هذا منشور ضيف كتبه Axfood AB.
في هذا المنشور، نشارك كيف قامت شركة Axfood، وهي شركة سويدية كبيرة لبيع المواد الغذائية بالتجزئة، بتحسين العمليات وقابلية التوسع لعمليات الذكاء الاصطناعي (AI) والتعلم الآلي (ML) الحالية الخاصة بها من خلال إنشاء نماذج أولية بالتعاون الوثيق مع خبراء AWS واستخدام الأمازون SageMaker.
اكسفود هي ثاني أكبر شركة لبيع المواد الغذائية بالتجزئة في السويد، ويعمل بها أكثر من 13,000 موظف وأكثر من 300 متجر. لدى Axfood هيكل يضم العديد من فرق علوم البيانات اللامركزية ذات مجالات مسؤولية مختلفة. جنبًا إلى جنب مع فريق منصة البيانات المركزية، تعمل فرق علوم البيانات على جلب الابتكار والتحول الرقمي من خلال حلول الذكاء الاصطناعي والتعلم الآلي إلى المؤسسة. تستخدم Axfood Amazon SageMaker لتنمية بياناتها باستخدام التعلم الآلي ولديها نماذج قيد الإنتاج لسنوات عديدة. في الآونة الأخيرة، يتزايد مستوى التطور والعدد الهائل من النماذج في الإنتاج بشكل كبير. ومع ذلك، على الرغم من أن وتيرة الابتكار عالية، فقد طورت الفرق المختلفة طرق العمل الخاصة بها وكانت تبحث عن أفضل ممارسات MLOps الجديدة.
التحدي الذي نواجهه
للحفاظ على قدرتها التنافسية فيما يتعلق بالخدمات السحابية والذكاء الاصطناعي/التعلم الآلي، اختارت Axfood الشراكة مع AWS وتتعاون معها منذ سنوات عديدة.
خلال إحدى جلسات العصف الذهني المتكررة مع AWS، كنا نناقش كيفية التعاون بشكل أفضل عبر الفرق لزيادة وتيرة الابتكار وكفاءة علوم البيانات وممارسي تعلم الآلة. قررنا بذل جهد مشترك لبناء نموذج أولي لأفضل الممارسات الخاصة بـ MLOps. كان الهدف من النموذج الأولي هو بناء نموذج نموذجي لجميع فرق علوم البيانات لبناء نماذج تعلم الآلة فعالة وقابلة للتطوير، وهو الأساس لجيل جديد من منصات الذكاء الاصطناعي والتعلم الآلي لشركة Axfood. يجب أن يربط القالب ويجمع بين أفضل الممارسات من خبراء AWS ML ونماذج أفضل الممارسات الخاصة بالشركة - وهو الأفضل في كلا العالمين.
قررنا بناء نموذج أولي من أحد نماذج تعلم الآلة الأكثر تطورًا حاليًا داخل Axfood: التنبؤ بالمبيعات في المتاجر. وبشكل أكثر تحديدًا، توقعات الحملات القادمة للفواكه والخضروات لمتاجر بيع المواد الغذائية بالتجزئة. يدعم التنبؤ اليومي الدقيق عملية الطلب للمتاجر، مما يزيد من الاستدامة عن طريق تقليل هدر الطعام نتيجة لتحسين المبيعات من خلال التنبؤ الدقيق بمستويات المخزون المطلوبة في المتجر. كان هذا هو المكان المثالي للبدء في النموذج الأولي الخاص بنا - لن تحصل Axfood على منصة جديدة للذكاء الاصطناعي/تعلم الآلة فحسب، بل سنحصل أيضًا على فرصة لتقييم قدراتنا في تعلم الآلة والتعلم من كبار خبراء AWS.
