يتم تدريب نماذج اللغات الكبيرة (LLMs) بشكل عام على مجموعات البيانات الكبيرة المتاحة للجمهور والتي لا تحدد المجال. على سبيل المثال، ميتا اللاما يتم تدريب النماذج على مجموعات البيانات مثل الزحف المشترك, C4، ويكيبيديا، و أرخايف. تشمل مجموعات البيانات هذه مجموعة واسعة من المواضيع والمجالات. على الرغم من أن النماذج الناتجة تسفر عن نتائج جيدة بشكل مثير للدهشة للمهام العامة، مثل إنشاء النص والتعرف على الكيانات، إلا أن هناك أدلة على أن النماذج المدربة باستخدام مجموعات البيانات الخاصة بالمجال يمكن أن تزيد من تحسين أداء LLM. على سبيل المثال، بيانات التدريب المستخدمة ل بلومبرججبت عبارة عن 51% من المستندات الخاصة بالمجال، بما في ذلك الأخبار المالية والملفات والمواد المالية الأخرى. يتفوق أداء LLM الناتج على LLMs المدربين على مجموعات البيانات غير الخاصة بالمجال عند اختباره في مهام خاصة بالتمويل. مؤلفو بلومبرججبت وخلصوا إلى أن نموذجهم يتفوق على جميع النماذج الأخرى التي تم اختبارها لأربعة من المهام المالية الخمس. وقد قدم النموذج أداءً أفضل عند اختباره للمهام المالية الداخلية لبلومبرج بفارق كبير، أفضل بما يصل إلى 60 نقطة (من 100). على الرغم من أنه يمكنك معرفة المزيد عن نتائج التقييم الشامل في ورقة، العينة التالية مأخوذة من بلومبرججبت يمكن أن تعطيك الورقة لمحة عن فائدة تدريب LLMs باستخدام البيانات المالية الخاصة بالمجال. كما هو موضح في المثال، قدم نموذج BloombergGPT الإجابات الصحيحة بينما عانت النماذج الأخرى غير الخاصة بالمجال:
يوفر هذا المنشور دليلاً لتدريب LLMs خصيصًا للمجال المالي. نحن نغطي المجالات الرئيسية التالية:
- جمع البيانات وإعدادها – إرشادات حول تحديد مصادر البيانات المالية ذات الصلة وتنظيمها للتدريب النموذجي الفعال
- التدريب المسبق المستمر مقابل الضبط الدقيق – متى تستخدم كل تقنية لتحسين أداء LLM الخاص بك
- التدريب المسبق المستمر الفعال – استراتيجيات لتبسيط عملية التدريب المسبق المستمر، وتوفير الوقت والموارد
يجمع هذا المنشور بين خبرات فريق أبحاث العلوم التطبيقية ضمن Amazon Finance Technology وفريق AWS العالمي المتخصص للصناعة المالية العالمية. ويستند بعض المحتوى على الورق تدريب مسبق فعال ومستمر لبناء نماذج لغة كبيرة خاصة بالمجال.
جمع وإعداد البيانات المالية
يتطلب التدريب المسبق المستمر للمجال مجموعة بيانات واسعة النطاق وعالية الجودة ومخصصة للمجال. فيما يلي الخطوات الرئيسية لتنظيم مجموعة بيانات المجال:
- تحديد مصادر البيانات - تشمل مصادر البيانات المحتملة لمجموعة النطاق الويب المفتوح ويكيبيديا والكتب ووسائل التواصل الاجتماعي والمستندات الداخلية.
- مرشحات بيانات المجال – نظرًا لأن الهدف النهائي هو تنظيم مجموعة النطاق، فقد تحتاج إلى تطبيق خطوات إضافية لتصفية العينات التي لا صلة لها بالمجال المستهدف. وهذا يقلل من المواد عديمة الفائدة للتدريب المسبق المستمر ويقلل من تكلفة التدريب.
