البيانات هي أداة تمييز الذكاء الاصطناعي التوليدية، وهي أداة ناجحة الذكاء الاصطناعي التوليدي يعتمد التنفيذ على استراتيجية بيانات قوية تتضمن استراتيجية شاملة بيانات الإدارة يقترب. يتطلب العمل مع نماذج اللغات الكبيرة (LLMs) لحالات الاستخدام المؤسسي تنفيذ اعتبارات الجودة والخصوصية لدفع الذكاء الاصطناعي المسؤول. ومع ذلك، فإن بيانات المؤسسة التي تم إنشاؤها من مصادر منعزلة إلى جانب عدم وجود استراتيجية لتكامل البيانات تخلق تحديات أمام توفير البيانات لتطبيقات الذكاء الاصطناعي التوليدية. الحاجة إلى نهاية إلى نهاية استراتيجية لإدارة البيانات ولا تزال حوكمة البيانات في كل خطوة من الرحلة - بدءًا من استيعاب البيانات وتخزينها والاستعلام عنها وحتى تحليل وتصور وتشغيل نماذج الذكاء الاصطناعي (AI) والتعلم الآلي (ML) - ذات أهمية قصوى للمؤسسات.
في هذا المنشور، نناقش احتياجات إدارة البيانات لخطوط أنابيب بيانات تطبيقات الذكاء الاصطناعي التوليدية، وهي لبنة بناء مهمة للتحكم في البيانات المستخدمة من قبل LLMs لتحسين دقة وأهمية استجاباتهم لمطالبات المستخدم بطريقة آمنة ومأمونة وشفافة. تقوم المؤسسات بذلك عن طريق استخدام البيانات الخاصة مع أساليب مثل توليد الاسترجاع المعزز (RAG)، والضبط الدقيق، والتدريب المسبق المستمر باستخدام النماذج الأساسية.
تعد حوكمة البيانات لبنة أساسية في جميع هذه الأساليب، ونحن نرى مجالين ناشئين للتركيز. أولاً، تعتمد العديد من حالات استخدام LLM على المعرفة المؤسسية التي يجب استخلاصها من البيانات غير المنظمة مثل المستندات والنصوص والصور، بالإضافة إلى البيانات المنظمة من مستودعات البيانات. عادةً ما يتم تخزين البيانات غير المنظمة عبر أنظمة منعزلة بتنسيقات مختلفة، ولا تتم إدارتها أو التحكم فيها بشكل عام بنفس مستوى الدقة مثل البيانات المنظمة. ثانيًا، تقدم تطبيقات الذكاء الاصطناعي التوليدية عددًا أكبر من تفاعلات البيانات مقارنة بالتطبيقات التقليدية، الأمر الذي يتطلب تنفيذ سياسات أمن البيانات والخصوصية والتحكم في الوصول كجزء من سير عمل مستخدم الذكاء الاصطناعي التوليدي.
في هذا المنشور، نغطي حوكمة البيانات لبناء تطبيقات الذكاء الاصطناعي التوليدية على AWS مع التركيز على مصادر المعرفة المؤسسية المنظمة وغير المنظمة، ودور حوكمة البيانات أثناء سير عمل الاستجابة لطلبات المستخدمين.
نظرة عامة على حالة الاستخدام
دعنا نستكشف مثالاً لمساعد الذكاء الاصطناعي لدعم العملاء. يوضح الشكل التالي سير عمل المحادثة النموذجي الذي يبدأ بمطالبة المستخدم.

يتضمن سير العمل خطوات إدارة البيانات الرئيسية التالية:
- موجه التحكم في وصول المستخدم وسياسات الأمان.
- سياسات الوصول لاستخراج الأذونات بناءً على البيانات ذات الصلة وتصفية النتائج بناءً على دور المستخدم والأذونات السريعة.
- فرض سياسات خصوصية البيانات مثل عمليات تنقيح معلومات التعريف الشخصية (PII).
