صورة المؤلف
يمكن أن يؤدي استخدام مسارات Scikit-learn إلى تبسيط خطوات المعالجة المسبقة والنمذجة، وتقليل تعقيد التعليمات البرمجية، وضمان الاتساق في المعالجة المسبقة للبيانات، والمساعدة في ضبط المعلمات الفائقة، وجعل سير عملك أكثر تنظيمًا وأسهل في الصيانة. من خلال دمج التحويلات المتعددة والنموذج النهائي في كيان واحد، تعمل خطوط الأنابيب على تعزيز إمكانية التكرار وجعل كل شيء أكثر كفاءة.
في هذا البرنامج التعليمي، سوف نعمل مع عنف البنك مجموعة بيانات من Kaggle لتدريب Random Forest Classifier. سنقوم بمقارنة النهج التقليدي للمعالجة المسبقة للبيانات والتدريب على النماذج بطريقة أكثر كفاءة باستخدام خطوط أنابيب Scikit-learn وColumnTransformers.
في مسار معالجة البيانات، سوف نتعلم كيفية تحويل كل من الأعمدة الفئوية والرقمية بشكل فردي. سنبدأ بالنمط التقليدي للتعليمات البرمجية ثم نعرض طريقة أفضل لإجراء معالجة مماثلة.
بعد استخراج البيانات من الملف المضغوط، قم بتحميل ملف "train.csv" مع "id" كعمود الفهرس. قم بإسقاط الأعمدة غير الضرورية وقم بتبديل مجموعة البيانات.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
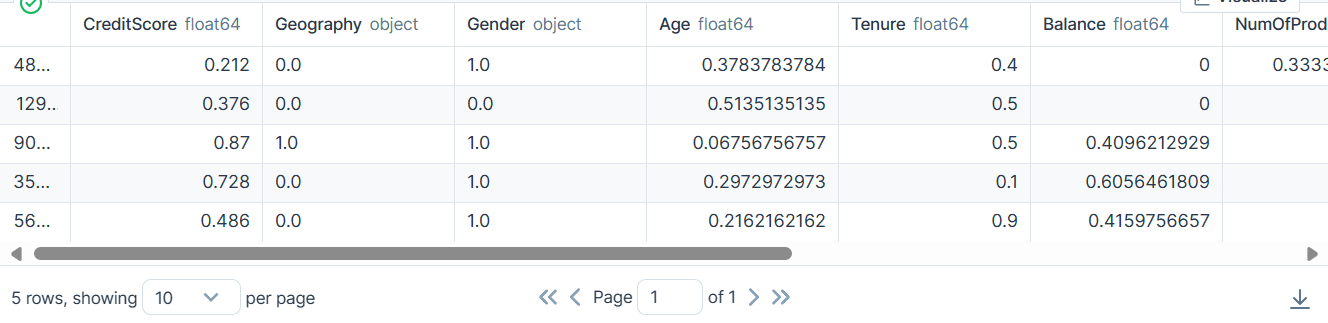
bank_df.head()
لدينا أعمدة فئوية، وعدد صحيح، وعائمة. تبدو مجموعة البيانات نظيفة جدًا.

رمز Scikit-Learn البسيط
كعالم بيانات، كتبت هذا الرمز عدة مرات. هدفنا هو ملء القيم المفقودة لكل من الميزات الفئوية والعددية. ولتحقيق ذلك، سوف نستخدم "SimpleImputer" مع استراتيجيات مختلفة لكل نوع من الميزات.
بعد ملء القيم المفقودة، سنقوم بتحويل الميزات الفئوية إلى أعداد صحيحة وتطبيق مقياس الحد الأدنى والحد الأقصى على الميزات الرقمية.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()
ونتيجة لذلك، حصلنا على مجموعة بيانات نظيفة ومحولة بقيم صحيحة أو عائمة فقط.
Scikit-Learn رمز خطوط الأنابيب
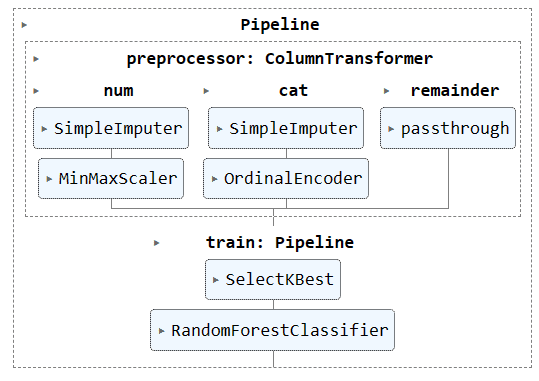
لنقم بتحويل الكود أعلاه باستخدام "خط الأنابيب" و"ColumnTransformer". بدلاً من تطبيق تقنية المعالجة المسبقة، سنقوم بإنشاء خطي أنابيب. أحدهما مخصص للأعمدة الرقمية، والآخر مخصص للأعمدة الفئوية.
