جدول المحتويات
في هذه المقالة، سنتعرف على كيفية ذلك اكتشاف الوجوه في الوقت الحقيقي باستخدام OpenCV. بعد اكتشاف الوجه من تدفق كاميرا الويب، سنقوم بحفظ الإطارات التي تحتوي على الوجه. سنقوم لاحقًا بتمرير هذه الإطارات (الصور) إلى مُصنف كاشف القناع الخاص بنا لمعرفة ما إذا كان الشخص يرتدي قناعًا أم لا.
سنرى أيضًا كيفية إنشاء كاشف قناع مخصص باستخدام Tensorflow و Keras ولكن يمكنك تخطي ذلك حيث سأقوم بإرفاق ملف النموذج المدرب أدناه والذي يمكنك تنزيله واستخدامه. فيما يلي قائمة بالمواضيع الفرعية التي سنغطيها:
- ما هو كشف الوجه؟
- طرق الكشف عن الوجه
- خوارزمية الكشف عن الوجه
- التعرف على الوجوه
- كشف الوجه باستخدام بايثون
- كشف الوجه باستخدام OpenCV
- إنشاء نموذج للتعرف على الوجوه التي ترتدي قناعًا (اختياري)
- كيفية القيام بالكشف عن القناع في الوقت الحقيقي
ابحث عن هو كشف الوجه؟
الهدف من اكتشاف الوجه هو تحديد ما إذا كان هناك أي وجوه في الصورة أو الفيديو. في حالة وجود وجوه متعددة، يتم إحاطة كل وجه بمربع محيط وبالتالي نعرف موقع الوجوه
الهدف الأساسي لخوارزميات اكتشاف الوجه هو تحديد وجود الوجوه وموضعها في الصورة أو الفيديو بدقة وكفاءة. وتقوم الخوارزميات بتحليل المحتوى المرئي للبيانات، والبحث عن الأنماط والميزات التي تتوافق مع خصائص الوجه. من خلال استخدام تقنيات مختلفة، مثل التعلم الآلي، ومعالجة الصور، والتعرف على الأنماط، تهدف خوارزميات اكتشاف الوجه إلى تمييز الوجوه عن الكائنات الأخرى أو عناصر الخلفية داخل البيانات المرئية.
يصعب نمذجة الوجوه البشرية نظرًا لوجود العديد من المتغيرات التي يمكن أن تتغير، على سبيل المثال تعبيرات الوجه، والاتجاه، وظروف الإضاءة، والإطباق الجزئي مثل النظارات الشمسية، والأوشحة، والأقنعة، وما إلى ذلك. وتعطي نتيجة الكشف معلمات موقع الوجه ويمكنها تكون مطلوبة بأشكال مختلفة، على سبيل المثال، مستطيل يغطي الجزء الأوسط من الوجه أو مراكز العين أو المعالم بما في ذلك العيون وزوايا الأنف والفم والحاجبين وفتحتي الأنف وما إلى ذلك.
طرق الكشف عن الوجه
هناك طريقتان رئيسيتان لاكتشاف الوجه:
- ميزة النهج الأساسي
- نهج قاعدة الصورة
ميزة النهج الأساسي
عادة ما يتم التعرف على الكائنات من خلال ميزاتها الفريدة. هناك العديد من الميزات في وجه الإنسان، والتي يمكن التعرف عليها بين الوجه والعديد من الأشياء الأخرى. فهو يحدد موقع الوجوه عن طريق استخراج السمات الهيكلية مثل العينين والأنف والفم وما إلى ذلك ثم يستخدمها للكشف عن الوجه. عادةً ما يكون هناك نوع من المصنف الإحصائي المؤهل ومن ثم يساعد في الفصل بين مناطق الوجه وغير الوجه. بالإضافة إلى ذلك، تمتلك الوجوه البشرية نسيجًا خاصًا يمكن استخدامه للتمييز بين الوجه والأشياء الأخرى. علاوة على ذلك، يمكن أن تساعد حافة الميزات في اكتشاف الأشياء من الوجه. في القسم التالي، سنقوم بتنفيذ نهج قائم على الميزات باستخدام البرنامج التعليمي OpenCV.
