المُقدّمة
في عالم اليوم سريع الخطى، تعد خدمة العملاء جانبًا حاسمًا في أي عمل تجاري. يمكن لـ Zendesk Answer Bot، المدعوم بنماذج اللغات الكبيرة (LLMs) مثل GPT-4، أن يعزز بشكل كبير كفاءة وجودة دعم العملاء من خلال أتمتة الاستجابات. سيرشدك منشور المدونة هذا خلال إنشاء ونشر Zendesk Auto Responder الخاص بك باستخدام LLMs وتنفيذ سير العمل المستند إلى RAG في GenAI لتبسيط العملية.

ما هي مسارات العمل المستندة إلى RAG في GenAI
تجمع مسارات العمل المستندة إلى RAG (الجيل المعزز للاسترجاع) في GenAI (الذكاء الاصطناعي المولد) بين فوائد الاسترجاع والإنشاء لتعزيز قدرات نظام الذكاء الاصطناعي، لا سيما في التعامل مع البيانات الواقعية والخاصة بالمجال. بعبارات بسيطة، يمكّن RAG الذكاء الاصطناعي من سحب المعلومات ذات الصلة من قاعدة بيانات أو مصادر أخرى لدعم توليد استجابات أكثر دقة واستنارة. وهذا مفيد بشكل خاص في إعدادات الأعمال حيث تعد الدقة والسياق أمرًا بالغ الأهمية.
ما هي المكونات الموجودة في سير العمل القائم على RAG؟
- قاعدة المعرفة: قاعدة المعرفة هي مستودع مركزي للمعلومات التي يشير إليها النظام عند الإجابة على الاستفسارات. ويمكن أن تتضمن الأسئلة الشائعة والأدلة والمستندات الأخرى ذات الصلة.
- المشغل/الاستعلام: هذا المكون مسؤول عن بدء سير العمل. عادةً ما يكون سؤال أو طلب العميل هو الذي يحتاج إلى استجابة أو إجراء.
- المهمة/الإجراء: استنادًا إلى تحليل المشغل/الاستعلام، يقوم النظام بتنفيذ مهمة أو إجراء محدد، مثل إنشاء استجابة أو تنفيذ عملية خلفية.
بعض الأمثلة على سير العمل القائم على RAG
- سير عمل تفاعل العملاء في الخدمات المصرفية:
- يمكن لروبوتات الدردشة المدعومة بـ GenAI وRAG تحسين معدلات المشاركة في الصناعة المصرفية بشكل كبير من خلال تخصيص التفاعلات.
- من خلال RAG، يمكن لروبوتات الدردشة استرداد المعلومات ذات الصلة واستخدامها من قاعدة البيانات لإنشاء ردود مخصصة على استفسارات العملاء.
- على سبيل المثال، أثناء جلسة الدردشة، يمكن لنظام GenAI المستند إلى RAG سحب سجل معاملات العميل أو معلومات الحساب من قاعدة البيانات لتوفير استجابات أكثر استنارة وتخصيصًا.
- لا يؤدي سير العمل هذا إلى تعزيز رضا العملاء فحسب، بل قد يزيد أيضًا من معدل الاحتفاظ بهم من خلال توفير تجربة تفاعل أكثر تخصيصًا وغنية بالمعلومات.
- سير عمل حملات البريد الإلكتروني:
- في التسويق والمبيعات، يعد إنشاء حملات مستهدفة أمرًا بالغ الأهمية.
- يمكن استخدام RAG للحصول على أحدث معلومات المنتج أو تعليقات العملاء أو اتجاهات السوق من مصادر خارجية للمساعدة في إنشاء مواد تسويق / مبيعات أكثر استنارة وفعالية.
- على سبيل المثال، عند صياغة حملة بريد إلكتروني، يمكن لسير العمل المستند إلى RAG استرداد المراجعات الإيجابية الأخيرة أو ميزات المنتج الجديدة لتضمينها في محتوى الحملة، وبالتالي تحسين معدلات المشاركة ونتائج المبيعات.
- توثيق الكود الآلي وسير عمل التعديل:
- في البداية، يمكن لنظام RAG سحب وثائق التعليمات البرمجية الحالية وقاعدة التعليمات البرمجية ومعايير الترميز من مستودع المشروع.
- عندما يحتاج المطور إلى إضافة ميزة جديدة، يمكن لـ RAG إنشاء مقتطف تعليمات برمجية يتبع معايير ترميز المشروع من خلال الرجوع إلى المعلومات المستردة.
- إذا كانت هناك حاجة إلى تعديل في الكود، فيمكن لنظام RAG اقتراح تغييرات من خلال تحليل الكود والوثائق الموجودة، مما يضمن الاتساق والالتزام بمعايير الترميز.
- تعديل أو إضافة الرمز البريدي، يمكن لـ RAG تحديث وثائق الكود تلقائيًا لتعكس التغييرات، وسحب المعلومات الضرورية من قاعدة التعليمات البرمجية والوثائق الموجودة.
كيفية تنزيل وفهرسة جميع تذاكر Zendesk لاسترجاعها
دعونا الآن نبدأ مع البرنامج التعليمي. سنقوم ببناء روبوت للرد على تذاكر Zendesk الواردة أثناء استخدام قاعدة بيانات مخصصة لتذاكر Zendesk السابقة والاستجابات لتوليد الإجابة بمساعدة LLMs.
- الوصول إلى واجهة برمجة تطبيقات Zendesk: استخدم Zendesk API للوصول إلى جميع التذاكر وتنزيلها. تأكد من أن لديك الأذونات اللازمة ومفاتيح API للوصول إلى البيانات.
نقوم أولاً بإنشاء مفتاح Zendesk API الخاص بنا. تأكد من أنك مستخدم إداري وقم بزيارة الرابط التالي لإنشاء مفتاح API الخاص بك - https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/apis/zendesk-api/settings/tokens
قم بإنشاء مفتاح API وانسخه إلى الحافظة الخاصة بك.
