المُقدّمة
في مجال الذكاء الاصطناعي، أحدثت نماذج اللغات الكبيرة (LLMs) ونماذج الذكاء الاصطناعي التوليدي مثل OpenAI's GPT-4، وAnthropic's Claude 2، وMeta's Llama، وFalcon، وGoogle’s Palm، وما إلى ذلك، ثورة في الطريقة التي نحل بها المشكلات. يستخدم LLMs تقنيات التعلم العميق لأداء مهام معالجة اللغة الطبيعية. ستعلمك هذه المقالة كيفية إنشاء تطبيقات LLM باستخدام قاعدة بيانات متجهة. ربما تكون قد تفاعلت مع برنامج chatbot مثل خدمة عملاء Amazon أو Flipkart Decision Assistant. إنها تولد نصًا يشبه الإنسان وتوفر تجربة مستخدم تفاعلية لا يمكن تمييزها تقريبًا عن المحادثات الواقعية. ومع ذلك، تحتاج دورات LLM هذه إلى التحسين حتى تنتج نتائج محددة وذات صلة للغاية لتكون مفيدة حقًا لحالات استخدام محددة.

على سبيل المثال، إذا سألت "كيف يمكنني تغيير لغتي في تطبيق Android؟" إلى تطبيق خدمة عملاء أمازون، ربما لم يتم تدريبه على هذا النص الدقيق وبالتالي قد لا يتمكن من الإجابة. هذا هو المكان الذي تأتي فيه قاعدة بيانات المتجهات للإنقاذ. تقوم قاعدة بيانات المتجهات بتخزين نصوص المجال (في هذه الحالة، مستندات المساعدة) والاستعلامات السابقة من قبل جميع المستخدمين، بما في ذلك سجل الطلبات، وما إلى ذلك، كتضمينات رقمية وتوفر بحثًا عن المتجهات المماثلة في الوقت الفعلي. في هذه الحالة، يقوم بتشفير هذا الاستعلام إلى متجه رقمي ويستخدمه لإجراء بحث تشابه في قاعدة بيانات المتجهات الخاصة به والعثور على أقرب جيرانه. ومن خلال هذه المساعدة، يمكن لبرنامج الدردشة الآلي توجيه المستخدم بشكل صحيح إلى قسم "تغيير تفضيلات اللغة" في تطبيق أمازون.
أهداف التعلم
- كيف تعمل LLMs، وما هي حدودها، ولماذا يحتاجون إلى قواعد بيانات متجهة؟
- مقدمة عن نماذج التضمين وكيفية تشفيرها واستخدامها في التطبيقات.
- تعرف على ما هي قاعدة بيانات المتجهات وكيف أنها جزء من بنية تطبيقات LLM.
- تعرف على كيفية ترميز تطبيقات LLM/Generative AI باستخدام قواعد البيانات المتجهة وtensorflow.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
ما هي ماجستير؟
نماذج اللغات الكبيرة (LLMs) هي نماذج أساسية للتعلم الآلي تستخدم خوارزميات التعلم العميق لمعالجة وفهم اللغة الطبيعية. يتم تدريب هذه النماذج على كميات هائلة من البيانات النصية لتعلم الأنماط وعلاقات الكيانات في اللغة. يمكن أن تقوم LLMs بأداء العديد من أنواع المهام اللغوية ، مثل ترجمة اللغات وتحليل المشاعر ومحادثات chatbot والمزيد. يمكنهم فهم البيانات النصية المعقدة ، وتحديد الكيانات والعلاقات فيما بينها ، وإنشاء نص جديد متماسك ودقيق نحويًا.
اقرأ المزيد عن LLMs هنا.
كيف تعمل LLMs؟
يتم تدريب LLMs باستخدام كمية كبيرة من البيانات، غالبًا ما تكون تيرابايت، وحتى بيتابايت، مع مليارات أو تريليونات من المعلمات، مما يمكنهم من التنبؤ وإنشاء الاستجابات ذات الصلة بناءً على مطالبات المستخدم أو استفساراته. يقومون بمعالجة بيانات الإدخال من خلال تضمين الكلمات وطبقات الاهتمام الذاتي وشبكات التغذية الأمامية لإنشاء نص ذي معنى. يمكنك قراءة المزيد عن معماريات LLM هنا.
