شركة KT هي واحدة من أكبر مزودي خدمات الاتصالات في كوريا الجنوبية، حيث تقدم مجموعة واسعة من الخدمات بما في ذلك الهاتف الثابت والاتصالات المحمولة والإنترنت وخدمات الذكاء الاصطناعي. يعد AI Food Tag من KT بمثابة حل لإدارة النظام الغذائي يعتمد على الذكاء الاصطناعي ويحدد نوع الطعام ومحتواه الغذائي في الصور باستخدام نموذج رؤية الكمبيوتر. يعتمد نموذج الرؤية هذا الذي طورته شركة KT على نموذج تم تدريبه مسبقًا بكمية كبيرة من بيانات الصور غير المسماة لتحليل المحتوى الغذائي ومعلومات السعرات الحرارية لمختلف الأطعمة. يمكن أن تساعد بطاقة AI Food Tag المرضى الذين يعانون من أمراض مزمنة مثل مرض السكري على إدارة وجباتهم الغذائية. استخدمت KT AWS و الأمازون SageMaker لتدريب نموذج AI Food Tag هذا بشكل أسرع 29 مرة من ذي قبل وتحسينه لنشر الإنتاج باستخدام تقنية التقطير النموذجية. في هذا المنشور، نصف رحلة تطوير نموذج KT ونجاحها باستخدام SageMaker.
التعريف بمشروع KT وتحديد المشكلة
يعتمد نموذج AI Food Tag الذي تم تدريبه مسبقًا بواسطة KT على بنية محولات الرؤية (ViT) ويحتوي على معلمات نموذجية أكثر من نموذج الرؤية السابق لتحسين الدقة. لتقليص حجم النموذج المخصص للإنتاج، تستخدم شركة KT تقنية تقطير المعرفة (KD) لتقليل عدد معلمات النموذج دون التأثير بشكل كبير على الدقة. مع تقطير المعرفة، يسمى النموذج المدرب مسبقًا أ نموذج المعلم، ويتم تدريب نموذج إخراج خفيف الوزن على أنه ملف نموذج الطالب، كما هو موضح في الشكل التالي. يحتوي نموذج الطالب خفيف الوزن على معلمات نموذج أقل من المعلم، مما يقلل من متطلبات الذاكرة ويسمح بالنشر على مثيلات أصغر وأقل تكلفة. يحافظ الطالب على دقة مقبولة ولو كانت أصغر من خلال التعلم من مخرجات نموذج المعلم.

يظل نموذج المعلم دون تغيير خلال KD، ولكن يتم تدريب نموذج الطالب باستخدام سجلات الإخراج الخاصة بنموذج المعلم كتسميات لحساب الخسارة. باستخدام نموذج KD هذا، يجب أن يكون كل من المعلم والطالب على ذاكرة GPU واحدة للتدريب. استخدمت KT في البداية وحدتي معالجة رسوميات (A100 80 جيجابايت) في بيئتها الداخلية المحلية لتدريب نموذج الطالب، لكن العملية استغرقت حوالي 40 يومًا لتغطية 300 حقبة. لتسريع التدريب وإنشاء نموذج للطلاب في وقت أقل، عقدت KT شراكة مع AWS. معًا، قامت الفرق بتقليل وقت التدريب النموذجي بشكل كبير. يصف هذا المنشور كيفية استخدام الفريق تدريب Amazon SageMakerأطلقت حملة مكتبة توازي بيانات SageMaker, الأمازون SageMaker المصححو ملف تعريف أمازون SageMaker لتطوير نموذج AI Food Tag خفيف الوزن بنجاح.
بناء بيئة تدريب موزعة باستخدام SageMaker
تدريب SageMaker عبارة عن بيئة تدريب للتعلم الآلي المُدار (ML) على AWS توفر مجموعة من الميزات والأدوات لتبسيط تجربة التدريب ويمكن أن تكون مفيدة في الحوسبة الموزعة، كما هو موضح في الرسم البياني التالي.
