المُقدّمة
لقد أحدث ظهور الذكاء الاصطناعي والتعلم الآلي ثورة في كيفية تفاعلنا مع المعلومات، مما يسهل استرجاعها وفهمها واستخدامها. في هذا الدليل العملي، نستكشف إنشاء مساعد أسئلة وأجوبة متطور مدعوم من LLamA2 وLLamAIndex، مع الاستفادة من نماذج اللغة الحديثة وأطر الفهرسة للتنقل في بحر من مستندات PDF دون عناء. تم تصميم هذا البرنامج التعليمي لتمكين المطورين وعلماء البيانات وعشاق التكنولوجيا بالأدوات والمعرفة اللازمة لبناء نظام توليد الاسترجاع المعزز (RAG) الذي يقف على أكتاف العمالقة في مجال البرمجة اللغوية العصبية.
في سعينا لإزالة الغموض عن إنشاء مساعد للأسئلة والأجوبة يعتمد على الذكاء الاصطناعي، يمثل هذا الدليل جسرًا بين المفاهيم النظرية المعقدة وتطبيقها العملي في سيناريوهات العالم الحقيقي. من خلال دمج فهم اللغة المتقدم لـ LLamA2 مع قدرات LLamAIndex الفعالة لاسترجاع المعلومات، فإننا نهدف إلى بناء نظام يجيب على الأسئلة بدقة ويعمق فهمنا للإمكانات والتحديات في مجال البرمجة اللغوية العصبية. تعد هذه المقالة بمثابة خريطة طريق شاملة للمتحمسين والمهنيين، حيث تسلط الضوء على التآزر بين النماذج المتطورة والمتطلبات المتطورة باستمرار لتكنولوجيا المعلومات.

أهداف التعلم
- قم بتطوير نظام RAG باستخدام نموذج LLamA2 من Hugging Face.
- دمج مستندات PDF متعددة.
- فهرسة المستندات لاسترجاعها بكفاءة.
- صياغة نظام الاستعلام.
- قم بإنشاء مساعد قوي قادر على الإجابة على الأسئلة المختلفة.
- التركيز على التنفيذ العملي بدلاً من الجوانب النظرية فقط.
- انخرط في البرمجة العملية والتطبيقات الواقعية.
- اجعل عالم البرمجة اللغوية العصبية المعقد متاحًا وجذابًا.
جدول المحتويات
نموذج LlamA2
LLamA2 هو منارة للابتكار في معالجة اللغة الطبيعية، مما يدفع حدود ما هو ممكن مع نماذج اللغة. تسمح هندسته المعمارية، المصممة لتحقيق الكفاءة والفعالية، بفهم غير مسبوق وإنشاء نص يشبه الإنسان. على عكس سابقاتها مثل BERT وGPT، يقدم LLamA2 نهجًا أكثر دقة لمعالجة اللغة، مما يجعله ماهرًا بشكل خاص في المهام التي تتطلب فهمًا عميقًا، مثل الإجابة على الأسئلة. تظهر فائدته في مختلف مهام البرمجة اللغوية العصبية، بدءًا من التلخيص وحتى الترجمة، تنوعه وقدرته على معالجة التحديات اللغوية المعقدة.

فهم LLamAIdex
الفهرسة هي العمود الفقري لأي نظام فعال لاسترجاع المعلومات. يبرز LLamAIndex، وهو إطار عمل مصمم لفهرسة المستندات والاستعلام عنها، من خلال توفير طريقة سلسة لإدارة مجموعات كبيرة من المستندات. لا يتعلق الأمر فقط بتخزين المعلومات؛ يتعلق الأمر بجعلها في متناول الجميع واسترجاعها في غمضة عين.

لا يمكن المبالغة في أهمية LLamAIndex، لأنها تتيح معالجة الاستعلام في الوقت الفعلي عبر قواعد بيانات واسعة النطاق، مما يضمن أن مساعد الأسئلة والأجوبة لدينا يمكنه تقديم إجابات سريعة ودقيقة مستمدة من قاعدة معرفية شاملة.
