المُقدّمة
النقل والخدمات اللوجستية والطعام والتسوق والمدفوعات والاحتياجات اليومية والأعمال والأخبار والترفيه ، Gojek ، وهي شركة إندونيسية تقوم بكل ذلك من خلال تطبيق جوال يساهم بأكثر من 7 مليارات دولار في الاقتصاد. لديها 900 ألف تاجر مسجل ، وأكثر من 190 مليون تنزيل للتطبيق ، وأكثر من 2 مليون سائق يقدمون أكثر من 180 ألف طلب في غضون 120 دقيقة. إنه عملاق! باستخدام تحليلات الأعمال ، سنحل دراسة حالة. فيما يلي أحدث الخدمات التي يقدمها أكثر من 20 خدمة:

- النقل والخدمات اللوجستية
- Go-ride - سيارة الأجرة ذات العجلتين ، أوجيك الأصلي
- Go-car - راحة على العجلات. اجلس بالخلف. ينام. شخير.
- Go-send - أرسل أو احصل على طرود يتم تسليمها في غضون ساعات.
- Go-box - هل تريد الخروج؟ سنفعل الأوزان.
- Go-bluebird - ركوب حصري مع Bluebird.
- Go-Transit - مساعد التنقل الخاص بك ، مع Gojek أو بدونه
- الطعام والتسوق
- Go-mall - تسوق من سوق عبر الإنترنت
- Go-mart - توصيل للمنازل من المتاجر القريبة
- Go-med - اشتر الأدوية والفيتامينات وما إلى ذلك من الصيدليات المرخصة.
- الدفع
- Go-pay - قم بإسقاط المحفظة واذهب بدون نقود
- Go-bills - دفع الفواتير بسرعة وبساطة
- Paylater - اطلب الآن الدفع لاحقًا.
- Go-pulsa - بيانات أو وقت التحدث ، قم بزيادة رصيدك أثناء التنقل.
- Go-sure - تأمين الأشياء التي تقدرها.
- Go-give - تبرع من أجل ما يهم ، المس الحياة.
- Go-Investasi - استثمر بذكاء وادخر بشكل أفضل.
- الاحتياجات اليومية
- يسمح GoFitness للمستخدمين بالوصول إلى تمارين مثل اليوغا والبيلاتس والباوند والبار والمواي تاي وزومبا.
- باقة الأعمال
- Go-biz - تاجر #SuperApp لإدارة وتنمية الأعمال التجارية.
- الأخبار والترفيه
- Go-tix - احجز عرضك ، تخطى قائمة الانتظار.
- Go-play - تطبيق للأفلام والمسلسلات.
- Go-games - اتجاهات نصائح الألعاب وما إلى ذلك
- Go-news - أهم الأخبار من أفضل المجمّعين.
البيانات التي يتم إنشاؤها من خلال هذه الخدمات هائلة وفريق GO لديه حلول هندسية للتعامل مع مشكلات هندسة البيانات اليومية. فريق التحليل المركزي والعلوم (CAST) يمكّن العديد من المنتجات داخل نظام Gojek البيئي من استخدام وفرة البيانات المتضمنة في عمل التطبيق بكفاءة. يضم الفريق محللين وعلماء بيانات ومهندسي بيانات ومحللي أعمال وعلماء قرار يعملون على تطوير حلول تحليلات عميقة داخلية وأنظمة ML الأخرى.
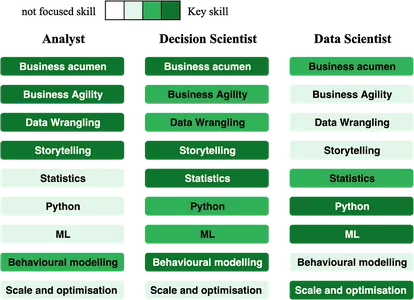
يتركز دور المحللين على حل مشاكل العمل اليومية ، والحصول على معرفة جيدة بالأعمال ، وخلق التأثير ، واشتقاق الرؤى ، و RCA (تحليل السبب الجذري) ، وإبقاء الإدارة العليا على اطلاع على المقاييس الجزئية والكلية ، وقرارات المنتج لمعالجة مشاكل العمل.
أهداف التعلم
- تحليل السبب الجذري حول محركات النمو والرياح المعاكسة التي تواجهها المنظمات.
- استخدام الباندا في EDA والتقطيع والتقطيع إلى مكعبات.
- تحسين ميزانية التسويق
- الأرباح بمقياس نجم الشمال (L0 metric)
- استخدام محلول اللب لحل LP.
- كتابة مشاكل LP باستخدام Pulps بتعليمات واضحة ونقية.
- الانحدار الخطي والتحقق المتبادل
- تمرين الانحدار البسيط باستخدام الخطوات الواردة في الاستبيان.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
المشكلة بيان
الجزء الأول
طلب مديرو GOJEK من محللي BI إلقاء نظرة على البيانات لفهم ما حدث خلال الربع الأول من عام 1 وما يجب عليهم فعله لزيادة الإيرادات للربع الثاني من عام 2016.
- بالنظر إلى البيانات الموجودة في المشكلة أ ، ما هي المشكلات الرئيسية التي نحتاج إلى التركيز عليها؟
- بالنظر إلى البيانات الواردة في الجدول ب ، كيف ستزيد الربح إلى أقصى حد إذا كان لدينا فقط ميزانية قدرها 40,000,000,000 روبية إندونيسية؟
- قدم نتائجك وحلولك الملموسة لاجتماع الإدارة.
الجزء الثاني
- مشكلة باستخدام الانحدار الخطي المتعدد ، توقع قيمة total_cbv.
- إنشاء نموذج واحد لكل خدمة.
- فترة التنبؤ = 2016-03-30 ، 2016-03-31 ، و 2016-04-01
- فترة التدريب = قائمة المتنبئين المتبقية:
- يوم من الشهر
- شهر
- يوم من الأسبوع
- علم عطلة نهاية الأسبوع / أيام الأسبوع (عطلة نهاية الأسبوع = السبت والأحد)
- المعالجة المسبقة (قم بذلك بالترتيب):
- إزالة GO-TIX
- احتفظ فقط بحالة الطلب "ملغاة"
- تأكد من وجود التوليفات الكاملة (المنتج الديكارتي) للتاريخ والخدمة
- نسب القيم المفقودة بـ 0
- إنشاء مؤشر إشارة is_weekend (1 في حالة السبت / الأحد ، 0 إذا كانت الأيام الأخرى)
- تشفير واحد ساخن للتنبؤ بالشهر واليوم من الأسبوع
- قم بتوحيد جميع المتنبئين في درجات z باستخدام المتوسط والانحراف المعياري عن بيانات فترة التدريب فقط
- مقياس التقييم: التحقق من صحة MAPE: مخطط ثلاثي. كل طية تحقق لها نفس طول فترة التنبؤ.