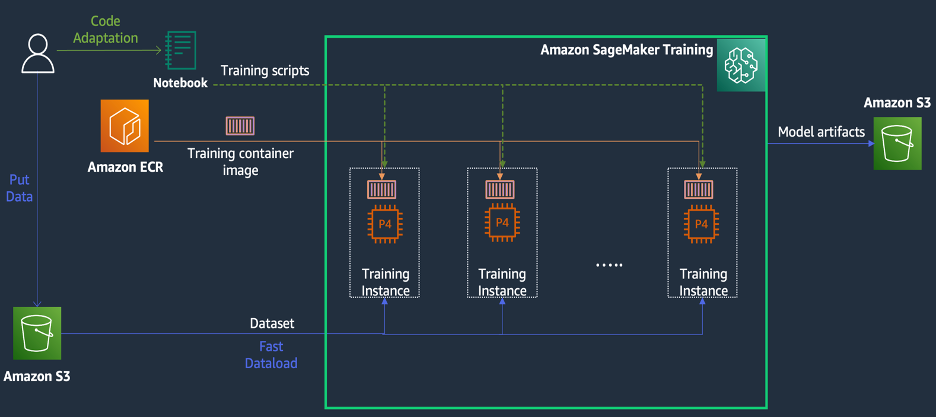
يمكن لعملاء SageMaker أيضًا الوصول إلى صور Docker المضمنة باستخدام العديد من أطر التعلم العميق المثبتة مسبقًا وحزم Linux وNCCL وPython اللازمة للتدريب النموذجي. يمكن لعلماء البيانات أو مهندسي تعلم الآلة الذين يرغبون في تشغيل تدريب نموذجي القيام بذلك دون تحمل عبء تكوين البنية التحتية للتدريب أو إدارة Docker وتوافق المكتبات المختلفة.
خلال ورشة عمل مدتها يوم واحد، تمكنا من إعداد تكوين تدريب موزع استنادًا إلى SageMaker ضمن حساب AWS الخاص بـ KT، وتسريع البرامج النصية لتدريب KT باستخدام مكتبة SageMaker Distributed Data Parallel (DDP)، وحتى اختبار مهمة تدريبية باستخدام 1 مل. مثيلات p4d.24xlarge. في هذا القسم، نصف تجربة KT في العمل مع فريق AWS واستخدام SageMaker لتطوير نموذجهم.
في إثبات المفهوم، أردنا تسريع مهمة التدريب باستخدام مكتبة SageMaker DDP، والتي تم تحسينها للبنية التحتية لـ AWS أثناء التدريب الموزع. للتغيير من PyTorch DDP إلى SageMaker DDP، ما عليك سوى الإعلان عن ملف torch_smddp الحزمة وتغيير الواجهة الخلفية إلى smddpكما هو موضح في الكود التالي:
لمعرفة المزيد حول مكتبة SageMaker DDP، راجع مكتبة توازي البيانات الخاصة بـ SageMaker.
تحليل أسباب بطء سرعة التدريب باستخدام SageMaker Debugger وProfiler
تتضمن الخطوة الأولى في تحسين عبء العمل التدريبي وتسريعه فهم وتشخيص مكان حدوث الاختناقات. بالنسبة لمهمة تدريب KT، قمنا بقياس وقت التدريب لكل تكرار لمحمل البيانات، والتمرير الأمامي، والتمرير الخلفي:
| وقت تكرار واحد - أداة تحميل البيانات: 1 ثانية، للأمام: 0.00053 ثانية، للخلف: 1.58002 ثوانى |
| وقت تكرار واحد - أداة تحميل البيانات: 2 ثانية، للأمام: 0.00063 ثانية، للخلف: 24.74539 ثوانى |
| وقت تكرار واحد - أداة تحميل البيانات: 3 ثانية، للأمام: 0.00061 ثانية، للخلف: 8.31253 ثوانى |
| وقت تكرار واحد - أداة تحميل البيانات: 4 ثانية، للأمام: 0.00060 ثانية، للخلف: 30.93830 ثوانى |
| وقت تكرار واحد - أداة تحميل البيانات: 5 ثانية، للأمام: 0.00080 ثانية، للخلف: 8.41030 ثوانى |
| وقت تكرار واحد - أداة تحميل البيانات: 6 ثانية، للأمام: 0.00067 ثانية، للخلف: 29.88415 ثوانى |
بالنظر إلى الوقت في الإخراج القياسي لكل تكرار، رأينا أن وقت تشغيل التمريرة الخلفية يتقلب بشكل كبير من التكرار إلى التكرار. هذا الاختلاف غير عادي ويمكن أن يؤثر على إجمالي وقت التدريب. للعثور على سبب سرعة التدريب غير المتسقة هذه، حاولنا أولاً تحديد اختناقات الموارد من خلال استخدام مراقب النظام (SageMaker Debugger UI)، والذي يسمح لك بتصحيح أخطاء مهام التدريب في SageMaker Training وعرض حالة الموارد مثل منصة التدريب المُدارة. وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU) والشبكة والإدخال/الإخراج خلال عدد محدد من الثواني.
