتم إنفاق التركيز على تقليل الاختبارات غير الضرورية. يستخدمون تقنيات ML المختلفة للتعلم من بيانات الإدخال / الإخراج / المراقبة التاريخية لضبط مولدات الاختبار العشوائية أو القضاء على الاختبارات التي من غير المحتمل أن تكون مفيدة. في تطور حديث ، تم استخدام نموذج قائم على التعلم المعزز (RL) للتعلم من مخرجات DUT والتنبؤ بالاختبارات الأكثر احتمالية لوحدة التحكم في ذاكرة التخزين المؤقت. عندما تكون المكافأة الممنوحة لنموذج ML هي أعماق FIFO ، فإن التجارب قادرة على التعلم من النتائج التاريخية والوصول إلى أعماق FIFO المستهدفة بالكامل في عدة تكرارات ، بينما لا يزال النهج العشوائي القائم على توليد الاختبار يكافح للوصول إلى أكثر من 1. تتطلب بنية ML ذات التفاصيل الدقيقة أن يتم تدريب نموذج ML لكل نقطة تغطية. يتم استخدام المصنف الثلاثي أيضًا للمساعدة في تحديد ما إذا كان يجب محاكاة الاختبار أو التخلص منه أو استخدامه لإعادة تدريب النموذج بشكل أكبر. تم اختبار جهاز ناقل الدعم (SVM) والغابات العشوائية والشبكة العصبية العميقة على تصميم وحدة المعالجة المركزية. يمكنه إغلاق التغطية بنسبة 100٪ مع اختبارات أقل من 3 إلى 5 مرات. أظهرت التجارب الإضافية على تصاميم ولايات ميكرونيزيا الموحدة وغير التابعة لها انخفاضًا بنسبة 69 ٪ و 72 ٪ مقارنةً بتوليد التسلسل الموجه. ومع ذلك ، لا تزال معظم هذه النتائج تعاني من محدودية الطبيعة الإحصائية لتعلم الآلة. تقدم مراجعة أكثر شمولاً لتوليد الاختبار الموجه بالتغطية (CDG) المستندة إلى ML نظرة عامة على العديد من نماذج ML ونتائج تجاربها. الخوارزميات الجينية لشبكة Bayesian وأساليب البرمجة الجينية ، ونموذج ماركوف ، واستخراج البيانات ، والبرمجة المنطقية الاستقرائية كلها تجارب بدرجات مختلفة من النجاح.
في جميع الأساليب التي تمت مناقشتها ، يمكن لنموذج ML أن يقوم بالتنبؤ بناءً على التعلم من البيانات التاريخية التي جمعها ولكن لديه الحد الأدنى من القدرة على التنبؤ بالمستقبل ، أي الاختبار الذي قد يكون خيارًا واعدًا أكثر للوصول إلى هدف اختبار مكشوف. نظرًا لعدم توفر هذا النوع من المعلومات حتى الآن ، فإن أفضل ما يمكنهم فعله هو اختيار الاختبارات التي لا تمت بصلة للاختبارات التاريخية. استكشفت تجربة واعدة أخرى نهجًا مختلفًا ، حيث يُنظر إلى DUT على أنه مربع أبيض ، ويتم تحليل الكود وتحويله إلى رسم بياني للتحكم / تدفق البيانات (CDFG). يستخدم البحث القائم على التدرج على شبكة Graph Neural Network المدربة (GNN) لإنشاء اختبارات لهدف اختبار محدد مسبقًا. حققت التجارب على IBEX v1 و v2 و TPU دقة 74٪ و 73٪ و 90٪ عند توقع التغطية عند التدريب مع 50٪ من نقاط التغطية. تؤكد العديد من التجارب الإضافية أيضًا أن طريقة البحث المتدرج المستخدمة غير حساسة لمعمارية GNN.
من الملاحظ أنه نظرًا لعدم توفر بيانات التدريب ، فإن معظم مناهج ML هذه تتعلم فقط من كل تصميم دون استغلال أي معرفة مسبقة من تصميمات أخرى مماثلة.
تحليل الأخطاء
يهدف تحليل الأخطاء إلى تحديد الأخطاء المحتملة وترجمة كتل التعليمات البرمجية التي تحتوي عليها وإعطاء اقتراحات الإصلاح. وجدت الدراسات الاستقصائية الحديثة أن التحقق من IC يقضي تقريبًا نفس مقدار الوقت الذي يستغرقه في التصميم وأن الأخطاء الوظيفية تساهم في حوالي 50 ٪ من عمليات التنفس لتصميم ASIC. لذلك ، من الأهمية بمكان أن يتم تحديد هذه الأخطاء وإصلاحها في مرحلة التحقق الوظيفي المبكر. تم استخدام ML لمساعدة المطورين على اكتشاف الأخطاء في التصميمات والعثور على الأخطاء بشكل أسرع.