حدود LLMs
في حين يبدو أن LLMs تولد استجابات بدقة عالية جدًا، حتى أفضل من البشر في كثير موحدة اختبارات، لا تزال هذه النماذج لها قيود. أولاً، يعتمدون فقط على بيانات التدريب الخاصة بهم لبناء تفكيرهم وبالتالي قد يفتقرون إلى معلومات محددة أو حالية في البيانات. يؤدي هذا إلى قيام النموذج بإنشاء استجابات غير صحيحة أو غير عادية، والمعروفة أيضًا باسم "الهلوسة". لقد كان هناك مستمرة جهد للتخفيف من هذا. ثانيًا، قد لا يتصرف النموذج أو يستجيب بطريقة تتوافق مع توقعات المستخدم.
ولمعالجة هذا الأمر، تعمل قواعد البيانات المتجهة ونماذج التضمين على تعزيز معرفة LLMs/الذكاء الاصطناعي التوليدي من خلال توفير عمليات بحث إضافية لطرائق مماثلة (نص، صورة، فيديو، وما إلى ذلك) التي يبحث المستخدم عن معلومات عنها. فيما يلي مثال حيث لا تمتلك LLMs الاستجابة التي يطلبها المستخدم وبدلاً من ذلك تعتمد على قاعدة بيانات متجهة للعثور على تلك المعلومات.

LLMs وقواعد بيانات المتجهات
يتم استخدام نماذج اللغات الكبيرة (LLMs) أو دمجها في العديد من أجزاء الصناعة، مثل التجارة الإلكترونية، والسفر، والبحث، وإنشاء المحتوى، والتمويل. تعتمد هذه النماذج على نوع أحدث نسبيًا من قواعد البيانات، يُعرف باسم قاعدة البيانات المتجهة، والتي تخزن تمثيلًا رقميًا للنصوص والصور ومقاطع الفيديو والبيانات الأخرى في تمثيل ثنائي يسمى التضمينات. يسلط هذا القسم الضوء على أساسيات قواعد بيانات المتجهات والتضمينات، والأهم من ذلك، يركز على كيفية استخدامها للتكامل مع تطبيقات LLM.
قاعدة البيانات المتجهة هي قاعدة بيانات تقوم بتخزين التضمينات والبحث عنها باستخدام مساحة عالية الأبعاد. هذه المتجهات عبارة عن تمثيلات رقمية لميزات أو سمات البيانات. باستخدام الخوارزميات التي تحسب المسافة أو التشابه بين المتجهات في مساحة عالية الأبعاد، يمكن لقواعد بيانات المتجهات استرداد البيانات المماثلة بسرعة وكفاءة. على عكس قواعد البيانات التقليدية القائمة على العددية والتي تخزن البيانات في صفوف أو أعمدة وتستخدم المطابقة التامة أو طرق البحث القائمة على الكلمات الرئيسية، تعمل قواعد البيانات المتجهة بشكل مختلف. يستخدمون قواعد بيانات المتجهات للبحث ومقارنة مجموعة كبيرة من المتجهات في فترة زمنية قصيرة جدًا (ترتيب المللي ثانية) باستخدام تقنيات مثل أقرب الجيران التقريبي (ANN).
برنامج تعليمي سريع حول التضمين
تقوم نماذج الذكاء الاصطناعي بإنشاء عمليات التضمين عن طريق إدخال البيانات الأولية مثل النص والفيديو والصور إلى مكتبة تضمين المتجهات مثل word2vec وفي سياق الذكاء الاصطناعي والتعلم الآلي، تمثل هذه الميزات أبعادًا مختلفة للبيانات التي تعتبر ضرورية لفهم علاقات الأنماط والهياكل الأساسية.