الحل الذي نقدمه: قالب ML جديد على Amazon SageMaker Studio
قد يكون إنشاء مسار كامل لتعلم الآلة مصممًا لحالة عمل فعلية أمرًا صعبًا. في هذه الحالة، نقوم بتطوير نموذج للتنبؤ، لذلك هناك خطوتان رئيسيتان يجب إكمالهما:
- تدريب النموذج على عمل تنبؤات باستخدام البيانات التاريخية.
- تطبيق النموذج المدرب للتنبؤ بالأحداث المستقبلية.
في حالة Axfood، تم بالفعل إعداد مسار يعمل بشكل جيد لهذا الغرض باستخدام دفاتر ملاحظات SageMaker وتم تنظيمه بواسطة منصة إدارة سير العمل التابعة لجهة خارجية Airflow. ومع ذلك، هناك العديد من الفوائد الواضحة لتحديث منصة ML لدينا والانتقال إليها أمازون ساجميكر ستوديو و خطوط أنابيب Amazon SageMaker. يوفر الانتقال إلى SageMaker Studio العديد من الميزات الجاهزة المحددة مسبقًا:
- مراقبة النموذج وجودة البيانات بالإضافة إلى إمكانية شرح النموذج
- أدوات بيئة التطوير المتكاملة (IDE) المضمنة مثل تصحيح الأخطاء
- مراقبة التكلفة/الأداء
- إطار قبول النموذج
- نموذج التسجيل
ومع ذلك، فإن الحافز الأكثر أهمية لشركة Axfood هو القدرة على إنشاء قوالب مشروع مخصصة باستخدام مشاريع Amazon SageMaker ليتم استخدامه كمخطط لجميع فرق علوم البيانات وممارسي تعلم الآلة. يتمتع فريق Axfood بالفعل بمستوى قوي وناضج من نماذج التعلم الآلي، لذلك كان التركيز الرئيسي على بناء البنية الجديدة.
حل نظرة عامة
يتمحور إطار تعلم الآلة الجديد المقترح من Axfood حول خطين رئيسيين: خط أنابيب بناء النموذج وخط أنابيب الاستدلال الدفعي:
- يتم إصدار خطوط الأنابيب هذه ضمن مستودعين Git منفصلين: مستودع إنشاء واحد ومستودع نشر (استدلال) واحد. ويشكلون معًا خط أنابيب قويًا للتنبؤ بالفواكه والخضروات.
- يتم تجميع خطوط الأنابيب في قالب مشروع مخصص باستخدام SageMaker Projects بالتكامل مع مستودع Git التابع لجهة خارجية (Bitbucket) وخطوط أنابيب Bitbucket للتكامل المستمر ومكونات النشر المستمر (CI/CD).
- يتضمن قالب مشروع SageMaker رمزًا أوليًا يتوافق مع كل خطوة من خطوات إنشاء المسارات ونشرها (سنناقش هذه الخطوات بمزيد من التفاصيل لاحقًا في هذا المنشور) بالإضافة إلى تعريف المسار — الوصفة لكيفية تشغيل الخطوات.
- يتم تبسيط أتمتة بناء المشاريع الجديدة بناءً على القالب كتالوج خدمة AWS، حيث يتم إنشاء المحفظة، لتكون بمثابة تجريد لمنتجات متعددة.
- كل منتج يترجم إلى تكوين سحابة AWS القالب، الذي يتم نشره عندما يقوم عالم البيانات بإنشاء مشروع SageMaker جديد باستخدام مخطط MLOps الخاص بنا كأساس. يؤدي هذا إلى تنشيط AWS لامدا وظيفة تقوم بإنشاء مشروع Bitbucket مع مستودعين - بناء النموذج ونشر النموذج - يحتويان على الكود الأولي.
ويوضح الرسم البياني التالي بنية الحل. يصور سير العمل A التدفق المعقد بين خطي الأنابيب النموذجيين - البناء والاستدلال. يُظهر سير العمل B التدفق لإنشاء مشروع ML جديد.