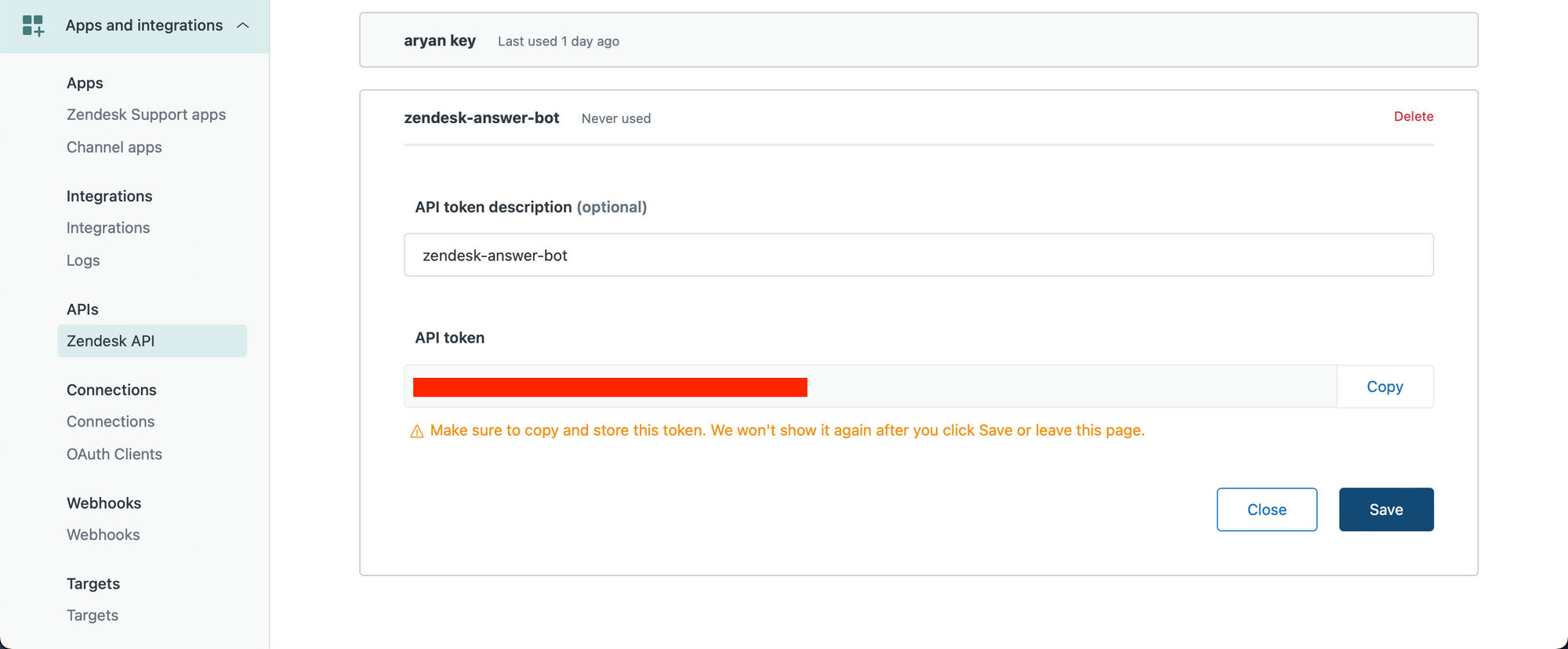
دعونا الآن نبدأ في دفتر ملاحظات بايثون.
نقوم بإدخال بيانات اعتماد Zendesk الخاصة بنا، بما في ذلك مفتاح API الذي حصلنا عليه للتو.
subdomain = YOUR_SUBDOMAIN
username = ZENDESK_USERNAME
password = ZENDESK_API_KEY
username = '{}/token'.format(username)نقوم الآن باسترداد بيانات التذاكر. في الكود أدناه، قمنا باسترداد الاستعلامات والردود من كل تذكرة، وقمنا بتخزين كل مجموعة [استعلام، مجموعة من الردود] تمثل تذكرة في مصفوفة تسمى com.ticketdata.
نحن نقوم فقط بجلب أحدث 1000 تذكرة. يمكنك تعديل هذا كما هو مطلوب.
import requests ticketdata = []
url = f"https://{subdomain}.zendesk.com/api/v2/tickets.json" params = {"sort_by": "created_at", "sort_order": "desc"} headers = {"Content-Type": "application/json"} tickettext = "" while len(ticketdata) <= 1000: response = requests.get( url, auth=(username, password), params=params, headers=headers ) tickets = response.json()["tickets"] for ticket in tickets: ticketid = ticket["id"] url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticketid}/comments.json" headers = { "Content-Type": "application/json", } response2 = requests.get(url, auth=(username, password), headers=headers) try: comments = response2.json()["comments"] except: comments = ["", ""] ticketelement = [ticketid, comments] ticketdata.append(ticketelement) if response.json()["next_page"]: url = response.json()["next_page"] else: breakكما ترون أدناه، قمنا باسترداد بيانات التذاكر من Zendesk db. كل عنصر في com.ticketdata يتضمن -
أ. معرف التذكرة
ب. جميع التعليقات / الردود في التذكرة.
