المُقدّمة
تعد آلة ناقل الدعم من الدرجة الواحدة (SVM) أحد أشكال SVM التقليدية. وهي مصممة خصيصا للكشف عن الحالات الشاذة. هدفها الأساسي هو تحديد الحالات التي تنحرف بشكل ملحوظ عن المعيار. على عكس التقليدية تعلم آلة النماذج التي تركز على التصنيف الثنائي أو متعدد الفئات، يتخصص SVM ذو الفئة الواحدة في الكشف عن العناصر الخارجية أو الجديدة ضمن مجموعات البيانات. في هذه المقالة، ستتعرف على كيفية اختلاف جهاز ناقل الدعم من فئة واحدة (SVM) عن جهاز SVM التقليدي. سوف تتعلم أيضًا كيفية عمل OC-SVM وكيفية تنفيذه. ستتعرف أيضًا على المعلمات الفائقة الخاصة به.
أهداف التعلم
- لفهم الشذوذ
- تعرف على SVM من فئة واحدة
- افهم كيف يختلف عن جهاز ناقل الدعم التقليدي (SVM)
- المعلمات الفائقة لـ OC-SVM في Sklearn
- كيفية اكتشاف الحالات الشاذة باستخدام OC-SVM
- حالات استخدام SVM من فئة واحدة
جدول المحتويات
فهم الشذوذ
الحالات الشاذة هي ملاحظات أو حالات تنحرف بشكل كبير عن السلوك الطبيعي لمجموعة البيانات. يمكن أن تظهر هذه الانحرافات في أشكال مختلفة، مثل القيم المتطرفة أو الضوضاء أو الأخطاء أو الأنماط غير المتوقعة. غالبًا ما تكون الحالات الشاذة رائعة لأنها قد تمثل رؤى قيمة. وقد يقدمون رؤى مثل تحديد المعاملات الاحتيالية، أو اكتشاف أعطال المعدات، أو الكشف عن ظواهر جديدة. يحدد اكتشاف الحداثة والجديدة الحالات الشاذة والملاحظات غير الطبيعية أو غير الشائعة.
اقرأ أيضا: دليل شامل لاكتشاف العيوب
فئة واحدة SVM
مقدمة لدعم الأجهزة المتجهة (SVMs)
دعم آلات المتجهات (SVMs) تحظى بشعبية خوارزمية التعلم تحت الإشراف لمهام التصنيف والانحدار. تعمل SVMs من خلال إيجاد المستوى الفائق الأمثل الذي يفصل بين الفئات المختلفة في مساحة الميزة مع زيادة الهامش بينها. يعتمد هذا المستوى الزائد على مجموعة فرعية من نقاط بيانات التدريب تسمى متجهات الدعم.
SVM من فئة واحدة مقابل SVM التقليدي
- تمثل SVMs من فئة واحدة نوعًا مختلفًا من خوارزمية SVM التقليدية المستخدمة بشكل أساسي في مهام الكشف الخارجية والجديدة. على عكس أجهزة SVM التقليدية، التي تتعامل مع مهام التصنيف الثنائية، فإن SVM من فئة واحدة تتدرب حصريًا على نقاط البيانات من فئة واحدة، تُعرف باسم الفئة المستهدفة. يهدف SVM من فئة واحدة إلى تعلم وظيفة الحدود أو القرار التي تغلف الفئة المستهدفة في مساحة الميزة، ونمذجة السلوك الطبيعي للبيانات بشكل فعال.
- تهدف SVMs التقليدية إلى إيجاد حدود القرار التي تزيد من الهامش بين الفئات المختلفة، مما يسمح بالتصنيف الأمثل لنقاط البيانات الجديدة. من ناحية أخرى، يسعى SVM من فئة واحدة إلى إيجاد حدود تغلف الفئة المستهدفة مع تقليل مخاطر تضمين القيم المتطرفة أو المثيلات الجديدة خارج هذه الحدود.
- تتطلب أجهزة SVM التقليدية بيانات مصنفة تحتوي على مثيلات من فئات متعددة، مما يجعلها مناسبة لمهام التصنيف الخاضعة للإشراف. في المقابل، يسمح SVM من فئة واحدة بالتطبيق في السيناريوهات التي تتوفر فيها البيانات من الفئة المستهدفة فقط، مما يجعلها مناسبة تمامًا للكشف عن الحالات الشاذة غير الخاضعة للرقابة ومهام الكشف عن الحداثة.