يجب حل ثلاث مشكلات تقدمية لتسريع عملية البحث عن الأخطاء في التحقق الوظيفي ، وهي تجميع الحشرات حسب أسبابها الجذرية ، وتصنيف الأسباب الجذرية ، واقتراح الحلول. تركز معظم الأبحاث على أول اثنين ، مع عدم توفر نتائج بحث عن الثالثة حتى الآن.
يمكن استخدام ملفات سجل المحاكاة شبه المنظمة لتحليل الأخطاء. يستخرج 616 ميزة مختلفة من البيانات الوصفية وخطوط الرسائل من ملفات السجل للتصاميم غير المكشوف عنها. حققت تجربة التجميع المعلومات المتبادلة المعدلة (AMI) 0.543 مع K-mean و clustering clustering و 0.593 مع DBSCAN حتى بعد تقليل أبعاد الميزة ، بعيدًا عن التجميع المثالي عندما تحقق AMI 1.0. تم أيضًا اختبار خوارزميات التصنيف المختلفة لتحديد دقتها في حل المشكلة 2. تمت مقارنة جميع الخوارزميات ، بما في ذلك الغابة العشوائية ، وتصنيف المتجهات الداعمة (SVC) ، وشجرة القرار ، والانحدار اللوجستي ، والجيران K ، والخوارزميات الساذجة ، وفقًا لقدرتها على توقع الأسباب الجذرية. تم تحقيق أفضل نتيجة بواسطة Random Forest مع دقة تنبؤ بنسبة 90.7٪ و 0.913 درجة F1. يقترح نهج آخر استخدام مجموعة بيانات مصنفة من التزام التعليمات البرمجية لتدريب نموذج تعزيز التدرج ، حيث تم اختبار أكثر من 100 ميزة حول المؤلفين والمراجعات والرموز والمشاريع حتى تم اختيار 36 ميزة للخوارزمية. تظهر التجارب أنه من الممكن التنبؤ بالالتزامات التي من المرجح أن تحتوي على رمز عربات التي تجرها الدواب ، ومن المحتمل أن تقلل من وقت البحث اليدوي بشكل كبير.
ومع ذلك ، نظرًا للبساطة النسبية لتقنيات ML المعتمدة ، فهم غير قادرين على تدريب نماذج ML التي يمكن أن تأخذ في الاعتبار دلالات غنية في التعليمات البرمجية أو التعلم من إصلاحات الأخطاء التاريخية. لذلك ، لا يمكنهم شرح سبب حدوث الأخطاء وكيفية حدوثها ولا يقترحون مراجعة الكود للقضاء على الأخطاء تلقائيًا أو شبه تلقائيًا.
تقنيات ونماذج تعلم الآلة الناشئة المطبقة على التحقق الوظيفي
شوهدت اختراقات كبيرة في تقنيات ونماذج وخوارزميات تعلم الآلة في السنوات الأخيرة. وجد بحثنا أن عددًا قليلاً جدًا من هذه التقنيات الناشئة يتم تبنيها من خلال أبحاث التحقق الوظيفي ، ونعتقد بتفاؤل أن النجاح الكبير سيكون ممكنًا بمجرد استخدامها لمعالجة المشكلات الصعبة في التحقق الوظيفي.
نماذج NL واسعة النطاق المستندة إلى المحولات مع مليارات من المعلمات المدربة على الكميات الهائلة من النص الذي تم تحقيقه بالقرب من مستوى أداء الإنسان أو تجاوز المستوى البشري في مهام NL المختلفة ، على سبيل المثال ، الإجابة على الأسئلة ، والترجمة الآلية ، وتصنيف النص ، والتلخيص التجريدي ، و آحرون. أظهر تطبيق نتائج البحث هذه في تحليل الكود أيضًا إمكانات وتنوع هذه النماذج الكبيرتين. وقد ثبت أن هذه النماذج يمكنها حقًا استيعاب مجموعة كبيرة من بيانات التدريب ، وتنظيم المعرفة المكتسبة وتوفير إمكانية الوصول بسهولة. هذه القدرة مفيدة في تحليل الكود الثابت ، وهندسة المتطلبات ، والمساعدة في الترميز للعديد من لغات البرمجة الشائعة. بالنظر إلى بيانات التدريب الكافية ، من المعقول الاعتقاد بأن هذه التقنيات يمكنها تدريب نماذج ML على مهام التحقق الوظيفية المختلفة.
حتى وقت قريب ، كان من الصعب تطبيق ML على بيانات الرسم البياني بسبب تعقيد هيكلها. لقد وعدت التطورات في الشبكة العصبية للرسم البياني (GNN) بفرصة جديدة للتحقق الوظيفي. أحد هذه الأساليب يحول التصميم إلى رسم بياني لتدفق البيانات / الكود ، والذي يستخدم بعد ذلك لتدريب GNN للمساعدة في التنبؤ بإغلاق التغطية للاختبار. يعد هذا النوع من نهج الصندوق الأبيض برؤية غير متوفرة سابقًا حول التحكم وتدفق البيانات في التصميم ، والتي يمكن أن تولد اختبارات موجهة لملء فجوات التغطية المحتملة. يمكن أن تمثل الرسوم البيانية معلومات ارتباطية وتركيبية ودلالية ثرية تمت مواجهتها أثناء التحقق. يمكن للمعلومات الغنية من تدريب نموذج ML على الرسوم البيانية تحمل العديد من مهام التحقق الوظيفية الجديدة الممكنة ، على سبيل المثال ، البحث عن الأخطاء وإغلاق التغطية.