- تجهيزها - قد تفكر في سلسلة من خطوات المعالجة المسبقة لتحسين جودة البيانات وكفاءة التدريب. على سبيل المثال، يمكن أن تحتوي بعض مصادر البيانات على عدد لا بأس به من الرموز المميزة المزعجة؛ يعتبر إلغاء البيانات المكررة خطوة مفيدة لتحسين جودة البيانات وتقليل تكلفة التدريب.
لتطوير برامج LLM المالية، يمكنك استخدام مصدرين مهمين للبيانات: News CommonCrawl وملفات SEC. إن ملف SEC هو بيان مالي أو مستند رسمي آخر يتم تقديمه إلى هيئة الأوراق المالية والبورصات الأمريكية (SEC). يتعين على الشركات المدرجة في البورصة تقديم مستندات مختلفة بانتظام. يؤدي هذا إلى إنشاء عدد كبير من المستندات على مر السنين. News CommonCrawl هي مجموعة بيانات أصدرتها CommonCrawl في عام 2016. وهي تحتوي على مقالات إخبارية من مواقع إخبارية من جميع أنحاء العالم.
أخبار CommonCrawl متاحة على خدمة تخزين أمازون البسيطة (أمازون S3) في commoncrawl دلو في crawl-data/CC-NEWS/. يمكنك الحصول على قوائم الملفات باستخدام واجهة سطر الأوامر AWS (AWS CLI) والأمر التالي:
In تدريب مسبق فعال ومستمر لبناء نماذج لغة كبيرة خاصة بالمجاليستخدم المؤلفون عنوان URL ونهجًا يعتمد على الكلمات الرئيسية لتصفية المقالات الإخبارية المالية من الأخبار العامة. على وجه التحديد، يحتفظ المؤلفون بقائمة من منافذ الأخبار المالية الهامة ومجموعة من الكلمات الرئيسية المتعلقة بالأخبار المالية. نحن نحدد المقالة على أنها أخبار مالية إذا كانت واردة من منافذ الأخبار المالية أو ظهرت أي كلمات رئيسية في عنوان URL. يمكّنك هذا الأسلوب البسيط والفعال من تحديد الأخبار المالية ليس فقط من منافذ الأخبار المالية ولكن أيضًا من أقسام التمويل في منافذ الأخبار العامة.
تتوفر ملفات SEC عبر الإنترنت من خلال قاعدة بيانات EDGAR (جمع البيانات الإلكترونية وتحليلها واسترجاعها) التابعة لهيئة الأوراق المالية والبورصة، والتي توفر الوصول إلى البيانات المفتوحة. يمكنك استخراج الملفات من EDGAR مباشرةً، أو استخدام واجهات برمجة التطبيقات (APIs) فيها الأمازون SageMaker مع بضعة أسطر من التعليمات البرمجية، لأي فترة زمنية ولعدد كبير من المؤشرات (أي المعرف المخصص لهيئة الأوراق المالية والبورصة). لمعرفة المزيد، راجع استرجاع ملفات SEC.
يلخص الجدول التالي التفاصيل الأساسية لكلا مصدري البيانات.
| . | أخبار الزحف المشترك | إيداع SEC |
| تغطية | 2016-2022 | 1993-2022 |
| حجم | 25.8 مليار كلمة | 5.1 مليار كلمة |
يمر المؤلفون ببعض خطوات المعالجة المسبقة الإضافية قبل إدخال البيانات في خوارزمية التدريب. أولاً، لاحظنا أن ملفات هيئة الأوراق المالية والبورصة تحتوي على نص صاخب بسبب إزالة الجداول والأشكال، لذلك قام المؤلفون بإزالة الجمل القصيرة التي تعتبر تسميات جداول أو أشكال. ثانيًا، نحن نطبق خوارزمية تجزئة حساسة للمكان لإلغاء تكرار المقالات والملفات الجديدة. بالنسبة لإيداعات هيئة الأوراق المالية والبورصات، نقوم بإلغاء التكرار على مستوى القسم بدلاً من مستوى المستند. أخيرًا، نقوم بتسلسل المستندات في سلسلة طويلة، ونقوم بترميزها، ثم نقوم بتقطيع الترميز إلى أجزاء ذات طول إدخال أقصى يدعمه النموذج المراد تدريبه. يؤدي ذلك إلى تحسين إنتاجية التدريب المسبق المستمر وتقليل تكلفة التدريب.