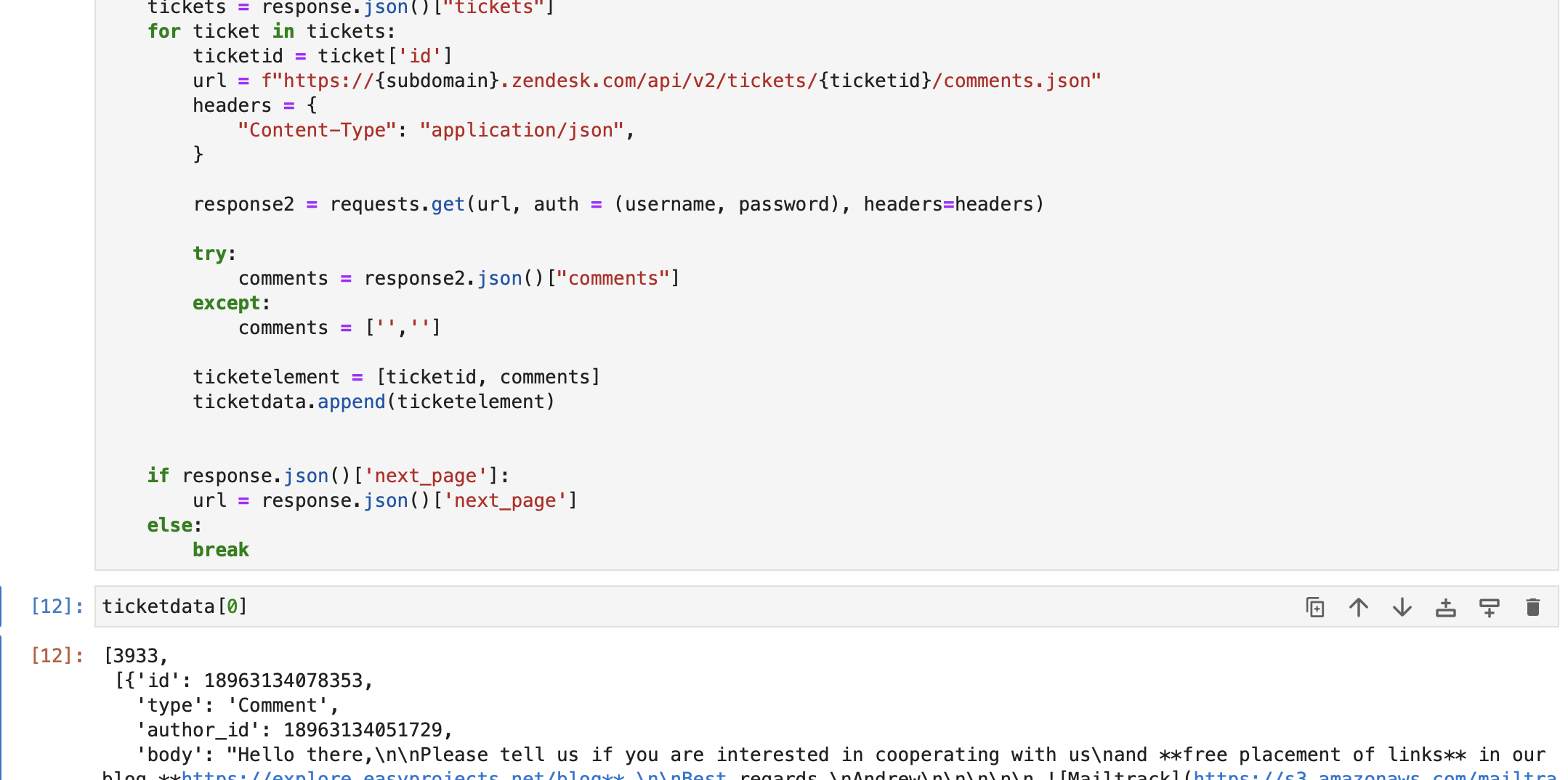
ننتقل بعد ذلك إلى إنشاء سلسلة نصية تحتوي على الاستعلامات والاستجابات الأولى من جميع التذاكر المستردة، باستخدام com.ticketdata مجموعة مصفوفة.
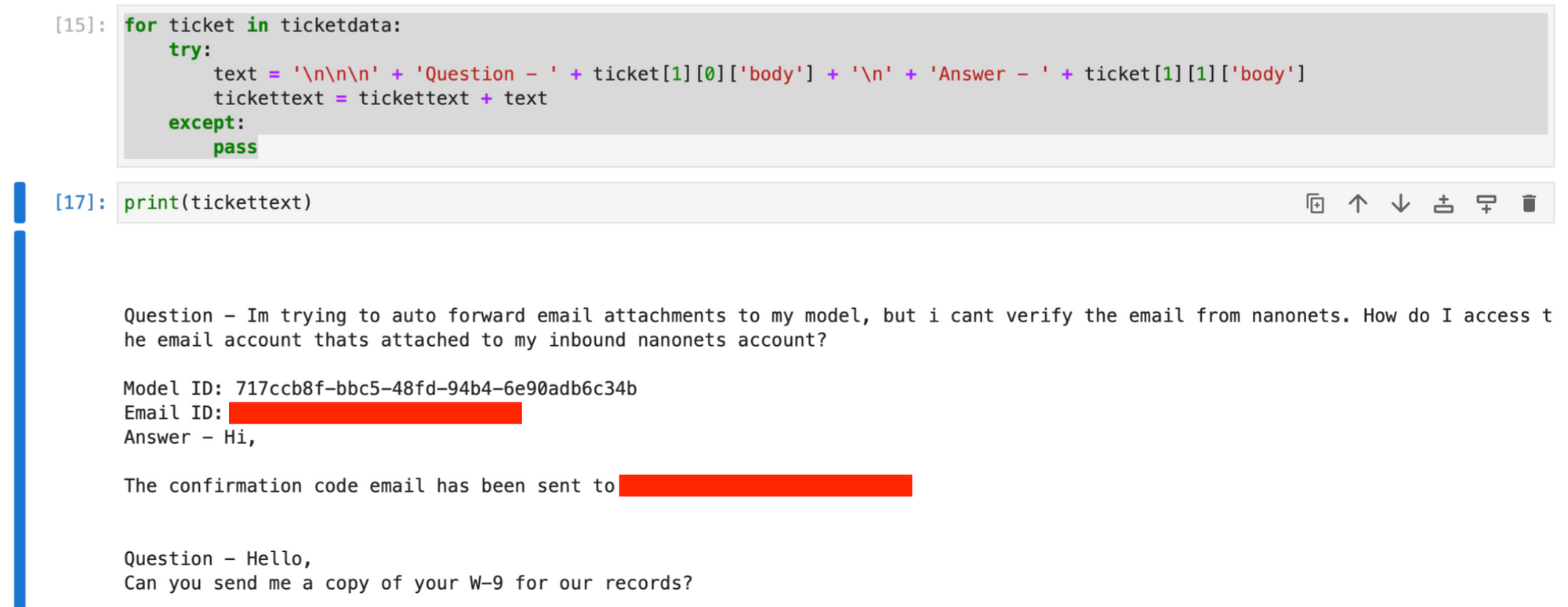
for ticket in ticketdata: try: text = ( "nnn" + "Question - " + ticket[1][0]["body"] + "n" + "Answer - " + ticket[1][1]["body"] ) tickettext = tickettext + text except: pass• Tickettext تحتوي السلسلة الآن على جميع التذاكر والإجابات الأولى، مع فصل بيانات كل تذكرة بأحرف السطر الجديد.