- السؤال 1 - بعد كل خطوات المعالجة المسبقة ، ما هي قيمة جميع المتنبئين للخدمة = GO-FOOD ، التاريخ = 2016-02-28؟
- السؤال 2 - إظهار الصفوف الستة الأولى من المتغيرات المشفرة الساخنة (الشهر واليوم من الأسبوع)
- السؤال 3 - طباعة أول 6 صفوف من البيانات بعد المعالجة المسبقة للخدمة = GO-KILAT. ترتيب تصاعدي حسب التاريخ
- السؤال 4 - حساب فترة التنبؤ MAPE لكل خدمة. عرض بترتيب تصاعدي على أساس MAPE
- السؤال 5 - قم بإنشاء رسوم بيانية لإظهار أداء كل طية تحقق. رسم بياني واحد خدمة واحدة. س = التاريخ ، ص = total_cbv. اللون: أسود = total_cbv فعلية ، ألوان أخرى = تنبؤات الطية (يجب أن يكون هناك 3 ألوان أخرى). أظهر فقط فترة التحقق من الصحة. على سبيل المثال ، إذا تم استخدام الصفوف 11 و 12 و 13 للتحقق من الصحة ، فلا تعرض الصفوف الأخرى في الرسوم البيانية. اعرض الشهر والتاريخ بوضوح على المحور السيني
الجزء الثالث
كان أداء خدمة GO-FOOD الخاصة بنا في سورابايا جيدًا للغاية الشهر الماضي - فقد حققوا زيادة بنسبة 20٪ في الطلبات المنجزة الشهر الماضي مقارنة بالشهر السابق. يحتاج مدير GO-FOOD في سورابايا إلى معرفة ما يحدث من أجل الحفاظ على هذا النجاح باستمرار للشهر التالي فصاعدًا.
- ما هي الأساليب الكمية التي ستستخدمها لتقييم النمو المفاجئ؟ كيف تقيم سلوك العملاء؟
بيانات
- جزء 1
- الجزء 2 [لينك]
حل الجزء الأول
قبل البدء في الحل ، ابدأ في البحث عن المدونات والأوراق التقنية الموجودة على موقع الشركة على الويب (تتم إضافة الروابط أدناه). توفر أرشيفات الشركة موارد مفيدة تعمل كمرشدين وتساعد على فهم ما تمثله الشركة أو ما تتوقعه الشركة من هذا الدور. يمكن اعتبار السؤالين الأول والثالث من المشاكل المفتوحة. السؤال الثاني هو تمرين بسيط على الانحدار ، ولا يركز بالضرورة على أفضل نموذج ، ولكن التركيز على العمليات المتضمنة في بناء نموذج.
تحليل السبب الجذري حول محركات النمو والرياح المعاكسة التي تواجهها المنظمات
بيانات الاستيراد:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
#import csv sales_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/sales_data_all.csv') print("Shape of the df")
display(sales_df.shape) print("HEAD")
display(sales_df.head()) print("NULL CHECK")
display(sales_df.isnull().any().sum()) print("NULL CHECK")
display(sales_df.isnull().sum()) print("df INFO")
display(sales_df.info()) print("DESCRIBE")
display(sales_df.describe())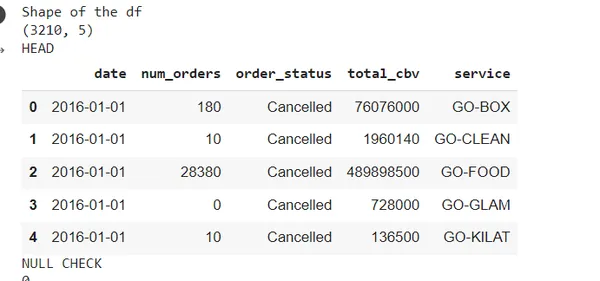
إنشاء الباندا التاريخ والوقت من تنسيق الكائن. تعد بيانات Pandas datetimes تنسيقًا سهلًا للتعامل مع التواريخ والتعامل معها. اشتق عمود الشهر من التاريخ والوقت. قم بتصفية الشهر الرابع (أبريل) أيضًا. إعادة تسمية الأشهر إلى يناير وفبراير ومارس.
## convert to date time # convert order_status to strinf
## time_to_pandas_time = ["date"] for cols in time_to_pandas_time: sales_df[cols] = pd.to_datetime(sales_df[cols]) sales_df.dtypes sales_df['Month'] = sales_df['date'].dt.month sales_df.head() sales_df['Month'].drop_duplicates() sales_df[sales_df['Month'] !=4] Q1_2016_df = sales_df[sales_df['Month'] !=4] Q1_2016_df['Month'] = np.where(Q1_2016_df['Month'] == 1,"Jan",np.where(Q1_2016_df['Month'] == 2,"Feb",np.where(Q1_2016_df['Month'] == 3,"Mar","Apr"))) print(Q1_2016_df.head(1)) display(Q1_2016_df.order_status.unique()) display(Q1_2016_df.service.unique())
#import csv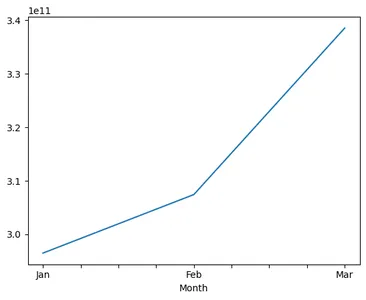

على مستوى المجموعة ، نما إجمالي الإيرادات بنسبة 14٪. هذه نتيجة إيجابية. دعنا نقسم هذا من خلال الخدمات المختلفة ونحدد الخدمات التي تعمل بشكل جيد.
revenue_total.sort_values(["Jan"], ascending=[False],inplace=True) revenue_total.head() revenue_total['cummul1'] = revenue_total["Jan"].cumsum()
revenue_total['cummul2'] = revenue_total["Feb"].cumsum()
revenue_total['cummul3'] = revenue_total["Mar"].cumsum() top_95_revenue = revenue_total[revenue_total["cummul3"]<=95 ] display(top_95_revenue)
ninety_five_perc_gmv = list(top_95_revenue.service.unique())
print(ninety_five_perc_gmv) top_95_revenue_plot = top_95_revenue[["Jan", "Feb", "Mar"]]
top_95_revenue_plot.index = top_95_revenue.service
top_95_revenue_plot.T.plot.line(figsize=(5,3)) ## share of revenue is changed but has the overall revenue changed for these top 4 services#import csv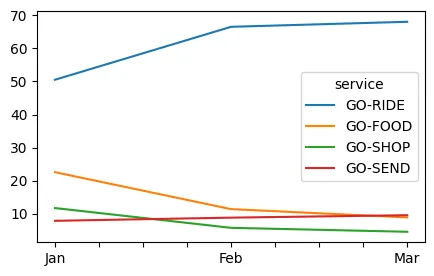

- للأشهر الثلاثة كلها ، ساهمت Ride و Food و Shop و Send في أكثر من 90٪ من صافي حصة الإيرادات (في Jan Ride ساهمت في 51٪ من صافي الإيرادات).
- ومن ثم ، باتباع قاعدة 80:20 للشهر الأخير ، يمكننا قصر هذا التحليل على أفضل 3 خدمات ، وهي - Ride ، و Food ، و Send.
- من بين 11 خدمة متاحة ، تساهم 3 خدمات فقط في أكثر من 90٪ من الإيرادات. هذا مدعاة للقلق وهناك فرصة هائلة لبقية الخدمات للنمو.