- فرض التحكم الدقيق في الوصول.
- منح أذونات دور المستخدم للمعلومات الحساسة وسياسات الامتثال.
لتوفير استجابة تتضمن سياق المؤسسة، يحتاج كل موجه مستخدم إلى تعزيزه بمجموعة من الرؤى من البيانات المنظمة من مستودع البيانات والبيانات غير المنظمة من بحيرة بيانات المؤسسة. على الواجهة الخلفية، تحتاج عمليات هندسة البيانات المجمعة التي تعمل على تحديث بحيرة بيانات المؤسسة إلى التوسع لاستيعاب البيانات غير المنظمة وتحويلها وإدارتها. وكجزء من عملية التحويل، يجب معالجة الكائنات لضمان خصوصية البيانات (على سبيل المثال، تنقيح معلومات تحديد الهوية الشخصية). وأخيرًا، يجب أيضًا توسيع سياسات التحكم في الوصول لتشمل كائنات البيانات غير المنظمة وإلى مخازن بيانات المتجهات.
دعونا نلقي نظرة على كيفية تطبيق إدارة البيانات على مسارات بيانات مصدر المعرفة في المؤسسة وسير عمل الاستجابة لطلبات المستخدمين.
المعرفة المؤسسية: إدارة البيانات
يلخص الشكل التالي اعتبارات إدارة البيانات لخطوط تدفق البيانات وسير العمل لتطبيق إدارة البيانات.
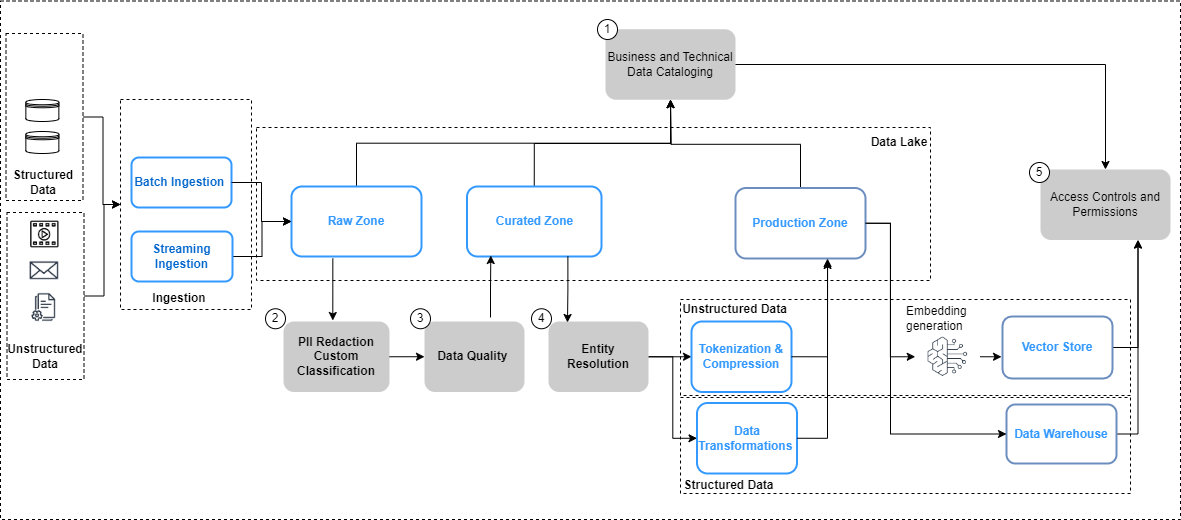
في الشكل أعلاه، تتضمن مسارات هندسة البيانات خطوات إدارة البيانات التالية:
- إنشاء وتحديث الكتالوج من خلال تطور البيانات.
- تنفيذ سياسات خصوصية البيانات.
- تنفيذ جودة البيانات حسب نوع البيانات ومصدرها.
- ربط مجموعات البيانات المنظمة وغير المنظمة.
- تنفيذ ضوابط الوصول الموحدة الدقيقة لمجموعات البيانات المنظمة وغير المنظمة.
