اليوم ، يواصل اتحاد كرة القدم الأميركي رحلته لزيادة عدد الإحصائيات التي يقدمها منصة احصائيات الجيل التالي لجميع الفرق الـ 32 والمشجعين على حد سواء. من خلال التحليلات المتقدمة المستمدة من التعلم الآلي (ML) ، ينشئ اتحاد كرة القدم الأميركي طرقًا جديدة لقياس كرة القدم ، وتزويد المشجعين بالأدوات اللازمة لزيادة معرفتهم بـ الألعاب داخل اللعبة كرة القدم. بالنسبة لموسم 2022 ، كان NFL يهدف إلى الاستفادة من بيانات تتبع اللاعب وتقنيات التحليلات المتقدمة الجديدة لفهم الفرق الخاصة بشكل أفضل.
كان الهدف من المشروع هو التنبؤ بعدد الياردات التي سيكسبها العائد في ركلة الجزاء أو ركلة البداية. أحد التحديات عند بناء نماذج تنبؤية لعودة ركلات الكرة وانطلاقها هو توافر أحداث نادرة جدًا - مثل الهبوط - التي لها أهمية كبيرة في ديناميكيات اللعبة. يعد توزيع البيانات مع ذيول كبيرة أمرًا شائعًا في تطبيقات العالم الحقيقي ، حيث يكون للأحداث النادرة تأثير كبير على الأداء العام للنماذج. يعد استخدام طريقة قوية لنمذجة التوزيع بدقة على الأحداث المتطرفة أمرًا بالغ الأهمية لتحسين الأداء العام.
في هذا المنشور ، نوضح كيفية استخدام توزيع Spliced Binned-Pareto المطبق في GluonTS لنمذجة هذه التوزيعات ذات الذيل الدهني بقوة.
نصف أولاً مجموعة البيانات المستخدمة. بعد ذلك ، نقدم المعالجة المسبقة للبيانات وطرق التحويل الأخرى المطبقة على مجموعة البيانات. ثم نشرح تفاصيل منهجية تعلم الآلة ونموذج إجراءات التدريب. أخيرًا ، نقدم نتائج أداء النموذج.
بيانات
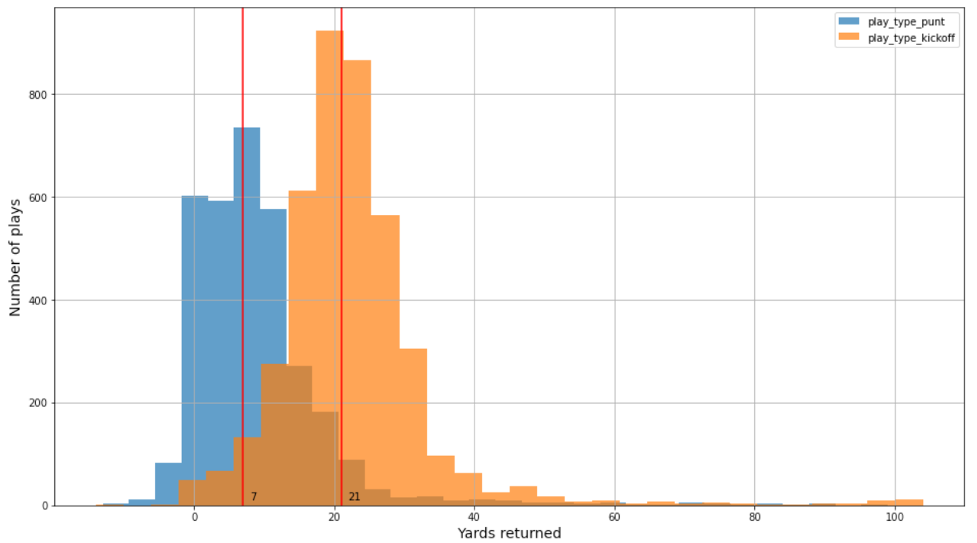
في هذا المنشور ، استخدمنا مجموعتي بيانات لبناء نماذج منفصلة لعودة الركل والبدء. تحتوي بيانات تتبع اللاعب على موقع اللاعب واتجاهه وتسارعه والمزيد (في إحداثيات x و y). هناك حوالي 3,000 و 4,000 مسرحية من أربعة مواسم في دوري كرة القدم الأمريكية (2018-2021) لمسرحيات ركلة الجزاء وبدء التشغيل ، على التوالي. بالإضافة إلى ذلك ، هناك عدد قليل جدًا من عمليات الهبوط ذات الصلة بالسرعة والانطلاق في مجموعات البيانات - فقط 0.23٪ و 0.8٪ على التوالي. يختلف توزيع البيانات للمباريات والبداية. على سبيل المثال ، يتشابه توزيع مقدار الياردات الحقيقي للركلات والركلات ، ولكن يتم تغييره ، كما هو موضح في الشكل التالي.
