AutoML يسمح لك باستخلاص رؤى سريعة وعامة من بياناتك مباشرة في بداية دورة حياة مشروع التعلم الآلي (ML). إن الفهم المسبق لتقنيات المعالجة المسبقة وأنواع الخوارزميات التي توفر أفضل النتائج يقلل من الوقت اللازم لتطوير النموذج الصحيح وتدريبه ونشره. إنه يلعب دورًا حاسمًا في عملية تطوير كل نموذج ويسمح لعلماء البيانات بالتركيز على تقنيات تعلم الآلة الواعدة. بالإضافة إلى ذلك، يوفر AutoML أداء نموذج أساسي يمكن أن يكون بمثابة نقطة مرجعية لفريق علوم البيانات.
تطبق أداة AutoML مجموعة من الخوارزميات المختلفة وتقنيات المعالجة المسبقة المتنوعة على بياناتك. على سبيل المثال، يمكنه قياس البيانات، وإجراء اختيار ميزة أحادية المتغير، وإجراء PCA عند مستويات مختلفة من عتبة التباين، وتطبيق التجميع. يمكن تطبيق تقنيات المعالجة المسبقة هذه بشكل فردي أو دمجها في خط أنابيب. بعد ذلك، ستقوم أداة AutoML بتدريب أنواع مختلفة من النماذج، مثل Linear Regression أو Elastic-Net أو Random Forest، على إصدارات مختلفة من مجموعة البيانات التي تمت معالجتها مسبقًا وإجراء تحسين المعلمات الفائقة (HPO). Amazon SageMaker الطيار الآلي يلغي الرفع الثقيل لبناء نماذج ML. بعد توفير مجموعة البيانات، يقوم SageMaker Autopilot تلقائيًا باستكشاف حلول مختلفة للعثور على أفضل نموذج. ولكن ماذا لو كنت تريد نشر نسختك المخصصة من سير عمل AutoML؟
يوضح هذا المنشور كيفية إنشاء سير عمل AutoML مخصص الأمازون SageMaker استخدام الضبط التلقائي لنموذج Amazon SageMaker مع نموذج التعليمات البرمجية المتاحة في GitHub الريبو.
حل نظرة عامة
في حالة الاستخدام هذه، لنفترض أنك جزء من فريق علوم البيانات الذي يقوم بتطوير النماذج في مجال متخصص. لقد قمت بتطوير مجموعة من تقنيات المعالجة المسبقة المخصصة وحددت عددًا من الخوارزميات التي تتوقع عادةً أن تعمل بشكل جيد مع مشكلة تعلم الآلة لديك. عند العمل على حالات استخدام جديدة لتعلم الآلة، فإنك ترغب أولاً في إجراء تشغيل AutoML باستخدام تقنيات المعالجة المسبقة والخوارزميات لتضييق نطاق الحلول المحتملة.
في هذا المثال، لا تستخدم مجموعة بيانات متخصصة؛ وبدلاً من ذلك، فإنك تعمل باستخدام مجموعة بيانات الإسكان في كاليفورنيا التي ستستورد منها خدمة تخزين أمازون البسيطة (أمازون إس 3). وينصب التركيز على توضيح التنفيذ الفني للحل باستخدام SageMaker HPO، والذي يمكن تطبيقه لاحقًا على أي مجموعة بيانات ومجال.
يعرض الرسم البياني التالي سير عمل الحل الشامل.

المتطلبات الأساسية المسبقة
فيما يلي المتطلبات الأساسية لإكمال الإرشادات التفصيلية في هذا المنشور:
تنفيذ الحل
الكود الكامل متاح في جيثب ريبو.
خطوات تنفيذ الحل (كما هو موضح في مخطط سير العمل) هي كما يلي:
- إنشاء نسخة دفتر ملاحظات وحدد ما يلي:
- في حالة نوع مثيل دفتر الملاحظات، اختر مل .3.
- في حالة الاستدلال المرن، اختر لا شيء.
- في حالة معرّف النظام الأساسي، اختر أمازون لينكس 2، جوبيتر لاب 3.
- في حالة دور IAM، اختر الافتراضي
AmazonSageMaker-ExecutionRole. إذا لم يكن موجودا، قم بإنشاء جديد إدارة الهوية والوصول AWS (IAM) دور وإرفاق سياسة AmazonSageMakerFullAccess IAM.
