في هذا المنشور، نوضح كيفية ضبط نموذج لغة البروتين الحديث (pLM) بكفاءة للتنبؤ بتوطين البروتين تحت الخلوي باستخدام الأمازون SageMaker.
البروتينات هي الآلات الجزيئية في الجسم، وهي مسؤولة عن كل شيء بدءًا من تحريك العضلات وحتى الاستجابة للعدوى. وعلى الرغم من هذا التنوع، فإن جميع البروتينات مصنوعة من سلاسل متكررة من الجزيئات تسمى الأحماض الأمينية. يشفر الجينوم البشري 20 حمضًا أمينيًا قياسيًا، لكل منها تركيب كيميائي مختلف قليلاً. ويمكن تمثيلها بأحرف أبجدية، مما يسمح لنا بعد ذلك بتحليل واستكشاف البروتينات كسلسلة نصية. إن العدد الهائل المحتمل من تسلسلات البروتين وبنيته هو ما يمنح البروتينات تنوعًا واسعًا في الاستخدامات.
تلعب البروتينات أيضًا دورًا رئيسيًا في تطوير الأدوية، كأهداف محتملة ولكن أيضًا كعلاجات. وكما هو موضح في الجدول التالي، فإن العديد من الأدوية الأكثر مبيعًا في عام 2022 كانت إما بروتينات (خاصة الأجسام المضادة) أو جزيئات أخرى مثل mRNA المترجمة إلى بروتينات في الجسم. ولهذا السبب، يحتاج العديد من الباحثين في علوم الحياة إلى الإجابة على الأسئلة المتعلقة بالبروتينات بشكل أسرع وأرخص وأكثر دقة.
| الاسم | الشركة المصنعة | المبيعات العالمية لعام 2022 (مليارات الدولارات الأمريكية) | مؤشرات |
| كوميرناتي | شركة Pfizer / BioNTech | $40.8 | كوفيد-19 |
| سبيكيفاكس | حديث | $21.8 | كوفيد-19 |
| هوميرا | AbbVie | $21.6 | التهاب المفاصل، ومرض كرون، وغيرها |
| Keytruda | ميرك | $21.0 | السرطانات المختلفة |
مصدر البيانات: أوركهارت، L. أهم الشركات والأدوية حسب المبيعات عام 2022. مراجعات الطبيعة اكتشاف المخدرات 22, 260-260 (2023).
ولأننا نستطيع تمثيل البروتينات كتسلسلات من الحروف، فيمكننا تحليلها باستخدام تقنيات تم تطويرها في الأصل للغة المكتوبة. يتضمن ذلك نماذج لغوية كبيرة (LLMs) تم تدريبها مسبقًا على مجموعات بيانات ضخمة، والتي يمكن بعد ذلك تكييفها لمهام محددة، مثل تلخيص النص أو روبوتات الدردشة. وبالمثل، يتم تدريب pLMs مسبقًا على قواعد بيانات تسلسل البروتين الكبيرة باستخدام التعلم غير المسمى والخاضع للإشراف الذاتي. يمكننا تكييفها للتنبؤ بأشياء مثل البنية ثلاثية الأبعاد للبروتين أو كيفية تفاعله مع الجزيئات الأخرى. حتى أن الباحثين استخدموا pLMs لتصميم بروتينات جديدة من الصفر. لا تحل هذه الأدوات محل الخبرة العلمية البشرية، ولكنها تمتلك القدرة على تسريع التطوير قبل السريري وتصميم التجارب.
أحد التحديات التي تواجه هذه النماذج هو حجمها. وقد نمت كل من LLMs وpLMs من حيث الحجم في السنوات القليلة الماضية، كما هو موضح في الشكل التالي. وهذا يعني أن تدريبهم على الدقة الكافية قد يستغرق وقتًا طويلاً. ويعني ذلك أيضًا أنك بحاجة إلى استخدام أجهزة، خاصة وحدات معالجة الرسومات، ذات كميات كبيرة من الذاكرة لتخزين معلمات النموذج.