المعالجة المسبقة للبيانات وهندسة الميزات
أولاً ، تمت تصفية بيانات التتبع للبيانات المتعلقة فقط بالركلات وعودة انطلاق المباراة. تم استخدام بيانات المشغل لاشتقاق ميزات لتطوير النموذج:
- X - موقع اللاعب على طول المحور الطويل للميدان
- Y - موقع اللاعب على طول المحور القصير للميدان
- S - السرعة في ياردة / ثانية ؛ تم استبداله بـ Dis * 10 لجعله أكثر دقة (Dis هي المسافة في آخر 0.1 ثانية)
- أنت - زاوية حركة اللاعب (بالدرجات)
من البيانات السابقة ، تم تحويل كل لعبة إلى 10x11X14 من البيانات مع 10 لاعبين مهاجمين (باستثناء حامل الكرة) و 11 مدافعًا و 14 ميزة مشتقة:
- sX - س سرعة لاعب
- sY - سرعة اللاعب ص
- s - سرعة اللاعب
- aX - x تسارع للاعب
- aY - تسارع ص للاعب
- relX - x مسافة اللاعب بالنسبة لحامل الكرة
- يعتمد - المسافة y للاعب بالنسبة إلى حامل الكرة
- relSx - س سرعة اللاعب بالنسبة لحامل الكرة
- relSy - سرعة اللاعب ص بالنسبة لحامل الكرة
- relDist - المسافة الإقليدية للاعب بالنسبة لحامل الكرة
- OPX - x مسافة لاعب الهجوم بالنسبة للاعب الدفاع
- أوبي - y مسافة لاعب الهجوم بالنسبة للاعب الدفاع
- OPSx –x سرعة لاعب الهجوم بالنسبة للاعب الدفاع
- مقابل - سرعة لاعب الهجوم بالنسبة للاعب الدفاع
لزيادة البيانات وحساب المواضع اليمنى واليسرى ، تم أيضًا عكس قيم الموضع X و Y لحساب مواضع الحقل الأيمن والأيسر. تم تكييف المعالجة المسبقة للبيانات وهندسة الميزات من الفائز في وعاء البيانات الكبيرة NFL المنافسة على Kaggle.
منهجية تعلم الآلة ونموذج التدريب
نظرًا لأننا مهتمون بجميع النتائج المحتملة من المسرحية ، بما في ذلك احتمال الهبوط ، لا يمكننا ببساطة توقع متوسط الياردات المكتسبة كمشكلة انحدار. نحتاج إلى التنبؤ بالتوزيع الاحتمالي الكامل لجميع مكاسب الفناء الممكنة ، لذلك قمنا بتأطير المشكلة على أنها توقع احتمالي.
تتمثل إحدى طرق تنفيذ التنبؤات الاحتمالية في تخصيص الساحات المكتسبة للعديد من الصناديق (مثل أقل من 0 ، من 0-1 ، من 1-2 ، ... ، من 14 إلى 15 ، أكثر من 15) والتنبؤ بالحاوية كتصنيف مشكلة. الجانب السلبي لهذا النهج هو أننا نريد أن يكون للصناديق الصغيرة صورة عالية الوضوح للتوزيع ، لكن الحاويات الصغيرة تعني نقاط بيانات أقل لكل حاوية وقد يكون توزيعنا ، وخاصة ذيول ، سيئ التقدير وغير منتظم.
