أوبن سيرش هي مجموعة برامج مفتوحة المصدر قابلة للتطوير ومرنة وقابلة للتوسيع لتطبيقات البحث والتحليلات والمراقبة الأمنية والمراقبة ، ومرخصة بموجب ترخيص Apache 2.0. وهو يتألف من محرك بحث ، OpenSearch ، الذي يقدم بحثًا وتجميعات بزمن انتقال منخفض ، ولوحات تحكم OpenSearch ، وأداة عرض مرئي ولوحة معلومات ، ومجموعة من المكونات الإضافية التي توفر إمكانات متقدمة مثل التنبيه ، والتحكم الدقيق في الوصول ، والملاحظة ، ومراقبة الأمان ، و ناقلات التخزين والمعالجة. خدمة Amazon OpenSearch هي خدمة مُدارة بالكامل تجعل من السهل نشر OpenSearch وتوسيع نطاقها وتشغيلها في سحابة AWS.
بصفتك مستخدمًا نهائيًا ، عند استخدامك لإمكانيات البحث في OpenSearch ، فإنك تضع هدفًا في ذهنك عمومًا - وهو شيء تريد تحقيقه. على طول الطريق ، يمكنك استخدام OpenSearch لجمع المعلومات لدعم تحقيق هذا الهدف (أو ربما تكون المعلومات هي الهدف الأصلي). لقد اعتدنا جميعًا على واجهة "مربع البحث" ، حيث تكتب بعض الكلمات ، ويعيد محرك البحث النتائج بناءً على مطابقة كلمة إلى كلمة. لنفترض أنك تريد شراء أريكة لقضاء أمسيات مريحة مع عائلتك حول المدفأة. تذهب إلى Amazon.com وتكتب "مكان مريح للجلوس بجوار النار". لسوء الحظ ، إذا أجريت هذا البحث على Amazon.com ، فستحصل على عناصر مثل حفر النار ومراوح التدفئة والديكورات المنزلية - وليس ما كنت تقصده. تكمن المشكلة في أن مصنعي الأريكة ربما لم يستخدموا الكلمات "دافئ" و "مكان" و "جلوس" و "نار" في عناوين منتجاتهم أو أوصافها.
في السنوات الأخيرة ، أصبحت تقنيات التعلم الآلي (ML) شائعة بشكل متزايد لتحسين البحث. من بينها استخدام نماذج التضمين ، وهو نوع من النماذج يمكنه ترميز مجموعة كبيرة من البيانات في فضاء ذي أبعاد n حيث يتم ترميز كل كيان في متجه ، ونقطة بيانات في تلك المساحة ، وتنظيمها بحيث تكون الكيانات المتشابهة اقرب معا. يمكن لنموذج التضمين ، على سبيل المثال ، ترميز دلالات مجموعة. من خلال البحث عن المتجهات الأقرب إلى وثيقة مشفرة - البحث عن أقرب جوار k (k-NN) - يمكنك العثور على المستندات الأكثر تشابهًا من الناحية المعنوية. يمكن أن تدعم نماذج التضمين المتطورة طرائق متعددة ، على سبيل المثال ، ترميز صورة ونص كتالوج المنتج وتمكين مطابقة التشابه في كلا الطريقتين.
توفر قاعدة بيانات المتجهات بحثًا فعالاً عن تشابه المتجهات من خلال توفير فهارس متخصصة مثل فهارس k-NN. كما يوفر وظائف أخرى لقاعدة البيانات مثل إدارة بيانات المتجه جنبًا إلى جنب مع أنواع البيانات الأخرى وإدارة عبء العمل والتحكم في الوصول والمزيد. يوفر المكون الإضافي k-NN الخاص بـ OpenSearch وظائف قاعدة بيانات المتجه الأساسية لـ OpenSearch، لذلك عندما يبحث عميلك عن "مكان مريح للجلوس بجوار النار" في الكتالوج الخاص بك ، يمكنك ترميز هذه المطالبة واستخدام OpenSearch لإجراء استعلام جار أقرب إلى السطح على الأريكة الزرقاء التي يبلغ ارتفاعها 8 أقدام مع وجود صور فوتوغرافية مرتبة من قبل المصمم المواقد.
استخدام خدمة OpenSearch كقاعدة بيانات متجه
مع إمكانيات قاعدة بيانات المتجه في OpenSearch Service ، يمكنك تنفيذ البحث الدلالي ، والجيل المعزز للاسترداد (RAG) مع LLMs ، ومحركات التوصية ، والبحث في الوسائط الغنية.
البحث الدلالي
باستخدام البحث الدلالي ، يمكنك تحسين ملاءمة النتائج المسترجعة باستخدام التضمينات القائمة على اللغة في مستندات البحث. يمكنك تمكين عملاء البحث لديك من استخدام استعلامات اللغة الطبيعية ، مثل "مكان مريح للجلوس بجوار النار" للعثور على أريكتهم الزرقاء التي يبلغ طولها 8 أقدام. لمزيد من المعلومات ، يرجى الرجوع إلى بناء محرك بحث دلالي في OpenSearch لمعرفة كيف يمكن أن يحقق البحث الدلالي تحسينًا في الملاءمة بنسبة 15٪ ، وفقًا للقياس بـ ربح تراكمي مخصوم طبيعي (nDCG) المقاييس مقارنة بالبحث عن الكلمات الرئيسية. للحصول على مثال ملموس ، لدينا تحسين ملاءمة البحث باستخدام ML في Amazon OpenSearch Service تستكشف ورشة العمل الفرق بين البحث الدلالي والكلمات الرئيسية ، بناءً على ملف تمثيلات التشفير ثنائي الاتجاه من المحولات (BERT) النموذج ، مستضاف بواسطة الأمازون SageMaker لإنشاء ناقلات وتخزينها في OpenSearch. تستخدم ورشة العمل إجابات أسئلة المنتج كمثال لإظهار كيف يؤدي البحث باستخدام الكلمات الرئيسية باستخدام الكلمات الرئيسية / عبارات الاستعلام إلى بعض النتائج غير ذات الصلة. البحث الدلالي قادر على استرداد المزيد من الوثائق ذات الصلة من خلال مطابقة سياق ودلالات الاستعلام. يُظهر الرسم البياني التالي نموذجًا معماريًا لتطبيق بحث دلالي باستخدام OpenSearch Service كقاعدة بيانات متجه.

