بدافع أمازون EMR 6.15، أطلقنا تكوين بحيرة AWS تعتمد على عناصر التحكم في الوصول الدقيقة (FGAC) على تنسيقات الطاولة المفتوحة (OTFs)، بما في ذلك Apache Hudi وApache Iceberg وDelta Lake. وهذا يسمح لك بتبسيط الأمن والحوكمة بحيرات بيانات المعاملات من خلال توفير عناصر التحكم في الوصول على أذونات على مستوى الجدول والعمود والصف مع وظائف Apache Spark. تسعى العديد من شركات المؤسسات الكبيرة إلى استخدام بحيرة بيانات المعاملات الخاصة بها للحصول على رؤى وتحسين عملية صنع القرار. يمكنك إنشاء تصميم معماري لمنزل على البحيرة باستخدام Amazon EMR المتكامل مع Lake Formation لـ FGAC. يتيح لك هذا المزيج من الخدمات إجراء تحليل البيانات في بحيرة بيانات المعاملات الخاصة بك مع ضمان الوصول الآمن والمتحكم فيه.
يدعم مكون خادم سجل Amazon EMR وظيفة تصفية البيانات على مستوى الجدول والعمود والصف والخلية والمتداخلة. وهو يقدم الدعم لتنسيقات Hive وApache Hudi وApache Iceberg وDelta Lake لكل من عمليات القراءة (بما في ذلك السفر عبر الزمن والاستعلام المتزايد) وعمليات الكتابة (على عبارات DML مثل INSERT). بالإضافة إلى ذلك، مع الإصدار 6.15، تقدم Amazon EMR حماية التحكم في الوصول لواجهة الويب الخاصة بالتطبيقات مثل Spark History Server الموجود على المجموعة، وYarn Timeline Server، وYarn Resource Manager UI.
في هذا المنشور، نوضح كيفية تنفيذ FGAC اباتشي هودي الجداول باستخدام Amazon EMR المتكاملة مع Lake Formation.
حالة استخدام بحيرة بيانات المعاملات
غالبًا ما يستخدم عملاء Amazon EMR تنسيقات الجدول المفتوح لدعم معاملات ACID واحتياجات السفر عبر الزمن في بحيرة البيانات. من خلال الحفاظ على الإصدارات التاريخية، يوفر السفر عبر الزمن في بحيرة البيانات فوائد مثل التدقيق والامتثال واستعادة البيانات والتراجع عنها والتحليل القابل للتكرار واستكشاف البيانات في نقاط زمنية مختلفة.
هناك حالة أخرى شائعة لاستخدام بحيرة بيانات المعاملات وهي الاستعلام التزايدي. يشير الاستعلام التزايدي إلى إستراتيجية استعلام تركز على معالجة وتحليل البيانات الجديدة أو المحدثة فقط داخل بحيرة البيانات منذ الاستعلام الأخير. الفكرة الأساسية وراء الاستعلامات المتزايدة هي استخدام بيانات التعريف أو تغيير آليات التتبع لتحديد البيانات الجديدة أو المعدلة منذ الاستعلام الأخير. ومن خلال تحديد هذه التغييرات، يمكن لمحرك الاستعلام تحسين الاستعلام لمعالجة البيانات ذات الصلة فقط، مما يقلل بشكل كبير من وقت المعالجة ومتطلبات الموارد.
حل نظرة عامة
في هذا المنشور، نوضح كيفية تنفيذ FGAC على جداول Apache Hudi باستخدام Amazon EMR الأمازون الحوسبة المرنة السحابية (Amazon EC2) متكامل مع Lake Formation. Apache Hudi هو إطار عمل لمستودع بيانات المعاملات مفتوح المصدر، والذي يعمل على تبسيط معالجة البيانات المتزايدة وتطوير خطوط أنابيب البيانات بشكل كبير. تدعم ميزة FGAC الجديدة جميع OTF. بالإضافة إلى العرض التوضيحي مع Hudi هنا، سنتابع مع جداول OTF الأخرى مع مدونات أخرى. نحن نستخدم أجهزة الكمبيوتر المحمولة in أمازون ساجميكر ستوديو لقراءة وكتابة بيانات Hudi عبر أذونات وصول مختلفة للمستخدم من خلال مجموعة السجلات الطبية الإلكترونية. يعكس هذا سيناريوهات الوصول إلى البيانات في العالم الحقيقي - على سبيل المثال، إذا كان المستخدم الهندسي يحتاج إلى الوصول الكامل إلى البيانات لاستكشاف الأخطاء وإصلاحها على نظام أساسي للبيانات، في حين قد يحتاج محللو البيانات فقط إلى الوصول إلى مجموعة فرعية من تلك البيانات التي لا تحتوي على معلومات تعريف شخصية (PII) ). التكامل مع تكوين البحيرة عبر دور وقت تشغيل Amazon EMR يمكّنك أيضًا من تحسين وضع أمان البيانات لديك وتبسيط إدارة التحكم في البيانات لأحمال عمل Amazon EMR. يضمن هذا الحل بيئة آمنة وخاضعة للرقابة للوصول إلى البيانات، وتلبية الاحتياجات المتنوعة ومتطلبات الأمان لمختلف المستخدمين والأدوار في المؤسسة.
يوضح الرسم البياني التالي بنية الحل.
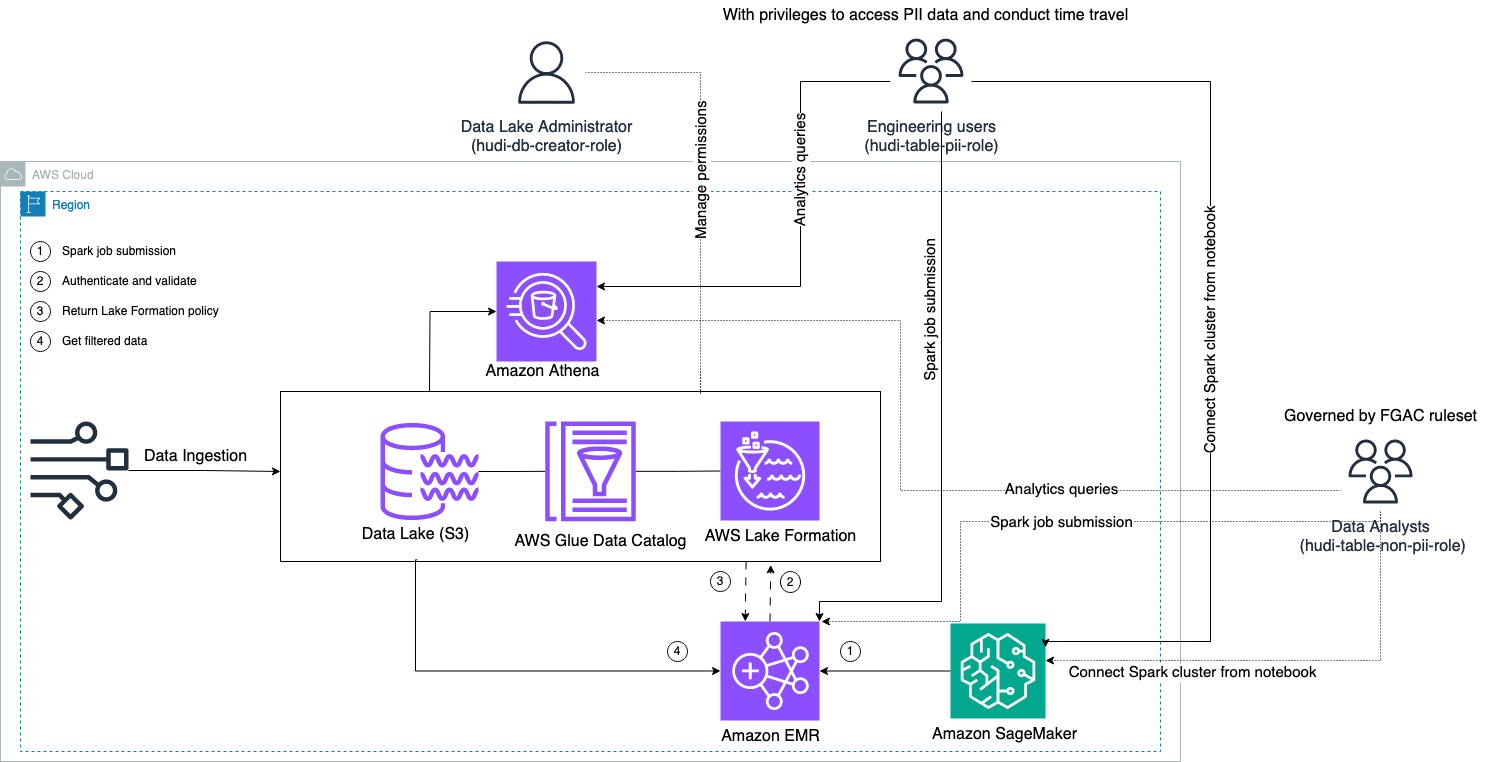
نقوم بإجراء عملية استيعاب البيانات لتحديث (تحديث وإدراج) مجموعة بيانات Hudi إلى ملف خدمة تخزين أمازون البسيطة (Amazon S3)، واستمر في مخطط الجدول أو قم بتحديثه في ملف غراء AWS كتالوج البيانات. مع عدم وجود حركة بيانات، يمكننا الاستعلام عن جدول Hudi الذي تحكمه Lake Formation عبر خدمات AWS المتنوعة، مثل أمازون أثيناوأمازون إي إم آر و الأمازون SageMaker.
عندما يرسل المستخدمون مهمة Spark من خلال أي نقاط نهاية لمجموعة EMR (EMR Steps وLivy وEMR Studio وSageMaker)، تتحقق Lake Formation من صحة امتيازاتهم وتوجه مجموعة EMR لتصفية البيانات الحساسة مثل بيانات PII.
