المُقدّمة
يعتبر Computer Vision أحد فروع الذكاء الاصطناعي الذي يوفر فهمًا عالي المستوى للآلة للصورة والقدرة على أداء المهام على الصور التي لا يستطيع حتى البشر القيام بها. كان عام 2022 عام الازدهار لشركة Computer Vision. لقد كان العام الأكثر إنتاجية لشركة Computer Vision حتى الآن. تم تطوير العديد من التقنيات الجديدة ، وتم إطلاق المنتجات ، وتم تشكيل نماذج جديدة ، وحدث الكثير من التحديث. من بين جميع الابتكارات هذا العام ، قمت بإدراج قائمة مختصرة لأفضل 10 موضوعات مفيدة وقوية وشائعة في رؤية الكمبيوتر في عام 2022.
كشف وتعقب الأشياء
يعد اكتشاف الأشياء وتتبعها مجالًا بحثيًا أساسيًا في رؤية الكمبيوتر وكان من بين الأفضل في رؤية الكمبيوتر في عام 2022. يعود العمل الأول في اكتشاف الكائنات إلى عام 2000. وعلى مدار العشرين عامًا التالية ، تحسن هذا المجال ونجح بشكل كبير. يواصل الباحثون السعي لبناء خوارزميات أفضل لاكتشاف الأشياء. لديها مجموعة واسعة من التطبيقات في رؤية الكمبيوتر ، مثل السيارات ذاتية القيادة ، والأمن والمراقبة ، إلخ. الآن ، سنحاول فهم اكتشاف الأشياء وتعقبها.
كما يوحي الاسم ، يحدد اكتشاف الكائن الكائن وموقعه في الصورة. في الوقت نفسه ، يشير تتبع الكائن إلى القدرة على تحديد كائن معين وموقعه في الفيديو. حالة الفن (UNDER ) في اكتشاف الكائن حتى عام 2021 كان YOLOv5. عندما يتعلق الأمر بتتبع الكائنات ، فقد تم استخدام خوارزميات التتبع MOT و Deepsort على نطاق واسع. عندما يتعلق الأمر برؤية الكمبيوتر في عام 2022 ، انفجرت تقنيتان تتعلقان باكتشاف الكائنات وتتبعها.
يولوف 7
يولوف 7 هي نسخة حديثة من عائلة YOLO. إنه أحدث ما توصلت إليه التقنية للكشف عن الأشياء اعتبارًا من اليوم. لقد تفوقت على جميع خوارزميات اكتشاف الكائنات الأخرى في السرعة والدقة.
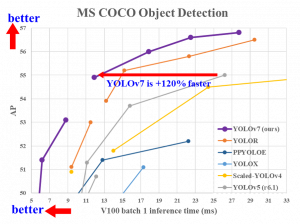
المصدر - جيثب
يمكن الاستدلال من الصورة الموضحة أعلاه أن YOLOv7 يؤدي 120٪ أسرع من جميع الإصدارات السابقة الأخرى من YOLO.
بايت تراك
ByteTrack هو نظام تتبع متعدد الكائنات. تتبع الكائنات المتعددة (MOT) هي عملية تتبع مسار كائنات متعددة موجودة في إطار واحد من الفيديو. تعمل معظم خوارزمية MOT على درجات الثقة والعتبة والمرتجعات objects ذات الدرجات المنخفضة. لا تعتمد خوارزمية ByteTrack على قيم الثقة للكائن المكتشف. بدلاً من ذلك ، يتتبع مسار الكائنات ذات الدرجات المنخفضة ويجد أوجه التشابه مع الإطارات الأخرى لاكتشاف الكائن الحقيقي وتتبع المسار وفقًا لذلك بدلاً من تجاهل الكائنات ذات الدرجات المنخفضة. تتم مطابقة الكائنات ذات الدرجات المنخفضة مع المسارات الصغيرة ويتم اكتشاف الكائن إذا كان موجودًا بالفعل. يعمل نموذج ByteTrack جيدًا حتى بالنسبة للأشياء التي يتم حجبها (عندما يكون الكائن مخفيًا خلف كائن آخر).
