Veriff هي شريك أساسي للتحقق من الهوية للمؤسسات المبتكرة التي تعتمد على النمو، بما في ذلك رواد الخدمات المالية والتكنولوجيا المالية والعملات المشفرة والألعاب والتنقل والأسواق عبر الإنترنت. إنها توفر تقنية متقدمة تجمع بين الأتمتة التي تعمل بالذكاء الاصطناعي والتعليقات البشرية والرؤى العميقة والخبرة.

توفر Veriff بنية أساسية مثبتة تمكن عملائها من الثقة في الهويات والسمات الشخصية لمستخدميها عبر جميع اللحظات ذات الصلة في رحلة العميل الخاصة بهم. تحظى Veriff بثقة العملاء مثل Bolt وDeel وMonese وStarship وSuper Awesome وTrustpilot وWise.
باعتبارها حلاً مدعومًا بالذكاء الاصطناعي، تحتاج Veriff إلى إنشاء وتشغيل العشرات من نماذج التعلم الآلي (ML) بطريقة فعالة من حيث التكلفة. تتراوح هذه النماذج من النماذج خفيفة الوزن المستندة إلى الأشجار إلى نماذج الرؤية الحاسوبية للتعلم العميق، والتي تحتاج إلى التشغيل على وحدات معالجة الرسومات لتحقيق زمن وصول منخفض وتحسين تجربة المستخدم. تقوم Veriff حاليًا أيضًا بإضافة المزيد من المنتجات إلى عروضها، مستهدفة حلاً شديد التخصيص لعملائها. إن تقديم نماذج مختلفة لعملاء مختلفين يزيد من الحاجة إلى حل عرض نموذجي قابل للتطوير.
في هذا المنشور، نوضح لك كيف قامت شركة Veriff بتوحيد سير عمل نشر النموذج الخاص بها باستخدام الأمازون SageMakerوخفض التكاليف ووقت التطوير.
تحديات البنية التحتية والتنمية
تعتمد بنية الواجهة الخلفية لـ Veriff على نمط الخدمات الصغيرة، مع تشغيل الخدمات على مجموعات Kubernetes المختلفة المستضافة على البنية التحتية لـ AWS. تم استخدام هذا النهج في البداية لجميع خدمات الشركة، بما في ذلك الخدمات الصغيرة التي تقوم بتشغيل نماذج ML للرؤية الحاسوبية باهظة الثمن.
تتطلب بعض هذه النماذج النشر على مثيلات GPU. وإدراكًا منه للتكلفة المرتفعة نسبيًا لأنواع المثيلات المدعومة بوحدة معالجة الرسومات، طور Veriff أ حل مخصص على Kubernetes لمشاركة موارد وحدة معالجة الرسومات (GPU) المحددة بين النسخ المتماثلة للخدمة المختلفة. عادةً ما تحتوي وحدة معالجة الرسومات الواحدة على ما يكفي من VRAM لاستيعاب العديد من نماذج رؤية الكمبيوتر الخاصة بشركة Veriff في الذاكرة.
على الرغم من أن الحل قد خفف من تكاليف وحدة معالجة الرسومات، إلا أنه جاء أيضًا مصحوبًا بالقيود التي احتاجها علماء البيانات للإشارة مسبقًا إلى مقدار ذاكرة وحدة معالجة الرسومات التي سيتطلبها نموذجهم. علاوة على ذلك، كانت DevOps مثقلة بتوفير مثيلات GPU يدويًا استجابةً لأنماط الطلب. وقد تسبب هذا في زيادة في النفقات التشغيلية وزيادة في توفير المثيلات، مما أدى إلى ملف تعريف تكلفة دون المستوى الأمثل.
بصرف النظر عن توفير وحدة معالجة الرسومات، يتطلب هذا الإعداد أيضًا من علماء البيانات إنشاء غلاف REST API لكل نموذج، والذي كان ضروريًا لتوفير واجهة عامة لخدمات الشركة الأخرى للاستهلاك، ولتغليف المعالجة المسبقة والمعالجة اللاحقة لبيانات النموذج. تتطلب واجهات برمجة التطبيقات هذه رمزًا خاصًا بدرجة الإنتاج، مما جعل من الصعب على علماء البيانات إنتاج النماذج.