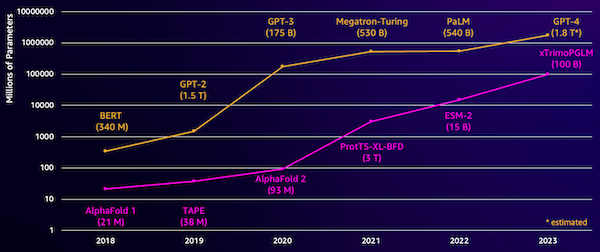
إن فترات التدريب الطويلة، بالإضافة إلى الحالات الكبيرة، تساوي تكلفة عالية، مما قد يجعل هذا العمل بعيدًا عن متناول العديد من الباحثين. على سبيل المثال، في عام 2023، أ فريق البحث وصف تدريب pLM بـ 100 مليار معلمة على 768 وحدة معالجة رسوميات A100 لمدة 164 يومًا! ولحسن الحظ، يمكننا في كثير من الحالات توفير الوقت والموارد من خلال تكييف pLM الموجود مع مهمتنا المحددة. هذه التقنية تسمى الكون المثالىويتيح لنا أيضًا استعارة أدوات متقدمة من أنواع أخرى من نماذج اللغة.
حل نظرة عامة
المشكلة المحددة التي نتناولها في هذا المنشور هي توطين تحت الخلوي: بالنظر إلى تسلسل البروتين، هل يمكننا بناء نموذج يمكنه التنبؤ بما إذا كان يعيش خارج الخلية (غشاء الخلية) أم داخلها؟ هذه معلومة مهمة يمكن أن تساعدنا في فهم الوظيفة وما إذا كانت ستشكل هدفًا جيدًا للأدوية.
نبدأ بتنزيل مجموعة البيانات العامة باستخدام أمازون ساجميكر ستوديو. ثم نستخدم SageMaker لضبط نموذج لغة البروتين ESM-2 باستخدام طريقة تدريب فعالة. وأخيرًا، قمنا بنشر النموذج كنقطة نهاية للاستدلال في الوقت الفعلي واستخدامه لاختبار بعض البروتينات المعروفة. ويوضح الرسم البياني التالي سير العمل هذا.

في الأقسام التالية، نستعرض خطوات إعداد بيانات التدريب الخاصة بك، وإنشاء برنامج نصي للتدريب، وتشغيل مهمة تدريب SageMaker. كل الكود الموجود في هذا المنشور متاح على GitHub جيثب:.
تحضير بيانات التدريب
نحن نستخدم جزء من مجموعة بيانات DeepLoc-2، والذي يحتوي على عدة آلاف من بروتينات SwissProt ذات المواقع المحددة تجريبيًا. نقوم بالتصفية للحصول على تسلسلات عالية الجودة بين 100-512 من الأحماض الأمينية:
df = pd.read_csv(
"https://services.healthtech.dtu.dk/services/DeepLoc-2.0/data/Swissprot_Train_Validation_dataset.csv"
).drop(["Unnamed: 0", "Partition"], axis=1)
df["Membrane"] = df["Membrane"].astype("int32")
# filter for sequences between 100 and 512 amino acides
df = df[df["Sequence"].apply(lambda x: len(x)).between(100, 512)]
# Remove unnecessary features
df = df[["Sequence", "Kingdom", "Membrane"]]
بعد ذلك، نقوم بترميز التسلسلات وتقسيمها إلى مجموعات تدريب وتقييم:
dataset = Dataset.from_pandas(df).train_test_split(test_size=0.2, shuffle=True)
tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t33_650M_UR50D")
def preprocess_data(examples, max_length=512):
text = examples["Sequence"]
encoding = tokenizer(text, truncation=True, max_length=max_length)
encoding["labels"] = examples["Membrane"]
return encoding
encoded_dataset = dataset.map(
preprocess_data,
batched=True,
num_proc=os.cpu_count(),
remove_columns=dataset["train"].column_names,
)
encoded_dataset.set_format("torch")
وأخيرًا، نقوم بتحميل بيانات التدريب والتقييم المعالجة إلى خدمة تخزين أمازون البسيطة (أمازون إس 3):
train_s3_uri = S3_PATH + "/data/train"
test_s3_uri = S3_PATH + "/data/test"
encoded_dataset["train"].save_to_disk(train_s3_uri)
encoded_dataset["test"].save_to_disk(test_s3_uri)إنشاء برنامج نصي للتدريب
وضع البرنامج النصي SageMaker يسمح لك بتشغيل كود التدريب المخصص الخاص بك في حاويات إطار عمل التعلم الآلي (ML) المحسنة التي تديرها AWS. في هذا المثال، نقوم بتكييف البرنامج النصي الموجود لتصنيف النص من عناق الوجه. يتيح لنا هذا تجربة عدة طرق لتحسين كفاءة عملنا التدريبي.
