المُقدّمة
البيانات هي الوقود لصناعة تكنولوجيا المعلومات و مشروع علم البيانات في عالم الإنترنت اليوم. تعتمد صناعات تكنولوجيا المعلومات بشكل كبير على الرؤى في الوقت الفعلي المستمدة من تدفق البيانات مصادر. يعد التعامل مع بيانات التدفق ومعالجتها هو العمل الأصعب تحليل البيانات. نحن نعلم أن البيانات المتدفقة هي البيانات المنبعثة بكميات كبيرة في معالجة مستمرة مما يعني أن البيانات تتغير كل ثانية. للتعامل مع هذه البيانات التي نستخدمها منصة ملتوية - توزيع ذاتي الإدارة على مستوى المؤسسة اباتشي كافكا.
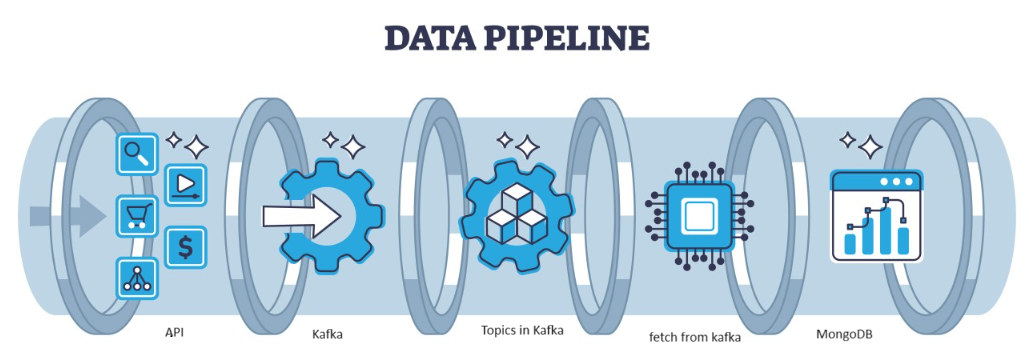
كافكا هو خطأ موزع يمكن معالجته بواسطة الهندسة المعمارية، وهو بمثابة خيار شائع لإدارة تدفقات البيانات عالية الإنتاجية. يتم جمع البيانات من كافكا في ملف MongoDB على شكل مجموعات. في هذه المقالة، سنقوم بإنشاء خط أنابيب شامل يتم من خلاله جلب البيانات بمساعدة واجهة برمجة التطبيقات (API) في خط الأنابيب ثم يتم جمعها في كافكا على شكل موضوعات ثم تخزينها في MongoDB ومن هناك يمكننا استخدامها في المشروع أو القيام بهندسة الميزات.
أهداف التعلم
- تعرف على ما هو دفق البيانات وكيفية التعامل مع دفق البيانات بمساعدة كافكا.
- فهم منصة Confluent – توزيعة تتم إدارتها ذاتيًا على مستوى المؤسسات لـ Apache Kafka.
- قم بتخزين البيانات التي جمعها كافكا في MongoDB وهي قاعدة بيانات NoSQL تقوم بتخزين البيانات غير المنظمة.
- قم بإنشاء خط أنابيب كامل من طرف إلى طرف لجلب البيانات وتخزينها في قاعدة البيانات.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
حدد المشكلة
للتعامل مع البيانات المتدفقة القادمة من المستشعر، يتم إنتاج المركبات التي تحتوي على بيانات المستشعر في الثانية، ومن الصعب التعامل مع البيانات ومعالجتها مسبقًا لاستخدامها في مشروع علوم البيانات. لذا، لمعالجة هذه المشكلة، نقوم بإنشاء خط أنابيب من طرف إلى طرف والذي يتعامل مع البيانات ويخزنها.