اختياري : يمكنك أيضًا جلب البيانات من مقالات دعم Zendesk الخاصة بك لتوسيع قاعدة المعرفة بشكل أكبر، عن طريق تشغيل الكود أدناه.
import re def remove_tags(text): clean = re.compile("<.*?>") return re.sub(clean, "", text) articletext = ""
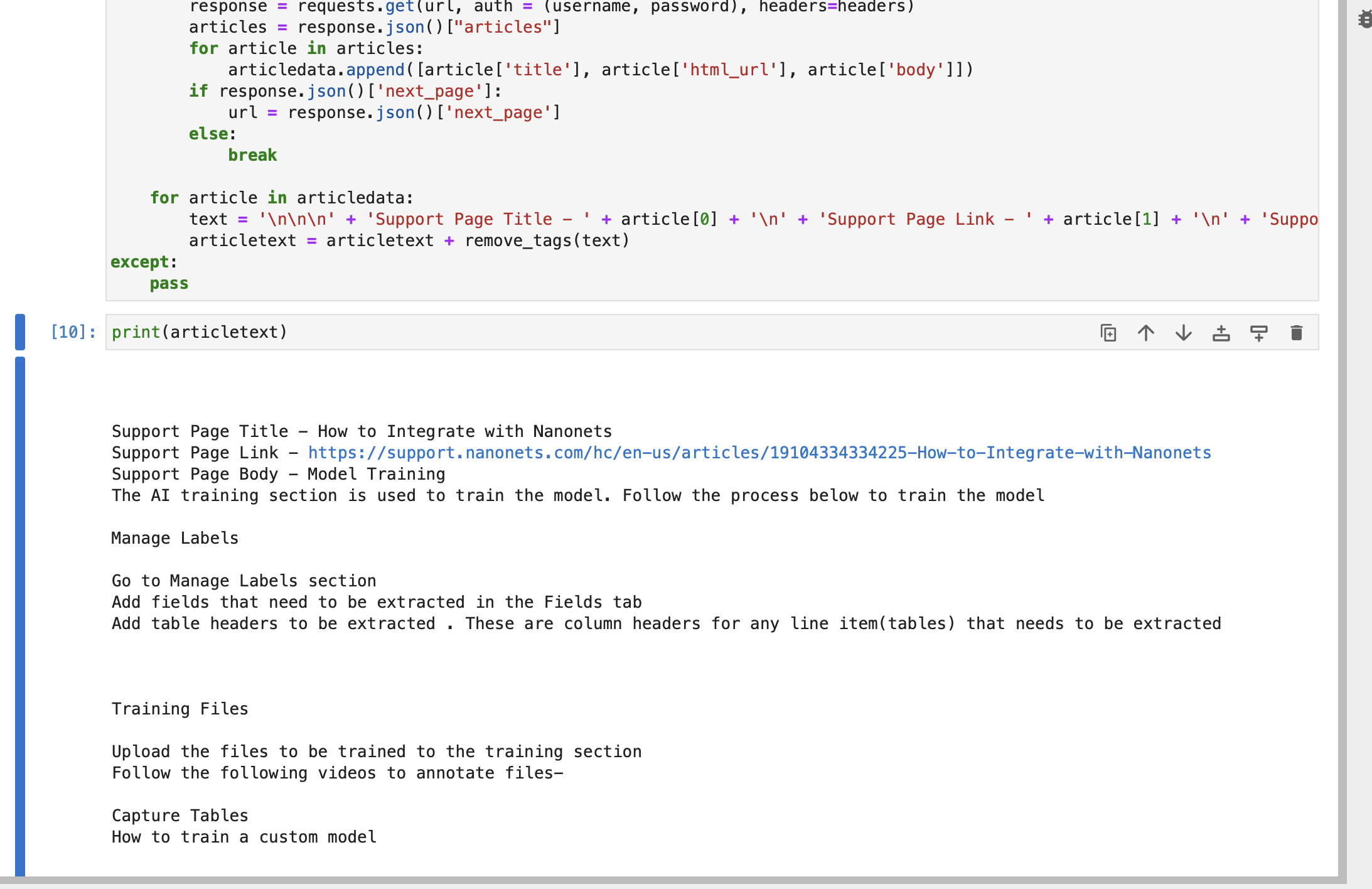
try: articledata = [] url = f"https://{subdomain}.zendesk.com/api/v2/help_center/en-us/articles.json" headers = {"Content-Type": "application/json"} while True: response = requests.get(url, auth=(username, password), headers=headers) articles = response.json()["articles"] for article in articles: articledata.append([article["title"], article["html_url"], article["body"]]) if response.json()["next_page"]: url = response.json()["next_page"] else: break for article in articledata: text = ( "nnn" + "Support Page Title - " + article[0] + "n" + "Support Page Link - " + article[1] + "n" + "Support Page Body - " + article[2] ) articletext = articletext + remove_tags(text)
except: passالسلسلة نص المادة يحتوي على عنوان ورابط ونص كل جزء من المقالة في صفحات دعم Zendesk الخاصة بك.