يحتوي هذا الحل على ثلاثة أنواع مختلفة من المستخدمين بمستويات مختلفة من الأذونات للوصول إلى بيانات Hudi:
- hudi-db-creator-role - يتم استخدامه من قبل مسؤول بحيرة البيانات الذي يتمتع بامتيازات تنفيذ عمليات DDL مثل إنشاء كائنات قاعدة البيانات وتعديلها وحذفها. يمكنهم تحديد قواعد تصفية البيانات في Lake Formation للتحكم في الوصول إلى البيانات على مستوى الصف والعمود. تضمن قواعد FGAC هذه تأمين بحيرة البيانات واستيفائها للوائح خصوصية البيانات المطلوبة.
- hudi-الجدول-pii-دور - يتم استخدامه من قبل المستخدمين الهندسيين. يستطيع المستخدمون الهندسيون تنفيذ السفر عبر الزمن والاستعلامات المتزايدة على كل من النسخ عند الكتابة (CoW) والدمج عند القراءة (MoR). لديهم أيضًا امتياز الوصول إلى بيانات PII بناءً على أي طوابع زمنية.
- hudi-table-non-pii-دور - يتم استخدامه من قبل محللي البيانات. تخضع حقوق الوصول إلى البيانات الخاصة بمحللي البيانات لقواعد FGAC المعتمدة والتي يتحكم فيها مسؤولو بحيرة البيانات. ليس لديهم رؤية على الأعمدة التي تحتوي على بيانات PII مثل الأسماء والعناوين. بالإضافة إلى ذلك، لا يمكنهم الوصول إلى صفوف البيانات التي لا تستوفي شروطًا معينة. على سبيل المثال، يمكن للمستخدمين فقط الوصول إلى صفوف البيانات التي تنتمي إلى بلدهم.
المتطلبات الأساسية المسبقة
يمكنك تنزيل دفاتر الملاحظات الثلاثة المستخدمة في هذا المنشور من جيثب ريبو.
قبل نشر الحل، تأكد من أن لديك ما يلي:
أكمل الخطوات التالية لإعداد أذوناتك:
- قم بتسجيل الدخول إلى حساب AWS الخاص بك باستخدام مستخدم IAM المسؤول الخاص بك.
تأكد من أنك فيus-east-1منطقة.
- قم بإنشاء دلو S3 في
us-east-1المنطقة (على سبيل المثال،emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
بعد ذلك، نقوم بتمكين تكوين البحيرة من خلال تغيير نموذج الإذن الافتراضي.
- قم بتسجيل الدخول إلى وحدة تحكم Lake Formation كمستخدم مسؤول.
- اختار إعدادات كتالوج البيانات مع الإدارة في جزء التنقل.
- تحت الأذونات الافتراضية لقواعد البيانات والجداول التي تم إنشاؤها حديثًا، قم بإلغاء التحديد استخدم فقط التحكم في الوصول IAM لقواعد البيانات الجديدة و استخدم فقط التحكم في الوصول IAM للجداول الجديدة في قواعد البيانات الجديدة.
- اختار حفظ.

وبدلاً من ذلك، تحتاج إلى إبطال IAMAllowedPrincipals على الموارد (قواعد البيانات والجداول) التي تم إنشاؤها إذا قمت بتشغيل Lake Formation باستخدام الخيار الافتراضي.
أخيرًا، قمنا بإنشاء زوج مفاتيح لـ Amazon EMR.
- في وحدة تحكم Amazon EC2 ، اختر أزواج المفاتيح في جزء التنقل.
- اختار إنشاء زوج المفاتيح.
- في حالة الاسم، أدخل اسمًا (على سبيل المثال
emr-fgac-hudi-keypair). - اختار إنشاء زوج المفاتيح.
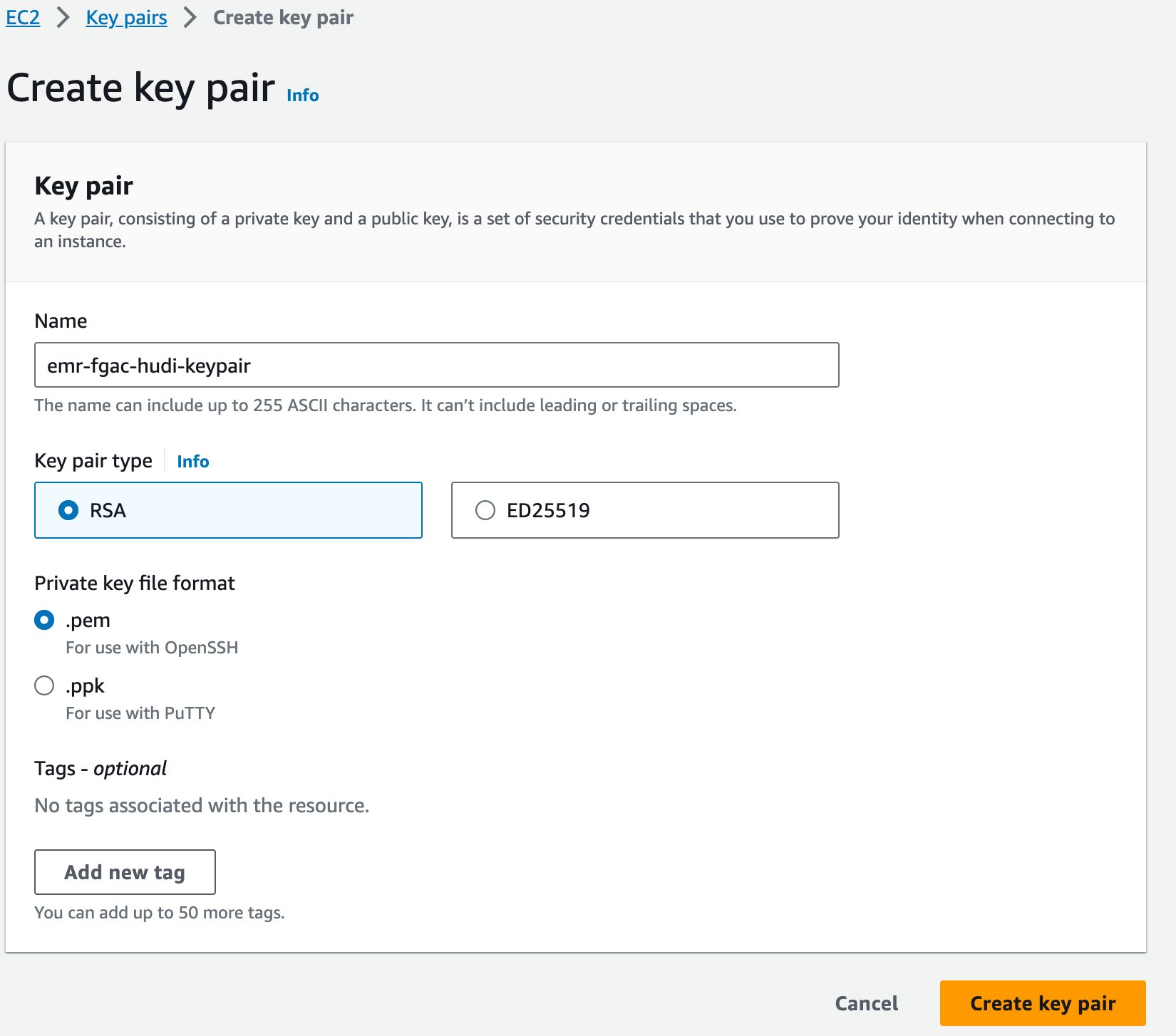
زوج المفاتيح الذي تم إنشاؤه (لهذا المنشور، emr-fgac-hudi-keypair.pem) سيتم حفظه على جهاز الكمبيوتر المحلي الخاص بك.
بعد ذلك ، نقوم بإنشاء ملف سحابة AWS 9 بيئة التطوير التفاعلية (IDE).
- في وحدة تحكم AWS Cloud9 ، اختر البيئات في جزء التنقل.
- اختار خلق البيئة.
- في حالة الاسم¸ أدخل اسمًا (على سبيل المثال ،
emr-fgac-hudi-env). - احتفظ بالإعدادات الأخرى كإعداد افتراضي.