هناك طريقة أخرى لتنفيذ التنبؤات الاحتمالية وهي نمذجة المخرجات كتوزيع احتمالي مستمر مع عدد محدود من المعلمات (على سبيل المثال ، توزيع Gaussian أو Gamma) والتنبؤ بالمعلمات. يعطي هذا النهج تعريفًا عاليًا للغاية وصورة منتظمة للتوزيع ، ولكنه صارم جدًا بحيث لا يتناسب مع التوزيع الحقيقي للساحات المكتسبة ، وهو متعدد الوسائط وذيل ثقيل.
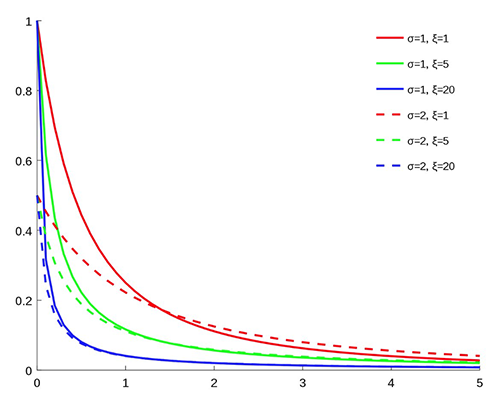
نستخدم كلتا الطريقتين للحصول على أفضل النتائج توزيع مقسم بينيد-باريتو (SBP) ، الذي يحتوي على صناديق لمركز التوزيع حيث يتوفر الكثير من البيانات ، و توزيع باريتو المعمم (GPD) في كلا الطرفين ، حيث يمكن أن تحدث أحداث نادرة ولكنها مهمة ، مثل الهبوط. يحتوي GPD على معلمتين: واحدة للمقياس والأخرى لثقل الذيل ، كما هو موضح في الرسم البياني التالي (المصدر: ويكيبيديا).
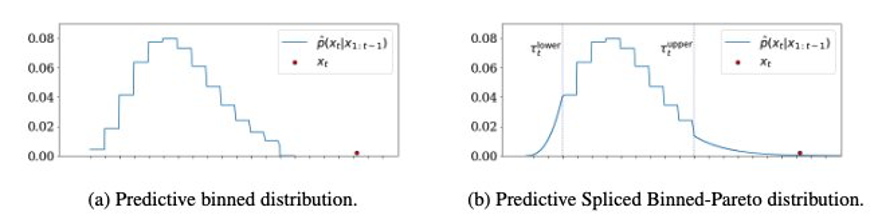
من خلال ربط GPD بالتوزيع المهمل (انظر الرسم البياني الأيسر التالي) على كلا الجانبين ، نحصل على SBP التالي على اليمين. العتبات الدنيا والعليا حيث يتم الربط هي معلمات فائقة.
كخط أساس ، استخدمنا النموذج الذي فاز وعاء البيانات الكبيرة NFL المنافسة على Kaggle. يستخدم هذا النموذج طبقات CNN لاستخراج الميزات من البيانات المعدة ، ويتنبأ بالنتيجة كمشكلة تصنيف "1 ياردة لكل حاوية". بالنسبة إلى نموذجنا ، احتفظنا بطبقات استخراج الميزة من خط الأساس وقمنا فقط بتعديل الطبقة الأخيرة لإخراج معلمات SBP بدلاً من الاحتمالات لكل حاوية ، كما هو موضح في الشكل التالي (تم تحرير الصورة من المنشور حل المركز الأول حديقة الحيوان).

استخدمنا توزيع SBP المقدم من جلونتس. GluonTS عبارة عن حزمة Python لنمذجة السلاسل الزمنية الاحتمالية ، لكن توزيع SBP ليس خاصًا بالسلسلة الزمنية ، وقد تمكنا من إعادة توظيفها من أجل الانحدار. لمزيد من المعلومات حول كيفية استخدام GluonTS SBP ، راجع العرض التوضيحي التالي مفكرة.
تم تدريب النماذج والتحقق من صحتها في مواسم 2018 و 2019 و 2020 واختبارها في موسم 2021. لتجنب التسرب أثناء التحقق المتقاطع ، قمنا بتجميع كل المسرحيات من نفس اللعبة في نفس الحظيرة.