اختياري : يمكنك توصيل قاعدة بيانات العملاء الخاصة بك أو أي قاعدة بيانات أخرى ذات صلة، ثم استخدامها أثناء إنشاء مخزن الفهرس.
دمج البيانات التي تم جلبها.
knowledge = tickettext + "nnn" + articletext- تذاكر الفهرس: بمجرد تنزيلها، قم بفهرسة التذاكر باستخدام طريقة فهرسة مناسبة لتسهيل استرجاعها بسرعة وكفاءة.
للقيام بذلك، نقوم أولاً بتثبيت التبعيات المطلوبة لإنشاء متجر المتجهات.
pip install langchain openai pypdf faiss-cpuإنشاء مخزن فهرس باستخدام البيانات التي تم جلبها. سيكون هذا بمثابة قاعدة معرفتنا عندما نحاول الرد على التذاكر الجديدة عبر GPT.
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY" from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np tokenizer = GPT2TokenizerFast.from_pretrained("gpt2") def count_tokens(text: str) -> int: return len(tokenizer.encode(text)) text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=24, length_function=count_tokens,
) chunks = text_splitter.create_documents([knowledge]) token_counts = [count_tokens(chunk.page_content) for chunk in chunks]
df = pd.DataFrame({"Token Count": token_counts})
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(chunks, embeddings)
path = "zendesk-index"
db.save_local(path)
يتم حفظ الفهرس الخاص بك على نظامك المحلي.

- تحديث الفهرس بانتظام: قم بتحديث الفهرس بانتظام ليشمل التذاكر الجديدة وتعديلات التذاكر الحالية، مما يضمن وصول النظام إلى أحدث البيانات.
يمكننا جدولة البرنامج النصي أعلاه ليتم تشغيله كل أسبوع، وتحديث "zendesk-index" الخاص بنا أو أي تردد آخر مرغوب فيه.
كيفية إجراء الاسترداد عند وصول تذكرة جديدة
- مراقبة التذاكر الجديدة: قم بإعداد نظام لمراقبة Zendesk للتذاكر الجديدة بشكل مستمر.
سنقوم بإنشاء واجهة برمجة تطبيقات Flask الأساسية واستضافتها. للبدء،
- قم بإنشاء مجلد جديد يسمى "Zendesk Answer Bot".
- أضف مجلد FAISS db الخاص بك "zendesk-index" إلى مجلد "Zendesk Answer Bot".
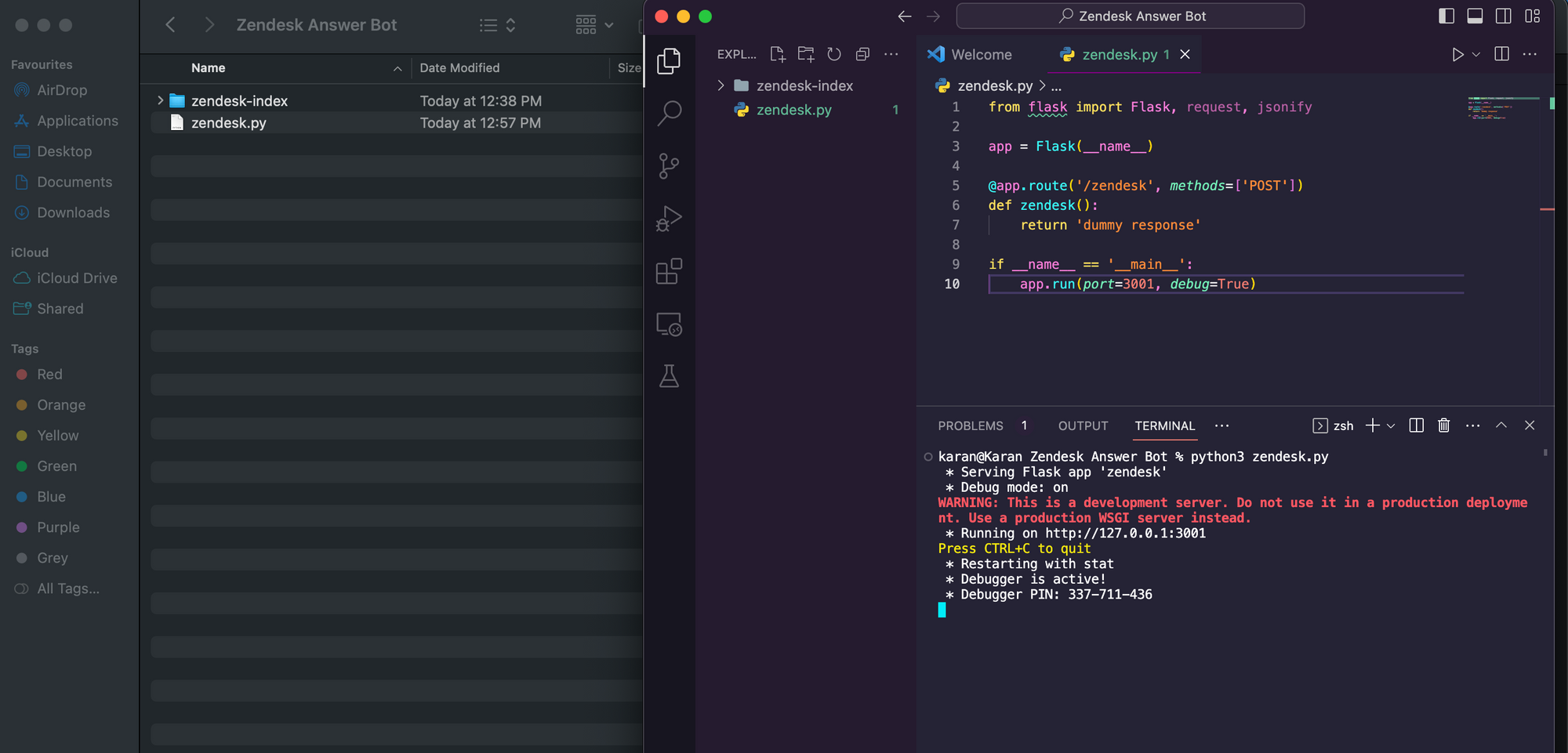
- قم بإنشاء ملف python جديد zendesk.py وانسخ الكود أدناه فيه.
