المُقدّمة
مع ظهور نماذج اللغات الكبيرة (ماجستير)، لقد تغلغلت في العديد من التطبيقات، لتحل محل نماذج المحولات الأصغر مثل بيرت أو النماذج القائمة على القواعد في الكثير معالجة اللغات الطبيعية (NLP) مهام. تتميز شهادات LLM بأنها متعددة الاستخدامات، وقادرة على التعامل مع مهام مثل تصنيف النص، والتلخيص، وتحليل المشاعر، ونمذجة الموضوع، وذلك نظرًا لتدريبهم المسبق المكثف. ومع ذلك، على الرغم من قدراتها الواسعة، غالبًا ما تتأخر شهادات LLM في الدقة مقارنة بنظيراتها الأصغر.
ولمعالجة هذا القيد، تتمثل إحدى الاستراتيجيات الفعالة في ضبط ماجستير إدارة الأعمال المدربين مسبقًا للتفوق في مهام محددة. يؤدي الضبط الدقيق للنماذج الكبيرة في كثير من الأحيان إلى نتائج مثالية. ومن الجدير بالذكر أن نموذج Gemini من Google، من بين النماذج الكبيرة الأخرى، يوفر الآن للمستخدمين القدرة على ضبط هذه النماذج باستخدام بيانات التدريب الخاصة بهم. في هذا الدليل، سنتعرف على عملية الضبط الدقيق لنماذج Gemini لمشاكل محددة، بالإضافة إلى كيفية تنظيم مجموعة بيانات باستخدام موارد من HuggingFace.
أهداف التعلم
- فهم أداء نماذج Google Gemini.
- تعلم إعداد مجموعة البيانات لضبط نموذج الجوزاء.
- تكوين المعلمات لضبط نموذج الجوزاء.
- مراقبة التقدم والمقاييس في الضبط الدقيق.
- اختبار أداء نموذج الجوزاء على البيانات الجديدة.
- استكشف تطبيقات نموذج Gemini لإخفاء معلومات تحديد الهوية الشخصية (PII).

تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
جوجل تعلن عن ضبط الجوزاء
يأتي Gemini في نسختين: Pro وUltra. يوجد في الإصدار Pro Gemini 1.0 Pro وGemini 1.5 Pro الجديد. تتنافس هذه النماذج من Google مع نماذج متقدمة أخرى مثل ChatGPT وClaude. يسهل على الجميع الوصول إلى نماذج Gemini من خلال AI Studio UI وواجهة برمجة التطبيقات المجانية.
أعلنت Google مؤخرًا عن ميزة جديدة لنماذج Gemini: الضبط الدقيق. هذا يعني أنه يمكن لأي شخص تعديل نموذج الجوزاء ليناسب احتياجاته. يمكنك ضبط Gemini باستخدام واجهة مستخدم AI Studio أو واجهة برمجة التطبيقات الخاصة بها. الضبط الدقيق هو عندما نعطي بياناتنا الخاصة إلى الجوزاء حتى يتمكن من التصرف بالطريقة التي نريدها. تستخدم Google تقنية Parameter Efficient Tuning (PET) لضبط بعض الأجزاء المهمة من نموذج Gemini بسرعة، مما يجعلها مفيدة لمهام مختلفة.
تحضير مجموعة البيانات
قبل أن نبدأ في ضبط النموذج، سنبدأ بتثبيت المكتبات اللازمة. بالمناسبة، سنعمل مع كولاب لإعداد هذا الدليل.
تثبيت المكتبات اللازمة
فيما يلي وحدات بايثون الضرورية للبدء:
!pip install -q google-generativeai datasets- جوجل جينيراتيفاي: إنها مكتبة من فريق Google تتيح لنا الوصول إلى نموذج Google Gemini. يمكن العمل مع نفس المكتبة لضبط نموذج الجوزاء.
- مجموعات البيانات: هذه مكتبة من HuggingFace يمكننا العمل معها لتنزيل مجموعة متنوعة من مجموعات البيانات من مركز HuggingFace. سنعمل مع مكتبة مجموعات البيانات هذه لتنزيل مجموعة بيانات PII (معلومات التعريف الشخصية) وإعطائها إلى نموذج Gemini للضبط الدقيق.
سيؤدي تشغيل التعليمات البرمجية التالية إلى تنزيل وتثبيت Google Geneative AI ومكتبة مجموعات البيانات في بيئة Python الخاصة بنا.
