المُقدّمة
من الأساليب الإحصائية الموثوقة لتحديد الأهمية تحليل التباين (ANOVA)، خاصة عند مقارنة أكثر من متوسطين للعينة. على الرغم من أن توزيع t كافٍ لمقارنة متوسط عينتين، إلا أن ANOVA مطلوب عند العمل مع ثلاث عينات أو أكثر في وقت واحد لتحديد ما إذا كانت وسائلها هي نفسها أم لا لأنها تأتي من نفس المجموعة السكانية الأساسية.
على سبيل المثال، يمكن استخدام تحليل التباين (ANOVA) لتحديد ما إذا كانت الأسمدة المختلفة لها تأثيرات مختلفة على إنتاج القمح في قطع أراضي مختلفة وما إذا كانت هذه المعالجات توفر نتائج مختلفة إحصائيًا من نفس المجموعة السكانية.

قدم البروفيسور آر إيه فيشر مصطلح "تحليل التباين" في عام 1920 عند التعامل مع المشكلة في تحليل البيانات الزراعية. التقلب هو سمة أساسية للأحداث الطبيعية. ينشأ الاختلاف العام في أي مجموعة بيانات معينة من مصادر متعددة، والتي يمكن تصنيفها على نطاق واسع على أنها أسباب قابلة للتخصيص وأسباب صدفة.
يمكن اكتشاف وقياس التباين الناتج عن الأسباب القابلة للتخصيص، في حين أن التباين الناتج عن أسباب الصدفة يكون خارج نطاق سيطرة اليد البشرية ولا يمكن معالجته بشكل منفصل.
وفقًا لـ RA Fisher، فإن تحليل التباين (ANOVA) هو "فصل التباين المنسوب إلى مجموعة واحدة من الأسباب عن التباين المنسوب إلى مجموعة أخرى".
أهداف التعلم
- فهم مفهوم تحليل التباين (ANOVA) وأهميته في التحليل الإحصائي، خاصة عند مقارنة متوسطات العينات المتعددة.
- التعرف على الافتراضات اللازمة لإجراء اختبار ANOVA وتطبيقه في مجالات مختلفة مثل الطب والتعليم والتسويق والتصنيع وعلم النفس والزراعة.
- استكشاف العملية خطوة بخطوة لإجراء تحليل التباين أحادي الاتجاه، بما في ذلك إعداد فرضيات العدم والبديلة، وجمع البيانات وتنظيمها، وحساب إحصائيات المجموعة، وتحديد مجموع المربعات، وحساب درجات الحرية، وحساب متوسط المربعات وحساب إحصائيات F وتحديد القيمة الحرجة واتخاذ القرار.
- احصل على رؤى عملية حول تنفيذ اختبار ANOVA أحادي الاتجاه في Python باستخدام مكتبة scipy.stats.
- فهم مستوى الأهمية وتفسير إحصائية F والقيمة p في سياق تحليل التباين (ANOVA).
- تعرف على طرق التحليل اللاحق مثل فرق Tukey's Honestly Significant Difference (HSD) لمزيد من التحليل للاختلافات المهمة بين المجموعات.
جدول المحتويات
افتراضات لاختبار ANOVA
يعتمد اختبار ANOVA على إحصائيات الاختبار F.
تتضمن الافتراضات المتعلقة بصلاحية اختبار F في تحليل التباين (ANOVA) ما يلي:
- الملاحظات مستقلة.
- السكان الأصليون الذين يتم أخذ الملاحظات منهم أمر طبيعي.
- تعتبر المعالجة المختلفة والتأثيرات البيئية مضافة بطبيعتها.
اتجاه واحد أنوفا
طريقة واحدة ANOVA هي أ اختبار إحصائي يستخدم لتحديد ما إذا كانت هناك فروق ذات دلالة إحصائية في متوسطات ثلاث مجموعات أو أكثر لعامل واحد (متغير مستقل). فهو يقارن التباين بين المجموعات بالتباين داخل المجموعات لتقييم ما إذا كانت هذه الاختلافات محتملة بسبب الصدفة العشوائية أو التأثير المنهجي للعامل.
عدة حالات استخدام لتحليل التباين (ANOVA) أحادي الاتجاه من مجالات مختلفة هي:
- دواء: يمكن استخدام ANOVA أحادي الاتجاه لمقارنة فعالية العلاجات المختلفة في حالة طبية معينة. على سبيل المثال، يمكن استخدامه لتحديد ما إذا كانت ثلاثة أدوية مختلفة لها تأثيرات مختلفة بشكل كبير على خفض ضغط الدم.