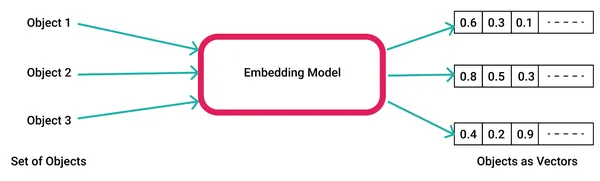
فيما يلي مثال لكيفية إنشاء تضمينات الكلمات باستخدام word2vec.
1. قم بإنشاء النموذج باستخدام مجموعة البيانات المخصصة لديك أو استخدم نموذجًا تم إنشاؤه مسبقًا من شراء مراجعات جوجل أو نص سريع. إذا قمت بإنشاء ملف خاص بك، فيمكنك حفظه في نظام الملفات الخاص بك كملف "word2vec.model".
import gensim # Create a word2vec model
model = gensim.models.Word2Vec(corpus) # Save the model file
model.save('word2vec.model')2. قم بتحميل النموذج، وقم بإنشاء تضمين متجه لكلمة إدخال، واستخدمه للحصول على كلمات مماثلة في مساحة تضمين المتجهات.
import gensim
import numpy as np # Load the word2vec model
model = gensim.models.Word2Vec.load('word2vec.model') # Get the vector for the word "king"
king_vector = model['king'] # Get the most similar vectors to the king vector
similar_vectors = model.similar_by_vector(king_vector, topn=5) # Print the most similar vectors
for vector in similar_vectors: print(vector[0], vector[1]) 3. فيما يلي أهم 5 كلمات قريبة من الكلمة المدخلة.
Output: man 0.85
prince 0.78
queen 0.75
lord 0.74
emperor 0.72هندسة التطبيقات LLM باستخدام قواعد البيانات المتجهة
على مستوى عالٍ، تعتمد قواعد بيانات المتجهات على نماذج التضمين للتعامل مع كل من إنشاء عمليات التضمين والاستعلام عنها. في مسار العرض، يتم تشفير محتوى المجموعة في متجهات باستخدام نموذج التضمين وتخزينه في قواعد بيانات المتجهات مثل Pinecone وChromaDB وWeaviate وما إلى ذلك. وفي مسار القراءة، يقوم التطبيق بإجراء استعلام باستخدام الجمل أو الكلمات، ويتم ترميزه مرة أخرى بواسطة نموذج التضمين في ناقل يتم بعد ذلك الاستعلام عنه في قاعدة بيانات المتجه لجلب النتائج.
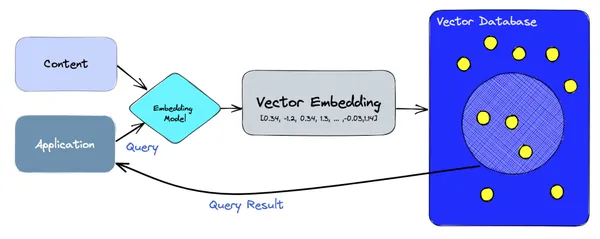
تطبيقات LLM باستخدام قواعد بيانات المتجهات
يساعد LLM في المهام اللغوية وهو مضمن في فئة أوسع من النماذج، مثل الذكاء الاصطناعي التوليدي يمكنه إنشاء صور ومقاطع فيديو بصرف النظر عن النص فقط. في هذا القسم، سوف نتعلم كيفية بناء تطبيقات LLM/الذكاء الاصطناعي التوليدي العملية باستخدام قواعد البيانات المتجهة. لقد استخدمت المحولات و libs الشعلة لنماذج اللغة و كوز الصنوبر كقاعدة بيانات المتجهات. يمكنك اختيار أي نموذج لغة لـ LLM/التضمينات وأي قاعدة بيانات متجهة للتخزين والبحث.