جولات كاملة
## NET - completed rides
Q1_2016_df_pivot_cbv_4 = Q1_2016_df[Q1_2016_df["order_status"] == "Completed"]
Q1_2016_df_pivot_cbv_4 = Q1_2016_df_pivot_cbv_4[Q1_2016_df_pivot_cbv_4.service.isin(ninety_five_perc_gmv)] Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv_4.pivot_table(index='service', columns=['Month' ], values='total_cbv', aggfunc= 'sum')
# display(Q1_2016_df_pivot_cbv.head())
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv[["Jan", "Feb", "Mar"]] for cols in Q1_2016_df_pivot_cbv.columns: Q1_2016_df_pivot_cbv[cols]=(Q1_2016_df_pivot_cbv[cols]/1000000000) display(Q1_2016_df_pivot_cbv) display(Q1_2016_df_pivot_cbv.T.plot()) ## We see that go shop as reduced its revenue but others the revenue is constant. Q1_2016_df_pivot_cbv_4 = Q1_2016_df_pivot_cbv
Q1_2016_df_pivot_cbv_4.reset_index(inplace = True) Q1_2016_df_pivot_cbv_4["Feb_jan_growth"] = (Q1_2016_df_pivot_cbv_4.Feb / Q1_2016_df_pivot_cbv_4.Jan -1)*100
Q1_2016_df_pivot_cbv_4["Mar_Feb_growth"] = (Q1_2016_df_pivot_cbv_4.Mar / Q1_2016_df_pivot_cbv_4.Feb -1)*100 display(Q1_2016_df_pivot_cbv_4)#import csv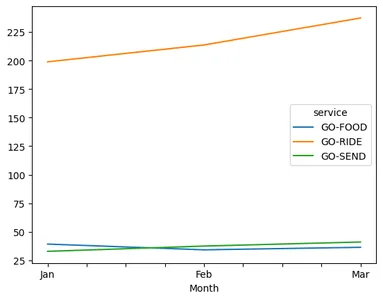

- Ride - وهو المحرك المحفز للإيرادات ، نما بنسبة 19٪ (من يناير إلى مارس) مقارنة بمحرك Send الذي نما بنسبة 25٪.
- انخفض الغذاء بنسبة 7٪ ، نظرًا لأن توصيل الطعام ينمو في جميع أنحاء العالم ، وهذا سبب رئيسي للقلق.
الرحلات الملغاة (فرصة ضائعة)
Q1_2016_df_pivot_cbv = Q1_2016_df[Q1_2016_df["order_status"] != "Completed"]
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv.pivot_table(index='service', columns=['Month' ], values='total_cbv', aggfunc= 'sum')
Q1_2016_df_pivot_cbv = Q1_2016_df_pivot_cbv[["Jan", "Feb", "Mar"]] revenue_total = pd.DataFrame() for cols in Q1_2016_df_pivot_cbv.columns: revenue_total[cols]=(Q1_2016_df_pivot_cbv[cols]/Q1_2016_df_pivot_cbv[cols].sum())*100 revenue_total.reset_index(inplace = True)
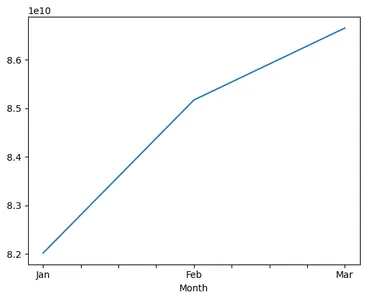
display(revenue_total.head()) overall_cbv = Q1_2016_df_pivot_cbv.sum()
print(overall_cbv)
overall_cbv.plot()
plt.show() overall_cbv = Q1_2016_df_pivot_cbv.sum()
overall_cbv_df = pd.DataFrame(data = overall_cbv).T
display(overall_cbv_df) overall_cbv_df["Feb_jan_growth"] = (overall_cbv_df.Feb / overall_cbv_df.Jan -1)*100
overall_cbv_df["Mar_Feb_growth"] = (overall_cbv_df.Mar / overall_cbv_df.Feb -1)*100 display(overall_cbv_df) revenue_total.sort_values(["Jan"], ascending=[False],inplace=True) revenue_total.head() revenue_total['cummul1'] = revenue_total["Jan"].cumsum()
revenue_total['cummul2'] = revenue_total["Feb"].cumsum()
revenue_total['cummul3'] = revenue_total["Mar"].cumsum() top_95_revenue = revenue_total[revenue_total["cummul3"]<=95 ] display(top_95_revenue)
ninety_five_perc_gmv = list(top_95_revenue.service.unique())
print(ninety_five_perc_gmv)

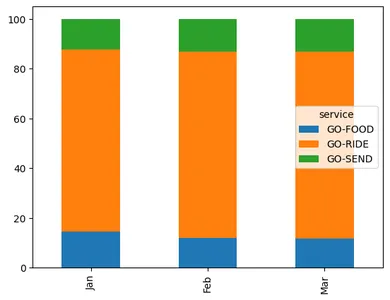
- نمت الإيرادات المفقودة بنسبة 6٪.
- يمكن للمديرين زيادة جهودهم لتقليل هذا إلى أقل من 5 ٪.
تحليل الطلبات
Q1_2016_df_can_com = Q1_2016_df[Q1_2016_df.order_status.isin(["Cancelled", "Completed"])]
Q1_2016_df_can_com = Q1_2016_df_can_com[Q1_2016_df_can_com.service.isin(ninety_five_perc_gmv)] Q1_2016_df_pivot = Q1_2016_df_can_com.pivot_table(index='service', columns=['order_status','Month' ], values='num_orders', aggfunc= 'sum')
Q1_2016_df_pivot.fillna(0, inplace = True) multi_tuples =[ ('Cancelled', 'Jan'), ('Cancelled', 'Feb'), ('Cancelled', 'Mar'), ('Completed', 'Jan'), ('Completed', 'Feb'), ('Completed', 'Mar')] multi_cols = pd.MultiIndex.from_tuples(multi_tuples, names=['Experiment', 'Lead Time']) Q1_2016_df_pivot = pd.DataFrame(Q1_2016_df_pivot, columns=multi_cols) display(Q1_2016_df_pivot.columns)
display(Q1_2016_df_pivot.head(3)) Q1_2016_df_pivot.columns = ['_'.join(col) for col in Q1_2016_df_pivot.columns.values] display(Q1_2016_df_pivot)
#import csv Q1_2016_df_pivot["jan_total"] = Q1_2016_df_pivot.Cancelled_Jan + Q1_2016_df_pivot.Completed_Jan
Q1_2016_df_pivot["feb_total"] = Q1_2016_df_pivot.Cancelled_Feb + Q1_2016_df_pivot.Completed_Feb
Q1_2016_df_pivot["mar_total"] = Q1_2016_df_pivot.Cancelled_Mar + Q1_2016_df_pivot.Completed_Mar Q1_2016_df_pivot[ "Cancelled_Jan_ratio" ] =Q1_2016_df_pivot.Cancelled_Jan/Q1_2016_df_pivot.jan_total
Q1_2016_df_pivot[ "Cancelled_Feb_ratio" ]=Q1_2016_df_pivot.Cancelled_Feb/Q1_2016_df_pivot.feb_total
Q1_2016_df_pivot[ "Cancelled_Mar_ratio" ]=Q1_2016_df_pivot.Cancelled_Mar/Q1_2016_df_pivot.mar_total
Q1_2016_df_pivot[ "Completed_Jan_ratio" ]=Q1_2016_df_pivot.Completed_Jan/Q1_2016_df_pivot.jan_total
Q1_2016_df_pivot[ "Completed_Feb_ratio" ]=Q1_2016_df_pivot.Completed_Feb/Q1_2016_df_pivot.feb_total
Q1_2016_df_pivot[ "Completed_Mar_ratio" ] =Q1_2016_df_pivot.Completed_Mar/Q1_2016_df_pivot.mar_total Q1_2016_df_pivot_1 = Q1_2016_df_pivot[["Cancelled_Jan_ratio"
,"Cancelled_Feb_ratio"
,"Cancelled_Mar_ratio"
,"Completed_Jan_ratio"
,"Completed_Feb_ratio"
,"Completed_Mar_ratio"]] Q1_2016_df_pivot_1
- في مارس ، تم إلغاء 17٪ و 15٪ و 13٪ من إجمالي الطلبات على التوالي.