الطريقة الأولى: فئة التدريب المرجح
مثل العديد من مجموعات البيانات البيولوجية، يتم توزيع بيانات DeepLoc بشكل غير متساو، مما يعني عدم وجود عدد متساو من البروتينات الغشائية وغير الغشائية. يمكننا إعادة تشكيل بياناتنا وتجاهل السجلات من فئة الأغلبية. ومع ذلك، فإن هذا من شأنه أن يقلل من إجمالي بيانات التدريب وربما يؤثر على دقتنا. وبدلاً من ذلك، نقوم بحساب أوزان الفئة أثناء مهمة التدريب ونستخدمها لضبط الخسارة.
في برنامجنا التدريبي، قمنا بتصنيف فرعي لـ Trainer فئة من transformers مع WeightedTrainer فئة تأخذ أوزان الفئة في الاعتبار عند حساب خسارة الإنتروبيا المتقاطعة. وهذا يساعد على منع التحيز في نموذجنا:
class WeightedTrainer(Trainer):
def __init__(self, class_weights, *args, **kwargs):
self.class_weights = class_weights
super().__init__(*args, **kwargs)
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.get("logits")
loss_fct = torch.nn.CrossEntropyLoss(
weight=torch.tensor(self.class_weights, device=model.device)
)
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else lossالطريقة الثانية: تراكم التدرج
التراكم المتدرج هو أسلوب تدريب يسمح للنماذج بمحاكاة التدريب على أحجام دفعات أكبر. عادةً ما يكون حجم الدفعة (عدد العينات المستخدمة لحساب التدرج في خطوة تدريب واحدة) محدودًا بسعة ذاكرة وحدة معالجة الرسومات. مع تراكم التدرج، يقوم النموذج بحساب التدرجات على دفعات أصغر أولاً. بعد ذلك، بدلاً من تحديث أوزان النموذج على الفور، يتم تجميع التدرجات على دفعات صغيرة متعددة. عندما تساوي التدرجات المتراكمة حجم الدفعة الأكبر المستهدف، يتم تنفيذ خطوة التحسين لتحديث النموذج. يتيح ذلك للنماذج التدريب بدفعات أكبر بشكل فعال دون تجاوز الحد الأقصى لذاكرة وحدة معالجة الرسومات.
ومع ذلك، هناك حاجة إلى عمليات حسابية إضافية للدفعات الصغيرة التي يتم تمريرها للأمام والخلف. يمكن أن تؤدي زيادة أحجام الدفعات عبر التراكم المتدرج إلى إبطاء التدريب، خاصة إذا تم استخدام عدد كبير جدًا من خطوات التراكم. الهدف هو زيادة استخدام وحدة معالجة الرسومات إلى الحد الأقصى مع تجنب التباطؤ المفرط الناتج عن العديد من خطوات الحساب المتدرجة الإضافية.
الطريقة الثالثة: فحص التدرج
إن نقطة التفتيش المتدرجة هي تقنية تقلل من الذاكرة المطلوبة أثناء التدريب مع الحفاظ على الوقت الحسابي معقولاً. تستهلك الشبكات العصبية الكبيرة قدرًا كبيرًا من الذاكرة لأنه يتعين عليها تخزين كافة القيم المتوسطة من التمريرة الأمامية من أجل حساب التدرجات أثناء التمريرة الخلفية. هذا يمكن أن يسبب مشاكل في الذاكرة. أحد الحلول هو عدم تخزين هذه القيم المتوسطة، ولكن بعد ذلك يجب إعادة حسابها أثناء التمرير للخلف، الأمر الذي يستغرق الكثير من الوقت.
توفر نقاط التفتيش المتدرجة نهجا متوازنا. فهو يحفظ فقط بعض القيم الوسيطة، التي تسمى نقاط التفتيش، ويعيد حساب الآخرين حسب الحاجة. لذلك، فهو يستخدم ذاكرة أقل من تخزين كل شيء، ولكنه يستخدم أيضًا عملية حسابية أقل من إعادة حساب كل شيء. من خلال الاختيار الاستراتيجي لعمليات التنشيط التي سيتم فحصها، تتيح عملية فحص التدرج إمكانية تدريب الشبكات العصبية الكبيرة باستخدام ذاكرة يمكن التحكم فيها ووقت حسابي. هذه التقنية المهمة تجعل من الممكن تدريب نماذج كبيرة جدًا والتي قد تتعرض لقيود الذاكرة.