التدريب المسبق المستمر مقابل الضبط الدقيق
معظم برامج LLM المتاحة هي للأغراض العامة وتفتقر إلى القدرات الخاصة بالمجال. أظهرت LLMs في المجال أداءً كبيرًا في المجالات الطبية أو المالية أو العلمية. لكي يكتسب ماجستير إدارة الأعمال المعرفة الخاصة بالمجال، هناك أربع طرق: التدريب من الصفر، والتدريب المسبق المستمر، وضبط التعليمات على مهام المجال، والجيل المعزز للاسترجاع (RAG).
في النماذج التقليدية، عادةً ما يتم استخدام الضبط الدقيق لإنشاء نماذج خاصة بمهمة معينة لمجال ما. وهذا يعني الحفاظ على نماذج متعددة لمهام متعددة مثل استخراج الكيان، أو تصنيف النوايا، أو تحليل المشاعر، أو الإجابة على الأسئلة. مع ظهور ماجستير إدارة الأعمال، أصبحت الحاجة إلى الحفاظ على نماذج منفصلة عفا عليها الزمن باستخدام تقنيات مثل التعلم في السياق أو التحفيز. وهذا يوفر الجهد المطلوب للحفاظ على مجموعة من النماذج للمهام ذات الصلة ولكن المتميزة.
بشكل حدسي، يمكنك تدريب LLMs من البداية باستخدام البيانات الخاصة بالمجال. على الرغم من أن معظم العمل لإنشاء مجال LLMs قد ركز على التدريب من الصفر، إلا أنه مكلف للغاية. على سبيل المثال، تكاليف نموذج GPT-4 أكثر من $ 100 مليون يتدرب. يتم تدريب هذه النماذج على مزيج من بيانات المجال المفتوح وبيانات المجال. يمكن أن يساعد التدريب المسبق المستمر النماذج على اكتساب المعرفة الخاصة بالمجال دون تكبد تكلفة التدريب المسبق من البداية لأنك تقوم بتدريب LLM موجود في مجال مفتوح مسبقًا على بيانات المجال فقط.
من خلال الضبط الدقيق للتعليمات في مهمة ما، لا يمكنك جعل النموذج يكتسب معرفة بالمجال لأن LLM يكتسب فقط معلومات المجال الموجودة في مجموعة بيانات الضبط الدقيق للتعليمات. ما لم يتم استخدام مجموعة بيانات كبيرة جدًا لضبط التعليمات، فلن يكفي اكتساب المعرفة بالمجال. عادة ما يكون الحصول على مجموعات بيانات تعليمات عالية الجودة أمرًا صعبًا وهو السبب وراء استخدام LLMs في المقام الأول. كما أن ضبط التعليمات في مهمة واحدة يمكن أن يؤثر على الأداء في المهام الأخرى (كما هو موضح في هذه الورقة). ومع ذلك، فإن ضبط التعليمات يكون أكثر فعالية من حيث التكلفة من أي من بدائل ما قبل التدريب.
يقارن الشكل التالي الضبط الدقيق التقليدي الخاص بالمهمة. مقابل نموذج التعلم في السياق مع LLMs.
 RAG هي الطريقة الأكثر فعالية لتوجيه LLM لإنشاء استجابات ترتكز على المجال. على الرغم من أنه يمكنه توجيه النموذج لتوليد الاستجابات من خلال توفير حقائق من المجال كمعلومات مساعدة، إلا أنه لا يكتسب اللغة الخاصة بالمجال لأن LLM لا يزال يعتمد على نمط لغة غير المجال لإنشاء الاستجابات.