ما هو تدفق البيانات؟
تدفق البيانات هي البيانات التي يتم إنشاؤها بشكل مستمر من مصادر مختلفة وهي بيانات غير منظمة. يشير إلى التدفق المستمر للبيانات الناتجة من مصادر مختلفة في الوقت الفعلي أو في الوقت الفعلي تقريبًا. في المعالجة المجمعة التقليدية حيث يتم جمع البيانات وتتم معالجة بيانات التدفق هذه عند إنشائها. يمكن أن تكون البيانات المتدفقة عبارة عن بيانات IOT مثل أجهزة استشعار درجة الحرارة وأجهزة تتبع نظام تحديد المواقع العالمي (GPS)، أو بيانات الآلة مثل البيانات التي يتم إنشاؤها بواسطة الآلات والمعدات الصناعية مثل بيانات القياس عن بعد من المركبات وآلات التصنيع. هناك منصات لمعالجة البيانات المتدفقة مثل Apache-Kafka.
ما هو كافكا؟
Apache Kafka عبارة عن منصة تُستخدم لبناء خطوط أنابيب البيانات وتطبيقات البث في الوقت الفعلي. تعد Kafka Streams API مكتبة قوية تسمح بالمعالجة السريعة، مما يتيح لك جمع وإنشاء معلمات النوافذ، وتنفيذ عمليات ربط البيانات داخل التدفق، والمزيد. يتكون Apache Kafka من طبقة تخزين وطبقة حسابية تجمع بين استيعاب البيانات بكفاءة في الوقت الفعلي وتدفق خطوط أنابيب البيانات والتخزين عبر الأنظمة.
ماذا سيكون النهج؟
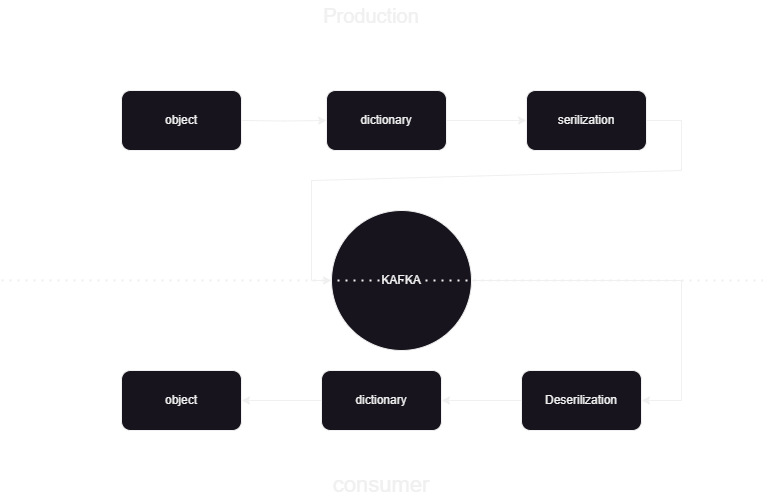
هذا عبارة عن خط أنابيب للتعلم الآلي لمساعدتنا في معرفة كيفية نشر ومعالجة البيانات من وإلى كافكا المتموجة بتنسيق JSON. هناك جزأين من المستهلك والمنتج لمعالجة بيانات كافكا. لتخزين البيانات المتدفقة من المنتجين المختلفين وتخزينها في أماكن متموجة ومن ثم يتم إلغاء تسلسل البيانات ويتم تخزين تلك البيانات في قاعدة البيانات.
نظرة عامة على بنية النظام
نقوم بمعالجة البيانات المتدفقة بمساعدة كافكا المتموجة وينقسم كافكا إلى قسمين من جزأين:
- منتج كافكا: منتج كافكا مسؤول عن إنتاج وإرسال البيانات إلى موضوعات كافكا.
- مستهلك كافكا: مستهلك كافكا هو قراءة ومعالجة البيانات من موضوعات كافكا.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
ما هي المكونات؟
- المواضيع: المواضيع هي قنوات أو فئات منطقية ينشرها المنتجون. يتم تقسيم كل موضوع إلى قسم واحد أو أكثر، ويتم نسخ كل موضوع عبر وسطاء متعددين للتسامح مع الخطأ. ينشر المنتجون بيانات حول مواضيع محددة، ويشترك المستهلكون في المواضيع لاستخدام البيانات.