لاحظ أنه يجب عليك إنشاء دور وسياسة تنفيذ ذات نطاق محدود في الإنتاج.
- افتح واجهة JupyterLab لمثيل الكمبيوتر الدفتري الخاص بك وقم باستنساخ GitHub repo.
يمكنك القيام بذلك عن طريق بدء جلسة طرفية جديدة وتشغيل الملف git clone <REPO> الأمر أو باستخدام وظيفة واجهة المستخدم، كما هو موضح في لقطة الشاشة التالية.

- فتح
automl.ipynbملف دفتر الملاحظات، حددconda_python3kernel، واتبع التعليمات لتشغيل ملف مجموعة من وظائف HPO.
لتشغيل الكود دون أي تغييرات، تحتاج إلى زيادة حصة الخدمة ml.m5.large للاستخدام الوظيفي التدريبي و عدد الحالات في جميع وظائف التدريب. تسمح AWS بشكل افتراضي بـ 20 مهمة تدريب متوازية فقط على SageMaker لكلا الحصتين. تحتاج إلى طلب زيادة الحصة إلى 30 لكليهما. يجب عادةً الموافقة على كلا التغييرين في الحصص خلال بضع دقائق. تشير إلى طلب زيادة الحصة للمزيد من المعلومات.

إذا كنت لا ترغب في تغيير الحصة النسبية، يمكنك ببساطة تعديل قيمة MAX_PARALLEL_JOBS متغير في البرنامج النصي (على سبيل المثال، إلى 5).
- ستكمل كل وظيفة HPO مجموعة من وظيفه تدريبيه التجارب والإشارة إلى النموذج باستخدام المعلمات الفائقة المثالية.
- تحليل النتائج و نشر النموذج الأفضل أداءً.
سيتحمل هذا الحل تكاليف في حساب AWS الخاص بك. ستعتمد تكلفة هذا الحل على عدد ومدة وظائف التدريب على HPO. وكلما زادت هذه التكاليف، زادت التكلفة. يمكنك تقليل التكاليف عن طريق الحد من وقت التدريب والتكوين TuningJobCompletionCriteriaConfig وفقًا للتعليمات التي تمت مناقشتها لاحقًا في هذا المنشور. للحصول على معلومات التسعير، راجع الأمازون SageMaker التسعير.
في الأقسام التالية، سنناقش دفتر الملاحظات بمزيد من التفاصيل مع أمثلة التعليمات البرمجية وخطوات تحليل النتائج واختيار النموذج الأفضل.
الإعداد الأولي
لنبدأ بتشغيل الواردات والإعداد في القسم custom-automl.ipynb دفتر. يقوم بتثبيت جميع التبعيات المطلوبة واستيرادها، وإنشاء جلسة SageMaker وعميله، وتعيين المنطقة الافتراضية وحاوية S3 لتخزين البيانات.
إعداد البيانات
قم بتنزيل مجموعة بيانات الإسكان في كاليفورنيا وقم بإعدادها عن طريق تشغيل تنزيل البيانات قسم من دفتر الملاحظات. يتم تقسيم مجموعة البيانات إلى إطارات بيانات تدريب واختبار وتحميلها إلى مجموعة S3 الافتراضية لجلسة SageMaker.
تحتوي مجموعة البيانات بأكملها على 20,640 سجلاً و9 أعمدة في المجمل، بما في ذلك الهدف. الهدف هو التنبؤ بالقيمة المتوسطة للمنزل (medianHouseValue عمود). تعرض لقطة الشاشة التالية الصفوف العليا لمجموعة البيانات.

قالب البرنامج النصي للتدريب
يعتمد سير عمل AutoML في هذا المنشور على تعلم الحروف المعالجة المسبقة لخطوط الأنابيب والخوارزميات. الهدف هو إنشاء مجموعة كبيرة من خطوط الأنابيب والخوارزميات المختلفة للمعالجة المسبقة للعثور على الإعداد الأفضل أداءً. لنبدأ بإنشاء برنامج نصي تدريبي عام، والذي يستمر محليًا في مثيل دفتر الملاحظات. في هذا البرنامج النصي، هناك كتلتان تعليق فارغتان: إحداهما لإدخال المعلمات الفائقة والأخرى لكائن خط أنابيب نموذج المعالجة المسبقة. سيتم حقنها ديناميكيًا لكل مرشح لنموذج المعالجة المسبقة. الغرض من وجود برنامج نصي عام واحد هو الحفاظ على التنفيذ جافًا (لا تكرر نفسك).
