تدفقات عمل أمازون المدارة لتدفق أباتشي (Amazon MWAA) هي خدمة تنسيق مُدارة لـ أباتشي تدفق الهواء التي يمكنك استخدامها لإعداد وتشغيل خطوط أنابيب البيانات في السحابة على نطاق واسع. Apache Airflow هي أداة مفتوحة المصدر تُستخدم لتأليف تسلسل العمليات والمهام وجدولتها ومراقبتها برمجيًا، ويشار إليها باسم سير العمل. باستخدام Amazon MWAA، يمكنك استخدام Apache Airflow وPython لإنشاء مسارات عمل دون الحاجة إلى إدارة البنية التحتية الأساسية لقابلية التوسع والتوفر والأمان.
باستخدام حسابات AWS المتعددة، يمكن للمؤسسات توسيع نطاق أعباء عملها وإدارة تعقيداتها بشكل فعال أثناء نموها. يوفر هذا النهج آلية قوية للتخفيف من التأثير المحتمل للاضطرابات أو حالات الفشل، مع التأكد من بقاء أعباء العمل الحيوية قيد التشغيل. بالإضافة إلى ذلك، فإنه يتيح تحسين التكلفة من خلال مواءمة الموارد مع حالات استخدام محددة، والتأكد من التحكم في النفقات بشكل جيد. ومن خلال عزل أعباء العمل مع متطلبات أمان محددة أو احتياجات الامتثال، يمكن للمؤسسات الحفاظ على أعلى مستويات خصوصية البيانات وأمانها. علاوة على ذلك، تتيح لك القدرة على تنظيم حسابات AWS المتعددة بطريقة منظمة مواءمة عملياتك التجارية ومواردك وفقًا لمتطلباتك التشغيلية والتنظيمية والميزانية الفريدة. ويعزز هذا النهج الكفاءة والمرونة وقابلية التوسع، مما يمكّن المؤسسات الكبيرة من تلبية احتياجاتها المتطورة وتحقيق أهدافها.
يوضح هذا المنشور كيفية تنسيق خط أنابيب الاستخراج والتحويل والتحميل (ETL) من طرف إلى طرف باستخدام خدمة تخزين أمازون البسيطة (Amazon S3) ، غراء AWSو أمازون Redshift Serverless مع أمازون MWAA.
حل نظرة عامة
بالنسبة لهذا المنشور، فإننا نعتبر حالة استخدام حيث يريد فريق هندسة البيانات إنشاء عملية ETL وتقديم أفضل تجربة للمستخدمين النهائيين عندما يريدون الاستعلام عن أحدث البيانات بعد إضافة ملفات أولية جديدة إلى Amazon S3 في المركز المركزي. الحساب (الحساب أ في مخطط البنية التالي). يريد فريق هندسة البيانات فصل البيانات الأولية في حساب AWS الخاص به (الحساب ب في الرسم التخطيطي) لزيادة الأمان والتحكم. يريدون أيضًا تنفيذ أعمال معالجة البيانات وتحويلها في حسابهم الخاص (الحساب ب) لتقسيم الواجبات ومنع أي تغييرات غير مقصودة على البيانات الأولية المصدر الموجودة في الحساب المركزي (الحساب أ). يتيح هذا الأسلوب للفريق معالجة البيانات الأولية المستخرجة من الحساب "أ" إلى الحساب "ب"، المخصص لمهام معالجة البيانات. وهذا يضمن إمكانية الحفاظ على البيانات الأولية والمعالجة منفصلة بشكل آمن عبر حسابات متعددة، إذا لزم الأمر، لتعزيز إدارة البيانات وأمانها.
يستخدم الحل الخاص بنا مسار ETL شامل يتم تنسيقه بواسطة Amazon MWAA والذي يبحث عن ملفات تزايدية جديدة في موقع Amazon S3 في الحساب أ، حيث توجد البيانات الأولية. يتم ذلك عن طريق استدعاء مهام AWS Glue ETL والكتابة إلى كائنات البيانات في مجموعة Redshift Serverless في الحساب B. ثم يبدأ تشغيل المسار الإجراءات المخزنة وأوامر SQL على Redshift Serverless. عند انتهاء تشغيل الاستعلامات، سيتم تفريغ يتم استدعاء العملية من مستودع بيانات Redshift إلى حاوية S3 في الحساب أ.
نظرًا لأهمية الأمان، يغطي هذا المنشور أيضًا كيفية تكوين اتصال Airflow باستخدام مدير أسرار AWS لتجنب تخزين بيانات اعتماد قاعدة البيانات ضمن اتصالات ومتغيرات Airflow.
يوضح الرسم التخطيطي التالي النظرة العامة المعمارية للمكونات المشاركة في تنسيق سير العمل.