RAG هي الطريقة الأكثر فعالية لتوجيه LLM لإنشاء استجابات ترتكز على المجال. على الرغم من أنه يمكنه توجيه النموذج لتوليد الاستجابات من خلال توفير حقائق من المجال كمعلومات مساعدة، إلا أنه لا يكتسب اللغة الخاصة بالمجال لأن LLM لا يزال يعتمد على نمط لغة غير المجال لإنشاء الاستجابات.
يعد التدريب المسبق المستمر بمثابة حل وسط بين التدريب المسبق وضبط التعليمات من حيث التكلفة مع كونه بديلاً قويًا لاكتساب المعرفة والأسلوب الخاص بالمجال. يمكن أن يوفر نموذجًا عامًا يمكن من خلاله إجراء المزيد من الضبط الدقيق للتعليمات على بيانات التعليمات المحدودة. يمكن أن يكون التدريب المسبق المستمر بمثابة استراتيجية فعالة من حيث التكلفة للمجالات المتخصصة حيث تكون مجموعة المهام النهائية كبيرة أو غير معروفة وتكون بيانات ضبط التعليمات المصنفة محدودة. في سيناريوهات أخرى، قد يكون الضبط الدقيق للتعليمات أو RAG أكثر ملاءمة.
لمعرفة المزيد حول الضبط الدقيق وRAG والتدريب على النماذج، راجع صقل نموذج الأساس, الجيل المعزز للاسترجاع (RAG)و تدريب نموذج مع Amazon SageMaker، على التوالى. في هذا المنشور، نركز على التدريب المسبق الفعال والمستمر.
منهجية التدريب المسبق الفعال المستمر
يتكون التدريب المسبق المستمر من المنهجية التالية:
- التدريب المسبق المستمر للتكيف مع المجال (DACP) - في ورقة تدريب مسبق فعال ومستمر لبناء نماذج لغة كبيرة خاصة بالمجاليقوم المؤلفون باستمرار بتدريب مجموعة نماذج لغة بيثيا مسبقًا على المجموعة المالية لتكييفها مع المجال المالي. الهدف هو إنشاء LLMs المالية عن طريق تغذية البيانات من المجال المالي بأكمله إلى نموذج مفتوح المصدر. ونظرًا لأن مجموعة التدريب تحتوي على جميع مجموعات البيانات المنسقة في المجال، فيجب أن يكتسب النموذج الناتج معرفة خاصة بالتمويل، وبالتالي يصبح نموذجًا متعدد الاستخدامات لمختلف المهام المالية. وينتج عن هذا نماذج FinPythia.
- التدريب المسبق المستمر للتكيف مع المهام (TACP) - يقوم المؤلفون بتدريب النماذج مسبقًا بشكل أكبر على بيانات المهام المسمى وغير المسمى لتخصيصها لمهام محددة. في ظروف معينة، قد يفضل المطورون النماذج التي تقدم أداءً أفضل لمجموعة من المهام داخل المجال بدلاً من النموذج العام للمجال. تم تصميم TACP كتدريب مسبق مستمر يهدف إلى تحسين الأداء في المهام المستهدفة، دون الحاجة إلى بيانات مصنفة. على وجه التحديد، يقوم المؤلفون باستمرار بتدريب النماذج مفتوحة المصدر على رموز المهمة (بدون تسميات). يكمن القيد الأساسي لـ TACP في إنشاء LLMs خاصة بالمهمة بدلاً من LLMs التأسيسية، وذلك بسبب الاستخدام الوحيد لبيانات المهام غير المسماة للتدريب. على الرغم من أن DACP يستخدم مجموعة أكبر بكثير، إلا أنه مكلف للغاية. لتحقيق التوازن بين هذه القيود، يقترح المؤلفون نهجين يهدفان إلى بناء LLMs أساسية خاصة بالمجال مع الحفاظ على الأداء المتفوق في المهام المستهدفة:
- DACP الفعال والمشابه للمهام (ETS-DACP) - يقترح المؤلفون اختيار مجموعة فرعية من المجموعة المالية التي تشبه إلى حد كبير بيانات المهمة باستخدام تضمين التشابه. يتم استخدام هذه المجموعة الفرعية للتدريب المسبق المستمر لجعلها أكثر كفاءة. على وجه التحديد، يقوم المؤلفون باستمرار بتدريب ماجستير إدارة الأعمال مفتوح المصدر على مجموعة صغيرة مستخرجة من المجموعة المالية القريبة من المهام المستهدفة في التوزيع. يمكن أن يساعد هذا في تحسين أداء المهمة لأننا نعتمد النموذج لتوزيع الرموز المميزة للمهام على الرغم من عدم الحاجة إلى البيانات المصنفة.