استرجاع معزز الجيل مع LLMs
RAG هي طريقة لبناء روبوتات محادثة تعمل بالذكاء الاصطناعي جديرة بالثقة باستخدام LLMs التوليدية مثل OpenAI أو ChatGPT أو نص أمازون تيتان. مع ظهور LLMs التوليدية ، يبحث مطورو التطبيقات عن طرق للاستفادة من هذه التكنولوجيا المبتكرة. تتضمن إحدى حالات الاستخدام الشائعة تقديم تجارب محادثة من خلال وكلاء أذكياء. ربما تكون مزودًا للبرامج ولديك قواعد معرفية لمعلومات المنتج أو الخدمة الذاتية للعملاء أو معرفة مجال الصناعة مثل قواعد الإبلاغ الضريبي أو المعلومات الطبية حول الأمراض والعلاجات. توفر تجربة البحث الحواري واجهة سهلة الاستخدام للمستخدمين للتنقل بين المعلومات من خلال الحوار والأسئلة والأجوبة. تعد LLMs التوليدية من تلقاء نفسها عرضة لذلك الهلوسة- موقف يولد فيه النموذج استجابة معقولة ولكنها غير صحيحة من الناحية الواقعية. تحل RAG هذه المشكلة من خلال استكمال LLMs التوليدية بقاعدة معرفة خارجية يتم بناؤها عادةً باستخدام قاعدة بيانات متجهية تم ترطيبها بمقالات معرفية مشفرة بالناقل.
كما هو موضح في الرسم التخطيطي التالي ، يبدأ سير عمل الاستعلام بسؤال تم ترميزه واستخدامه لاسترداد المقالات المعرفية ذات الصلة من قاعدة بيانات المتجه. يتم إرسال هذه النتائج إلى LLM التوليدية التي تتمثل وظيفتها في زيادة تلك النتائج ، عادةً عن طريق تلخيص النتائج كاستجابة محادثة. من خلال استكمال النموذج التوليدي بقاعدة معرفية ، تقوم RAG بتأسيس النموذج على الحقائق لتقليل الهلوسة. يمكنك معرفة المزيد حول بناء حل RAG في وحدة الاسترجاع المعزز في ورشة عمل البحث الدلالي الخاصة بنا.
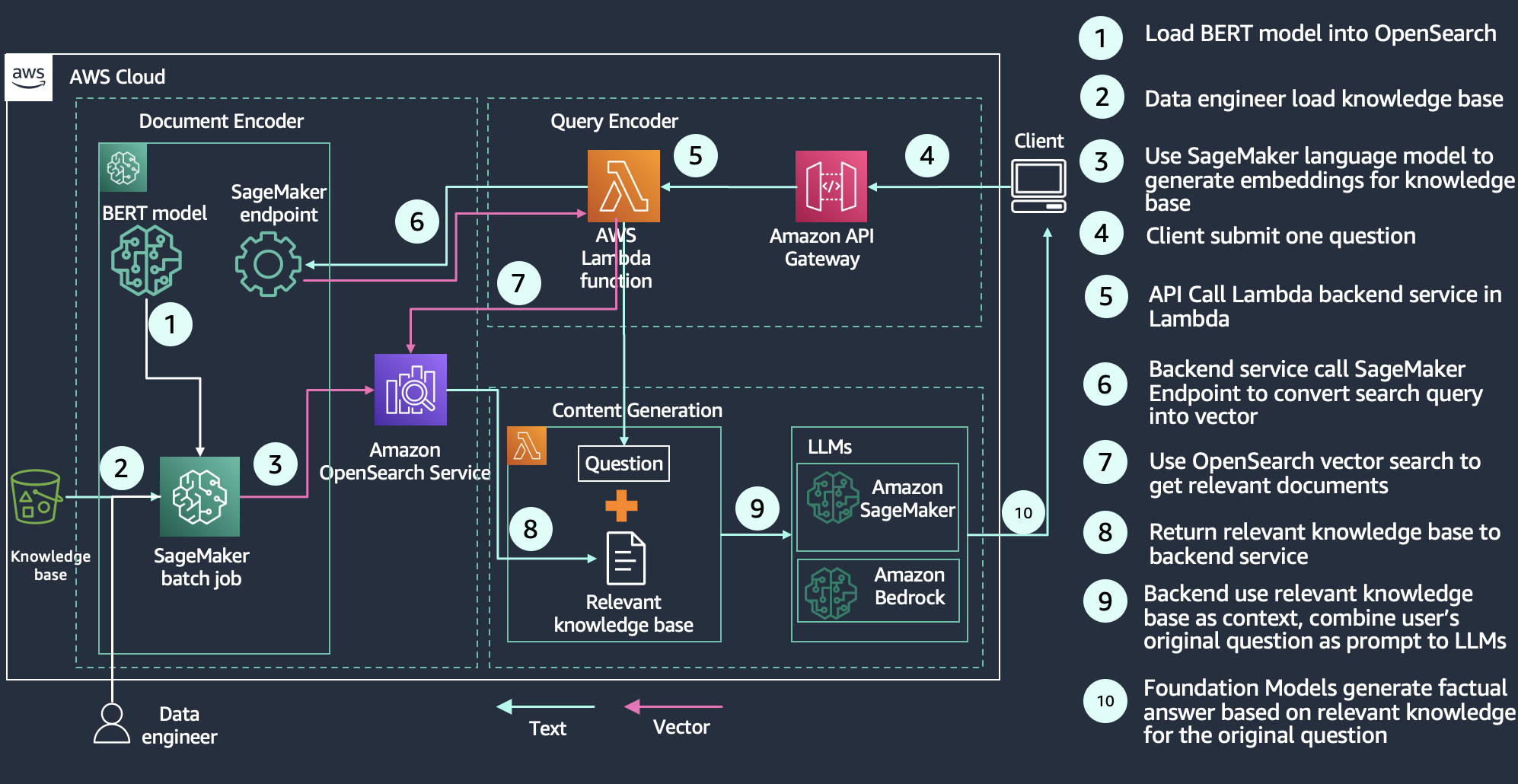
محرك التوصية
تعتبر التوصيات مكونًا شائعًا في تجربة البحث ، خاصة لتطبيقات التجارة الإلكترونية. يمكن أن تؤدي إضافة ميزة تجربة المستخدم مثل "المزيد من هذا القبيل" أو "العملاء الذين اشتروا هذا أيضًا اشتروا ذلك" إلى تحقيق أرباح إضافية من خلال الحصول على العملاء ما يريدون. يستخدم مهندسو البحث العديد من التقنيات والتقنيات لبناء التوصيات ، بما في ذلك الشبكة العصبية العميقة (DNN) الخوارزميات القائمة على التوصية مثل نموذج شبكي عصبي مكون من برجين, يوتيوب. يشفر نموذج التضمين المُدرَّب المنتجات ، على سبيل المثال ، في مساحة التضمين حيث تُعتبر المنتجات التي يتم شراؤها معًا بشكل متكرر أكثر تشابهًا ، وبالتالي يتم تمثيلها كنقاط بيانات أقرب معًا في مساحة التضمين. امكانية اخرى
هو أن حفلات الزفاف للمنتج تستند إلى تشابه في التصنيف المشترك بدلاً من نشاط الشراء. يمكنك استخدام بيانات التقارب هذه من خلال حساب تشابه المتجه بين تضمين مستخدم معين والمتجهات في قاعدة البيانات لإرجاع العناصر الموصى بها. يُظهر الرسم البياني التالي نموذجًا معماريًا لبناء محرك توصية باستخدام OpenSearch كمتجر متجه.