- زادت المواد الغذائية من معدل إتمام طلباتها ، من 69٪ في يناير إلى 83٪ في مارس. هذا تحسن كبير.
## column wise cancellation check if increased
perc_of_cols_orders = pd.DataFrame() for cols in Q1_2016_df_pivot.columns: perc_of_cols_orders[cols]=(Q1_2016_df_pivot[cols]/Q1_2016_df_pivot[cols].sum())*100 perc_of_cols_orders perc_of_cols_cbv.T.plot(kind='bar', stacked=True)
perc_of_cols_orders.T.plot(kind='bar', stacked=True)
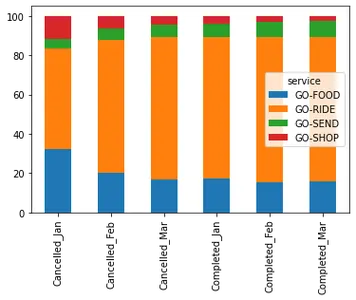

- في مارس ، من بين جميع الرحلات التي تم إلغاؤها ، حصلت Ride على 72٪ من الطلبات ، تليها Food (17٪) وأرسلت (6٪).
ملخص النتائج والتوصيات الخاصة بتحليلات الأعمال

- اركب -
- أكبر مساهم في الإيرادات.
- ارتفع معدل الإلغاء (GMV) في شهر مارس بنسبة 42٪
- قلل عمليات الإلغاء من خلال تدخل المنتج وميزات المنتج الجديدة.
- طعام -
- زادت الطلبات الملغاة ، ولكن بسبب تحسين التكلفة ، تم إيقاف خسارة GMV بنجاح.
- زيادة صافي الإيرادات عن طريق تقليل التكاليف والإلغاءات.
- زيادة اكتساب العملاء.
- إرسال -
- تم إلغاء أوامر GMV والأوامر الملغاة ، وقد تعرض كلاهما لضربة كبيرة ويشكلان سببًا رئيسيًا للقلق.
- خبرة جيدة في إكمال الركوب ، وبالتالي ، زيادة الاحتفاظ وتعزيز نمو الإيرادات من خلال الاحتفاظ.
تعظيم الأرباح عن طريق تحسين الإنفاق في الميزانية
يمتلك فريق العمل ميزانية قدرها 40 مليارًا للربع الثاني وقد وضع أهدافًا للنمو لكل خدمة. لكل خدمة ، ترد أدناه تكلفة 2 رحلة إضافية وأقصى هدف للنمو في الربع الثاني. بالنسبة لـ Go-Box ، للحصول على 100 حجز إضافي ، يكلف 2 مليونًا ، والحد الأقصى المستهدف للنمو في الربع الثاني هو 100٪.

استيراد بيانات الميزانية واستخدام بيانات المبيعات من التحليل أعلاه.
budget_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/optimization_budge.csv') print("Shape of the df")
display(budget_df.shape) print("HEAD")
display(budget_df.head()) print("NULL CHECK")
display(budget_df.isnull().any().sum()) print("NULL CHECK")
display(budget_df.isnull().sum()) print("df INFO")
display(budget_df.info()) print("DESCRIBE")
display(budget_df.describe()) ## convert to date time # convert order_status to string
## time_to_pandas_time = ["date"] for cols in time_to_pandas_time: sales_df[cols] = pd.to_datetime(sales_df[cols]) sales_df.dtypes sales_df['Month'] = sales_df['date'].dt.month sales_df.head() sales_df['Month'].drop_duplicates() sales_df_q1 = sales_df[sales_df['Month'] !=4]
## Assumptions
sales_df_q1 = sales_df_q1[sales_df_q1["order_status"] == "Completed"] # Q1_2016_df_pivot = Q1_2016_df.pivot_table(index='service', columns=['order_status','Month' ], values='num_orders', aggfunc= 'sum') sales_df_q1_pivot = sales_df_q1.pivot_table(index='service', columns=['order_status'], values='total_cbv', aggfunc= 'sum')
sales_df_q1_pivot_orders = sales_df_q1.pivot_table(index='service', columns=['order_status'], values='num_orders', aggfunc= 'sum') sales_df_q1_pivot.reset_index(inplace = True)
sales_df_q1_pivot.columns = ["Service","Q1_revenue_completed"]
sales_df_q1_pivot sales_df_q1_pivot_orders.reset_index(inplace = True)
sales_df_q1_pivot_orders.columns = ["Service","Q1_order_completed"] optimization_Df = pd.merge( sales_df_q1_pivot, budget_df, how="left", on="Service", ) optimization_Df = pd.merge( optimization_Df, sales_df_q1_pivot_orders, how="left", on="Service", ) optimization_Df.columns = ["Service", "Q1_revenue_completed", "Cost_per_100_inc_booking", "max_q2_growth_rate","Q1_order_completed"]
optimization_Df.head(5)
#import csv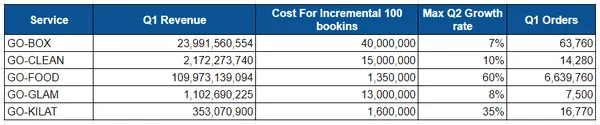
- بالنسبة إلى Box ، تبلغ إيرادات الربع الأول 1B ، وتبلغ تكلفة 23 رحلة إضافية 100 مليونًا ، ويبلغ الحد الأقصى لمعدل النمو المتوقع 40٪ ، وتم إكمال 7 ألف رحلة إجمالية عند 63 ألفًا لكل طلب.
هل من الممكن تحقيق أقصى معدل نمو لجميع الخدمات بميزانية متاحة تبلغ 40 مليار؟
## If all service max growth is to be achived what is the budget needed? and whats the deficiet?
optimization_Df["max_q2_growth_rate_upd"] = optimization_Df['max_q2_growth_rate'].str.extract('(d+)').astype(int) ## extract int from string
optimization_Df["max_growth_q2_cbv"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.max_q2_growth_rate_upd/100)) ## Q2 max orders based on Q1 orders
optimization_Df["abs_inc_orders"] = optimization_Df.max_growth_q2_cbv-optimization_Df.Q1_order_completed ## Total increase in orders optimization_Df["cost_of_max_inc_q2_order"] = optimization_Df.abs_inc_orders * optimization_Df.Cost_per_100_inc_booking /100 ## Total Cost to get maximum growth for each serivce display(optimization_Df) display(budget_df[budget_df["Service"] == "Budget:"].reset_index())
budget_max = budget_df[budget_df["Service"] == "Budget:"].reset_index()
budget_max = budget_max.iloc[:,2:3].values[0][0]
print("Budget difference by")
display(budget_max-optimization_Df.cost_of_max_inc_q2_order.sum() ) ## Therefore max of the everything cannot be achieved#import csvالإجابة هي رقم 247 ب (247,244,617,204،XNUMX،XNUMX،XNUMX) مطلوب المزيد من الميزانية لتحقيق أهداف النمو لجميع الخدمات.