في البرنامج النصي التدريبي الخاص بنا، نقوم بتشغيل تنشيط التدرج والتحقق من خلال إضافة المعلمات الضرورية إلى ملف TrainingArguments موضوع:
from transformers import TrainingArguments
training_args = TrainingArguments(
gradient_accumulation_steps=4,
gradient_checkpointing=True
)الطريقة الرابعة: التكيف ذو الرتبة المنخفضة للماجستير في القانون
يمكن أن تحتوي نماذج اللغات الكبيرة مثل ESM-2 على مليارات من المعلمات التي يعد تدريبها وتشغيلها مكلفًا. الباحثين طورت طريقة تدريب تسمى التكيف منخفض الرتبة (LoRA) لجعل ضبط هذه النماذج الضخمة أكثر كفاءة.
الفكرة الأساسية وراء LoRA هي أنه عند ضبط نموذج لمهمة محددة، لا تحتاج إلى تحديث جميع المعلمات الأصلية. بدلاً من ذلك، تضيف LoRA مصفوفات جديدة أصغر إلى النموذج الذي يحول المدخلات والمخرجات. يتم تحديث هذه المصفوفات الأصغر فقط أثناء الضبط الدقيق، وهو أسرع بكثير ويستخدم ذاكرة أقل. تظل معلمات النموذج الأصلي مجمدة.
بعد الضبط الدقيق باستخدام LoRA، يمكنك دمج المصفوفات الصغيرة المعدلة مرة أخرى في النموذج الأصلي. أو يمكنك الاحتفاظ بها منفصلة إذا كنت تريد ضبط النموذج بسرعة لمهام أخرى دون نسيان المهام السابقة. بشكل عام، يسمح LoRA لـ LLMs بالتكيف بكفاءة مع المهام الجديدة بجزء بسيط من التكلفة المعتادة.
في برنامجنا التدريبي، نقوم بتكوين LoRA باستخدام ملف PEFT مكتبة من عناق الوجه:
from peft import get_peft_model, LoraConfig, TaskType
import torch
from transformers import EsmForSequenceClassification
model = EsmForSequenceClassification.from_pretrained(
“facebook/esm2_t33_650M_UR50D”,
Torch_dtype=torch.bfloat16,
Num_labels=2,
)
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
bias="none",
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=[
"query",
"key",
"value",
"EsmSelfOutput.dense",
"EsmIntermediate.dense",
"EsmOutput.dense",
"EsmContactPredictionHead.regression",
"EsmClassificationHead.dense",
"EsmClassificationHead.out_proj",
]
)
model = get_peft_model(model, peft_config)إرسال وظيفة تدريب SageMaker
بعد تحديد البرنامج النصي للتدريب، يمكنك تكوين مهمة تدريب SageMaker وإرسالها. أولاً، حدد المعلمات الفائقة:
hyperparameters = {
"model_id": "facebook/esm2_t33_650M_UR50D",
"epochs": 1,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 4,
"use_gradient_checkpointing": True,
"lora": True,
}بعد ذلك، حدد المقاييس التي يجب التقاطها من سجلات التدريب:
metric_definitions = [
{"Name": "epoch", "Regex": "'epoch': ([0-9.]*)"},
{
"Name": "max_gpu_mem",
"Regex": "Max GPU memory use during training: ([0-9.e-]*) MB",
},
{"Name": "train_loss", "Regex": "'loss': ([0-9.e-]*)"},
{
"Name": "train_samples_per_second",
"Regex": "'train_samples_per_second': ([0-9.e-]*)",
},
{"Name": "eval_loss", "Regex": "'eval_loss': ([0-9.e-]*)"},
{"Name": "eval_accuracy", "Regex": "'eval_accuracy': ([0-9.e-]*)"},
]أخيرًا، حدد مُقدِّر Hugging Face وأرسله للتدريب على نوع مثيل ml.g5.2xlarge. يعد هذا نوع مثيل فعال من حيث التكلفة ومتوفر على نطاق واسع في العديد من مناطق AWS:
from sagemaker.experiments.run import Run
from sagemaker.huggingface import HuggingFace
from sagemaker.inputs import TrainingInput
hf_estimator = HuggingFace(
base_job_name="esm-2-membrane-ft",
entry_point="lora-train.py",
source_dir="scripts",
instance_type="ml.g5.2xlarge",
instance_count=1,
transformers_version="4.28",
pytorch_version="2.0",
py_version="py310",
output_path=f"{S3_PATH}/output",
role=sagemaker_execution_role,
hyperparameters=hyperparameters,
metric_definitions=metric_definitions,
checkpoint_local_path="/opt/ml/checkpoints",
sagemaker_session=sagemaker_session,
keep_alive_period_in_seconds=3600,
tags=[{"Key": "project", "Value": "esm-fine-tuning"}],
)
with Run(
experiment_name=EXPERIMENT_NAME,
sagemaker_session=sagemaker_session,
) as run:
hf_estimator.fit(
{
"train": TrainingInput(s3_data=train_s3_uri),
"test": TrainingInput(s3_data=test_s3_uri),
}
)يقارن الجدول التالي طرق التدريب المختلفة التي ناقشناها وتأثيرها على وقت التشغيل والدقة ومتطلبات ذاكرة وحدة معالجة الرسومات لعملنا.