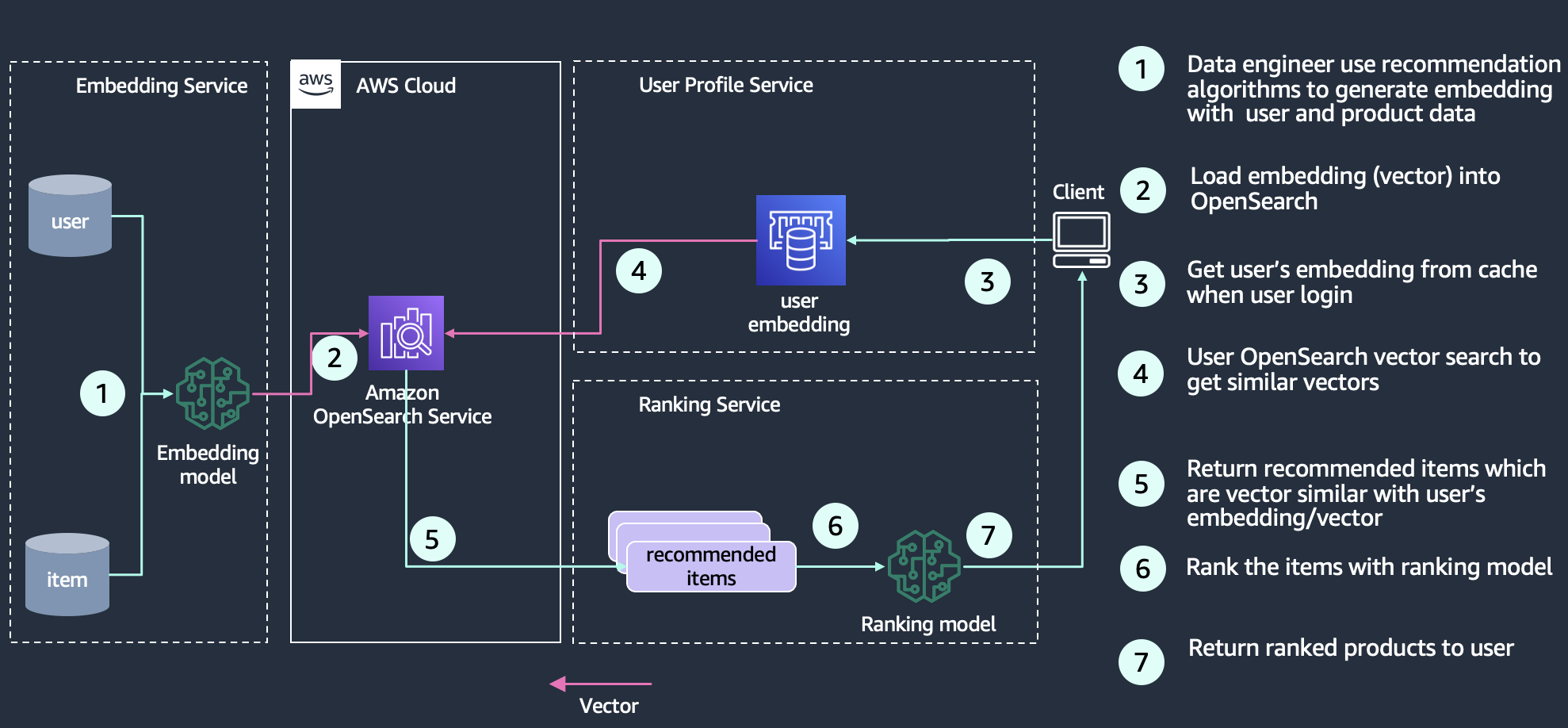
البحث عن وسائل الإعلام
يمكّن البحث عن الوسائط المستخدمين من الاستعلام عن محرك البحث باستخدام الوسائط الغنية مثل الصور والصوت والفيديو. يشبه تنفيذه البحث الدلالي - يمكنك إنشاء تضمين متجه لمستندات البحث الخاصة بك ثم الاستعلام عن خدمة OpenSearch Service باستخدام ناقل. الفرق هو أنك تستخدم شبكة عصبية عميقة لرؤية الكمبيوتر (على سبيل المثال الشبكة العصبية التلافيفية (CNN)) مثل ريسنيت لتحويل الصور إلى نواقل. يُظهر الرسم البياني التالي مثالاً معمارية لبناء بحث عن الصور باستخدام OpenSearch كمتجر متجه.