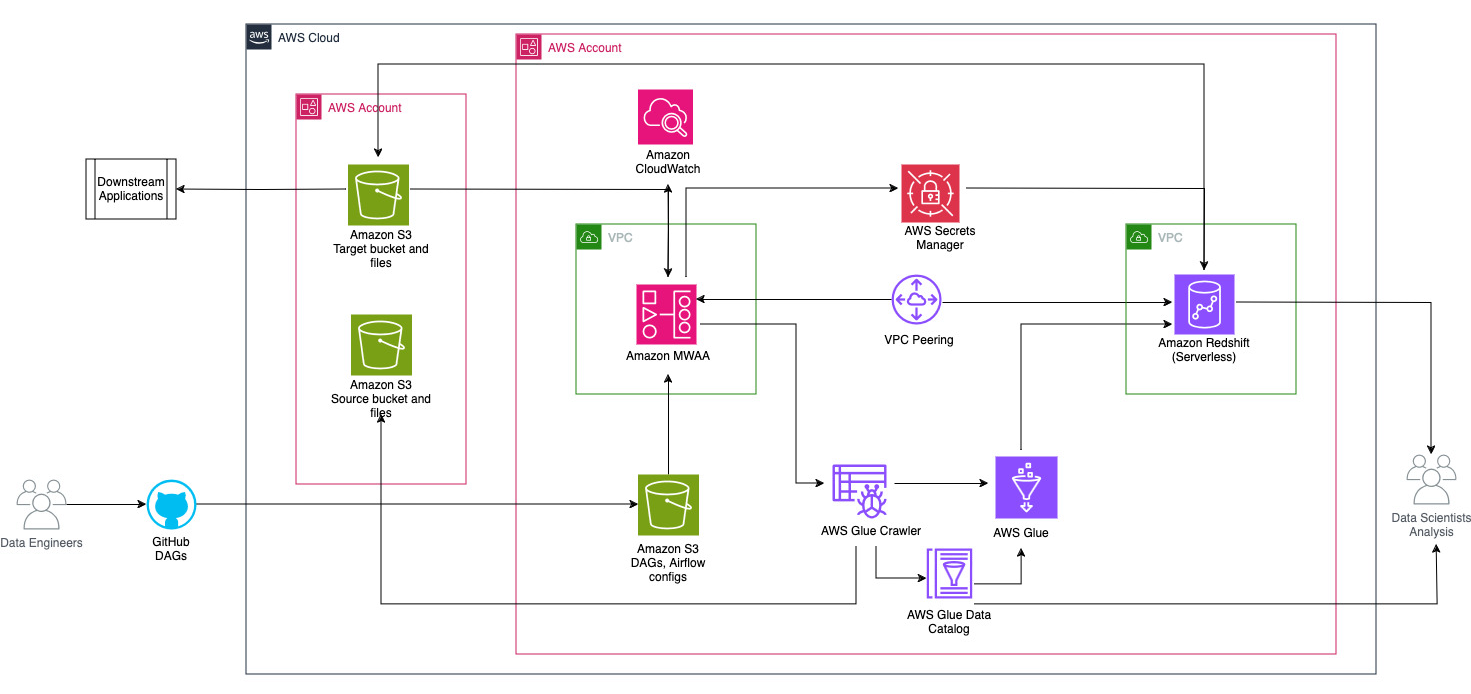
يتكون سير العمل من المكونات التالية:
- توجد حاويات S3 المصدر والهدف في حساب مركزي (الحساب أ)، بينما توجد Amazon MWAA وAWS Glue وAmazon Redshift في حساب مختلف (الحساب ب). تم إعداد الوصول عبر الحسابات بين مجموعات S3 في الحساب أ مع الموارد الموجودة في الحساب ب لتتمكن من تحميل البيانات وإلغاء تحميلها.
- في الحساب الثاني، تتم استضافة Amazon MWAA في VPC واحد وRedshift Serverless في VPC مختلف، وهما متصلان من خلال نظير VPC. يتم تأمين مجموعة عمل Redshift Serverless داخل شبكات فرعية خاصة عبر ثلاث مناطق توافر خدمات.
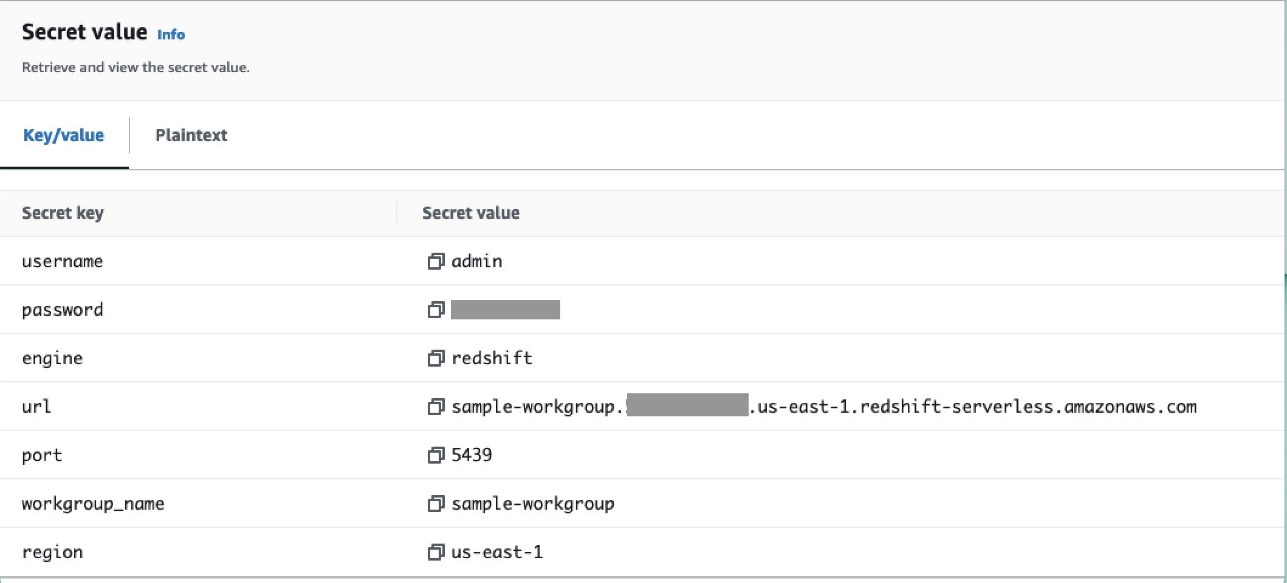
- يتم تخزين أسرار مثل اسم المستخدم وكلمة المرور ومنفذ قاعدة البيانات ومنطقة AWS لـ Redshift Serverless في Secrets Manager.
- يتم إنشاء نقاط نهاية VPC لـ Amazon S3 وSecrets Manager للتفاعل مع الموارد الأخرى.
- عادةً ما يقوم مهندسو البيانات بإنشاء رسم بياني دوري موجه لتدفق الهواء (DAG) وتنفيذ تغييراتهم على GitHub. باستخدام إجراءات GitHub، يتم نشرها في حاوية S3 في الحساب B (في هذا المنشور، نقوم بتحميل الملفات إلى حاوية S3 مباشرةً). يقوم دلو S3 بتخزين الملفات المتعلقة بـ Airflow مثل ملفات DAG،
requirements.txtالملفات والمكونات الإضافية. يتم تخزين نصوص وأصول AWS Glue ETL في حاوية S3 أخرى. يساعد هذا الفصل في الحفاظ على التنظيم وتجنب الارتباك. - يستخدم Airflow DAG العديد من المشغلين وأجهزة الاستشعار والاتصالات والمهام والقواعد لتشغيل خط أنابيب البيانات حسب الحاجة.