يحقق إجمالي 80.3 ميجاوات

المصدر - جيثب
يمكنك قراءة المزيد عن ByteTrack هنا - https://arxiv.org/abs/2110.06864
توليد الصور والفيديو
أتاحت التكنولوجيا إمكانية إنشاء صور ومقاطع فيديو بناءً على وصف نصي أساسي لموقف أو صورة. هذه تقنية رؤية حاسوبية مثيرة في عام 2022 حيث يمكن أن تساعدك على تصور ما تتخيله وإظهاره للآخرين. حققت Soft-truncation ، وهي تقنية تدريب عالمية لنماذج الانتشار القائمة على النقاط ، أحدث النتائج في إنشاء الصور حتى عام 2021 في مجموعات البيانات CIFAR-10 و CelebA و CelebA-HQ 256 × 256 و STL-10. كان هناك تقدم في هذا المجال والعديد من الشركات الكبرى مثل meta و google و OpenAI وغيرها ، توصلت إلى تقنيات وأساليب مختلفة. بعض الأدوات والتقنيات التي تم إطلاقها في عام 2022 موصوفة أدناه-
صورة
Imagen ، الذي طورته Google وتم إطلاقه في عام 2022 ، هو نموذج لنشر النص إلى الصورة. يأخذ وصفًا للصورة وينتج صورًا واقعية. نماذج الانتشار هي نماذج توليدية تنتج صورًا عالية الدقة. تعمل هذه النماذج في خطوتين. في الخطوة الأولى ، تتم إضافة بعض الضوضاء العشوائية إلى الصورة ، ثم في الخطوة الثانية ، يتعلم النموذج عكس العملية عن طريق إزالة الضوضاء ، وبالتالي توليد بيانات جديدة.
يقوم Imagen بترميز النص إلى ترميزات ثم يستخدم نموذج الانتشار لتوليد صورة. تُستخدم سلسلة من نماذج الانتشار لإنتاج صور عالية الدقة. إنها تقنية مثيرة للاهتمام حقًا حيث يمكنك تصور تفكيرك الإبداعي بمجرد وصف صورة وإنشاء ما تريده في لحظات.
وصف IMG - صورة لكلب من فصيلة فصيل كورجي يركب دراجة في تايمز سكوير. إنها ترتدي نظارة شمسية وقبعة شاطئ.
الإخراج:

المصدر - جوجل
يشفر مشفر النص وصف المعطى وينتج الترميزات التي على أساسها ينتج نموذج الانتشار صورًا عالية الدقة. هنا ورقة البحث للرجوع اليها https://imagen.research.google/paper.pdf
اصنع مقطع فيديو
ما الذي يمكن أن يكون أكثر إثارة للاهتمام من إنشاء صورة بناءً على الوصف؟ نعم! لقد خمنت ذلك بشكل صحيح! يسمح لك Make-A-Video ، الذي أطلقته Meta في عام 2022 ، بإنشاء مقطع فيديو بناءً على وصف الصورة. يستخدم النموذج صورًا مع بعض الوصف لعمل مقطع فيديو معطى الوصف. يستخدم أيضًا مقاطع فيديو غير مصنفة لتعلم وتحسين الفيديو الذي تم إنشاؤه.
يمكن شرح مفهوم النموذج في 3 خطوات بسيطة. إنشاء نص إلى صورة ، أخذ حالات من مجموعة من مقاطع الفيديو غير الخاضعة للإشراف ، ثم شبكة الاستيفاء لملء الإطارات وتشكيل مقطع فيديو. يتم استخدام مجموعة من النماذج وتوليفها لإنشاء مقاطع فيديو عالية الدقة. يتم توفير رابط الورقة البحثية أدناه إذا كنت ترغب في قراءة المزيد عن التكنولوجيا.