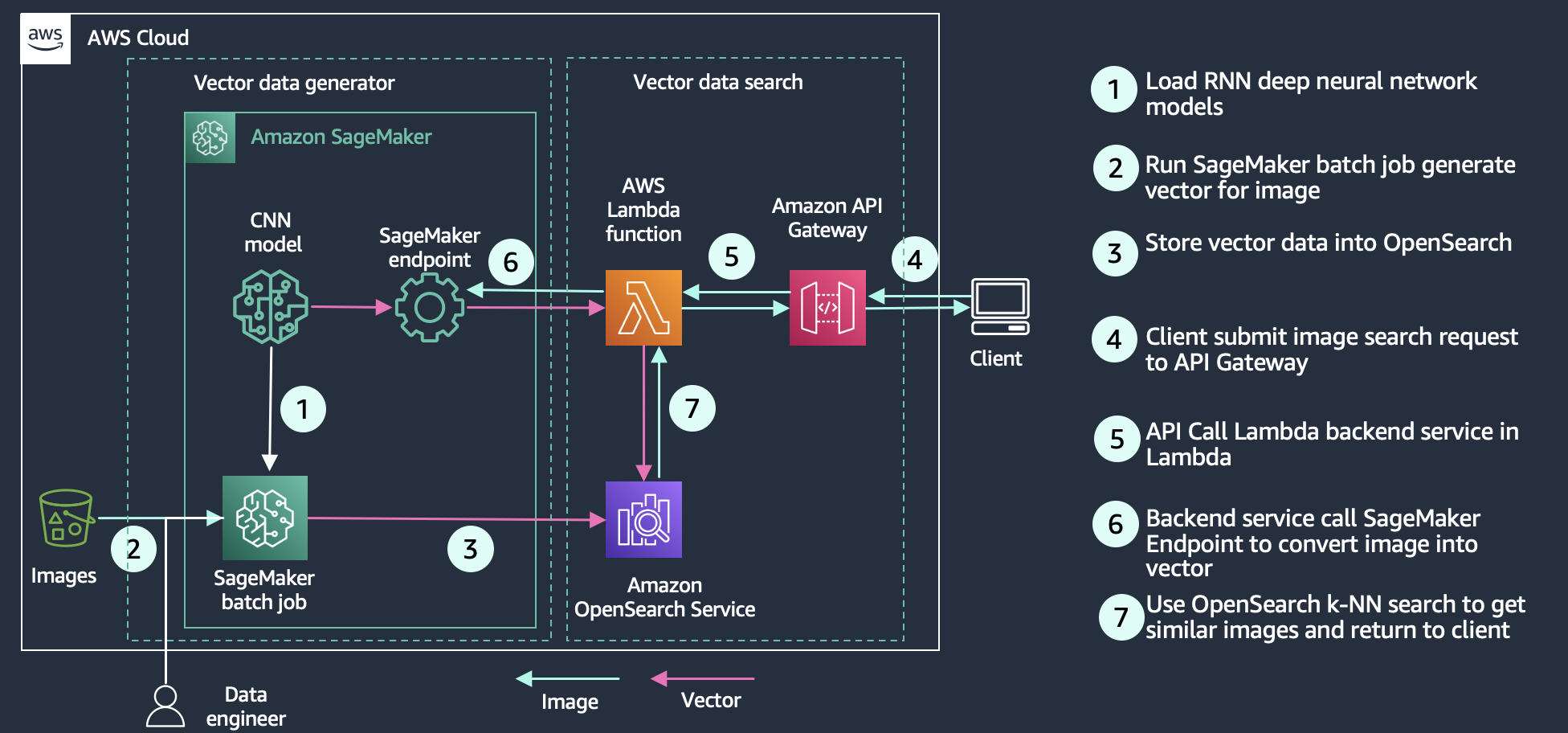
فهم التكنولوجيا
يستخدم OpenSearch خوارزميات أقرب الجيران (ANN) التقريبية من نمسليب, فايسو لوسين مكتبات لتشغيل بحث k-NN. تستخدم طرق البحث هذه ANN لتحسين زمن انتقال البحث لمجموعات البيانات الكبيرة. من بين طرق البحث الثلاث التي يوفرها المكون الإضافي k-NN ، توفر هذه الطريقة أفضل قابلية توسعة للبحث لمجموعات البيانات الكبيرة. تفاصيل المحرك كما يلي:
- مكتبة الفضاء غير المترية (NMSLIB) - تنفذ NMSLIB خوارزمية HNSW ANN
- البحث عن تشابه الذكاء الاصطناعي على Facebook (FAISS) - تنفذ FAISS كلاً من خوارزميات HNSW و IVF ANN
- لوسين - تطبق لوسين خوارزمية HNSW
كل محرك من المحركات الثلاثة المستخدمة في البحث التقريبي k-NN له سماته الخاصة التي تجعل استخدامه أكثر منطقية من المحركات الأخرى في حالة معينة. يمكنك اتباع المعلومات العامة الواردة في هذا القسم للمساعدة في تحديد المحرك الذي سيلبي متطلباتك على أفضل وجه.
بشكل عام ، يجب اختيار NMSLIB و FAISS لحالات الاستخدام على نطاق واسع. يعد Lucene خيارًا جيدًا لعمليات النشر الأصغر ، ولكنه يوفر مزايا مثل التصفية الذكية حيث يتم تطبيق إستراتيجية التصفية المثلى - التصفية المسبقة أو ما بعد التصفية أو k-NN الدقيق - تلقائيًا حسب الموقف. يلخص الجدول التالي الاختلافات بين كل خيار.