توفر واجهة مستخدم SageMaker Debugger بيانات تفصيلية وأساسية يمكن أن تساعد في تحديد وتشخيص الاختناقات في مهمة التدريب. على وجه التحديد، لفت انتباهنا المخطط الخطي لاستخدام وحدة المعالجة المركزية والخريطة الحرارية لاستخدام وحدة المعالجة المركزية/وحدة معالجة الرسومات لكل مثيل.
في المخطط الخطي لاستخدام وحدة المعالجة المركزية، لاحظنا أن بعض وحدات المعالجة المركزية تم استخدامها بنسبة 100%.
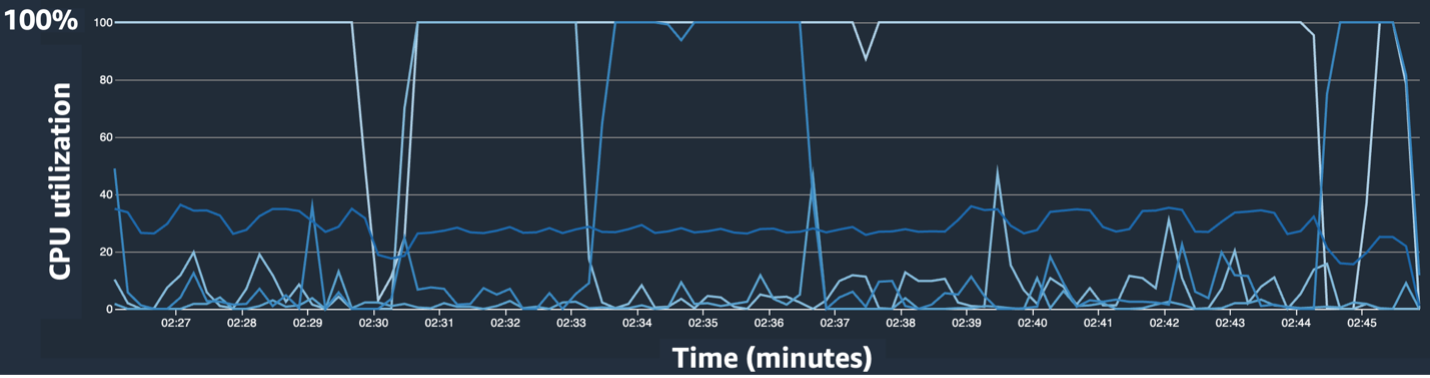
في الخريطة الحرارية (حيث تشير الألوان الداكنة إلى استخدام أعلى)، لاحظنا أن عددًا قليلًا من نوى وحدة المعالجة المركزية كان لها استخدام مرتفع طوال التدريب، في حين أن استخدام وحدة معالجة الرسومات لم يكن مرتفعًا باستمرار مع مرور الوقت.

من هنا، بدأنا نشك في أن أحد أسباب بطء سرعة التدريب هو عنق الزجاجة في وحدة المعالجة المركزية. لقد قمنا بمراجعة كود البرنامج النصي للتدريب لمعرفة ما إذا كان هناك أي شيء يسبب اختناق وحدة المعالجة المركزية. وكان الجزء الأكثر إثارة للريبة هو القيمة الكبيرة لـ num_workers في محمل البيانات، لذلك قمنا بتغيير هذه القيمة إلى 0 أو 1 لتقليل استخدام وحدة المعالجة المركزية. ثم قمنا بمهمة التدريب مرة أخرى وتحققنا من النتائج.
تعرض لقطات الشاشة التالية المخطط الخطي لاستخدام وحدة المعالجة المركزية، واستخدام وحدة معالجة الرسومات، والخريطة الحرارية بعد تخفيف عنق الزجاجة لوحدة المعالجة المركزية.