تطبيق Chatbot
لإنشاء روبوت محادثة باستخدام قاعدة بيانات متجهة، يمكنك اتباع الخطوات التالية:
- اختر قاعدة بيانات متجهة مثل Pinecone وChroma وWeaviate وAWS Kendra وما إلى ذلك.
- قم بإنشاء فهرس متجه لروبوت الدردشة الخاص بك.
- تدريب نموذج لغة باستخدام مجموعة نصية كبيرة من اختيارك. على سبيل المثال، بالنسبة لبرنامج الدردشة الإخبارية، يمكنك تغذية بيانات الأخبار.
- دمج قاعدة بيانات المتجهات ونموذج اللغة.
فيما يلي مثال بسيط لتطبيق chatbot يستخدم قاعدة بيانات متجهة ونموذج لغة:
import pinecone
import transformers # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the language model
model = transformers.AutoModelForCausalLM.from_pretrained("google/bigbird-roberta-base") # Define a function to generate text
def generate_text(prompt): inputs = model.prepare_inputs_for_generation(prompt, return_tensors="pt") outputs = model.generate(inputs, max_length=100) return outputs[0].decode("utf-8") # Define a function to retrieve the most similar vectors to the user's query vector
def retrieve_similar_vectors(query_vector): results = client.search("my_index", query_vector) return results # Define a function to generate a response to the user's query
def generate_response(query): # Retrieve the most similar vectors to the user's query vector similar_vectors = retrieve_similar_vectors(query) # Generate text based on the retrieved vectors response = generate_text(similar_vectors[0]) return response # Start the chatbot
while True: # Get the user's query query = input("What is your question? ") # Generate a response to the user's query response = generate_response(query) # Print the response print(response)سيقوم تطبيق chatbot هذا باسترداد المتجهات الأكثر تشابهًا مع متجه استعلام المستخدم من قاعدة بيانات المتجهات ثم إنشاء نص باستخدام نموذج اللغة استنادًا إلى المتجهات المستردة.
ChatBot > What is your question?
User_A> How tall is the Eiffel Tower?
ChatBot>The height of the Eiffel Tower measures 324 meters (1,063 feet) from its base to the top of its antenna. تطبيق مولد الصور
دعنا نستكشف كيفية إنشاء تطبيق Image Generator الذي يستخدم كليهما الذكاء الاصطناعي التوليدي ومكتبات LLM.
- قم بإنشاء قاعدة بيانات متجهة لتخزين متجهات الصور الخاصة بك.
- استخراج ناقلات الصور من بيانات التدريب الخاصة بك.
- أدخل متجهات الصورة في قاعدة بيانات المتجهات.
- تدريب شبكة الخصومة التوليدية (GAN). يقرأ هنا إذا كنت بحاجة إلى مقدمة لـ GAN.
- دمج قاعدة بيانات المتجهات وGAN.
فيما يلي مثال بسيط لبرنامج يدمج قاعدة بيانات متجهة وشبكة GAN لإنشاء الصور:
import pinecone
import torch
from torchvision import transforms # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the GAN
generator = torch.load("generator.pt") # Define a function to generate an image from a vector
def generate_image(vector): # Convert the vector to a tensor tensor = torch.from_numpy(vector).float() # Generate the image image = generator(tensor) # Transform the image to a PIL image image = transforms.ToPILImage()(image) return image # Start the image generator
while True: # Get the user's query query = input("What kind of image would you like to generate? ") # Retrieve the most similar vector to the user's query vector similar_vectors = client.search("my_index", query) # Generate an image from the retrieved vector image = generate_image(similar_vectors[0]) # Display the image image.show()سيقوم هذا البرنامج باسترداد المتجه الأكثر تشابهًا مع متجه استعلام المستخدم من قاعدة بيانات المتجهات ثم إنشاء صورة باستخدام GAN استنادًا إلى المتجه المسترد.
ImageBot>What kind of image would you like to generate?
Me>An idyllic image of a mountain with a flowing river.
ImageBot> Wait a minute! Here you go...