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): return 'dummy response' if __name__ == '__main__': app.run(port=3001, debug=True)- قم بتشغيل كود بايثون.
- قم بتنزيل وتكوين ngrok باستخدام التعليمات هنا. تأكد من تكوين رمز المصادقة ngrok في جهازك الطرفي وفقًا لتوجيهات الرابط.
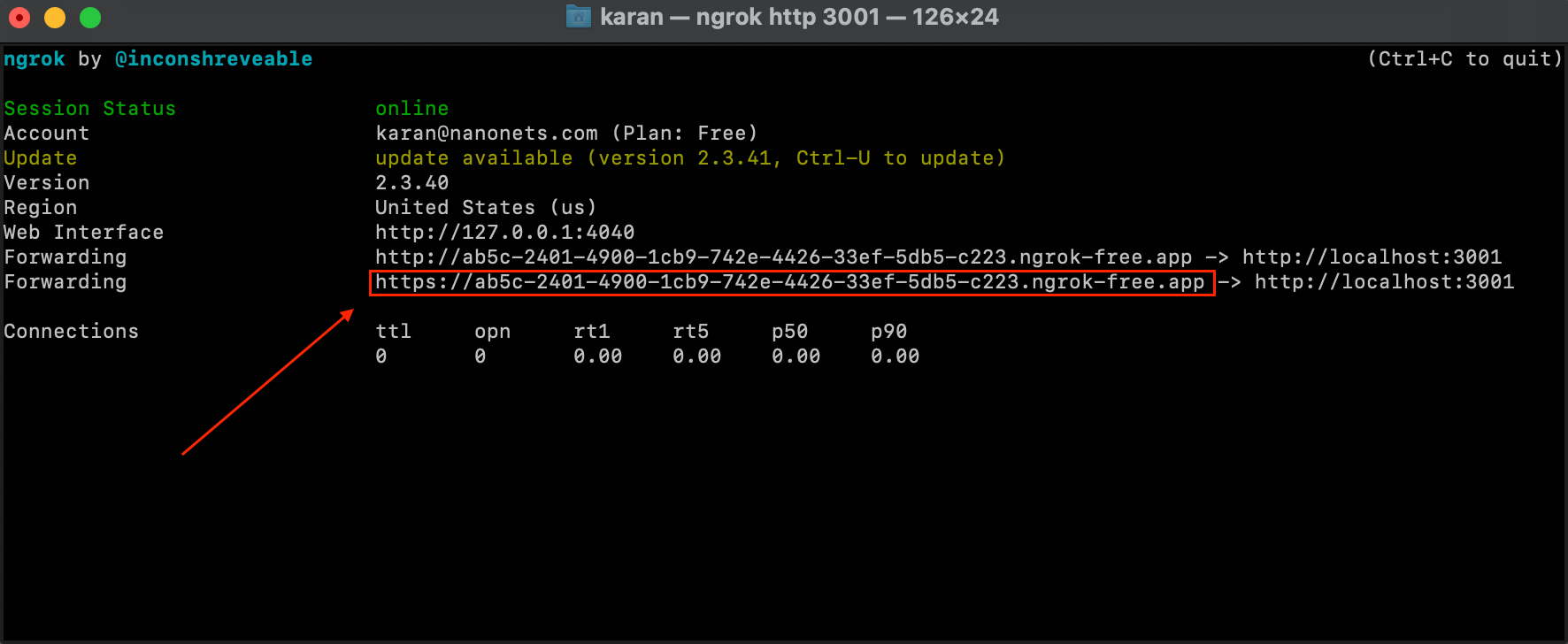
- افتح مثيلًا طرفيًا جديدًا وقم بتشغيل الأمر أدناه.
ngrok http 3001- لدينا الآن خدمة Flask الخاصة بنا مكشوفة عبر عنوان IP خارجي يمكننا من خلاله إجراء مكالمات API لخدمتنا من أي مكان.
- قمنا بعد ذلك بإعداد Zendesk Webhook، إما عن طريق زيارة الرابط التالي - https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/webhooks/webhooks أو تشغيل الكود أدناه مباشرةً في دفتر Jupyter الأصلي الخاص بنا.