- في خط الأنابيب العددي، استخدمنا عملية حسابية بسيطة مع استراتيجية "متوسطة" وقمنا بتطبيق مقياس الحد الأدنى والحد الأقصى للتطبيع.
- في خط الأنابيب الفئوي، استخدمنا جهاز الكمبيوتر البسيط مع استراتيجية "الأكثر_تكرارًا" وجهاز التشفير الأصلي لتحويل الفئات إلى قيم رقمية.
لقد قمنا بدمج خطي الأنابيب باستخدام ColumnTransformer وقمنا بتزويد كل منهما بفهرس الأعمدة. سيساعدك ذلك على تطبيق خطوط الأنابيب هذه على أعمدة معينة. على سبيل المثال، سيتم تطبيق خط أنابيب المحولات الفئوية على العمودين 1 و2 فقط.
ملحوظة: الباقي = "العبور" يعني أنه سيتم إضافة الأعمدة التي لم تتم معالجتها في النهاية. في حالتنا، هو العمود الهدف.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
بعد التحويل، تحتوي المصفوفة الناتجة على قيمة تحويل رقمية في البداية وقيمة تحويل فئوية في النهاية، بناءً على ترتيب خطوط الأنابيب في محول العمود.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
يمكنك تشغيل كائن خط الأنابيب في Jupyter Notebook لتصور خط الأنابيب. تأكد من حصولك على أحدث إصدار من Scikit-learn.
preproc_pipe

لتدريب نموذجنا وتقييمه، نحتاج إلى تقسيم مجموعة البيانات الخاصة بنا إلى مجموعتين فرعيتين: التدريب والاختبار.
للقيام بذلك، سنقوم أولاً بإنشاء متغيرات تابعة ومستقلة وتحويلها إلى مصفوفات NumPy. بعد ذلك، سوف نستخدم وظيفة `train_test_split` لتقسيم مجموعة البيانات إلى مجموعتين فرعيتين.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)رمز Scikit-Learn البسيط
تتمثل الطريقة التقليدية لكتابة كود التدريب في إجراء اختيار الميزة أولاً باستخدام `SelectKBest` ثم توفير الميزة الجديدة لنموذج Random Forest Classifier الخاص بنا.
سنقوم أولاً بتدريب النموذج باستخدام مجموعة التدريب وتقييم النتائج باستخدام مجموعة بيانات الاختبار.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
لقد حققنا درجة دقة جيدة إلى حد معقول.
0.8613035487063481Scikit-Learn رمز خطوط الأنابيب
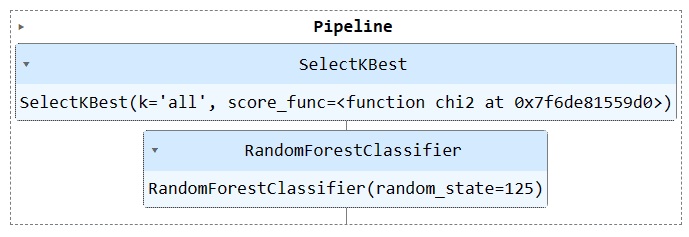
فلنستخدم وظيفة "خط الأنابيب" لدمج خطوتين التدريب في مسار. يمكننا بعد ذلك ملاءمة النموذج في مجموعة التدريب وتقييمه في مجموعة الاختبار.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
لقد حققنا نتائج مماثلة، ولكن يبدو أن الكود أكثر كفاءة ومباشرة. من السهل جدًا إضافة خطوات جديدة أو إزالتها من مسار التدريب.