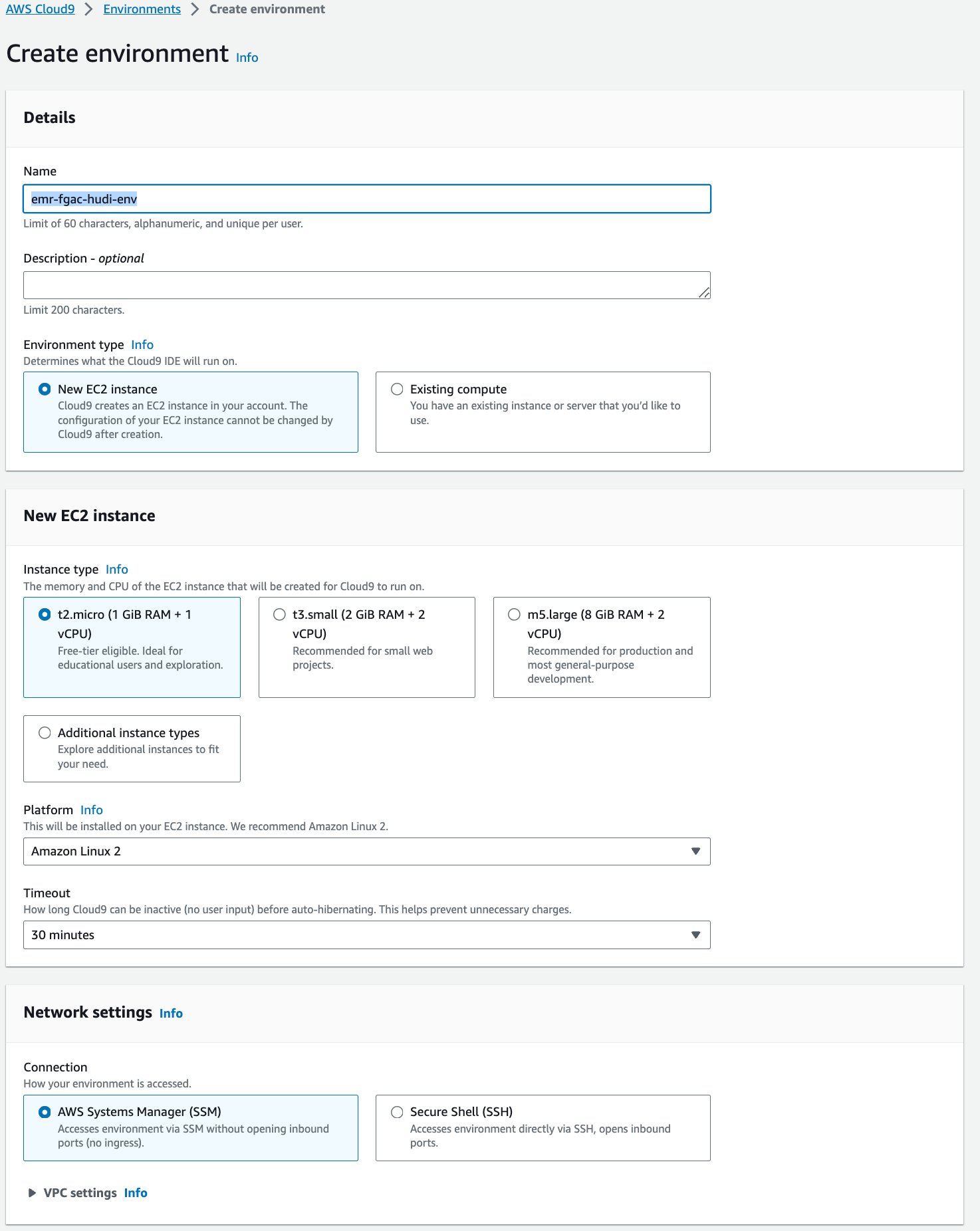
- اختار إنشاء.
- عندما يكون IDE جاهزًا، اختر ساعات العمل لفتحه.
- في AWS Cloud9 IDE، على قم بتقديم القائمة، اختر تحميل الملفات المحلية.

- تحميل ملف زوج المفاتيح (
emr-fgac-hudi-keypair.pem). - اختر علامة الجمع واختر مبنى جديد.
- في المحطة، أدخل أسطر الأوامر التالية:
لاحظ أن رمز المثال هو دليل على المفهوم لأغراض العرض التوضيحي فقط. بالنسبة لأنظمة الإنتاج، استخدم مرجعًا مصدقًا موثوقًا (CA) لإصدار الشهادات. تشير إلى توفير شهادات لتشفير البيانات أثناء النقل باستخدام تشفير Amazon EMR للتفاصيل.
انشر الحل عبر AWS CloudFormation
نحن نقدم تكوين سحابة AWS القالب الذي يقوم تلقائيًا بإعداد الخدمات والمكونات التالية:
- دلو S3 لبحيرة البيانات. أنه يحتوي على مجموعة بيانات TPC-DS النموذجية.
- مجموعة EMR مع تمكين تكوين الأمان وDNS العام.
- أدوار IAM في وقت تشغيل EMR مع أذونات Lake Formation الدقيقة:
- -hudi-db-creator-role - يستخدم هذا الدور لإنشاء قاعدة بيانات وجداول Apache Hudi.
- -hudi-table-pii-role – يوفر هذا الدور الإذن بالاستعلام عن جميع أعمدة جداول Hudi، بما في ذلك الأعمدة التي تحتوي على معلومات تحديد الهوية الشخصية (PII).
- -hudi-table-non-pii-role - يوفر هذا الدور إذنًا للاستعلام عن جداول Hudi التي قامت بتصفية أعمدة PII بواسطة Lake Formation.
- أدوار تنفيذ SageMaker Studio التي تسمح للمستخدمين بتولي أدوار وقت تشغيل EMR المقابلة لهم.
- موارد الشبكات مثل VPC والشبكات الفرعية ومجموعات الأمان.
أكمل الخطوات التالية لنشر الموارد:
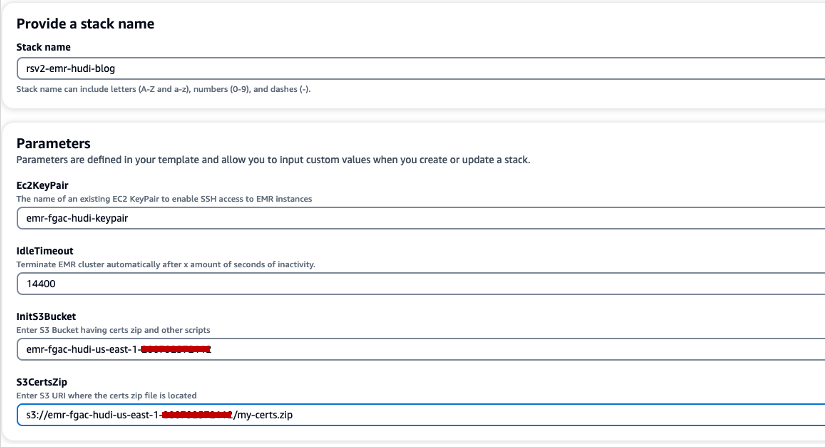
- اختار كومة إنشاء سريعة لإطلاق مكدس CloudFormation.
- في حالة اسم المكدس، أدخل اسم المكدس (على سبيل المثال ،
rsv2-emr-hudi-blog). - في حالة Ec2KeyPair، أدخل اسم زوج المفاتيح الخاص بك.
- في حالة IdleTimeout، أدخل مهلة خاملة لمجموعة EMR لتجنب الدفع مقابل المجموعة عندما لا يتم استخدامها.
- في حالة InitS3Bucket، أدخل اسم حاوية S3 الذي قمت بإنشائه لحفظ ملف .zip لشهادة تشفير Amazon EMR.
- في حالة S3CertsZip، أدخل S3 URI لملف .zip لشهادة تشفير Amazon EMR.
- أختار أقر بأن AWS CloudFormation قد تنشئ موارد IAM بأسماء مخصصة.
- اختار إنشاء مكدس.
يستغرق نشر مكدس CloudFormation حوالي 10 دقائق.
قم بإعداد Lake Formation لتكامل Amazon EMR
أكمل الخطوات التالية لإعداد Lake Formation:
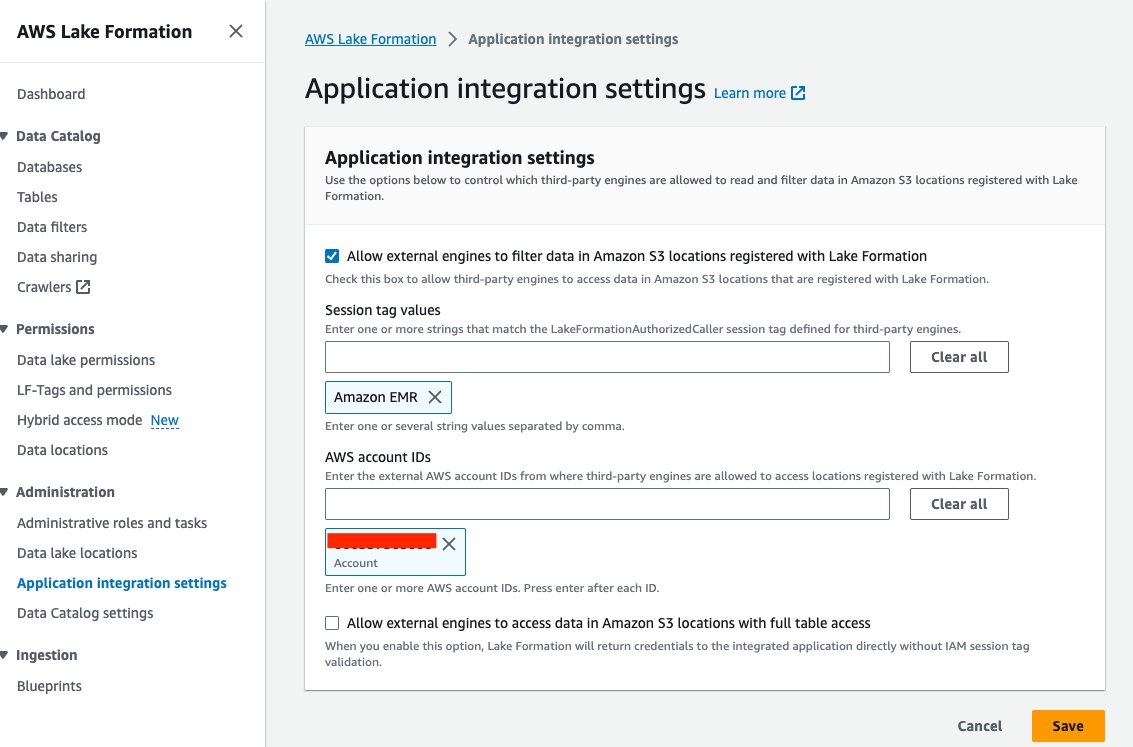
- في وحدة التحكم Lake Formation ، اختر إعدادات تكامل التطبيق مع الإدارة في جزء التنقل.
- أختار السماح للمحركات الخارجية بتصفية البيانات في مواقع Amazon S3 المسجلة لدى Lake Formation.