دعونا نلقي نظرة على بعض التغييرات الرئيسية في خطوط أنابيب البيانات، وهي فهرسة البيانات، وجودة البيانات، وأمن تضمين المتجهات بمزيد من التفاصيل.
إمكانية اكتشاف البيانات
على عكس البيانات المنظمة، التي تتم إدارتها في صفوف وأعمدة محددة جيدًا، يتم تخزين البيانات غير المنظمة ككائنات. لكي يتمكن المستخدمون من اكتشاف البيانات واستيعابها، تتمثل الخطوة الأولى في إنشاء كتالوج شامل باستخدام البيانات الوصفية التي يتم إنشاؤها والتقاطها في الأنظمة المصدر. يبدأ ذلك بالكائنات (مثل المستندات وملفات النصوص) التي يتم استيعابها من أنظمة المصدر ذات الصلة إلى المنطقة الأولية في بحيرة البيانات in خدمة تخزين أمازون البسيطة (Amazon S3) بتنسيقاتها الأصلية (كما هو موضح في الشكل السابق). من هنا، يتم إنشاء البيانات التعريفية للكائن (مثل مالك الملف وتاريخ الإنشاء ومستوى السرية). مستخرج و تم الاستعلام عنها باستخدام إمكانيات Amazon S3. يمكن أن تختلف البيانات التعريفية حسب مصدر البيانات، ومن المهم فحص الحقول، واستخلاص الحقول الضرورية، عند الاقتضاء، لإكمال كافة البيانات التعريفية الضرورية. على سبيل المثال، إذا لم يتم وضع علامة على سمة مثل سرية المحتوى على مستوى المستند في التطبيق المصدر، فقد يلزم اشتقاق ذلك كجزء من عملية استخراج بيانات التعريف وإضافتها كسمة في كتالوج البيانات. تحتاج عملية الاستيعاب إلى التقاط تحديثات الكائنات (التغييرات والحذف) بالإضافة إلى الكائنات الجديدة بشكل مستمر. للحصول على إرشادات التنفيذ التفصيلية، راجع إدارة البيانات غير المنظمة وحوكمتها باستخدام خدمات AWS AI/ML والتحليلات. لمزيد من تبسيط الاكتشاف والاستبطان بين مسارد الأعمال وكتالوجات البيانات التقنية، يمكنك استخدام أمازون داتازون لمستخدمي الأعمال لاكتشاف ومشاركة البيانات المخزنة عبر صوامع البيانات.
خصوصية البيانات
غالبًا ما تحتوي مصادر المعرفة المؤسسية على معلومات تحديد الهوية الشخصية (PII) وبيانات حساسة أخرى (مثل العناوين وأرقام الضمان الاجتماعي). استنادًا إلى سياسات خصوصية البيانات الخاصة بك، يجب معالجة هذه العناصر (إخفائها أو ترميزها أو تنقيحها) من المصادر قبل أن يتم استخدامها في حالات الاستخدام النهائية. من المنطقة الأولية في Amazon S3، يجب معالجة الكائنات قبل أن يتم استهلاكها بواسطة نماذج الذكاء الاصطناعي التوليدية. الشرط الرئيسي هنا هو تحديد معلومات تحديد الهوية الشخصية (PII) وتنقيحهاوالتي يمكنك التنفيذ بها فهم الأمازون. من المهم أن تتذكر أنه لن يكون من الممكن دائمًا تجريد جميع البيانات الحساسة دون التأثير على سياق البيانات. السياق الدلالي يعد أحد العوامل الرئيسية التي تحدد دقة وملاءمة مخرجات نماذج الذكاء الاصطناعي التوليدية، ومن المهم العمل بشكل عكسي من حالة الاستخدام وتحقيق التوازن اللازم بين عناصر التحكم في الخصوصية وأداء النموذج.