مزيد من المعلومات: تصنيف من فئة واحدة باستخدام آلات ناقلات الدعم
كلاهما يختلفان في تركيبات الهوامش الناعمة وطريقة استخدامها:
(يتم استخدام الهامش الناعم في SVM للسماح بدرجة معينة من سوء التصنيف)
يهدف SVM من فئة واحدة إلى اكتشاف مستوى فائق بأقصى هامش داخل مساحة الميزة عن طريق فصل البيانات المعينة عن الأصل. في مجموعة البيانات Dn = {x1, . . . , xn} مع xi ∈ X (xi هي ميزة) وأبعاد n:
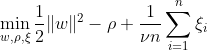
تمثل هذه المعادلة صياغة المشكلة الأولية لـ OC-SVM، حيث w هي الطائرة المفرطة المنفصلة، ρ هي الإزاحة من الأصل، و ξi هي متغيرات بطيئة. إنها تسمح بهامش بسيط ولكنها تعاقب الانتهاكات. تتحكم المعلمة الفائقة ν ∈ (0, 1] في تأثير متغير الركود ويجب تعديلها وفقًا للحاجة. الهدف هو تقليل معيار w مع معاقبة الانحرافات عن الهامش. علاوة على ذلك، يسمح هذا بتعديل جزء من البيانات تقع ضمن الهامش أو على الجانب الخطأ من المستوى الزائد.
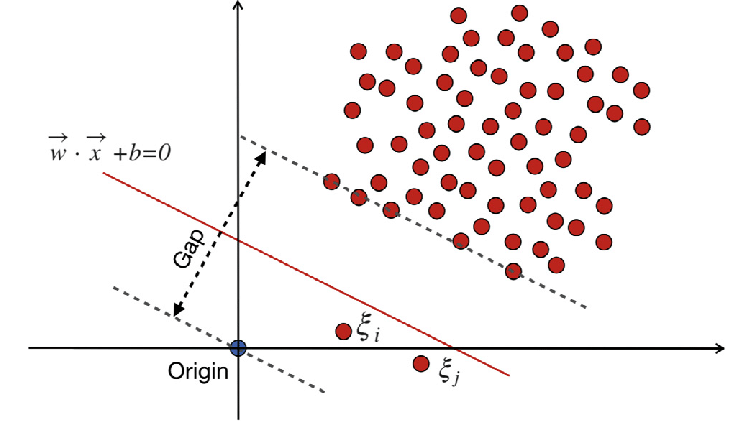
WX + b = 0 هي حدود القرار، والمتغيرات البطيئة تعاقب الانحرافات.
آلات ناقلات الدعم التقليدية (SVM)
تستخدم آلات ناقل الدعم التقليدية (SVM) صيغة الهامش الناعم لأخطاء التصنيف الخاطئ. أو يستخدمون نقاط البيانات التي تقع ضمن الهامش أو على الجانب الخطأ من حدود القرار.
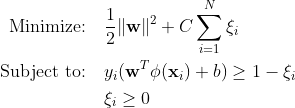
أين:
w هو ناقل الوزن.
ب هو مصطلح التحيز.
ξi هي متغيرات بطيئة تسمح بتحسين الهامش الناعم.
C هي معلمة التنظيم التي تتحكم في المفاضلة بين تعظيم الهامش وتقليل خطأ التصنيف.
يمثل ϕ(xi) وظيفة تعيين الميزات.