إنشاء المعالجة المسبقة ومجموعات النماذج
• preprocessors يحتوي القاموس على مواصفات تقنيات المعالجة المسبقة المطبقة على كافة ميزات الإدخال للنموذج. يتم تعريف كل وصفة باستخدام Pipeline أو FeatureUnion كائن من scikit-Learn، الذي يربط تحويلات البيانات الفردية معًا ويجمعها معًا. على سبيل المثال، mean-imp-scale هي وصفة بسيطة تضمن احتساب القيم المفقودة باستخدام القيم المتوسطة للأعمدة المعنية وأن جميع المعالم يتم قياسها باستخدام مقياس قياسي. في المقابل ، فإن mean-imp-scale-pca سلاسل الوصفات معًا بضع عمليات أخرى:
- قم بإسناد القيم المفقودة في الأعمدة بمتوسطها.
- تطبيق تحجيم الميزات باستخدام المتوسط والانحراف المعياري.
- قم بحساب PCA أعلى بيانات الإدخال عند قيمة عتبة تباين محددة ودمجها مع ميزات الإدخال المحسوبة والمقيسة.
في هذا المنشور، جميع ميزات الإدخال رقمية. إذا كان لديك المزيد من أنواع البيانات في مجموعة البيانات المدخلة، فيجب عليك تحديد مسار أكثر تعقيدًا حيث يتم تطبيق فروع المعالجة المسبقة المختلفة على مجموعات أنواع الميزات المختلفة.
• models يحتوي القاموس على مواصفات الخوارزميات المختلفة التي تناسب مجموعة البيانات. يأتي كل نوع طراز مزودًا بالمواصفات التالية في القاموس:
- script_output – يشير إلى موقع البرنامج النصي التدريبي الذي يستخدمه المقدر. يتم ملء هذا الحقل ديناميكيًا عند
modelsيتم دمج القاموس معpreprocessorsقاموس. - الإدراج - تحديد الكود الذي سيتم إدراجه في
script_draft.pyوحفظها بعد ذلك تحتscript_output. المفتاح“preprocessor”تم تركه فارغًا عمدًا لأن هذا الموقع مملوء بأحد المعالجات الأولية من أجل إنشاء مجموعات متعددة من النماذج والمعالجات الأولية. - معلمات مفرطة - مجموعة من المعلمات الفائقة التي تم تحسينها بواسطة وظيفة HPO.
- include_cls_metadata - المزيد من تفاصيل التكوين المطلوبة بواسطة SageMaker
Tunerفئة.
مثال كامل على models القاموس متاح في مستودع جيثب.
بعد ذلك، دعونا نكرر من خلال preprocessors و models القواميس وإنشاء جميع المجموعات الممكنة. على سبيل المثال، إذا كان لديك preprocessors يحتوي القاموس على 10 وصفات ولديك 5 تعريفات للنماذج في models القاموس، يحتوي قاموس خطوط الأنابيب الذي تم إنشاؤه حديثًا على 50 خط أنابيب لنموذج المعالج المسبق والتي يتم تقييمها أثناء HPO. لاحظ أنه لم يتم إنشاء البرامج النصية لخطوط الأنابيب الفردية بعد في هذه المرحلة. تتكرر كتلة التعليمات البرمجية التالية (الخلية 9) من دفتر Jupyter عبر جميع كائنات نموذج المعالج المسبق في pipelines يقوم القاموس بإدراج جميع أجزاء التعليمات البرمجية ذات الصلة، ويحتفظ بإصدار البرنامج النصي الخاص بمسار التدفق محليًا في دفتر الملاحظات. يتم استخدام هذه البرامج النصية في الخطوات التالية عند إنشاء مقدرات فردية تقوم بتوصيلها بمهمة HPO.