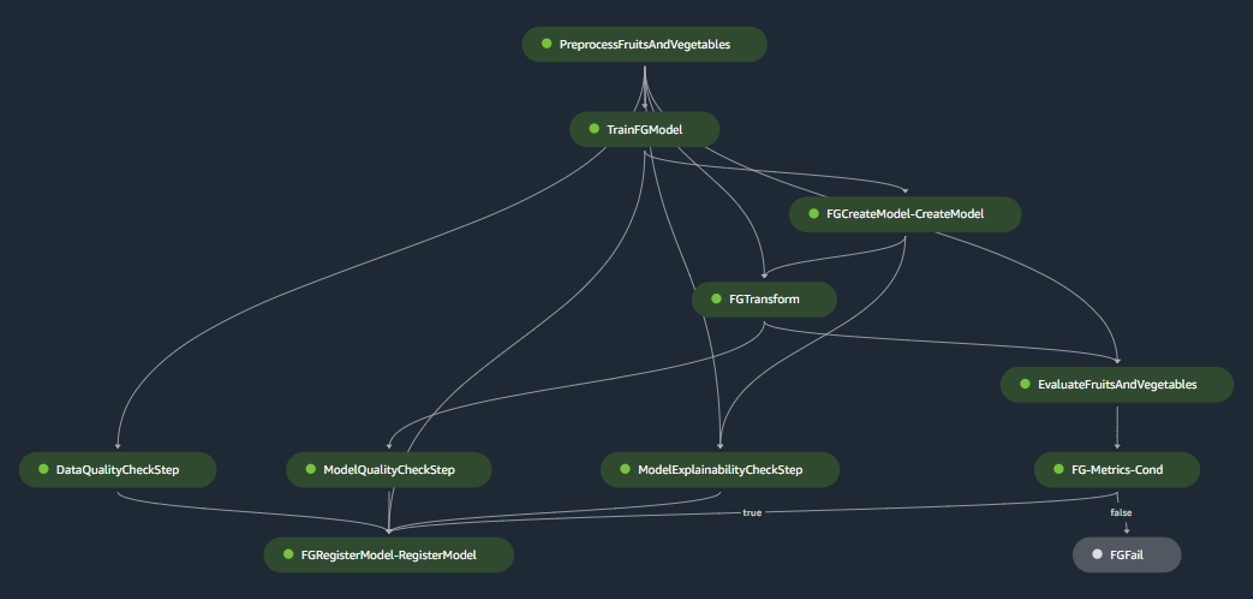
نموذج بناء خط الأنابيب
ينسق خط أنابيب بناء النموذج دورة حياة النموذج، بدءًا من المعالجة المسبقة، والانتقال خلال التدريب، وينتهي بالتسجيل في سجل النموذج:
- تجهيزها – هنا صانع الحكيم
ScriptProcessorيتم استخدام الفئة لهندسة الميزات، مما يؤدي إلى مجموعة البيانات التي سيتم تدريب النموذج عليها. - التدريب وتحويل الدفعة - يتم تسخير حاويات التدريب والاستدلال المخصصة من SageMaker لتدريب النموذج على البيانات التاريخية وإنشاء تنبؤات بشأن بيانات التقييم باستخدام SageMaker Estimator وTransformer للمهام المعنية.
- التقييم – يخضع النموذج المتدرب للتقييم من خلال مقارنة التنبؤات المولدة على بيانات التقييم مع الحقيقة الأرضية باستخدام
ScriptProcessor. - وظائف خط الأساس - يقوم خط الأنابيب بإنشاء خطوط أساس بناءً على الإحصائيات الموجودة في البيانات المدخلة. تعتبر هذه العناصر ضرورية لمراقبة البيانات وجودة النموذج، بالإضافة إلى إسناد الميزات.
- نموذج التسجيل – يتم تسجيل النموذج المدرب للاستخدام المستقبلي. ستتم الموافقة على النموذج من قبل علماء البيانات المعينين لنشر النموذج لاستخدامه في الإنتاج.