- يتم تسجيل الدخول إلى سجلات Airflow الأمازون CloudWatchويمكن تكوين التنبيهات لمراقبة المهام. لمزيد من المعلومات، راجع مراقبة لوحات المعلومات والإنذارات على Amazon MWAA.
المتطلبات الأساسية المسبقة
نظرًا لأن هذا الحل يتمحور حول استخدام Amazon MWAA لتنسيق مسار ETL، فإنك تحتاج إلى إعداد موارد أساسية معينة عبر الحسابات مسبقًا. على وجه التحديد، تحتاج إلى إنشاء مجموعات ومجلدات S3 وموارد AWS Glue وموارد Redshift Serverless في حساباتها الخاصة قبل تنفيذ التكامل الكامل لسير العمل باستخدام Amazon MWAA.
انشر الموارد في الحساب أ باستخدام AWS CloudFormation
في الحساب أ، قم بتشغيل المقدم تكوين سحابة AWS كومة لإنشاء الموارد التالية:
- مجموعات ومجلدات S3 المصدر والهدف. كأفضل ممارسة، يتم تنسيق هياكل دلو الإدخال والإخراج بتقسيم نمط الخلية كـ
s3://<bucket>/products/YYYY/MM/DD/. - مجموعة بيانات عينة تسمى
products.csvالتي نستخدمها في هذا المنصب.
![]()
قم بتحميل مهمة AWS Glue إلى Amazon S3 في الحساب ب
في الحساب ب، قم بإنشاء موقع Amazon S3 يسمى aws-glue-assets-<account-id>-<region>/scripts (إذا لم يكن موجودا). استبدل المعلمات الخاصة بمعرف الحساب والمنطقة في ملف Sample_glue_job.py البرنامج النصي وتحميل ملف مهمة AWS Glue إلى موقع Amazon S3.
انشر الموارد في الحساب "ب" باستخدام AWS CloudFormation
في الحساب ب، قم بتشغيل قالب حزمة CloudFormation المقدم لإنشاء الموارد التالية:
- دلو S3
airflow-<username>-bucketلتخزين الملفات المتعلقة بـ Airflow بالبنية التالية:- الخناجر - مجلد ملفات DAG.
- الإضافات - الملف الخاص بأي ملحقات Airflow مخصصة أو مجتمعية.
- المتطلبات - و
requirements.txtملف لأي حزم بايثون. - مخطوطات - أي نصوص SQL مستخدمة في DAG.
- البيانات - أي مجموعات بيانات مستخدمة في DAG.
- بيئة Redshift بدون خادم. اسم مجموعة العمل ومساحة الاسم مسبوقة بـ
sample. - بيئة AWS Glue، والتي تحتوي على ما يلي:
- غراء AWS الزاحف، الذي يقوم بالزحف إلى البيانات من مجموعة مصدر S3
sample-inp-bucket-etl-<username>في الحساب أ - قاعدة بيانات تسمى
products_dbفي كتالوج بيانات AWS Glue. - تعليم اللغة الإنجليزية وظيفة تسمى
sample_glue_job. يمكن لهذه الوظيفة قراءة الملفات منproductsالجدول في كتالوج البيانات وتحميل البيانات في جدول Redshiftproducts.
- غراء AWS الزاحف، الذي يقوم بالزحف إلى البيانات من مجموعة مصدر S3
- نقطة نهاية بوابة VPC إلى Amazon S3.
- بيئة أمازون MWAA. للحصول على خطوات تفصيلية لإنشاء بيئة Amazon MWAA باستخدام وحدة تحكم Amazon MWAA، راجع تقديم مهام سير العمل المُدارة من Amazon لتدفق هواء Apache (MWAA).
![]()
قم بإنشاء موارد Amazon Redshift
قم بإنشاء جدولين وإجراء مخزن في مجموعة عمل Redshift Serverless باستخدام Products.sql ملف.
في هذا المثال، قمنا بإنشاء جدولين يسمى products و products_f. اسم الإجراء المخزن هو sp_products.
تكوين أذونات تدفق الهواء
بعد إنشاء بيئة Amazon MWAA بنجاح، ستظهر الحالة كـ متوفرة . أختر افتح واجهة مستخدم تدفق الهواء لعرض واجهة مستخدم تدفق الهواء. تتم مزامنة DAGs تلقائيًا من مجموعة S3 وتكون مرئية في واجهة المستخدم. ومع ذلك، في هذه المرحلة، لا توجد DAGs في المجلد S3.
أضف السياسة التي يديرها العميل AmazonMWAAFullConsoleAccess، والذي يمنح مستخدمي Airflow أذونات الوصول إدارة الهوية والوصول AWS (IAM)، وإرفاق هذه السياسة بدور Amazon MWAA. لمزيد من المعلومات، راجع الوصول إلى بيئة Amazon MWAA.
تتمتع السياسات المرتبطة بدور Amazon MWAA بإمكانية الوصول الكامل ويجب استخدامها فقط لأغراض الاختبار في بيئة اختبار آمنة. بالنسبة لعمليات نشر الإنتاج، اتبع مبدأ الامتياز الأقل.
هيئ البيئة
يوضح هذا القسم خطوات تكوين البيئة. تتضمن العملية الخطوات عالية المستوى التالية:
- قم بتحديث أي مقدمي خدمات ضروريين.
- قم بإعداد الوصول عبر الحسابات.
- أنشئ اتصال نظير VPC بين Amazon MWAA VPC وAmazon Redshift VPC.
- قم بتكوين Secrets Manager للتكامل مع Amazon MWAA.
- تحديد اتصالات تدفق الهواء.
قم بتحديث مقدمي الخدمة
اتبع الخطوات الواردة في هذا القسم إذا كان إصدار Amazon MWAA الخاص بك أقل من 2.8.1 (أحدث إصدار حتى كتابة هذا المنشور).
مقدمي هي حزم يتم صيانتها بواسطة المجتمع وتتضمن جميع المشغلين الأساسيين والخطافات وأجهزة الاستشعار لخدمة معينة. يتم استخدام موفر Amazon للتفاعل مع خدمات AWS مثل Amazon S3 وAmazon Redshift Serverless وAWS Glue والمزيد. هناك أكثر من 200 وحدة داخل مزود أمازون.