تعريف المقدرين
يمكنك الآن العمل على تحديد مقدرات SageMaker التي تستخدمها مهمة HPO بعد أن تصبح البرامج النصية جاهزة. لنبدأ بإنشاء فئة مجمعة تحدد بعض الخصائص الشائعة لجميع المقدرين. ويرث من SKLearn class ويحدد الدور وعدد المثيلات والنوع، بالإضافة إلى الأعمدة التي يستخدمها البرنامج النصي كميزات وهدف.
دعونا نبني estimators القاموس من خلال التكرار عبر جميع البرامج النصية التي تم إنشاؤها من قبل والموجودة في ملف scripts الدليل. يمكنك إنشاء مثيل لمقدر جديد باستخدام SKLearnBase فئة، مع اسم مقدر فريد، وأحد البرامج النصية. نلاحظ أن estimators يحتوي القاموس على مستويين: المستوى الأعلى يحدد أ pipeline_family. هذا تجميع منطقي يعتمد على نوع النماذج المطلوب تقييمها ويساوي طول النموذج models قاموس. يحتوي المستوى الثاني على أنواع المعالجات المسبقة الفردية المدمجة مع المعطى pipeline_family. هذا التجميع المنطقي مطلوب عند إنشاء مهمة HPO.
تعريف وسيطات موالف HPO
لتحسين تمرير الوسائط إلى HPO Tuner الطبقة ، و HyperparameterTunerArgs تتم تهيئة فئة البيانات باستخدام الوسائط التي تتطلبها فئة HPO. يأتي مزودًا بمجموعة من الوظائف التي تضمن إرجاع وسيطات HPO بالتنسيق المتوقع عند نشر تعريفات نماذج متعددة في وقت واحد.
تستخدم كتلة التعليمات البرمجية التالية ما تم تقديمه مسبقًا HyperparameterTunerArgs فئة البيانات. قمت بإنشاء قاموس آخر يسمى hp_args وإنشاء مجموعة من معلمات الإدخال الخاصة بكل منها estimator_family من estimators قاموس. يتم استخدام هذه الوسائط في الخطوة التالية عند تهيئة وظائف HPO لكل عائلة نموذجية.
إنشاء كائنات موالف HPO
في هذه الخطوة، يمكنك إنشاء موالفات فردية لكل منها estimator_family. لماذا تقوم بإنشاء ثلاث وظائف منفصلة لـ HPO بدلاً من إطلاق واحدة فقط عبر جميع المقدرين؟ ال HyperparameterTuner يقتصر الفصل على 10 تعريفات نموذجية مرفقة به. لذلك، يكون كل HPO مسؤولاً عن العثور على المعالج المسبق الأفضل أداءً لعائلة نموذجية معينة وضبط المعلمات الفائقة لعائلة النموذج تلك.
فيما يلي بعض النقاط الإضافية المتعلقة بالإعداد:
- استراتيجية التحسين هي استراتيجية بايزي، مما يعني أن HPO يراقب بنشاط أداء جميع التجارب ويتنقل في التحسين نحو مجموعات المعلمات الفائقة الواعدة. يجب ضبط التوقف المبكر على خصم or السيارات عند العمل مع استراتيجية بايزي، التي تتعامل مع هذا المنطق نفسه.
- تعمل كل وظيفة HPO بحد أقصى 100 وظيفة وتدير 10 وظائف بالتوازي. إذا كنت تتعامل مع مجموعات بيانات أكبر، فقد ترغب في زيادة العدد الإجمالي للوظائف.
- بالإضافة إلى ذلك، قد ترغب في استخدام الإعدادات التي تتحكم في مدة تشغيل المهمة وعدد المهام التي يقوم HPO بتشغيلها. إحدى الطرق للقيام بذلك هي تعيين الحد الأقصى لوقت التشغيل بالثواني (في هذه المقالة، قمنا بتعيينه على ساعة واحدة). آخر هو استخدام الذي تم إصداره مؤخرا
TuningJobCompletionCriteriaConfig. فهو يقدم مجموعة من الإعدادات التي تراقب تقدم وظائفك وتقرر ما إذا كان من المحتمل أن يؤدي المزيد من الوظائف إلى تحسين النتيجة. في هذا المنشور، قمنا بتعيين الحد الأقصى لعدد المهام التدريبية التي لا تتحسن إلى 20. وبهذه الطريقة، إذا لم تتحسن النتيجة (على سبيل المثال، من التجربة الأربعين)، فلن تضطر إلى دفع تكاليف التجارب المتبقية حتىmax_jobsيتم التوصل إليه.