بحث فريق منصة علوم البيانات في Veriff عن طرق بديلة لهذا النهج. كان الهدف الرئيسي هو دعم علماء البيانات في الشركة من خلال انتقال أفضل من البحث إلى الإنتاج من خلال توفير مسارات نشر أبسط. كان الهدف الثانوي هو تقليل التكاليف التشغيلية لتوفير مثيلات وحدة معالجة الرسومات.
حل نظرة عامة
يتطلب Veriff حلاً جديدًا يحل مشكلتين:
- السماح ببناء أغلفة REST API حول نماذج ML بسهولة
- السماح بإدارة سعة مثيل GPU المتوفرة على النحو الأمثل، وإذا أمكن، تلقائيًا
في النهاية، اتفق فريق منصة تعلم الآلة على قرار الاستخدام نقاط نهاية Sagemaker متعددة النماذج (إم إم إي). كان هذا القرار مدفوعًا بدعم MME لـ NVIDIA خادم الاستدلال تريتون (خادم يركز على التعلم الآلي يجعل من السهل تغليف النماذج كواجهات برمجة تطبيقات REST؛ كما كان Veriff يقوم بالفعل بتجربة استخدام Triton)، بالإضافة إلى قدرته على إدارة القياس التلقائي لمثيلات وحدة معالجة الرسومات (GPU) عبر سياسات القياس التلقائي البسيطة.
تم إنشاء اثنين من MMEs في Veriff، أحدهما للتدريج والآخر للإنتاج. يتيح لهم هذا الأسلوب تشغيل خطوات الاختبار في بيئة التدريج دون التأثير على نماذج الإنتاج.
SageMaker MMEs
SageMaker هي خدمة مُدارة بالكامل توفر للمطورين وعلماء البيانات القدرة على إنشاء نماذج تعلم الآلة وتدريبها ونشرها بسرعة. توفر SageMaker MMEs حلاً قابلاً للتطوير ومنخفض التكلفة لنشر عدد كبير من النماذج للاستدلال في الوقت الفعلي. تستخدم MME حاوية خدمة مشتركة ومجموعة من الموارد التي يمكنها استخدام مثيلات متسارعة مثل وحدات معالجة الرسومات لاستضافة جميع النماذج الخاصة بك. هذا يقلل من تكاليف الاستضافة عن طريق زيادة استخدام نقطة النهاية مقارنة باستخدام نقاط النهاية أحادية النموذج. كما أنه يقلل من عبء النشر لأن SageMaker يدير نماذج التحميل والتفريغ في الذاكرة وقياسها بناءً على أنماط حركة المرور الخاصة بنقطة النهاية. بالإضافة إلى ذلك ، تستفيد جميع نقاط نهاية الوقت الحقيقي لـ SageMaker من الإمكانات المضمنة لإدارة النماذج ومراقبتها ، مثل تضمين متغيرات الظل, التحجيم التلقائي، والتكامل المحلي مع الأمازون CloudWatch (لمزيد من المعلومات ، يرجى الرجوع إلى مقاييس CloudWatch لعمليات النشر متعددة النماذج نقطة النهاية).
نماذج فرقة تريتون المخصصة
كانت هناك عدة أسباب دفعت Veriff إلى استخدام Triton Inference Server، أهمها:
- يسمح لعلماء البيانات ببناء واجهات برمجة تطبيقات REST من النماذج عن طريق ترتيب ملفات العناصر النموذجية بتنسيق دليل قياسي (لا يوجد حل برمجي)
- إنه متوافق مع جميع أطر عمل الذكاء الاصطناعي الرئيسية (PyTorch وTensorflow وXGBoost والمزيد)
- وهو يوفر تحسينات منخفضة المستوى والخادم خاصة بـ ML مثل التجميع الديناميكي من الطلبات
يتيح استخدام Triton لعلماء البيانات نشر النماذج بسهولة لأنهم يحتاجون فقط إلى إنشاء مستودعات نماذج منسقة بدلاً من كتابة التعليمات البرمجية لإنشاء واجهات برمجة تطبيقات REST (يدعم Triton أيضًا نماذج بايثون إذا كان منطق الاستدلال المخصص مطلوبًا). يؤدي هذا إلى تقليل وقت نشر النموذج ويمنح علماء البيانات مزيدًا من الوقت للتركيز على بناء النماذج بدلاً من نشرها.