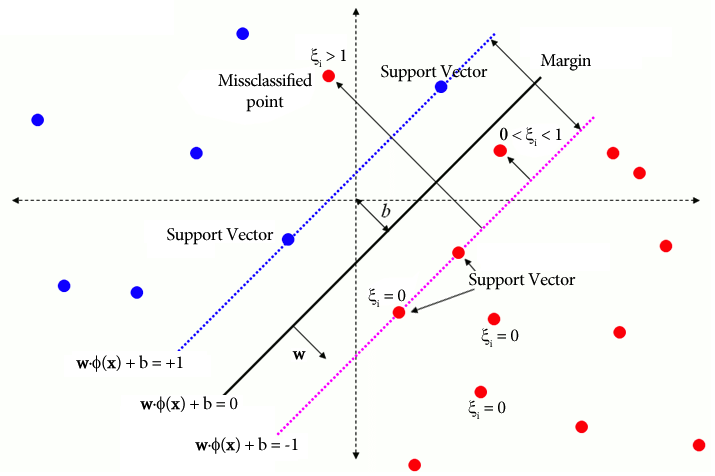
في SVM التقليدي، تتضمن طريقة التعلم الخاضع للإشراف والتي تعتمد على تسميات الفصل للفصل متغيرات Slack للسماح بمستوى معين من سوء التصنيف. الهدف الأساسي لـ SVM هو فصل نقاط البيانات من الفئات المميزة باستخدام حدود القرار WX + b = 0. تختلف قيمة متغيرات الركود اعتمادًا على موقع نقاط البيانات: يتم ضبطها على 0 إذا كانت نقاط البيانات موجودة خارج الهوامش. إذا كانت نقطة البيانات موجودة داخل الهامش، فإن متغيرات الركود تتراوح بين 0 و1، وتمتد إلى ما بعد الهامش المقابل إذا كان أكبر من 1.
تهدف كل من SVMs التقليدية وSVMs من فئة واحدة ذات تركيبات هامشية ناعمة إلى تقليل معيار ناقل الوزن. ومع ذلك، فإنها تختلف في أهدافها وكيفية التعامل مع أخطاء التصنيف الخاطئ أو الانحرافات عن حدود القرار. تعمل أجهزة SVM التقليدية على تحسين دقة التصنيف لتجنب التجهيز الزائد، بينما تركز أجهزة SVM ذات الفئة الواحدة على نمذجة الفئة المستهدفة والتحكم في نسبة القيم المتطرفة أو المثيلات الجديدة.
اقرأ أيضا: دليل AZ لدعم آلة المتجهات
المعلمات الفائقة الهامة في SVM من فئة واحدة
- نو: يعد هذا أحد المعلمات الفائقة الحاسمة في SVM من فئة واحدة، والذي يتحكم في نسبة القيم المتطرفة المسموح بها. فهو يحدد حدًا أعلى لجزء من أخطاء التدريب وحدًا أدنى لجزء من متجهات الدعم. وتتراوح عادة بين 0 و1، حيث تشير القيم المنخفضة إلى هامش أكثر صرامة وقد تلتقط عددًا أقل من القيم المتطرفة، في حين أن القيم الأعلى تكون أكثر تساهلاً. القيمة الافتراضية هي 0.5.
- نواة: تحدد وظيفة kernel نوع حدود القرار التي يستخدمها SVM. تتضمن الاختيارات الشائعة "خطي"، و"rbf" (دالة أساس شعاعي غاوسي)، و"poly" (متعدد الحدود)، و"السيني". غالبًا ما يتم استخدام نواة "rbf" لأنها يمكنها التقاط العلاقات غير الخطية المعقدة بشكل فعال.
- غاما: هذه معلمة للطائرات الفائقة غير الخطية. فهو يحدد مدى تأثير مثال تدريبي واحد. كلما كانت قيمة جاما أكبر، كلما كانت الأمثلة الأخرى أقرب للتأثر. هذه المعلمة خاصة بنواة RBF ويتم تعيينها عادةً على "تلقائي"، والتي تكون القيمة الافتراضية 1 / n_features.
- معلمات النواة (الدرجة، coef0): هذه المعلمات مخصصة للنواة متعددة الحدود والسينية. "الدرجة" هي درجة دالة النواة متعددة الحدود، و"coef0" هو المصطلح المستقل في دالة النواة. قد يكون ضبط هذه المعلمات ضروريًا لتحقيق الأداء الأمثل.
- الرقم: هذا هو معيار التوقف. تتوقف الخوارزمية عندما تكون فجوة الازدواجية أصغر من التسامح. إنها معلمة تتحكم في التسامح مع معيار التوقف.