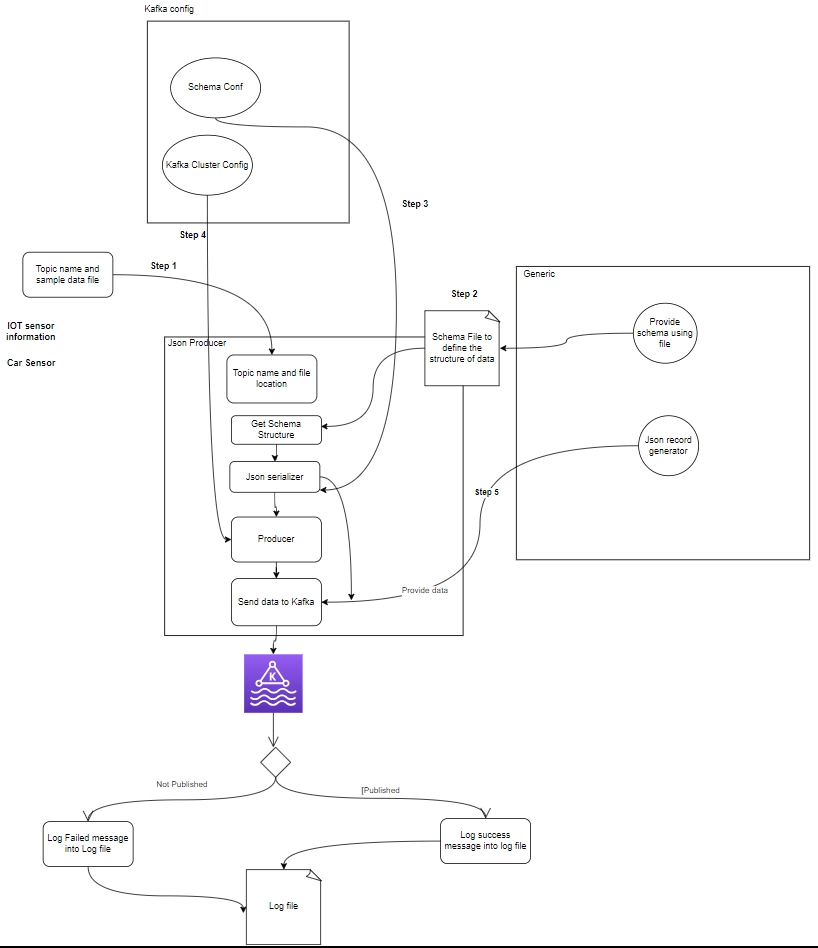
- المنتجين: منتج Apache Kafka هو تطبيق عميل ينشر (يكتب) الأحداث إلى مجموعة Kafka. تُعرف التطبيقات التي ترسل البيانات إلى المواضيع باسم منتجي كافكا. يقدم هذا القسم لمحة عامة عن منتج كافكا.
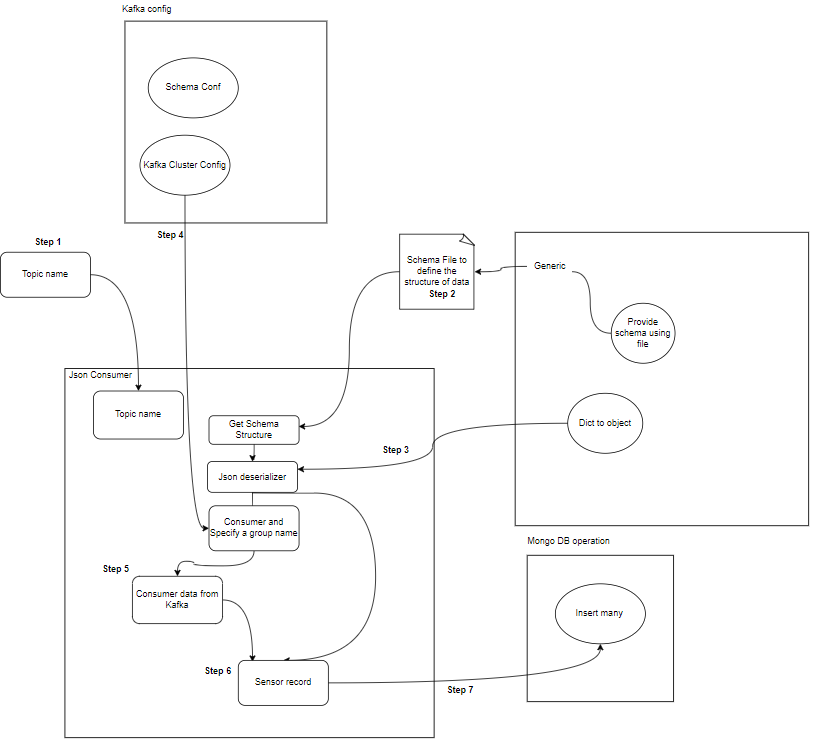
- مستهلك: يتحمل مستهلكو كافكا مسؤولية قراءة البيانات ومعالجتها من موضوعات كافكا ومعالجتها. يمكن للمستهلكين أن يكونوا جزءًا من أي تطبيق يحتاج إلى استخدام البيانات الواردة من كافكا والتفاعل معها. إنهم يشتركون في واحد أو أكثر من المواضيع والبيانات من وسطاء كافكا. يمكن تنظيم المستهلكين في مجموعات مستهلكين، حيث تضم كل مجموعة مستهلكين مستهلكًا واحدًا أو أكثر، ويتم استهلاك كل موضوع من قبل مستهلك واحد فقط داخل المجموعة. وهذا يسمح بالمعالجة المتوازية وموازنة التحميل لاستهلاك البيانات.