نهج قاعدة الصورة
بشكل عام، تعتمد الأساليب القائمة على الصور على تقنيات من التحليل الإحصائي والتعلم الآلي للعثور على الخصائص ذات الصلة لصور الوجه وغير الوجه. الخصائص المستفادة تكون في شكل نماذج توزيع أو وظائف تمييزية يتم استخدامها بالتالي للكشف عن الوجه. في هذه الطريقة، نستخدم خوارزميات مختلفة مثل الشبكات العصبية، HMM، SVM, التعلم AdaBoost. في القسم التالي، سنرى كيف يمكننا اكتشاف الوجوه باستخدام MTCNN أو Multi-Task Cascaded Convolutional الشبكة العصبية، وهو نهج قائم على الصور للكشف عن الوجه
خوارزمية الكشف عن الوجه
إحدى الخوارزميات الشائعة التي تستخدم النهج القائم على الميزات هي خوارزمية فيولا جونز وهنا سأناقشه بإيجاز. إذا كنت تريد معرفة ذلك بالتفصيل، أقترح عليك الاطلاع على هذه المقالة، اكتشاف الوجه باستخدام خوارزمية فيولا جونز.
فيولا جونز تمت تسمية الخوارزمية على اسم اثنين من الباحثين في مجال الرؤية الحاسوبية الذين اقترحوا هذه الطريقة في عام 2001، وهما بول كمان متوسط ومايكل جونز في ورقتهم البحثية، "الاكتشاف السريع للأشياء باستخدام سلسلة معززة من الميزات البسيطة". على الرغم من كونه إطارًا قديمًا، إلا أن Viola-Jones قوي جدًا، وقد أثبت تطبيقه أنه ملحوظ بشكل استثنائي في اكتشاف الوجه في الوقت الفعلي. هذه الخوارزمية بطيئة للغاية في التدريب، لكنها تستطيع اكتشاف الوجوه في الوقت الفعلي بسرعة مذهلة.
بالنظر إلى صورة (تعمل هذه الخوارزمية على صور ذات تدرج رمادي)، تبحث الخوارزمية في العديد من المناطق الفرعية الأصغر وتحاول العثور على وجه من خلال البحث عن ميزات محددة في كل منطقة فرعية. يجب التحقق من العديد من المواضع والمقاييس المختلفة لأن الصورة يمكن أن تحتوي على العديد من الوجوه بأحجام مختلفة. استخدمت فيولا وجونز ميزات تشبه هار لاكتشاف الوجوه في هذه الخوارزمية.
التعرف على الوجه
غالبًا ما يتم استخدام اكتشاف الوجه والتعرف على الوجه بالتبادل، لكنهما مختلفان تمامًا. في الواقع، يعد اكتشاف الوجه مجرد جزء من التعرف على الوجه.
التعرف على الوجه هو وسيلة لتحديد هوية الفرد أو التحقق منها باستخدام وجهه. هناك العديد من الخوارزميات التي يمكنها التعرف على الوجوه ولكن دقتها قد تختلف. سأقوم هنا بوصف كيفية التعرف على الوجوه باستخدام التعلم العميق.
في الواقع، إليك مقالة بعنوان Face Recognition Python والتي توضح كيفية تنفيذ ميزة التعرف على الوجه.
كشف الوجه باستخدام بايثون
كما ذكرنا من قبل، سنرى هنا كيف يمكننا اكتشاف الوجوه باستخدام نهج قائم على الصور. تعد MTCNN أو الشبكة العصبية التلافيفية المتتالية متعددة المهام بلا شك واحدة من أكثر أدوات الكشف عن الوجه شيوعًا وأكثرها دقة والتي تعمل بهذا المبدأ. وعلى هذا النحو، فهو يعتمد على أ التعلم العميق الهندسة المعمارية، وتتكون على وجه التحديد من 3 شبكات عصبية (P-Net، وR-Net، وO-Net) متصلة في سلسلة.