على الرغم من أن إصدار Airflow المدعوم في Amazon MWAA هو 2.6.3، والذي يأتي مرفقًا مع إصدار الحزمة المقدمة من Amazon 8.2.0، لم تتم إضافة دعم Amazon Redshift Serverless حتى قدمت Amazon إصدار الحزمة 8.4.0. نظرًا لأن إصدار الموفر المجمع الافتراضي أقدم مما كان عليه عندما تم تقديم دعم Redshift Serverless، فيجب ترقية إصدار الموفر لاستخدام هذه الوظيفة.
الخطوة الأولى هي تحديث ملف القيود و requirements.txt الملف بالإصدارات الصحيحة. تشير إلى تحديد حزم الموفر الأحدث للتعرف على خطوات تحديث حزمة موفر Amazon.
- حدد المتطلبات على النحو التالي:
- قم بتحديث الإصدار الموجود في ملف القيود إلى 8.4.0 أو أعلى.
- إضافة القيود-3.11-updated.txt ملف ل
/dagsالمجلد.
الرجوع إلى إصدارات Apache Airflow على مسارات العمل المُدارة من Amazon لـ Apache Airflow للحصول على الإصدارات الصحيحة من ملف القيود اعتمادًا على إصدار Airflow.
- انتقل إلى بيئة Amazon MWAA واختر تعديل.
- تحت رمز DAG في Amazon S3، ل ملف المتطلبات، اختر الإصدار الأحدث.
- اختار حفظ.
سيؤدي هذا إلى تحديث البيئة وسيصبح الموفرون الجدد ساريين.
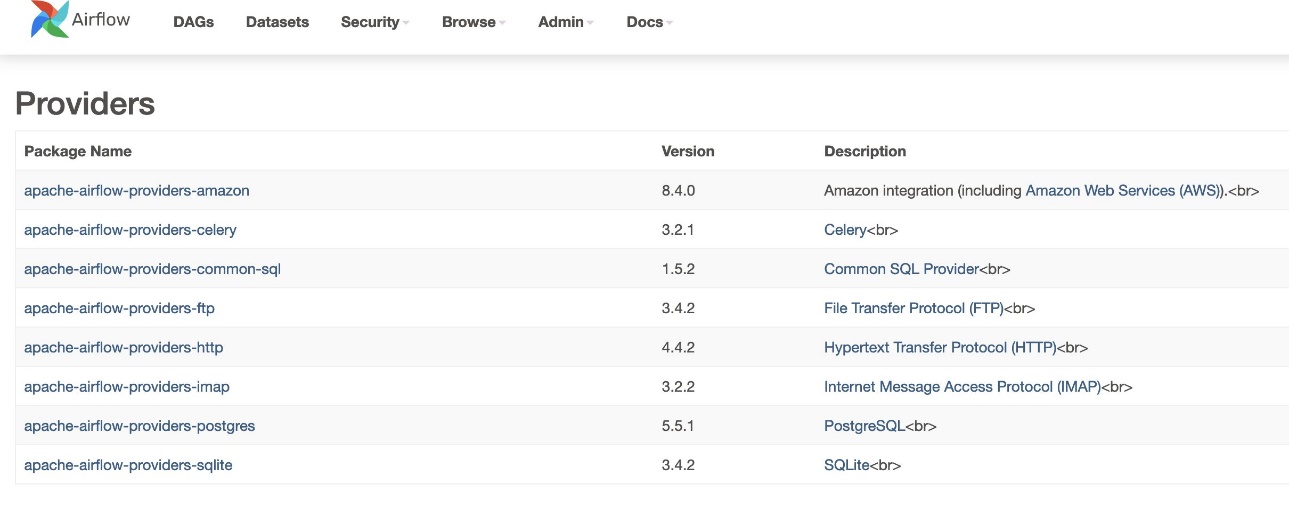
- للتحقق من إصدار الموفرين، انتقل إلى مقدمي تحت إداري الجدول.
يجب أن يكون إصدار حزمة موفر Amazon هو 8.4.0، كما هو موضح في لقطة الشاشة التالية. إذا لم يكن الأمر كذلك، فقد حدث خطأ أثناء التحميل requirements.txt. لتصحيح أي أخطاء، انتقل إلى وحدة تحكم CloudWatch وافتح الملف requirements_install_ip بتسجيل الدخول سجل التدفقات، حيث يتم سرد الأخطاء. تشير إلى تمكين السجلات على وحدة تحكم Amazon MWAA لمزيد من التفاصيل.