إعداد OAuth
في الخطوة التالية، نحتاج إلى إعداد OAuth لهذا البرنامج التعليمي. يعد OAuth ضروريًا حتى تكون البيانات التي نرسلها إلى Google من أجل Fine-Tuning Gemini آمنة. للحصول على OAuth اتبع هذا الصفحة . ثم قم بتنزيل Client_secret.json بعد إنشاء OAuth. احفظ محتويات Client_secrent.json في Colab Secrets تحت اسم CLIENT_SECRET وقم بتشغيل الكود أدناه:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'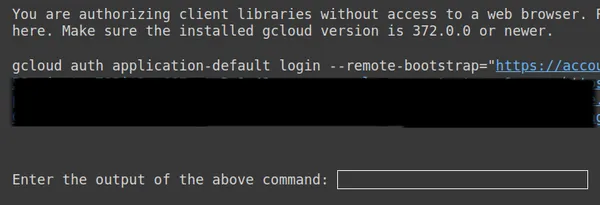
أعلاه، انسخ الرابط الثاني والصقه في نظام CMD المحلي لديك وقم بتشغيله.
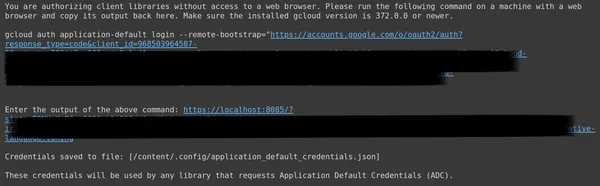
ستتم بعد ذلك إعادة توجيهك إلى متصفح الويب لتسجيل الدخول باستخدام البريد الإلكتروني الذي قمت بإعداد OAuth به. بعد تسجيل الدخول، في CMD، نحصل على عنوان URL، والآن قم بلصق عنوان URL هذا في السطر الثالث واضغط على Enter. لقد انتهينا الآن من إجراء OAuth مع Google.
تنزيل وإعداد مجموعة البيانات
أولاً، سنبدأ بتنزيل مجموعة البيانات التي سنعمل معها لضبطها لتناسب نموذج الجوزاء. لهذا، نحن نعمل مع مكتبة مجموعات البيانات. الكود الخاص بهذا سيكون:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- نبدأ هنا باستيراد وظيفة Load_dataset من مكتبة مجموعات البيانات.
- إلى وظيفةload_dataset() هذه، نقوم بتمرير مجموعة البيانات التي نرغب في تنزيلها. هنا في مثالنا هو "ai4privacy/pii-masking-200k"، والذي يحتوي على 200 ألف صف من بيانات معلومات تحديد الهوية الشخصية المقنعة وغير المقنعة.
- ثم نقوم بطباعة مجموعة البيانات.

نرى أن مجموعة البيانات تحتوي على 209261 صفًا من بيانات التدريب ولا تحتوي على بيانات اختبار. ويحتوي كل صف على أعمدة مختلفة مثل Masked_text، وunmasked_text، وprivacy_mask، وspan_labels، وbio_labels، وtokenised_text. بيانات العينة مذكورة أدناه:
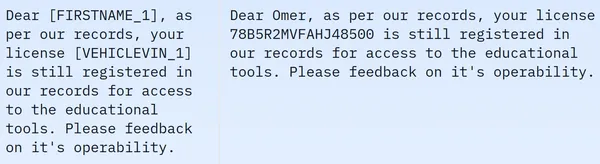
في الصورة المعروضة، نلاحظ الجمل المقنعة وغير المقنعة. على وجه التحديد، في الجملة المقنعة، يتم حجب عناصر معينة مثل اسم الشخص ورقم السيارة بواسطة علامات محددة. لإعداد البيانات لمزيد من المعالجة، نحتاج الآن إلى إجراء بعض المعالجة المسبقة للبيانات. فيما يلي رمز خطوة المعالجة المسبقة هذه:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- أولاً، نأخذ الجزء التدريبي من البيانات من مجموعة البيانات (تحتوي مجموعة البيانات التي قمنا بتنزيلها على الجزء التدريبي فقط). ثم نقوم بتحويل هذا إلى Pandas Dataframe.
- هنا لضبط الجوزاء، نحتاج فقط إلى عمودين النص غير المقنع والنص المقنع، لذلك نأخذ هذين العمودين فقط.
- ثم نحصل على أول 2000 صف من البيانات. سنعمل مع أول 2000 صف لضبط الجوزاء.