| الاعداد | الوقت القابل للفوترة (دقيقة) | دقة التقييم | الحد الأقصى لاستخدام ذاكرة وحدة معالجة الرسومات (جيجابايت) |
| نموذج القاعدة | 28 | 0.91 | 22.6 |
| قاعدة + جي ايه | 21 | 0.90 | 17.8 |
| قاعدة + جي سي | 29 | 0.91 | 10.2 |
| قاعدة + لورا | 23 | 0.90 | 18.6 |
أنتجت جميع الطرق نماذج ذات دقة تقييم عالية. أدى استخدام LoRA وتنشيط التدرج إلى تقليل وقت التشغيل (والتكلفة) بنسبة 18% و25% على التوالي. أدى استخدام نقاط التفتيش المتدرجة إلى تقليل الحد الأقصى لاستخدام ذاكرة وحدة معالجة الرسومات بنسبة 55%. اعتمادًا على القيود التي تواجهك (التكلفة والوقت والأجهزة)، قد يكون أحد هذه الأساليب أكثر منطقية من الآخر.
تعمل كل من هذه الطرق بشكل جيد بمفردها، ولكن ماذا يحدث عندما نستخدمها معًا؟ ويلخص الجدول التالي النتائج.
| الاعداد | الوقت القابل للفوترة (دقيقة) | دقة التقييم | الحد الأقصى لاستخدام ذاكرة وحدة معالجة الرسومات (جيجابايت) |
| جميع الأساليب | 12 | 0.80 | 3.3 |
وفي هذه الحالة، نرى انخفاضًا في الدقة بنسبة 12%. ومع ذلك، فقد قمنا بتقليل وقت التشغيل بنسبة 57% واستخدام ذاكرة وحدة معالجة الرسومات بنسبة 85%! وهذا انخفاض هائل يسمح لنا بالتدريب على مجموعة واسعة من أنواع المثيلات الفعالة من حيث التكلفة.
تنظيف
إذا كنت تتابع في حساب AWS الخاص بك، فاحذف أي نقاط نهاية وبيانات للاستدلال في الوقت الفعلي قمت بإنشائها لتجنب المزيد من الرسوم.
predictor.delete_endpoint()
bucket = boto_session.resource("s3").Bucket(S3_BUCKET)
bucket.objects.filter(Prefix=S3_PREFIX).delete()وفي الختام
في هذا المنشور، أظهرنا كيفية ضبط نماذج لغة البروتين بكفاءة مثل ESM-2 لمهمة ذات صلة علميًا. لمزيد من المعلومات حول استخدام مكتبات Transformers وPEFT لتدريب pLMS، راجع المنشورات التعلم العميق مع البروتينات و ESMBind (ESMB): التكيف ذو الرتبة المنخفضة لـ ESM-2 للتنبؤ بموقع ربط البروتين على مدونة Hugging Face. يمكنك أيضًا العثور على المزيد من الأمثلة على استخدام التعلم الآلي للتنبؤ بخصائص البروتين في تحليل بروتين رائع على AWS مستودع جيثب.
عن المؤلف
 بريان لويال هو كبير مهندسي حلول AI / ML في فريق الرعاية الصحية العالمية وعلوم الحياة في Amazon Web Services. يتمتع بخبرة تزيد عن 17 عامًا في مجال التكنولوجيا الحيوية والتعلم الآلي ، وهو متحمس لمساعدة العملاء على حل تحديات الجينوم والبروتينات. في أوقات فراغه ، يستمتع بالطهي وتناول الطعام مع أصدقائه وعائلته.
بريان لويال هو كبير مهندسي حلول AI / ML في فريق الرعاية الصحية العالمية وعلوم الحياة في Amazon Web Services. يتمتع بخبرة تزيد عن 17 عامًا في مجال التكنولوجيا الحيوية والتعلم الآلي ، وهو متحمس لمساعدة العملاء على حل تحديات الجينوم والبروتينات. في أوقات فراغه ، يستمتع بالطهي وتناول الطعام مع أصدقائه وعائلته.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/efficiently-fine-tune-the-esm-2-protein-language-model-with-amazon-sagemaker/