قم بإعداد الوصول عبر الحسابات
يتعين عليك إعداد سياسات وأدوار عبر الحسابات بين الحساب "أ" والحساب "ب" للوصول إلى حاويات S3 لتحميل البيانات وإلغاء تحميلها. أكمل الخطوات التالية:
- في الحساب أ، قم بتكوين سياسة الحاوية الخاصة بالحاوية
sample-inp-bucket-etl-<username>لمنح أذونات لأدوار AWS Glue وAmazon MWAA في الحساب B للكائنات الموجودة في المجموعةsample-inp-bucket-etl-<username>: - وبالمثل، قم بتكوين سياسة الحاوية الخاصة بالحاوية
sample-opt-bucket-etl-<username>لمنح أذونات لأدوار Amazon MWAA في الحساب B لوضع الكائنات في هذه المجموعة: - في الحساب أ، قم بإنشاء سياسة IAM تسمى
policy_for_roleA، والذي يسمح بإجراءات Amazon S3 الضرورية على مجموعة الإخراج: - قم بإنشاء دور IAM جديد يسمى
RoleAمع الحساب "ب" باعتباره دور الكيان الموثوق به وأضف هذه السياسة إلى الدور. يتيح ذلك للحساب "ب" تولي الدور "أ" لتنفيذ إجراءات Amazon S3 الضرورية على حاوية المخرجات. - في الحساب ب، قم بإنشاء سياسة IAM تسمى
s3-cross-account-accessمع الإذن بالوصول إلى الكائنات الموجودة في المجموعةsample-inp-bucket-etl-<username>، الموجود في الحساب أ. - أضف هذه السياسة إلى دور AWS Glue ودور Amazon MWAA:
- في الحساب ب، قم بإنشاء سياسة IAM
policy_for_roleBتحديد الحساب "أ" ككيان موثوق به. فيما يلي سياسة الثقة التي يجب افتراضهاRoleAفي الحساب أ: - قم بإنشاء دور IAM جديد يسمى
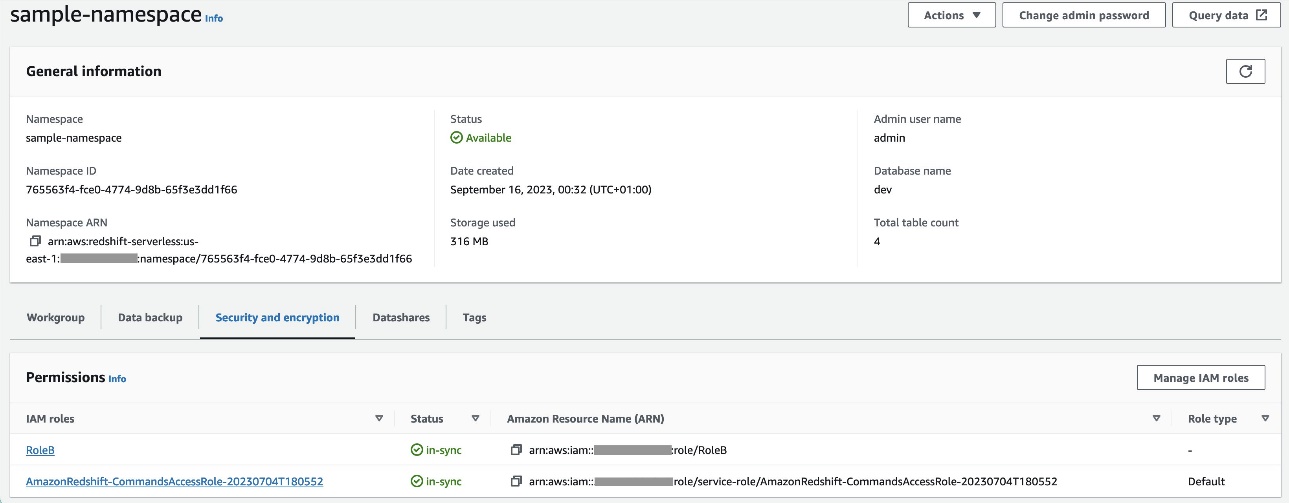
RoleBمع Amazon Redshift كنوع الكيان الموثوق به وإضافة هذه السياسة إلى الدور. هذا يسمحRoleBلنفترضRoleAفي الحساب أ وأيضًا يمكن افتراضه بواسطة Amazon Redshift. - تعلق
RoleBإلى مساحة الاسم Redshift Serverless، حتى يتمكن Amazon Redshift من كتابة الكائنات إلى حاوية إخراج S3 في الحساب A. - إرفاق السياسة
policy_for_roleBإلى دور Amazon MWAA، الذي يسمح لـ Amazon MWAA بالوصول إلى مجموعة المخرجات في الحساب أ.
الرجوع إلى كيف يمكنني توفير الوصول عبر الحسابات إلى العناصر الموجودة في حاويات Amazon S3؟ لمزيد من التفاصيل حول إعداد الوصول عبر الحسابات إلى العناصر في Amazon S3 من AWS Glue وAmazon MWAA. تشير إلى كيف يمكنني نسخ أو إلغاء تحميل البيانات من Amazon Redshift إلى حاوية Amazon S3 في حساب آخر؟ لمزيد من التفاصيل حول إعداد الأدوار لتفريغ البيانات من Amazon Redshift إلى Amazon S3 من Amazon MWAA.
قم بإعداد نظير VPC بين Amazon MWAA وAmazon Redshift VPCs
نظرًا لأن Amazon MWAA وAmazon Redshift موجودان في حاسبين افتراضيين خاصين (VPC) منفصلين، فأنت بحاجة إلى إعداد نظير VPC بينهما. يجب عليك إضافة مسار إلى جداول المسار المرتبطة بالشبكات الفرعية لكلا الخدمتين. تشير إلى العمل مع اتصالات نظير VPC للحصول على تفاصيل حول نظير VPC.

تأكد من أن نطاق CIDR الخاص بـ Amazon MWAA VPC مسموح به في مجموعة أمان Redshift وأن نطاق CIDR الخاص بـ Amazon Redshift VPC مسموح به في مجموعة أمان Amazon MWAA، كما هو موضح في لقطة الشاشة التالية.

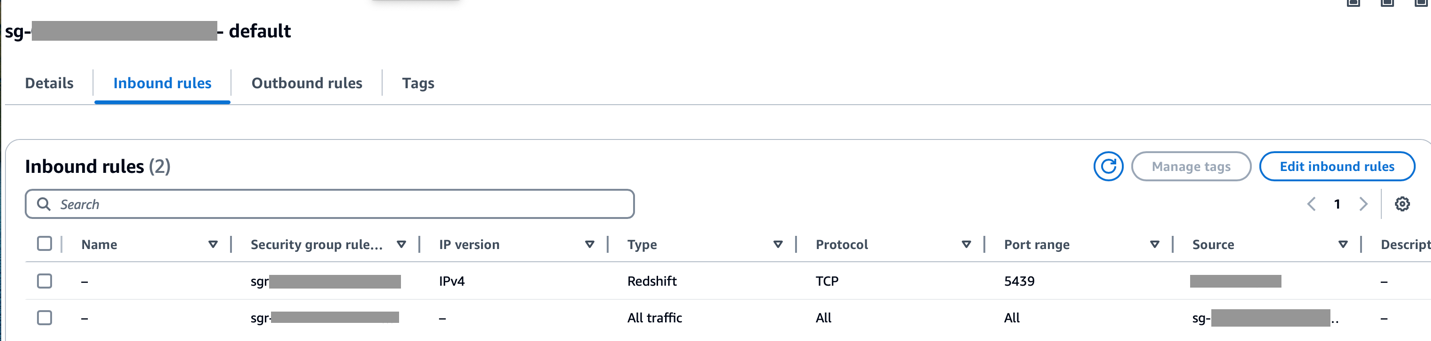
إذا تم تكوين أي من الخطوات السابقة بشكل غير صحيح، فمن المحتمل أن تواجه خطأ "مهلة الاتصال" أثناء تشغيل DAG.