إثراء البيانات
بالإضافة إلى ذلك، قد يلزم استخراج بيانات تعريف إضافية من الكائنات. يوفر Amazon Comprehend إمكانيات لـ التعرف على الكيان (على سبيل المثال، تحديد البيانات الخاصة بالمجال مثل أرقام البوليصة وأرقام المطالبات) و تصنيف مخصص (على سبيل المثال، تصنيف نص محادثة خدمة العملاء استنادًا إلى وصف المشكلة). علاوة على ذلك، قد تحتاج إلى الجمع بين البيانات غير المنظمة والبيانات المنظمة لإنشاء صورة شاملة للكيانات الرئيسية، مثل العملاء. على سبيل المثال، في سيناريو ولاء شركات الطيران، ستكون هناك قيمة كبيرة في ربط التقاط البيانات غير المنظمة لتفاعلات العملاء (مثل نصوص دردشة العملاء ومراجعات العملاء) مع إشارات البيانات المنظمة (مثل شراء التذاكر واستبدال الأميال) لإنشاء تجربة أكثر اكتمالاً ملف تعريف العميل الذي يمكنه بعد ذلك تمكين تقديم توصيات أفضل وأكثر صلة بالرحلة. حل كيان AWS هي خدمة ML تساعد في مطابقة السجلات وربطها. تساعد هذه الخدمة على ربط مجموعات المعلومات ذات الصلة لإنشاء بيانات أعمق وأكثر ارتباطًا حول الكيانات الرئيسية مثل العملاء والمنتجات وما إلى ذلك، مما يمكن أن يزيد من تحسين جودة مخرجات LLM وملاءمتها. يتوفر هذا في المنطقة المحولة في Amazon S3 وهو جاهز للاستهلاك في المراحل النهائية لمخازن المتجهات أو الضبط الدقيق أو تدريب حاملي شهادات الماجستير. بعد هذه التحويلات، يمكن إتاحة البيانات في المنطقة المنسقة في Amazon S3.
جودة البيانات
يعتمد أحد العوامل الحاسمة لتحقيق الإمكانات الكاملة للذكاء الاصطناعي التوليدي على جودة البيانات المستخدمة لتدريب النماذج بالإضافة إلى البيانات المستخدمة لزيادة وتعزيز استجابة النموذج لمدخلات المستخدم. إن فهم النماذج ونتائجها في سياق الدقة والتحيز والموثوقية يتناسب بشكل مباشر مع جودة البيانات المستخدمة لبناء النماذج وتدريبها.
الأمازون SageMaker نموذج مراقب يوفر اكتشافًا استباقيًا للانحرافات في انجراف جودة بيانات النموذج وانجراف مقاييس جودة النموذج. كما أنه يراقب انحراف التحيز في تنبؤات النموذج الخاص بك وإسناد الميزة. لمزيد من التفاصيل، راجع مراقبة نماذج ML أثناء الإنتاج على نطاق واسع باستخدام Amazon SageMaker Model Monitor. يعد اكتشاف التحيز في النموذج الخاص بك لبنة أساسية للذكاء الاصطناعي المسؤول، و توضيح Amazon SageMaker يساعد على اكتشاف التحيز المحتمل الذي يمكن أن يؤدي إلى نتيجة سلبية أو أقل دقة. لمعرفة المزيد، راجع تعرف على كيفية مساعدة Amazon SageMaker Clarify في اكتشاف التحيز.