الآن دعونا نكرر من خلال tuners و hp_args القواميس وتشغيل جميع وظائف HPO في SageMaker. لاحظ استخدام وسيطة الانتظار المعينة على Falseمما يعني أن النواة لن تنتظر حتى تكتمل النتائج ويمكنك تشغيل جميع المهام مرة واحدة.
من المحتمل ألا تكتمل جميع وظائف التدريب وقد يتم إيقاف بعضها بواسطة وظيفة HPO. والسبب في ذلك هو TuningJobCompletionCriteriaConfig—ينتهي التحسين في حالة استيفاء أي من المعايير المحددة. في هذه الحالة، عندما لا تتحسن معايير التحسين لـ 20 مهمة متتالية.
تحليل النتائج
تتحقق الخلية 15 من دفتر الملاحظات مما إذا كانت جميع مهام HPO مكتملة وتجمع كل النتائج في شكل إطار بيانات الباندا لمزيد من التحليل. قبل تحليل النتائج بالتفصيل، دعونا نلقي نظرة رفيعة المستوى على وحدة تحكم SageMaker.
في الجزء العلوي من وظائف ضبط Hyperparameter في الصفحة، يمكنك رؤية وظائف HPO الثلاثة التي تم إطلاقها. لقد انتهوا جميعًا مبكرًا ولم يؤدوا جميع الوظائف التدريبية المائة. في لقطة الشاشة التالية، يمكنك أن ترى أن عائلة نماذج Elastic-Net أكملت أكبر عدد من التجارب، في حين أن الآخرين لم يحتاجوا إلى الكثير من المهام التدريبية للحصول على أفضل النتائج.
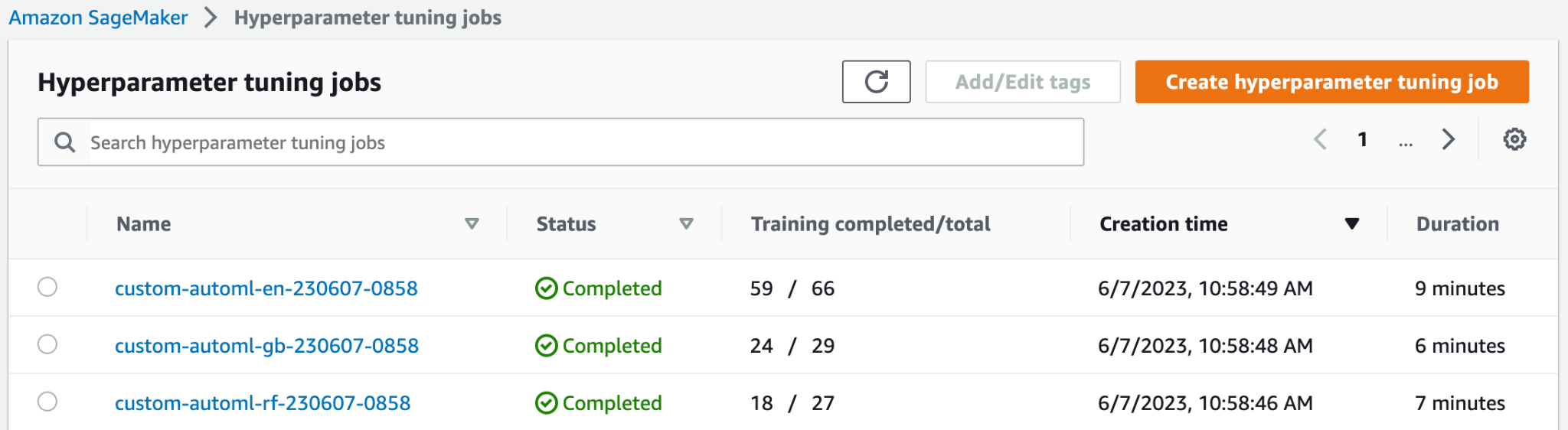
يمكنك فتح وظيفة HPO للوصول إلى مزيد من التفاصيل، مثل وظائف التدريب الفردية وتكوين الوظيفة وأفضل معلومات وأداء وظيفة التدريب.