مبدأ العمل لـ SVM من فئة واحدة
وظائف النواة في SVM من فئة واحدة
تلعب وظائف Kernel دورًا حاسمًا في SVM من فئة واحدة من خلال السماح للخوارزمية بالعمل في مساحات ميزات ذات أبعاد أعلى دون حساب التحويلات بشكل صريح. في SVM من فئة واحدة، كما هو الحال في SVMs التقليدية، يتم استخدام وظائف kernel لقياس التشابه بين أزواج نقاط البيانات في مساحة الإدخال. تتضمن وظائف kernel الشائعة المستخدمة في SVM من فئة واحدة نواة غاوسية (RBF)، ومتعددة الحدود، ونواة سيني. تقوم هذه النوى بتعيين مساحة الإدخال الأصلية إلى مساحة ذات أبعاد أعلى، حيث تصبح نقاط البيانات قابلة للفصل خطيًا أو تظهر أنماطًا أكثر تميزًا، مما يسهل التعلم. من خلال اختيار وظيفة kernel مناسبة وضبط معلماتها، يمكن لـ One-Class SVM التقاط العلاقات المعقدة والهياكل غير الخطية في البيانات بشكل فعال، مما يحسن قدرتها على اكتشاف الحالات الشاذة أو القيم المتطرفة.
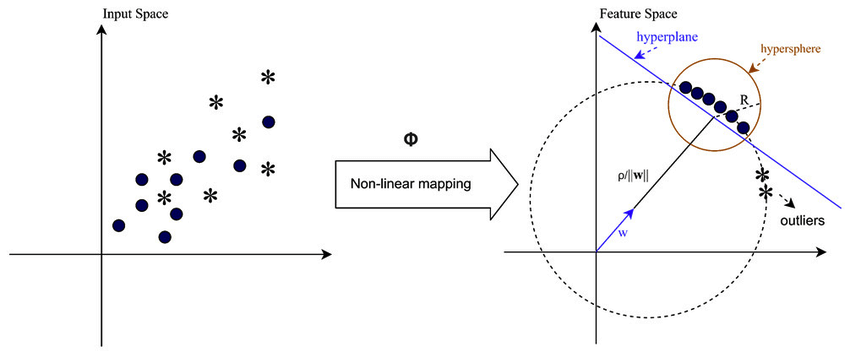
في الحالات التي لا تكون فيها البيانات قابلة للفصل خطيًا، كما هو الحال عند التعامل مع الأنماط المعقدة أو المتداخلة، يمكن لأجهزة المتجهات الداعمة (SVMs) استخدام نواة وظيفة الأساس الشعاعي (RBF) لفصل القيم المتطرفة عن بقية البيانات بشكل فعال. تقوم نواة RBF بتحويل بيانات الإدخال إلى مساحة ميزات ذات أبعاد أعلى يمكن فصلها بشكل أفضل.
ناقلات الهامش والدعم
يشبه مفهوم الهامش ومتجهات الدعم في SVM من فئة واحدة ذلك الموجود في SVMs التقليدية. يشير الهامش إلى المنطقة الواقعة بين حدود القرار (السطح الزائد) وأقرب نقاط البيانات من كل فئة. في SVM من فئة واحدة، يمثل الهامش المنطقة التي تقع فيها معظم نقاط البيانات التي تنتمي إلى الفئة المستهدفة. يعد تعظيم الهامش أمرًا بالغ الأهمية بالنسبة لـ One-Class SVM لأنه يساعد على تعميم نقاط البيانات الجديدة بشكل جيد ويحسن قوة النموذج. متجهات الدعم هي نقاط البيانات التي تقع على الهامش أو داخله وتساهم في تحديد حدود القرار.
في SVM من فئة واحدة، تكون متجهات الدعم هي نقاط البيانات من الفئة المستهدفة الأقرب إلى حدود القرار. تلعب متجهات الدعم هذه دورًا مهمًا في تحديد شكل واتجاه حدود القرار، وبالتالي، في الأداء العام لنموذج SVM من الفئة الواحدة. من خلال تحديد متجهات الدعم، يتعلم SVM من فئة واحدة بشكل فعال تمثيل الفئة المستهدفة في مساحة الميزة ويبني حدود القرار التي تغلف معظم نقاط البيانات مع تقليل مخاطر تضمين القيم المتطرفة أو المثيلات الجديدة.