- اختار أمازون EMR For قيم علامة الجلسة.
- أدخل معرف حساب AWS الخاص بك لـ معرفات حساب AWS.
- اختار حفظ.
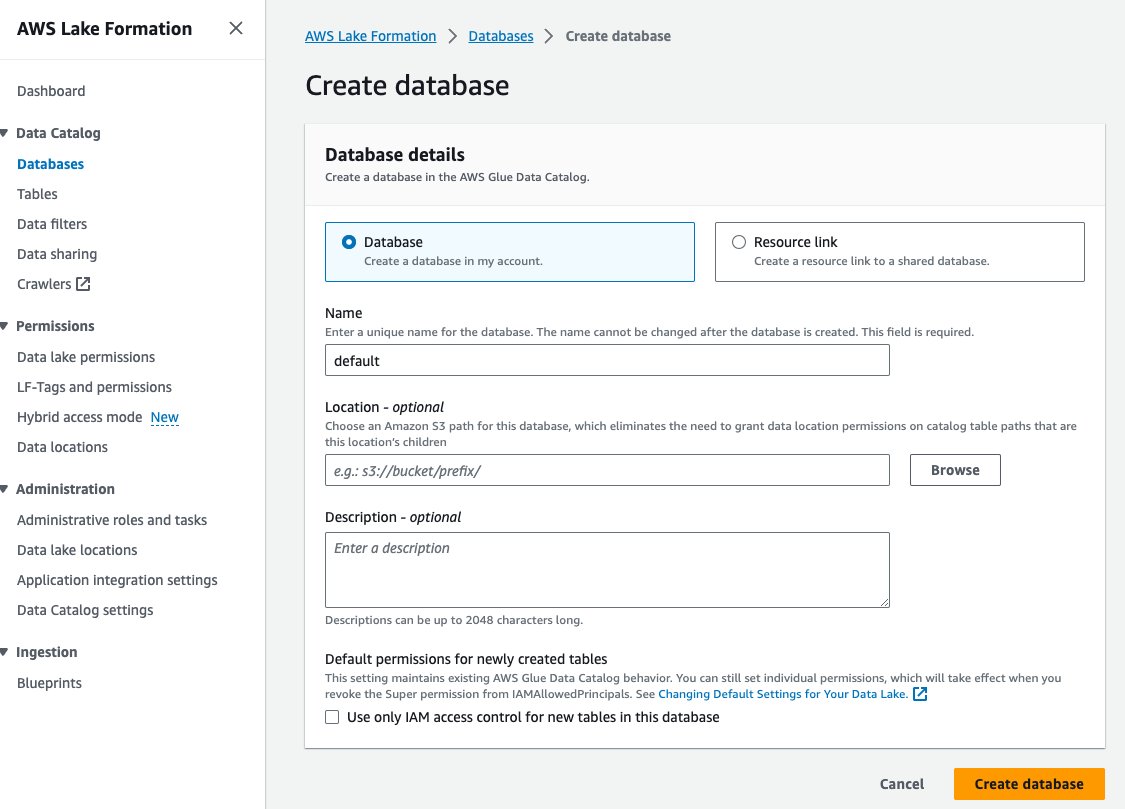
- اختار قواعد بيانات مع كتالوج البيانات في جزء التنقل.
- اختار إنشاء قاعدة البيانات.
- في حالة الاسم، أدخل الافتراضي.
- اختار إنشاء قاعدة البيانات.
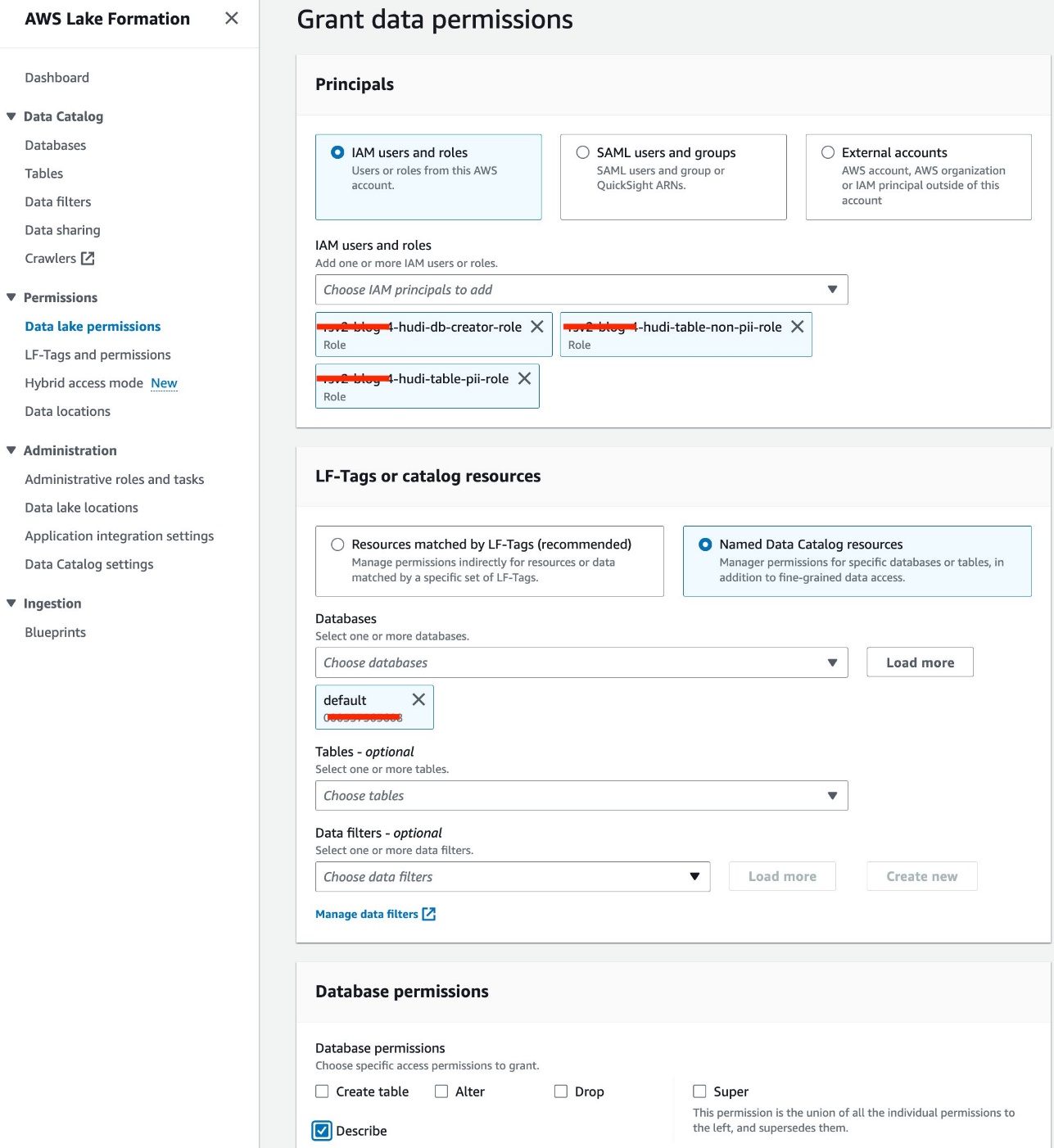
- اختار أذونات بحيرة البيانات مع أذونات في جزء التنقل.
- اختار منحة.
- أختار مستخدمي IAM وأدوارها.
- اختر أدوار IAM الخاصة بك.
- في حالة قواعد بيانات، اختر الافتراضي.
- في حالة أذونات قاعدة البيانات، حدد وصف.
- اختار منحة.
انسخ ملف Hudi JAR إلى Amazon EMR HDFS
إلى استخدم Hudi مع دفاتر Jupyter، تحتاج إلى إكمال الخطوات التالية لمجموعة EMR، والتي تتضمن نسخ ملف Hudi JAR من دليل Amazon EMR المحلي إلى وحدة تخزين HDFS الخاصة به، بحيث يمكنك تكوين جلسة Spark لاستخدام Hudi:
- تفويض حركة مرور SSH الواردة (المنفذ 22).
- انسخ قيمة العقدة الأساسية DNS العام (على سبيل المثال، ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) من مجموعة EMR نبذة عامة والقسم الخاص به.
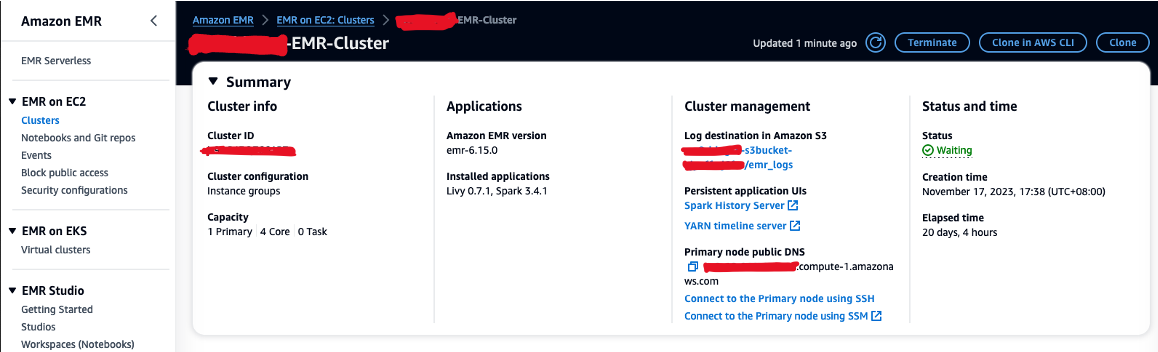
- ارجع إلى محطة AWS Cloud9 السابقة التي استخدمتها لإنشاء زوج مفاتيح EC2.