- نقوم بعد ذلك بتحرير أسماء الأعمدة من unmasked_text وmasked_text إلى أعمدة الإدخال والإخراج، لأنه عندما نعطي بيانات نص الإدخال التي تحتوي على PII (معلومات التعريف الشخصية) إلى نموذج Gemini، نتوقع منه إنشاء بيانات نص الإخراج حيث PII ملثم.
تنسيق البيانات لضبط الجوزاء
والخطوة التالية هي تنسيق البيانات لدينا. للقيام بذلك، سنقوم بإنشاء وظيفة المنسق:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- نحدد هنا منسق دالة، والذي يأخذ صفًا من بياناتنا x.
- ثم يقوم بتعريف نص متغير باستخدام سلاسل f، حيث نوفر السياق، متبوعًا بالبيانات المدخلة من إطار البيانات.
- وأخيرا، نعيد النص المنسق.
- يطبق السطر الأخير وظيفة المنسق على كل صف من إطار البيانات الذي أنشأناه من خلال وظيفة application().
- يخبرنا المحور = 1 أنه سيتم تطبيق الوظيفة على كل صف في إطار البيانات.
سيؤدي تشغيل الكود إلى إنشاء عمود جديد يسمى "القطار" الذي يحتوي على النص المنسق لكل صف بما في ذلك حقل الإدخال. دعونا نحاول مراقبة أحد عناصر إطار البيانات:
تقسيم البيانات إلى تدريب ومجموعات اختبار
يمكننا أن نرى أن text_input يحتوي على البيانات حيث يحتوي كل صف على السياق في بداية البيانات التي تطلب إخفاء معلومات تحديد الهوية الشخصية ثم تليها بيانات الإدخال ويتبعها إخراج الكلمة، حيث يحتاج النموذج إلى إنشاء الإخراج. نحتاج الآن إلى تقسيم إطار البيانات إلى تدريب واختبار:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- نبدأ بتصفية البيانات بحيث تحتوي على text_input وأعمدة الإخراج. هذه هي الأعمدة التي تتوقعها مكتبة Google Fine-Tune لتدريب برج الجوزاء
- سوف يحصل الجوزاء على text_input ويتعلم كيفية كتابة الإخراج
- نقوم بتقسيم البيانات إلى df_train الذي يحتوي على 1900 صفًا من بياناتنا الأصلية
- وdf_test الذي يحتوي على حوالي 100 صف من البيانات الأصلية
- نقوم بتدريب الجوزاء على df_train ثم اختباره من خلال أخذ 3-4 أمثلة من df_test لمعرفة المخرجات الناتجة عنه
لذا فإن تشغيل الكود سيؤدي إلى تصفية بياناتنا وتقسيمها إلى تدريب واختبار. أخيرًا، انتهينا من جزء المعالجة المسبقة للبيانات.
ضبط نموذج الجوزاء
اتبع الخطوات المذكورة أدناه لضبط نموذج الجوزاء الخاص بك:
معلمات ضبط الإعداد
في هذا القسم، سنتناول عملية ضبط نموذج الجوزاء. لهذا سنعمل بالكود التالي:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- استيراد مكتبة google.geneativeai: توفر هذه المكتبة واجهات برمجة التطبيقات للتفاعل مع خدمات الذكاء الاصطناعي التوليدية من Google.
- قم بتوفير اسم النموذج الأساسي: هذا هو اسم النموذج الذي تم تدريبه مسبقًا والذي نريد العمل معه كنقطة البداية لنموذجنا المضبوط. في الوقت الحالي، النموذج الوحيد القابل للضبط هوmodels/gemini-1.0-pro-001، ونقوم بتخزينه في المتغير bm_name.
- قم بتوفير اسم النموذج المضبوط: هذا هو الاسم الذي نريد أن نعطيه لنموذجنا المضبوط. هنا نعطيه اسم "pii-model".
- إنشاء كائن عملية نموذج مضبوط: يمثل هذا الكائن عملية إنشاء نموذج مضبوط. يستغرق الحجج التالية:
- source_model: اسم النموذج الأساسي
- Training_data: بيانات التدريب الخاصة بالنموذج الدقيق الذي قمنا بإنشائه للتو وهو df_train
- المعرف: معرف/اسم النموذج الدقيق
- Epoch_count: عدد فترات التدريب. في هذا المثال، سنستخدم عصرين
- Batch_size: حجم الدفعة للتدريب. في هذا المثال، سنستخدم القيمة 4
- Learning_rate: معدل التعلم للتدريب. نحن هنا نزودها بقيمة 0.001
- لقد انتهينا من توفير المعلمات. سيؤدي تشغيل هذا الرمز إلى إنشاء كائن نموذج دقيق. الآن نحن بحاجة لبدء عملية تدريب Gemini LLM. لهذا، نحن نعمل مع الكود التالي.