- DACP الفعال الملحد للمهام (ETA-DACP) - يقترح المؤلفون استخدام مقاييس مثل الحيرة والإنتروبيا من النوع المميز التي لا تتطلب بيانات مهمة لاختيار عينات من المجموعة المالية للتدريب المسبق المستمر الفعال. تم تصميم هذا الأسلوب للتعامل مع السيناريوهات التي لا تتوفر فيها بيانات المهام أو تُفضل نماذج المجال الأكثر تنوعًا للمجال الأوسع. يعتمد المؤلفون بعدين لاختيار عينات البيانات المهمة للحصول على معلومات المجال من مجموعة فرعية من بيانات مجال ما قبل التدريب: الحداثة والتنوع. تشير الجدة، التي تقاس بالحيرة التي سجلها النموذج المستهدف، إلى المعلومات التي لم تكن مرئية من قبل LLM من قبل. تشير البيانات ذات الجدة العالية إلى معرفة جديدة لماجستير القانون، ويُنظر إلى هذه البيانات على أنها أكثر صعوبة في التعلم. يؤدي هذا إلى تحديث LLMs العامة بمعرفة مكثفة بالمجال أثناء التدريب المسبق المستمر. ومن ناحية أخرى، يجسد التنوع تنوع توزيعات أنواع الرموز المميزة في مجموعة المجال، والتي تم توثيقها كميزة مفيدة في البحث عن تعلم المناهج الدراسية حول نمذجة اللغة.
يقارن الشكل التالي مثالاً لـ ETS-DACP (يسار) مقابل ETA-DACP (يمين).

نحن نعتمد نظامين لأخذ العينات لاختيار نقاط البيانات بشكل فعال من المجموعة المالية المنسقة: أخذ العينات الصعبة وأخذ العينات الناعمة. يتم إجراء الأول عن طريق ترتيب المجموعة المالية أولاً من خلال المقاييس المقابلة ثم اختيار عينات top-k، حيث يتم تحديد k مسبقًا وفقًا لميزانية التدريب. بالنسبة للأخيرة، يقوم المؤلفون بتعيين أوزان العينات لكل نقطة بيانات وفقًا للقيم المترية، ثم أخذ عينات عشوائية من نقاط البيانات k لتلبية ميزانية التدريب.
النتيجة والتحليل
يقوم المؤلفون بتقييم LLMs المالية الناتجة على مجموعة من المهام المالية للتحقيق في فعالية التدريب المسبق المستمر:
- بنك العبارات المالية - مهمة تصنيف المشاعر على الأخبار المالية.
- فيكا سا - مهمة تصنيف المشاعر على أساس الجانب بناءً على الأخبار المالية والعناوين الرئيسية.
- عنوان رئيسي – مهمة تصنيف ثنائية حول ما إذا كان العنوان الرئيسي الخاص بكيان مالي يحتوي على معلومات معينة.
- NER – مهمة استخراج كيان مالي محدد بناءً على قسم تقييم مخاطر الائتمان في تقارير هيئة الأوراق المالية والبورصات. يتم شرح الكلمات في هذه المهمة باستخدام PER وLOC وORG وMISC.