كيف يمكن اكتشاف الحالات الشاذة باستخدام SVM من فئة واحدة؟
اكتشاف الحالات الشاذة باستخدام SVM من فئة واحدة (آلة ناقل الدعم) من خلال كل من تقنيات اكتشاف الحداثة والكشف الخارجي:
كشف خارجي
ويتضمن تحديد الملاحظات في بيانات التدريب التي تنحرف بشكل كبير عن الباقي، والتي تسمى غالبًا القيم المتطرفة. المقدرون ل الكشف الخارجى تهدف إلى ملاءمة المجالات التي تتركز فيها بيانات التدريب بشكل أكبر، متجاهلة هذه الملاحظات المنحرفة.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
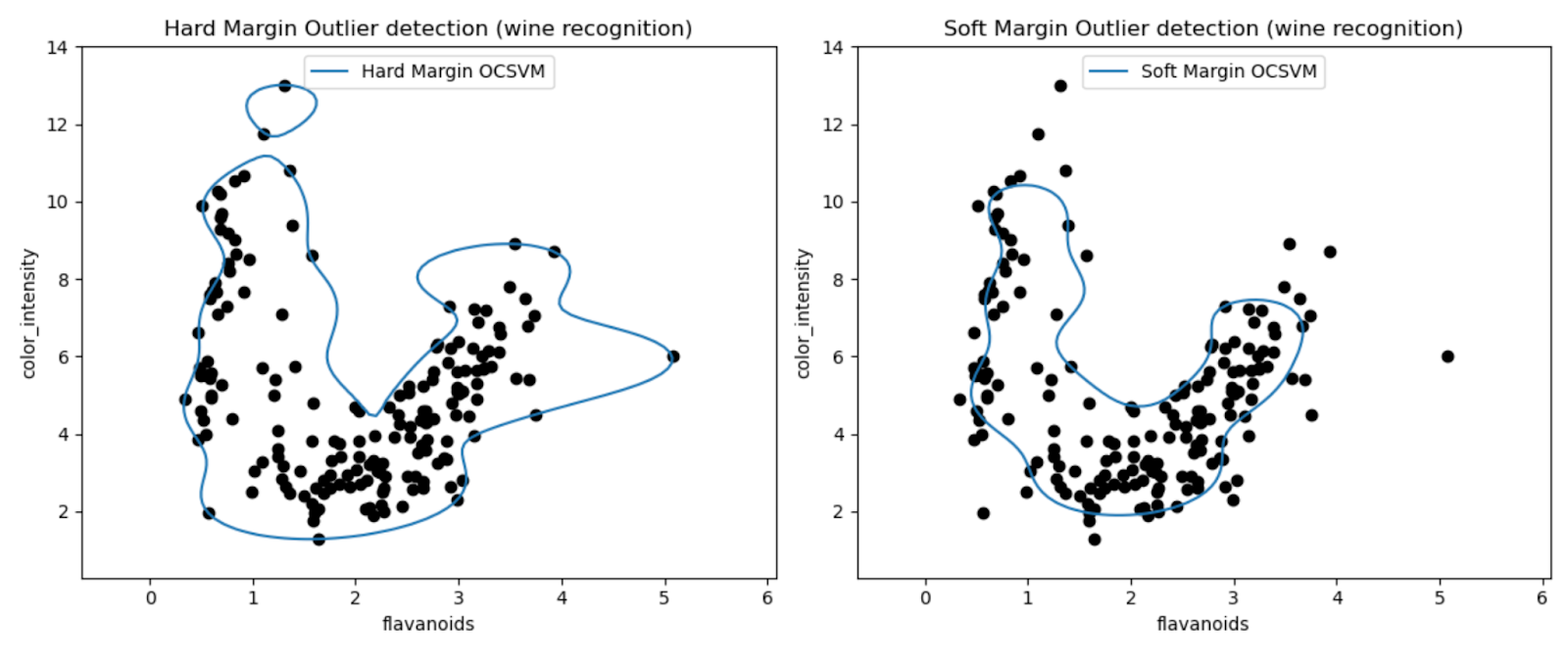
تسمح لنا المخططات بفحص أداء نماذج SVM من الفئة الواحدة بصريًا في اكتشاف القيم المتطرفة في مجموعة بيانات Wine.
من خلال مقارنة نتائج نماذج SVM ذات الهامش الثابت والهامش الناعم من فئة واحدة، يمكننا ملاحظة كيف يؤثر اختيار إعداد الهامش (معلمة nu) على الاكتشاف الخارجي.
من المحتمل أن يؤدي نموذج الهامش الثابت بقيمة نو صغيرة جدًا (0.01) إلى حدود قرار أكثر تحفظًا. إنه يلتف بإحكام حول غالبية نقاط البيانات ومن المحتمل أن يصنف عددًا أقل من النقاط على أنها قيم متطرفة.