- التعليم: يمكن استخدام ANOVA أحادي الاتجاه لتحليل ما إذا كانت هناك فروق ذات دلالة إحصائية في درجات الاختبار بين الطلاب الذين تم تدريسهم باستخدام طرق تدريس مختلفة.
- تسويق: يمكن استخدام ANOVA أحادي الاتجاه لتقييم ما إذا كانت هناك اختلافات كبيرة في مستويات رضا العملاء بين المنتجات من العلامات التجارية المختلفة.
- التصنيع: يمكن استخدام ANOVA أحادي الاتجاه لتحليل ما إذا كانت هناك اختلافات كبيرة في قوة المواد التي تنتجها عمليات التصنيع المختلفة.
- علم النفس: يمكن استخدام ANOVA أحادي الاتجاه لمعرفة ما إذا كانت هناك اختلافات كبيرة في مستويات القلق بين المشاركين المعرضين لضغوطات مختلفة.
- الزراعة: يمكن استخدام تحليل التباين الأحادي (ANOVA) لتحديد ما إذا كانت الأسمدة المختلفة تؤدي إلى اختلاف كبير في إنتاجية المحاصيل في التجارب الزراعية.
دعونا نفهم هذا مع مثال الزراعة بالتفصيل:
في البحوث الزراعية، يمكن استخدام تحليل التباين (ANOVA) أحادي الاتجاه لتقييم ما إذا كانت الأسمدة المختلفة تؤدي إلى إنتاجية محاصيل مختلفة بشكل كبير.
تأثير الأسمدة على نمو النبات
تخيل أنك تبحث عن تأثير الأسمدة المختلفة على نمو النبات. يمكنك استخدام ثلاثة أنواع من الأسمدة (أ، ب، ج) لمجموعات منفصلة من النباتات. وبعد فترة محددة، تقوم بقياس متوسط ارتفاع النباتات في كل مجموعة. يمكنك استخدام تحليل التباين أحادي الاتجاه لاختبار ما إذا كان هناك اختلاف كبير في متوسط الارتفاع بين النباتات المزروعة بأسمدة مختلفة.
الخطوة الأولى: الفرضيات الصفرية والبديلة
الخطوة الأولى هي تكثيف الفرضيات الصفرية والبديلة:
- الفرضية الصفرية(H0): متوسطات جميع المجموعات متساوية (لا يوجد فرق معنوي في نمو النبات حسب نوع السماد)
- الفرضية البديلة (H1): يختلف متوسط مجموعة واحدة على الأقل عن المجموعات الأخرى (نوع الأسمدة له تأثير كبير على نمو النبات).
الخطوة الثانية: جمع البيانات وتنظيمها
بعد فترة نمو محددة، قم بقياس الارتفاع النهائي لكل نبات في المجموعات الثلاث بعناية. الآن قم بتنظيم بياناتك. يمثل كل عمود نوع سماد (A، B، C) ويحمل كل صف ارتفاع النبات الفردي ضمن تلك المجموعة.
الخطوة 3: حساب إحصائيات المجموعة
- احسب متوسط الارتفاع النهائي للنباتات في كل مجموعة أسمدة (A، B، C).
- حساب العدد الإجمالي للنباتات التي لوحظت (N) في جميع المجموعات.
- حدد العدد الإجمالي للمجموعات (K) في حالتنا، k=3(A, B, C)
الخطوة 4: حساب مجموع المربع
لذلك سيتم حساب مجموع المربعات، ومجموع المربعات بين المجموعات، ومجموع المربعات داخل المجموعة.
هنا، يمثل مجموع المربعات إجمالي التباين في الارتفاع النهائي عبر جميع النباتات.
يعكس مجموع المربعات بين المجموعات التباين الملحوظ بين متوسط ارتفاعات مجموعات الأسمدة الثلاث. ويلتقط مجموع المربعات داخل المجموعة التباين في الارتفاعات النهائية داخل كل مجموعة أسمدة.
الخطوة 5: حساب درجات الحرية
تحدد درجات الحرية عدد المعلومات المستقلة المستخدمة لتقدير المعلمة السكانية.