- قم بتشغيل الأمر التالي إلى SSH في العقدة الأساسية لـ EMR. استبدل العنصر النائب باسم مضيف EMR DNS الخاص بك:
- قم بتشغيل الأمر التالي لنسخ ملف Hudi JAR إلى HDFS:
إنشاء قاعدة البيانات والجداول Hudi في Lake Formation
نحن الآن جاهزون لإنشاء قاعدة بيانات وجداول Hudi مع تمكين FGAC بواسطة دور وقت تشغيل EMR. ال دور وقت تشغيل السجلات الطبية الإلكترونية هو دور IAM يمكنك تحديده عند إرسال وظيفة أو استعلام إلى مجموعة EMR.
منح إذن منشئ قاعدة البيانات
أولاً، دعونا نمنح إذن منشئ قاعدة بيانات Lake Formation بذلك<STACK-NAME>-hudi-db-creator-role:
- قم بتسجيل الدخول إلى حساب AWS الخاص بك كمسؤول.
- في وحدة التحكم Lake Formation ، اختر الأدوار والمهام الإدارية مع الإدارة في جزء التنقل.
- تأكد من إضافة مستخدم تسجيل الدخول إلى AWS كمسؤول عن Data Lake.
- في مجلة منشئ قاعدة البيانات القسم، اختر منحة.
- في حالة مستخدمي IAM وأدوارها، اختر
<STACK-NAME>-hudi-db-creator-role. - في حالة أذونات الكتالوج، حدد إنشاء قاعدة البيانات.
- اختار منحة.
تسجيل موقع بحيرة البيانات
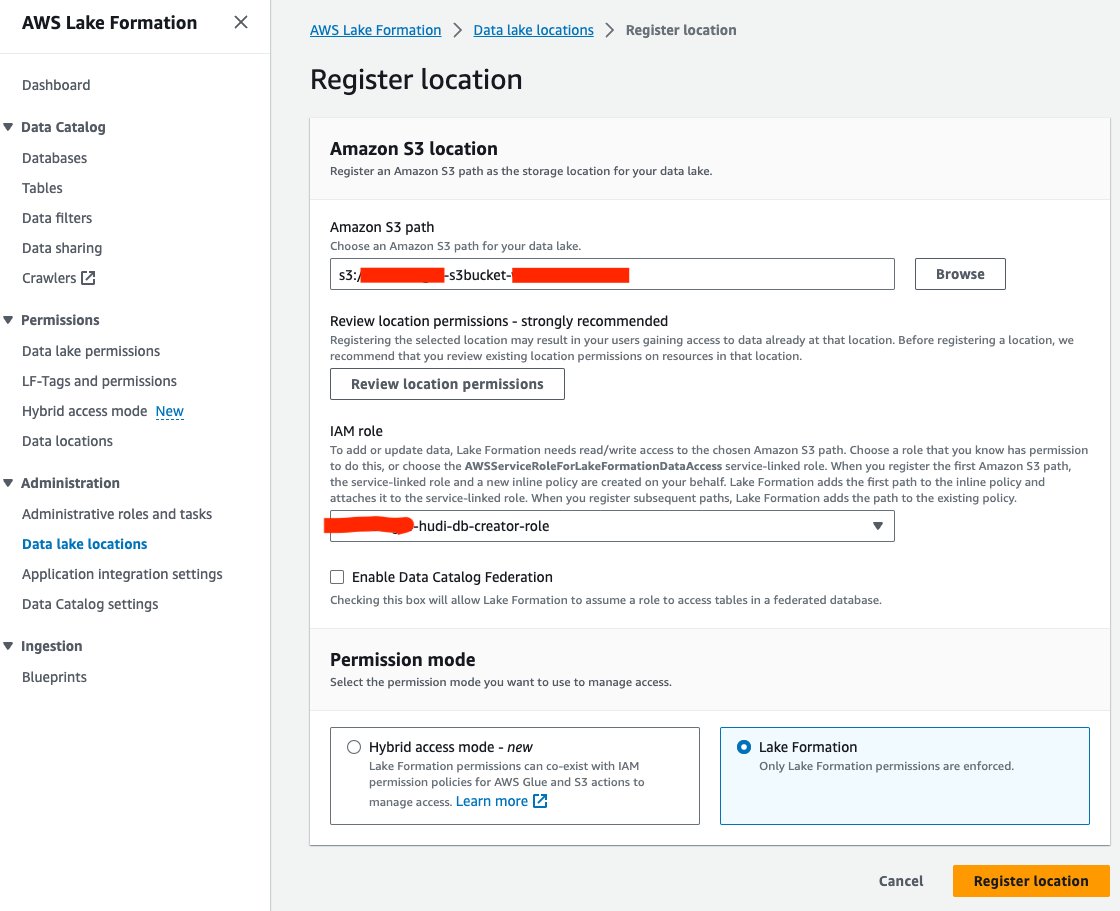
بعد ذلك، لنسجل موقع بحيرة بيانات S3 في Lake Formation:
- في وحدة التحكم Lake Formation ، اختر مواقع بحيرة البيانات مع الإدارة في جزء التنقل.
- اختار تسجيل الموقع.
- في حالة مسار Amazon S3اختر تصفح واختر دلو Data Lake S3. (
<STACK_NAME>s3bucket-XXXXXXX) تم إنشاؤها من مكدس CloudFormation. - في حالة دور IAM، اختر
<STACK-NAME>-hudi-db-creator-role. - في حالة وضع الإذن، حدد تشكيل البحيرة.
- اختار تسجيل الموقع.
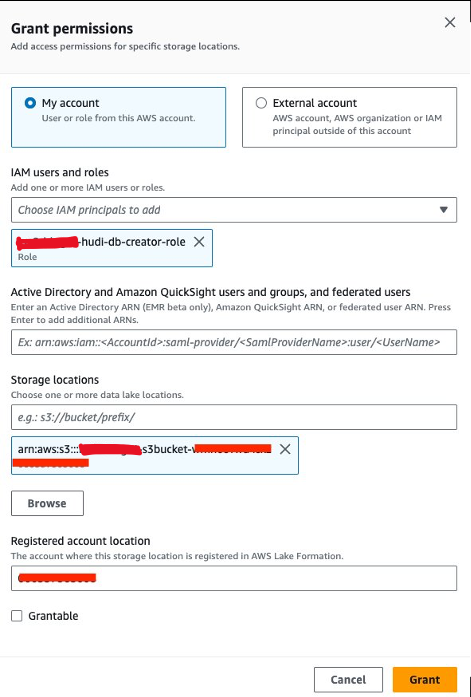
منح إذن موقع البيانات
بعد ذلك، نحن بحاجة إلى منح<STACK-NAME>-hudi-db-creator-roleإذن موقع البيانات:
- في وحدة التحكم Lake Formation ، اختر مواقع البيانات مع أذونات في جزء التنقل.
- اختار منحة.
- في حالة مستخدمي IAM وأدوارها، اختر
<STACK-NAME>-hudi-db-creator-role. - في حالة مواقع التخزين، أدخل دلو S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - اختار منحة.
الاتصال بمجموعة EMR
الآن، دعنا نستخدم دفتر ملاحظات Jupyter في SageMaker Studio للاتصال بمجموعة EMR مع دور وقت تشغيل EMR لمنشئ قاعدة البيانات:
- في وحدة تحكم SageMaker ، اختر المجالات في جزء التنقل.
- اختر المجال
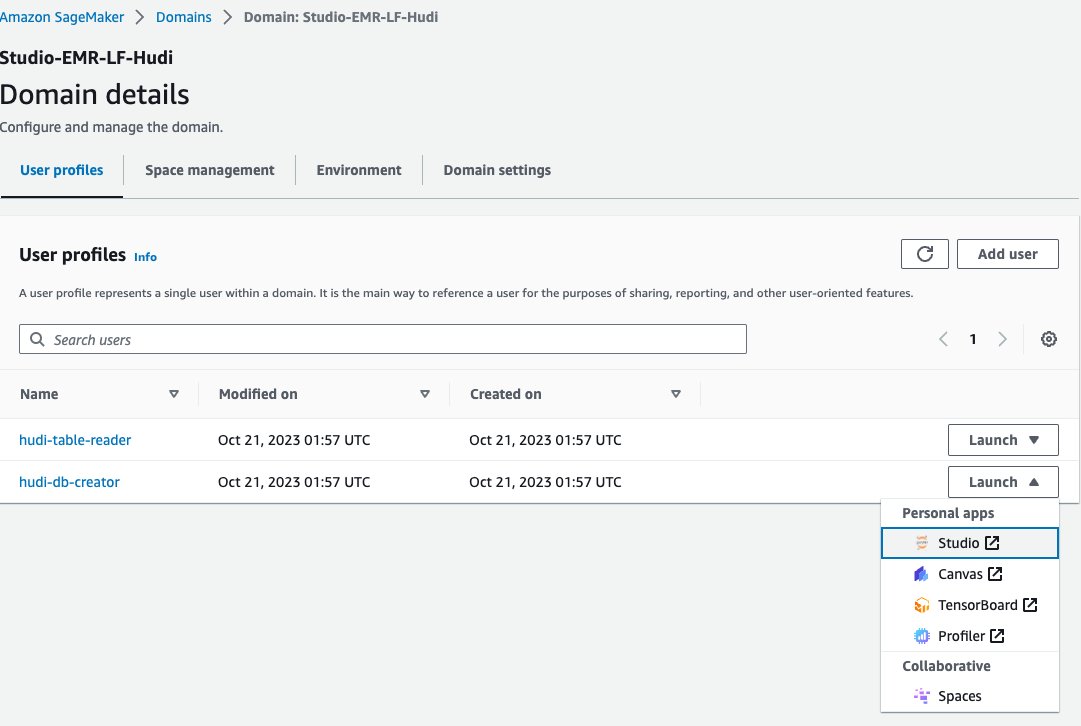
<STACK-NAME>-Studio-EMR-LF-Hudi. - على إطلاق القائمة الموجودة بجوار ملف تعريف المستخدم
<STACK-NAME>-hudi-db-creator، اختر استوديو.