للتقييم ، احتفظنا بالمقياس المستخدم في مسابقة Kaggle ، وهو درجة الاحتمالية ذات التصنيف المستمر (CRPS)، والتي يمكن اعتبارها بديلاً عن احتمالية السجل الأكثر قوة للقيم المتطرفة. استخدمنا أيضًا ملف معامل ارتباط بيرسون و RMSE كمقاييس دقة عامة وقابلة للتفسير. علاوة على ذلك ، نظرنا في احتمالية الهبوط وخطط الاحتمال لتقييم المعايرة.
تم تدريب النموذج على خسارة CRPS باستخدام متوسط الوزن العشوائي والتوقف المبكر.
للتعامل مع عدم انتظام الجزء المهمل من توزيعات الإخراج ، استخدمنا طريقتين:
- عقوبة نعومة تتناسب مع الفرق التربيعي بين صندوقين متتاليين
- تم تدريب نماذج التجميع أثناء التحقق المتبادل
نتائج أداء النموذج
لكل مجموعة بيانات ، أجرينا بحثًا شبكيًا عبر الخيارات التالية:
- النماذج الاحتمالية
- كان خط الأساس احتمالًا واحدًا لكل ياردة
- كان SBP احتمالًا واحدًا لكل ياردة في المركز ، وهو SBP المعمم في ذيول
- تجانس التوزيع
- لا تجانس (عقوبة النعومة = 0)
- عقوبة النعومة = 5
- عقوبة النعومة = 10
- إجراءات التدريب والاستدلال
- 10 طيات عبر التحقق من الصحة واستدلال المجموعة (k10)
- التدريب على بيانات التدريب والتحقق من الصحة لمدة 10 فترات أو 20 حقبة
ثم نظرنا إلى المقاييس الخاصة بالنماذج الخمسة الأولى مرتبة حسب CRPS (الأقل هو الأفضل).
بالنسبة لبيانات الانطلاق ، فإن نموذج SBP يتفوق قليلاً في الأداء من حيث CRPS ولكن الأهم من ذلك أنه يقدر احتمالية الهبوط بشكل أفضل (الاحتمال الحقيقي هو 0.80٪ في مجموعة الاختبار). نرى أن أفضل الموديلات تستخدم تجميع 10 طيات (k10) ولا توجد عقوبة نعومة ، كما هو موضح في الجدول التالي.
| قادة الإيمان | الموديل | نعومة | CRPS | RMSE | ٪ صحيح | P (هبوط)٪ |
| k10 | SBP. | 0 | 4.071 | 9.641 | 47.15 | 0.78 |
| k10 | خط الأساس | 0 | 4.074 | 9.62 | 47.585 | 0.306 |
| k10 | خط الأساس | 5 | 4.075 | 9.626 | 47.43 | 0.274 |
| k10 | SBP. | 5 | 4.079 | 9.656 | 46.977 | 0.682 |
| k10 | خط الأساس | 10 | 4.08 | 9.621 | 47.519 | 0.265 |
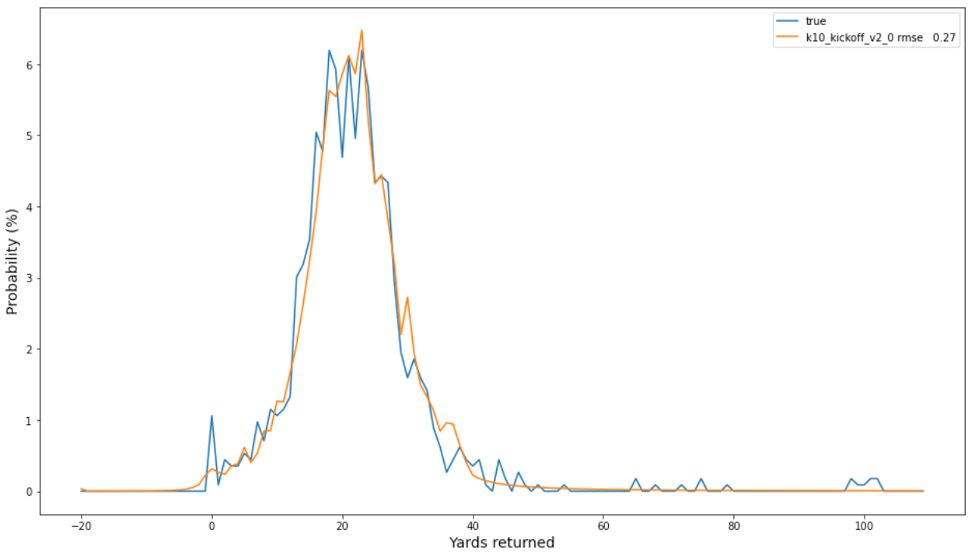
يشير الرسم البياني التالي للترددات المرصودة والاحتمالات المتوقعة إلى معايرة جيدة لأفضل نموذج لدينا ، مع RMSE يبلغ 0.27 بين التوزيعين. لاحظ حدوث مقدار كبير من الياردات (على سبيل المثال ، 100) الذي يحدث في ذيل التوزيع التجريبي الحقيقي (الأزرق) ، والذي تكون احتمالاته أكثر قابلية للتسجيل بواسطة SBP من طريقة خط الأساس.