لقد انتهينا من إعداد المعلمات. سيؤدي تشغيل هذا الرمز إلى إنشاء كائن نموذج مضبوط. الآن نحن بحاجة لبدء عملية تدريب Gemini LLM. ولهذا نعمل بالكود التالي:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)إنشاء نموذج مضبوط
هنا، نستخدم الدالة .get_tuned_model() من مكتبة genai، ونمرر اسم النموذج المحدد لدينا، ونبدأ عملية التدريب. ومن ثم نقوم بطباعة النموذج كما هو موضح في الصورة أدناه:
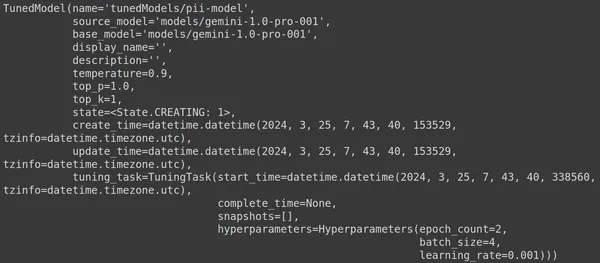
النموذج من النوع TunedModel. هنا يمكننا ملاحظة معلمات مختلفة للنموذج الذي حددناه. هم:
- الاسم: يحتوي هذا المتغير على الاسم الذي قدمناه لنموذجنا المضبوط
- source_model: هذا هو النموذج المصدر الذي نقوم بضبطه، وهو في مثالناmodels/gemini-1.0-pro
- base_model: هذا هو النموذج الأساسي الذي نقوم بضبطه مرة أخرى، وهو في مثالناmodels/Gemini-1.0-pro. يمكن أن يكون النموذج الأساسي نموذجًا تم ضبطه مسبقًا. نحن هنا هو نفسه بالنسبة لكليهما
- Display_name: اسم العرض للنموذج الذي تم ضبطه
- الوصف: يحتوي على أي وصف لنموذجنا وما يدور حوله النموذج
- درجة الحرارة: كلما ارتفعت القيمة، كلما تم إنشاء الإجابات الأكثر إبداعًا من نموذج اللغة الكبير. هنا تم ضبطه على 0.9 افتراضيًا
- top_p: يحدد الاحتمالية الأعلى لاختيار الرمز المميز أثناء إنشاء النص. كلما تم تحديد عدد أكبر من الرموز المميزة، أي يتم تحديد الرموز المميزة من عينة أكبر من البيانات
- top_k: يخبرك بأخذ عينة من الرموز المميزة التالية على الأرجح في كل خطوة. هنا top_k هو 1، مما يعني أن الرمز المميز التالي الأكثر احتمالاً هو الذي سيتم تحديده، أي سيتم دائمًا تحديد الرمز المميز ذو الاحتمالية الأعلى
- الحالة: الحالة قيد الإنشاء، وهذا يعني أن النموذج قيد الضبط حاليًا
- create_time: الوقت الذي تم فيه إنشاء النموذج
- update_time: هو الوقت الذي تم فيه ضبط النموذج آخر مرة
- tuning_task: يحتوي على المعلمات التي حددناها للضبط، والتي تشمل درجة الحرارة والعصور وحجم الدفعة
بدء عملية التدريب
يمكننا أيضًا الحصول على الحالة والبيانات الوصفية للنموذج المضبوط من خلال الكود التالي:
print(operation.metadata)
يعرض هنا إجمالي الخطوات، أي 950، وهو أمر يمكن التنبؤ به. لأنه في مثالنا لدينا 1900 صف من بيانات التدريب. في كل خطوة، نأخذ دفعة من 4، أي 4 صفوف، لذلك لعصر واحد كامل لدينا 1900/4، أي 475 خطوة. لقد حددنا حقبتين للتدريب، مما يعني أن 2*2 = 475 خطوة.
مراقبة تقدم التدريب
ينشئ الكود أدناه شريط حالة يوضح مقدار النسبة المئوية للتدريب الذي تم الانتهاء منه والوقت الذي سيستغرقه إكمال عملية التدريب بأكملها:
import time
for status in operation.wait_bar():
time.sleep(30)
يقوم الكود أعلاه بإنشاء شريط تقدم، وعند اكتماله يعني أن عملية الضبط لدينا قد انتهت.