يمكنك تخصيص هذا البرنامج لتلبية احتياجاتك الخاصة. على سبيل المثال، يمكنك تدريب GAN المتخصصة في إنشاء نوع معين من الصور، مثل الصور الشخصية أو المناظر الطبيعية.
تطبيق توصيات الأفلام
دعنا نستكشف كيفية إنشاء تطبيق لتوصية الأفلام من مجموعة أفلام. يمكنك استخدام فكرة مشابهة لبناء نظام توصية للمنتجات أو الكيانات الأخرى.
- قم بإنشاء قاعدة بيانات متجهة لتخزين متجهات الفيلم الخاصة بك.
- استخراج ناقلات الفيلم من البيانات الوصفية للفيلم الخاص بك.
- أدخل متجهات الفيلم في قاعدة بيانات المتجهات.
- يوصي الأفلام للمستخدمين.
فيما يلي مثال لكيفية استخدام Pinecone API للتوصية بالأفلام للمستخدمين:
import pinecone # Create an API client
client = pinecone.Client(api_key="YOUR_API_KEY") # Get the user's vector
user_vector = client.get_vector("user_index", user_id) # Recommend movies to the user
results = client.search("movie_index", user_vector) # Print the results
for result in results: print(result["title"])فيما يلي عينة توصية للمستخدم
The Shawshank Redemption
The Dark Knight
Inception
The Godfather
Pulp Fictionحالات الاستخدام الواقعي لـ LLMs باستخدام بحث المتجهات/قاعدة البيانات
- تستخدم Microsoft وTikTok قواعد بيانات متجهة مثل Pinecone للذاكرة طويلة المدى وعمليات البحث الأسرع. هذا شيء لا يمكن لـ LLM القيام به بمفرده بدون قاعدة بيانات متجهة. إنها تساعد المستخدمين على حفظ أسئلتهم/إجاباتهم السابقة واستئناف جلستهم. على سبيل المثال، يمكن للمستخدمين أن يسألوا: "أخبرني المزيد عن وصفة المعكرونة التي ناقشناها الأسبوع الماضي". يقرأ هنا.

- يوصي مساعد اتخاذ القرار في Flipkart بالمنتجات للمستخدمين من خلال تشفير الاستعلام أولاً على أنه تضمين متجه وإجراء بحث مقابل المتجهات التي تخزن المنتجات ذات الصلة في مساحة عالية الأبعاد. على سبيل المثال، إذا كنت تبحث عن "سترة Wrangler الجلدية ذات اللون البني للرجال المتوسطة"، فإنها توصي المستخدم بالمنتجات ذات الصلة باستخدام بحث تشابه المتجهات. بخلاف ذلك، لن يكون لدى LLM أي توصيات، حيث لن يحتوي أي كتالوج منتج على مثل هذه العناوين أو تفاصيل المنتج. يمكنك قراءتها هنا.
- تستخدم شركة Chipper Cash، وهي شركة للتكنولوجيا المالية في أفريقيا، قاعدة بيانات متجهة لتقليل عمليات تسجيل المستخدمين الاحتياليين بمقدار 10 أضعاف. يقوم بذلك عن طريق تخزين جميع صور اشتراكات المستخدم السابقة كتضمينات متجهة. وبعد ذلك، عندما يقوم مستخدم جديد بالتسجيل، فإنه يقوم بتشفيره كمتجه ومقارنته بالمستخدمين الحاليين للكشف عن الاحتيال. يمكنك قراءتها هنا.

- يستخدم Facebook مكتبة البحث المتجهة الخاصة به والتي تسمى فايس ( مدونة) في العديد من المنتجات داخليًا، بما في ذلك Instagram Reels وFacebook Stories، لإجراء بحث سريع عن أي وسائط متعددة والعثور على مرشحين مشابهين لعرض اقتراحات أفضل للمستخدم.