قم بتكوين اتصال Amazon MWAA مع Secrets Manager
عندما يتم تكوين مسار Amazon MWAA لاستخدام Secrets Manager، فإنه سيبحث أولاً عن الاتصالات والمتغيرات في واجهة خلفية بديلة (مثل Secrets Manager). إذا كانت الواجهة الخلفية البديلة تحتوي على القيمة المطلوبة، فسيتم إرجاعها. وإلا، فإنه سيتحقق من قاعدة بيانات البيانات التعريفية بحثًا عن القيمة ويعيدها بدلاً من ذلك. لمزيد من التفاصيل، راجع تكوين اتصال Apache Airflow باستخدام سر AWS Secrets Manager.
أكمل الخطوات التالية:
- تكوين أ نقطة نهاية VPC لربط Amazon MWAA و Secrets Manager (
com.amazonaws.us-east-1.secretsmanager).
يتيح ذلك لـ Amazon MWAA الوصول إلى بيانات الاعتماد المخزنة في Secrets Manager.

- لتزويد Amazon MWAA بالإذن للوصول إلى المفاتيح السرية لـ Secrets Manager، قم بإضافة السياسة المسماة
SecretsManagerReadWriteلدور IAM للبيئة. - لإنشاء الواجهة الخلفية لـ Secrets Manager كخيار تكوين Apache Airflow، انتقل إلى خيارات تكوين Airflow، وأضف أزواج القيمة الرئيسية التالية، واحفظ إعداداتك.
يؤدي هذا إلى تكوين Airflow للبحث عن سلاسل الاتصال والمتغيرات في ملف airflow/connections/* و airflow/variables/* مسارات:

- لإنشاء سلسلة URI لاتصال Airflow، انتقل إلى أوس كلاودشيل والدخول في قذيفة بايثون.
- قم بتشغيل التعليمة البرمجية التالية لإنشاء سلسلة URI للاتصال:
يجب إنشاء سلسلة الاتصال على النحو التالي:
- أضف الاتصال في Secrets Manager باستخدام الأمر التالي في ملف واجهة سطر الأوامر AWS (AWS CLI).
يمكن القيام بذلك أيضًا من وحدة تحكم Secrets Manager. ستتم إضافة هذا في Secrets Manager كنص عادي.
استخدم الاتصال airflow/connections/secrets_redshift_connection في داج. عند تشغيل DAG، سيبحث عن هذا الاتصال ويستعيد الأسرار من Secrets Manager. في حالة RedshiftDataOperator، مرر ال secret_arn كمعلمة بدلاً من اسم الاتصال.
يمكنك أيضًا إضافة أسرار باستخدام وحدة تحكم Secrets Manager كأزواج قيمة المفتاح.
- أضف سرًا آخر في Secrets Manager واحفظه باسم
airflow/connections/redshift_conn_test.
قم بإنشاء اتصال Airflow من خلال قاعدة بيانات التعريف
يمكنك أيضًا إنشاء اتصالات في واجهة المستخدم. في هذه الحالة، سيتم تخزين تفاصيل الاتصال في قاعدة بيانات تعريف Airflow. إذا لم يتم تكوين بيئة Amazon MWAA لاستخدام الواجهة الخلفية لـ Secrets Manager، فسوف تتحقق من قاعدة بيانات البيانات التعريفية بحثًا عن القيمة وتعيدها. يمكنك إنشاء اتصال Airflow باستخدام واجهة المستخدم، أو AWS CLI، أو API. نعرض في هذا القسم كيفية إنشاء اتصال باستخدام واجهة مستخدم Airflow.
- في حالة معرف الاتصال، أدخل اسمًا للاتصال.
- في حالة نوع الاتصال، اختر الأمازون الأحمر.
- في حالة مضيف، أدخل نقطة نهاية Redshift (بدون منفذ وقاعدة بيانات) لـ Redshift Serverless.
- في حالة قاعدة البيانات، أدخل
dev. - في حالة مستخدم، أدخل اسم المستخدم المسؤول الخاص بك.
- في حالة كلمة المرور، ادخل رقمك السري.
- في حالة ميناءاستخدم المنفذ 5439.
- في حالة إكسترا، تعيين
regionوtimeoutالمعلمات. - اختبر الاتصال، ثم احفظ إعداداتك.

إنشاء وتشغيل DAG
في هذا القسم، نوضح كيفية إنشاء DAG باستخدام مكونات مختلفة. بعد إنشاء DAG وتشغيله، يمكنك التحقق من النتائج عن طريق الاستعلام عن جداول Redshift والتحقق من مجموعات S3 المستهدفة.
قم بإنشاء DAG
في Airflow، يتم تعريف خطوط أنابيب البيانات في كود Python على أنها DAGs. نقوم بإنشاء DAG يتكون من عوامل تشغيل وأجهزة استشعار واتصالات ومهام وقواعد مختلفة:
- يبدأ DAG بالبحث عن الملفات المصدر في حاوية S3
sample-inp-bucket-etl-<username>ضمن الحساب "أ" لليوم الحالي باستخدامS3KeySensor. يتم استخدام S3KeySensor لانتظار وجود مفتاح واحد أو عدة مفاتيح في حاوية S3.- على سبيل المثال، تم تقسيم حاوية S3 الخاصة بنا إلى
s3://bucket/products/YYYY/MM/DD/، لذلك يجب أن يقوم المستشعر بالتحقق من المجلدات التي تحتوي على التاريخ الحالي. لقد اشتقنا التاريخ الحالي في DAG وقمنا بتمريره إلىS3KeySensor، والذي يبحث عن أي ملفات جديدة في مجلد اليوم الحالي. - نحن أيضا نضع
wildcard_matchasTrue، والتي تمكن عمليات البحث علىbucket_keyليتم تفسيرها على أنها نمط البدل يونكس. تعيينmodeإلىrescheduleبحيث تقوم مهمة المستشعر بتحرير فتحة العامل عند عدم استيفاء المعايير وإعادة جدولتها في وقت لاحق. كأفضل ممارسة، استخدم هذا الوضع عندماpoke_intervalأكثر من دقيقة واحدة لمنع التحميل الزائد على المجدول.