تصور أداء التدريب
يحتوي كائن العملية أيضًا على لقطات من التدريب. أنها ستحتوي على مقاييس التقييم مثل متوسط الخسارة لكل فترة. يمكننا تصور ذلك بالكود التالي:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- هنا نحصل على النموذج المضبوط النهائي من العملية.النتيجة ()
- عندما ندرب النموذج، يأخذ النموذج لقطات على فترات زمنية متكررة. تحتوي هذه اللقطات على بيانات مثل متوسط الخسارة. ومن ثم نقوم باستخراج لقطات النموذج الذي تم ضبطه عن طريق استدعاء model.tuning_task.snapshots
- نقوم بإنشاء إطار بيانات من هذه اللقطات عن طريق تمرير اللقطات إلى pd.DataFrame وتخزينها في متغير اللقطات
- وأخيرًا، نقوم بإنشاء مخطط خطي من بيانات اللقطة المستخرجة
سيؤدي تشغيل الكود إلى الرسم البياني التالي:
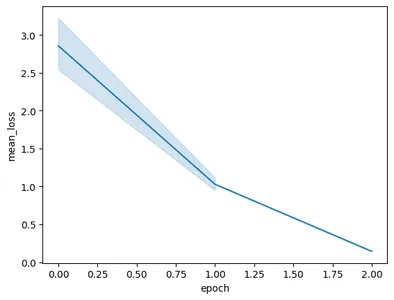
في هذه الصورة، يمكننا أن نرى أننا قمنا بتقليل الخسارة من 3 إلى أقل من 0.5 في فترتين فقط من التدريب. وأخيرًا، انتهينا من تدريب نموذج الجوزاء
اختبار نموذج الجوزاء المضبوط
في هذا القسم، سوف نقوم باختبار نموذجنا على بيانات الاختبار. الآن للعمل مع النموذج المضبوط، نعمل بالكود التالي:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')سيقوم الكود أعلاه بتحميل النموذج المضبوط الذي قمنا بتدريبه للتو باستخدام بيانات معلومات التعريف الشخصية. والآن سنقوم باختبار هذا النموذج ببعض الأمثلة من بيانات الاختبار التي وضعناها جانبًا. لهذا دعونا نطبع text_input العشوائي والمخرجات المقابلة له من مجموعة الاختبار:
print(df_test['text_input'][1900])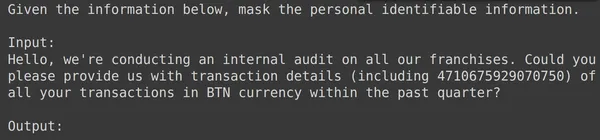
df_test['output'][1900]
أعلاه يمكننا أن نرى text_input عشوائي والمخرجات المأخوذة من مجموعة الاختبار. سنقوم الآن بتمرير text_input هذا إلى النموذج وملاحظة المخرجات التي تم إنشاؤها:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
نرى أن النموذج كان ناجحًا في إخفاء معلومات التعريف الشخصية لمدخل النص المحدد وأن المخرجات التي تم إنشاؤها بواسطة النموذج تتطابق تمامًا مع المخرجات من مجموعة الاختبار. الآن دعونا نجرب ذلك مع بعض الأمثلة الإضافية:
print(df_test['text_input'][1969])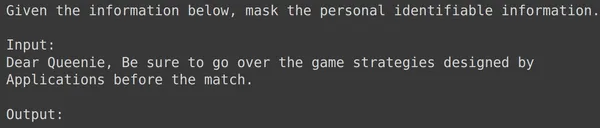
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])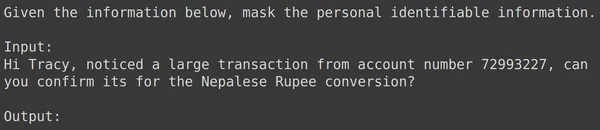
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])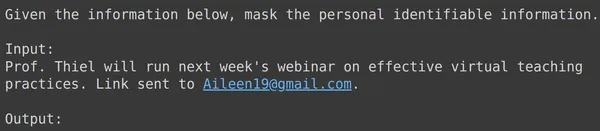
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
بالنسبة لجميع الأمثلة المذكورة أعلاه، نرى أن أداء نموذجنا المضبوط جيدًا. كان النموذج قادرًا على التعلم من بيانات التدريب المقدمة وتطبيق الإخفاء بشكل صحيح لإخفاء المعلومات الشخصية الحساسة. لذلك رأينا من البداية إلى النهاية كيفية إنشاء مجموعة بيانات للضبط الدقيق وكيفية ضبط نموذج الجوزاء على مجموعة بيانات والنتائج التي نراها تبدو واعدة جدًا بالنسبة للنموذج الدقيق
وفي الختام
في الختام، قدم هذا الدليل دليلاً شاملاً حول ضبط نماذج Gemini الرائدة من Google لإخفاء معلومات التعريف الشخصية (PII). لقد بدأنا باستكشاف منشور مدونة Google حول إمكانية الضبط الدقيق لنماذج Gemini، مع تسليط الضوء على الحاجة إلى الضبط الدقيق لهذه النماذج لتحقيق دقة خاصة بالمهمة. من خلال الخطوات العملية الموضحة في الدليل، بما في ذلك إعداد مجموعة البيانات، وضبط نموذج Gemini، واختبار أدائه، يمكن للمستخدمين تسخير قوة نماذج اللغة الكبيرة لمهام إخفاء معلومات تحديد الهوية الشخصية (PII).