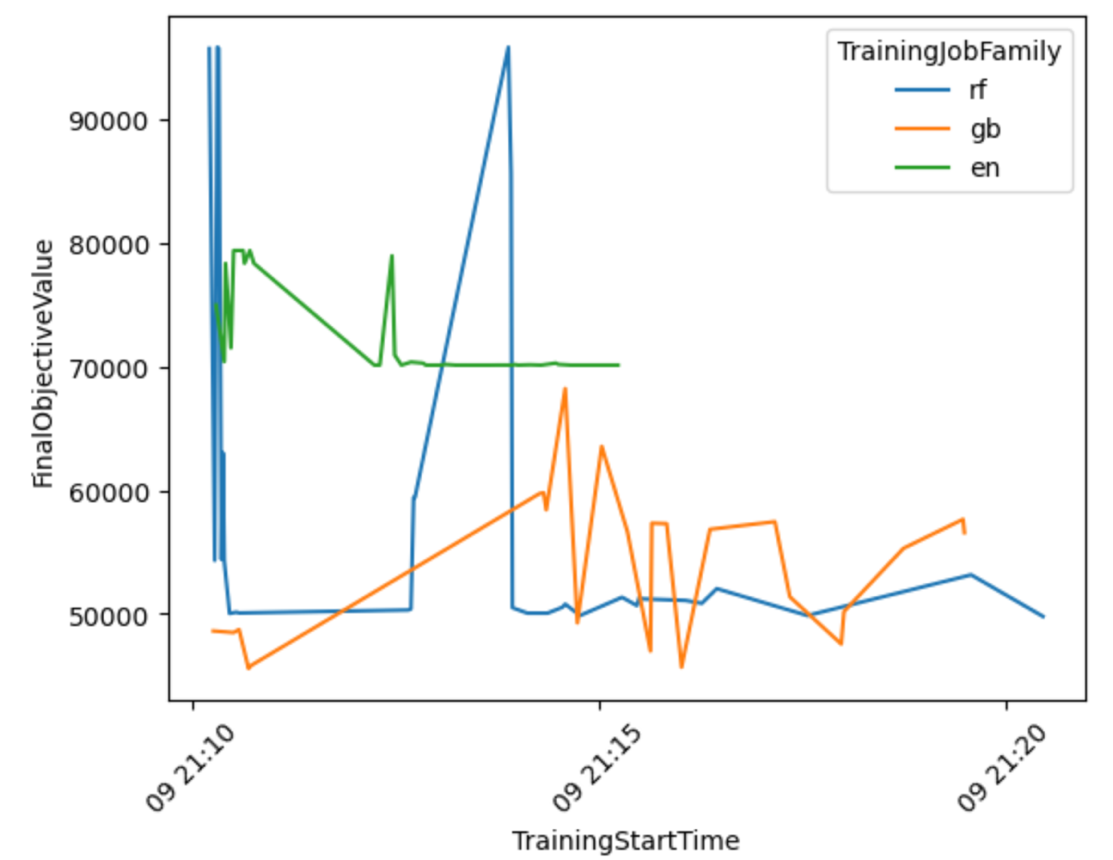
دعونا ننتج تصورًا بناءً على النتائج للحصول على مزيد من المعلومات حول أداء سير عمل AutoML عبر جميع مجموعات النماذج.
من الرسم البياني التالي يمكنك استنتاج أن Elastic-Net كان أداء النموذج يتأرجح بين 70,000 و80,000 RMSE وتوقف في النهاية، حيث لم تكن الخوارزمية قادرة على تحسين أدائها على الرغم من تجربة تقنيات المعالجة المسبقة المختلفة وقيم المعلمات الفائقة. ويبدو ذلك أيضًا RandomForest اختلف الأداء كثيرًا اعتمادًا على مجموعة المعلمات الفائقة التي استكشفتها HPO، ولكن على الرغم من العديد من التجارب، لم تتمكن من الوصول إلى أقل من 50,000 خطأ RMSE. GradientBoosting حقق أفضل أداء بالفعل منذ البداية حيث انخفض إلى أقل من 50,000 RMSE. حاولت HPO تحسين هذه النتيجة بشكل أكبر ولكنها لم تتمكن من تحقيق أداء أفضل عبر مجموعات المعلمات الفائقة الأخرى. الاستنتاج العام لجميع وظائف HPO هو أنه لم تكن هناك حاجة للعديد من الوظائف للعثور على أفضل مجموعة من المعلمات الفائقة أداءً لكل خوارزمية. لتحسين النتيجة بشكل أكبر، ستحتاج إلى تجربة إنشاء المزيد من الميزات وإجراء هندسة ميزات إضافية.
