

@مارتن أندرسونmartin@martinanderson.ai
كاتب مستقل في مجال الذكاء الاصطناعي والتعلم الآلي والبيانات الضخمة.
نشرت أصلا في روس داوسون.
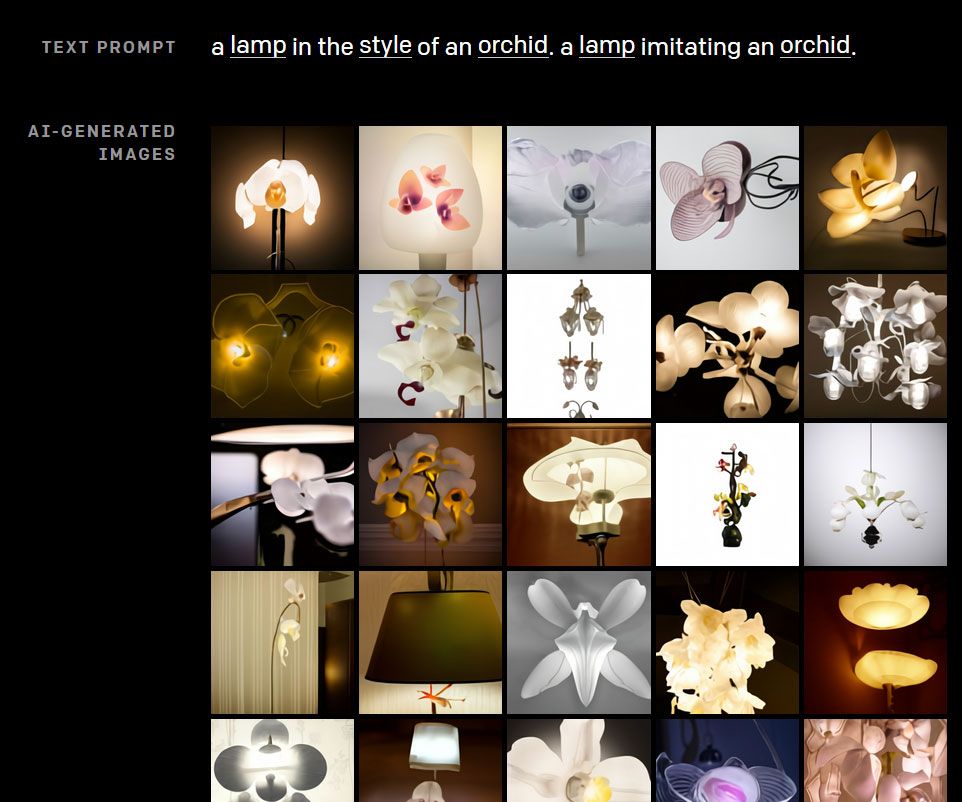
بعد وقت قصير من العام الجديد 2021أطلقت حملة مجتمع توليف الوسائط في رديت أصبح مخدرًا أكثر من المعتاد.
أصبحت اللوحة مشبعة بالصور غير الأرضية انهار الدم, بيكاسو كينغ كونغأو المعلم بيكاتشو يطارد مارك زوكربيرج, السحرة Synthwave, القطط التي يسببها الحمضو بوابة متعددة الأبعادأطلقت حملة ثورة صناعية و طفل محتمل باراك أوباما ودونالد ترامب.
تم إنشاء الصور الغريبة من خلال إدخال عبارات قصيرة في دفاتر Google Colab (صفحات الويب التي يمكن للمستخدم من خلالها الوصول إلى موارد التعلم الآلي الهائلة لعملاق البحث) ، والسماح للخوارزميات المدربة بحساب الصور الممكنة بناءً على هذا النص.
في معظم الحالات ، تم الحصول على أفضل النتائج في دقائق. عادة ما تؤدي المحاولات المختلفة لنفس العبارة إلى نتائج مختلفة تمامًا.
في مجال تخليق الصورة ، تعتبر وسيلة الاختراع ذات النطاق الحر هذا شيئًا جديدًا ؛ ليس فقط جسرًا بين مجالات النص والصورة ، ولكن نظرة مبكرة على أنظمة إنشاء الصور الشاملة المدعومة بالذكاء الاصطناعي والتي لا تحتاج إلى تدريب شديد التحديد في مجالات محدودة للغاية (مثل إطار عمل إنشاء المناظر الطبيعية لـ NVIDIA GauGAN [والذي ، المزيد لاحقًا] ، والتي يمكن أن تحول الرسومات إلى مناظر طبيعية ، ولكن فقط إلى مناظر طبيعية ؛ أو الرسم المتنوع> مشروعات وجه Pix2Pix ، والتي هي أيضًا "متخصصة").

صور نموذجية تم إنشاؤها باستخدام دفتر Big Sleep Colab [12]. فوق،
نص الإدخال أدناه النتيجة. (https://old.reddit.com/r/MediaSynthesis/)
الجودة بدائية في أحسن الأحوال ، مثل ذكرى نصف متكونة من الأحلام ، والتكنولوجيا وليدة بشكل واضح ؛ لكن الآثار طويلة المدى على المؤثرات البصرية مهمة.
إذن من أين أتت هذه التقنيات؟
موجة جديدة من الشبكات العصبية متعددة الوسائط
في أوائل عام 2021 مختبر أبحاث الذكاء الاصطناعي OpenAI ، حديثًا عن العام السابق ضجة كبيرة فيما يتعلق بقوة GPT-3 نموذج اللغة الانحدار التلقائي ، أصدرت تفاصيل عن شبكتين عصبيتين جديدتين متعدد الوسائط قادران على التداخل بين مجالين حوسبيين متنوعين: النص والصور.
أوبن إيه آي: CLIP
CLIP (التدريب المسبق على الصورة التقابلية) هو أ صفر طلقة الشبكة العصبية التي تقيم أهمية مقتطف نصي لأي صورة معينة بدون نفس التحسين الذي كان يتعين على الشبكات السابقة القيام به من أجل تحقيق ذلك.
لا يتم تدريب CLIP على مجموعة بيانات ثابتة ومعنونة مسبقًا ، ولكن على الصور التي تم الحصول عليها عبر الإنترنت (محتوى الصورة) ، والتي تحاول إقرانها بأكثر ما يناسب 32,768 من المقتطفات النصية العشوائية.
مع هذا النهج ، يبتعد CLIP عن الأنظمة السابقة التي - تدعي الشركة - عادةً ما تكون مفرطة التحسين للاختبارات المعيارية ، ولديها قابلية تطبيق عامة أقل على مجموعات بيانات الصور "غير المرئية"

تقوم بنية CLIP بتدريب برنامج تشفير النص ومشفّر الصور للعثور على أزواج الصورة / التسمية التوضيحية المتطابقة في مجموعة بيانات المصدر الخاصة بها. مع انخفاض قيم الخسارة (أي أنه يتحسن في القيام بذلك) ، يكتسب النموذج القدرة على إجراء تصنيف "اللقطة الصفرية" لصورة لم يسبق له مثيل من قبل. (https://openai.com/blog/clip/)
في الاختبارات ، تمكنت CLIP من مطابقة أداء معيار ImageNet ريسنت 50 التحدي دون الاستفادة من الإشارة إلى أي من مجموعة البيانات البالغ عددها 1.28 مليون صورة مصنفة - وهو تقدم غير مسبوق. بعد ذلك ، أتاحت OpenAI إمكانية الوصول إلى CLIP عبر ملف CoLab.
أوبن أيه: DALL-E
لوح يستخدم 12 مليار من 175 مليار معلمة لمجموعة بيانات GPT-3 لإنشاء أزواج بين الصور والنص قادرة على إنتاج نسبيًا
الصور الواقعية - اعتمادًا على توفر مصدر الصورة
المواد التي سيتم استدعاؤها من مجموعة البيانات بواسطة موجه النص:
النظام عرضة للخلل الدلالي العرضي:

يظهر غموض مصطلح "زجاج" في إخراج DALL-E. (https://openai.com/blog/dall-e/)
كما لاحظ المبدعون ، فإن DALL-E يميل إلى الخلط بين الألوان والكائنات عند زيادة عدد الكائنات المطلوبة في موجه النص. أيضًا ، يمكن أن تؤدي إعادة صياغة الموجه إلى أشكال معقدة نحويًا أو غير مألوفة إلى القضاء على القدرات التفسيرية للنموذج (على سبيل المثال ، عندما يكون موضوع الملكية غير واضح).
إذا كانت بيانات الصورة المشتقة من الويب لمطالبة نصية متكررة ومفصلة ، فمن الممكن إنشاء إحساس حقيقي بالأداة ، بأسلوب واجهة النمذجة ثلاثية الأبعاد ، وإن لم يكن ذلك عن بُعد في الوقت الفعلي:

تتمتع Dall-E بوسائل عالية ، حتى لو ظل الاتساق يمثل مشكلة. هنا يعيد الذكاء الاصطناعي بناء تمثال نصفي لأفلاطون باستخدام صورة جزئية في دورات مختلفة ، وموجه نصي. (https://openai.com/blog/dall-e/)
من المفترض أن يؤدي إدراج الصورة التي تم إنشاؤها مسبقًا في تسلسل من هذا النوع إلى تحسين الاستمرارية عبر الإطارات ؛ ولكن في المثال أعلاه ، على حد علمنا ، فإن DALL-E "يبدأ حديثًا" مع كل صورة ، بناءً على موجه النص ، وعلى ما يمكن أن تراه أعلى رأس أفلاطون.
تستحوذ القدرات التحويلية والتفسيرية لـ DALL-E حاليًا على خيال المتحمسين لتوليف الصور ، لأسباب ليس أقلها أن الأنظمة قد تم تحويلها إلى سلعة بسرعة من قبل الباحثين و
المتحمسون (انظر "المصنفات المشتقة" أدناه):

في حدود الموضوعات الأكثر إنتاجية في مجموعات البيانات المساهمة ، يمكن لـ DALL-E اللحام ببعض العناصر غير المتوافقة معًا.(https://openai.com/blog/dall-e/)
DALL-E يبني على OpenAI's Image GPT مولد كهربائي، نموذج محول إثبات المفهوم قادر على إنهاء الصور غير المكتملة (وإن كان ذلك مع مجموعة واسعة من الاستجابات المحتملة).

تحاول Image GPT "إكمال" ملصقات الأفلام الشهيرة. يحتوي النموذج على تكلفة حسابية عالية ، ويتم تدريبه على دقة منخفضة تبلغ 32 × 32 و 48 × 48 و 64 × 64. لتحسين الأداء بشكل أكبر ، يستخدم النظام لوحة ألوان مختصرة 9 بت. (https://openai.com/blog/image-gpt/)
تكيف مبسط من طرف ثالث لـ DALL-E's مصدر متاح في جيثب، مع المصاحبة CoLab.
أعمال مشتقة
للأسف ، لا يوجد وصول عام إلى هذه القدرات التحويلية غير العادية ؛ أوبن إيه آي سيطلق فقط وحدة فك ترميز dVAE ومشفّر الشبكة العصبية التلافيفية (CNN) من DALL-E ، ولا توجد خطة رسمية لإطلاق نموذج المحول الذي يدعم الصور عالية الجودة التي تظهر في المنشورات "الرسمية" (انظر أعلاه). ومع ذلك ، أ التعليق من مطور OpenAI على GitHub في فبراير ، صرح بأن الشركة "تفكر" في الوصول إلى واجهة برمجة التطبيقات DALL-E ، والتي من شأنها توسيع القوة التفسيرية لأنظمة توليف الصور التابعة لجهات خارجية.
في غضون ذلك ، حاول المطورون إعادة إنشاء الوظيفة
من DALL-E مع واجهات برمجة التطبيقات المتوفرة. على الرغم من أن النتائج ليست محددة أو متماسكة مثل تلك الناتجة عن DALL-E المنعزل ، إلا أنها تشير إلى ما يمكن تحقيقه من خلال الاستفادة من تقنيات تحويل النص إلى صورة التي يتم تشغيلها بواسطة مجموعات بيانات صور واسعة النطاق.
CLIP-GlaSS
تم إنتاج بحث من جامعة بيزا مؤخرًا CLIP-GlaSS، والذي يبني على إطار OpenAI للتضمين بيججان, ستايل و GPT-2 كمحفزات لتوليد الصور النصية.
تعمل CLIP-GlaSS عبر مجموعة من أطر عمل GAN المتميزة ، وأكثرها تعميمًا هو BigGAN الخاص بـ DeepMind. تقدم شبكات GAN المخصصة الأخرى مجالات لتوليد الوجه ، وسيارة ، وكنيسة ، ولإنشاء نص عبر GPT-2 ، بالإضافة إلى متغيرات جودة أعلى (لشبكات GAN القائمة على الصور).


تحاول CLIP-GlaSS إعادة إنشاء "batmobile" باستخدام مجموعة "السيارة" StyleGAN2.

"كاتدرائية في الليل على طراز Blade Runner" - تستخدم CLIP-GlaSS إعداد "الكنيسة" في StyleGAN2 لتقريب مشهد مشابه لفيلم الخيال العلمي لعام 1982. ستظهر مجموعات "الكنيسة" و "السيارة" أحيانًا أشخاصًا ، في حين تركز مجموعة StyleGan2 ffhq (ميزة الوجه) بشكل حاد على الوجوه ، مع الحد الأدنى من التحولات خارج منطقة الصورة.
قد يكون لشعبية CLIP-GlaSS بين عشية وضحاها علاقة بما يمكن الوصول إليه بسهولة دفتر كولاب التي أتاحها الباحثون الإيطاليون.
على عكس Big Sleep (انظر أدناه) ، تتحسن جودة صور CLIP-GlaSS عادةً عندما يُسمح لها بالتدريب لفترة أطول قليلاً. ولكن نظرًا لأن هذه المولدات "بدون طلقة" ، فإنها تميل إلى الوصول إلى سقف الجودة الخاص بها (الحد الأدنى من الخسارة) بسرعة.
نوم كبير وصورة Aleph2
مبرمج وطالب دكتوراه في جامعة يوتا ريان موردوك يحتفظ بعدد من المشاريع المشتقة من CLIP ، بما في ذلك Aleph2Image و BigSleep - وقد أثار هذا الأخير اهتمامًا كبيرًا بمجموعة توليف وسائط Reddit.

الصور المشتقة في BigSleep Colab من النص موجه "فناني المؤثرات البصرية". إلى جانب العاصفة الرملية وأضواء الاستوديو في الصورة الثالثة ، هل كل هذه الصور رعوية ورسمية لأن الموجه يحتوي على كلمة "فنان"؟
"لقد ابتكرت BigSleep و Aleph لأنني أحب صنع الفن العصبي ،" Murdock
اخبرني. وأردت معرفة ما إذا كان من الممكن الحصول على باب خلفي
حول DALL-E لم يتم إطلاق سراحه.