| . |
NMSLIB-HNSW |
فايس-HNSW |
فايس-IVF |
لوسين- HNSW |
|
البعد الأقصى |
16,000 |
16,000 |
16,000 |
1024 |
|
الفرز |
مرشح آخر |
مرشح آخر |
مرشح آخر |
تصفية أثناء البحث |
|
التدريب مطلوب |
لا |
لا |
نعم |
لا |
|
مقاييس التشابه |
l2 ، منتج داخلي ، cosinesimil ، l1 ، لينف |
l2 ، المنتج الداخلي |
l2 ، المنتج الداخلي |
l2 ، جيب تمام |
|
حجم المتجه |
عشرات المليارات |
عشرات المليارات |
عشرات المليارات |
<عشرة ملايين |
|
زمن انتقال الفهرسة |
منخفض |
منخفض |
أدنى |
منخفض |
|
استعلام الكمون والجودة |
كمون منخفض وجودة عالية |
كمون منخفض وجودة عالية |
كمون منخفض وجودة منخفضة |
الكمون العالي والجودة العالية |
|
ضغط المتجهات |
شقة |
شقة المنتج الكمي |
شقة المنتج الكمي |
شقة |
|
استهلاك الذاكرة |
مرتفع |
مرتفع منخفض مع PQ |
متوسط منخفض مع PQ |
مرتفع |
البحث التقريبي والدقيق أقرب الجيران
يدعم البرنامج المساعد k-NN OpenSearch Service ثلاث طرق مختلفة للحصول على أقرب جيران k من فهرس المتجهات: تقريبي k-NN ، ونص النقاط (بالضبط k-NN) ، وملحقات غير مؤلمة (بالضبط k-NN).
التقريبي k-NN
تأخذ الطريقة الأولى نهجًا تقريبيًا لأقرب جيران - فهي تستخدم واحدة من عدة خوارزميات لإرجاع أقرب k التقريبي إلى متجه الاستعلام. عادةً ما تضحي هذه الخوارزميات بسرعة الفهرسة ودقة البحث مقابل مزايا الأداء مثل زمن الوصول المنخفض ، وبصمات الذاكرة الأصغر ، والمزيد من البحث القابل للتوسع. يعد k-NN التقريبي هو الخيار الأفضل لعمليات البحث عبر الفهارس الكبيرة (أي مئات الآلاف من المتجهات أو أكثر) التي تتطلب زمن انتقال منخفض. يجب ألا تستخدم k-NN التقريبي إذا كنت ترغب في تطبيق مرشح على الفهرس قبل البحث في k-NN ، مما يقلل بشكل كبير من عدد المتجهات المراد البحث عنها. في هذه الحالة ، يجب عليك استخدام طريقة البرنامج النصي للدرجات أو ملحقات غير مؤلمة.
يسجل السيناريو
الطريقة الثانية يوسع وظيفة البرنامج النصي لتسجيل نقاط خدمة OpenSearch لتشغيل القوة الغاشمة ، ابحث بالضبط عن k-NN knn_vector الحقول أو الحقول التي يمكن أن تمثل كائنات ثنائية. باستخدام هذا الأسلوب ، يمكنك تشغيل بحث k-NN على مجموعة فرعية من المتجهات في الفهرس الخاص بك (يشار إليها أحيانًا باسم البحث قبل التصفية). يُفضل هذا الأسلوب لعمليات البحث على مجموعات أصغر من المستندات أو عند الحاجة إلى تصفية مسبقة. قد يؤدي استخدام هذا النهج في الفهارس الكبيرة إلى ارتفاع وقت الاستجابة.
ملحقات غير مؤلمة
الطريقة الثالثة تضيف وظائف المسافة كملحقات غير مؤلمة يمكنك استخدامها في مجموعات أكثر تعقيدًا. على غرار البرنامج النصي لتسجيل النقاط k-NN ، يمكنك استخدام هذه الطريقة لأداء القوة الغاشمة ، والبحث الدقيق عن k-NN عبر فهرس ، والذي يدعم أيضًا التصفية المسبقة. يحتوي هذا الأسلوب على أداء استعلام أبطأ قليلاً مقارنةً بالبرنامج النصي لتسجيل نقاط k-NN. إذا كانت حالة الاستخدام الخاصة بك تتطلب مزيدًا من التخصيص على النتيجة النهائية ، فيجب عليك استخدام هذا الأسلوب فوق البرنامج النصي لتسجيل النقاط k-NN.
خوارزميات البحث المتجه
الطريقة البسيطة للعثور على نواقل مماثلة هي استخدام k- أقرب الجيران (k-NN) الخوارزميات ، والتي تحسب المسافة بين متجه الاستعلام والمتجهات الأخرى في قاعدة بيانات المتجه. كما ذكرنا سابقًا ، تستخدم طرق البحث عن امتدادات k-NN النصي وطرق البحث غير المؤلمة خوارزميات k-NN الدقيقة تحت الغطاء. ومع ذلك ، في حالة مجموعات البيانات الكبيرة للغاية ذات الأبعاد العالية ، فإن هذا يخلق مشكلة تحجيم تقلل من كفاءة البحث. يمكن لأساليب البحث في أقرب الجيران (ANN) التغلب على ذلك من خلال استخدام الأدوات التي تعيد هيكلة الفهارس بشكل أكثر كفاءة وتقليل أبعاد المتجهات القابلة للبحث. هناك خوارزميات بحث ANN مختلفة. على سبيل المثال ، التجزئة الحساسة للمنطقة المحلية ، والمستندة إلى الشجرة ، والقائمة على الكتلة ، والمستندة إلى الرسم البياني. تنفذ OpenSearch خوارزميتين من خوارزميات ANN: العوالم الصغيرة القابلة للملاحة الهرمية (HNSW) ونظام الملفات المقلوبة (IVF). للحصول على شرح أكثر تفصيلاً عن كيفية عمل خوارزميات HNSW و IVF في OpenSearch ، راجع منشور المدونة "اختر خوارزمية k-NN لحالة استخدامك على نطاق مليار مع OpenSearch".
عوالم صغيرة قابلة للملاحة هرمية
تعد خوارزمية HNSW واحدة من أكثر الخوارزميات شيوعًا لبحث ANN. الفكرة الأساسية للخوارزمية هي بناء رسم بياني بحواف تربط متجهات الفهرس القريبة من بعضها البعض. بعد ذلك ، عند البحث ، يتم اجتياز هذا الرسم البياني جزئيًا للعثور على أقرب الجيران التقريبي لمتجه الاستعلام. لتوجيه الاجتياز نحو أقرب جيران للاستعلام ، تزور الخوارزمية دائمًا أقرب مرشح إلى متجه الاستعلام التالي.