مجال التركيز الأحدث في الذكاء الاصطناعي التوليدي هو استخدام وجودة البيانات في المطالبات من مخازن البيانات الخاصة بالمؤسسات والملكية. أفضل الممارسات الناشئة التي يجب مراعاتها هنا هي تحول اليسار، والذي يركز بشدة على آليات ضمان الجودة المبكرة والاستباقية. في سياق خطوط أنابيب البيانات المصممة لمعالجة البيانات لتطبيقات الذكاء الاصطناعي التوليدية، فإن هذا يعني تحديد مشكلات جودة البيانات وحلها في وقت مبكر للتخفيف من التأثير المحتمل لمشكلات جودة البيانات لاحقًا. جودة بيانات AWS Glue لا يقوم فقط بقياس ومراقبة جودة بياناتك غير النشطة في بحيرات البيانات ومستودعات البيانات وقواعد بيانات المعاملات، ولكنه يسمح أيضًا بالكشف المبكر عن مشكلات الجودة وتصحيحها لخطوط الاستخراج والتحويل والتحميل (ETL) الخاصة بك لضمان بياناتك يلبي معايير الجودة قبل استهلاكه. لمزيد من التفاصيل، راجع بدء استخدام AWS Glue Data Quality من AWS Glue Data Catalog.
إدارة متجر المتجهات
التضمين في قواعد بيانات المتجهات رفع مستوى ذكاء وقدرات تطبيقات الذكاء الاصطناعي التوليدية من خلال تمكين ميزات مثل البحث الدلالي وتقليل الهلوسة. تحتوي عمليات التضمين عادةً على بيانات خاصة وحساسة، ويعد تشفير البيانات خطوة موصى بها في سير عمل إدخال المستخدم. أمازون أوبن سيرش سيرفرليس يقوم بتخزين وبحث تضمينات المتجهات الخاصة بك، وتشفير بياناتك أثناء الراحة خدمة إدارة مفتاح AWS (أوس كيه إم إس). لمزيد من التفاصيل، انظر نقدم لكم المحرك المتجه لـ Amazon OpenSearch Serverless، وهو الآن قيد المعاينة. وبالمثل، فإن خيارات محرك المتجهات الإضافية على AWS، بما في ذلك أمازون كندرا و أمازون أورورا، قم بتشفير بياناتك غير النشطة باستخدام AWS KMS. لمزيد من المعلومات، راجع التشفير عند الراحة و حماية البيانات باستخدام التشفير.
نظرًا لإنشاء التضمينات وتخزينها في مخزن متجه، يصبح التحكم في الوصول إلى البيانات باستخدام التحكم في الوصول المستند إلى الدور (RBAC) متطلبًا أساسيًا للحفاظ على الأمان العام. خدمة Amazon OpenSearch ويوفر ضوابط الوصول الدقيقة (FGAC) يتميز ب إدارة الهوية والوصول AWS (IAM) القواعد التي يمكن أن ترتبط بها أمازون كوجنيتو المستخدمين. يتم أيضًا توفير آليات التحكم في وصول المستخدم المقابلة بواسطة OpenSearch بدون خادم, أمازون كندرا، و أورورا. لمعرفة المزيد، راجع التحكم في الوصول إلى البيانات لـ Amazon OpenSearch Serverless, التحكم في وصول المستخدم إلى المستندات باستخدام الرموز المميزةو إدارة الهوية والوصول إلى Amazon Aurora، على التوالي.
سير عمل الاستجابة لطلب المستخدم
يجب دمج عناصر التحكم في مستوى إدارة البيانات في تطبيق الذكاء الاصطناعي التوليدي كجزء من الإجمالي نشر الحل لضمان الامتثال لسياسات أمن البيانات (استنادًا إلى عناصر التحكم في الوصول المستندة إلى الدور) وخصوصية البيانات (استنادًا إلى الوصول المستند إلى الدور إلى البيانات الحساسة). يوضح الشكل التالي سير العمل لتطبيق إدارة البيانات.