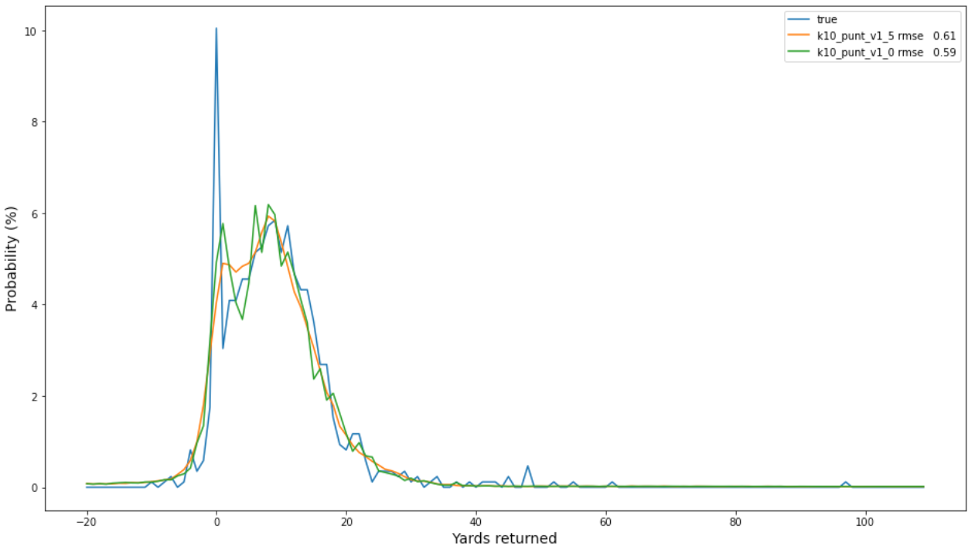
بالنسبة لبيانات punt ، يتفوق خط الأساس على SBP ، ربما لأن ذيول مقدار كبير من الياردات لديها عدد أقل من الإدراك. لذلك ، من الأفضل الحصول على طريقة بين 0-10 ياردات القمم ؛ وعلى عكس بيانات ركلة البداية ، فإن أفضل نموذج يستخدم عقوبة السلاسة. يلخص الجدول التالي النتائج التي توصلنا إليها.
| قادة الإيمان | الموديل | نعومة | CRPS | RMSE | ٪ صحيح | P (هبوط)٪ |
| k10 | خط الأساس | 5 | 3.961 | 8.313 | 35.227 | 0.547 |
| k10 | خط الأساس | 0 | 3.972 | 8.346 | 34.227 | 0.579 |
| k10 | خط الأساس | 10 | 3.978 | 8.351 | 34.079 | 0.555 |
| k10 | SBP. | 5 | 3.981 | 8.342 | 34.971 | 0.723 |
| k10 | SBP. | 0 | 3.991 | 8.378 | 33.437 | 0.677 |
يشير المخطط التالي للترددات الملحوظة (باللون الأزرق) والاحتمالات المتوقعة لأفضل نموذجين للرمي إلى أن النموذج غير المصقول (باللون البرتقالي) تمت معايرته بشكل أفضل قليلاً من النموذج المصقول (باللون الأخضر) وقد يكون خيارًا أفضل بشكل عام.