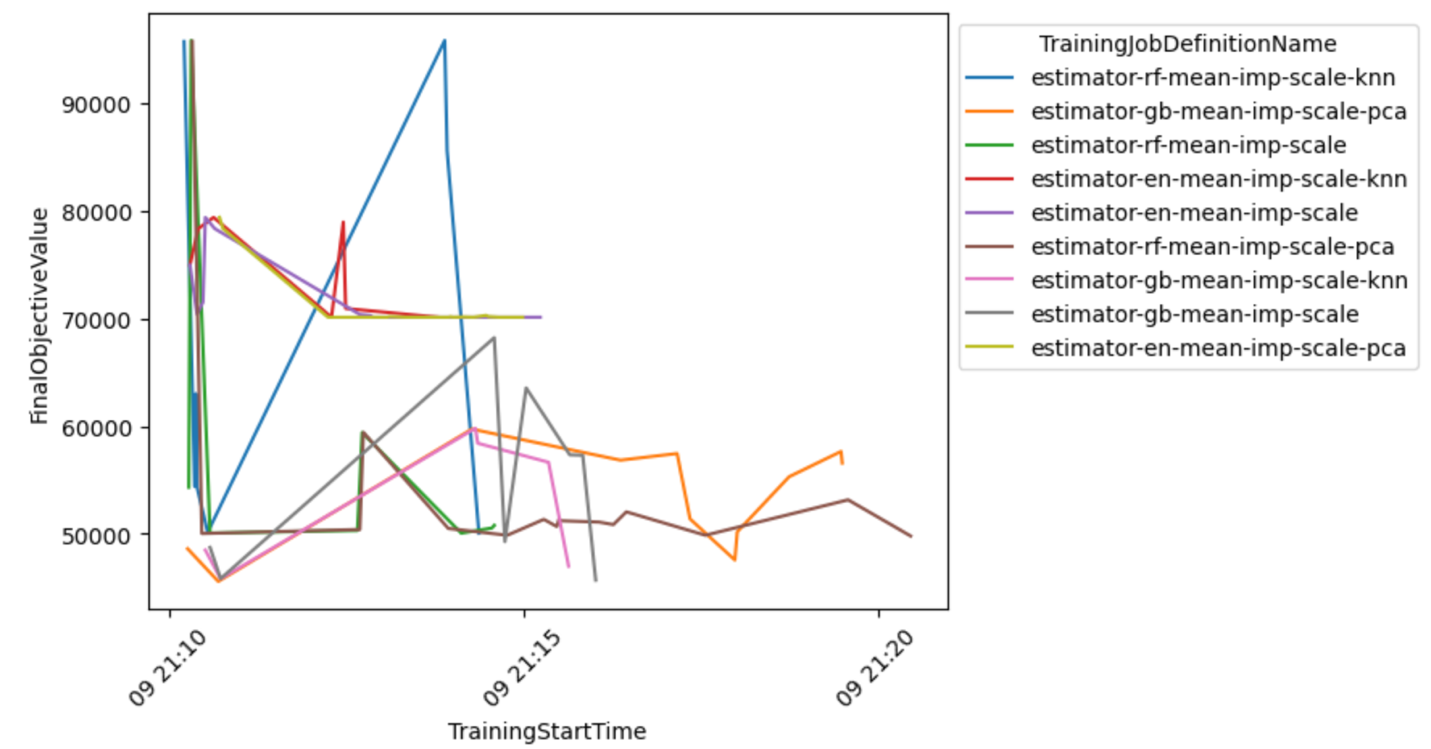
يمكنك أيضًا فحص عرض أكثر تفصيلاً لمجموعة النموذج والمعالج المسبق لاستخلاص استنتاجات حول المجموعات الواعدة.