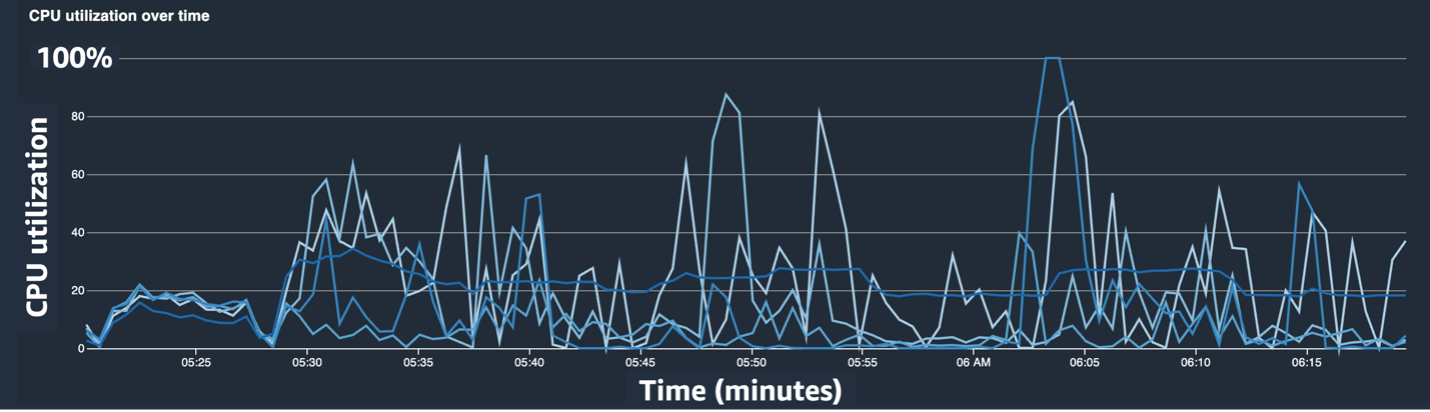


بمجرد التغيير num_workers، شهدنا انخفاضًا كبيرًا في استخدام وحدة المعالجة المركزية وزيادة إجمالية في استخدام وحدة معالجة الرسومات. كان هذا تغييرًا مهمًا أدى إلى تحسين سرعة التدريب بشكل ملحوظ. ومع ذلك، أردنا أن نرى أين يمكننا تحسين استخدام وحدة معالجة الرسومات. ولهذا استخدمنا SageMaker Profiler.
يساعد SageMaker Profiler في تحديد أدلة التحسين من خلال توفير رؤية حول الاستخدام من خلال العمليات، بما في ذلك تتبع مقاييس استخدام وحدة معالجة الرسومات ووحدة المعالجة المركزية واستهلاك kernel لوحدة معالجة الرسومات/وحدة المعالجة المركزية ضمن البرامج النصية للتدريب. يساعد المستخدمين على فهم العمليات التي تستهلك الموارد. أولاً، لاستخدام SageMaker Profiler، تحتاج إلى إضافة ProfilerConfig إلى الوظيفة التي تستدعي مهمة التدريب باستخدام SageMaker SDK، كما هو موضح في التعليمة البرمجية التالية:
في SageMaker Python SDK، لديك المرونة اللازمة لإضافة ملف annotate وظائف SageMaker Profiler لتحديد التعليمات البرمجية أو الخطوات في البرنامج النصي للتدريب الذي يحتاج إلى إنشاء ملفات تعريف. فيما يلي مثال للتعليمة البرمجية التي يجب أن تعلن عنها لـ SageMaker Profiler في البرامج النصية للتدريب:
بعد إضافة الكود السابق، إذا قمت بتشغيل مهمة تدريبية باستخدام نصوص التدريب، فيمكنك الحصول على معلومات حول العمليات التي تستهلكها نواة وحدة معالجة الرسومات (كما هو موضح في الشكل التالي) بعد تشغيل التدريب لفترة من الوقت. في حالة نصوص تدريب KT، قمنا بتشغيلها لفترة واحدة وحصلنا على النتائج التالية.