- على سبيل المثال، تم تقسيم حاوية S3 الخاصة بنا إلى
- بعد توفر الملف في حاوية S3، يتم تشغيل زاحف AWS Glue باستخدام
GlueCrawlerOperatorللزحف إلى مجموعة مصدر S3sample-inp-bucket-etl-<username>ضمن الحساب أ ويقوم بتحديث بيانات تعريف الجدول ضمنproducts_dbقاعدة البيانات في كتالوج البيانات. يستخدم الزاحف دور AWS Glue وقاعدة بيانات كتالوج البيانات التي تم إنشاؤها في الخطوات السابقة. - يستخدم DAG
GlueCrawlerSensorلانتظار اكتمال الزاحف. - عند اكتمال مهمة الزاحف،
GlueJobOperatorيتم استخدامه لتشغيل مهمة AWS Glue. اسم البرنامج النصي AWS Glue (مع الموقع) ويتم تمريره إلى المشغل مع دور AWS Glue IAM. معلمات أخرى مثلGlueVersion,NumberofWorkersوWorkerTypeيتم تمريرها باستخدامcreate_job_kwargsالمعلمة. - يستخدم DAG
GlueJobSensorلانتظار اكتمال مهمة AWS Glue. عند اكتماله، يظهر جدول التدريج الخاص بالتحول نحو الأحمرproductsسيتم تحميله بالبيانات من ملف S3. - يمكنك الاتصال بـ Amazon Redshift من Airflow باستخدام ثلاثة أنواع مختلفة مشغلي:
PythonOperator.SQLExecuteQueryOperator، والذي يستخدم اتصال PostgreSQL وredshift_defaultكالاتصال الافتراضي.RedshiftDataOperator، والذي يستخدم Redshift Data API وaws_defaultكالاتصال الافتراضي.
في DAG لدينا، نستخدم SQLExecuteQueryOperator و RedshiftDataOperator لإظهار كيفية استخدام هذه العوامل. يتم تشغيل إجراءات Redshift المخزنة RedshiftDataOperator. يقوم DAG أيضًا بتشغيل أوامر SQL في Amazon Redshift لحذف البيانات من الجدول المرحلي باستخدام SQLExecuteQueryOperator.
نظرًا لأننا قمنا بتكوين بيئة Amazon MWAA الخاصة بنا للبحث عن الاتصالات في Secrets Manager، فعند تشغيل DAG، فإنه يسترد تفاصيل اتصال Redshift مثل اسم المستخدم وكلمة المرور والمضيف والمنفذ والمنطقة من Secrets Manager. إذا لم يتم العثور على الاتصال في Secrets Manager، فسيتم استرداد القيم من الاتصالات الافتراضية.
In SQLExecuteQueryOperator، نقوم بتمرير اسم الاتصال الذي أنشأناه في Secrets Manager. إنه يبحث عن airflow/connections/secrets_redshift_connection ويستعيد الأسرار من مدير الأسرار. إذا لم يتم إعداد Secrets Manager، فسيتم إنشاء الاتصال يدويًا (على سبيل المثال، redshift-conn-id) يمكن تمريرها.
In RedshiftDataOperator، نمرر سر_الـ airflow/connections/redshift_conn_test تم إنشاء الاتصال في Secrets Manager كمعلمة.
- كمهمة أخيرة،
RedshiftToS3Operatorيُستخدم لتفريغ البيانات من جدول Redshift إلى حاوية S3sample-opt-bucket-etlفي الحساب ب.airflow/connections/redshift_conn_testمن Secrets Manager يستخدم لتفريغ البيانات. TriggerRuleومن المقرر أنALL_DONE، والذي يتيح تشغيل الخطوة التالية بعد اكتمال جميع المهام الأولية.- يتم تعريف تبعية المهام باستخدام
chain()الوظيفة، والتي تسمح بتشغيل المهام بشكل متوازي إذا لزم الأمر. في حالتنا، نريد تنفيذ جميع المهام بالتسلسل.
فيما يلي رمز DAG الكامل. ال dag_id يجب أن يتطابق مع اسم البرنامج النصي DAG، وإلا فلن تتم مزامنته مع واجهة مستخدم Airflow.
التحقق من تشغيل DAG
بعد إنشاء ملف DAG (استبدل المتغيرات في البرنامج النصي DAG) وتحميله إلى ملف s3://sample-airflow-instance/dags المجلد، ستتم مزامنته تلقائيًا مع واجهة مستخدم Airflow. تظهر جميع DAGs على DAGs فاتورة غير مدفوعة. تبديل ON خيار لجعل DAG قابلاً للتشغيل. لأنه تم ضبط DAG الخاص بنا على schedule="@once"، فأنت بحاجة إلى تشغيل المهمة يدويًا عن طريق اختيار أيقونة التشغيل الموجودة أسفل الإجراءات. عند اكتمال DAG، يتم تحديث الحالة باللون الأخضر، كما هو موضح في لقطة الشاشة التالية.
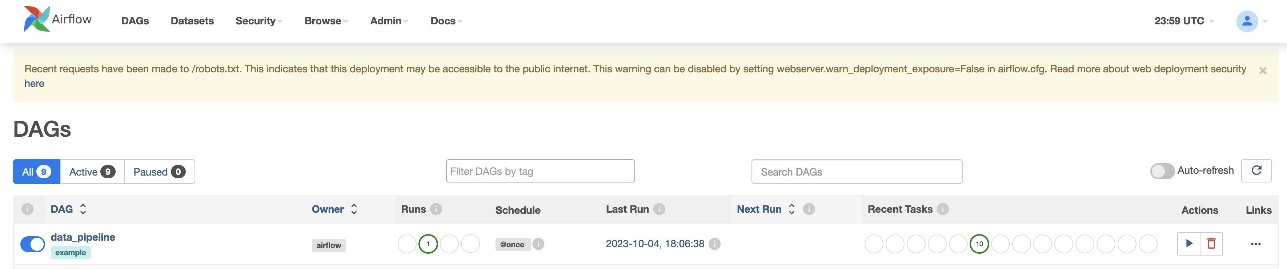
في مجلة روابط القسم، هناك خيارات لعرض الكود والرسم البياني والشبكة والسجل والمزيد. يختار رسم بياني لتصور DAG بتنسيق رسم بياني. كما هو موضح في لقطة الشاشة التالية، يشير كل لون في العقدة إلى عامل تشغيل محدد، ويشير لون مخطط العقدة إلى حالة محددة.