ملاحظة: من المهم ملاحظة أنه على الرغم من أن استخدام ngrok يعد أمرًا جيدًا لأغراض الاختبار، إلا أنه يوصى بشدة بتحويل خدمة Flask API إلى مثيل الخادم. في هذه الحالة، يصبح عنوان IP الثابت للخادم هو نقطة نهاية Zendesk Webhook وستحتاج إلى تكوين نقطة النهاية في Zendesk Webhook للإشارة إلى هذا العنوان – https://YOUR_SERVER_STATIC_IP:3001/zendesk
zendesk_workflow_endpoint = "HTTPS_NGROK_FORWARDING_ADDRESS" url = "https://" + subdomain + ".zendesk.com/api/v2/webhooks"
payload = { "webhook": { "endpoint": zendesk_workflow_endpoint, "http_method": "POST", "name": "Nanonets Workflows Webhook v1", "status": "active", "request_format": "json", "subscriptions": ["conditional_ticket_events"], }
}
headers = {"Content-Type": "application/json"} auth = (username, password) response = requests.post(url, json=payload, headers=headers, auth=auth)
webhook = response.json() webhookid = webhook["webhook"]["id"]
- قمنا الآن بإعداد Zendesk Trigger، والذي سيؤدي إلى تشغيل خطاف الويب أعلاه الذي أنشأناه للتو للتشغيل عند ظهور تذكرة جديدة. يمكننا إعداد مشغل Zendesk إما بزيارة الرابط التالي – https://YOUR_SUBDOMAIN.zendesk.com/admin/objects-rules/rules/triggers أو عن طريق تشغيل الكود أدناه مباشرةً في دفتر Jupyter الأصلي الخاص بنا.
url = "https://" + subdomain + ".zendesk.com/api/v2/triggers.json" trigger_payload = { "trigger": { "title": "Nanonets Workflows Trigger v1", "active": True, "conditions": {"all": [{"field": "update_type", "value": "Create"}]}, "actions": [ { "field": "notification_webhook", "value": [ webhookid, json.dumps( { "ticket_id": "{{ticket.id}}", "org_id": "{{ticket.url}}", "subject": "{{ticket.title}}", "body": "{{ticket.description}}", } ), ], } ], }
} response = requests.post(url, auth=(username, password), json=trigger_payload)
trigger = response.json()
- استرجاع المعلومات ذات الصلة: عندما تأتي تذكرة جديدة، استخدم قاعدة المعرفة المفهرسة لاسترداد المعلومات ذات الصلة والتذاكر السابقة التي يمكن أن تساعد في توليد الاستجابة.
بعد إعداد المشغل وخطاف الويب، ستضمن Zendesk أن خدمة Flask التي تعمل حاليًا ستتلقى استدعاء API على مسار /zendesk مع معرف التذكرة والموضوع والنص عند وصول تذكرة جديدة.
يتعين علينا الآن تكوين خدمة Flask الخاصة بنا
أ. قم بإنشاء استجابة باستخدام متجر المتجهات الخاص بنا "zendesk-index".
ب. قم بتحديث التذكرة بالاستجابة التي تم إنشاؤها.
نقوم باستبدال رمز خدمة القارورة الحالي الخاص بنا في zendesk.py بالرمز أدناه -
from flask import Flask, request, jsonify
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson['body'] zendb = FAISS.load_local('zendesk-index', zenembeddings) docs = zendb.similarity_search(query) if __name__ == '__main__': app.run(port=3001, debug=True)كما ترون، لقد أجرينا بحثًا عن التشابه في فهرس المتجهات الخاص بنا واستخرجنا التذاكر والمقالات الأكثر صلة للمساعدة في توليد الاستجابة.
كيفية إنشاء رد ونشره على Zendesk
- توليد الاستجابة: استخدم LLM لإنشاء استجابة متماسكة ودقيقة بناءً على المعلومات المستردة والسياق الذي تم تحليله.
دعونا الآن نواصل إعداد نقطة نهاية API الخاصة بنا. نقوم أيضًا بتعديل الكود كما هو موضح أدناه لإنشاء استجابة بناءً على المعلومات ذات الصلة التي تم استردادها.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query)
• إجابة سيحتوي المتغير على الاستجابة التي تم إنشاؤها.
- استجابة المراجعة: اختياريًا، اطلب من وكيل بشري مراجعة الاستجابة التي تم إنشاؤها للتأكد من دقتها وملاءمتها قبل النشر.
الطريقة التي نضمن بها ذلك هي عدم نشر الرد الذي تم إنشاؤه بواسطة GPT مباشرة كرد Zendesk. وبدلاً من ذلك، سنقوم بإنشاء وظيفة لتحديث التذاكر الجديدة بملاحظة داخلية تحتوي على الاستجابة التي تم إنشاؤها بواسطة GPT.
أضف الوظيفة التالية إلى خدمة zendesk.py flask –
def update_ticket_with_internal_note( subdomain, ticket_id, username, password, comment_body
): url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticket_id}.json" email = username headers = {"Content-Type": "application/json"} comment_body = "Suggested Response - " + comment_body data = {"ticket": {"comment": {"body": comment_body, "public": False}}} response = requests.put(url, json=data, headers=headers, auth=(email, password))
- أرسل إلى Zendesk: استخدم Zendesk API لنشر الرد الذي تم إنشاؤه على التذكرة المقابلة، مما يضمن التواصل في الوقت المناسب مع العميل.
دعونا الآن ندمج وظيفة إنشاء الملاحظات الداخلية في نقطة نهاية واجهة برمجة التطبيقات (API) الخاصة بنا.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query) update_ticket_with_internal_note(subdomain, ticket, username, password, answer) return answer
هذا يكمل سير العمل لدينا!
دعونا نراجع سير العمل الذي قمنا بإعداده –
- يبدأ Zendesk Trigger سير العمل عند ظهور تذكرة Zendesk جديدة.
- يرسل المشغل بيانات التذكرة الجديدة إلى Webhook الخاص بنا.
- يرسل Webhook الخاص بنا طلبًا إلى خدمة Flask لدينا.
- تستعلم خدمة Flask الخاصة بنا عن مخزن المتجهات الذي تم إنشاؤه باستخدام بيانات Zendesk السابقة لاسترداد التذاكر والمقالات السابقة ذات الصلة للرد على التذكرة الجديدة.