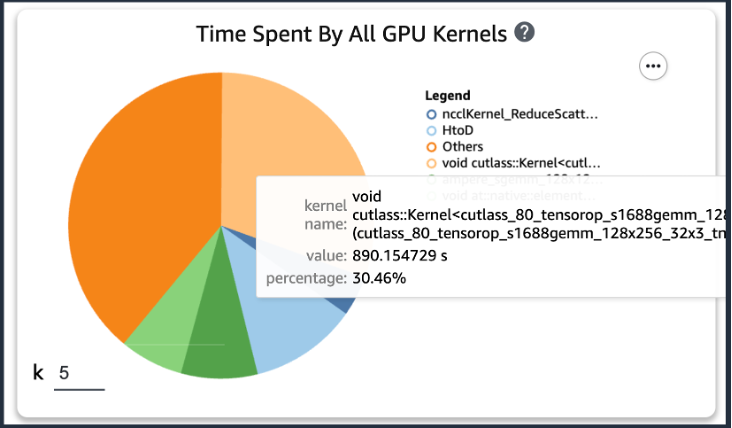
عندما قمنا بفحص أعلى خمسة أوقات لاستهلاك تشغيل نواة وحدة معالجة الرسومات من بين نتائج SageMaker Profiler، وجدنا أنه بالنسبة لبرنامج تدريب KT، يتم استهلاك معظم الوقت من خلال عملية منتج المصفوفة، وهي عملية ضرب المصفوفة العامة (GEMM) على وحدات معالجة الرسومات. بفضل هذه الرؤية المهمة من SageMaker Profiler، بدأنا في البحث عن طرق لتسريع هذه العمليات وتحسين استخدام وحدة معالجة الرسومات.
تسريع وقت التدريب
لقد قمنا بمراجعة طرق مختلفة لتقليل وقت حساب ضرب المصفوفة وقمنا بتطبيق وظيفتين من PyTorch.
ينص محسن Shard على ZeroRedundancyOptimizer
إذا نظرتم الى محسن التكرار الصفري (ZeRO)، تتيح تقنية DeepSpeed/ZeRO تدريب نموذج كبير بكفاءة مع سرعة تدريب أفضل عن طريق التخلص من التكرار في الذاكرة التي يستخدمها النموذج. محسن التكرار الصفري يستخدم PyTorch تقنية تقسيم حالة المحسن لتقليل استخدام الذاكرة لكل عملية في البيانات الموزعة المتوازية (DDP). يستخدم DDP تدرجات متزامنة في التمرير للخلف بحيث تتكرر جميع النسخ المتماثلة للمحسن عبر نفس المعلمات وقيم التدرج، ولكن بدلاً من الحصول على كافة معلمات النموذج، يتم الحفاظ على كل حالة محسن من خلال التقسيم فقط لعمليات DDP المختلفة لتقليل استخدام الذاكرة.
لاستخدامه، يمكنك ترك المُحسِّن الحالي لديك optimizer_class ويعلن أ ZeroRedundancyOptimizer مع بقية معلمات النموذج ومعدل التعلم كمعلمات.
الدقة المختلطة التلقائية
الدقة المختلطة التلقائية (AMP) يستخدم نوع البيانات torch.float32 لبعض العمليات و torch.bfloat16 أو torch.float16 للآخرين، لسهولة الحساب السريع وتقليل استخدام الذاكرة. على وجه الخصوص، نظرًا لأن نماذج التعلم العميق عادةً ما تكون أكثر حساسية للبتات الأسية من البتات الكسرية في حساباتها، فإن torch.bfloat16 تعادل البتات الأسية لـ torch.float32، مما يسمح لها بالتعلم بسرعة بأقل قدر من الخسارة. يعمل torch.bfloat16 فقط على المثيلات ذات بنية A100 NVIDIA (Ampere) أو أعلى، مثل ml.p4d.24xlarge وml.p4de.24xlarge وml.p5.48xlarge.
لتطبيق AMP، يمكنك أن تعلن torch.cuda.amp.autocast في البرامج النصية للتدريب كما هو موضح في الكود أعلاه وقم بالإعلان dtype مثل torch.bfloat16.
النتائج في ملف تعريف SageMaker
بعد تطبيق الوظيفتين على نصوص التدريب وتشغيل مهمة التدريب لفترة واحدة مرة أخرى، قمنا بفحص أعلى خمس أوقات لاستهلاك العمليات لنواة وحدة معالجة الرسومات في SageMaker Profiler. ويوضح الشكل التالي نتائجنا.
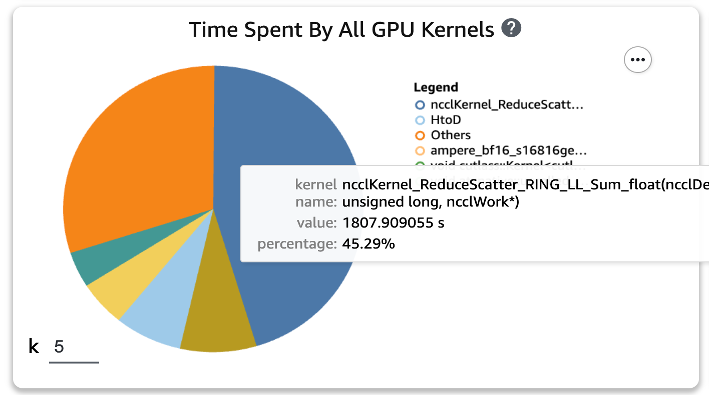
يمكننا أن نرى أن عملية GEMM، التي كانت في أعلى القائمة قبل تطبيق وظيفتي Torch، قد اختفت من العمليات الخمس الأولى، وحلت محلها عملية ReduceScatter، والتي تحدث عادةً في التدريب الموزع.