ملف مقلوب
تفصل خوارزمية التلقيح الاصطناعي متجهات الفهرس الخاصة بك إلى مجموعة من المجموعات ، ثم لتقليل وقت البحث ، لا تبحث إلا من خلال مجموعة فرعية من هذه المجموعات. ومع ذلك ، إذا قسمت الخوارزمية المتجهات بشكل عشوائي إلى مجموعات مختلفة ، وبحثت فقط في مجموعة فرعية منها ، فسيؤدي ذلك إلى تقريب ضعيف. تستخدم خوارزمية التلقيح الاصطناعي أسلوبًا أكثر أناقة. أولاً ، قبل بدء الفهرسة ، تقوم بتعيين متجه تمثيلي لكل مجموعة. عند فهرسة المتجه ، تتم إضافته إلى الحاوية التي بها أقرب متجه تمثيلي. بهذه الطريقة ، يتم وضع المتجهات الأقرب لبعضها البعض تقريبًا في الدلاء نفسها أو القريبة.
مقاييس تشابه المتجهات
تستخدم جميع محركات البحث مقياس تشابه لترتيب النتائج وفرزها وإحضار النتائج الأكثر صلة إلى الأعلى. عند استخدام استعلام نص عادي ، يسمى مقياس التشابه TF-IDF ، والذي يقيس أهمية المصطلحات في الاستعلام ويولد درجة بناءً على عدد التطابقات النصية. عندما يتضمن استعلامك متجهًا ، تكون مقاييس التشابه مكانية بطبيعتها ، وتستفيد من القرب في مساحة المتجه. يدعم OpenSearch العديد من مقاييس التشابه أو المسافة:
- المسافة الإقليدية - مسافة الخط المستقيم بين النقطتين.
- المسافة L1 (مانهاتن) - مجموع الاختلافات بين جميع مكونات المتجه. تقيس المسافة L1 عدد كتل المدينة المتعامدة التي تحتاجها للعبور من النقطة أ إلى النقطة ب.
- مسافة L- اللانهاية (رقعة الشطرنج) - عدد الحركات التي قد يقوم بها الملك على رقعة الشطرنج ذات الأبعاد n. إنها تختلف عن المسافة الإقليدية على الأقطار - فالخطوة القطرية على رقعة الشطرنج ثنائية الأبعاد تبعد 2 وحدة إقليدية ، ولكن على بعد وحدتين L-infinity.
- منتج داخلي - حاصل ضرب مقادير متجهين وجيب الزاوية بينهما. عادة ما تستخدم لمعالجة تشابه متجه (NLP) للغة الطبيعية.
- تشابه جيب التمام - جيب تمام الزاوية بين متجهين في فراغ متجه.
- مسافة هامينج - بالنسبة إلى المتجهات ثنائية التشفير ، عدد البتات التي تختلف بين المتجهين.
ميزة OpenSearch كقاعدة بيانات متجه
عند استخدام OpenSearch Service كقاعدة بيانات متجه ، يمكنك الاستفادة من ميزات الخدمة مثل قابلية الاستخدام وقابلية التوسع والتوافر وقابلية التشغيل البيني والأمان. الأهم من ذلك ، يمكنك استخدام ميزات البحث في OpenSearch لتحسين تجربة البحث. على سبيل المثال ، يمكنك استخدام ملفات تعلم الرتبة في OpenSearch لدمج بيانات سلوك النقر إلى الظهور للمستخدم في تطبيق البحث وتحسين ملاءمة البحث. يمكنك أيضًا الجمع بين البحث عن نص OpenSearch وإمكانيات البحث في المتجهات للبحث في المستندات باستخدام الكلمات الأساسية والتشابه الدلالي. يمكنك أيضًا استخدام الحقول الأخرى في الفهرس لتصفية المستندات لتحسين الصلة. للمستخدمين المتقدمين ، يمكنك استخدام نموذج تسجيل مختلط للجمع درجة ملاءمة OpenSearch المستندة إلى النصوص ، والمحسوبة بوظيفة Okapi BM25 ونتائج البحث المتجه لتحسين ترتيب نتائج البحث الخاصة بك.
مقياس وحدود
OpenSearch كقاعدة بيانات ناقلات تدعم المليارات من سجلات المتجهات. ضع في اعتبارك الآلة الحاسبة التالية فيما يتعلق بعدد المتجهات والأبعاد لحجم المجموعة الخاصة بك.
عدد النواقل
تستفيد OpenSearch VectorDB من إمكانيات التجزئة الخاصة بـ OpenSearch ويمكنها توسيع نطاق المليارات من المتجهات في زمن انتقال مكون من رقم واحد بالمللي ثانية عن طريق تجزئة المتجهات والقياس أفقيًا عن طريق إضافة المزيد من العقد. عدد المتجهات التي يمكن احتواؤها في جهاز واحد هو دالة لتوافر الذاكرة خارج الكومة على الجهاز. سيعتمد عدد العقد المطلوبة على حجم الذاكرة التي يمكن استخدامها للخوارزمية لكل عقدة والمقدار الإجمالي للذاكرة التي تتطلبها الخوارزمية. كلما زاد عدد العقد ، زادت الذاكرة والأداء الأفضل. يتم حساب مقدار الذاكرة المتاحة لكل عقدة على شكل memory_available = (node_memory - jvm_size) * circuit_breaker_limit، بالمعايير التالية:
- node_memory - إجمالي ذاكرة المثيل.
- jvm_size - حجم كومة OpenSearch JVM. تم تعيين هذا على نصف ذاكرة الوصول العشوائي للمثيل ، بحد أقصى 32 جيجابايت تقريبًا.
- قاطع_دائرة_حد - عتبة استخدام الذاكرة الأصلية لقاطع الدائرة. تم ضبط هذا على 0.5.
يعتمد تقدير ذاكرة الكتلة الإجمالية على العدد الإجمالي لسجلات وخوارزميات المتجهات. HNSW و IVF لهما متطلبات ذاكرة مختلفة. يمكنك الرجوع إلى تقدير الذاكرة لمزيد من التفاصيل.