هل من الممكن تحقيق 10٪ على الأقل من الحد الأقصى لمعدل النمو لجميع الخدمات بميزانية متاحة تبلغ 40 مليار؟
## Then what is the budget needed and what will the extra budget at hand??
optimization_Df["min_10_max_growth_q2_cbv"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.max_q2_growth_rate_upd/1000)) ## atleast 10% of max if achieved, this is orders optimization_Df["min_10_abs_inc_orders"] = optimization_Df.min_10_max_growth_q2_cbv-optimization_Df.Q1_order_completed ## what is the increase in orders needed to achieve 10% orders growth
optimization_Df["min_10_cost_of_max_inc_q2_order"] = optimization_Df.min_10_abs_inc_orders * optimization_Df.Cost_per_100_inc_booking /100 ## Cost associatedfor 10% increase in orders display(budget_max-optimization_Df.min_10_cost_of_max_inc_q2_order.sum() ) ## Total budget remaining display((budget_max-optimization_Df.min_10_cost_of_max_inc_q2_order.sum())/budget_max) ## Budget utilization percentage optimization_Df["perc_min_10_max_growth_q2_cbv"] =( ( optimization_Df.max_q2_growth_rate_upd/1000)) ## atleast 10% of max if achieved, 7 to percent divide by 100, 10% of this number. divide by 10, so 1000
optimization_Df["perc_max_growth_q2_cbv"] =( ( optimization_Df.max_q2_growth_rate_upd/100)) ## Max growth to be achieved optimization_Df["q1_aov"] = optimization_Df.Q1_revenue_completed/optimization_Df.Q1_order_completed ## Q1 average order value
optimization_Df["order_profitability"] = 0.1 ## this is assumption that 10% will be profit optimization_Df["a_orders_Q2"] = (optimization_Df.Q1_order_completed *(1+ optimization_Df.perc_min_10_max_growth_q2_cbv)) ## based on 10% growth, total new orders for qc optimization_Df["a_abs_inc_orders"] = optimization_Df.a_orders_Q2-optimization_Df.Q1_order_completed optimization_Df["a_Q2_costs"] = optimization_Df.Cost_per_100_inc_booking* optimization_Df.a_abs_inc_orders/100 ##There is scope for improvement here, so This can be adjusted based on revenue or ranking from Q1
display(budget_max - optimization_Df.a_Q2_costs.sum()) optimization_Df#import csvالجواب نعم. مع 28٪ فقط من ميزانية 40 مليار المتاحة ، يمكن تحقيق ذلك. إن عدم استخدام الميزانية المتاحة ليس خيارًا مطلقًا ، ولن يستخدم أي قائد أعمال 28٪ فقط من الميزانية المتاحة.
لذلك ، لا يمكن تحقيق الحد الأقصى للنمو في جميع الخدمات ، وسيؤدي تحقيق 10٪ من معدل النمو الأقصى إلى نقص استخدام الميزانية. ومن هنا تأتي الحاجة هنا إلى تحسين الإنفاق مثل:
- لا يتجاوز حرق النقود الإجمالي 40B.
- معدل النمو الإجمالي في الربع الثاني عبر الخدمات يساوي أو أقل من معدل النمو الأقصى.
- هناك قيود تسمى في التحسين الخطي.
- الهدف هو تعظيم الأرباح.
الافتراضات المستخدمة هنا:
- كل خدمة لها ربح 10٪.
- ستبقى AOV (الإيرادات / الطلبات) كما هي في Q1.
خط أنابيب بيانات التحسين المسبق:
## Data prep for pulp optimization
perc_all_df = pd.DataFrame(data = list(range(1,optimization_Df.max_q2_growth_rate_upd.max()+1)), columns = ["growth_perc"]) ## create a list of all percentage growth, from 1 to max to growth expected, this is to create simulation for optimization
display(perc_all_df.head(1)) optimization_Df_2 = optimization_Df.merge(perc_all_df, how = "cross") ## cross join with opti DF ## Filter and keeping all percentgaes upto maximum for each service
## Minimum percentage kept is 1
optimization_Df_2["filter_flag"] = np.where(optimization_Df_2.max_q2_growth_rate_upd >= (optimization_Df_2.growth_perc),1,0)
optimization_Df_2["abs_profit"] = (optimization_Df_2.q1_aov)*(optimization_Df_2.order_profitability)
optimization_Df_3 = optimization_Df_2[optimization_Df_2["filter_flag"] == 1] display(optimization_Df_3.head(1))
display(optimization_Df_3.columns) ## Filter columns needed
optimization_Df_4 = optimization_Df_3[[ 'Service', ## services offered 'Cost_per_100_inc_booking', ## cost of additional 100 orders 'Q1_order_completed', ## to calculate q2 growth based on q1 orders 'perc_min_10_max_growth_q2_cbv', ## minimum growth percent need 'perc_max_growth_q2_cbv', ## max growth percent allowed 'abs_profit', ## profit per order 'growth_perc' ## to simulative growth percet across ]] display(optimization_Df_4.head(2)) optimization_Df_4["orders_Q2"] = (optimization_Df_4.Q1_order_completed *(1+ optimization_Df_4.growth_perc/100)) ## based on growth, total new orders for qc
optimization_Df_4["abs_inc_orders"] = optimization_Df_4.orders_Q2-optimization_Df_4.Q1_order_completed
optimization_Df_4["profit_Q2_cbv"] = optimization_Df_4.orders_Q2 * optimization_Df_4.abs_profit
optimization_Df_4["growth_perc"] = optimization_Df_4.growth_perc/100
optimization_Df_4["Q2_costs"] = optimization_Df_4.Cost_per_100_inc_booking* optimization_Df_4.abs_inc_orders/100 display(optimization_Df_4.head()) optimization_Df_5 = optimization_Df_4[[ 'Service', ## services offered 'Q2_costs', ## cost total for the growth expected 'perc_min_10_max_growth_q2_cbv', ## minimum growth percent need 'perc_max_growth_q2_cbv', ## max growth percent allowed 'profit_Q2_cbv', ## total profit at the assumed order_profitability rate 'growth_perc' ## to simulative growth percet across ]] optimization_Df_5 display(optimization_Df_5.head(10))
display(optimization_Df_5.shape)
فهم مجموعة بيانات التحسين
- الخدمة - منتج Go.
- 10٪ من الحد الأقصى للنمو ، هو الحد الأدنى للنمو الذي يجب أن تحققه كل خدمة. لذلك يجب أن يحقق Box نموًا بنسبة 0.7٪ على الأقل.
- هذا قيد.
- الحد الأقصى للنمو الذي قرره قادة الأعمال لـ Box هو 7٪.
- هذا قيد.
- بالنسبة إلى Box ، يكون نطاق النمو من 1٪ إلى 7٪ ، يمثل 1٪ أكثر من 0.7٪ و 7٪ هو الحد الأقصى. سيختار المحسن أفضل معدل نمو بناءً على القيود.