ميزة أخرى مهمة لـ Triton هي أنها تسمح لك بالبناء مجموعات نموذجية، وهي عبارة عن مجموعات من النماذج المرتبطة ببعضها البعض. يمكن تشغيل هذه المجموعات كما لو كانت نموذجًا واحدًا من طراز Triton. تستخدم Veriff حاليًا هذه الميزة لنشر منطق المعالجة المسبقة والمعالجة اللاحقة مع كل نموذج تعلم الآلة باستخدام نماذج Python (كما ذكرنا سابقًا)، مما يضمن عدم وجود عدم تطابق في بيانات الإدخال أو مخرجات النموذج عند استخدام النماذج في الإنتاج.
فيما يلي الشكل الذي يبدو عليه مستودع نموذج Triton النموذجي لعبء العمل هذا:
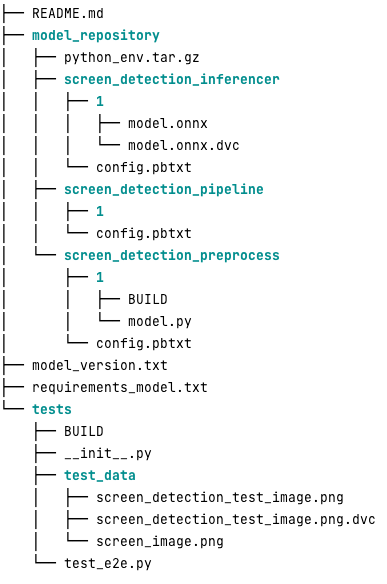
• model.py يحتوي الملف على رمز المعالجة المسبقة والمعالجة اللاحقة. الأوزان النموذجية المدربة موجودة في screen_detection_inferencer الدليل، ضمن الإصدار النموذجي 1 (النموذج بتنسيق ONNX في هذا المثال، ولكن يمكن أيضًا أن يكون بتنسيق TensorFlow أو PyTorch أو غير ذلك). تعريف نموذج المجموعة موجود في screen_detection_pipeline الدليل، حيث يتم تعيين المدخلات والمخرجات بين الخطوات في ملف التكوين.
تم تفصيل التبعيات الإضافية اللازمة لتشغيل نماذج Python في ملف requirements.txt ملف، ويجب أن يكون معبأًا لإنشاء بيئة Conda (python_env.tar.gz). لمزيد من المعلومات ، يرجى الرجوع إلى إدارة وقت تشغيل بايثون والمكتبات. أيضًا، يجب الإشارة إلى ملفات التكوين الخاصة بخطوات Python python_env.tar.gz يستخدم ال EXECUTION_ENV_PATH التوجيه.
يحتاج مجلد النموذج بعد ذلك إلى ضغط TAR وإعادة تسميته باستخدام model_version.txt. وأخيرا النتيجة <model_name>_<model_version>.tar.gz يتم نسخ الملف إلى خدمة تخزين أمازون البسيطة دلو (Amazon S3) متصل بـ MME، مما يسمح لـ SageMaker باكتشاف النموذج وخدمته.
إصدار النموذج والنشر المستمر
كما أوضح القسم السابق، فإن بناء مستودع نموذج Triton أمر بسيط ومباشر. ومع ذلك، فإن تنفيذ جميع الخطوات اللازمة لنشره أمر ممل ومعرض للأخطاء، إذا تم تشغيله يدويًا. للتغلب على ذلك، قامت Veriff ببناء monorepo يحتوي على جميع النماذج التي سيتم نشرها في MMEs، حيث يتعاون علماء البيانات في نهج يشبه Gitflow. يحتوي هذا monorepo على الميزات التالية:
- يتم إدارتها باستخدام بنطال.
- يتم تطبيق أدوات جودة التعليمات البرمجية مثل Black وMyPy باستخدام Pants.
- يتم تحديد اختبارات الوحدة لكل نموذج، والتي تتحقق من أن مخرجات النموذج هي المخرجات المتوقعة لمدخل نموذج معين.
- يتم تخزين أوزان النماذج بجانب مستودعات النماذج. يمكن أن تكون هذه الأوزان ملفات ثنائية كبيرة، لذا DVC يتم استخدامه لمزامنتها مع Git بطريقة محددة الإصدار.