- قم بتنزيل دفتر الملاحظات rsv2-hudi-db-creator-notebook.
- اختر أيقونة التحميل.
- اختر دفتر Jupyter الذي تم تنزيله واختر ساعات العمل.
- افتح دفتر الملاحظات الذي تم تحميله.
- في حالة صورة، اختر سبارك ماجيك.
- في حالة نواة، اختر بايسبارك.
- اترك التكوينات الأخرى كإعداد افتراضي واختر أختار.

- اختار كتلة للاتصال بمجموعة EMR.

- اختر EMR على مجموعة EC2 (
<STACK-NAME>-EMR-Cluster) تم إنشاؤها باستخدام مكدس CloudFormation. - اختار التواصل.
- في حالة دور تنفيذ السجلات الطبية الإلكترونية، اختر
<STACK-NAME>-hudi-db-creator-role. - اختار التواصل.
إنشاء قاعدة البيانات والجداول
يمكنك الآن اتباع الخطوات الموجودة في دفتر الملاحظات لإنشاء قاعدة بيانات وجداول Hudi. الخطوات الرئيسية هي كما يلي:
- عند بدء تشغيل دفتر الملاحظات، قم بتكوينه
“spark.sql.catalog.spark_catalog.lf.managed":"true"لإبلاغ Spark بأن spark_catalog محمي بواسطة Lake Formation. - قم بإنشاء جداول Hudi باستخدام Spark SQL التالي.
- إدراج البيانات من الجدول المصدر إلى جداول Hudi.
- أدخل البيانات مرة أخرى في جداول Hudi.
الاستعلام عن جداول Hudi عبر Lake Formation مع FGAC
بعد إنشاء قاعدة بيانات وجداول Hudi، تصبح جاهزًا للاستعلام عن الجداول باستخدام التحكم الدقيق في الوصول باستخدام Lake Formation. لقد أنشأنا نوعين من جداول Hudi: النسخ عند الكتابة (COW) والدمج عند القراءة (MOR). يقوم جدول COW بتخزين البيانات بتنسيق عمودي (Parquet)، ويقوم كل تحديث بإنشاء إصدار جديد من الملفات أثناء الكتابة. وهذا يعني أنه مع كل تحديث، يقوم Hudi بإعادة كتابة الملف بأكمله، والذي يمكن أن يكون أكثر استهلاكًا للموارد ولكنه يوفر أداء أسرع للقراءة. من ناحية أخرى، يتم تقديم MOR للحالات التي قد لا تكون فيها COW هي الأمثل، خاصة لأعباء العمل الثقيلة للكتابة أو التغيير. في جدول MOR، في كل مرة يكون هناك تحديث، يكتب Hudi فقط الصف الخاص بالسجل الذي تم تغييره، مما يقلل التكلفة ويتيح عمليات الكتابة ذات زمن الوصول المنخفض. ومع ذلك، قد يكون أداء القراءة أبطأ مقارنة بجداول COW.
منح إذن الوصول إلى الجدول
نحن نستخدم دور IAM<STACK-NAME>-hudi-table-pii-roleللاستعلام عن Hudi COW وMOR التي تحتوي على أعمدة PII. نمنح أولاً إذن الوصول إلى الجدول عبر Lake Formation:
- في وحدة التحكم Lake Formation ، اختر أذونات بحيرة البيانات مع أذونات في جزء التنقل.
- اختار منحة.
- اختار
<STACK-NAME>-hudi-table-pii-roleFor مستخدمي IAM وأدوارها. - اختيار
rsv2_blog_hudi_db_1قاعدة بيانات ل قواعد بيانات. - في حالة طاولات الطعام، اختر جداول Hudi الأربعة التي قمت بإنشائها في دفتر Jupyter.
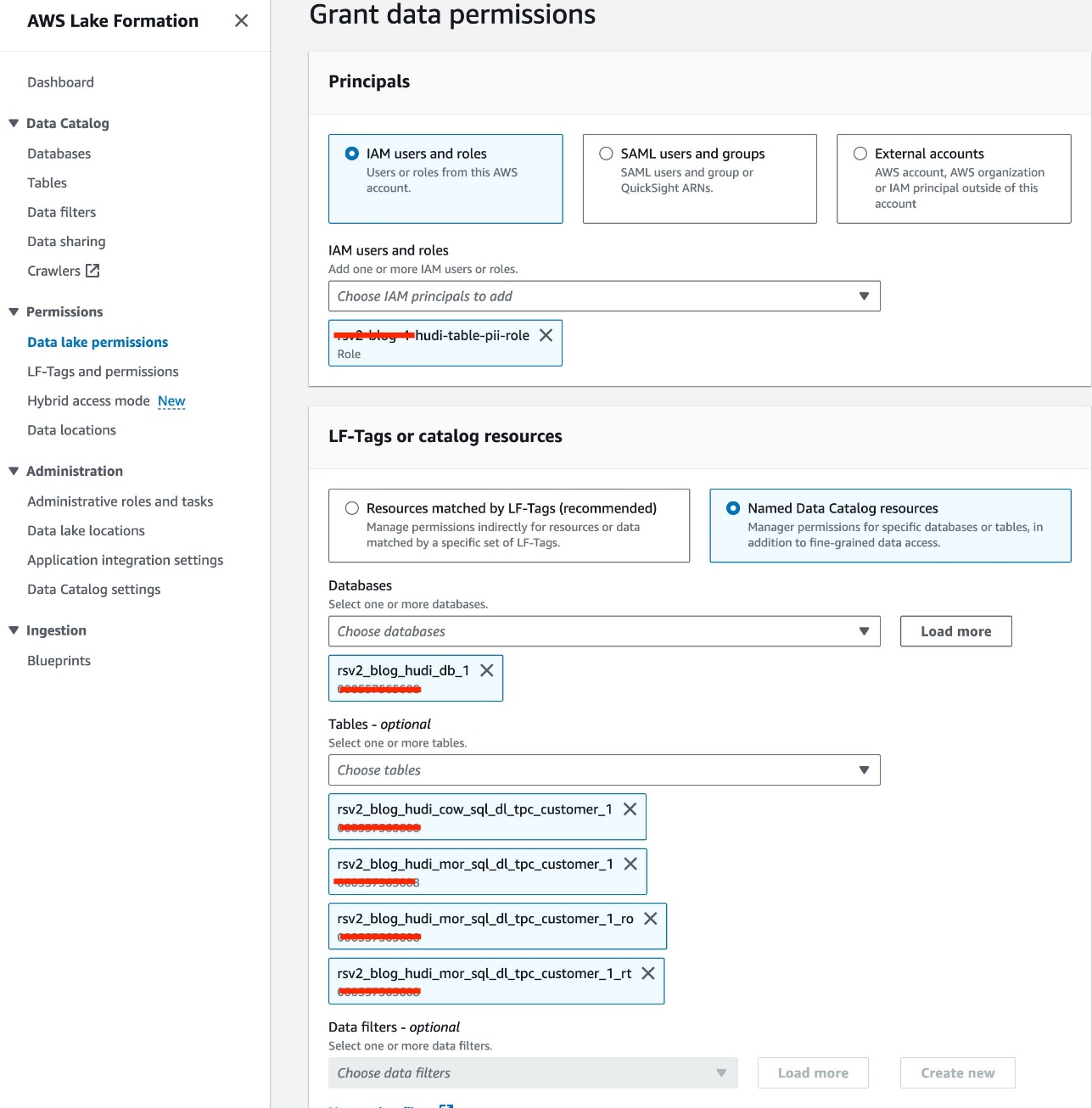
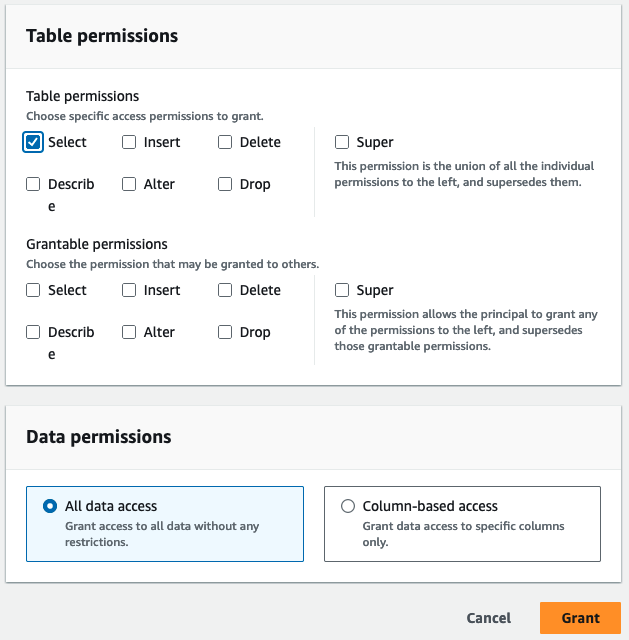
- في حالة أذونات الجدول، حدد أختار.
- اختار منحة.
أعمدة الاستعلام عن معلومات تحديد الهوية الشخصية (PII).
أنت الآن جاهز لتشغيل دفتر الملاحظات للاستعلام عن جداول Hudi. دعونا نتبع خطوات مشابهة للقسم السابق لتشغيل دفتر الملاحظات في SageMaker Studio:
- في وحدة تحكم SageMaker ، انتقل إلى ملف
<STACK-NAME>-Studio-EMR-LF-Hudiالمجال. - على إطلاق القائمة بجانب
<STACK-NAME>-hudi-table-readerملف تعريف المستخدم، اختر استوديو. - قم بتحميل دفتر الملاحظات الذي تم تنزيله rsv2-hudi-table-pii-قارئ دفتر الملاحظات.