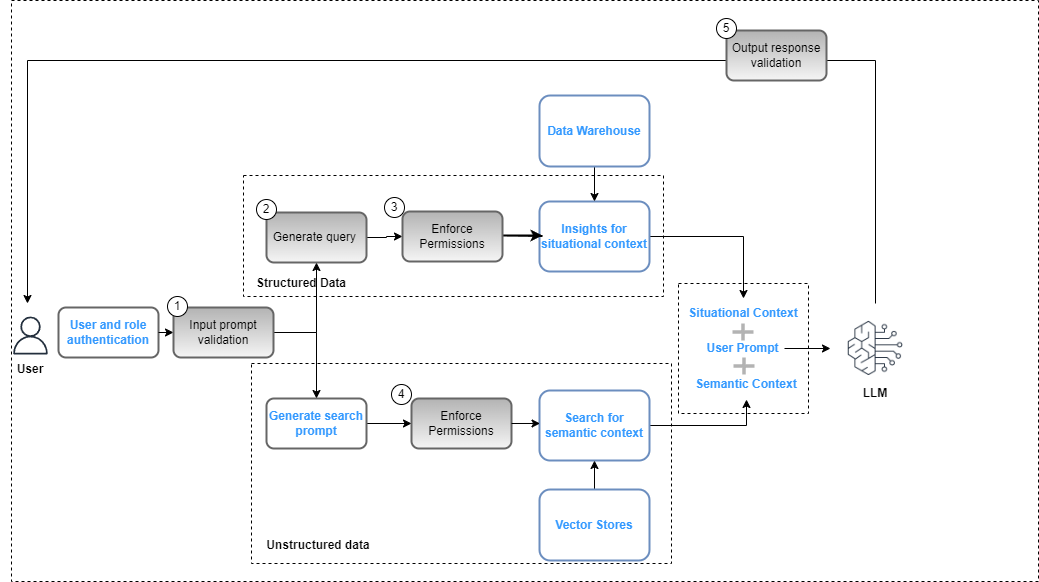
يتضمن سير العمل خطوات إدارة البيانات الرئيسية التالية:
- قم بتوفير موجه إدخال صالح للتوافق مع سياسات الامتثال (على سبيل المثال، التحيز والسمية).
- قم بإنشاء استعلام عن طريق تعيين الكلمات الأساسية السريعة باستخدام كتالوج البيانات.
- تطبيق سياسات FGAC بناءً على دور المستخدم.
- تطبيق سياسات RBAC بناءً على دور المستخدم.
- قم بتطبيق تنقيح البيانات والمحتوى على الاستجابة بناءً على أذونات دور المستخدم وسياسات الامتثال.
كجزء من دورة المطالبة، يجب تحليل مطالبة المستخدم واستخراج الكلمات الرئيسية لضمان توافقها مع سياسات الامتثال باستخدام خدمة مثل Amazon Comprehend (راجع الجديد في Amazon Comprehend - اكتشاف السمية) أو حواجز الحماية لأمازون بيدروك (معاينة). عند التحقق من صحة ذلك، إذا تطلب الموجه استخراج بيانات منظمة، فيمكن استخدام الكلمات الأساسية مقابل كتالوج البيانات (التجارية أو الفنية) لاستخراج جداول وحقول البيانات ذات الصلة وإنشاء استعلام من مستودع البيانات. يتم تقييم أذونات المستخدم باستخدام تكوين بحيرة AWS لتصفية البيانات ذات الصلة. في حالة البيانات غير المنظمة، يتم تقييد نتائج البحث بناءً على سياسات أذونات المستخدم المطبقة في مخزن المتجهات. كخطوة أخيرة، يجب تقييم استجابة المخرجات من LLM مقابل أذونات المستخدم (لضمان خصوصية البيانات وأمنها) والامتثال للسلامة (على سبيل المثال، إرشادات التحيز والسمية).
على الرغم من أن هذه العملية خاصة بتنفيذ RAG وتنطبق على استراتيجيات تنفيذ LLM الأخرى، إلا أن هناك ضوابط إضافية:
- الهندسة السريعة - يجب تقييد الوصول إلى قوالب المطالبة للاستدعاء بناءً على ذلك ضوابط الوصول مدعومة بمنطق الأعمال.
- نماذج الضبط الدقيق ونماذج أسس التدريب - في الحالات التي يتم فيها استخدام الكائنات من المنطقة المنسقة في Amazon S3 كبيانات تدريب لضبط النماذج الأساسية، يجب تكوين سياسات الأذونات باستخدام إدارة الهوية والوصول إلى Amazon S3 على مستوى الجرافة أو الكائن بناءً على المتطلبات.