وفي الختام
في هذا المنشور ، أظهرنا كيفية بناء نماذج تنبؤية مع توزيع البيانات ذات الذيل الدهني. استخدمنا توزيع Spliced Binned-Pareto ، الذي تم تنفيذه في GluonTS ، والذي يمكنه تصميم مثل هذه التوزيعات ذات الذيل الدهني بقوة. استخدمنا هذه التقنية لبناء نماذج لعودة ركلات الكرة وانطلاقها. يمكننا تطبيق هذا الحل على حالات استخدام مماثلة حيث يوجد عدد قليل جدًا من الأحداث في البيانات ، ولكن هذه الأحداث لها تأثير كبير على الأداء العام للنماذج.
إذا كنت ترغب في المساعدة في تسريع استخدام ML في منتجاتك وخدماتك ، فيرجى الاتصال بـ مختبر أمازون ML Solutions برنامج.
حول المؤلف
 تسفاجابير مهاريزغي هو عالم بيانات في مختبر أمازون ML Solutions حيث يساعد عملاء AWS عبر مختلف الصناعات مثل الرعاية الصحية وعلوم الحياة والتصنيع والسيارات والرياضة والإعلام ، على تسريع استخدامهم للتعلم الآلي وخدمات AWS السحابية لحل تحديات أعمالهم.
تسفاجابير مهاريزغي هو عالم بيانات في مختبر أمازون ML Solutions حيث يساعد عملاء AWS عبر مختلف الصناعات مثل الرعاية الصحية وعلوم الحياة والتصنيع والسيارات والرياضة والإعلام ، على تسريع استخدامهم للتعلم الآلي وخدمات AWS السحابية لحل تحديات أعمالهم.
 مارك فان أودهيوسدن هو عالم بيانات أقدم مع فريق Amazon ML Solutions Lab في Amazon Web Services. يعمل مع عملاء AWS لحل مشاكل العمل باستخدام الذكاء الاصطناعي والتعلم الآلي. خارج العمل ، قد تجده على الشاطئ أو يلعب مع أطفاله أو يمارس رياضة ركوب الأمواج أو ركوب الأمواج شراعيًا.
مارك فان أودهيوسدن هو عالم بيانات أقدم مع فريق Amazon ML Solutions Lab في Amazon Web Services. يعمل مع عملاء AWS لحل مشاكل العمل باستخدام الذكاء الاصطناعي والتعلم الآلي. خارج العمل ، قد تجده على الشاطئ أو يلعب مع أطفاله أو يمارس رياضة ركوب الأمواج أو ركوب الأمواج شراعيًا.
 بانبان شو هو عالم تطبيقي كبير ومدير مع Amazon ML Solutions Lab في AWS. تعمل على البحث والتطوير لخوارزميات التعلم الآلي لتطبيقات العملاء عالية التأثير في مجموعة متنوعة من القطاعات الصناعية لتسريع تبني الذكاء الاصطناعي والسحابة. تشمل اهتماماتها البحثية إمكانية تفسير النموذج ، والتحليل السببي ، والذكاء الاصطناعي البشري في الحلقة ، وتصور البيانات التفاعلي.
بانبان شو هو عالم تطبيقي كبير ومدير مع Amazon ML Solutions Lab في AWS. تعمل على البحث والتطوير لخوارزميات التعلم الآلي لتطبيقات العملاء عالية التأثير في مجموعة متنوعة من القطاعات الصناعية لتسريع تبني الذكاء الاصطناعي والسحابة. تشمل اهتماماتها البحثية إمكانية تفسير النموذج ، والتحليل السببي ، والذكاء الاصطناعي البشري في الحلقة ، وتصور البيانات التفاعلي.
 كيونغ هون (جوناثان) جونغ هو مهندس برمجيات كبير في الرابطة الوطنية لكرة القدم. لقد عمل مع فريق Next Gen Stats على مدار السنوات السبع الماضية للمساعدة في بناء النظام الأساسي من تدفق البيانات الأولية ، وإنشاء خدمات صغيرة لمعالجة البيانات ، إلى إنشاء واجهات برمجة التطبيقات التي تعرض البيانات المعالجة. لقد تعاون مع Amazon Machine Learning Solutions Lab في توفير بيانات نظيفة لهم للعمل معها بالإضافة إلى توفير معرفة المجال حول البيانات نفسها. خارج العمل ، يستمتع بركوب الدراجات في لوس أنجلوس والمشي لمسافات طويلة في سيراس.