لذلك، دعونا نرى كيف يمكننا استخدام هذه الخوارزمية في بايثون للكشف عن الوجوه في الوقت الحقيقي. أولاً، تحتاج إلى تثبيت مكتبة MTCNN التي تحتوي على نموذج مدرب يمكنه اكتشاف الوجوه.
pip install mtcnnالآن دعونا نرى كيفية استخدام MTCNN:
from mtcnn import MTCNN
import cv2
detector = MTCNN()
#Load a videopip TensorFlow
video_capture = cv2.VideoCapture(0) while (True): ret, frame = video_capture.read() frame = cv2.resize(frame, (600, 400)) boxes = detector.detect_faces(frame) if boxes: box = boxes[0]['box'] conf = boxes[0]['confidence'] x, y, w, h = box[0], box[1], box[2], box[3] if conf > 0.5: cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 255), 1) cv2.imshow("Frame", frame) if cv2.waitKey(25) & 0xFF == ord('q'): break video_capture.release()
cv2.destroyAllWindows()
كشف الوجه باستخدام OpenCV
في هذا القسم، سنقوم بتنفيذ العمل في الوقت الفعلي كشف الوجه باستخدام OpenCV من البث المباشر عبر كاميرا الويب الخاصة بنا.
كما تعلم، تتكون مقاطع الفيديو أساسًا من إطارات، وهي صور ثابتة. نقوم بإجراء اكتشاف الوجه لكل إطار في الفيديو. لذا، عندما يتعلق الأمر باكتشاف وجه في صورة ثابتة واكتشاف وجه في دفق فيديو في الوقت الفعلي، فلا يوجد فرق كبير بينهما.
سنستخدم خوارزمية Haar Cascade، المعروفة أيضًا باسم خوارزمية Voila-Jones لاكتشاف الوجوه. إنها في الأساس خوارزمية اكتشاف كائنات التعلم الآلي التي يتم استخدامها لتحديد الكائنات في الصورة أو الفيديو. في OpenCV، لدينا العديد من نماذج Haar Cascade المدربة والتي يتم حفظها كملفات XML. بدلاً من إنشاء النموذج وتدريبه من الصفر، نستخدم هذا الملف. سنستخدم ملف "haarcascade_frontalface_alt2.xml" في هذا المشروع. الآن دعونا نبدأ في ترميز هذا الأمر
الخطوة الأولى هي العثور على المسار إلى ملف "haarcascade_frontalface_alt2.xml". نقوم بذلك باستخدام وحدة نظام التشغيل في لغة بايثون.
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"الخطوة التالية هي تحميل المصنف الخاص بنا. يذهب المسار إلى ملف XML أعلاه كوسيطة لأسلوب CascadeClassifier() الخاص بـ OpenCV.
faceCascade = cv2.CascadeClassifier(cascPath)بعد تحميل المصنف، دعونا نفتح كاميرا الويب باستخدام رمز OpenCV البسيط هذا
video_capture = cv2.VideoCapture(0)بعد ذلك، نحتاج إلى الحصول على الإطارات من دفق كاميرا الويب، ونقوم بذلك باستخدام وظيفة القراءة (). نستخدمها في حلقة لا نهائية للحصول على جميع الإطارات حتى الوقت الذي نريد فيه إغلاق الدفق.
while True: # Capture frame-by-frame ret, frame = video_capture.read()تقوم الدالة read() بإرجاع:
- قراءة إطار الفيديو الفعلي (إطار واحد في كل حلقة)
- رمز العودة
يخبرنا رمز الإرجاع إذا نفدت الإطارات لدينا، وهو ما سيحدث إذا كنا نقرأ من ملف. هذا لا يهم عند القراءة من كاميرا الويب حيث يمكننا التسجيل إلى الأبد، لذلك سوف نتجاهل ذلك.