ما هو هيكل المشروع؟
يوضح هذا المخطط الانسيابي للمشروع كيفية تقسيم المجلد والملفات في المشروع:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- منتج كافكا: المنتج هو الجزء الرئيسي الذي يقوم بإنشاء بيانات الاستشعار (على سبيل المثال، من ملفات CSV في Sample_data/) وينشرها في موضوع كافكا. حالات الخطأ التي قد تحدث أثناء إنشاء البيانات أو نشرها.
- وسيط (وسطاء) كافكا: يقوم وسطاء كافكا بتخزين البيانات ونسخها عبر مجموعة كافكا، والتعامل مع تقسيم البيانات، وضمان التسامح مع الأخطاء والتوافر العالي.
- مستهلك (مستهلكو) كافكا: يقرأ المستهلكون البيانات من موضوعات كافكا، ويعالجونها (على سبيل المثال، التحويلات والتجميعات)، ويخزنونها في MongoDB. كما يقومون أيضًا بمراقبة حالات الخطأ التي قد تحدث أثناء معالجة البيانات.
- مونغو دي بي: يقوم MongoDB بتخزين بيانات المستشعر الواردة من مستهلكي كافكا. فهو يوفر استعلامًا لاسترجاع البيانات ويضمن متانة البيانات من خلال آليات النسخ المتماثل والتسامح مع الأخطاء.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
المتطلبات الأساسية لتخزين البيانات
كافكا المتكدسة
- إنشاء حساب: لفهم كافكا، أنت بحاجة إلى Confluent، فأنت تحب Apache Kafka®، ولكن لا تحب إدارته. إن الخدمة السحابية الأصلية والكاملة والمُدارة بالكامل تتجاوز كافكا حتى يتمكن أفضل الأشخاص لديك من التركيز على تقديم قيمة لشركتك.
- إنشاء المواضيع:
- انتقل إلى الصفحة الرئيسية وعلى الشريط الجانبي
- انتقل إلى البيئة ثم انقر على الافتراضي
- اذهب إلى المواضيع

- حدد موضوع جديد وإعطاء اسم الموضوع

MongoDB
قم بإنشاء الاشتراك ثم قم بتسجيل الدخول على MongoDB Atlas واحفظ رابط الاتصال الخاص بـ Mongodb Atlas لمزيد من الاستخدام.
دليل خطوة بخطوة لإعداد المشروع
- تثبيت بايثون: تأكد من تثبيت بايثون على جهازك. يمكنك تحميل وتثبيت بايثون من الموقع الرسمي.
- إصدار كوندا: تحقق من إصدار كوندا في المحطة.