- افتح دفتر الملاحظات الذي تم تحميله.
- كرر خطوات إعداد دفتر الملاحظات واتصل بنفس مجموعة السجلات الطبية الإلكترونية (EMR)، لكن استخدم الدور
<STACK-NAME>-hudi-table-pii-role.
في المرحلة الحالية، تحتاج مجموعة السجلات الطبية الإلكترونية التي تدعم FGAC إلى الاستعلام عن العمود الزمني للالتزام الخاص بـ Hudi لإجراء الاستعلامات الإضافية والسفر عبر الزمن. وهو لا يدعم بناء جملة "الطابع الزمني اعتبارًا من" الخاص بـ Spark و Spark.read(). نحن نعمل بنشاط على دمج الدعم لكلا الإجراءين في إصدارات Amazon EMR المستقبلية مع تمكين FGAC.
يمكنك الآن اتباع الخطوات الموجودة في دفتر الملاحظات. فيما يلي بعض الخطوات المميزة:
- تشغيل استعلام لقطة.
- تشغيل استعلام تزايدي.
- قم بتشغيل استعلام السفر عبر الزمن.
- قم بتشغيل استعلامات جدول MOR المحسنة للقراءة وفي الوقت الفعلي.
استعلم عن جداول Hudi باستخدام مرشحات البيانات على مستوى الأعمدة وعلى مستوى الصفوف
نحن نستخدم دور IAM<STACK-NAME>-hudi-table-non-pii-roleللاستعلام عن الجداول هودي. غير مسموح لهذا الدور بالاستعلام عن أي أعمدة تحتوي على معلومات تحديد الهوية الشخصية (PII). نحن نستخدم مرشحات البيانات على مستوى العمود ومستوى الصف في Lake Formation لتنفيذ التحكم الدقيق في الوصول:
- في وحدة التحكم Lake Formation ، اختر مرشحات البيانات مع كتالوج البيانات في جزء التنقل.
- اختار إنشاء مرشح جديد.
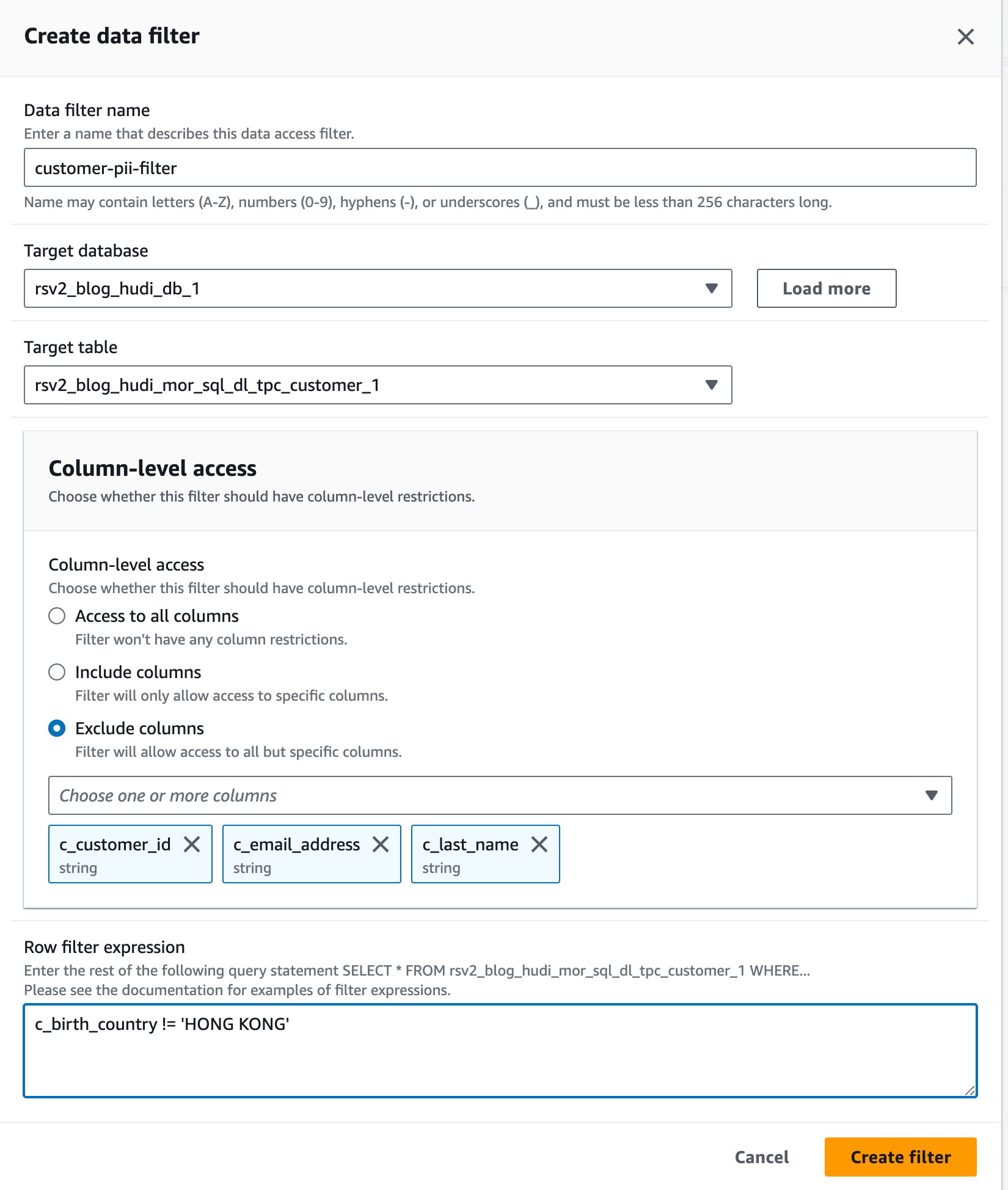
- في حالة اسم عامل تصفية البيانات، أدخل
customer-pii-filter. - اختار
rsv2_blog_hudi_db_1For قاعدة البيانات الهدف. - اختار
rsv2_blog_hudi_mor_sql_dl_customer_1For الجدول الهدف. - أختار استبعاد الأعمدة واختيار
c_customer_id,c_email_addressوc_last_nameالأعمدة. - أدخل
c_birth_country != 'HONG KONG'For تعبير مرشح الصف. - اختار إنشاء مرشح.
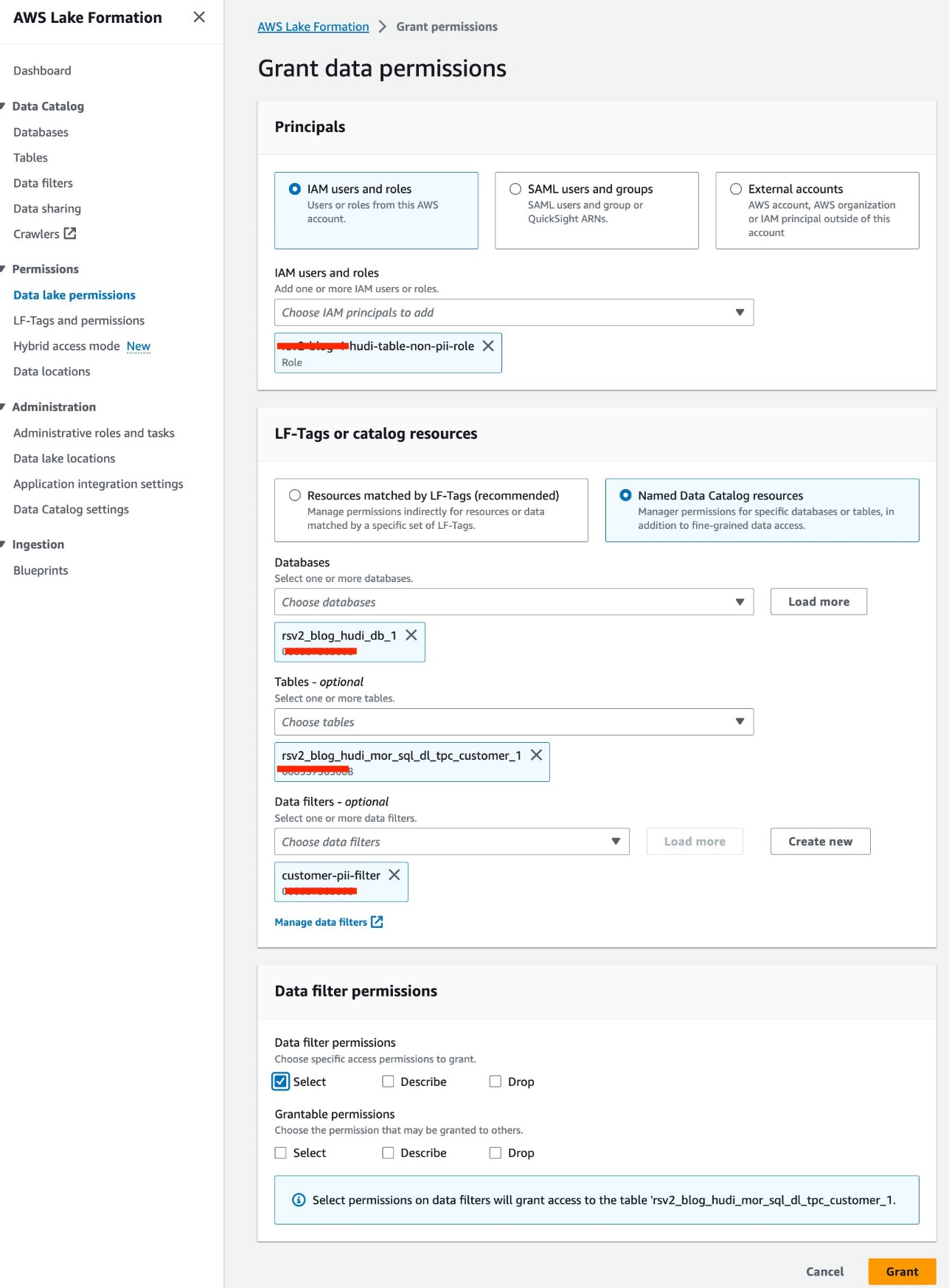
- اختار أذونات بحيرة البيانات مع أذونات في جزء التنقل.