لكي يعمل هذا المصنف المحدد، نحتاج إلى تحويل الإطار إلى تدرج رمادي.
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)يحتوي كائنfaceCascade على طريقة DetectMultiScale()، التي تستقبل إطارًا (صورة) كوسيطة وتقوم بتشغيل سلسلة المصنفات فوق الصورة. يشير مصطلح MultiScale إلى أن الخوارزمية تنظر إلى المناطق الفرعية من الصورة بمقاييس متعددة لاكتشاف الوجوه ذات الأحجام المختلفة.
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)دعنا نذهب من خلال هذه الحجج لهذه الوظيفة:
- ScaleFactor - معلمة تحدد مقدار تقليل حجم الصورة عند كل مقياس صورة. من خلال إعادة قياس الصورة المدخلة، يمكنك تغيير حجم الوجه الأكبر إلى وجه أصغر، مما يجعله قابلاً للاكتشاف بواسطة الخوارزمية. 1.05 هي قيمة محتملة جيدة لذلك، مما يعني أنك تستخدم خطوة صغيرة لتغيير الحجم، أي تقليل الحجم بنسبة 5%، مما يزيد من فرصة العثور على حجم مطابق للنموذج المراد اكتشافه.
- minNeighbors - معلمة تحدد عدد الجيران الذي يجب أن يحتفظ به كل مستطيل مرشح. ستؤثر هذه المعلمة على جودة الوجوه المكتشفة. تؤدي القيمة الأعلى إلى عدد أقل من الاكتشافات ولكن بجودة أعلى. 3~6 قيمة جيدة بالنسبة له.
- الأعلام – طريقة التشغيل
- minSize - الحد الأدنى لحجم الكائن الممكن. يتم تجاهل الكائنات الأصغر من ذلك.
تحتوي الوجوه المتغيرة الآن على كافة الاكتشافات الخاصة بالصورة المستهدفة. يتم حفظ الاكتشافات كإحداثيات بكسل. يتم تعريف كل اكتشاف من خلال إحداثيات الزاوية العلوية اليسرى وعرض المستطيل الذي يشمل الوجه المكتشف وارتفاعه.
لإظهار الوجه المكتشف، سنرسم مستطيلًا فوقه. يرسم مستطيل OpenCV () مستطيلات فوق الصور، ويحتاج إلى معرفة إحداثيات البكسل للزوايا العلوية اليسرى والسفلى اليمنى. تشير الإحداثيات إلى صف وعمود البكسل في الصورة. يمكننا بسهولة الحصول على هذه الإحداثيات من الوجه المتغير.
for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2)المستطيل() يقبل الوسائط التالية:
- الصورة الأصلية
- إحداثيات النقطة العلوية اليسرى للكشف
- إحداثيات النقطة السفلية اليمنى للاكتشاف
- لون المستطيل (صف يحدد مقدار اللون الأحمر والأخضر والأزرق (0-255)). في حالتنا، قمنا بتعيين اللون الأخضر فقط مع الحفاظ على المكون الأخضر عند 255 والباقي على الصفر.
- سمك الخطوط المستطيلة
بعد ذلك، نقوم فقط بعرض الإطار الناتج ونحدد أيضًا طريقة للخروج من هذه الحلقة اللانهائية وإغلاق بث الفيديو. بالضغط على المفتاح "q"، يمكننا الخروج من البرنامج النصي هنا
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakالسطران التاليان مخصصان فقط لتنظيف الصورة وتحريرها.
video_capture.release()
cv2.destroyAllWindows()فيما يلي الكود والإخراج الكامل.
import cv2
import os
cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) for (x,y,w,h) in faces: cv2.rectangle(frame, (x, y), (x + w, y + h),(0,255,0), 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
الإخراج:
إنشاء نموذج للتعرف على الوجوه التي ترتدي قناعًا
في هذا القسم، سنقوم بإنشاء مصنف يمكنه التمييز بين الوجوه ذات الأقنعة وتلك التي لا تحتوي على أقنعة. في حالة رغبتك في تخطي هذا الجزء، فإليك أ الصفحة لتحميل النموذج المدرّب مسبقاً. احفظه وانتقل إلى القسم التالي لمعرفة كيفية استخدامه للكشف عن الأقنعة باستخدام OpenCV. تحقق من مجموعتنا من دورات OpenCV لمساعدتك على تطوير مهاراتك وفهم أفضل.