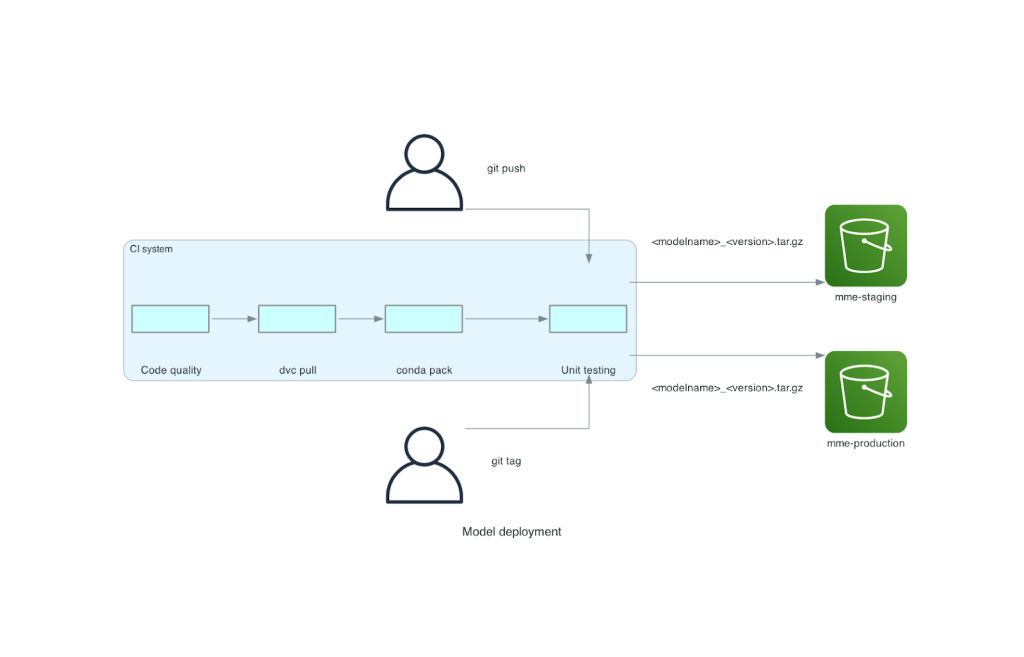
تم دمج هذا monorepo مع أداة التكامل المستمر (CI). لكل دفعة جديدة إلى الريبو أو النموذج الجديد، يتم تشغيل الخطوات التالية:
- اجتياز فحص جودة الكود.
- تحميل الأوزان النموذجية.
- بناء بيئة كوندا.
- قم بتدوير خادم Triton باستخدام بيئة Conda واستخدمه لمعالجة الطلبات المحددة في اختبارات الوحدة.
- إنشاء ملف TAR للنموذج النهائي (
<model_name>_<model_version>.tar.gz).
تتأكد هذه الخطوات من أن النماذج تتمتع بالجودة المطلوبة للنشر، لذلك لكل دفعة إلى فرع الريبو، يتم نسخ ملف TAR الناتج (في خطوة CI أخرى) إلى حاوية S3 المرحلية. عند إجراء الدفعات في الفرع الرئيسي، يتم نسخ ملف النموذج إلى حاوية الإنتاج S3. الرسم البياني التالي يصور نظام CI/CD هذا.
فوائد التكلفة وسرعة النشر
يسمح استخدام MMEs لـ Veriff باستخدام نهج monorepo لنشر النماذج في الإنتاج. باختصار، يتكون سير عمل نشر النموذج الجديد لـ Veriff من الخطوات التالية:
- قم بإنشاء فرع في monorepo بالنموذج الجديد أو إصدار النموذج.
- تحديد وتشغيل اختبارات الوحدة في جهاز التطوير.
- ادفع الفرع عندما يكون النموذج جاهزًا للاختبار في بيئة التدريج.
- قم بدمج الفرع في القسم الرئيسي عندما يصبح النموذج جاهزًا للاستخدام في الإنتاج.
مع وجود هذا الحل الجديد، يعد نشر النموذج في Veriff جزءًا مباشرًا من عملية التطوير. انخفض وقت تطوير النموذج الجديد من 10 أيام إلى يومين في المتوسط.