- هذا متغير قرار. ستختار الخوارزمية واحدة من 7.
- بالنسبة للنمو بنسبة 1٪ (التدريجي) ، فإن الحرق النقدي هو 255 مليونًا.
- هذا قيد.
- إذا كان النمو التدريجي 1٪ ، فإن الربح الإجمالي (عضوي + غير عضوي) يكون 2.4 مليار.
- هذا هو الهدف.
## Best optimization for our case case. This is good. prob = LpProblem("growth_maximize", LpMaximize) ## Initialize optimization problem - Maximization problem optimization_Df_5.reset_index(inplace = True, drop = True) markdowns = list(optimization_Df_5['growth_perc'].unique()) ## List of all growth percentages
cost_v = list(optimization_Df_5['Q2_costs']) ## List of all incremental cost to achieve the growth % needed perc_min_10_max_growth_q2_cbv = list(optimization_Df_5['perc_min_10_max_growth_q2_cbv'])
growth_perc = list(optimization_Df_5['growth_perc']) ## lp variables
low = LpVariable.dicts("l_", perc_min_10_max_growth_q2_cbv, lowBound = 0, cat = "Continuous")
growth = LpVariable.dicts("g_", growth_perc, lowBound = 0, cat = "Continuous")
delta = LpVariable.dicts ("d", markdowns, 0, 1, LpBinary)
x = LpVariable.dicts ("x", range(0, len(optimization_Df_5)), 0, 1, LpBinary) ## objective function - Maximise profit, column name - profit_Q2_cbv
## Assign value for each of the rows -
## For all rows in the table each row will be assidned x_0, x_1, x_2 etc etc
## This is later used to filter the optimal growth percent prob += lpSum(x[i] * optimization_Df_5.loc[i, 'profit_Q2_cbv'] for i in range(0, len(optimization_Df_5))) ## one unique growth percentahe for each service
## Constraint one for i in optimization_Df_5['Service'].unique(): prob += lpSum([x[idx] for idx in optimization_Df_5[(optimization_Df_5['Service'] == i) ].index]) == 1 ## Do not cross total budget
## Constraint two
prob += (lpSum(x[i] * optimization_Df_5.loc[i, 'Q2_costs'] for i in range(0, len(optimization_Df_5))) - budget_max) <= 0 ## constraint to say minimum should be achived
for i in range(0, len(optimization_Df_5)): prob += lpSum(x[i] * optimization_Df_5.loc[i, 'growth_perc'] ) >= lpSum(x[i] * optimization_Df_5.loc[i, 'perc_min_10_max_growth_q2_cbv'] ) prob.writeLP('markdown_problem') ## Write Problem name
prob.solve() ## Solve Problem
display(LpStatus[prob.status]) ## Problem status - Optimal, if problem solved successfully
display(value(prob.objective)) ## Objective, in this case what is the maximized profit with availble budget - 98731060158.842 @ 10% profit per order #import csv
print(prob)
print(growth)إن فهم كيفية كتابة مشكلة LP هو مفتاح حلها
- بدء المشكلة
- prob = LpProblem (“growth_maximize” ، LpMaximize)
- Grow_maximize هو اسم المشكلة.
- LpMaximize هو السماح للحل بمعرفة أنها مشكلة تعظيم.
- قم بإنشاء متغير لوظيفة القرار
- النمو = LpVariable.dicts ("g_"، growth_perc، lowBound = 0، cat = "مستمر")
- بالنسبة لللب ، يجب إنشاء إملاءات اللب
- g_ هي بادئة المتغير.
- Grow_perc هو اسم القائمة
- الحد الأدنى هو النسبة المئوية الدنيا للنمو ، ويمكن أن يبدأ من 0.
- المتغير مستمر.
- توجد 60 نسبة نمو فريدة تتراوح من 1٪ (حد أدنى) إلى 60٪ (حد أقصى). (الغذاء له معدل نمو 60٪ كحد أقصى).
- المتغيرات - 0 <= x_0 <= 1 عدد صحيح للصف 0 إلى 0 <= x_279 <= 1 عدد صحيح للصف 279.
- أضف وظيفة موضوعية إلى المشكلة
- prob + = lpSum (x [i] * optimization_Df_5.loc [i، 'kingdom_Q2_cbv'] لـ i في النطاق (0، len (optimization_Df_5)))
- يتم إنشاء معادلة بواسطة اللب -> 2423147615.954 * x_0 + 2447139176.5080004 * x_1 + 225916468.96 * x_3 +…. + 8576395.965000002 * x_279. يوجد 280 صفًا في مجموعة البيانات ، لذلك يتم إنشاء متغير لكل قيمة ربح.
- إضافة قيد:
- واحد - نسبة نمو واحدة لكل خدمة
- لـ i in optimization_Df_5 ['Service']. unique (): prob + = lpSum ([x [idx] for idx in optimization_Df_5 [(optimization_Df_5 ['Service'] == i)] .index]) == 1
- لكل خدمة ، حدد نسبة نمو واحدة فقط.
- للمربع من 1 إلى 7 ، حدد واحدًا فقط.
- معادلة المربع - _C1: x_0 + x_1 + x_2 + x_3 + x_4 + x_5 + x_6 = 1
- معادلة GLAM - _C2: x_10 + x_11 + x_12 + x_13 + x_14 + x_15 + x_16 + x_7 + x_8 + x_9 = 1
- نظرًا لوجود 11 خدمة ، تم إنشاء 11 قيدًا ، واحد لكل خدمة.
- ثانيًا - لا تتجاوز الميزانية الإجمالية 40 مليارًا
- prob += (lpSum(x[i] * optimization_Df_5.loc[i, ‘Q2_costs’] for i inrange(0, len(optimization_Df_5))) – budget_max) <= 0
- يجب أن يكون مجموع جميع التكاليف مطروحًا منه الميزانية الإجمالية أقل من أو يساوي الصفر.
- المعادلة _C12: 255040000 x_0 + 510080000 x_1 +…. + 16604 x_279 <= 0
- _C12: هو القيد الوحيد هنا نظرًا لوجود ميزانية إجمالية واحدة قدرها 40 مليارًا ، ولا توجد قيود على المبلغ الذي يمكن أن تنفقه كل خدمة.
- ثالثًا - الإلزام بالقول إنه يجب تحقيق الحد الأدنى
- بالنسبة لـ i في النطاق (0، len (optimization_Df_5)): prob + = lpSum (x [i] * optimization_Df_5.loc [i، 'growth_perc'])> = lpSum (x [i] * optimization_Df_5.loc [i، ' perc_min_10_max_growth_q2_cbv '])
- لكل صف ، يتم إنشاء معادلة الحد الأدنى لنسبة النمو. يوجد 279 صفًا ، لذلك تم إنشاء 279 قيدًا.
- _C13: 0.003 x_0> = 0 من الصف 0 إلى _C292: 0.315 x_279> = 0 إلى الصف 279.
- "الأمثل"" هو الناتج المطلوب.
- عرض (LpStatus [prob.status])
- 98731060158.842 هو الربح الأقصى.