- درجات الحرية بين المجموعة: ك-1 (عدد المجموعات ناقص 1) إذن، هنا سيكون 3-1 =2
- درجات الحرية داخل المجموعة: Nk (إجمالي عدد الملاحظات ناقص عدد المجموعات)
الخطوة 6: حساب متوسط المربعات
يتم الحصول على متوسط المربعات عن طريق قسمة مجموع المربعات المعنية على درجات الحرية.
- يعني مربع بين: بين-المجموعة مجموع المربعات/درجات الحرية بين-المجموعة
- يعني مربع داخل: داخل المجموعة مجموع مربعات/درجات الحرية داخل المجموعة
الخطوة 7: حساب إحصائيات F
إحصاء F هو إحصاء اختباري يستخدم لمقارنة التباين بين المجموعات بالتباين داخل المجموعات. تشير إحصائية F الأعلى إلى وجود تأثير أقوى محتمل لنوع الأسمدة على نمو النبات.
يتم حساب إحصائية F لتحليل التباين أحادي الاتجاه باستخدام هذه الصيغة:
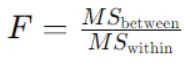
هنا،
MSbetween هو متوسط المربع بين المجموعات، ويتم حسابه كمجموع المربعات بين المجموعات مقسومًا على درجات الحرية بين المجموعات.
MSwithin هو متوسط المربع داخل المجموعات، ويتم حسابه كمجموع المربعات داخل المجموعات مقسومًا على درجات الحرية داخل المجموعات.
- درجات الحرية بين المجموعات (dof_between): dof_between = k-1
حيث k هو عدد المجموعات (المستويات) للمتغير المستقل.
- درجات الحرية داخل المجموعات (dof_within): dof_within = نك
حيث N هو عدد الملاحظات و k هو عدد مجموعات (مستويات) المتغير المستقل.
بالنسبة لتحليل التباين أحادي الاتجاه، فإن إجمالي درجات الحرية هو مجموع درجات الحرية بين المجموعات وداخل المجموعات:
dof_total= dof_between+dof_within
الخطوة 8: تحديد القيمة الحاسمة والقرار
اختر مستوى الأهمية (ألفا) للتحليل، وعادةً ما يتم اختيار 0.05
ابحث عن قيمة F الحرجة عند مستوى ألفا المختار ودرجات الحرية المحسوبة بين المجموعة ودرجات الحرية داخل المجموعة باستخدام جدول توزيع F.
قارن إحصائية F المحسوبة مع قيمة F الحرجة
- إذا كانت إحصائية F المحسوبة أكبر من قيمة F الحرجة، فارفض الفرضية الصفرية (H0). وهذا يدل على وجود فرق ذو دلالة إحصائية في متوسط ارتفاع النباتات بين المجموعات السمادية الثلاث.
- إذا كانت إحصائية F المحسوبة أقل من أو تساوي قيمة F الحرجة، تفشل في رفض الفرضية الصفرية (H0). لا يمكنك استنتاج فرق كبير بناءً على هذه البيانات.
الخطوة 9: التحليل اللاحق (إذا لزم الأمر)
إذا كان فرضية العدم تم رفضه، مما يدل على وجود اختلاف إجمالي كبير، فقد ترغب في التعمق أكثر. يمكن للفرق اللاحق مثل Tukey's Honestly Significant Difference (HSD) أن يساعد في تحديد مجموعات الأسمدة المحددة التي لها متوسط ارتفاعات نباتية مختلفة إحصائيًا.
التنفيذ في بايثون:
import scipy.stats as stats
# Sample plant height data for each fertilizer type
plant_heights_A = [25, 28, 23, 27, 26]
plant_heights_B = [20, 22, 19, 21, 24]
plant_heights_C = [18, 20, 17, 19, 21]
# Perform one-way ANOVA
f_value, p_value = stats.f_oneway(plant_heights_A, plant_heights_B, plant_heights_C)
# Interpretation
print("F-statistic:", f_value)
print("p-value:", p_value)
# Significance level (alpha) - typically set at 0.05
alpha = 0.05
if p_value < alpha:
print("Reject H0: There is a significant difference in plant growth between the fertilizer groups.")
else:
print("Fail to reject H0: We cannot conclude a significant difference based on this sample.")