جلبت ميزات توفير البنية التحتية المُدارة والقياس التلقائي لـ SageMaker فوائد إضافية لـ Veriff. استخدموا الدعاء في الحال مقياس CloudWatch قابل للتوسيع وفقًا لأنماط حركة المرور، مما يوفر التكاليف دون التضحية بالموثوقية. لتحديد قيمة الحد للمقياس، أجروا اختبار الحمل على نقطة النهاية المرحلية للعثور على أفضل مقايضة بين زمن الوصول والتكلفة.
بعد نشر سبعة نماذج إنتاج إلى MMEs وتحليل الإنفاق، أبلغت شركة Veriff عن انخفاض في التكلفة بنسبة 75% في نموذج وحدة معالجة الرسوميات (GPU) الذي يخدم مقارنة بالحل الأصلي المستند إلى Kubernetes. كما تم تخفيض تكاليف التشغيل أيضًا، نظرًا لرفع عبء توفير المثيلات يدويًا عن مهندسي DevOps في الشركة.
وفي الختام
في هذا المنشور، قمنا بمراجعة سبب اختيار Veriff لـ Sagemaker MMEs بدلاً من نشر النماذج المُدارة ذاتيًا على Kubernetes. تتولى SageMaker العبء الثقيل غير المتمايز، مما يسمح لشركة Veriff بتقليل وقت تطوير النموذج، وزيادة الكفاءة الهندسية، وخفض تكلفة الاستدلال في الوقت الفعلي بشكل كبير مع الحفاظ على الأداء المطلوب لعملياتها الحيوية للأعمال. أخيرًا، عرضنا نموذج Veriff البسيط والفعال لنشر نماذج CI/CD وآلية إصدار النماذج، والتي يمكن استخدامها كتنفيذ مرجعي للجمع بين أفضل ممارسات تطوير البرامج وSageMaker MMEs. يمكنك العثور على نماذج التعليمات البرمجية لاستضافة نماذج متعددة باستخدام SageMaker MMEs GitHub جيثب:.
حول المؤلف
 ريكارد بوراس هو أحد كبار موظفي التعلم الآلي في Veriff، حيث يقود جهود MLOps في الشركة. إنه يساعد علماء البيانات على بناء منتجات AI / ML أسرع وأفضل من خلال بناء منصة علوم البيانات في الشركة، والجمع بين العديد من الحلول مفتوحة المصدر مع خدمات AWS.
ريكارد بوراس هو أحد كبار موظفي التعلم الآلي في Veriff، حيث يقود جهود MLOps في الشركة. إنه يساعد علماء البيانات على بناء منتجات AI / ML أسرع وأفضل من خلال بناء منصة علوم البيانات في الشركة، والجمع بين العديد من الحلول مفتوحة المصدر مع خدمات AWS.
 جواو مورا هو مهندس حلول متخصص في الذكاء الاصطناعي/تعلم الآلة في AWS، ومقره في إسبانيا. إنه يساعد العملاء في نموذج التعلم العميق للتدريب على نطاق واسع وتحسين الاستدلال، وبناء منصات تعلم الآلة واسعة النطاق على AWS على نطاق أوسع.
جواو مورا هو مهندس حلول متخصص في الذكاء الاصطناعي/تعلم الآلة في AWS، ومقره في إسبانيا. إنه يساعد العملاء في نموذج التعلم العميق للتدريب على نطاق واسع وتحسين الاستدلال، وبناء منصات تعلم الآلة واسعة النطاق على AWS على نطاق أوسع.
 ميغيل فيريرا يعمل كمهندس أول للحلول في AWS ومقرها في هلسنكي، فنلندا. لقد كان الذكاء الاصطناعي/تعلم الآلة محل اهتمام مدى الحياة وقد ساعد العديد من العملاء على دمج Amazon SageMaker في سير عمل تعلم الآلة الخاص بهم.
ميغيل فيريرا يعمل كمهندس أول للحلول في AWS ومقرها في هلسنكي، فنلندا. لقد كان الذكاء الاصطناعي/تعلم الآلة محل اهتمام مدى الحياة وقد ساعد العديد من العملاء على دمج Amazon SageMaker في سير عمل تعلم الآلة الخاص بهم.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/how-veriff-decreased-deployment-time-by-80-using-amazon-sagemaker-multi-model-endpoints/