نظرًا لأن تعليمات ماجستير إدارة الأعمال المالية يتم ضبطها بدقة، يقوم المؤلفون بتقييم النماذج في إعداد من 5 لقطات لكل مهمة من أجل المتانة. في المتوسط، يتفوق FinPythia 6.9B على Pythia 6.9B بنسبة 10% في أربع مهام، مما يوضح فعالية التدريب المسبق المستمر الخاص بالمجال. بالنسبة للنموذج 1B، يكون التحسن أقل عمقًا، لكن الأداء لا يزال يتحسن بنسبة 2% في المتوسط.
يوضح الشكل التالي اختلاف الأداء قبل وبعد DACP في كلا الطرازين.

يعرض الشكل التالي مثالين نوعيين تم إنشاؤهما بواسطة Pythia 6.9B وFinPythia 6.9B. بالنسبة لسؤالين متعلقين بالتمويل فيما يتعلق بمدير المستثمر والمصطلح المالي، لا يفهم Pythia 6.9B المصطلح أو يتعرف على الاسم، بينما يقوم FinPythia 6.9B بإنشاء إجابات مفصلة بشكل صحيح. توضح الأمثلة النوعية أن التدريب المسبق المستمر يمكّن طلاب LLM من اكتساب المعرفة بالمجال أثناء العملية.

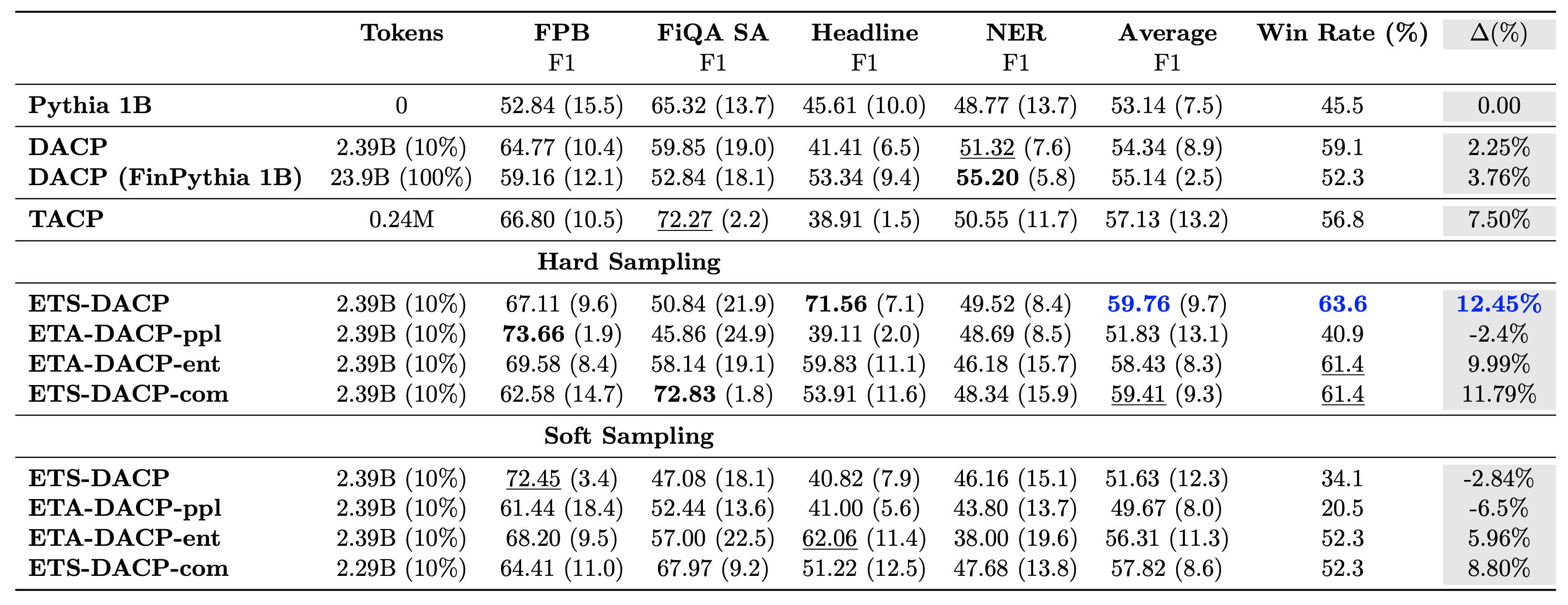
يقارن الجدول التالي بين أساليب التدريب المسبق الفعالة والمستمرة. ETA-DACP-ppl هو ETA-DACP يعتمد على الحيرة (الجدة)، ويعتمد ETA-DACP-ent على الإنتروبيا (التنوع). يشبه ETS-DACP-com DACP مع اختيار البيانات عن طريق حساب متوسط المقاييس الثلاثة. وفيما يلي بعض الوجبات السريعة من النتائج:
- طرق اختيار البيانات فعالة - إنها تتجاوز التدريب المسبق المستمر القياسي بنسبة 10% فقط من بيانات التدريب. التدريب المسبق الفعال والمستمر بما في ذلك DACP للمهام المشابهة (ETS-DACP)، وDACP غير المتوافقة مع المهام استنادًا إلى الإنتروبيا (ESA-DACP-ent)، وDACP للمهام المشابهة استنادًا إلى المقاييس الثلاثة (ETS-DACP-com) يتفوق على DACP القياسي في المتوسط على الرغم من حقيقة أنهم تم تدريبهم على 10% فقط من الجانب المالي.