المصدر - makeavideo.studio
يمكنك استكشاف هذا الاختراع المذهل والقيام بالعديد من الأشياء ، مثل إضافة الحركة إلى إطار ثابت وجلب خيالك إلى الشاشة. هذه التكنولوجيا مثيرة وتستحق الاستكشاف. يمكنك قراءة ورقة البحث هنا: https://arxiv.org/abs/2209.14792
دال-E2
DALL-E2 هو نظام ذكاء اصطناعي تم تطويره بواسطة OpenAI وتم إطلاقه في عام 2022 يمكنه إنشاء صور وفنون واقعية بناءً على الأوصاف النصية. لقد رأينا بالفعل نفس التقنيات ، لكن هذا النظام يستحق الاستكشاف وقضاء بعض الوقت. لقد وجدت DALL-E2 كواحد من أفضل الموديلات الموجودة ، والتي تعمل على إنشاء الصور.

يستخدم إصدارًا من GPT-3 معدلًا لإنشاء الصور ويتم تدريبه على ملايين الصور من جميع أنحاء الإنترنت. يستخدم DALL-E مجموعة من تقنيات البرمجة اللغوية العصبية لفهم معنى إدخال النص وتقنيات رؤية الكمبيوتر لإنشاء الصورة. يتم تدريبه على مجموعة بيانات كبيرة من الصور والأوصاف النصية المرتبطة بها ، مما يسمح لها بتعلم العلاقات بين الكلمات والميزات المرئية. يمكن لـ DALL-E إنشاء صور متماسكة مع نص الإدخال من خلال تعلم هذه العلاقات.
إليك رابط الورقة البحثية إذا كنت مهتمًا بالقراءة بالتفصيل: https://arxiv.org/abs/2102.12092
فيلم: إطار إقحام للحركة الكبيرة
FILM هو نموذج جيل فيديو آخر تم تطويره بواسطة Google والذي يتحول صور متشابهة تقريبًا ومتباعدة عن بعضها البعض في فيديو بطيء الحركة. يجعل النموذج الأمر يبدو كما لو تم التقاط الفيديو بواسطة كاميرا بالحركة البطيئة عن طريق إقحام الإطارات بين الإطارين. تثبت المسافة بين الإطار أنها مشكلة ، ولكن يتم الاهتمام بذلك بواسطة مستخرج الميزة. يتم استخدام مفاهيم أخرى ، ربما ، يمكن إزالتها في مدونة أخرى. لكن مجرد نظرة عامة في الوقت الحالي.
الرموز والنموذج المدرّب مسبقًا موجودان على موقع Google-Research GitHub لمزيد من المرجع. يمكن لهذا النموذج إنتاج لقطة مثل صورة حية في iPhone بالحركة البطيئة. يمكن أن يكون ممتعًا ومفيدًا للغاية لأنه في بعض الأحيان قد تفوتنا لقطة مثالية ولكن مهلا! هناك فيلم لرعاية ذلك….
المصدر - film-net.github.io
هنا رابط الورقة البحثية للرجوع اليها: https://arxiv.org/pdf/2202.04901.pdf
Infinite Nature Zero: إنشاء صور متحركة ثلاثية الأبعاد من الصور الثابتة
أنا متأكد من أنك شاهدت تلك اللقطات المجنونة في الأفلام وتحديداً في أفلام وثائقية عن الحياة البرية حيث تطير الكاميرا فوق المنظر لتنتج لقطة مريضة للطبيعة أو لقطات متتابعة للسحابة ، والتي تبدو جميلة جدًا. أطلق فريق البحث في Google نموذج Infinite Nature Zero في عام 2022 الذي يمكنه إنشاء تلك اللقطات المذهلة من الصور الثابتة. نعم! لقد سمعتها بشكل صحيح ، من الصور الثابتة. يحتوي على صفر في اسمه لأنه يتطلب 0 مقاطع فيديو للتدريب على إنتاج مقاطع فيديو.
يستخدم النموذج شبكات GAN (شبكات الخصومة التوليدية) لإنشاء الصور. يستخدم النموذج نمط تدريب لتوليد الرؤية تحت الإشراف الذاتي عن طريق أخذ عينات من المناظر المتشابهة بزوايا ومسارات كاميرا مماثلة. يمكن للنموذج أن يولد لقطات ساحرة دون تغذية أي فيديو.