الترميز والتضمين
تتضمن الخطوة الأولى في فهم نماذج اللغة تقسيم النص إلى أجزاء يمكن التحكم فيها، وهي عملية تعرف باسم الترميز. هذه المهمة التأسيسية ضرورية لإعداد البيانات لمزيد من المعالجة. بعد الترميز، يأتي مفهوم التضمين حيز التنفيذ، حيث يترجم الكلمات والجمل إلى متجهات رقمية.
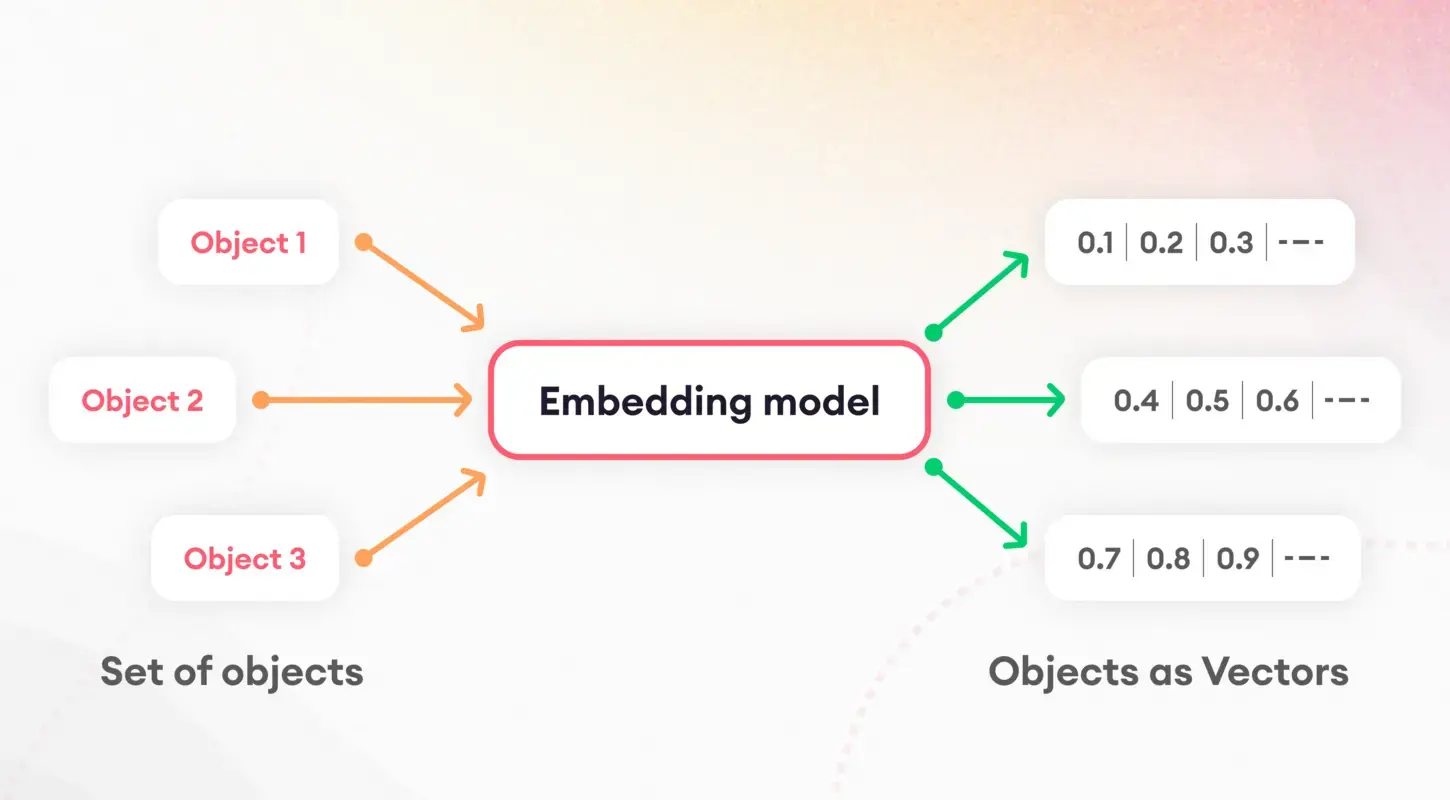
تلتقط هذه التضمينات جوهر السمات اللغوية، مما يمكّن النماذج من تمييز واستخدام الخصائص الدلالية الأساسية للنص. على وجه الخصوص، تلعب عمليات تضمين الجملة دورًا محوريًا في مهام مثل تشابه المستندات واسترجاعها، مما يشكل أساس استراتيجية الفهرسة لدينا.