- عرض (قيمة (موضوع موضوعي))
- واحد - نسبة نمو واحدة لكل خدمة
var_name = []
var_values = []
for variable in prob.variables(): if 'x' in variable.name: var_name.append(variable.name) var_values.append(variable.varValue) results = pd.DataFrame() results['variable_name'] = var_name
results['variable_values'] = var_values
results['variable_name_1'] = results['variable_name'].apply(lambda x: x.split('_')[0])
results['variable_name_2'] = results['variable_name'].apply(lambda x: x.split('_')[1])
results['variable_name_2'] = results['variable_name_2'].astype(int)
results.sort_values(by='variable_name_2', inplace=True)
results.drop(columns=['variable_name_1', 'variable_name_2'], inplace=True)
results.reset_index(inplace=True)
results.drop(columns='index', axis=1, inplace=True) # results.head() optimization_Df_5['variable_name'] = results['variable_name'].copy()
optimization_Df_5['variable_values'] = results['variable_values'].copy()
optimization_Df_5['variable_values'] = optimization_Df_5['variable_values'].astype(int)# optimization_Df_6.head() #import csv## with no budget contraint
optimization_Df_10 = optimization_Df_5[optimization_Df_5['variable_values'] == 1].reset_index() optimization_Df_10["flag"] = np.where(optimization_Df_10.growth_perc >= optimization_Df_10.perc_min_10_max_growth_q2_cbv,1,0) display(optimization_Df_10) display(budget_max - optimization_Df_10.Q2_costs.sum())
display( optimization_Df_10.Q2_costs.sum())
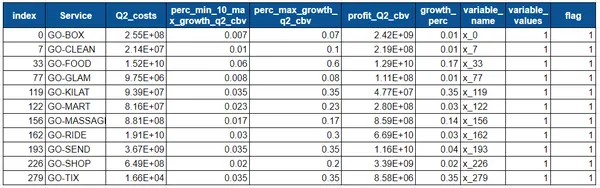
- الحد الأقصى لمعدل النمو للخدمات المعنية في الرسم البياني أعلاه. بالنسبة إلى Box هو 1٪ ، وللنظافة 1٪ ، وللأغذية 17٪ ، إلخ.
- إجمالي الحرق النقدي - 39999532404.0
- الميزانية غير المستغلة بالكامل - 467596.0
- الربح الأقصى - 98731060158.0
حل الجزء الثاني
sales_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/09_gojek/model_analytics__data.csv') time_to_pandas_time = ["date"] for cols in time_to_pandas_time: sales_df[cols] = pd.to_datetime(sales_df[cols]) sales_df['Month'] = sales_df['date'].dt.month Q1_2016_df = sales_df[sales_df['Month'] !=900] Q1_2016_df['Month'] = np.where(Q1_2016_df['Month'] == 1,"Jan",np.where(Q1_2016_df['Month'] == 2,"Feb",np.where(Q1_2016_df['Month'] == 3,"Mar","Apr"))) Q1_2016_df['test_control'] = np.where(Q1_2016_df['date'] <= "2016-03-30","train", "test") display(Q1_2016_df.head(5)) display(Q1_2016_df.order_status.unique()) display(Q1_2016_df.service.unique()) display(Q1_2016_df.date.max())
#import csv- استيراد مجموعة البيانات
- تحويل التاريخ إلى تاريخ الباندا
- اشتقاق أعمدة الشهر
- اشتق أعمدة القطار والاختبار
display(Q1_2016_df.head())
display(Q1_2016_df.date.max()) Q1_2016_df_2 = Q1_2016_df[Q1_2016_df["date"] <= "2016-04-01"]
display(Q1_2016_df_2.date.max()) Q1_2016_df_2 = Q1_2016_df_2[Q1_2016_df["order_status"] == "Cancelled"] Q1_2016_df_date_unique = Q1_2016_df_2[["date"]].drop_duplicates()
Q1_2016_df_date_service = Q1_2016_df_2[["service"]].drop_duplicates() Q1_2016_df_CJ = Q1_2016_df_date_unique.merge(Q1_2016_df_date_service, how = "cross") ## cross join with opti DF display(Q1_2016_df_date_unique.head())
display(Q1_2016_df_date_unique.shape)
display(Q1_2016_df_date_unique.max())
display(Q1_2016_df_date_unique.min()) display(Q1_2016_df_2.shape)
Q1_2016_df_3 = Q1_2016_df_CJ.merge(Q1_2016_df_2, on=['date','service'], how='left', suffixes=('_x', '_y')) display(Q1_2016_df_3.head())
display(Q1_2016_df_3.shape)
display(Q1_2016_df_CJ.shape) Q1_2016_df_3["total_cbv"].fillna(0, inplace = True)
print("Null check ",Q1_2016_df_3.isnull().values.any()) nan_rows = Q1_2016_df_3[Q1_2016_df_3['total_cbv'].isnull()]
nan_rows display(Q1_2016_df_3[Q1_2016_df_3.isnull().any(axis=1)]) Q1_2016_df_3["dayofweek"] = Q1_2016_df_3["date"].dt.dayofweek
Q1_2016_df_3["dayofmonth"] = Q1_2016_df_3["date"].dt.day Q1_2016_df_3["Is_Weekend"] = Q1_2016_df_3["date"].dt.day_name().isin(['Saturday', 'Sunday']) Q1_2016_df_3.head()- تصفية الطلبات الملغاة فقط.
- بالنسبة لجميع الخدمات ، انضم إلى التواريخ من 01 كانون الثاني (يناير) إلى 01 نيسان (أبريل) ، بحيث تتوفر التنبؤات لجميع الأيام.
- استبدل NULL بـ 0.
- اشتق يوم من الشهر
- اشتق يوم من الأسبوع.
- إنشاء عمود ثنائي نهاية الأسبوع / أيام الأسبوع

Q1_2016_df_4 = Q1_2016_df_3[Q1_2016_df_3["service"] != "GO-TIX"] Q1_2016_df_5 = pd.get_dummies(Q1_2016_df_4, columns=["Month","dayofweek"]) display(Q1_2016_df_5.head()) import numpy as np
import pandas as pd
# from sklearn.datasets import load_boston
from sklearn.preprocessing import Normalizer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from numpy import mean
from numpy import std
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_val_predict Q1_2016_df_5.columns all_columns = ['date', 'service', 'num_orders', 'order_status', 'total_cbv', 'test_control', 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb', 'Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2', 'dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6'] model_variables = [ 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb', 'Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2', 'dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6'] target_Variable = ["total_cbv"] all_columns = ['service', 'test_control', 'dayofmonth', 'Is_Weekend', 'Month_Apr', 'Month_Feb', 'Month_Jan', 'Month_Mar', 'dayofweek_0', 'dayofweek_1', 'dayofweek_2', 'dayofweek_3', 'dayofweek_4', 'dayofweek_5', 'dayofweek_6']- تصفية GO-TIX
- ترميز واحد ساخن - الشهر واليوم من الأسبوع
- استيراد جميع المكتبات اللازمة
- قم بإنشاء قائمة بالأعمدة ، والتدريب ، والتنبؤ ، وما إلى ذلك.
model_1 = Q1_2016_df_5[Q1_2016_df_5["service"] =="GO-FOOD"] test = model_1[model_1["test_control"]!="train"]
train = model_1[model_1["test_control"]=="train"] X = train[model_variables]
y = train[target_Variable] train_predict = model_1[model_1["test_control"]=="train"]
x_ = X[model_variables] sc = StandardScaler()
X_train = sc.fit_transform(X)
X_test = sc.transform(x_)
- تصفية البيانات لخدمة واحدة - GO-FOOD
- إنشاء تدريب واختبار إطارات البيانات
- إنشاء X - باستخدام أعمدة القطار ، و y مع عمود التوقع.