لذلك، لإنشاء هذا المصنف، نحتاج إلى بيانات في شكل صور. لحسن الحظ، لدينا مجموعة بيانات تحتوي على صور وجوه بقناع وبدون قناع. نظرًا لأن عدد هذه الصور أقل جدًا، فلا يمكننا تدريب الشبكة العصبية من الصفر. وبدلاً من ذلك، قمنا بضبط شبكة مدربة مسبقًا تسمى MobileNetV2 والتي تم تدريبها على مجموعة بيانات Imagenet.
دعونا أولاً نستورد جميع المكتبات الضرورية التي سنحتاجها.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import osالخطوة التالية هي قراءة جميع الصور وتخصيصها لبعض القائمة. نحصل هنا على جميع المسارات المرتبطة بهذه الصور ثم نقوم بتسميتها وفقًا لذلك. تذكر أن مجموعة البيانات الخاصة بنا موجودة في مجلدين، وهما with_masks وwithout_masks. حتى نتمكن من الحصول على التصنيفات بسهولة عن طريق استخراج اسم المجلد من المسار. نقوم أيضًا بمعالجة الصورة مسبقًا وتغيير حجمها إلى أبعاد 224 × 224.
imagePaths = list(paths.list_images('/content/drive/My Drive/dataset'))
data = []
labels = []
# loop over the image paths
for imagePath in imagePaths: # extract the class label from the filename label = imagePath.split(os.path.sep)[-2] # load the input image (224x224) and preprocess it image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) # update the data and labels lists, respectively data.append(image) labels.append(label)
# convert the data and labels to NumPy arrays
data = np.array(data, dtype="float32")
labels = np.array(labels)الخطوة التالية هي تحميل النموذج المُدرب مسبقًا وتخصيصه وفقًا لمشكلتنا. لذلك نقوم فقط بإزالة الطبقات العليا من هذا النموذج المُدرب مسبقًا وإضافة طبقات قليلة خاصة بنا. كما ترون، تحتوي الطبقة الأخيرة على عقدتين حيث أن لدينا مخرجين فقط. وهذا ما يسمى نقل التعلم.
baseModel = MobileNetV2(weights="imagenet", include_top=False, input_shape=(224, 224, 3))
# construct the head of the model that will be placed on top of the
# the base model
headModel = baseModel.output
headModel = AveragePooling2D(pool_size=(7, 7))(headModel)
headModel = Flatten(name="flatten")(headModel)
headModel = Dense(128, activation="relu")(headModel)
headModel = Dropout(0.5)(headModel)
headModel = Dense(2, activation="softmax")(headModel) # place the head FC model on top of the base model (this will become
# the actual model we will train)
model = Model(inputs=baseModel.input, outputs=headModel)
# loop over all layers in the base model and freeze them so they will
# *not* be updated during the first training process
for layer in baseModel.layers: layer.trainable = Falseنحن الآن بحاجة إلى تحويل التسميات إلى ترميز واحد ساخن. بعد ذلك، قمنا بتقسيم البيانات إلى مجموعات تدريب واختبار لتقييمها. كما أن الخطوة التالية هي زيادة البيانات مما يزيد بشكل كبير من تنوع البيانات المتاحة لنماذج التدريب، دون جمع بيانات جديدة فعليًا. تُستخدم تقنيات زيادة البيانات مثل الاقتصاص والتدوير والقص والقلب الأفقي بشكل شائع لتدريب الشبكات العصبية الكبيرة.