BigSleep يفسر "كاتدرائية بأسلوب Blade Runner". في هذه المرحلة من الاستيعاب ، وفي هذا القرار ، من الصعب تحديد ما إذا كانت BigGAN التي تشغل BigSleep تعتمد بشكل أساسي على رسومات الإنتاج أو الصور الثابتة أو اللقطات الفعلية ، نظرًا لأن النتائج في حد ذاتها متشابهة في الجودة مع فن مفهوم الإنتاج.
BigSleep لديه أكثر سهولة في الاستخدام دفتر كولاب من أي من العروض الحالية:

لتنفيذ صورة في BigSleep ، تحتاج إلى الضغط على زرين في Colab وتقديم رسالة نصية.
في غياب أدوات GAN التي لم تصدرها OpenAI من أجل DALL-E ، ربط موردوك القدرات التنبؤية لـ CLIP بالقدرات التوليدية لـ بيججان.
لدى BigSleep اثنين من الانحرافات المحددة: أولاً ، BigGAN متخصص في 1000 خاص فئات ImageNet (كثير منها أنواع حيوانية). من المحتمل أن يكون الموجه الذي يتضمن أيًا من هذه الفئات أفضل من واحد خارج هذا النطاق.
ثانيًا ، تكون صورة "البذور" الخاصة بـ BigSleep دائمًا صورة عشوائية لسلالة كلاب ، وفي بعض الأحيان تواجه التكرارات صعوبة في التخلي عن عنصر الكلاب هذا. بعد ذلك ، يمكن أن ينتهي الأمر بالناس في صور BigSleep بارتداء عدد غير عصري من معاطف الفرو (انظر صور "همفري بوجارت" لاحقًا في المقالة).
مشروع أحدث من موردوك هو Aleph2Image، والذي يستغل التشفير التلقائي المتغير الكمي المتغير لـ DALL-E (VQ-VAE).

خريطة مفاهيمية لـ VQ-VAE ، مع تصور مساحة التضمين على اليمين. يشترك المشفر ووحدة فك التشفير في نفس مساحة الأبعاد ، مما يساعد على تقليل خسارة إعادة البناء بشكل متكرر. (https://arxiv.org/pdf/1711.00937.pdf)
النتائج التي يطلبها النص هي أكثر انطباعية حتى من BigSleep ، لكنها تميل إلى الاتساق البصري أكثر:

(https://old.reddit.com/r/MediaSynthesis/)
Aleph2Image's CoLab حاليًا أقل سهولة في الاستخدام من BigSleep ، لكن المؤلف يعد بتجربة مستخدم أفضل في الإصدارات المستقبلية.
تحتفظ مجموعة Reddit Media Synthesis بملف قائمة من مستودعات تجميع الصور الأخرى Colabs و GitHub التي تستفيد من CLIP لتوليد الصور ، على الرغم من تعطل بعضها من خلال تحديثات إطار العمل التي لا تدعمها أجهزة الكمبيوتر المحمولة القديمة.
يعتقد موردوك أن استخدام عمليات نشر CLIP + GAN مثل هذا في بيئات الإنتاج ، حتى بالنسبة لاستكشاف التصميم العام ، "نادر جدًا" في الوقت الحالي ، ويقر بوجود بعض العوائق الصعبة التي يجب التغلب عليها في تطوير هذه الأنظمة بشكل أكبر.
قال لي: "أعتقد أن الأجهزة تمثل عنق زجاجة كبير". أشك في أنه من الممكن لأي شخص لديه أي برنامج محاكاة شيء مثل CLIP بدون عدد من وحدات معالجة الرسومات على الأقل ووقت طويل.
لكن البيانات هي أخطر عنق الزجاجة والبطل المجهول لمعظم التطورات. قد تكون البرامج بمثابة عنق زجاجة ، لكنها بالفعل تحمل وطأة اهتمام الناس.
الإبحار في هواجس CLIP الغريبة
حتى عندما لا يكون النص متورطًا بشكل مباشر في تركيب الصور ، كما هو الحال مع CLIP Colabs ، فهو مرتبط بعمق في التجزئة الدلالية التي تحدد الكائنات والكيانات ، والتي تدعم العديد من الأنظمة التوليدية الموصوفة هنا.
الشبكة العصبية لـ CLIP هي بنية مثالية مدربة على بيانات من عالم غير كامل. نظرًا لأن العالم مهتم جدًا بـ Spider-Man ، فإن الخلايا العصبية متعددة الوسائط في CLIP ستنطلق حتى للإشارة الأكثر غموضًا إلى قاذف الويب الودود في منطقتك:
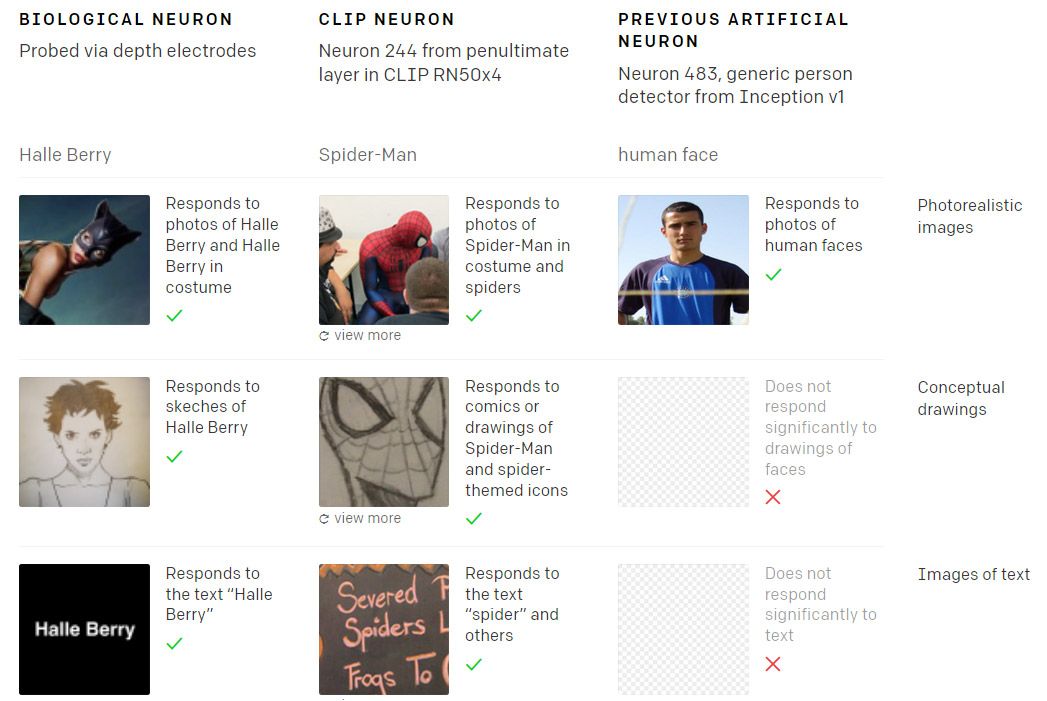
في عام 2005 اكتشف الباحثون خلية عصبية بشرية في موضوعات اختبار استجابت عبر مجموعة غير عادية من المحفزات المحتملة فيما يتعلق بالممثلة هالي بيري [31]. وبالمثل ، يحتوي CLIP ، من بين الأشياء الغريبة الأخرى ، على خلية عصبية متعددة الوسائط "الرجل العنكبوت" يسهل تنشيطها ، حتى من خلال مراجع مائلة للغاية. (https://openai.com/blog/multimodal-neurons/)
لنترك جانباً ما إذا كان CLIP يجب أن يكون أكثر اهتمامًا بـ Spider-Man من
شكسبير أو غاندي ، يجب أن يؤخذ في الاعتبار أن أنظمة تركيب الصور التي تعتمد عليها يجب أن تعاني أيضًا من غرابة أطوار CLIP.
تميل الشبكات العصبية التي تم تدريبها بواسطة الإنترنت إلى إظهار الهواجس والتحيزات وفقًا لحجم واتساع المواد التي قد يجدونها في أي موضوع معين. كلما كان الكيان أكثر انتشارًا في مجموعة البيانات المساهمة في نظام تركيب الصور ، زاد احتمال ظهوره غير محظور ، أو أن يتم تشغيله بواسطة كلمات أو صور غير مرتبطة على ما يبدو:

في عام 2020 وجه الممثل ريان جوسلينج ظهر عشوائيًا في إخراج برنامج ترقية الصور المستند إلى الذكاء الاصطناعي في Gigapixel ، والذي يبدو أن نماذج التعلم الآلي الخاصة به قد تم تدريبها جزئيًا على مجموعة بيانات المشاهير أ.
إذا جربت وقتًا طويلاً بما يكفي مع أدوات تحويل النص إلى صورة المستندة إلى CLIP ، فسوف تقوم بسرعة ببناء صورة لـ "اهتماماتها" وارتباطاتها وهواجسها. إنه ليس نظامًا محايدًا - لديه الكثير من الآراء ، ولم يشكلها بالضرورة من أفضل المصادر ، مثل OpenAI مؤخرًا اعترف في بلوق وظيفة.
لذلك ، فيما يتعلق بتطوير أنظمة تجميع صور المؤثرات البصرية الاحترافية ، ربما ينبغي النظر إلى تطبيقات CLIP على أنها ملعب لإثبات صحة المفهوم لبنى البيانات المستقبلية والأكثر صرامة.
توليف صورة نقية في المؤثرات البصرية الاحترافية؟
ومع ذلك ، لا يبدو أن محترفي المؤثرات البصرية من المحتمل أن يشعروا بالتهديد من خلال التشتت المخدر لمولدات صور GAN القائمة على CLIP مثل BigSleep ، أو حتى يشعرون بالضرورة بالقدرة على إرضاء فضولهم وحماسهم بشأن توليف الصورة الأداة مقيدة للغاية والقدرة على التحكم في المخرجات محدودة للغاية.
ربما قانون العمارة قابل للتطبيق هنا ؛ صرح عالم المستقبل والعالم الأمريكي الراحل "نميل إلى المبالغة في تقدير تأثير التكنولوجيا على المدى القصير والتقليل من التأثير على المدى الطويل."

كيف لعبت CGI من حيث قانون Amara - اليسار ، رسوم متحركة تجريبية للوجه حدودي من جامعة يوتا في 1974 ؛ بعد ثلاثة وأربعين عامًا ، قامت لجنة السياسة النقدية بإعادة الشباب للممثلة شون يونغ ، من أجل بليد رانر 2049 (2017).
استمرارًا للتماثل مع CGI ، يمكننا أن نرى أن تطور تقنيات VFX التخريبية متقطع وغير متسق ؛ وأن التقنيات الجديدة غالبًا ما تضعف بسبب فضول الصناعة والسعي المتخصص إلى أن يؤدي الاختراق غير المتوقع إلى انقراض دور المؤثرات البصرية العزيزة ، ويجعل من الضروري اللحاق بالركب والتكيف ، مثل فعل سيد وقف الحركة فيل تيبيت أثناء صنع الحديقة الجوراسية (1993).
في الجانب الثاني - دعنا نلقي نظرة على الأساليب الجديدة التي يمكن أن تحقق قدرًا أكبر من التحكم والأدوات لتركيب الصور المحض ، وتسهيل تطوير أدوات جديدة ، وربما حتى مهن جديدة داخل القطاع.
القوة والمزالق لمجموعات البيانات المقترنة
"بمجرد أن تصل إلى المرحلة التي لم تعد فيها بالضرورة تصمم أداة ، لكنك تطلب من الذكاء الاصطناعي أن يفعل شيئًا من أجلك ، وهو يفعل ذلك ... يفتح لك الكثير من الاحتمالات."
فالنتين كوزين هو الفنان التقني الرئيسي في استوديو الألعاب البريطاني Rare. قاده شغفه بالإمكانيات التي يمكن أن يفتحها التعلم الآلي لخطوط أنابيب VFX لاستضافة شعبية عرض تقديمي عن التعلم العميق العملي للصناعة في ديسمبر 2020.
قال لي "مع GPT-3". "يمكنك حتى استخدامه لأنظمة الألعاب. بدلاً من تدوين قواعد ما يحدث عندما تصطدم شعلة ملتهبة بجسم من الماء ، لا يتعين عليك كتابة التعليمات البرمجية في حقيقة أن الحريق يتم إطفاءه - يمكنك فقط أن تسأل الذكاء الاصطناعي "ماذا يحدث إذا جمعت بين النار والماء؟ "، وسيخبرك الذكاء الاصطناعي" يتم إطفاء الحريق "، لأنه يحتوي على نوع من هذا النوع من المعرفة بالتفاعل".
تتمثل إحدى اهتمامات Kozin البحثية الرئيسية في الوقت الحالي في إمكانات مجموعات البيانات المقترنة لمساعدة شبكات الخصومة التوليدية على تحويل الرسومات (أو الأشكال الأخرى من الصور الإرشادية الأولية) إلى صور مُحققة بالكامل تم إنشاؤها بواسطة الذكاء الاصطناعي.

مدخلات تدريب مجموعة البيانات المقترنة الخاصة بلعبة الفيديو Sea Pirates. في العمودين الأولين ، "الحقيقة الأساسية" المساهمة - تقدم الرسومات وتنتجها. في العمود الثالث ، الصور المركبة التي تنتجها الشبكة العصبية. (التعلم العميق العملي للمؤثرات البصرية والفنانين التقنيين - https://www.youtube.com/watch?v=miLIwQ7yPkA)
لتحقيق ذلك ، هناك حاجة إلى مجموعتي بيانات للتدريب - واحدة حيث يتم تقديم وجوه الشخصيات بشكل تقليدي ، والأخرى حيث تظهر الوجوه نفسها في شكل رسومات بدائية. يمكن إنشاء هذا الأخير من خلال مشاريع GitHub مفتوحة المصدر مثل PhotoSketch.

يستخدم برنامج PhotoSketch اكتشاف الحدود المدعوم بالذكاء الاصطناعي لاستنتاج ملامح ما يعادل رسم تخطيطي لصورة إدخال. يمكن أن تساعد المخرجات من النماذج المدربة في المشروع والخوارزميات الافتراضية في تدريب أنظمة التعلم الآلي الجديدة للتعرف على المجالات والأشياء والأقسام المقسمة للكائنات وتصنيفها (مثل الوجوه) ، ثم ربط هذه الملصقات بالصور لاحقًا. (https://github.com/mtli/PhotoSketch)
لكن المعيار العام الحالي للرسم> استدلال الصورة هو Pix2Pix، وهو مشروع من مختبر Berkeley AI Research (BAIR) ، والذي يستخدم شبكات الخصومة المشروطة كحجر رشيد لترجمة الصور.