الإخراج:

درجة الحرية بين هي K-1 = 3-1 =2 حيث تمثل k عدد مجموعات الأسمدة. درجة الحرية داخل هي Nk = 15-3 = 12، حيث تمثل N إجمالي عدد نقاط البيانات.
يمكن حساب F-Critical عند dof(2,12) من F- جدول التوزيع عند مستوى دلالة 0.05.
F-حرجة = 9.42
وبما أن F-Critical < F-statistics، فإننا نرفض الفرضية الصفرية التي تنص على وجود فرق معنوي في نمو النبات بين المجموعات السمادية.
مع قيمة p أقل من 0.05، يظل استنتاجنا ثابتًا: نحن نرفض فرضية العدم، مما يشير إلى وجود اختلاف كبير في نمو النبات بين مجموعات الأسمدة.
في اتجاهين ANOVA
تحليل التباين أحادي الاتجاه مناسب لعامل واحد فقط، ولكن ماذا لو كان لديك عاملين يؤثران على تجربتك؟ ثم يتم استخدام تحليل التباين ثنائي الاتجاه والذي يسمح لك بتحليل تأثيرات متغيرين مستقلين على متغير تابع واحد.
الخطوة الأولى: وضع الفرضيات
- فرضية لاغية (H0): لا يوجد فرق معنوي في متوسط ارتفاع النبات النهائي بسبب نوع السماد (أ، ب، ج) أو موعد الزراعة (مبكر، متأخر) أو التفاعل بينهما.
- الفرضية البديلة (H1): واحد على الأقل مما يلي صحيح:
- نوع السماد له تأثير كبير على متوسط الارتفاع النهائي.
- وقت الزراعة له تأثير كبير على متوسط الارتفاع النهائي.
- هناك تأثير تفاعلي معنوي بين نوع السماد ووقت الزراعة. أي أن تأثير أحد العوامل (السماد) يعتمد على مستوى العامل الآخر (زمن الزراعة).
الخطوة الثانية: جمع البيانات وتنظيمها
- قياس ارتفاعات النبات النهائية.
- قم بتنظيم بياناتك في جدول يحتوي على صفوف تمثل النباتات الفردية والأعمدة من أجل:
- نوع السماد (أ، ب، ج)
- وقت الزراعة (مبكر، متأخر)
- الارتفاع النهائي (سم)
هنا الجدول:

الخطوة 3: حساب مجموع المربع
كما هو الحال مع تحليل التباين أحادي الاتجاه، سيتعين عليك حساب مجموعات مختلفة من المربعات لتقييم التباين في الارتفاعات النهائية:
- إجمالي مجموع المربعات (SST): يمثل التباين الكلي في جميع النباتات. مجموع التأثير الرئيسي للمربع:
- أنواع الأسمدة بين (SSB_F): يعكس التباين الناتج عن الاختلافات في نوع الأسمدة (متوسطه عبر أوقات الزراعة)
- الأوقات بين الطلاء (SSB_T): يعكس التباين الناتج عن الاختلافات في أوقات الزراعة (المتوسط عبر أنواع الأسمدة).
- مجموع التفاعل المربع (SSI): يلتقط الاختلاف بسبب التفاعل بين نوع الأسمدة ووقت الزراعة.
- مجموع المربعات داخل المجموعة (SSW): يمثل التباين في الارتفاعات النهائية خلال كل مجموعة زمنية لزراعة الأسمدة.
الخطوة 4: حساب درجات الحرية (df):
تحدد درجات الحرية عدد المعلومات المستقلة لكل تأثير.
- إجمالي df: N-1 (مجموع الملاحظات ناقص 1)
- الأسمدة: عدد أنواع الأسمدة -1
- وقت الزراعة: عدد مرات الزراعة -1
- تفاعل df: (عدد أنواع الأسمدة -1) * (عدد مرات الزراعة -1)
- dfداخل: dfTotal-dfFertilizer-dfplanting-dfInteraction
الخطوة 5: حساب متوسط المربعات
اقسم كل مجموع مربع على درجة الحرية المقابلة له.