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
# partition the data into training and testing splits using 80% of
# the data for training and the remaining 20% for testing
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
aug = ImageDataGenerator( rotation_range=20, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest")والخطوة التالية هي تجميع النموذج وتدريبه على البيانات المعززة.
INIT_LR = 1e-4
EPOCHS = 20
BS = 32
print("[INFO] compiling model...")
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"])
# train the head of the network
print("[INFO] training head...")
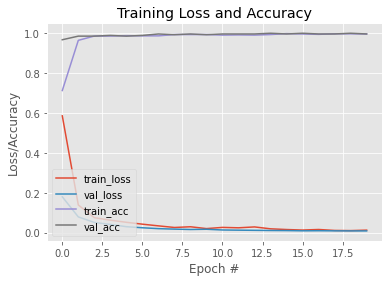
H = model.fit( aug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS)الآن بعد أن تم تدريب نموذجنا، دعونا نرسم رسمًا بيانيًا لرؤية منحنى التعلم الخاص به. كما نقوم بحفظ النموذج لاستخدامه لاحقًا. هنا أ الصفحة لهذا النموذج المدرب.
N = EPOCHS
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")الإخراج:
#To save the trained model
model.save('mask_recog_ver2.h5')كيفية القيام بالكشف عن القناع في الوقت الحقيقي
قبل الانتقال إلى الجزء التالي، تأكد من تنزيل النموذج أعلاه من هذا الصفحة وضعه في نفس المجلد الذي يحتوي على برنامج python النصي الذي ستكتب فيه الكود أدناه.
الآن بعد أن تم تدريب نموذجنا، يمكننا تعديل الكود في القسم الأول حتى يتمكن من اكتشاف الوجوه ويخبرنا أيضًا ما إذا كان الشخص يرتدي قناعًا أم لا.
لكي يعمل نموذج كاشف القناع الخاص بنا، فإنه يحتاج إلى صور للوجوه. لهذا، سوف نقوم باكتشاف الإطارات ذات الوجوه باستخدام الطرق الموضحة في القسم الأول ثم تمريرها إلى نموذجنا بعد معالجتها مسبقًا. لذلك دعونا أولاً نستورد جميع المكتبات التي نحتاجها.
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as npالأسطر القليلة الأولى هي بالضبط نفس القسم الأول. الشيء الوحيد المختلف هو أننا قمنا بتخصيص نموذج كاشف القناع المُدرب مسبقًا للنموذج المتغير.
ascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE)بعد ذلك، نحدد بعض القوائم. تحتوي قائمة faces_list على جميع الوجوه التي تم اكتشافها بواسطة نموذج FaceCascade ويتم استخدام القائمة المسبقة لتخزين التنبؤات التي أجراها نموذج كاشف القناع.
faces_list=[]
preds=[]نظرًا لأن متغير الوجوه يحتوي أيضًا على إحداثيات الزاوية العلوية اليسرى وارتفاع وعرض المستطيل الذي يشمل الوجوه، فيمكننا استخدام ذلك للحصول على إطار للوجه ثم معالجة ذلك الإطار مسبقًا بحيث يمكن إدخاله في النموذج للتنبؤ . خطوات المعالجة المسبقة هي نفسها التي يتم اتباعها عند تدريب النموذج في القسم الثاني. على سبيل المثال، تم تدريب النموذج على صور RGB لذلك نقوم بتحويل الصورة إلى RGB هنا
for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: #mask contain probabily of wearing a mask and vice versa (mask, withoutMask) = pred بعد الحصول على التوقعات نرسم مستطيلاً على الوجه ونضع علامة حسب التوقعات.
label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2)باقي الخطوات هي نفس القسم الأول.
cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()إليك الكود والإخراج الكامل:
import cv2
import os
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
import numpy as np cascPath = os.path.dirname( cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
model = load_model("mask_recog1.h5") video_capture = cv2.VideoCapture(0)
while True: # Capture frame-by-frame ret, frame = video_capture.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(60, 60), flags=cv2.CASCADE_SCALE_IMAGE) faces_list=[] preds=[] for (x, y, w, h) in faces: face_frame = frame[y:y+h,x:x+w] face_frame = cv2.cvtColor(face_frame, cv2.COLOR_BGR2RGB) face_frame = cv2.resize(face_frame, (224, 224)) face_frame = img_to_array(face_frame) face_frame = np.expand_dims(face_frame, axis=0) face_frame = preprocess_input(face_frame) faces_list.append(face_frame) if len(faces_list)>0: preds = model.predict(faces_list) for pred in preds: (mask, withoutMask) = pred label = "Mask" if mask > withoutMask else "No Mask" color = (0, 255, 0) if label == "Mask" else (0, 0, 255) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (x, y- 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (x, y), (x + w, y + h),color, 2) # Display the resulting frame cv2.imshow('Video', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
video_capture.release()
cv2.destroyAllWindows()
الإخراج:
يقودنا هذا إلى نهاية هذه المقالة حيث تعلمنا كيفية اكتشاف الوجوه في الوقت الفعلي وقمنا أيضًا بتصميم نموذج يمكنه اكتشاف الوجوه باستخدام الأقنعة. باستخدام هذا النموذج، تمكنا من تعديل كاشف الوجه ليتحول إلى كاشف قناع.
تحديث: لقد قمت بتدريب نموذج آخر يمكنه تصنيف الصور إلى ارتداء قناع، وعدم ارتداء قناع، وعدم ارتداء قناع بشكل صحيح. هنا رابط لل دفتر Kaggle من هذا النموذج. يمكنك تعديله وكذلك تنزيل النموذج من هناك واستخدامه بدلاً من النموذج الذي قمنا بتدريبه في هذه المقالة. على الرغم من أن هذا النموذج ليس بنفس كفاءة النموذج الذي قمنا بتدريبه هنا، إلا أنه يحتوي على ميزة إضافية تتمثل في اكتشاف الأقنعة التي لا يتم ارتداؤها بشكل صحيح.
إذا كنت تستخدم هذا النموذج، فستحتاج إلى إجراء بعض التغييرات الطفيفة على الكود. استبدل الأسطر السابقة بهذه الأسطر.
#Here are some minor changes in opencv code
for (box, pred) in zip(locs, preds): # unpack the bounding box and predictions (startX, startY, endX, endY) = box (mask, withoutMask,notproper) = pred # determine the class label and color we'll use to draw # the bounding box and text if (mask > withoutMask and mask>notproper): label = "Without Mask" elif ( withoutMask > notproper and withoutMask > mask): label = "Mask" else: label = "Wear Mask Properly" if label == "Mask": color = (0, 255, 0) elif label=="Without Mask": color = (0, 0, 255) else: color = (255, 140, 0) # include the probability in the label label = "{}: {:.2f}%".format(label, max(mask, withoutMask, notproper) * 100) # display the label and bounding box rectangle on the output # frame cv2.putText(frame, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)يمكنك أيضًا تحسين مهاراتك من خلال التعلم الرائع دورة الذكاء الاصطناعي وتعلم الآلة PGP. تقدم الدورة الإرشاد من قادة الصناعة، وستتاح لك أيضًا الفرصة للعمل في مشاريع ذات صلة بالصناعة في الوقت الفعلي.
لمزيد من القراءة
- اكتشاف الكائن في الوقت الفعلي باستخدام TensorFlow
- اكتشاف كائن YOLO باستخدام OpenCV
- الكشف عن الكائنات في Pytorch | ما هو كشف الكائنات؟
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- تمويل EVM. واجهة موحدة للتمويل اللامركزي. الوصول هنا.
- مجموعة كوانتوم ميديا. تضخيم IR / PR. الوصول هنا.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.mygreatlearning.com/blog/real-time-face-detection/