عدد الأبعاد
حد البعد الحالي لـ OpenSearch لحقل المتجه knn_vector هو 16,000 بعد. يتم تمثيل كل بُعد على أنه عائم 32 بت. كلما زادت الأبعاد ، زادت الذاكرة التي ستحتاج إليها للفهرسة والبحث. يتم تحديد عدد الأبعاد عادةً بواسطة نماذج التضمين التي تترجم الكيان إلى متجه. هناك الكثير من الخيارات للاختيار من بينها عند بناء ملف knn_vector مجال. لتحديد الطرق والمعلمات الصحيحة للاختيار ، ارجع إلى اختيار الطريقة الصحيحة.
قصص العملاء:
أمازون الموسيقى
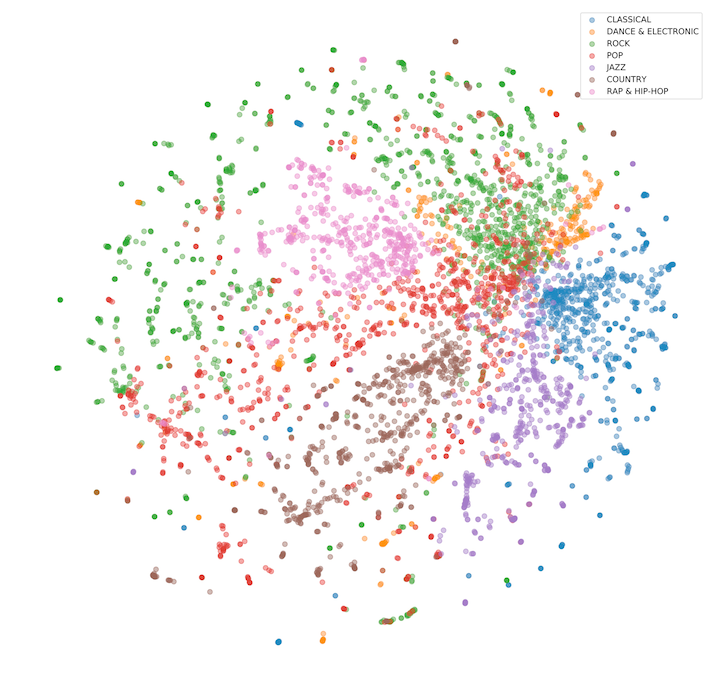
تعمل Amazon Music دائمًا على الابتكار لتزويد العملاء بتجارب فريدة وشخصية. تتمثل إحدى مناهج Amazon Music في التوصيات الموسيقية في إعادة مزج ابتكار كلاسيكي من Amazon ، التصفية التعاونية من عنصر إلى عنصر، وقواعد البيانات المتجهة. باستخدام البيانات المجمعة بناءً على سلوك استماع المستخدم ، أنشأت Amazon Music نموذج تضمين يشفر المقطوعات الموسيقية وتمثيلات العملاء في مساحة متجه حيث تمثل المتجهات المجاورة مسارات متشابهة. تم ترميز 100 مليون أغنية في متجهات ، وفهرستها في OpenSearch ، وتقديمها عبر مناطق جغرافية متعددة لتشغيل التوصيات في الوقت الفعلي. تدير OpenSearch حاليًا 1.05 مليار متجه وتدعم ذروة تحميل تبلغ 7,100 استعلام متجه في الثانية لتشغيل توصيات Amazon Music.
لا يزال عامل التصفية التعاوني من عنصر إلى عنصر من بين الأساليب الأكثر شيوعًا لتوصيات المنتجات عبر الإنترنت نظرًا لفعاليته في التوسع إلى قواعد العملاء الكبيرة وكتالوجات المنتجات. يسهّل OpenSearch تشغيل وزيادة قابلية التوسّع الخاصة بالتوصية من خلال توفير بنية تحتية قابلة للتوسيع ومؤشرات k-NN التي تنمو خطيًا فيما يتعلق بعدد المسارات والبحث عن التشابه في الوقت اللوغاريتمي.
يوضح الشكل التالي المساحة عالية الأبعاد التي تم إنشاؤها بواسطة التضمين المتجه.
حماية العلامة التجارية في أمازون
تسعى أمازون جاهدة لتقديم تجربة التسوق الأكثر جدارة بالثقة في العالم ، حيث تقدم للعملاء أكبر مجموعة ممكنة من المنتجات الأصلية. لكسب ثقة عملائنا والحفاظ عليها ، نحظر بشدة بيع المنتجات المقلدة ، ونواصل الاستثمار في الابتكارات التي تضمن وصول المنتجات الأصلية فقط إلى عملائنا. تعمل برامج حماية العلامة التجارية في أمازون على بناء الثقة مع العلامات التجارية من خلال تمثيل علامتها التجارية بدقة وحمايتها بالكامل. نحن نسعى جاهدين لضمان أن التصور العام يعكس التجربة الجديرة بالثقة التي نقدمها. تركز إستراتيجية حماية علامتنا التجارية على أربع ركائز: (1) الضوابط الاستباقية (2) أدوات قوية لحماية العلامات التجارية (3) محاسبة الفاعلين السيئين (4) حماية العملاء وتثقيفهم. تعد Amazon OpenSearch Service جزءًا أساسيًا من عناصر التحكم الاستباقية في Amazon.