- إنشاء بيئة افتراضية: قم بإنشاء بيئة افتراضية باستخدام venv.
conda create -p venv python==3.10 -y- تفعيل البيئة الافتراضية: تفعيل البيئة الافتراضية:
conda activate venv/- تثبيت الحزم المطلوبة: استخدم النقطة لتثبيت التبعيات الضرورية المدرجة في ملف require.txt:
pip install -r requirements.txt- يتعين علينا تعيين بعض متغيرات البيئة في النظام المحلي. هذا هو متغير بيئة الكتلة السحابية المتجانسة
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
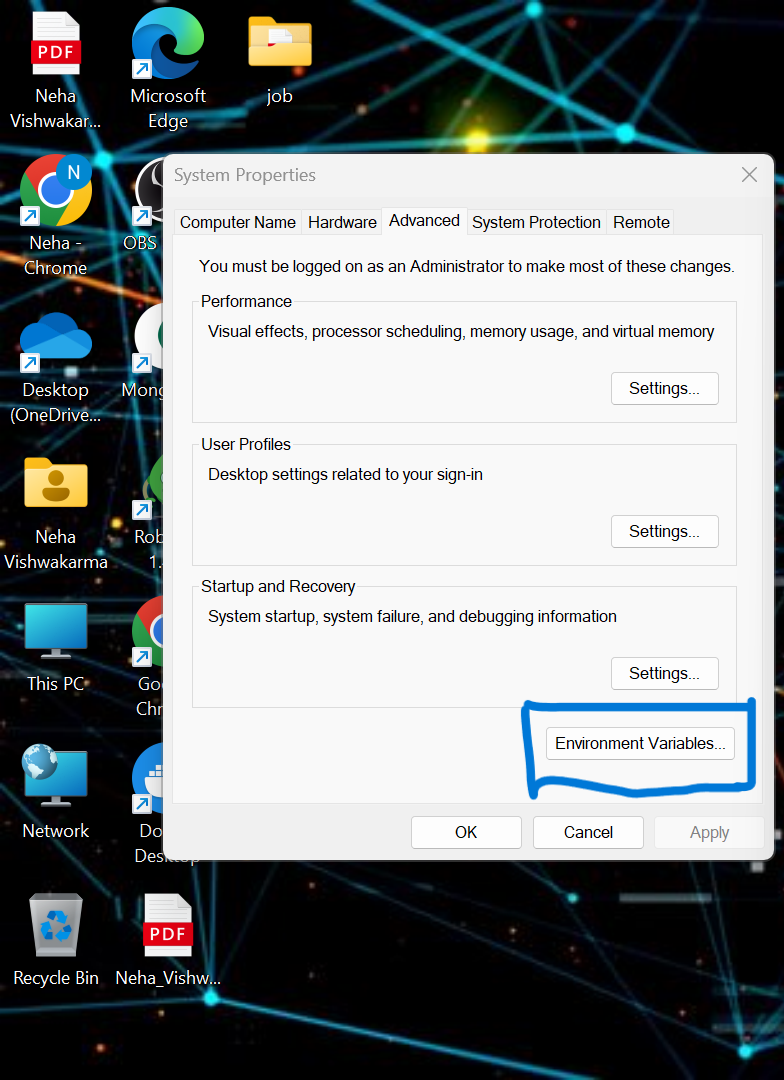
قم بتحديث بيانات الاعتماد في ملف .env وقم بتشغيل الأمر أدناه لتشغيل التطبيق الخاص بك في عامل الإرساء.
- قم بإنشاء ملف .env في المجلد الجذر لمشروعك إذا لم يكن متاحًا، فالصق المحتوى أدناه وقم بتحديث بيانات الاعتماد
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- تشغيل ملف المنتج والمستهلك:
python producer_main.py
python consumer_main.pyكيفية تنفيذ التعليمات البرمجية؟
- سرك/: هذا الدليل هو المجلد الرئيسي لجميع ملفات التعليمات البرمجية المصدر. ضمن هذا الدليل، لدينا الدلائل الفرعية التالية:
Consumer/: يحتوي هذا الدليل على كود Kafka_consumer، المسؤول عن قراءة البيانات من موضوعات كافكا ومعالجتها.
Producer/: يحتوي هذا الدليل على الكود الخاص بـ Kafka_producer، المسؤول عن إنشاء وإرسال بيانات الاستشعار إلى موضوعات Kafka. - التمهيدي.md: يحتوي ملف Markdown هذا على وثائق وتعليمات للمشروع، بما في ذلك نظرة عامة على الغرض منه والتعليمات وإرشادات الاستخدام وأي معلومات.