بالنسبة لبيئات الإنتاج، تتم إدارة استيعاب البيانات وآليات التشغيل عبر تنسيق Airflow الأساسي. وفي الوقت نفسه، أثناء التطوير، يتم تنشيط المسار في كل مرة يتم فيها تقديم التزام جديد إلى مستودع بناء النموذج Bitbucket. يصور الشكل التالي خط أنابيب بناء النموذج.
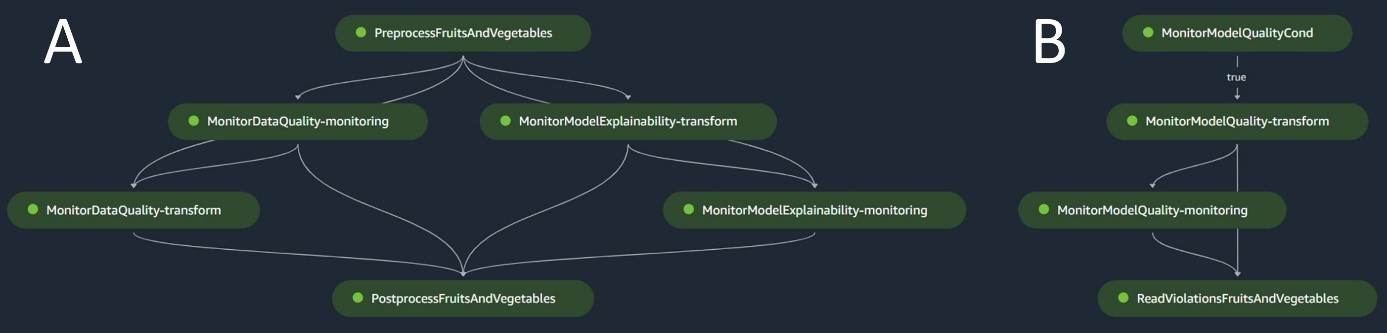
دفعة خط أنابيب الاستدلال
يتعامل خط أنابيب الاستدلال الدفعي مع مرحلة الاستدلال، والتي تتكون من الخطوات التالية:
- تجهيزها - تتم معالجة البيانات باستخدام
ScriptProcessor. - تحويل دفعة - يستخدم النموذج حاوية الاستدلال المخصصة مع محول SageMaker ويقوم بإنشاء تنبؤات في ضوء بيانات الإدخال التي تمت معالجتها مسبقًا. النموذج المستخدم هو أحدث نموذج مدرب معتمد في سجل النماذج.
- المعالجة البعدية - تخضع التنبؤات لسلسلة من خطوات المعالجة اللاحقة باستخدام
ScriptProcessor. - مراقبة - تكمل المراقبة المستمرة عمليات التحقق من الانحرافات المتعلقة بجودة البيانات وجودة النموذج وإسناد الميزة.
في حالة ظهور تناقضات، يقوم منطق الأعمال داخل البرنامج النصي للمعالجة اللاحقة بتقييم ما إذا كانت إعادة تدريب النموذج ضرورية أم لا. ومن المقرر أن يتم تشغيل خط الأنابيب على فترات منتظمة.
يوضح الرسم البياني التالي خط أنابيب الاستدلال الدفعي. يتوافق سير العمل أ مع المعالجة المسبقة وجودة البيانات وفحوصات انجراف إسناد الميزة والاستدلال والمعالجة اللاحقة. يتوافق سير العمل B مع اختبارات انحراف جودة النموذج. يتم تقسيم خطوط الأنابيب هذه لأن فحص انحراف جودة النموذج لن يتم تشغيله إلا في حالة توفر بيانات حقيقة أرضية جديدة.