التكميم النموذجي
يقدم نموذج التكميم استراتيجية لتعزيز أداء وكفاءة مساعد الأسئلة والأجوبة لدينا. ومن خلال تقليل دقة الحسابات الرقمية للنموذج، يمكننا تقليل حجمه بشكل كبير وتسريع أوقات الاستدلال. أثناء تقديم مقايضة بين الدقة والكفاءة، تعتبر هذه العملية ذات قيمة خاصة في البيئات المحدودة الموارد مثل الأجهزة المحمولة أو تطبيقات الويب. من خلال التطبيق الدقيق، يسمح لنا التكميم بالحفاظ على مستويات عالية من الدقة مع الاستفادة من انخفاض زمن الوصول ومتطلبات التخزين.
سياق الخدمة ومحرك الاستعلام
يعد ServiceContext داخل LLamAIndex مركزًا مركزيًا لإدارة الموارد والتكوينات، مما يضمن أن نظامنا يعمل بسلاسة وكفاءة. يربط الغراء تطبيقنا معًا، مما يتيح التكامل السلس بين التطبيقات نموذج LlamA2وعملية التضمين والمستندات المفهرسة. من ناحية أخرى، يعد محرك الاستعلام هو العمود الفقري الذي يعالج استعلامات المستخدم، ويستفيد من البيانات المفهرسة لجلب المعلومات ذات الصلة بسرعة. يضمن هذا الإعداد المزدوج أن مساعد الأسئلة والأجوبة لدينا يمكنه التعامل بسهولة مع الاستفسارات المعقدة، مما يوفر إجابات سريعة ودقيقة للمستخدمين.
تطبيق
دعونا نتعمق في التنفيذ. يرجى ملاحظة أنني استخدمت Google Colab لإنشاء هذا المشروع.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexتمهد هذه الأوامر الطريق عن طريق تثبيت المكتبات الضرورية، بما في ذلك المحولات للتفاعل النموذجي ومحولات الجملة للتضمينات. يعد تثبيت llama_index أمرًا بالغ الأهمية لإطار عمل الفهرسة الخاص بنا.
بعد ذلك، نقوم بتهيئة مكوناتنا (تأكد من إنشاء مجلد باسم "data" في قسم الملفات في Google Colab، ثم قم بتحميل ملف PDF إلى المجلد):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptبعد إعداد بيئتنا وقراءة المستندات، نقوم بصياغة موجه نظام لتوجيه استجابات نموذج LLamA2. يعد هذا القالب مفيدًا في ضمان توافق مخرجات النموذج مع توقعاتنا فيما يتعلق بالدقة والملاءمة.
!huggingface-cli login
يعد الأمر أعلاه بمثابة بوابة للوصول إلى مستودع نماذج Hugging Face الضخم. يتطلب رمزًا مميزًا للمصادقة.
عليك زيارة الرابط التالي: وجه يعانق (تأكد أولاً من تسجيل الدخول على Hugging Face)، ثم قم بإنشاء رمز مميز جديد، وقم بتوفير اسم للمشروع، وحدد النوع كمقروء، ثم انقر فوق إنشاء رمز مميز.