وفي الختام
تعمل EDA 4.0 على تحويل أتمتة التصميم الإلكتروني من خلال قوة الذكاء الاصطناعي وتوفر العديد من التقنيات الرئيسية التي ستساعد المهندسين على إدراك التغييرات الثورية في الصناعة 4.0. في هذه المقالة نقدم مسحًا شاملاً للمساهمات المحتملة للتعلم الآلي في معالجة الجوانب المختلفة للتحقق الوظيفي. تسلط المقالة الضوء على التطبيقات النموذجية لتعلم الآلة في التحقق الوظيفي وتلخص أحدث الإنجازات في هذا المجال.
ومع ذلك ، على الرغم من تطبيق تقنيات تعلم الآلة المتنوعة ، فإن البحث الحالي يعتمد في المقام الأول على أساليب تعلم الآلة الأساسية ويقتصر على توافر بيانات التدريب. يذكرنا هذا الموقف بالمراحل المبكرة لتطبيقات ML في المجالات المتقدمة الأخرى ، مما يشير إلى أن تطبيقات ML في التحقق الوظيفي لا تزال في مرحلتها الناشئة. لا تزال هناك إمكانات كبيرة غير مستغلة للاستفادة من التقنيات والنماذج المتقدمة للاستغلال الكامل لقدرات ML. علاوة على ذلك ، فإن استخدام المعلومات الدلالية والعلائقية والهيكلية في تطبيقات ML اليوم لم يتحقق بالكامل.
لاستكشاف أكثر تفصيلاً لهذا الموضوع ، ندعوك للرجوع إلى ورقتنا البيضاء بعنوان مسح لتطبيقات التعلم الآلي في التحقق الوظيفي. في هذا المستند التعريفي التمهيدي ، نتعمق أكثر في الموضوع ، ونقدم رؤى من منظور صناعي ونناقش التحدي الملح الذي يمثله التوافر المحدود للبيانات. تتضمن الورقة الكاملة أيضًا مراجع شاملة للبحوث الرائعة والكتابات التي تُعلم الكثير من هذه المقالة.
هاري فوستر هو كبير العلماء للتحقق في شركة Siemens Digital Industries Software ؛ وهو المؤسس المشارك والمحرر التنفيذي لأكاديمية التحقق. شغل فوستر منصب الرئيس العام لمؤتمر أتمتة التصميم لعام 2021 ويشغل حاليًا منصب الرئيس السابق. وهو حاصل على براءات اختراع متعددة في مجال التحقق وشارك في تأليف ستة كتب عن التحقق. حصل فوستر على جائزة Accellera Technical Excellence لإسهاماته في تطوير معايير الصناعة وكان المنشئ الأصلي لمعيار مكتبة Accellera Open Verification Library (OVL). بالإضافة إلى ذلك ، حصل فوستر على جائزة الخدمة المتميزة لعام 2022 ACM وجائزة الخدمة المتميزة لعام 2022 IEEE CEDA.
Tom Fitzpatrick هو مهندس التحقق الاستراتيجي في شركة Siemens Digital Industries Software (Siemens EDA) حيث يعمل على تطوير منهجيات ولغات ومعايير تحقق متقدمة. لقد كان مساهمًا كبيرًا في العديد من معايير الصناعة التي حسنت بشكل كبير مشهد التحقق الوظيفي على مدار الـ 25 عامًا الماضية ، بما في ذلك Verilog 1364 و SystemVerilog 1800 و UVM 1800.2. وهو عضو مؤسس ونائب رئيس حالي لمجموعة عمل Accellera Portable Stimulus Working Group ويشغل حاليًا منصب رئيس مجموعات عمل IEEE 1800 و Accellera UVM-AMS. فيتزباتريك عضو منذ فترة طويلة في لجنة التوجيه DVCon الأمريكية وهو الرئيس العام لـ DVConUS 2024. وهو أيضًا عضو في اللجنة التنفيذية لمؤتمر أتمتة التصميم. يحمل فيتزباتريك درجتي الماجستير والبكالوريوس في الهندسة الكهربائية وعلوم الكمبيوتر من معهد ماساتشوستس للتكنولوجيا.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- شراء وبيع الأسهم في شركات ما قبل الاكتتاب مع PREIPO®. الوصول هنا.
- المصدر https://semiengineering.com/welcome-to-eda-4-0-and-the-ai-driven-revolution/