- اختار منحة.
- اختار
<STACK-NAME>-hudi-table-non-pii-roleFor مستخدمي IAM وأدوارها. - اختار
rsv2_blog_hudi_db_1For قواعد بيانات. - اختار
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1For طاولات الطعام. - اختار
customer-pii-filterFor مرشحات البيانات. - في حالة أذونات تصفية البيانات، حدد أختار.
- اختار منحة.
دعونا نتبع خطوات مماثلة لتشغيل دفتر الملاحظات في SageMaker Studio:
- على وحدة تحكم SageMaker، انتقل إلى المجال
Studio-EMR-LF-Hudi. - على إطلاق القائمة ل
hudi-table-readerملف تعريف المستخدم، اختر استوديو. - قم بتحميل دفتر الملاحظات الذي تم تنزيله rsv2-hudi-table-non-pii-reader-notebook واختر ساعات العمل.
- كرر خطوات إعداد دفتر الملاحظات واتصل بنفس مجموعة السجلات الطبية الإلكترونية (EMR)، ولكن حدد الدور
<STACK-NAME>-hudi-table-non-pii-role.
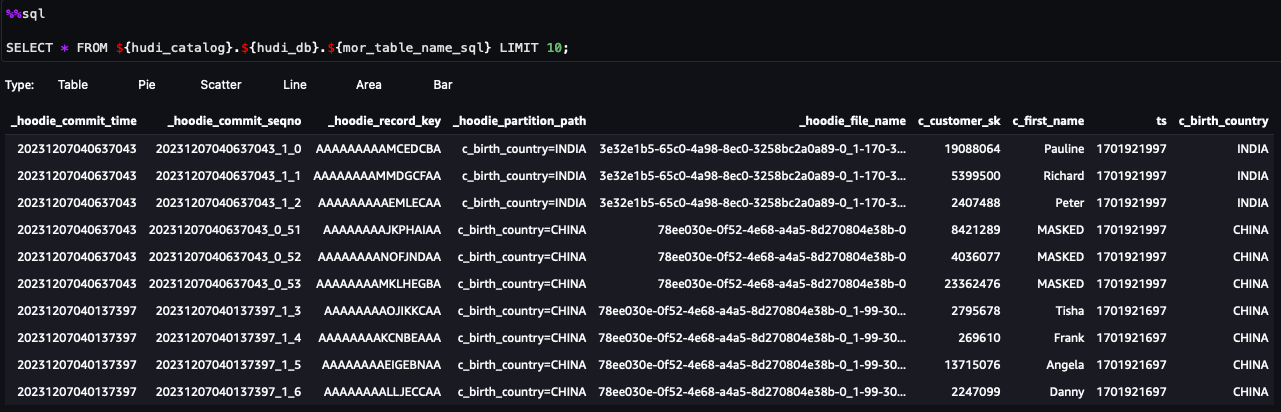
يمكنك الآن اتباع الخطوات الموجودة في دفتر الملاحظات. من نتائج الاستعلام، يمكنك أن ترى أنه تم تطبيق FGAC عبر مرشح بيانات Lake Formation. لا يمكن للدور رؤية أعمدة معلومات تحديد الهوية الشخصية (PII).c_customer_id,c_last_nameوc_email_address. وكذلك الصفوف منHONG KONGتم تصفيتها.
تنظيف
بعد الانتهاء من تجربة الحل، نوصي بتنظيف الموارد من خلال الخطوات التالية لتجنب التكاليف غير المتوقعة:
- قم بإيقاف تشغيل تطبيقات SageMaker Studio لملفات تعريف المستخدمين.
سيتم حذف مجموعة EMR تلقائيًا بعد قيمة مهلة الخمول.
- حذف نظام ملفات أمازون المرن تم إنشاء وحدة تخزين (Amazon EFS) للمجال.
- إفراغ دلاء S3 تم إنشاؤها بواسطة مكدس CloudFormation.
- في وحدة تحكم AWS CloudFormation، احذف المجموعة.
وفي الختام
في هذا المنشور، استخدمنا Apachi Hudi، أحد أنواع جداول OTF، لتوضيح هذه الميزة الجديدة لفرض التحكم الدقيق في الوصول إلى Amazon EMR. يمكنك تحديد الأذونات الدقيقة في Lake Formation لجداول OTF وتطبيقها عبر استعلامات Spark SQL على مجموعات EMR. يمكنك أيضًا استخدام ميزات بحيرة بيانات المعاملات مثل تشغيل استعلامات اللقطة والاستعلامات التزايدية والسفر عبر الزمن واستعلام DML. يرجى ملاحظة أن هذه الميزة الجديدة تغطي جميع جداول OTF.
يتم إطلاق هذه الميزة بدءًا من الإصدار 6.15 من Amazon EMR بشكل عام المناطق حيث يتوفر Amazon EMR. من خلال تكامل Amazon EMR مع Lake Formation، يمكنك إدارة البيانات الضخمة ومعالجتها بثقة، وإطلاق العنان للرؤى وتسهيل اتخاذ القرارات المستنيرة مع الحفاظ على أمن البيانات وإدارتها.
لمعرفة المزيد ، يرجى الرجوع إلى تمكين تكوين البحيرة باستخدام Amazon EMR ولا تتردد في الاتصال بمهندسي حلول AWS، الذين يمكنهم تقديم المساعدة إلى جانب رحلة البيانات الخاصة بك.
عن المؤلف
 ريموند لاي هو مهندس حلول أول متخصص في تلبية احتياجات عملاء المؤسسات الكبيرة. تكمن خبرته في مساعدة العملاء في ترحيل أنظمة وقواعد بيانات المؤسسات المعقدة إلى AWS، وبناء مستودعات بيانات المؤسسة ومنصات بحيرة البيانات. يبرع ريموند في تحديد وتصميم الحلول لحالات استخدام الذكاء الاصطناعي/التعلم الآلي، ويركز بشكل خاص على حلول AWS Serverless وتصميم البنية المستندة إلى الأحداث.
ريموند لاي هو مهندس حلول أول متخصص في تلبية احتياجات عملاء المؤسسات الكبيرة. تكمن خبرته في مساعدة العملاء في ترحيل أنظمة وقواعد بيانات المؤسسات المعقدة إلى AWS، وبناء مستودعات بيانات المؤسسة ومنصات بحيرة البيانات. يبرع ريموند في تحديد وتصميم الحلول لحالات استخدام الذكاء الاصطناعي/التعلم الآلي، ويركز بشكل خاص على حلول AWS Serverless وتصميم البنية المستندة إلى الأحداث.
 بن وانغدكتوراه، هو أحد كبار مهندسي الحلول التحليلية المتخصصة في AWS، ويتمتع بخبرة تزيد عن 12 عامًا في مجال تعلم الآلة، مع التركيز بشكل خاص على الإعلانات. يمتلك خبرة في معالجة اللغات الطبيعية (NLP)، وأنظمة التوصية، وخوارزميات تعلم الآلة المتنوعة، وعمليات تعلم الآلة. إنه متحمس للغاية لتطبيق ML/DL وتقنيات البيانات الضخمة لحل مشاكل العالم الحقيقي.
بن وانغدكتوراه، هو أحد كبار مهندسي الحلول التحليلية المتخصصة في AWS، ويتمتع بخبرة تزيد عن 12 عامًا في مجال تعلم الآلة، مع التركيز بشكل خاص على الإعلانات. يمتلك خبرة في معالجة اللغات الطبيعية (NLP)، وأنظمة التوصية، وخوارزميات تعلم الآلة المتنوعة، وعمليات تعلم الآلة. إنه متحمس للغاية لتطبيق ML/DL وتقنيات البيانات الضخمة لحل مشاكل العالم الحقيقي.
 أديتيا شاه هو مهندس تطوير البرمجيات في AWS. وهو مهتم بقواعد البيانات ومحركات مستودعات البيانات وعمل على تحسين الأداء والامتثال الأمني والامتثال لـ ACID لمحركات مثل Apache Hive وApache Spark.
أديتيا شاه هو مهندس تطوير البرمجيات في AWS. وهو مهتم بقواعد البيانات ومحركات مستودعات البيانات وعمل على تحسين الأداء والامتثال الأمني والامتثال لـ ACID لمحركات مثل Apache Hive وApache Spark.
 ميلودي يانغ هو كبير مهندسي حلول البيانات الضخمة في Amazon EMR في AWS. إنها قائدة تحليلات ذات خبرة تعمل مع عملاء AWS لتقديم إرشادات أفضل الممارسات والمشورة الفنية من أجل مساعدتهم في نجاحهم في تحويل البيانات. مجالات اهتماماتها هي الأطر مفتوحة المصدر والأتمتة وهندسة البيانات و DataOps.
ميلودي يانغ هو كبير مهندسي حلول البيانات الضخمة في Amazon EMR في AWS. إنها قائدة تحليلات ذات خبرة تعمل مع عملاء AWS لتقديم إرشادات أفضل الممارسات والمشورة الفنية من أجل مساعدتهم في نجاحهم في تحويل البيانات. مجالات اهتماماتها هي الأطر مفتوحة المصدر والأتمتة وهندسة البيانات و DataOps.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/