من ورقة بيركلي 2018. يتعلم Pix2Pix التعيين ويستوعبه من المدخلات إلى الصور المخرجة ، ولكنه يوفر أيضًا وظيفة الخسارة لتدريب التعيين. والنتيجة هي قدرة تحويلية عامة بين صفات وفئات مختلفة جدًا من أنواع الصور ، على الرغم من أنها عادة ما تكون ضمن مجال مستهدف ("منازل" ، "قطط" ، "أشخاص" ، إلخ.). (https://www.tensorflow.org/tutorials/generative/pix2pix)
المساهمة بمجموعات البيانات التي تعرف القليل جدًا أو كثيرًا جدًا
على الرغم من أن إمكانية التوفير وتوليد الأصول باستخدام هذه التقنيات واضحة ، إلا أن المسار إلى الأداة الحقيقية والتحكم الدقيق للحصول على دقة عالية وإخراج واقعي مقيد باعتبارات تصميم البيانات وهندستها كما هو الحال مع قيود الأجهزة الحالية للشبكات العصبية .
على سبيل المثال ، اختيار همفري بوجارت شفرة عداء هي تجربة انطباعية متوقعة في النطاق الجديد من ملاعب كولاب لتحويل النص إلى صورة مثل BigSleep و Aleph2Image.

مطالبات BigSleep مختلفة بخصوص "همفري بوجارت في Blade Runner". لاحظ أنه يرتدي معطفًا من الفرو في الصورة الثانية ، وأن الفراء يتكرر في الصور الأخرى - بقايا من حقيقة أن كل عرض BigSleep يبدأ بصورة مشتقة من مجموعة بيانات من سلالات الكلاب!
من الواضح أن 1.3 مليون صورة في مجموعة بيانات ImageNet التي تدعم BigGAN تحتوي على مادة كافية لفهم ملامح وجه بوجارت الأساسية والأيقونات ، ورسومات إنتاجية كافية ، ومقاطع فيديو وصور ثابتة من فيلم 1982 لـ Colabs لتجميع أسلوب شفرة عداء جيد جدا. لماذا إذن يصعب الحصول على صور متماسكة؟
المشكلة جزئياً هي مشكلة دلالية ، كما يقول العديد من المتحمسين لتركيب الصور عن T2I Colabs الجديدة الشهيرة: إذا قمت بتحفيز الذكاء الاصطناعي بـ "رجل يرتدي بدلة داكنة" ، فقد ينتهي بك الأمر ، على الرغم من القصد "الواضح" من العبارة أ) مشهد قاعة المحكمة ب) شقة ساكن واحد مصنوعة من الجبردين أو ج) دارث فيدر.
بصرف النظر عن المشكلات المذكورة أعلاه المتعلقة بتكرار المفاهيم عالية المستوى "الشائعة" في قاعدة البيانات / قواعد البيانات المساهمة ، فهذه مشكلة مرتبطة باستدلال النية في معالجة اللغة الطبيعية (NLP) ؛ وحتى ، يمكن القول ، في مجال تحليل المشاعر. من المرجح أن تأتي التحسينات في هذا الصدد من أبحاث البرمجة اللغوية العصبية التي لها أهداف أعلى (أو على الأقل أهداف تجارية فورية).
ولكن فيما يتعلق بتطوير تدفقات عمل التعلم الآلي المتمحورة حول المؤثرات البصرية ، فإن
القضية الأكثر إلحاحًا هي أحد نطاق واتساع مجموعات بيانات الصور المساهمة.
إذا كان المولد الخاص بك يستخدم مستودعات بيانات واسعة ومعممة مثل ImageNet أو ملف الزحف المشترك، سوف تستدعي قسمًا فرعيًا صغيرًا فقط من الصور المتاحة ذات الصلة بقصدك - ولا تحتوي مجموعات البيانات التمثيلية هذه على مساحة كافية أو تفويض للقيام بفهرسة شاملة لكل من همفري بوغارت أو شفرة عداء صورة على الإنترنت.
فلماذا لا ترعى بوغارت و شفرة عداء مجموعة البيانات ، وتدريب النموذج حصريًا على هذه؟
مخرجات تركيب الصورة الهشة من مجموعات البيانات المجهزة
كما يلاحظ فالنتين كوزين ، فإن الخصوصية المفرطة لمجموعات البيانات هذه ، مع تحسين جودة الصورة ، تجعل إخراج هش وغير مرن، بدون "البذرة العشوائية" التي تميز الإنتاج الأكثر حيوية لـ BigSleep وزملائها T2I Colabs:

هنا رسم كوزين وجهًا بجبهة عالية ، لكن نموذج مجموعة البيانات المزدوجة الذي دربه (بشخصيات من لعبة الفيديو) يتميز بوجوه ذات جبهات منخفضة حصريًا ، ونرى الأداة الشبحية حيث اعتقد الذكاء الاصطناعي أن الجبهة ' يجب أن تنتهي.
في النهاية ، اضطر كوزين إلى التنازل عن نموذج أكثر عمومية وتنوعًا في التدريب ، مما أدى إلى خوارزمية أكثر قوة وتفسيرًا ؛ على سبيل المثال ، ستنتج وجوهًا بأفواه حتى في حالة عدم رسم المستخدم لفمه:

لكن كوزين يلاحظ أن النموذج الآن غير قادر على رسم الوجه بدون الفم ، إذا كان المستخدم يرغب في ذلك ، وهذا ، بمعنى ما ، تأتي هذه "المرونة" المستعادة مع مجموعة من القيود المحبطة الخاصة بها.
بنى البيانات المحتملة لتوليف الصور
يقول كوزين: "الجزء الأكبر الذي لم يتم حله مما تفعله شركة OpenAI بأشياء مثل GPT-3". "هو أنه بنك معرفة ثابت إلى حد كبير. تحتوي على نافذة انتباه من ألف أو ألفين ... إنه ليس عاملًا يمكنه معرفة المزيد عن المهمة ديناميكيًا ومن ثم التكيف ، بحيث تكون هناك "لقطة" يمكننا تطبيقها على أشياء مختلفة.
"الحل لذلك هو بنيات الذكاء الاصطناعي القادرة على الحصول على مجموعة البيانات الكبيرة هذه ، ولكنها أيضًا قادرة على معرفة المزيد حول تفاصيل للمشكلة التي يحاولون حلها ، وقادرون على تطبيق تلك المعرفة العامة والمحددة. وبعد ذلك ، هذا نوع من الاقتراب من مستوى الإبداع البشري ، كما أفترض.
"أعتقد أن هذا نموذج لم نمتلكه حقًا بعد. بمجرد أن نحصل عليه ، من المحتمل أن يكون ذلك قويا للغاية ".
ريان موردوك يعتقد أنه في الوقت الحالي ، يظل استخدام مجموعات صور كبيرة الحجم وبعيدة المدى ضروريًا لإنشاء هياكل متماسكة وجديدة ، وأن تدريب GAN منفصل لكل عنصر من عناصر الصورة المحتملة (الحركة ، هيكل الوضع ، الإضاءة ، إلخ) تكون كثيفة العمالة.
يقول: "إن فائدة البيانات الضخمة هي السماح للنظام بملء الفجوات من خلال معرفته النقابية الكبيرة. آمل أن يكون من الممكن يومًا ما الحصول على [صورة] محددة جدًا ، ولكن في الوقت الحالي أعتقد أن أقرب شيء هو توجيه CLIP من خلال إعطائها نوعًا من الهيكل.
يمكنك في الأساس إعطاء أي صورة هيكلًا ثم ملء CLIP بالباقي ، إما بتغيير الصورة أو إعطائها مساحة معينة لتعبئتها ، مما يسمح لها بالحصول على بعض القيود المفيدة المحتملة.
"لم أفعل هذا حتى الآن ، لأنني مشغول للغاية ، لكنه نوع من الأشياء التي هي عبارة عن فاكهة معلقة منخفضة بشكل مدهش لتقريب البشر من الحلقة."
يعالج عدد من المشاريع البحثية حاليًا التحدي المتمثل في تدريب شبكات الخصومة التوليدية مع بيانات محدودة أكثر ، دون إنتاج نتائج هشة أو تركيب. وتشمل هذه المبادرات من NVIDIA, معهد ماساتشوستس للتكنولوجيا، و ميتاجان دراسة التعلم قليلة الطلقات.
توليف المناظر الطبيعية
في عام 2019 ، أصدر ذراع البحث الخاص بـ NVIDIA تفاصيل عن غوغان، وهو تطبيق فني للذكاء الاصطناعي يسمح للمستخدم بتطوير مناظر طبيعية واقعية من الرسومات الأولية.