على العكس من ذلك، من المحتمل أن يؤدي نموذج الهامش الناعم ذو القيمة النووية الأكبر (0.35) إلى حدود قرار أكثر مرونة. وبالتالي السماح بهامش أوسع وربما التقاط المزيد من القيم المتطرفة.
كشف الجدة
ومن ناحية أخرى، فإننا نطبقها عندما تكون بيانات التدريب خالية من القيم المتطرفة، والهدف هو تحديد ما إذا كانت الملاحظة الجديدة نادرة، أي مختلفة تمامًا عن الملاحظات المعروفة. هذه الملاحظة الأخيرة هنا تسمى حداثة.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- قم بإنشاء مجموعة بيانات تركيبية تحتوي على مجموعتين من نقاط البيانات. قم بذلك عن طريق توليدها بتوزيع طبيعي حول مركزين مختلفين: (2، 2) و (-2، -2) لبيانات التدريب والاختبار. قم بإنشاء عشرين نقطة بيانات بشكل عشوائي داخل منطقة مربعة تتراوح من -4 إلى 4 على طول كلا البعدين. تمثل نقاط البيانات هذه ملاحظات غير طبيعية أو قيم متطرفة تنحرف بشكل كبير عن السلوك الطبيعي الملحوظ في بيانات التدريب والاختبار.
- تشير الحدود المستفادة إلى حدود القرار التي تعلمها نموذج SVM من فئة واحدة. تفصل هذه الحدود مناطق مساحة الميزة حيث يعتبر النموذج نقاط البيانات طبيعية عن القيم المتطرفة.
- يمثل التدرج اللوني من الأزرق إلى الأبيض في الخطوط درجات متفاوتة من الثقة أو اليقين التي يعينها نموذج SVM من فئة واحدة لمناطق مختلفة في مساحة الميزة، مع ظلال داكنة تشير إلى ثقة أعلى في تصنيف نقاط البيانات على أنها "طبيعية". يشير اللون الأزرق الداكن إلى المناطق ذات الإشارة القوية إلى كونها "طبيعية" وفقًا لوظيفة اتخاذ القرار الخاصة بالنموذج. عندما يصبح اللون أفتح في الكفاف، يكون النموذج أقل ثقة بشأن تصنيف نقاط البيانات على أنها "طبيعية".