تحقق من النتائج
في وحدة تحكم Amazon Redshift ، انتقل إلى ملف محرر الاستعلام الإصدار 2 وحدد البيانات الموجودة في products_f طاولة. يجب أن يتم تحميل الجدول وأن يحتوي على نفس عدد السجلات الموجودة في ملفات S3.

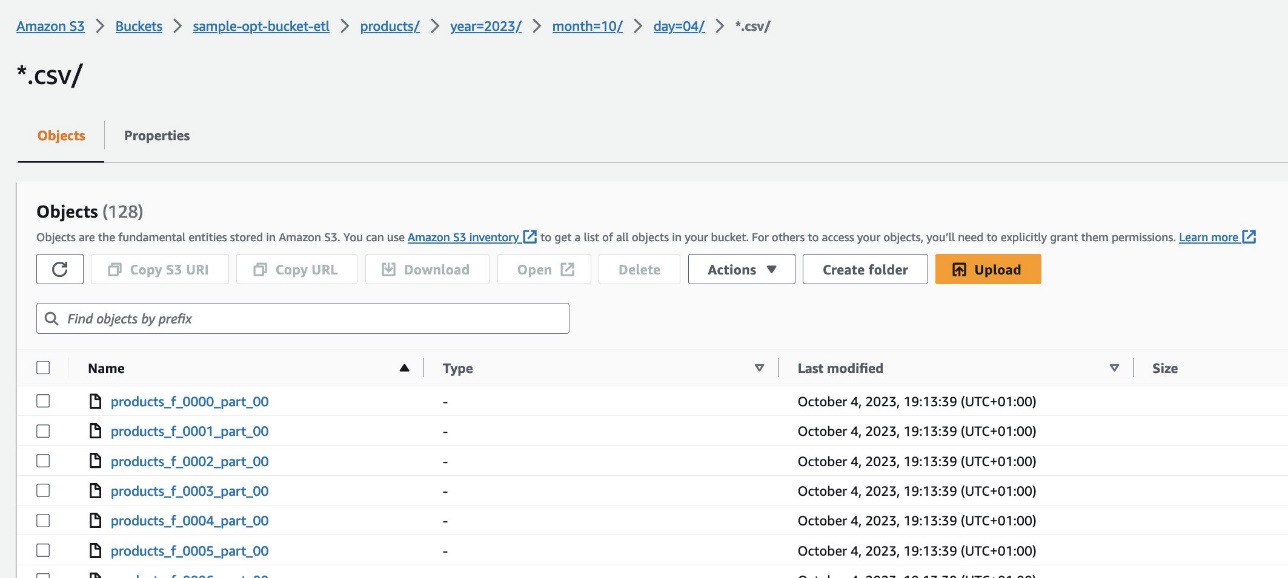
على وحدة تحكم Amazon S3، انتقل إلى حاوية S3 s3://sample-opt-bucket-etl في الحساب ب product_f يجب إنشاء الملفات ضمن بنية المجلد s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.
تنظيف
قم بتنظيف الموارد التي تم إنشاؤها كجزء من هذا المنشور لتجنب تكبد الرسوم المستمرة:
- احذف مكدسات CloudFormation وحاوية S3 التي قمت بإنشائها كمتطلبات أساسية.
- احذف اتصالات نظير VPCs وVPC، والسياسات والأدوار عبر الحسابات، والأسرار في Secrets Manager.
وفي الختام
باستخدام Amazon MWAA، يمكنك إنشاء مسارات عمل معقدة باستخدام Airflow وPython دون إدارة المجموعات أو العقد أو أي حمل تشغيلي آخر يرتبط عادةً بنشر Airflow وتوسيع نطاقه في الإنتاج. في هذا المنشور، أظهرنا كيف توفر Amazon MWAA طريقة تلقائية لاستيعاب البيانات وتحويلها وتحليلها وتوزيعها بين الحسابات والخدمات المختلفة داخل AWS. لمزيد من الأمثلة على مشغلي AWS الآخرين، راجع ما يلي مستودع جيثب; نحن نشجعك على معرفة المزيد من خلال تجربة بعض هذه الأمثلة.
حول المؤلف

راديكا جاكولا هو مهندس حلول النماذج الأولية للبيانات الضخمة في AWS. إنها تساعد العملاء على بناء نماذج أولية باستخدام خدمات تحليلات AWS وقواعد البيانات المصممة لهذا الغرض. وهي متخصصة في تقييم مجموعة واسعة من المتطلبات وتطبيق خدمات AWS ذات الصلة وأدوات البيانات الضخمة وأطر العمل لإنشاء بنية قوية.
 سيدهانث موراليدهار هو مدير الحساب الفني الرئيسي في AWS. إنه يعمل مع عملاء المؤسسات الكبيرة الذين يديرون أعباء العمل الخاصة بهم على AWS. إنه متحمس للعمل مع العملاء ومساعدتهم في تصميم أعباء العمل فيما يتعلق بالتكاليف والموثوقية والأداء والتميز التشغيلي على نطاق واسع في رحلتهم السحابية. لديه اهتمام كبير بتحليلات البيانات أيضًا.
سيدهانث موراليدهار هو مدير الحساب الفني الرئيسي في AWS. إنه يعمل مع عملاء المؤسسات الكبيرة الذين يديرون أعباء العمل الخاصة بهم على AWS. إنه متحمس للعمل مع العملاء ومساعدتهم في تصميم أعباء العمل فيما يتعلق بالتكاليف والموثوقية والأداء والتميز التشغيلي على نطاق واسع في رحلتهم السحابية. لديه اهتمام كبير بتحليلات البيانات أيضًا.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/