نبذة عامة
تعد حوكمة البيانات أمرًا بالغ الأهمية لتمكين المؤسسات من بناء تطبيقات الذكاء الاصطناعي المولدة للمؤسسة. مع استمرار تطور حالات الاستخدام المؤسسي، ستكون هناك حاجة لتوسيع البنية التحتية للبيانات للتحكم وإدارة مجموعات البيانات الجديدة والمتنوعة وغير المنظمة لضمان التوافق مع سياسات الخصوصية والأمان والجودة. يجب تنفيذ هذه السياسات وإدارتها كجزء من استيعاب البيانات وتخزينها وإدارتها لقاعدة معارف المؤسسة جنبًا إلى جنب مع سير عمل تفاعل المستخدم. وهذا يضمن أن تطبيقات الذكاء الاصطناعي التوليدية لا تقلل فقط من مخاطر مشاركة المعلومات غير الدقيقة أو الخاطئة، ولكنها تحمي أيضًا من التحيز والسمية التي يمكن أن تؤدي إلى نتائج ضارة أو تشهيرية. لمعرفة المزيد حول إدارة البيانات على AWS، راجع ما هي إدارة البيانات؟
في المنشورات اللاحقة، سنقدم إرشادات التنفيذ حول كيفية توسيع حوكمة البنية التحتية للبيانات لدعم حالات الاستخدام التوليدي للذكاء الاصطناعي.
حول المؤلف
 كريشنا روباناجونتا يقود فريقًا من متخصصي البيانات والذكاء الاصطناعي في AWS. يعمل هو وفريقه مع العملاء لمساعدتهم على الابتكار بشكل أسرع واتخاذ قرارات أفضل باستخدام البيانات والتحليلات والذكاء الاصطناعي/التعلم الآلي. ويمكن الوصول إليه عبر LinkedIn.
كريشنا روباناجونتا يقود فريقًا من متخصصي البيانات والذكاء الاصطناعي في AWS. يعمل هو وفريقه مع العملاء لمساعدتهم على الابتكار بشكل أسرع واتخاذ قرارات أفضل باستخدام البيانات والتحليلات والذكاء الاصطناعي/التعلم الآلي. ويمكن الوصول إليه عبر LinkedIn.
 امتياز (طاز) سيد هو قائد WW Tech للتحليلات في AWS. إنه يستمتع بالتفاعل مع المجتمع في كل ما يتعلق بالبيانات والتحليلات. ويمكن الوصول إليه عبر LinkedIn.
امتياز (طاز) سيد هو قائد WW Tech للتحليلات في AWS. إنه يستمتع بالتفاعل مع المجتمع في كل ما يتعلق بالبيانات والتحليلات. ويمكن الوصول إليه عبر LinkedIn.
 راجفندر أرني (أرني) يقود فريق تسريع العملاء (CAT) داخل AWS Industries. CAT هو فريق عالمي متعدد الوظائف من المهندسين السحابيين الذين يواجهون العملاء ومهندسي البرمجيات وعلماء البيانات وخبراء ومصممي الذكاء الاصطناعي/تعلم الآلة الذين يدفعون الابتكار من خلال النماذج الأولية المتقدمة، ويدفعون التميز التشغيلي السحابي من خلال الخبرة الفنية المتخصصة.
راجفندر أرني (أرني) يقود فريق تسريع العملاء (CAT) داخل AWS Industries. CAT هو فريق عالمي متعدد الوظائف من المهندسين السحابيين الذين يواجهون العملاء ومهندسي البرمجيات وعلماء البيانات وخبراء ومصممي الذكاء الاصطناعي/تعلم الآلة الذين يدفعون الابتكار من خلال النماذج الأولية المتقدمة، ويدفعون التميز التشغيلي السحابي من خلال الخبرة الفنية المتخصصة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