- تمثل الحبكة بصريًا كيف يمكن لنموذج SVM من الفئة الواحدة التمييز بين الملاحظات المنتظمة وغير الطبيعية. تفصل حدود القرار المستفادة بين مناطق الملاحظات العادية وغير الطبيعية. يثبت SVM من فئة واحدة للكشف عن الجدة فعاليته في تحديد الملاحظات غير الطبيعية في مجموعة بيانات معينة.
بالنسبة للنو = 0.5:
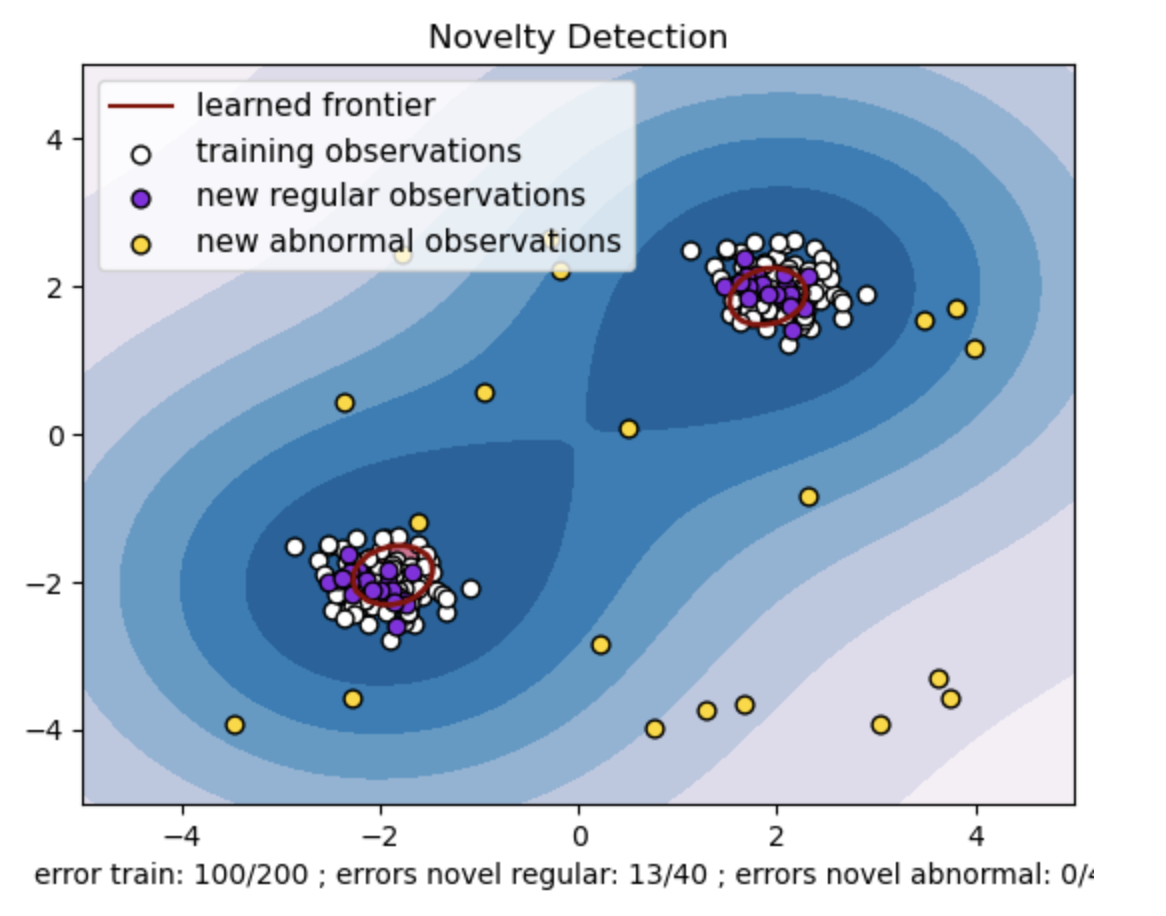
تلعب قيمة "nu" في SVM من فئة واحدة دورًا حاسمًا في التحكم في جزء القيم المتطرفة التي يتحملها النموذج. فهو يؤثر بشكل مباشر على قدرة النموذج على تحديد الحالات الشاذة وبالتالي يؤثر على التنبؤ. يمكننا أن نرى أن النموذج يسمح بتصنيف 100 نقطة تدريب بشكل خاطئ. تشير القيمة المنخفضة لـ nu إلى وجود قيود أكثر صرامة على الجزء المسموح به من القيم المتطرفة. يؤثر اختيار nu على أداء النموذج في اكتشاف الحالات الشاذة. ويتطلب أيضًا ضبطًا دقيقًا استنادًا إلى المتطلبات المحددة للتطبيق وخصائص مجموعة البيانات.
لجاما = 0.5 و نو = 0.5
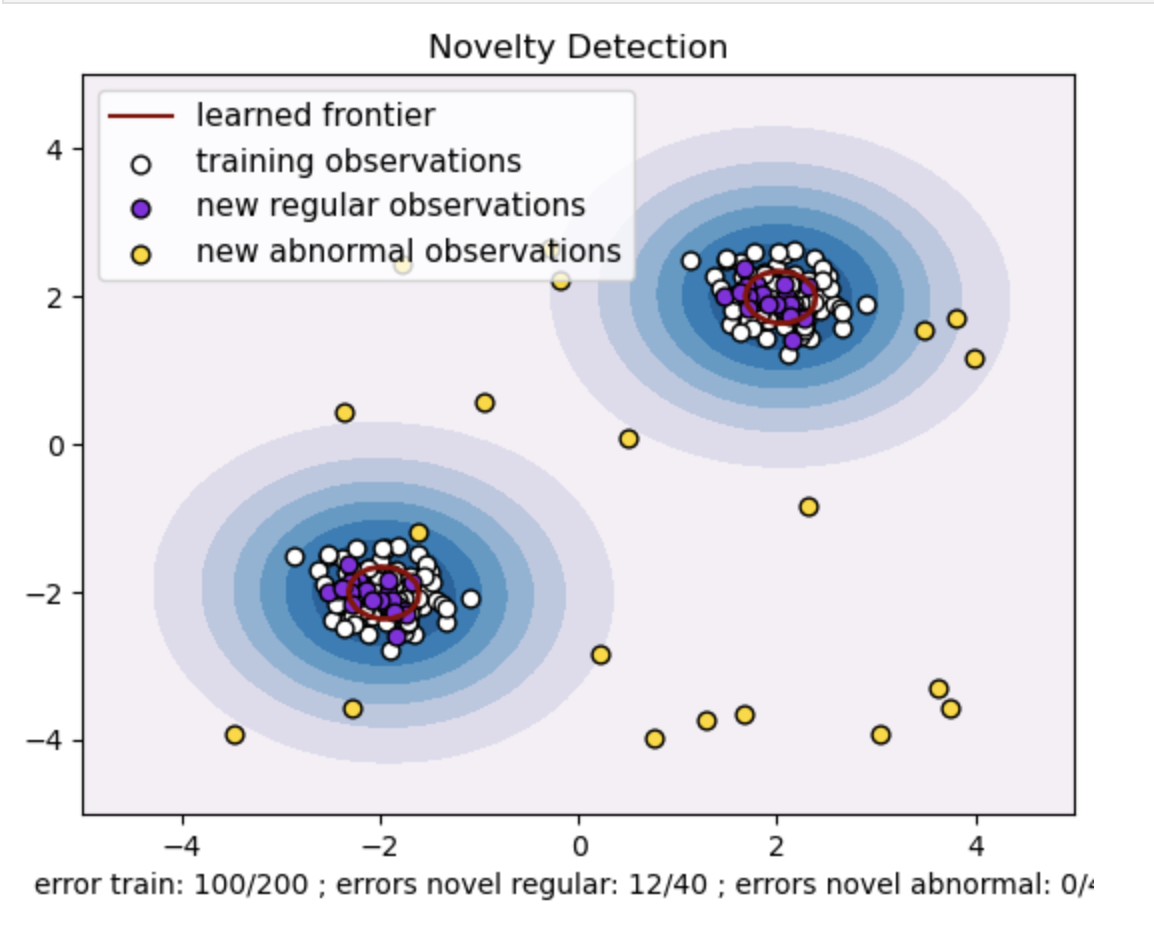
في SVM من فئة واحدة، تمثل معلمة جاما الفائقة معامل kernel للنواة 'rbf'. تؤثر هذه المعلمة الفائقة على شكل حدود القرار، وبالتالي تؤثر على الأداء التنبؤي للنموذج.