كيونغ هون (جوناثان) جونغ هو مهندس برمجيات كبير في الرابطة الوطنية لكرة القدم. لقد عمل مع فريق Next Gen Stats على مدار السنوات السبع الماضية للمساعدة في بناء النظام الأساسي من تدفق البيانات الأولية ، وإنشاء خدمات صغيرة لمعالجة البيانات ، إلى إنشاء واجهات برمجة التطبيقات التي تعرض البيانات المعالجة. لقد تعاون مع Amazon Machine Learning Solutions Lab في توفير بيانات نظيفة لهم للعمل معها بالإضافة إلى توفير معرفة المجال حول البيانات نفسها. خارج العمل ، يستمتع بركوب الدراجات في لوس أنجلوس والمشي لمسافات طويلة في سيراس.
 مايكل تشي هو مدير أول للتكنولوجيا يشرف على إحصائيات الجيل القادم وهندسة البيانات في الرابطة الوطنية لكرة القدم. حصل على شهادة في الرياضيات وعلوم الكمبيوتر من جامعة إلينوي في أوربانا شامبين. انضم مايكل لأول مرة إلى NFL في عام 2007 وركز بشكل أساسي على التكنولوجيا والمنصات لإحصاءات كرة القدم. في أوقات فراغه ، يستمتع بقضاء الوقت مع أسرته في الهواء الطلق.
مايكل تشي هو مدير أول للتكنولوجيا يشرف على إحصائيات الجيل القادم وهندسة البيانات في الرابطة الوطنية لكرة القدم. حصل على شهادة في الرياضيات وعلوم الكمبيوتر من جامعة إلينوي في أوربانا شامبين. انضم مايكل لأول مرة إلى NFL في عام 2007 وركز بشكل أساسي على التكنولوجيا والمنصات لإحصاءات كرة القدم. في أوقات فراغه ، يستمتع بقضاء الوقت مع أسرته في الهواء الطلق.
 مايك باند هو مدير أول للأبحاث والتحليلات لإحصائيات الجيل التالي في الرابطة الوطنية لكرة القدم. منذ انضمامه إلى الفريق في عام 2018 ، كان مسؤولاً عن التفكير والتطوير والتواصل بشأن الإحصائيات والرؤى الرئيسية المستمدة من بيانات تتبع اللاعب للجماهير وشركاء بث اتحاد كرة القدم الأميركي والأندية الـ 32 على حدٍ سواء. يجلب مايك ثروة من المعرفة والخبرة للفريق مع درجة الماجستير في التحليلات من جامعة شيكاغو ، ودرجة البكالوريوس في إدارة الرياضة من جامعة فلوريدا ، والخبرة في كل من قسم الكشافة في مينيسوتا فايكنغز وقسم التوظيف فريق فلوريدا جاتور لكرة القدم.
مايك باند هو مدير أول للأبحاث والتحليلات لإحصائيات الجيل التالي في الرابطة الوطنية لكرة القدم. منذ انضمامه إلى الفريق في عام 2018 ، كان مسؤولاً عن التفكير والتطوير والتواصل بشأن الإحصائيات والرؤى الرئيسية المستمدة من بيانات تتبع اللاعب للجماهير وشركاء بث اتحاد كرة القدم الأميركي والأندية الـ 32 على حدٍ سواء. يجلب مايك ثروة من المعرفة والخبرة للفريق مع درجة الماجستير في التحليلات من جامعة شيكاغو ، ودرجة البكالوريوس في إدارة الرياضة من جامعة فلوريدا ، والخبرة في كل من قسم الكشافة في مينيسوتا فايكنغز وقسم التوظيف فريق فلوريدا جاتور لكرة القدم.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/predict-football-punt-and-kickoff-return-yards-with-fat-tailed-distribution-using-gluonts/