- يعمل اختيار البيانات المدركة للمهمة بشكل أفضل بما يتماشى مع أبحاث نماذج اللغة الصغيرة - تسجل ETS-DACP أفضل متوسط أداء بين جميع الطرق، واستنادًا إلى المقاييس الثلاثة جميعها، تسجل ثاني أفضل أداء للمهمة. يشير هذا إلى أن استخدام بيانات المهام غير المسماة لا يزال أسلوبًا فعالاً لتعزيز أداء المهام في حالة LLMs.
- ويأتي اختيار البيانات الحيادية في المرتبة الثانية - يتبع ESA-DACP-ent أداء نهج اختيار البيانات المدرك للمهمة، مما يعني أنه لا يزال بإمكاننا تعزيز أداء المهمة من خلال الاختيار النشط لعينات عالية الجودة غير مرتبطة بمهام محددة. وهذا يمهد الطريق لبناء ماجستير في القانون المالي للمجال بأكمله مع تحقيق أداء فائق للمهام.
أحد الأسئلة الحاسمة المتعلقة بالتدريب المسبق المستمر هو ما إذا كان يؤثر سلبًا على الأداء في المهام غير المتعلقة بالمجال. يقوم المؤلفون أيضًا بتقييم النموذج المُدرب مسبقًا بشكل مستمر على أربع مهام عامة مستخدمة على نطاق واسع: ARC، وMMLU، وTruthQA، وHellaSwag، والتي تقيس القدرة على الإجابة على الأسئلة، والتفكير، والإكمال. يجد المؤلفون أن التدريب المسبق المستمر لا يؤثر سلبًا على الأداء خارج المجال. لمزيد من التفاصيل، راجع تدريب مسبق فعال ومستمر لبناء نماذج لغة كبيرة خاصة بالمجال.
وفي الختام
قدم هذا المنشور رؤى حول جمع البيانات واستراتيجيات التدريب المسبق المستمر لتدريب حاملي شهادة الماجستير في المجال المالي. يمكنك البدء في تدريب LLMs الخاص بك على المهام المالية باستخدام تدريب Amazon SageMaker or أمازون بيدروك اليوم.
حول المؤلف
 يونغ شيه هو عالم تطبيقي في Amazon FinTech. يركز على تطوير نماذج لغوية كبيرة وتطبيقات الذكاء الاصطناعي التوليدية للتمويل.