تؤكد هذه الخطوة على أهمية تأمين بيئة التطوير الخاصة بك وتخصيصها.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)هنا، نقوم بتهيئة نموذج LLamA2 بمعلمات محددة مصممة خصيصًا لنظام الأسئلة والأجوبة الخاص بنا. يسلط هذا الإعداد الضوء على تنوع النموذج وقدرته على التكيف مع سياقات وتطبيقات مختلفة.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))يعد اختيار نموذج التضمين أمرًا بالغ الأهمية لالتقاط الجوهر الدلالي لمستنداتنا. من خلال استخدام محولات الجملة، نضمن أن نظامنا يمكنه قياس مدى تشابه المحتوى النصي وأهميته بدقة، وبالتالي تعزيز فعالية عملية الفهرسة.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)يتم إنشاء مثيل ServiceContext بالإعدادات الافتراضية، وربط نموذج LLamA2 الخاص بنا ودمج النموذج في إطار عمل متماسك. تضمن هذه الخطوة أن جميع مكونات النظام متناغمة وجاهزة لعمليات الفهرسة والاستعلام.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()تشير هذه السطور إلى ذروة عملية الإعداد لدينا، حيث نقوم بفهرسة مستنداتنا وإعداد محرك الاستعلام. يعد هذا الإعداد محوريًا لنقل إعداد البيانات إلى رؤى قابلة للتنفيذ، مما يمكّن مساعد الأسئلة والأجوبة لدينا من الرد على الاستعلامات بناءً على المحتوى المفهرس.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)أخيرًا، قمنا باختبار نظامنا من خلال الاستعلام عنه للحصول على ملخصات وأفكار مستمدة من مجموعة المستندات الخاصة بنا. يوضح هذا التفاعل الفائدة العملية لمساعد الأسئلة والأجوبة لدينا ويعرض التكامل السلس بين LLamA2 وLLamAIndex والأساسي تقنيات البرمجة اللغوية العصبية التي تجعل من الممكن.
الإخراج:

الآثار الأخلاقية والقانونية
إن تطوير أنظمة الأسئلة والأجوبة التي تعمل بالذكاء الاصطناعي يجلب العديد من الاعتبارات الأخلاقية والقانونية إلى الواجهة. تعد معالجة التحيزات المحتملة في بيانات التدريب أمرًا بالغ الأهمية، فضلاً عن ضمان العدالة والحياد في الاستجابات. بالإضافة إلى ذلك، يعد الالتزام بلوائح خصوصية البيانات أمرًا بالغ الأهمية، حيث تتعامل هذه الأنظمة غالبًا مع المعلومات الحساسة. ويجب على المطورين التغلب على هذه التحديات بكل جدية ونزاهة، والالتزام بالمبادئ الأخلاقية التي تحمي المستخدمين وسلامة المعلومات المقدمة.
الاتجاهات والتحديات المستقبلية
إن مجال أنظمة الأسئلة والأجوبة مليء بفرص الابتكار، بدءًا من التفاعلات متعددة الوسائط وحتى التطبيقات الخاصة بالمجال. ومع ذلك، تأتي هذه التطورات مصحوبة بتحدياتها الخاصة، بما في ذلك التوسع لاستيعاب مجموعات المستندات الضخمة وضمان التنوع في استعلامات المستخدم. يعد التطوير والتحسين المستمر لنماذج مثل LLamA2 وأطر الفهرسة مثل LLamAIndex أمرًا بالغ الأهمية للتغلب على هذه العقبات ودفع حدود ما هو ممكن في البرمجة اللغوية العصبية.
دراسات الحالة والأمثلة
تؤكد التطبيقات الواقعية لأنظمة الأسئلة والأجوبة، مثل روبوتات خدمة العملاء والأدوات التعليمية، على تنوع وتأثير التقنيات مثل LLamA2 وLLamAIndex. توضح دراسات الحالة هذه التطبيقات العملية للذكاء الاصطناعي في صناعات متنوعة وتسلط الضوء على قصص النجاح والدروس المستفادة، مما يوفر رؤى قيمة للتطورات المستقبلية.
وفي الختام
لقد اجتاز هذا الدليل مشهد إنشاء مساعد الأسئلة والأجوبة المستند إلى PDF، بدءًا من المفاهيم الأساسية لـ LLamA2 وLLamAIndex وحتى خطوات التنفيذ العملية. وبينما نواصل استكشاف وتوسيع قدرات الذكاء الاصطناعي في استرجاع المعلومات ومعالجتها، فإن إمكانية تحويل تفاعلنا مع المعرفة لا حدود لها. وبالتسلح بهذه الأدوات والرؤى، فإن الرحلة نحو أنظمة أكثر ذكاءً واستجابة قد بدأت للتو.