في عام 2022 ، قامت تقنية أمازون الآلية بمسح أكثر من 8 مليارات محاولة تغيير يوميًا لصفحات تفاصيل المنتج بحثًا عن علامات إساءة الاستخدام المحتملة. وجدت عناصر التحكم الاستباقية الخاصة بنا أكثر من 99٪ من القوائم المحظورة أو المُزالة قبل أن تضطر العلامة التجارية إلى العثور عليها والإبلاغ عنها. تم الاشتباه في أن هذه القوائم احتيالية أو منتهكة أو مزيفة أو معرضة لخطر أشكال أخرى من إساءة الاستخدام. لإجراء عمليات المسح هذه ، ابتكرت أمازون أدوات تستخدم تقنيات متقدمة ومبتكرة ، بما في ذلك استخدام نماذج التعلم الآلي المتقدمة لأتمتة الكشف عن انتهاكات الملكية الفكرية في القوائم عبر متاجر أمازون على مستوى العالم. يتمثل أحد التحديات التقنية الرئيسية في تنفيذ مثل هذا النظام الآلي في القدرة على البحث عن الملكية الفكرية المحمية ضمن مجموعة ضخمة من المليار ناقل بطريقة سريعة وقابلة للتطوير وفعالة من حيث التكلفة. بالاستفادة من إمكانات قاعدة بيانات المتجه القابلة للتطوير في Amazon OpenSearch Service والبنية الموزعة ، نجحنا في تطوير خط أنابيب استيعاب يضم إجمالي 68 مليار متجه و 128 و 1024 بُعدًا في خدمة البحث المفتوح لتمكين العلامات التجارية والأنظمة الآلية من إجراء اكتشاف الانتهاك بشكل حقيقي. - الوقت ، من خلال واجهة برمجة تطبيقات بحث متاحة للغاية وسريعة (ثانوية).
وفي الختام
سواء كنت تقوم ببناء حل ذكاء اصطناعي عام ، أو تبحث عن وسائط غنية وصوت ، أو تجلب المزيد من البحث الدلالي إلى تطبيقك القائم على البحث ، فإن OpenSearch هي قاعدة بيانات متجهية قادرة. يدعم OpenSearch مجموعة متنوعة من المحركات والخوارزميات ومقاييس المسافة التي يمكنك استخدامها لبناء الحل الصحيح. يوفر OpenSearch محركًا قابلًا للتطوير يمكنه دعم البحث المتجه بزمن انتقال منخفض وما يصل إلى مليارات من المتجهات. من خلال OpenSearch وإمكانيات قاعدة بيانات Vector الخاصة به ، يمكن للمستخدمين العثور على الأريكة الزرقاء التي يبلغ ارتفاعها 8 أقدام بسهولة ، والاسترخاء بجوار نيران دافئة.
حول المؤلف
 جون هاندلر هو مهندس حلول رئيسي رئيسي في Amazon Web Services ومقره بالو ألتو ، كاليفورنيا. يعمل Jon عن كثب مع OpenSearch و Amazon OpenSearch Service ، حيث يقدم المساعدة والإرشاد لمجموعة واسعة من العملاء الذين لديهم أعباء عمل بحث وتسجيل لأعباء عمل يريدون نقلها إلى سحابة AWS. قبل انضمامه إلى AWS ، تضمنت مسيرة جون المهنية كمطور برمجيات أربع سنوات من ترميز محرك بحث للتجارة الإلكترونية واسع النطاق. يحمل جون بكالوريوس الآداب من جامعة بنسلفانيا ، وماجستير في العلوم ودكتوراه في علوم الكمبيوتر والذكاء الاصطناعي من جامعة نورث وسترن.
جون هاندلر هو مهندس حلول رئيسي رئيسي في Amazon Web Services ومقره بالو ألتو ، كاليفورنيا. يعمل Jon عن كثب مع OpenSearch و Amazon OpenSearch Service ، حيث يقدم المساعدة والإرشاد لمجموعة واسعة من العملاء الذين لديهم أعباء عمل بحث وتسجيل لأعباء عمل يريدون نقلها إلى سحابة AWS. قبل انضمامه إلى AWS ، تضمنت مسيرة جون المهنية كمطور برمجيات أربع سنوات من ترميز محرك بحث للتجارة الإلكترونية واسع النطاق. يحمل جون بكالوريوس الآداب من جامعة بنسلفانيا ، وماجستير في العلوم ودكتوراه في علوم الكمبيوتر والذكاء الاصطناعي من جامعة نورث وسترن.
 جيانوي لي هو أخصائي تحليلات رئيسي TAM في Amazon Web Services. تقدم Jianwei خدمة استشارية للعملاء لمساعدة العملاء في تصميم وبناء منصة بيانات حديثة. تعمل Jianwei في مجال البيانات الضخمة كمطور برامج ومستشار وقائد تقني.
جيانوي لي هو أخصائي تحليلات رئيسي TAM في Amazon Web Services. تقدم Jianwei خدمة استشارية للعملاء لمساعدة العملاء في تصميم وبناء منصة بيانات حديثة. تعمل Jianwei في مجال البيانات الضخمة كمطور برامج ومستشار وقائد تقني.
 ديلان تونج هو مدير أول للمنتجات في AWS. إنه يعمل مع العملاء للمساعدة في دفع نجاحهم على منصة AWS من خلال القيادة الفكرية والتوجيه بشأن تصميم الحلول المصممة جيدًا. لقد أمضى معظم حياته المهنية في البناء على خبرته في إدارة البيانات والتحليلات من خلال العمل للقادة والمبتكرين في الفضاء.
ديلان تونج هو مدير أول للمنتجات في AWS. إنه يعمل مع العملاء للمساعدة في دفع نجاحهم على منصة AWS من خلال القيادة الفكرية والتوجيه بشأن تصميم الحلول المصممة جيدًا. لقد أمضى معظم حياته المهنية في البناء على خبرته في إدارة البيانات والتحليلات من خلال العمل للقادة والمبتكرين في الفضاء.
 فامشي فيجاي ناكيرثا هو مدير هندسة برمجيات يعمل على مشروع OpenSearch و Amazon OpenSearch Service. تشمل اهتماماته الأساسية الأنظمة الموزعة. وهو مساهم نشط في العديد من المكونات الإضافية ، مثل k-NN و GeoSpatial وخرائط لوحة القيادة.
فامشي فيجاي ناكيرثا هو مدير هندسة برمجيات يعمل على مشروع OpenSearch و Amazon OpenSearch Service. تشمل اهتماماته الأساسية الأنظمة الموزعة. وهو مساهم نشط في العديد من المكونات الإضافية ، مثل k-NN و GeoSpatial وخرائط لوحة القيادة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- تمويل EVM. واجهة موحدة للتمويل اللامركزي. الوصول هنا.
- مجموعة كوانتوم ميديا. تضخيم IR / PR. الوصول هنا.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/amazon-opensearch-services-vector-database-capabilities-explained/