المصدر - infinite-nature-zero.github.io
يمكنك إلقاء نظرة على ورقة البحث للرجوع اليها https://arxiv.org/abs/2207.11148
تطبيق المحولات على مشاكل الصورة
المحولات هي شبكات عصبية ذاتية الاهتمام تعمل على آلية الموازاة. يتعلم المنطق ودلالات الجمل ويمكن استخدامه لمعالجة اللغة الطبيعية. وهي تختلف عن تقنيات البرمجة اللغوية العصبية الأخرى حيث يمكن للتقنيات الأخرى معالجة النص دفعة واحدة أو "بالتوازي". في المقابل ، يمكن أن يثبت المحول فعاليته حيث يمكن أيضًا مقارنة الكلمات البعيدة عن بعضها البعض وتحليلها ، مما يؤدي إلى تنبؤات أفضل وسياق النص.

المصدر - ويكيبيديا
يتفوق محول الرؤية الشبيه بالمحول على سوتا سي إن إن الحالي والذي يستخدم على نطاق واسع في مهمة رؤية الكمبيوتر ، ولكن كان هناك ارتفاع في استخدام المحولات في هذا المجال لأنه يتفوق على CNN من حيث الدقة والسرعة.
بعض التقنيات التي انفجرت في رؤية الكمبيوتر عام 2022:
تحجيم محولات الرؤية
حقق Vision Transformer (ViT) أحدث النتائج في العديد من معايير رؤية الكمبيوتر. إنها تحقق دقة إجمالية تبلغ 90.45٪ على مجموعة بيانات ImageNet وهي سوتا حتى الآن. مفهوم القياس هو المفهوم الرئيسي الذي يساعد النموذج على تحقيق ذروة الدقة. تم إجراء بعض التجارب مع البيانات وقياس النموذج وتحليلها ، وتم تحقيق البنية النهائية المكررة. إليك رابط الورقة البحثية إذا كنت ترغب في قراءة المزيد عن التكنولوجيا: https://arxiv.org/abs/2106.04560
Pix2Seq: واجهة لغة جديدة لاكتشاف الكائنات
Pix2Seq هو إطار عمل خوارزمية لاكتشاف الكائنات أطلقته Google في عام 2022. يفترض إطار العمل مهمة اكتشاف الكائن كتوقع الكلمة التالية في البرمجة اللغوية العصبية. يتم أخذ المربعات المحيطة كرموز حيث يتم تدريب الآلة على فهم الصورة وإنشاء مربعات إحاطة مماثلة. يحقق النموذج دقة ملحوظة في مجموعة بيانات COCO دون استخدام أساليب مثل زيادة البيانات والتقنيات الأخرى التي تستخدمها الخوارزميات الأخرى.
التعلم تحت الإشراف الذاتي
كان التعلم الخاضع للإشراف الذاتي أحد أهم الموضوعات في عام 2022. لا تتطلب خوارزمية التعلم الخاضع للإشراف الذاتي تسميات واضحة كمدخلات. بدلاً من ذلك ، يتعلم من جزء من البيانات نفسها. تحل خوارزمية التعلم الخاضع للإشراف الذاتي مشكلة اعتمادنا المفرط على البيانات المصنفة. يؤدي التوليد التلقائي للملصقات إلى تحويل المشكلة من مشكلة غير خاضعة للإشراف إلى مشكلة تعلم خاضعة للإشراف. فيما يلي بعض التقنيات التي تم إطلاقها في رؤية الكمبيوتر في عام 2022 للتعلم تحت الإشراف الذاتي.
Data2vec
تم إطلاق Data2Vec في وقت سابق من هذا العام في يناير 2022. يتم استخدام Data2vec في أنماط التعلم في البيانات ويستخدم نفس طريقة التعلم للكلام أو البرمجة اللغوية العصبية أو رؤية الكمبيوتر. الحدس وراء Data2Vec هو أن النموذج يُعطى عرضًا مكسورًا / مقنعًا للإدخال ، مثل الصورة الموضحة أدناه. لذلك ، يُعطى النموذج 20٪ فقط من البيانات الأولية ويطلب منه التنبؤ بالمخرجات من خلال تحليل الأنماط وتعلم التمثيل المجرد في البيانات دون تغذية آلاف الصور لقط مثل الخوارزميات التقليدية.