- يتم تمرير التذاكر والمقالات السابقة ذات الصلة إلى GPT مع بيانات التذكرة الجديدة لإنشاء رد.
- يتم تحديث التذكرة الجديدة بملاحظة داخلية تحتوي على الاستجابة التي تم إنشاؤها في GPT.
يمكننا اختبار ذلك يدويًا –
- نقوم بإنشاء تذكرة على Zendesk يدويًا لاختبار التدفق.
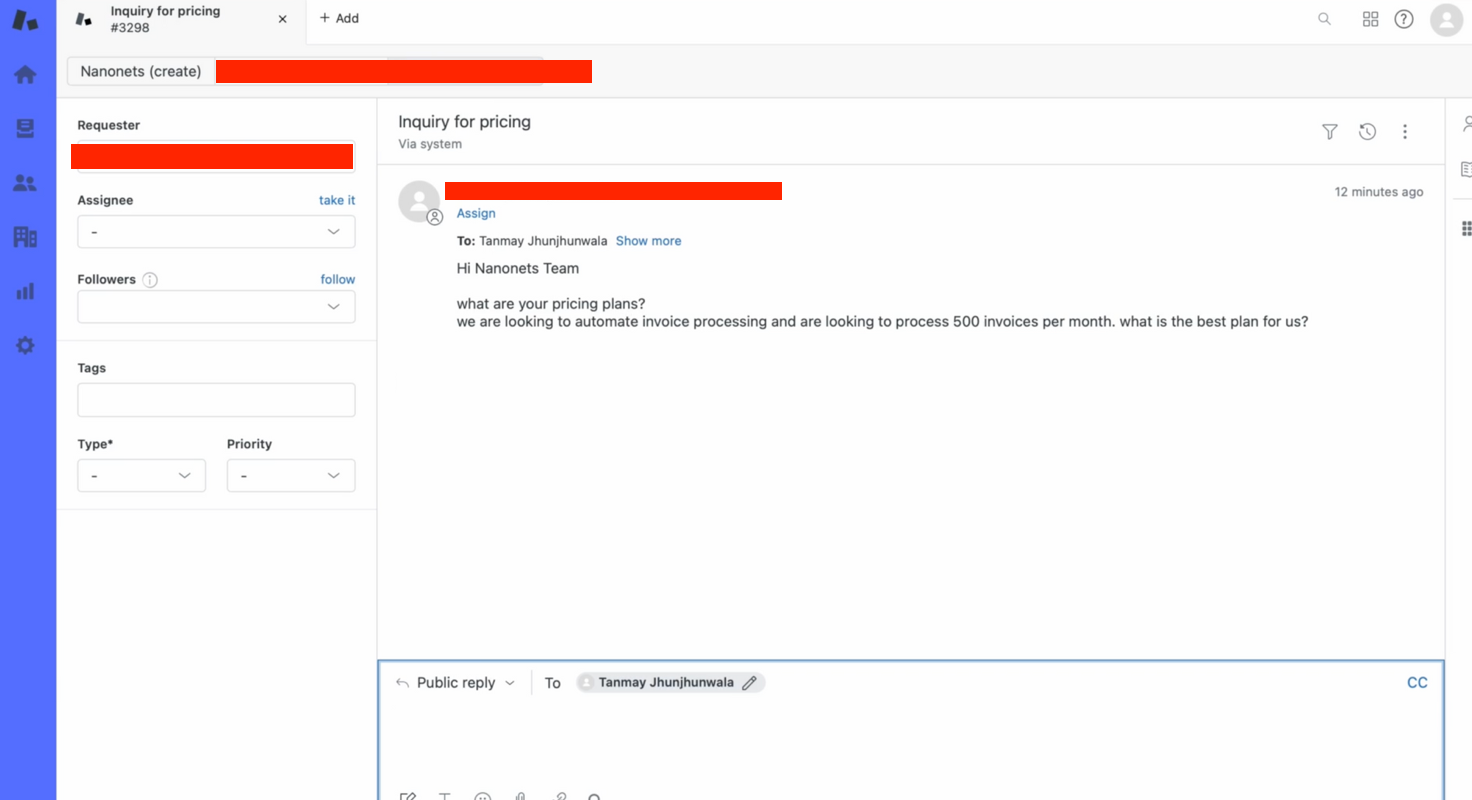
- في غضون ثوانٍ، يقدم الروبوت الخاص بنا إجابة ذات صلة لاستعلام التذاكر!

كيفية القيام بسير العمل بأكمله مع Nanonets
توفر Nanonets منصة قوية لتنفيذ وإدارة سير العمل المستند إلى RAG بسلاسة. إليك كيفية الاستفادة من شبكات النانو في سير العمل هذا:
- التكامل مع Zendesk: قم بتوصيل Nanonets مع Zendesk لمراقبة التذاكر واستردادها بكفاءة.
- بناء النماذج وتدريبها: استخدم Nanonets لبناء وتدريب LLMs لتوليد استجابات دقيقة ومتماسكة بناءً على قاعدة المعرفة والسياق الذي تم تحليله.
- الاستجابات التلقائية: قم بإعداد قواعد التشغيل الآلي في Nanonets لنشر الاستجابات التي تم إنشاؤها تلقائيًا إلى Zendesk أو إعادة توجيهها إلى وكلاء بشريين للمراجعة.
- المراقبة والتحسين: مراقبة أداء سير العمل باستمرار وتحسين النماذج والقواعد لتحسين الدقة والكفاءة.
من خلال دمج LLMs مع سير العمل القائم على RAG في GenAI والاستفادة من قدرات Nanonets، يمكن للشركات تعزيز عمليات دعم العملاء بشكل كبير، وتوفير استجابات سريعة ودقيقة لاستفسارات العملاء على Zendesk.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://nanonets.com/blog/build-your-own-zendesk-answer-bot-with-llms/