عندما تكون جاما عالية، فإن مثال تدريبي واحد يحد من تأثيرها على المنطقة المجاورة لها مباشرة. يؤدي هذا إلى إنشاء حدود قرار أكثر محلية. لذلك، يجب أن تكون نقاط البيانات أقرب إلى متجهات الدعم حتى تنتمي إلى نفس الفئة.
وفي الختام
يوفر استخدام SVM من فئة واحدة للكشف عن الحالات الشاذة، واستخدام الكشف الغريب والجديد حلاً قويًا عبر مجالات مختلفة. يساعد هذا في السيناريوهات التي تكون فيها البيانات الشاذة المصنفة نادرة أو غير متوفرة. مما يجعلها ذات قيمة خاصة في تطبيقات العالم الحقيقي حيث تكون الحالات الشاذة نادرة ويصعب تحديدها بشكل صريح. وتمتد حالات استخدامه إلى مجالات متنوعة، مثل الأمن السيبراني وتشخيص الأخطاء، حيث يكون للحالات الشاذة عواقب. ومع ذلك، على الرغم من أن One-Class SVM يقدم فوائد عديدة، فمن الضروري تعيين المعلمات الفائقة وفقًا للبيانات للحصول على نتائج أفضل، وهو ما قد يكون مملاً في بعض الأحيان.
الأسئلة المتكررة
A. يقوم SVM من فئة واحدة بإنشاء مستوى فائق (أو كرة مفرطة في أبعاد أعلى) يقوم بتغليف نقاط البيانات العادية. تم وضع هذا المستوى الزائد لتعظيم الهامش بين البيانات العادية وحدود القرار. يتم تصنيف نقاط البيانات على أنها عادية (داخل الحدود) أو شاذة (خارج الحدود) أثناء الاختبار أو الاستدلال.
ج: يعتبر SVM من فئة واحدة مفيدًا لأنه لا يتطلب بيانات مصنفة للحالات الشاذة أثناء التدريب. ويمكنه التعلم من مجموعة بيانات تحتوي على حالات عادية فقط، مما يجعله مناسبًا للسيناريوهات التي تكون فيها الحالات الشاذة نادرة ويصعب الحصول على أمثلة مصنفة للتدريب.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