- MS_Fertilizer: SSB_F/dfFertilizer
- MS_PlantingTime: SSB_T/dfPlanting
- تفاعل MS_: SSI/dfInteraction
- MS_داخل: SSW/dfWithin
الخطوة 6: حساب إحصائيات F
احسب إحصائيات F المنفصلة لنوع الأسمدة ووقت الزراعة وتأثير التفاعل:
- F_التسميد: MS_Fertilizer/MS_Within
- F_وقت الزراعة: MS_PlantingTime/ MS_Within
- F_التفاعل: MS_Inteaction/MS_Within
- F_وقت الزراعة: MS_PlantingTime/MS_Within
- F_التفاعل: MS_Interaction/ MS_Within
الخطوة 7: تحديد القيم الحاسمة والقرار:
اختر مستوى الأهمية (ألفا) لتحليلك، وعادة ما نأخذ 0.05
ابحث عن قيم F الحرجة لكل تأثير (الأسمدة ووقت الزراعة والتفاعل) عند مستوى ألفا المختار ودرجات الحرية الخاصة بكل منها باستخدام جدول توزيع F أو برنامج إحصائي.
قارن إحصائيات F المحسوبة بقيم F المهمة لكل تأثير:
- إذا كانت إحصائية F أكبر من قيمة F الحرجة، فارفض فرضية العدم (H0) لهذا التأثير. وهذا يدل على وجود فرق ذو دلالة إحصائية.
- إذا كانت إحصائية F أقل من أو تساوي قيمة F الحرجة، تفشل في رفض H0 لهذا التأثير. وهذا يدل على وجود فرق كبير إحصائيا.
الخطوة 8: التحليل اللاحق (إذا لزم الأمر)
إذا تم رفض فرضية العدم، مما يدل على وجود اختلاف إجمالي كبير، فقد ترغب في التعمق أكثر. يمكن للفرق اللاحق مثل Tukey's Honestly Significant Difference (HSD) أن يساعد في تحديد مجموعات الأسمدة المحددة التي لها متوسط ارتفاعات نباتية مختلفة إحصائيًا.
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
# Create a DataFrame from the dictionary
plant_heights = {
'Treatment': ['A', 'A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C', 'C'],
'Time': ['Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late'],
'Height': [25, 28, 23, 27, 26, 24,
20, 22, 19, 21, 24, 22,
18, 20, 17, 19, 21, 20]
}
df = pd.DataFrame(plant_heights)
# Fit the ANOVA model
model = ols('Height ~ C(Treatment) + C(Time) + C(Treatment):C(Time)', data=df).fit()
# Perform ANOVA
anova_table = sm.stats.anova_lm(model, typ=2)
# Print the ANOVA table
print(anova_table)
# Interpret the results
alpha = 0.05 # Significance level
if anova_table['PR(>F)'][0] < alpha:
print("nReject null hypothesis for Treatment factor.")
else:
print("nFail to reject null hypothesis for Treatment factor.")
if anova_table['PR(>F)'][1] < alpha:
print("Reject null hypothesis for Time factor.")
else:
print("Fail to reject null hypothesis for Time factor.")
if anova_table['PR(>F)'][2] < alpha:
print("Reject null hypothesis for Interaction between Treatment and Time.")
else:
print("Fail to reject null hypothesis for Interaction between Treatment and Time.")
الإخراج:
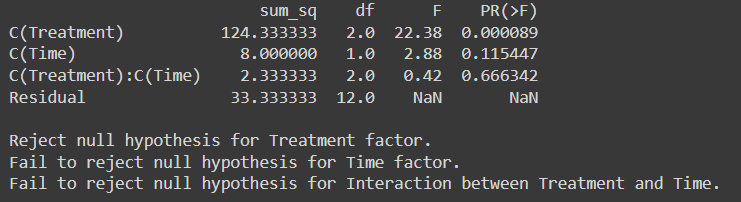
F- القيمة الحرجة للمعاملة عند درجة الحرية (2,12،0.05) عند مستوى دلالة XNUMX من جدول التوزيع F هو 9.42
F- القيمة الحرجة للزمن عند درجة الحرية (1,12) عند مستوى دلالة 0.05 هي 61.22
F- القيمة الحرجة للتفاعل بين العلاج والزمن عند مستوى دلالة 0.05 عند درجة الحرية (2,12) هي 9.42
بما أن F-Critical < F-statistics، فإننا نرفض الفرضية الصفرية لعامل المعالجة.
لكن بالنسبة لعامل الوقت والتفاعل بين العلاج وعامل الوقت فشلنا في رفض الفرضية الصفرية كقيمة إحصائية F > قيمة F الحرجة
مع قيمة p أقل من 0.05، يظل استنتاجنا ثابتًا: نحن نرفض الفرضية الصفرية لعامل العلاج بينما مع القيمة p أعلى من 0.05 نفشل في رفض الفرضية الصفرية لعامل الوقت والتفاعل بين العلاج وعامل الوقت.