فيما يلي النقاط الرئيسية من هذا الدليل:
- توفر نماذج Gemini مكتبة قوية للضبط الدقيق، مما يسمح للمستخدمين بتخصيصها لمهام محددة، بما في ذلك إخفاء معلومات تحديد الهوية الشخصية (PII)، من خلال الضبط الفعال للمعلمات (PET)
- يعد إعداد مجموعة البيانات خطوة حاسمة، حيث تتضمن تثبيت الوحدات الضرورية، وبدء OAuth لأمن البيانات، وتنسيق البيانات للتدريب
- تتضمن عملية الضبط الدقيق توفير معلمات مثل النموذج الأساسي وعدد العصور وحجم الدفعة ومعدل التعلم لتدريب نموذج Gemini على مجموعة البيانات المعدة
- يتم تسهيل مراقبة تقدم التدريب من خلال تحديثات الحالة وتصورات المقاييس مثل متوسط الخسارة لكل فترة
- يؤدي اختبار النموذج الدقيق على مجموعة بيانات اختبار منفصلة إلى التحقق من أدائه في إخفاء معلومات تحديد الهوية الشخصية (PII) بدقة مع الحفاظ على سلامة البيانات
- توضح الأمثلة المقدمة فعالية نموذج جيميني المضبوط في إخفاء المعلومات الشخصية الحساسة بنجاح، مما يشير إلى نتائج واعدة لتطبيقات العالم الحقيقي
الأسئلة المتكررة
A. يعد الضبط الفعال للمعلمات (PET) أحد تقنيات الضبط الدقيق التي تعمل فقط على ضبط مجموعة صغيرة من معلمات النموذج. يتم استخدام هذا بواسطة Google لضبط الطبقات المهمة بسرعة في نموذج الجوزاء. فهو يكيف النموذج بكفاءة مع بيانات المستخدم، مما يحسن أدائه لمهام محددة
ج: يتضمن ضبط نموذج Gemini توفير معلمات مثل اسم النموذج الأساسي وعدد العصور وحجم الدفعة ومعدل التعلم. تؤثر هذه المعلمات على عملية التدريب وتؤثر في النهاية على أداء النموذج
ج. يمكن للمستخدمين مراقبة تقدم التدريب لنموذج Gemini المضبوط من خلال تحديثات الحالة، وتصورات المقاييس مثل متوسط الخسارة لكل فترة، ومن خلال مراقبة لقطات عملية التدريب
ج: قبل ضبط نموذج Gemini، يحتاج المستخدمون إلى تثبيت المكتبات الضرورية مثل google-geneativeai ومجموعات البيانات. بالإضافة إلى ذلك، يعد بدء OAuth لأمان البيانات وتنسيق مجموعة البيانات للتدريب خطوات مهمة
ج. يمكن تطبيق نموذج Gemini المضبوط في مجالات مختلفة حيث يكون إخفاء معلومات تحديد الهوية الشخصية (PII) ضروريًا، مثل إخفاء هوية البيانات، والحفاظ على الخصوصية في تطبيقات البرمجة اللغوية العصبية (NLP)، والامتثال للوائح حماية البيانات مثل اللائحة العامة لحماية البيانات (GDPR).
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