يمكن للنموذج إعادة بناء الصورة كما هو موضح أدناه

يُظهر النموذج أداءً متطورًا مقارنةً بالطرق الموجودة سابقًا. يمكنك إلقاء نظرة على الورقة البحثية من خلال هذا الرابط: ورقة بحثية
تحسين نقل التعلم
لقد جعل استخدام التعلم الانتقالي حياة المتحمسين لعلوم البيانات أسهل. نقل التعلم هو عندما نستخدم نموذجًا مدربًا مسبقًا مثل VGG-16 لأداء مهمة مماثلة على مجموعة بيانات مخصصة. يتم إعادة استخدام الأوزان التي تعلمها النموذج وإعادة تدريبها على البيانات التي نريد أداء المهمة المماثلة التي تم تدريب النموذج من أجلها. يوفر هذا الكثير من الوقت والجهد حيث لا يتعين علينا تدريب النموذج على ملايين الصور والقلق بشأن دقة النموذج والجوانب الأخرى.
على الرغم من أن التعلم بالنقل كان سريعًا ، إلا أنه كان هناك المزيد من التحسن في عام 2022 وهو أفضل بالنسبة لنا. إليك بعض التقنيات التي انفجرت في عام 2022.
ضبط دقيق قوي للنماذج الصفرية
نماذج Zero-shot ، كما يوحي الاسم ، هي نماذج لم يتم ضبطها بدقة على مجموعة بيانات معينة. أثبتت هذه التقنية أنها دقيقة في توزيع معين ولكنها تقلل من المتانة في ظل نوبات التوزيع. أدى الضبط الدقيق لنماذج اللقطة الصفرية إلى تحسين دقة هذه النماذج في ظل نوبات التوزيع. المفهوم المستخدم هو الاستخدام المتناغم لأوزان نموذج اللقطة الصفرية والنموذج الدقيق (WiSE-FT).
يؤدي ذلك إلى تحسين دقة تحولات التوزيع إلى 4-6٪ و 1.6 نقطة مئوية على مجموعة بيانات ImageNet. اقرأ المزيد عن الضبط الدقيق القوي لنماذج اللقطة الصفرية هنا: https://arxiv.org/abs/2109.01903
اكتشاف أجسام قليلة الطلقات باستخدام محول عرضي كامل
يشير اكتشاف كائن قليل اللقطات إلى المهمة التي يكتشف فيها النموذج الفصول غير المرئية مع عدد قليل جدًا من أمثلة التدريب. تحل هذه الطريقة مشكلة اعتمادنا المفرط على آلاف الصور المشروحة. استخدمت سوتا السابقة شبكة سيامي ثنائية الفروع لاكتشاف الأجسام ذات اللقطات القليلة. كانت هناك بعض المشكلات في الشبكة المستخدمة والتي يتم التعامل معها من خلال النموذج القائم على المحولات المتقاطعة بالكامل.
المفهوم الكامن وراء هذا النهج هو أنه يشفر مجموعة من الصور القليلة التي يتم تقديمها كأمثلة تدريبية. يتضمن محولات متقاطعة في كل من العمود الفقري ورأس الكشف ويستخدم SGD لتحسين التدريب لتقليل الأخطاء.بين الطبقات الفعلية والمتوقعة بشكل خاطئ. اقرأ المزيد عن اكتشاف الأجسام ذات اللقطات القليلة باستخدام المحولات المتقاطعة بالكامل هنا:
https://arxiv.org/abs/2203.15021
وفي الختام
تقدم هذه المقالة نظرة عامة على أحدث التقنيات التي تم إطلاقها وازدهارها في رؤية الكمبيوتر في عام 2022 ؛ لا يزال هناك الكثير ليأتي. لقد فهمنا بإيجاز بعض المفاهيم المستخدمة في هذه التقنيات. الرؤية الحاسوبية مجال واسع لا يزال يشق طريقه. هناك الكثير لاكتشافه واستكشافه والعديد من الفرص في المستقبل القريب. أنا أشجعك على البحث في الموضوعات التي ناقشناها والتعمق في مجد رؤية الكمبيوتر. أتمنى أن تكون المقالة قد أحببت وأتطلع إلى استكشافها.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2022/12/computer-vision-in-2022-a-quick-recap/