مراقب نموذج SageMaker
بدافع الأمازون SageMaker نموذج مراقب متكاملة، تستفيد خطوط الأنابيب من المراقبة في الوقت الحقيقي لما يلي:
- جودة البيانات - يراقب أي انحراف أو تناقضات في البيانات
- جودة النموذج - مراقبة أي تقلبات في أداء النموذج
- إسناد الميزة – التحقق من الانجراف في سمات الميزة
تتطلب مراقبة جودة النموذج الوصول إلى بيانات الحقيقة الأرضية. على الرغم من أن الحصول على الحقيقة الأساسية قد يكون أمرًا صعبًا في بعض الأحيان، إلا أن استخدام مراقبة انحراف البيانات أو إسناد الميزات يعد بمثابة وكيل كفؤ لجودة النموذج.
على وجه التحديد، في حالة انحراف جودة البيانات، يراقب النظام ما يلي:
- مفهوم الانجراف - يتعلق هذا بالتغيرات في العلاقة بين المدخلات والمخرجات، مما يتطلب الحقيقة الأساسية
- التحول المتغير – يتم التركيز هنا على التعديلات في توزيع متغيرات المدخلات المستقلة
تعمل وظيفة انحراف البيانات في SageMaker Model Monitor على التقاط البيانات المدخلة وتدقيقها بدقة، ونشر القواعد والفحوصات الإحصائية. يتم رفع التنبيهات كلما تم الكشف عن الحالات الشاذة.
بالتوازي مع استخدام عمليات فحص انحراف جودة البيانات كبديل لمراقبة تدهور النموذج، يراقب النظام أيضًا انحراف إسناد الميزة باستخدام درجة الكسب التراكمي المخصوم (NDCG). تعتبر هذه النتيجة حساسة لكل من التغييرات في ترتيب تصنيف إسناد الميزة وكذلك لدرجات الإسناد الأولية للميزات. من خلال مراقبة الانحراف في إسناد الميزات الفردية وأهميتها النسبية، يصبح من السهل اكتشاف التدهور في جودة النموذج.
شرح النموذج
تعد إمكانية شرح النموذج جزءًا محوريًا من عمليات نشر تعلم الآلة، لأنها تضمن الشفافية في التنبؤات. لفهم مفصل نستخدم توضيح Amazon SageMaker.
وهو يقدم تفسيرات للنماذج العالمية والمحلية من خلال تقنية إسناد الميزة المحايدة للنموذج استنادًا إلى مفهوم قيمة شابلي. يُستخدم هذا لفك تشفير سبب إجراء تنبؤ معين أثناء الاستدلال. مثل هذه التفسيرات، والتي هي بطبيعتها متناقضة، يمكن أن تختلف بناء على خطوط أساس مختلفة. يساعد SageMaker Clarify في تحديد خط الأساس هذا باستخدام وسائل K أو نماذج K في مجموعة بيانات الإدخال، والتي تتم إضافتها بعد ذلك إلى مسار بناء النموذج. تتيح لنا هذه الوظيفة إنشاء تطبيقات ذكاء اصطناعي توليدية في المستقبل لزيادة فهم كيفية عمل النموذج.
التصنيع: من النموذج الأولي إلى الإنتاج
يتضمن مشروع MLOps درجة عالية من الأتمتة ويمكن أن يكون بمثابة مخطط لحالات استخدام مماثلة:
- يمكن إعادة استخدام البنية التحتية بالكامل، في حين يمكن تكييف الكود الأساسي لكل مهمة، مع اقتصار معظم التغييرات على تعريف خط الأنابيب ومنطق الأعمال للمعالجة المسبقة والتدريب والاستدلال والمعالجة اللاحقة.
- تتم استضافة البرامج النصية للتدريب والاستدلال باستخدام حاويات SageMaker المخصصة، بحيث يمكن استيعاب مجموعة متنوعة من النماذج دون إجراء تغييرات على البيانات ومراقبة النموذج أو خطوات شرح النموذج، طالما أن البيانات في تنسيق جدولي.