- المتطلبات.txt: يسرد هذا الملف مكتبة بايثون المطلوبة للمشروع. يتم سرد كل تبعية مع رقم الإصدار الخاص بها. يمكن لأدوات مثل النقطة استخدام هذا الملف لتثبيت التبعيات الضرورية تلقائيًا.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: لتوصيل MongoDB Altas من خلال الرابط، نقوم بكتابة نص python
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
أدخل عنوان URL الخاص بك والذي هو نسخة من MongoDb Altas
الإخراج:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
يتم تشغيل هذا الملف ثم نسميه بيثون Producer_main.py وهذا سوف يستدعي الملف أدناه:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
الإخراج:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
يتم تشغيل هذا الملف ثم نسميه بيثون Consumer_main.py وهذا سوف يستدعي الملف أدناه:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()الإخراج:

عندما نقوم بتشغيل كل من المستهلك والمنتج، يتم تشغيل النظام على الكافكا ويتم جمع المعلومات/البيانات بشكل أسرع

الإخراج:
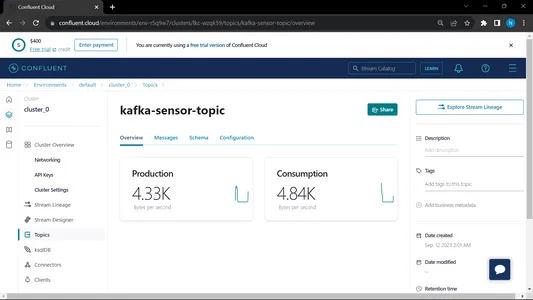
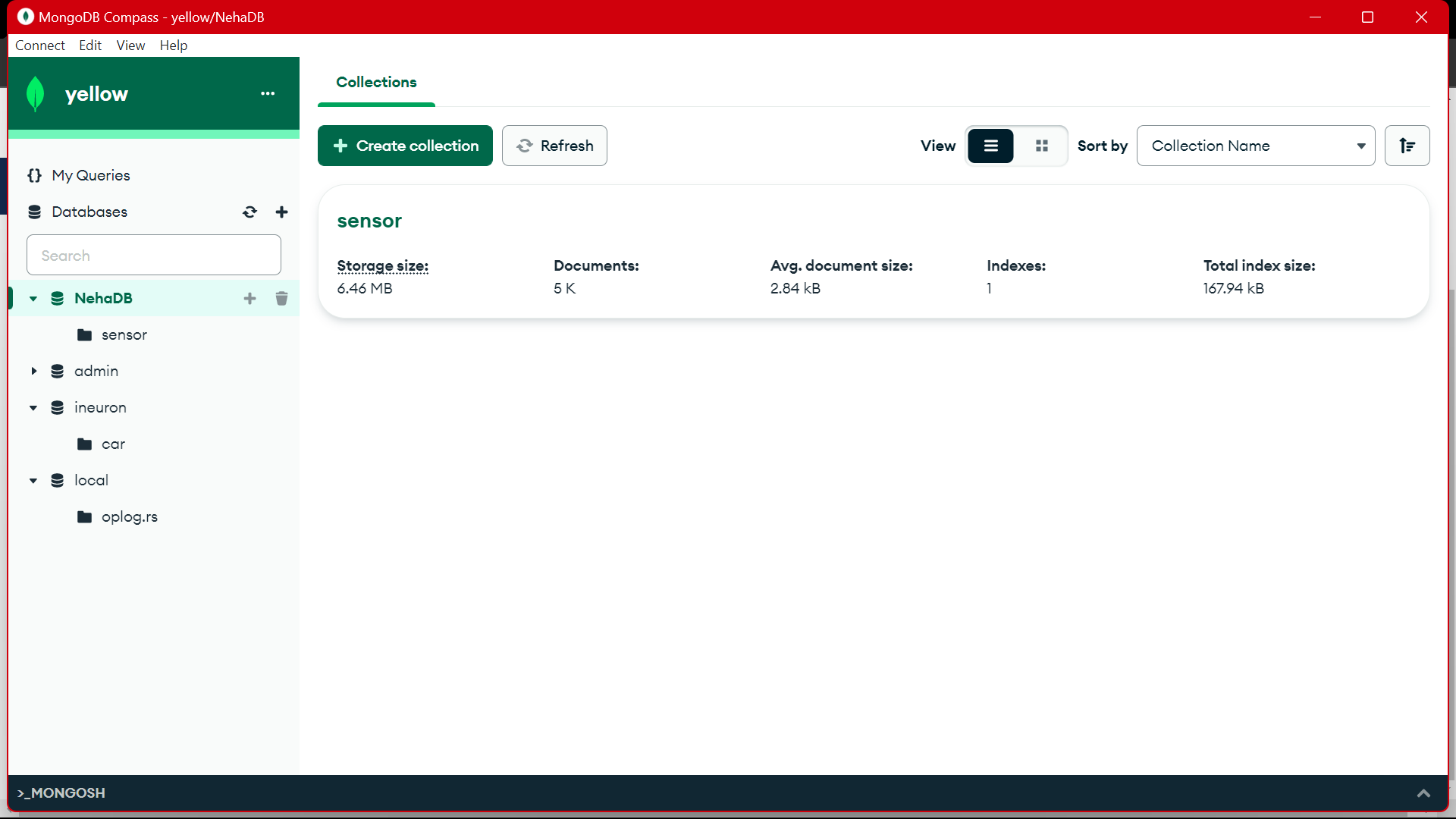
من MongoDB، نستخدم هذه البيانات للمعالجة المسبقة في EDA، ويتم تنفيذ أعمال هندسة الميزات وتحليلات البيانات على هذه البيانات.
[المحتوى جزءا لا يتجزأ]
وفي الختام
في هذه المقالة، نفهم كيف نقوم بتخزين ومعالجة البيانات المتدفقة من المستشعر إلى كافكا في شكل تنسيق JSON ثم نقوم بتخزين البيانات في MongoDB. نحن نعلم أن البيانات المتدفقة هي البيانات المنبعثة بكميات كبيرة في معالجة مستمرة مما يعني أن