حدد النموذج الأفضل وقم بنشره
يحدد مقتطف الكود التالي أفضل نموذج بناءً على أقل قيمة موضوعية تم تحقيقها. يمكنك بعد ذلك نشر النموذج كنقطة نهاية SageMaker.
تنظيف
لمنع فرض رسوم غير مرغوب فيها على حساب AWS الخاص بك ، نوصي بحذف موارد AWS التي استخدمتها في هذا المنشور:
- في وحدة تحكم Amazon S3، قم بإفراغ البيانات من حاوية S3 حيث تم تخزين بيانات التدريب.

- على وحدة تحكم SageMaker، قم بإيقاف مثيل دفتر الملاحظات.

- احذف نقطة نهاية النموذج إذا قمت بنشرها. يجب حذف نقاط النهاية عندما لا تكون قيد الاستخدام، لأنه تتم محاسبتها حسب وقت النشر.
وفي الختام
في هذا المنشور، عرضنا كيفية إنشاء مهمة HPO مخصصة في SageMaker باستخدام مجموعة مخصصة من الخوارزميات وتقنيات المعالجة المسبقة. على وجه الخصوص، يوضح هذا المثال كيفية أتمتة عملية إنشاء العديد من البرامج النصية التدريبية وكيفية استخدام هياكل برمجة Python للنشر الفعال لمهام التحسين المتوازية المتعددة. نأمل أن يشكل هذا الحل الأساس لأي مهام ضبط نموذج مخصصة ستنشرها باستخدام SageMaker لتحقيق أداء أعلى وتسريع سير عمل ML لديك.
تحقق من الموارد التالية لتعميق معرفتك بكيفية استخدام SageMaker HPO:
حول المؤلف
 كونراد سيمش هو أحد كبار مهندسي حلول ML في فريق Amazon Web Services Data Lab. إنه يساعد العملاء على استخدام التعلم الآلي لحل تحديات أعمالهم مع AWS. إنه يستمتع بالاختراع والتبسيط لتمكين العملاء من خلال حلول بسيطة وعملية لمشاريع الذكاء الاصطناعي/تعلم الآلة الخاصة بهم. إنه متحمس جدًا لـ MlOps وعلوم البيانات التقليدية. خارج العمل، فهو من أشد المعجبين بركوب الأمواج شراعيًا وركوب الأمواج شراعيًا.
كونراد سيمش هو أحد كبار مهندسي حلول ML في فريق Amazon Web Services Data Lab. إنه يساعد العملاء على استخدام التعلم الآلي لحل تحديات أعمالهم مع AWS. إنه يستمتع بالاختراع والتبسيط لتمكين العملاء من خلال حلول بسيطة وعملية لمشاريع الذكاء الاصطناعي/تعلم الآلة الخاصة بهم. إنه متحمس جدًا لـ MlOps وعلوم البيانات التقليدية. خارج العمل، فهو من أشد المعجبين بركوب الأمواج شراعيًا وركوب الأمواج شراعيًا.
 تونا ارسوي هو مهندس حلول أول في AWS. ينصب تركيزها الأساسي على مساعدة عملاء القطاع العام على اعتماد التقنيات السحابية لأعباء العمل الخاصة بهم. لديها خلفية في تطوير التطبيقات، وهندسة المؤسسات، وتقنيات مراكز الاتصال. تشمل اهتماماتها البنى التحتية بدون خادم والذكاء الاصطناعي/التعلم الآلي.
تونا ارسوي هو مهندس حلول أول في AWS. ينصب تركيزها الأساسي على مساعدة عملاء القطاع العام على اعتماد التقنيات السحابية لأعباء العمل الخاصة بهم. لديها خلفية في تطوير التطبيقات، وهندسة المؤسسات، وتقنيات مراكز الاتصال. تشمل اهتماماتها البنى التحتية بدون خادم والذكاء الاصطناعي/التعلم الآلي.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/implement-a-custom-automl-job-using-pre-selected-algorithms-in-amazon-sagemaker-automatic-model-tuning/