بعد الانتهاء من العمل على النموذج الأولي، تحولنا إلى كيفية استخدامه في الإنتاج. للقيام بذلك، شعرنا بالحاجة إلى إجراء بعض التعديلات الإضافية على قالب MLOps:
- يتضمن الكود الأساسي الأصلي المستخدم في النموذج الأولي للقالب خطوات المعالجة المسبقة والمعالجة اللاحقة التي يتم تشغيلها قبل وبعد خطوات تعلم الآلة الأساسية (التدريب والاستدلال). ومع ذلك، عند توسيع نطاق استخدام القالب لحالات الاستخدام المتعددة في الإنتاج، قد تؤدي خطوات المعالجة المسبقة والمعالجة اللاحقة المضمنة إلى تقليل عمومية التعليمات البرمجية وإعادة إنتاجها.
- لتحسين العمومية وتقليل التعليمات البرمجية المتكررة، اخترنا تقليص التدفقات بشكل أكبر. بدلاً من تشغيل خطوات المعالجة المسبقة والمعالجة اللاحقة كجزء من خط أنابيب تعلم الآلة، نقوم بتشغيلها كجزء من تنسيق تدفق الهواء الأساسي قبل وبعد تشغيل خط أنابيب تعلم الآلة.
- بهذه الطريقة، يتم استخلاص مهام المعالجة الخاصة بحالة الاستخدام من القالب، وما تبقى هو خط أنابيب ML الأساسي الذي يؤدي المهام العامة عبر حالات الاستخدام المتعددة مع الحد الأدنى من تكرار التعليمات البرمجية. يتم توفير المعلمات التي تختلف بين حالات الاستخدام كمدخلات إلى خط أنابيب ML من تنسيق Airflow الأساسي.
النتيجة: نهج سريع وفعال لبناء النموذج ونشره
أدى النموذج الأولي بالتعاون مع AWS إلى إنشاء قالب MLOps يتبع أفضل الممارسات الحالية وهو متاح الآن للاستخدام لجميع فرق علوم البيانات في Axfood. من خلال إنشاء مشروع SageMaker جديد داخل SageMaker Studio، يمكن لعلماء البيانات البدء في مشاريع تعلم الآلة الجديدة بسرعة وسهولة الانتقال إلى الإنتاج، مما يسمح بإدارة الوقت بشكل أكثر كفاءة. أصبح هذا ممكنًا من خلال أتمتة مهام MLOps المملة والمتكررة كجزء من القالب.
علاوة على ذلك، تمت إضافة العديد من الوظائف الجديدة بطريقة آلية إلى إعداد تعلم الآلة لدينا. وتشمل هذه المكاسب:
- مراقبة النموذج – يمكننا إجراء فحوصات الانجراف للتأكد من جودة النموذج والبيانات بالإضافة إلى إمكانية شرح النموذج
- نموذج ونسب البيانات - أصبح من الممكن الآن تتبع البيانات التي تم استخدامها لأي نموذج بالضبط
- نموذج التسجيل – يساعدنا ذلك في فهرسة النماذج للإنتاج وإدارة إصدارات النماذج
وفي الختام
في هذا المنشور، ناقشنا كيفية قيام Axfood بتحسين العمليات وقابلية التوسع لعمليات الذكاء الاصطناعي والتعلم الآلي الحالية لدينا بالتعاون مع خبراء AWS وباستخدام SageMaker والمنتجات ذات الصلة.
ستساعد هذه التحسينات فرق علوم البيانات في Axfood على بناء سير عمل تعلم الآلة بطريقة أكثر توحيدًا وستعمل على تبسيط تحليل النماذج ومراقبتها في الإنتاج بشكل كبير - مما يضمن جودة نماذج تعلم الآلة التي تم إنشاؤها وصيانتها بواسطة فرقنا.
يرجى ترك أي تعليقات أو أسئلة في قسم التعليقات.