- استخدم Standardscalar للتحويل z-Score.
#define custom function which returns single output as metric score
def NMAPE(y_true, y_pred): return 1 - np.mean(np.abs((y_true - y_pred) / y_true)) * 100 #make scorer from custome function
nmape_scorer = make_scorer(NMAPE) # prepare the cross-validation procedure
cv = KFold(n_splits=3, random_state=1, shuffle=True)
# create model
model = LinearRegression()
# evaluate model
scores = cross_val_score(model, X, y, scoring=nmape_scorer, cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) y_pred = cross_val_predict(model, X, y, cv=cv)
- لا يحتوي cross_val_score على MAPE باعتباره أداة تسجيل مضمنة ، لذا حدد MAPE.
- إنشاء مثيل السيرة الذاتية
- إنشاء مثيل LR
- استخدم cross_val_score للحصول على متوسط درجات MAPE عبر طيات السيرة الذاتية لـ GO-Foods.
- لكل خدمة ، يمكن إزالة هذا الرمز ، وإنشاء وظيفة لإنشاء
def go_model(Q1_2016_df_5, go_service,model_variables,target_Variable): """ Q1_2016_df_5 go_service model_variables target_Variable """ model_1 = Q1_2016_df_5[Q1_2016_df_5["service"] ==go_service] test = model_1[model_1["test_control"]!="train"] train = model_1[model_1["test_control"]=="train"] X = train[model_variables] y = train[target_Variable] train_predict = model_1[model_1["test_control"]=="train"] x_ = X[model_variables] X_train = sc.fit_transform(X) X_test = sc.transform(x_) # prepare the cross-validation procedure cv = KFold(n_splits=3, random_state=1, shuffle=True) # create model model = LinearRegression() # evaluate model scores = cross_val_score(model, X, y, scoring=nmape_scorer, cv=cv, n_jobs=-1) # report performance print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) y_pred = cross_val_predict(model, X, y, cv=cv) return y_pred,mean(scores), std(scores) a,b,c = go_model(Q1_2016_df_5, "GO-FOOD",model_variables,target_Variable) b- خطوات النمذجة المحولة إلى دالة:
- Q1_2016_df_5 - البيانات الأساسية
- go_service - go-tix ، go-send ، إلخ
- model_variables - المتغيرات المستخدمة لتدريب النموذج
- target_Variable - متغير التنبؤ (total_cbv).
- لكل خدمة ، يمكن تشغيل الطريقة للحصول على متوسط توقعات MAPE عبر جميع الخدمات الإحدى عشرة.
حل الجزء الثالث
السؤال 3 هو سؤال مفتوح ويتم تشجيع القراء على حله بأنفسهم. بعض الفرضيات هي:
- نظرًا لأن هذا خاص بمنطقة جسيم وجغرافيا واحدة ، فمن الآمن افتراض أن التطبيق ظل إلى حد ما كما هو ، وكان من الممكن أن تلعب تدخلات المنتج دورًا ثانويًا فقط. وإذا كان هناك تدخل في المنتج ، فهو يقتصر فقط على هذا المجال بالذات.
- تم تجهيز المطاعم عالية الجودة / الشهيرة وسلاسل الطعام ، وأصبح لدى المستخدمين الآن الكثير من الخيارات الجيدة للطلب أو الطلب من المطاعم المألوفة.
- تم تحسين سرعة التسليم بشكل كبير من خلال إعداد عدد أكبر من وكلاء التوصيل.
- إعادة تدريب وكلاء التوصيل بشكل فعال للحد من عمليات الإلغاء.
- عملت مع شركاء المطعم للتعامل مع فوضى أوقات الذروة بطريقة أفضل.
مصادر ومراجع مفيدة
- العمل في 'Central Analytics and Science Team'
- كيفية نحن نقدر وقت إنزال الطعام باستخدام "Tensoba"
- باقة الأعمال تعيينات دراسة الحالة لمحللي بيانات مستوى الدخول
- حل تعيينات دراسة الحالة التجارية لعلماء البيانات
- باستخدام بيانات لتقدير عملائنا
- تحت غطاء محرك أداة التنبؤ الآلي Gojek
- تجريب في Gojek
- GO-JEK's التأثير على إندونيسيا
- اذهب بسرعة: المعطيات وراء رمضان
- لب الاقوي.
- خطي البرمجة باستخدام اللب.
- التسويق تحسين الحملة.
- الاشارات طرق لتحسين شيء ما باستخدام بيثون.
وفي الختام
دراسات الحالة ، عند القيام بها بشكل صحيح ، باتباع الخطوات المذكورة أعلاه ، سيكون لها تأثير إيجابي على العمل. لا يبحث المسؤولون عن التوظيف عن إجابات ، بل يبحثون عن نهج لتلك الإجابات ، والهيكل المتبع ، والمنطق المستخدم ، والمعرفة العملية والعملية باستخدام تحليلات الأعمال. توفر هذه المقالة إطارًا سهل المتابعة لمحللي البيانات باستخدام دراسة حالة عمل حقيقية كمثال.
الوجبات السريعة الرئيسية:
- هناك طريقتان للإجابة على دراسة الحالة هذه ، من أسفل إلى أعلى ومن أعلى إلى أسفل. هنا ، تم النظر في النهج التصاعدي ، بسبب عدم الإلمام بالبيانات وعدم توفر سياق الأعمال.
- يعد تقسيم أرقام المبيعات إلى شرائح وتقطيعها عبر الأبعاد وتحديد الاتجاهات والأنماط عبر الخدمات أفضل نهج لمعرفة تحديات النمو.
- كن هشًا ومباشرًا ، مع تقديم التوصيات.
- دع البيانات تحكي قصة ، بدلاً من مجرد إثبات نقاط البيانات - على سبيل المثال: تساهم الخدمات الثلاث الأولى في أكثر من 90٪ من الإيرادات. بينما على مستوى المجموعة ، يكون النمو على الجانب الإيجابي ، في مختلف الخدمات ، هناك تحديات تتعلق بإكمال الرحلة ، وإلغاء السائق ، وما إلى ذلك. بالنسبة للطعام - سيؤدي تقليل الإلغاءات بنسبة Y٪ إلى زيادة الإيرادات في الربع الثاني بنسبة x٪ وما إلى ذلك.
- التحسين باستخدام اللب أمر مخيف عندما يكون هناك أكثر من 3 قيود. كتابة مشكلة LP على قطعة من الورق ، ثم ترميزها سيجعل المهمة بالتأكيد أسهل.
حظ سعيد! هذا هو بلدي لينكد إن الملف الشخصي إذا كنت تريد الاتصال بي أو تريد المساعدة في تحسين المقالة. لا تتردد في الاتصال بي توب ميت/مينترو؛ يمكنك مراسلتي مع استفسارك. سأكون سعيدا لكوني على اتصال. تحقق من مقالاتي الأخرى حول علم البيانات والتحليلات هنا.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- شراء وبيع الأسهم في شركات ما قبل الاكتتاب مع PREIPO®. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/05/business-analytics-solving-business-case-studies-assignments/