يونغ شيه هو عالم تطبيقي في Amazon FinTech. يركز على تطوير نماذج لغوية كبيرة وتطبيقات الذكاء الاصطناعي التوليدية للتمويل.
 كاران أغاروال هو أحد كبار العلماء التطبيقيين في Amazon FinTech مع التركيز على الذكاء الاصطناعي التوليدي لحالات الاستخدام المالي. يتمتع كاران بخبرة واسعة في تحليل السلاسل الزمنية والبرمجة اللغوية العصبية، مع اهتمام خاص بالتعلم من البيانات المحدودة
كاران أغاروال هو أحد كبار العلماء التطبيقيين في Amazon FinTech مع التركيز على الذكاء الاصطناعي التوليدي لحالات الاستخدام المالي. يتمتع كاران بخبرة واسعة في تحليل السلاسل الزمنية والبرمجة اللغوية العصبية، مع اهتمام خاص بالتعلم من البيانات المحدودة
 اعتزاز احمد هو مدير العلوم التطبيقية في أمازون حيث يقود فريقًا من العلماء الذين يقومون ببناء تطبيقات مختلفة للتعلم الآلي والذكاء الاصطناعي التوليدي في مجال التمويل. تتمثل اهتماماته البحثية في البرمجة اللغوية العصبية (NLP) والذكاء الاصطناعي التوليدي (Generative AI) ووكلاء LLM (LLM). حصل على درجة الدكتوراه في الهندسة الكهربائية من جامعة تكساس إيه آند إم.
اعتزاز احمد هو مدير العلوم التطبيقية في أمازون حيث يقود فريقًا من العلماء الذين يقومون ببناء تطبيقات مختلفة للتعلم الآلي والذكاء الاصطناعي التوليدي في مجال التمويل. تتمثل اهتماماته البحثية في البرمجة اللغوية العصبية (NLP) والذكاء الاصطناعي التوليدي (Generative AI) ووكلاء LLM (LLM). حصل على درجة الدكتوراه في الهندسة الكهربائية من جامعة تكساس إيه آند إم.
 تشينغوي لي هو متخصص في التعلم الآلي في Amazon Web Services. حصل على الدكتوراه. في بحوث العمليات بعد أن كسر حساب المنحة البحثية لمستشاره وفشل في تسليم جائزة نوبل التي وعد بها. وهو حاليًا يساعد العملاء في مجال الخدمات المالية على بناء حلول التعلم الآلي على AWS.
تشينغوي لي هو متخصص في التعلم الآلي في Amazon Web Services. حصل على الدكتوراه. في بحوث العمليات بعد أن كسر حساب المنحة البحثية لمستشاره وفشل في تسليم جائزة نوبل التي وعد بها. وهو حاليًا يساعد العملاء في مجال الخدمات المالية على بناء حلول التعلم الآلي على AWS.
 راجفيندر أرني يقود فريق تسريع العملاء (CAT) داخل AWS Industries. CAT هو فريق عالمي متعدد الوظائف من المهندسين السحابيين الذين يواجهون العملاء ومهندسي البرمجيات وعلماء البيانات وخبراء ومصممي الذكاء الاصطناعي/تعلم الآلة الذين يدفعون الابتكار من خلال النماذج الأولية المتقدمة، ويدفعون التميز التشغيلي السحابي من خلال الخبرة الفنية المتخصصة.
راجفيندر أرني يقود فريق تسريع العملاء (CAT) داخل AWS Industries. CAT هو فريق عالمي متعدد الوظائف من المهندسين السحابيين الذين يواجهون العملاء ومهندسي البرمجيات وعلماء البيانات وخبراء ومصممي الذكاء الاصطناعي/تعلم الآلة الذين يدفعون الابتكار من خلال النماذج الأولية المتقدمة، ويدفعون التميز التشغيلي السحابي من خلال الخبرة الفنية المتخصصة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