حول المؤلف
 الدكتور بيورن بلومكفيست هو رئيس استراتيجية الذكاء الاصطناعي في Axfood AB. قبل انضمامه إلى Axfood AB، قاد فريقًا من علماء البيانات في Dagab، وهي جزء من Axfood، لبناء حلول مبتكرة للتعلم الآلي بهدف توفير طعام جيد ومستدام للناس في جميع أنحاء السويد. ولد ونشأ في شمال السويد، وفي أوقات فراغه يغامر بيورن بالذهاب إلى الجبال الثلجية والبحار المفتوحة.
الدكتور بيورن بلومكفيست هو رئيس استراتيجية الذكاء الاصطناعي في Axfood AB. قبل انضمامه إلى Axfood AB، قاد فريقًا من علماء البيانات في Dagab، وهي جزء من Axfood، لبناء حلول مبتكرة للتعلم الآلي بهدف توفير طعام جيد ومستدام للناس في جميع أنحاء السويد. ولد ونشأ في شمال السويد، وفي أوقات فراغه يغامر بيورن بالذهاب إلى الجبال الثلجية والبحار المفتوحة.
 أوسكار كلانج هو أحد كبار علماء البيانات في قسم التحليلات في داغاب، حيث يستمتع بالعمل في كل ما يتعلق بالتحليلات والتعلم الآلي، على سبيل المثال تحسين عمليات سلسلة التوريد، وبناء نماذج التنبؤ، ومؤخرًا، تطبيقات GenAI. وهو ملتزم ببناء خطوط أنابيب أكثر بساطة للتعلم الآلي، مما يعزز الكفاءة وقابلية التوسع.
أوسكار كلانج هو أحد كبار علماء البيانات في قسم التحليلات في داغاب، حيث يستمتع بالعمل في كل ما يتعلق بالتحليلات والتعلم الآلي، على سبيل المثال تحسين عمليات سلسلة التوريد، وبناء نماذج التنبؤ، ومؤخرًا، تطبيقات GenAI. وهو ملتزم ببناء خطوط أنابيب أكثر بساطة للتعلم الآلي، مما يعزز الكفاءة وقابلية التوسع.
 بافيل ماسلوف هو أحد كبار مهندسي DevOps وML في فريق المنصات التحليلية. يتمتع Pavel بخبرة واسعة في تطوير أطر العمل والبنية التحتية والأدوات في مجالات DevOps وML/AI على منصة AWS. لقد كان بافيل أحد اللاعبين الرئيسيين في بناء القدرة التأسيسية داخل تعلم الآلة في Axfood.
بافيل ماسلوف هو أحد كبار مهندسي DevOps وML في فريق المنصات التحليلية. يتمتع Pavel بخبرة واسعة في تطوير أطر العمل والبنية التحتية والأدوات في مجالات DevOps وML/AI على منصة AWS. لقد كان بافيل أحد اللاعبين الرئيسيين في بناء القدرة التأسيسية داخل تعلم الآلة في Axfood.
 يواكيم بيرج هو قائد الفريق ومنصات تحليل مالك المنتج، ومقره في ستوكهولم بالسويد. يقود فريقًا من مهندسي DevOps/MLOps نهاية Data Platform الذين يوفرون منصات البيانات وتعلم الآلة لفرق علوم البيانات. يتمتع يواكيم بسنوات عديدة من الخبرة في قيادة فرق التطوير والهندسة المعمارية من مختلف الصناعات.
يواكيم بيرج هو قائد الفريق ومنصات تحليل مالك المنتج، ومقره في ستوكهولم بالسويد. يقود فريقًا من مهندسي DevOps/MLOps نهاية Data Platform الذين يوفرون منصات البيانات وتعلم الآلة لفرق علوم البيانات. يتمتع يواكيم بسنوات عديدة من الخبرة في قيادة فرق التطوير والهندسة المعمارية من مختلف الصناعات.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/how-axfood-enables-accelerated-machine-learning-throughout-the-organization-using-amazon-sagemaker/