البيانات تتغير كل ثانية. لقد أنشأنا خط الأنابيب الشامل الذي يتم من خلاله جلب البيانات بمساعدة API في خط الأنابيب ثم جمعها في كافكا في شكل موضوعات ثم تخزينها في MongoDB من هناك يمكننا استخدامها في المشروع أو القيام بالأمر هندسة الميزات.
الوجبات السريعة الرئيسية
- تعرف على ما هو دفق البيانات وكيفية التعامل مع دفق البيانات بمساعدة كافكا.
- فهم Confluent Platform – توزيعة تتم إدارتها ذاتيًا على مستوى المؤسسة لـ Apache Kafka.
- قم بتخزين البيانات التي تم جمعها بواسطة Kafka في MongoDB وهي قاعدة بيانات NoSQL تقوم بتخزين البيانات غير المنظمة.
- قم بإنشاء خط أنابيب كامل من طرف إلى طرف لجلب البيانات وتخزينها في قاعدة البيانات.
- فهم وظيفة كل مكون من مكونات المشروع، وتنفيذها على عامل الإرساء وتنفيذها على السحابة لاستخدامها في أي وقت.
الموارد
الأسئلة المتكررة
A. يقوم MongoDB بتخزين البيانات في بيانات غير منظمة. البيانات المتدفقة هي أشكال غير منظمة من البيانات لاستخدام الذاكرة، ونحن نستخدم MongoDB كقاعدة بيانات.
ج. الغرض هو إنشاء خط أنابيب لمعالجة البيانات في الوقت الفعلي حيث يمكن استهلاك البيانات التي يتم استيعابها في موضوعات كافكا ومعالجتها وتخزينها في MongoDB لمزيد من التحليل أو إعداد التقارير أو استخدام التطبيق.
ج. تشمل حالات الاستخدام التحليلات في الوقت الفعلي، ومعالجة بيانات إنترنت الأشياء، وتجميع السجلات، ومراقبة وسائل التواصل الاجتماعي، وأنظمة التوصية، حيث يلزم معالجة البيانات المتدفقة وتخزينها لمزيد من التحليل أو استخدام التطبيق.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