الوجبات السريعة الرئيسية
- إحداث ثورة في التفاعل المعلوماتي: أدى تكامل الذكاء الاصطناعي والتعلم الآلي، المتمثل في LLamA2 وLLamAIndex، إلى تغيير طريقة وصولنا إلى المعلومات واستخدامها، مما مهد الطريق لمساعدي الأسئلة والأجوبة المتطورين القادرين على التنقل بسهولة بين مجموعات كبيرة من مستندات PDF.
- الجسر العملي بين النظرية والتطبيق: يعمل هذا الدليل على سد الفجوة بين المفاهيم النظرية والتنفيذ العملي، وتمكين المطورين وعشاق التكنولوجيا من بناء أنظمة توليد الاسترجاع المعزز (RAG) التي تستفيد من أحدث نماذج البرمجة اللغوية العصبية وأطر الفهرسة.
- أهمية الفهرسة الفعالة: يلعب LLamAIndex دورًا حاسمًا في استرجاع المعلومات بكفاءة من خلال فهرسة مجموعات المستندات الضخمة. ويضمن ذلك استجابات سريعة ودقيقة لاستفسارات المستخدم ويعزز الوظيفة العامة لمساعد الأسئلة والأجوبة.
- تحسين الأداء والكفاءة: تعمل تقنيات مثل تقدير حجم النموذج على تحسين أداء وكفاءة مساعدي الأسئلة والأجوبة، مما يسمح بتقليل زمن الوصول ومتطلبات التخزين دون المساس بالدقة.
- الاعتبارات الأخلاقية والتوجهات المستقبلية: يتطلب تطوير أنظمة الأسئلة والأجوبة المدعومة بالذكاء الاصطناعي معالجة الآثار الأخلاقية والقانونية، بما في ذلك تخفيف التحيز وخصوصية البيانات. وبالنظر إلى المستقبل، فإن التطورات في أنظمة الأسئلة والأجوبة توفر فرصًا للابتكار بينما تطرح أيضًا تحديات في قابلية التوسع وتنوع استعلامات المستخدم
أسئلة شائعة
الجواب. يقدم LLamA2 نهجًا أكثر دقة لمعالجة اللغة، مما يتيح مهام الفهم العميق مثل الإجابة على الأسئلة. تعطي بنيتها الأولوية للكفاءة والفعالية، مما يجعلها متعددة الاستخدامات عبر مهام البرمجة اللغوية العصبية المختلفة.
الجواب. LLamAIindex هو إطار عمل لفهرسة المستندات والاستعلام عنها، مما يسهل معالجة الاستعلام في الوقت الفعلي عبر قواعد بيانات واسعة النطاق. فهو يضمن أن مساعدي الأسئلة والأجوبة يمكنهم استرداد المعلومات ذات الصلة بسرعة من قواعد المعرفة الشاملة.
الجواب. التضمينات، وخاصة تضمينات الجملة، تلتقط الجوهر الدلالي للمحتوى النصي، مما يتيح القياس الدقيق للتشابه والملاءمة. يؤدي ذلك إلى تعزيز فعالية عملية الفهرسة، وتحسين قدرة المساعد على تقديم الاستجابات ذات الصلة.
الجواب. يعمل تكميم النموذج على تحسين الأداء والكفاءة عن طريق تقليل حجم الحسابات الرقمية، وبالتالي تقليل زمن الوصول ومتطلبات التخزين. ومع تقديم مقايضة بين الدقة والكفاءة، إلا أنها ذات قيمة في البيئات المحدودة الموارد.
الجواب. يجب على المطورين معالجة التحيزات المحتملة في بيانات التدريب، وضمان العدالة والحياد في الاستجابات، والالتزام بلوائح خصوصية البيانات. إن الالتزام بالمبادئ الأخلاقية يحمي المستخدمين ويحافظ على سلامة المعلومات المقدمة من مساعد الأسئلة والأجوبة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