نتائج سرعة التدريب للنموذج المقطر KT
لقد قمنا بزيادة حجم دفعة التدريب بمقدار 128 عددًا إضافيًا لمراعاة توفير الذاكرة من خلال تطبيق وظيفتي Torch، مما أدى إلى حجم دفعة نهائي قدره 1152 بدلاً من 1024. وتمكن تدريب نموذج الطالب النهائي من تشغيل 210 حقبة في يوم واحد ; يتم تلخيص وقت التدريب والتسريع بين بيئة التدريب الداخلية لـ KT وSageMaker في الجدول التالي.
| بيئة التدريب | مواصفات GPU للتدريب. | عدد وحدات معالجة الرسومات | وقت التدريب (ساعات) | عصر | ساعات لكل عصر | نسبة الانخفاض |
| بيئة التدريب الداخلية في KT | A100 (80 جيجابايت) | 2 | 960 | 300 | 3.20 | 29 |
| الأمازون SageMaker | A100 (40 جيجابايت) | 32 | 24 | 210 | 0.11 | 1 |
أتاحت لنا قابلية التوسع في AWS إكمال مهمة التدريب بشكل أسرع 29 مرة من ذي قبل باستخدام 32 وحدة معالجة رسوميات بدلاً من 2 في مكان العمل. ونتيجة لذلك، فإن استخدام المزيد من وحدات معالجة الرسومات على SageMaker كان من شأنه أن يقلل بشكل كبير من وقت التدريب دون أي فرق في تكاليف التدريب الإجمالية.
وفي الختام
علق Park Sang-min (قائد فريق تكنولوجيا خدمة Vision AI) من مختبر AI2XL في مركز تكنولوجيا التقارب في KT على التعاون مع AWS لتطوير نموذج AI Food Tag:
"في الآونة الأخيرة، نظرًا لوجود المزيد من النماذج القائمة على المحولات في مجال الرؤية، تتزايد معلمات النموذج وذاكرة GPU المطلوبة. نحن نستخدم تقنية خفيفة الوزن لحل هذه المشكلة، ويستغرق الأمر الكثير من الوقت، حوالي شهر للتعلم مرة واحدة. من خلال إثبات المفهوم (PoC) مع AWS، تمكنا من تحديد اختناقات الموارد بمساعدة SageMaker Profiler وDebugger، وحلها، ثم استخدام مكتبة توازي بيانات SageMaker لإكمال التدريب في يوم واحد تقريبًا باستخدام رمز النموذج المحسن على أربعة ml.p4d. 24xlarge من الحالات.
ساعد SageMaker في توفير أسابيع من الوقت لفريق Sang-min في التدريب والتطوير النموذجي.
بناءً على هذا التعاون في نموذج الرؤية، ستواصل AWS وفريق SageMaker التعاون مع KT في العديد من مشاريع أبحاث الذكاء الاصطناعي/التعلم الآلي لتحسين تطوير النماذج وإنتاجية الخدمة من خلال تطبيق إمكانات SageMaker.
لمعرفة المزيد حول الميزات ذات الصلة في SageMaker، راجع ما يلي:
عن المؤلفين
 يونججون تشوييتمتع AI/ML Expert SA بخبرة في تكنولوجيا المعلومات المؤسسية في العديد من الصناعات مثل التصنيع والتكنولوجيا الفائقة والتمويل كمطور ومهندس معماري وعالم بيانات. أجرى بحثًا حول التعلم الآلي والتعلم العميق، وتحديدًا حول موضوعات مثل تحسين المعلمات الفائقة وتكييف المجال، وتقديم الخوارزميات والأوراق البحثية. في AWS، يتخصص في الذكاء الاصطناعي/التعلم الآلي عبر الصناعات، ويوفر التحقق الفني باستخدام خدمات AWS للتدريب الموزع/النماذج واسعة النطاق وبناء عمليات MLOs. يقترح ويراجع البنى التي تهدف إلى المساهمة في توسيع النظام البيئي للذكاء الاصطناعي/التعلم الآلي.