الفرق بين تحليل التباين أحادي الاتجاه و تحليل التباين ثنائي الاتجاه
تعد كل من ANOVA أحادية الاتجاه وTwo-way ANOVA من التقنيات الإحصائية المستخدمة لتحليل الاختلافات بين المجموعات، ولكنها تختلف من حيث عدد المتغيرات المستقلة التي تأخذها في الاعتبار ومدى تعقيد التصميم التجريبي.
فيما يلي الاختلافات الرئيسية بين ANOVA أحادي الاتجاه وANOVA ثنائي الاتجاه:
| الجانب | اتجاه واحد أنوفا | في اتجاهين ANOVA |
|---|---|---|
| عدد المتغيرات | تحليل متغير مستقل واحد (عامل) على متغير تابع مستمر | تحليل متغيرين مستقلين (عوامل) على متغير تابع مستمر |
| تصميم تجريبي | متغير مستقل قاطع واحد ذو مستويات متعددة (مجموعات) | متغيران مستقلان (عوامل) فئويتان، غالبًا ما يُطلق عليهما A وB، بمستويات متعددة. يسمح بفحص التأثيرات الرئيسية وتأثيرات التفاعل |
| ترجمة | يشير إلى اختلافات كبيرة بين وسائل المجموعة | يوفر معلومات عن التأثيرات الرئيسية للعوامل (A وB) وتفاعلها. يساعد على تقييم الاختلافات بين مستويات العوامل والاعتماد المتبادل |
| تعقيد | واضحة نسبيا وسهلة التفسير | أكثر تعقيدًا، حيث يتم تحليل التأثيرات الرئيسية لعاملين وتفاعلهما. يتطلب دراسة متأنية لعلاقات العوامل |
وفي الختام
ANOVA هي أداة قوية لتحليل الاختلافات بين متوسطات المجموعة، وهي ضرورية عند مقارنة أكثر من متوسطين للعينة. يقوم ANOVA أحادي الاتجاه بتقييم تأثير عامل واحد على نتيجة مستمرة، بينما يقوم ANOVA ثنائي الاتجاه بتوسيع هذا التحليل ليأخذ في الاعتبار عاملين وتأثيرات تفاعلهما. إن فهم هذه الاختلافات يمكّن الباحثين من اختيار النهج التحليلي الأنسب لتصاميمهم التجريبية وأسئلتهم البحثية.
الأسئلة المتكررة
A. ANOVA تعني تحليل التباين، وهي طريقة إحصائية تستخدم لتحليل الاختلافات بين وسائل المجموعة. يتم استخدامه عند مقارنة المتوسطات عبر ثلاث مجموعات أو أكثر لتحديد ما إذا كانت هناك اختلافات كبيرة.
ج: يتم استخدام ANOVA أحادي الاتجاه عندما يكون لديك متغير مستقل فئوي (عامل) بمستويات متعددة وتريد مقارنة وسائل هذه المستويات. على سبيل المثال، مقارنة فعالية العلاجات المختلفة على نتيجة واحدة.
ج: يتم استخدام ANOVA ثنائي الاتجاه عندما يكون لديك متغيرين مستقلين فئويين (عوامل) وتريد تحليل تأثيرهما على متغير تابع مستمر، بالإضافة إلى التفاعل بين العاملين. إنه مفيد لدراسة التأثيرات المجمعة لعاملين على النتيجة.
A. تشير القيمة p في ANOVA إلى احتمال مراقبة البيانات إذا كانت الفرضية الصفرية (لا يوجد فرق كبير بين وسائل المجموعة) صحيحة. تشير القيمة p المنخفضة (<0.05) إلى وجود أدلة مهمة لرفض فرضية العدم واستنتاج أن هناك اختلافات بين المجموعات.)
أ. إحصائية F في ANOVA تقيس نسبة التباين بين المجموعات إلى التباين داخل المجموعات. تشير إحصائية F الأعلى إلى أن التباين بين المجموعات أكبر بالنسبة إلى التباين داخل المجموعات، مما يشير إلى وجود فرق كبير بين وسائل المجموعة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/04/one-way-and-two-way-analysis-of-variance-anova/