0.8613035487063481
قم بتشغيل كائن خط الأنابيب لتصور خط الأنابيب.
train_pipe
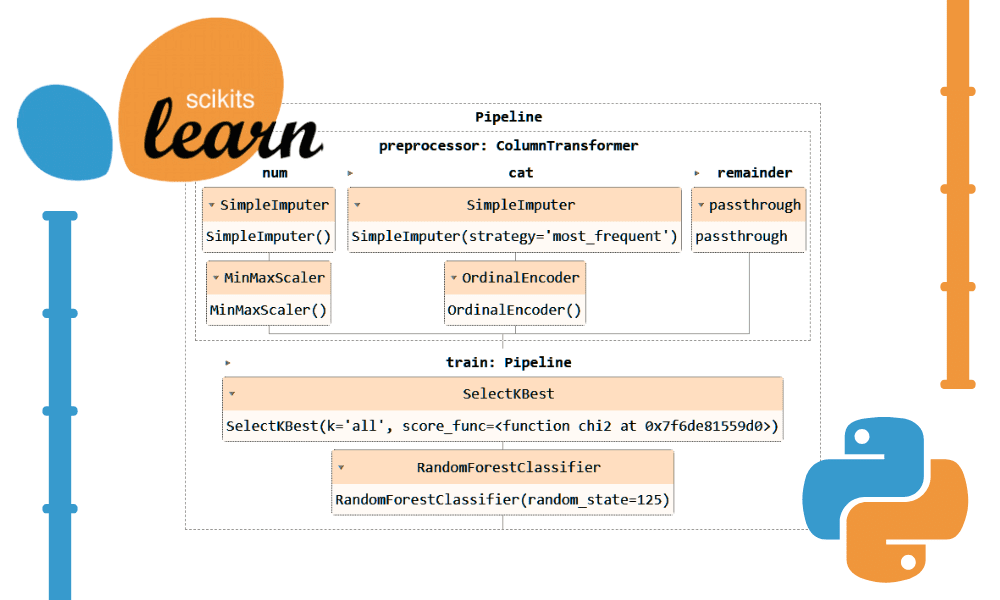
الآن، سنقوم بدمج كل من المعالجة المسبقة وخط الأنابيب للتدريب عن طريق إنشاء خط أنابيب آخر وإضافة كلا الخطين.
ها هو الكود الكامل:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
الإخراج:
0.8592837955201874
تصور خط الأنابيب الكامل.
complete_pipe

إحدى المزايا الرئيسية لاستخدام خطوط الأنابيب هي أنه يمكنك حفظ خط الأنابيب بالنموذج. أثناء الاستدلال، ما عليك سوى تحميل كائن خط الأنابيب، والذي سيكون جاهزًا لمعالجة البيانات الأولية وتزويدك بتنبؤات دقيقة. لا تحتاج إلى إعادة كتابة وظائف المعالجة والتحويل في ملف التطبيق، لأنها ستعمل خارج الصندوق. وهذا يجعل سير عمل التعلم الآلي أكثر كفاءة ويوفر الوقت.
دعونا أولاً نحفظ خط الأنابيب باستخدام ملف skops-dev/skops مكتبة.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
ثم قم بتحميل خط الأنابيب المحفوظ وعرض خط الأنابيب.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
كما نرى، لقد قمنا بتحميل خط الأنابيب بنجاح.
لتقييم خط الأنابيب المحمل لدينا، سنقوم بعمل تنبؤات على مجموعة الاختبار ثم نحسب الدقة ونتائج F1.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
اتضح أننا بحاجة إلى التركيز على فئات الأقليات لتحسين نتيجة الفورمولا 1.
Accuracy: 86.0% F1: 0.76
ملفات المشروع والتعليمات البرمجية متاحة على مساحة عمل Deepnote. تحتوي مساحة العمل على دفتري ملاحظات: أحدهما مزود بمسار Scikit-Learn والآخر بدونه.
في هذا البرنامج التعليمي، تعلمنا كيف يمكن أن تساعد مسارات Scikit-Learn في تبسيط سير عمل التعلم الآلي من خلال ربط تسلسلات تحويلات البيانات والنماذج معًا. من خلال الجمع بين المعالجة المسبقة والتدريب النموذجي في كائن Pipeline واحد، يمكننا تبسيط التعليمات البرمجية، وضمان تحويلات البيانات المتسقة، وجعل سير العمل لدينا أكثر تنظيمًا وقابلية للتكرار.
عابد علي عوان (@ 1abidaliawan) هو عالم بيانات متخصص محترف يحب بناء نماذج التعلم الآلي. يركز حاليًا على إنشاء المحتوى وكتابة مدونات تقنية حول تقنيات التعلم الآلي وعلوم البيانات. عابد حاصل على درجة الماجستير في إدارة التكنولوجيا ودرجة البكالوريوس في هندسة الاتصالات. تتمثل رؤيته في بناء منتج للذكاء الاصطناعي باستخدام شبكة عصبية بيانية للطلاب الذين يعانون من مرض عقلي.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