وفي الختام
تعد قواعد بيانات المتجهات مفيدة لإنشاء تطبيقات LLM متنوعة، مثل إنشاء الصور وتوصيات الأفلام أو المنتجات وروبوتات الدردشة. إنهم يزودون LLMs بمعلومات إضافية أو مشابهة لم يتم تدريب LLMs عليها. يقومون بتخزين عمليات تضمين المتجهات بكفاءة في مساحة عالية الأبعاد ويستخدمون بحث أقرب الجيران للعثور على عمليات تضمين مماثلة بدقة عالية.
الوجبات السريعة الرئيسية
تتمثل النقاط الرئيسية المستفادة من هذه المقالة في أن قواعد البيانات المتجهة مناسبة جدًا لتطبيقات LLM وتوفر الميزات المهمة التالية للمستخدمين للتكامل معها:
- الأداء: تم تصميم قواعد بيانات المتجهات خصيصًا لتخزين واسترجاع بيانات المتجهات بكفاءة، وهو أمر مهم لتطوير تطبيقات LLM عالية الأداء.
- دقة: يمكن لقواعد بيانات المتجهات أن تتطابق بدقة مع المتجهات المتشابهة، حتى لو كانت تظهر اختلافات طفيفة. يستخدمون خوارزميات الجوار الأقرب لحساب المتجهات المماثلة.
- متعدد الوسائط: يمكن أن تستوعب قواعد بيانات المتجهات العديد من البيانات متعددة الوسائط، بما في ذلك النصوص والصور والصوت. هذا التنوع يجعلها خيارًا مثاليًا لتطبيقات LLM/Generative AI التي تتطلب العمل مع أنواع بيانات متنوعة.
- صديقة للمطور: تعتبر قواعد بيانات المتجهات سهلة الاستخدام نسبيًا، حتى بالنسبة للمطورين الذين قد لا يمتلكون معرفة واسعة بتقنيات التعلم الآلي.
بالإضافة إلى ذلك، أود تسليط الضوء على أن العديد من حلول SQL/NoSQL الحالية تضيف بالفعل تخزينًا مضمنًا للتضمين المتجه، وفهرسة، وميزات بحث أسرع للتشابه، على سبيل المثال، كيو و رديس. هذا المجال سريع التطور، لذلك سيكون لدى مطوري التطبيقات العديد من الخيارات المتاحة في المستقبل القريب لإنشاء تطبيقات مبتكرة.
الأسئلة المتكررة
ج. نماذج اللغة الكبيرة أو LLMs هي برامج ذكاء اصطناعي متقدمة (AI) تم تدريبها على مجموعة كبيرة من البيانات النصية باستخدام الشبكات العصبية لتقليد الاستجابات الشبيهة بالإنسان مع السياق. يمكنهم التنبؤ والإجابة وإنشاء البيانات النصية في المجال الذي تم تدريبهم عليه.
أ. التضمينات عبارة عن تمثيلات رقمية للنص أو الصور أو الفيديو أو تنسيقات البيانات الأخرى. إنها تجعل تحديد الموقع وإيجاد كائنات متشابهة لغويًا أسهل في مساحة عالية الأبعاد.
أ. تقوم قاعدة البيانات بتخزين عمليات تضمين المتجهات عالية الأبعاد والاستعلام عنها للعثور على متجهات مماثلة باستخدام خوارزميات الجوار الأقرب مثل التجزئة الحساسة للمكان. يحتاج LLMs/Generative AI إليهم لمساعدتهم في توفير عمليات بحث إضافية عن ناقلات مماثلة بدلاً من ضبط LLM أنفسهم.
A. قواعد البيانات المتجهة هي قواعد بيانات متخصصة تساعد في فهرسة عمليات تضمين المتجهات والبحث فيها. تحظى بشعبية كبيرة في مجتمع المصادر المفتوحة، ويتم دمج العديد من المؤسسات/التطبيقات معها. ومع ذلك، فإن العديد من قواعد بيانات SQL/NoSQL الحالية تضيف إمكانات مماثلة بحيث يكون لدى مجتمع المطورين العديد من الخيارات في المستقبل القريب.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/10/how-to-build-llm-apps-using-vector-database/