يونججون تشوييتمتع AI/ML Expert SA بخبرة في تكنولوجيا المعلومات المؤسسية في العديد من الصناعات مثل التصنيع والتكنولوجيا الفائقة والتمويل كمطور ومهندس معماري وعالم بيانات. أجرى بحثًا حول التعلم الآلي والتعلم العميق، وتحديدًا حول موضوعات مثل تحسين المعلمات الفائقة وتكييف المجال، وتقديم الخوارزميات والأوراق البحثية. في AWS، يتخصص في الذكاء الاصطناعي/التعلم الآلي عبر الصناعات، ويوفر التحقق الفني باستخدام خدمات AWS للتدريب الموزع/النماذج واسعة النطاق وبناء عمليات MLOs. يقترح ويراجع البنى التي تهدف إلى المساهمة في توسيع النظام البيئي للذكاء الاصطناعي/التعلم الآلي.
 جونغ هون كيم هو حساب SA لشركة AWS Korea. استنادًا إلى خبراته في تصميم هندسة التطبيقات وتطويرها ونمذجة الأنظمة في مختلف الصناعات مثل التكنولوجيا الفائقة والتصنيع والتمويل والقطاع العام، فهو يعمل على تحسين رحلة AWS Cloud وأعباء العمل على AWS لعملاء المؤسسات.
جونغ هون كيم هو حساب SA لشركة AWS Korea. استنادًا إلى خبراته في تصميم هندسة التطبيقات وتطويرها ونمذجة الأنظمة في مختلف الصناعات مثل التكنولوجيا الفائقة والتصنيع والتمويل والقطاع العام، فهو يعمل على تحسين رحلة AWS Cloud وأعباء العمل على AWS لعملاء المؤسسات.
 روك ساكونج هو باحث في KT R&D. لقد أجرى بحثًا وتطويرًا للرؤية AI في مجالات مختلفة وأجرى بشكل أساسي سمات الوجه (الجنس/النظارات والقبعات وما إلى ذلك)/تقنية التعرف على الوجه المتعلقة بالوجه. وهو يعمل حاليًا على تقنية خفيفة الوزن لنماذج الرؤية.
روك ساكونج هو باحث في KT R&D. لقد أجرى بحثًا وتطويرًا للرؤية AI في مجالات مختلفة وأجرى بشكل أساسي سمات الوجه (الجنس/النظارات والقبعات وما إلى ذلك)/تقنية التعرف على الوجه المتعلقة بالوجه. وهو يعمل حاليًا على تقنية خفيفة الوزن لنماذج الرؤية.
 مانوج رافي هو مدير منتج أول في Amazon SageMaker. إنه متحمس لبناء منتجات الذكاء الاصطناعي من الجيل التالي ويعمل على البرامج والأدوات لتسهيل التعلم الآلي على نطاق واسع للعملاء. وهو حاصل على درجة الماجستير في إدارة الأعمال من كلية هاس للأعمال ودرجة الماجستير في إدارة نظم المعلومات من جامعة كارنيجي ميلون. في أوقات فراغه، يستمتع مانوج بلعب التنس ومتابعة تصوير المناظر الطبيعية.
مانوج رافي هو مدير منتج أول في Amazon SageMaker. إنه متحمس لبناء منتجات الذكاء الاصطناعي من الجيل التالي ويعمل على البرامج والأدوات لتسهيل التعلم الآلي على نطاق واسع للعملاء. وهو حاصل على درجة الماجستير في إدارة الأعمال من كلية هاس للأعمال ودرجة الماجستير في إدارة نظم المعلومات من جامعة كارنيجي ميلون. في أوقات فراغه، يستمتع مانوج بلعب التنس ومتابعة تصوير المناظر الطبيعية.
 روبرت فان دوسين هو مدير منتج أول في Amazon SageMaker. وهو يقود الأطر والمجمعات وتقنيات التحسين للتدريب على التعلم العميق.
روبرت فان دوسين هو مدير منتج أول في Amazon SageMaker. وهو يقود الأطر والمجمعات وتقنيات التحسين للتدريب على التعلم العميق.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/kts-journey-to-reduce-training-time-for-a-vision-transformers-model-using-amazon-sagemaker/