(https://blogs.nvidia.com/blog/2019/03/18/gaugan-photorealistic-landscapes-nvidia-research/)
يمكن القول إن GauGAN هو مثال مثالي لنوع نظام توليف الوسائط المقيّد موضعيًا والذي يمكن تطويره من خلال تدريب مجموعات البيانات المقترنة على عدد صغير من المجالات المحددة - في هذه الحالة ، الصور المتعلقة بالمناظر الطبيعية ، والتي يتم تدريبها بشكل ثنائي ضد الصور التخطيطية لتطوير التبادل التفسيري بين الدهانات الخام والصور الفوتوغرافية الحقيقية.
على الرغم من أنه ليس من الواضح كيف يمكن للمرء إنشاء أي شيء بخلاف صور المناظر الطبيعية باستخدام GauGAN ، إلا أن NVIDIA لديها رقية استخدام فنان مفهوم VFX ومصمم النماذج Colie Wertz للأداة كأساس لرسم أكثر تعقيدًا لسفينة الفضاء.

(https://blogs.nvidia.com/blog/2019/07/30/gaugan-ai-painting/)
فيديو ترويجي لاحق تم إنشاؤه باستخدام GauGAN بواسطة ممارسي VFX من Lucasfilm و Ubisoft و Marvel Studios:
في العيش عرض تفاعلي، يسمح GauGAN للمستخدم بتحديد خريطة التقسيم ، حيث يتم ربط الألوان بأنواع مختلفة من المخرجات ، مثل البحر والصخور والأشجار والأوجه الأخرى لصور المناظر الطبيعية.
يمكن رسم الخريطة إما مباشرة في الواجهة ، أو إنشاؤها في مكان آخر بواسطة المستخدم وتحميلها كمدخل مباشر في نظام التوليف.
تتحكم الشبكة العصبية في مولد SPADE (انظر "Google's Infinite Flyovers" أدناه) في تنشيط الطبقة عبر قناع التجزئة ، متجاوزًا طبقات الاختزال المستخدمة بواسطة نموذج Pix2PixHD (المركز العلوي المصور في الصورة أدناه) ، مما يحقق نتائج أفضل وأداء محسن مع عدد أقل من المعلمات.

(https://arxiv.org/pdf/1903.07291.pdf)
تفسير موسع في تركيب الصور والفيديو
التقسيم الدلالي: المفتاح لبناء عالم الذكاء الاصطناعي؟
في العام السابق لإصدار GauGAN ، أظهرت NVIDIA إمكانية إنشاء التجزئة الدلالية مشاهد عشوائية للشوارع الحضرية، بدلاً من المراعي المثالية:

هذا النظام يسمى Vid2Vidما متدرب مئات الساعات من لقطات الشارع على مستوى السيارة ، ثم ضد شبكة عصبية منفصلة ، من أجل اشتقاق فئات الكائنات لمحتويات مقاطع فيديو الشوارع "الخيالية" - السيارات والطرق والعلامات ومصابيح الشوارع والتفاصيل البيئية الأخرى.

اشتقاق التجزئة الدلالية من لقطات العالم الحقيقي. (https://github.com/NVIDIA/vid2vid)
بمجرد إنشاء التجزئة ، من الممكن إرفاق العديد من الجوانب المختلفة بالمقطع الذي تم إنشاؤه ، بما في ذلك تغييرات السطح ...

تركيب فيديو متعدد الوسائط مع NVIDIA's Vid2Vid. بمجرد إنشاء التجزئة ، يتيح نقل النمط تغيير السطح والجوانب الأخرى لمظهر الكائن. (https://arxiv.org/pdf/1808.06601.pdf)
…وقت اليوم…

(https://www.youtube.com/watch?v=tSOCHisHIAw)
... والوقت من العام.

(https://www.youtube.com/watch?v=e3aXvYIWIq0)
تحقيق الاتساق الزمني في تركيب الفيديو
مع Vid2Vid من NVIDIA ، كما هو الحال مع العديد من أدوات تركيب الصور الناشئة ، كان محترفو VFX عرضة للتعبير عن قلقهم بشأن نقص التحكم ، والقدرة على تطبيق منطق أو استمرارية متسقة على المخرجات.
في صيف 2020 بحث جديد من NVIDIA بعنوان تركيب فيديو متسق عالميًا، عالج هذه المشكلة بهيكل شبكة عصبية جديدة قادرة على تحقيق اتساق زمني طويل المدى
تولد البنية الجديدة "صورًا إرشادية" - نوع من "الإطار الرئيسي" الذي يتم تقييمه من بيانات الحركة في تدفق المشهد ، والذي يجمع جميع وجهات النظر السابقة بدلاً من مجرد حساب الصورة التالية من الإطار السابق ، كما هو الحال مع Vid2Vid الأصلي ، أو مع نظام Google "Infinite Nature" (الذي سننظر إليه قريبًا).

تميل الألوان والبنى إلى التغيير في إخراج Vid2Vid الأصلي ، لأن العارض لديه "ذاكرة" الإطار السابق فقط لبناء الإطار التالي. نرى هنا توليد صورة إرشادية يمكنها نقل المعلومات المستقرة حول الأشياء الموجودة في المشهد.(https://arxiv.org/pdf/2007.08509.pdf)
يُعد الاهتمام والتركيز من المجالات الحاسمة في أبحاث الذكاء الاصطناعي العامة ، وعلى الرغم من أنه ليس من الواضح مقدار التماسك والمتسق الناتج عن تطبيق NVIDIA الجديد لـ Vid2Vid الذي يمكن أن يحققه للحصول على لقطات فيديو أطول ، فإن هذا هو بالضبط نوع التأييد الفعال للمنطق الدلالي الذي يستخدمه الذكاء الاصطناعي في المؤثرات البصرية. من أجل المضي قدمًا في بيئات الإنتاج.
نيرف
في أغسطس من عام 2020 ، أصدر باحثون من جامعة كاليفورنيا في بيركلي وجامعة كاليفورنيا في سان دييغو وجوجل تفاصيل لطريقة جديدة للتعلم الآلي قادرة على تسمى Neural Radiance Fields (NeRF) - طريقة مبتكرة لتحويل الصور ثنائية الأبعاد إلى مساحة ثلاثية الأبعاد قابلة للملاحة ومدارة بواسطة الذكاء الاصطناعي:

بقيادة الباحث في بيركلي ماثيو تانسيك ، يستخدم النهج شبكة عصبية بسيطة (بدون إدراك أو طبقات تلافيفية) لترجمة عدد محدود من صور مشهد أو كائن إلى مساحة ثلاثية الأبعاد حجمية بشكل فعال ، حيث يكون لكل بكسل RGB علامة X مخصصة / Y / Z تنسيق.
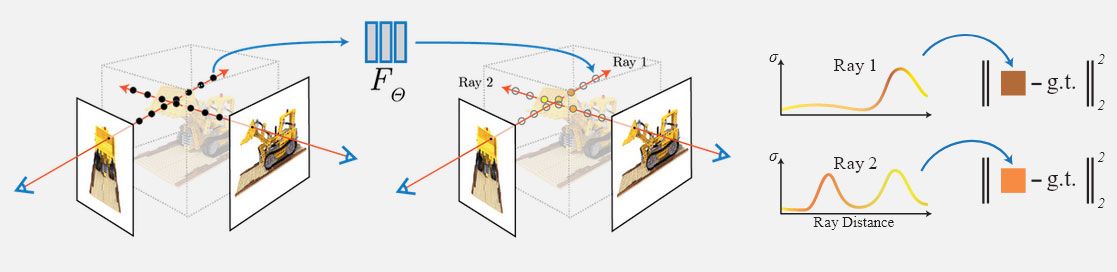
تقوم مساحة NeRF بتجميع سحابة صلبة من النقاط عن طريق الاستعلام عن إحداثيات 5D على مسار أشعة الكاميرا ، وإبراز كثافات وألوان الإخراج باستخدام تقنيات عرض الحجم الثابتة. وبهذا المعنى ، فإنه يشبه في بعض النواحي تتبع أشعة CGI التقليدي. (https://www.matthewtancik.com/nerf)
تحسنت NeRF بشكل ملحوظ على أربعة أسلاف في هذا المجال:

صور مصدر الحقيقة الأرضية (العمود الأيسر) ، متبوعة بالقدرات التفسيرية لـ NeRF ، والنتائج المكافئة من ثلاث خوارزميات سابقة.(https://arxiv.org/pdf/2003.08934.pdf)
هذا ليس مجرد استيفاء أو استيفاء للصورة ، ولكنه مكافئ لإنشاء سحابة نقطية متسقة لدرجة أنه يمكن استخدامها لإنشاء شبكة ثلاثية الأبعاد (انظر الصورة أدناه) ، وتسمح بالتحريك والإمالة والرفع ، بدرجة عالية انتقالات الإضاءة الدقيقة وخرائط عمق الانسداد.
"أعتقد أن ورقة NeRF قد تكون أول قطعة دومينو في سلالة جديدة من أوراق التعلم الآلي التي ستؤتي ثمارها أكثر للتأثيرات المرئية." يقول مشرف VFX و متحمس للتعلم الآلي تشارلي وينتر. "تظهر النتائج الفرعية حتى الآن القدرة على القيام بأشياء قد تكون مستحيلة ببساطة باستخدام GAN التقليدي."
"الطريقة التي تولد بها الشبكة العصبية التلافيفية صورة". أخبرني وينتر ، `` يتم من خلال التوسع التدريجي للحسابات وتشغيلها على جزء من المعلومات ثنائية الأبعاد. بالنظر إلى مهمة مماثلة ، فإن القيد على ذلك هو أنه إذا لم يكن لديك العديد من العينات حول زاوية معينة ، فإن النتائج تصبح أسوأ بكثير وحتى غير مستقرة ، حيث يمكن فقط استخدام الحيل التي تم تعلمها في 2D لتقريب ما قد يكون هناك تقريبًا.
مع NeRF ، ما يتم تعلمه هو تقريب للشكل ثلاثي الأبعاد وانعكاس الضوء ، ويتم إنشاء الصورة فقط عن طريق حركة الأشعة عبر المشهد وأخذ عينات من الشبكة في كل نقطة.
إنه مشابه للطريقة التي يتم بها عرض مشهد CG. باستخدام هذه التقنية ، لا يزال من الممكن وجود زوايا بجودة أقل. ومع ذلك ، نظرًا لأن هذه التقنية لا "تقطع الزاوية" للتعلم ثلاثي الأبعاد ، فمن المرجح أن تظهر معلومات متماسكة.

يمكن لمساحة NeRF أن تولد مكعبًا يسير [55] شبكة مثلث. (https://www.matthewtancik.com/nerf)
على عكس الأساليب التي تستخدم التجزئة الدلالية أو خرائط عمق البيانات الوصفية / المستنبطة ، يوفر NeRF انسدادًا قائمًا على الهندسة لأغراض التركيب.

تجعل المساحة ثلاثية الأبعاد الكاملة لـ NeRF رسم خرائط الانسداد أمرًا بسيطًا نسبيًا.
• بي جان يغطي تطبيق NeRF من مختبر التصوير الحسابي في ستانفورد أرضية مماثلة ، من حيث استخراج الشبكة والاستمرارية ، بينما تم تكييف NeRF لعدة أغراض أخرى ، بما في ذلك إنشاء وجهات نظر بديلة من فيديو أحادي؛ جيل الآلهة من أحادي و متعدد العرض إدخال؛ واستخراج الشبكات والقوام الجاهز للعبة من فيديو أحادي.
يلاحظ وينتر أن NeRF متطلب للغاية فيما يتعلق بوقت المعالجة ، حيث قد يستغرق عرض مشهد واحد معقد شهرًا. هذا يمكن أن يكون
تم التخفيف من حدته من خلال استخدام العديد من TPU / TPU ، ولكن هذا لا يؤدي إلا إلى تقصير وقت العرض - لا يقلل من تكاليف المعالجة.
DyNeRF: تركيب الفيديو العصبي ثلاثي الأبعاد على Facebook
في مارس 2021 ، لاحقة للاتعاون بين Facebook و USC بعنوان التوليف العصبي ثلاثي الأبعاد، طورت مبادئ NeRF إلى تكرار جديد يسمى Dynamic Neural Radiance Field (DyNeRF). النظام قادر على إنتاج بيئات ثلاثية الأبعاد قابلة للملاحة من مدخلات فيديو متعددة الكاميرات.

يستخدم نظام الالتقاط خلف مقطع DyNeRF هذا 21 كاميرا GoPro Black Hero 7 (انظر الصورة أدناه) تسجل بدقة 2.7k بمعدل 30 إطارًا في الثانية.(https://neural-3d-video.github.io/)

تم استخدام 18 نقطة عرض للكاميرا لتدريب الشبكات العصبية على إنشاء بيئة إشراق لكل مقطع فيديو.
بشكل افتراضي ، يولد تسلسل فيديو متعدد العرض 10 × 1014 مدته 1352 ثوانٍ باستخدام 18 كاميرا كمية مذهلة من البيانات الحسابية - 7.4
مليار عينة شعاع لكل حقبة في الدورة التدريبية.
مع وجود 8 وحدات معالجة رسومات (GPU) تقدم 24,576 عينة لكل تكرار و 300,000 إجمالي التكرار المطلوب ، يتطلب التدريب عادةً 3-4 أيام - لا سيما أكثر للتكرارات المتتالية لتحسين جودة الفيديو.
لتحسين أوقات الحساب هذه ، يقوم DyNeRF بتقييم أولوية كل بكسل ، ويخصص لها وزنًا على حساب وحدات البكسل الأخرى التي ستساهم بشكل أقل في الإخراج المقدم. بهذه الطريقة ، يتم الاحتفاظ بأوقات التقارب (المدة التي تستغرقها جلسة التدريب لتحقيق الحد الأدنى من نتيجة الخسارة المقبولة) ضمن الحدود العملية.

يتم تنفيذ التدريب الهرمي بالتسلسل ، أولاً على الإطارات الرئيسية الفردية ، ثم على التسلسل المستمر ، مع تغيير المظهر الزمني إلى أوزان للخوارزمية النهائية. (https://neural-3d-video.github.io/)
ومع ذلك ، يعترف الباحثون بأن النتائج "قريبة" من الصورة الواقعية. أن القوة الحسابية اللازمة لتوليد هذا المستوى من التفسير هائلة ؛ وأن استقراء الأشياء خارج حدود عروض الكاميرا سيكون تحديًا إضافيًا.
DyNeRF قادر على التعامل بشكل جيد مع العناصر المرئية ذات المشاكل التقليدية مثل النار والبخار والماء ، ومع العناصر متباينة الخواص مثل انعكاسات المواد المسطحة ، وغيرها من الاعتبارات البيئية القائمة على الضوء.
بمجرد تحقيق التوليف ، يصبح متعدد الاستخدامات بشكل ملحوظ. يمكن رفع مستوى معدل الإطارات من 30 إطارًا في الثانية الأصلي إلى 150 إطارًا في الثانية أو أكثر ، وعكس هذه الآلية يسمح بتحقيق تأثيرات الحركة البطيئة للغاية و "وقت الرصاص".
Facebook SynSin - عرض التوليف من صورة واحدة
تقدم ورقة بحثية لعام 2020 من Facebook AI Research (FAIR) نهجًا أقل إرهاقًا لتوليف العرض الديناميكي ، وإن كان أقل إبهارًا.
سينسين تستمد الصور المتحركة من صورة واحدة ثابتة من خلال الاستدلال والسياق.

(https://www.robots.ox.ac.uk/~ow/synsin.html)
هنا يجب أن يتضمن النموذج فهمًا للبنية ثلاثية الأبعاد والدلالات ، حيث يجب أن يستنتج ويرسم أجزاء المشهد التي يتم الكشف عنها كمسارات الحركة خارج حدود الصورة الأصلية.
يعتمد العمل المماثل في السنوات الأخيرة على طرق العرض متعددة الكاميرات (مثل DyNeRF) ، أو على الصور المصحوبة ببيانات خريطة العمق ، والتي تم تصنيعها خارجيًا (لنموذج التدريب) أو تم التقاطها في وقت التقاط الصورة.
بدلاً من ذلك ، تقدر SynSin سحابة نقطية محدودة أكثر من DyNeRF ، وتستخدم عاكسًا للعمق لتغطية مقدار الحركة اللازمة. ال
يتم عرض الميزات التي تعلمتها الشبكة العصبية في الفضاء ثلاثي الأبعاد المحسوب ، ثم يتم تمرير تلك الميزات المقدمة إلى شبكة تحسين للإخراج النهائي.

(SynSin: عرض توليف من طرف إلى طرف من صورة واحدة)
الجسور اللانهائية من Google
بينما يمتد هذا النوع من "الصور المتحركة" إلى ما هو أبعد من نظام iOS الخاص بشركة Apple صور حية ، (وانتقلت Adobe أيضًا إلى هذه المنطقة في عام 2018 بامتداد اللقطات المتحركة للمشروع المبادرة) ليست بالضبط "التكبير اللامتناهي" الذي وعدنا به شفرة عداء.

تقدم Google Research شيئًا أقرب إلى هذا في شكل الطبيعة اللانهائية، نظام تعلم آلي قادر على توليد `` مناظر دائمة '' - جسور علوية لا نهاية لها يتم زرعها بواسطة صورة واحدة ، والتي تستخدم معرفة المجال بالمناظر الجوية لتصور رحلة مباشرة من خلال الصورة الأولية وما بعدها ، إلى المناظر الطبيعية الخيالية وفوقها

(https://github.com/google-research/google-research/tree/master/infinite_nature)
تم تدريب Infinite Nature على 700 مقطع فيديو من لقطات الطائرات بدون طيار من السواحل والمشاهد الطبيعية ، وهي قاعدة بيانات تضم أكثر من مليوني إطار. قام الباحثون بتشغيل هيكل من الحركة (SFM) لتحديد مسارات الكاميرا ثلاثية الأبعاد. تم إنشاء قاعدة البيانات الناتجة ، والتي تسمى مجموعة بيانات صور الساحل الجوي (ACID) متاح للعامة.
على الرغم من أن النظام يستلهم بعض الإلهام من حساب SynSin الكامل لمسار الحركة ، فإنه يؤدي بدلاً من ذلك حلقة لا نهائية ، أطلق عليها الباحثون اسم تقديم - صقل - كرر.

(https://www.youtube.com/watch?v=oXUf6anNAtc)
من الإطار المصدر إلى كل إطار "وهمي" ، يتم تقييم كل صورة من الخطوة التالية المحسوبة في المسار. يتم بعد ذلك طلاء الجغرافيا التي تم الكشف عنها حديثًا بناءً على بيانات ميزة المناظر الطبيعية للنموذج ، وتتكرر العملية بأكملها بطريقة الانحدار التلقائي.
يقوم عارض النظام القابل للتفاضل بمقارنة الإطار الحالي بالإطار التالي المتوقع ويقوم بإنشاء "خريطة التباين" ، والتي تكشف عن مكان وجود الثقوب في المشهد.

(https://arxiv.org/pdf/2012.09855.pdf)
تستخدم شبكة التحسين التي تملأ هذه الفجوات تركيب الصورة الدلالية لـ NVIDIA مع التطبيع المكاني المتكيف (السيوف) ، والذي يدعم أيضًا نظام GauGAN المذكور سابقًا.
تقدم جوجل تفاعلية دفتر كولاب، حيث يمكنك القيام برحلة (غير دقيقة جغرافيًا!) من صورة البداية التي تم تحميلها.

ومع ذلك ، سيتحول التسلسل بسرعة كبيرة إلى صور جوية للمناظر الطبيعية ، إذا اخترت تقديم أي نوع آخر من الصور.
لا يوجد ما يمنع المطورين المستقبليين من تطبيق هذا المنطق على أنواع أخرى من "الرحلة اللانهائية" في مجالات مختلفة ، مثل صور الشوارع الحضرية على غرار Vid2Vid ، أو استخدام مجموعات البيانات الاصطناعية لإنتاج رحلات يتم إنشاؤها عشوائيًا عبر عوالم أخرى أو ثقافات غريبة.
إذا تمكنت من جمع صور شجاعة كافية لأوائل الثمانينيات المتشائمة
مساكن نيويورك ، يمكنك حتى إنهاء ديكارد اسبير تحليل صور بولارويد الرجعية الخاصة به ، واكتشف أخيرًا إلى أي مدى تذهب وظيفة "التعزيز".
وفي الختام
تتراوح تكاليف تطوير GPT-3 و DALL-E في الملايين المنخفضة ، على عكس نزهات VFX ذات الميزانيات الكبيرة مثل المنتقمون: حرب إنفينيتي، والذي هو وذكرت لإنفاق 220 مليون دولار أمريكي على التأثيرات المرئية وحدها. لذلك ، يبدو من المرجح أن الاستوديوهات الكبرى ستحول بعض أموال البحث إلى أطر تركيب صور قابلة للمقارنة ، وذلك للتأكد من القيود الحالية لهذا النوع من الهندسة المعمارية - ولكن نأمل ، في النهاية ، تطوير حالة الفن بشكل جذري.
كقياس للوقت الذي استغرقته CGI للحصول على موطئ قدم حقيقي في صناعة المؤثرات البصرية ، فإن تركيب الصور حاليًا أقرب إلى Westworld (1973) من غضب خان (1982) ؛ لكن هناك صوت رعد بعيد.
مارتن أندرسون كاتبة مستقلة في التعلم الآلي والذكاء الاصطناعي.
نشرت سابقا في https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
الاوسمة (تاج)
قم بإنشاء حسابك المجاني لفتح تجربة القراءة المخصصة الخاصة بك.
كوينسمارت. Beste Bitcoin-Börse في أوروبا
المصدر: https://hackernoon.com/ai-image-synthesis-what-the-future-holds-tau33tg؟source=rss

