اليوم ، يقوم العديد من عملاء AWS ببناء منصات التعلم الآلي الجاهزة للمؤسسات (ML) على خدمة أمازون مطاطا Kubernetes (Amazon EKS) باستخدام Kubeflow على AWS (توزيع Kubeflow الخاص بـ AWS) عبر العديد من حالات الاستخدام ، بما في ذلك رؤية الكمبيوتر وفهم اللغة الطبيعية وترجمة الكلام والنمذجة المالية.
مع أحدث إصدار من Kubeflow v1.6.1 مفتوح المصدر، يواصل مجتمع Kubeflow دعم هذا التبني الواسع النطاق لـ Kubeflow لحالات استخدام المؤسسات. يتضمن الإصدار الأخير العديد من الميزات المثيرة الجديدة مثل دعم Kubernetes v1.22 ، و Python SDK المدمجة لـ PyTorch ، و MXNet ، و MPI ، و XGBoost في مشغل التدريب الموزع في Kubeflow ، و ClusterServingRuntime و ServingRuntime CRDs لخدمة النموذج ، وغير ذلك الكثير.
تدعم مساهمات AWS في Kubeflow مع الإطلاق الأخير لـ Kubeflow على AWS 1.6.1 جميع ميزات Kubeflow مفتوحة المصدر وتتضمن العديد من عمليات التكامل الجديدة مع خدمات AWS المحسّنة للغاية والجاهزة للمؤسسات والتي ستساعدك على بناء موثوق به للغاية ، أنظمة ML آمنة ومحمولة وقابلة للتطوير.
في هذا المنشور ، نناقش Kubeflow الجديد على ميزات AWS v1.6.1 ونسلط الضوء على ثلاث عمليات تكامل مهمة تم تجميعها في نظام أساسي واحد لنقدم لك:
- البنية التحتية ككود (IaaC) حل بنقرة واحدة يعمل على أتمتة التثبيت الشامل لـ Kubeflow ، بما في ذلك إنشاء مجموعة EKS
- دعم لتوزيع التدريب على الأمازون SageMaker استخدام عوامل تشغيل Amazon SageMaker لـ Kubernetes (ACK) و مكونات SageMaker لأنابيب Kubeflow ومحليا على Kubernetes باستخدام مشغلي تدريب Kubeflow. يستخدم العديد من العملاء هذه الإمكانية لبناء هياكل التعلم الآلي الهجينة حيث يستفيدون من كلاً من حوسبة Kubernetes لمرحلة التجريب و SageMaker لتشغيل أعباء العمل على نطاق الإنتاج.
- تحسين المراقبة والمراقبة لأحمال عمل ML بما في ذلك Amazon EKS ومقاييس Kubeflow وسجلات التطبيق باستخدام Prometheus و Grafana و الأمازون CloudWatch التكاملات
ستركز حالة الاستخدام في هذه المدونة بشكل خاص على تكامل SageMaker مع Kubeflow على AWS والذي يمكن إضافته إلى تدفقات عمل Kubernetes الحالية لديك مما يتيح لك إنشاء بنيات التعلم الآلي الهجينة.
Kubeflow على AWS
يوفر Kubeflow على AWS 1.6.1 مسارًا واضحًا لاستخدام Kubeflow ، مع إضافة خدمات AWS التالية بالإضافة إلى الإمكانات الحالية:
- تكامل SageMaker مع Kubeflow لتشغيل تدفقات عمل ML المختلطة باستخدام SageMaker Operators لـ Kubernetes (ACK) ومكونات SageMaker لخطوط أنابيب Kubeflow.
- تم تحسين خيارات النشر الآلي وتبسيطها باستخدام البرامج النصية Kustomize ومخططات Helm.
- دعم إضافي للبنية التحتية كـ Code (IaC) للنشر بنقرة واحدة لـ Kubeflow على AWS باستخدام Terraform لكل ما هو متاح خيارات النشر. يعمل هذا البرنامج النصي على أتمتة إنشاء موارد AWS التالية:
- دعم لل AWS الرابط الخاص بالنسبة إلى Amazon S3 لتمكين مستخدمي المنطقة غير التجارية من الاتصال بنقاط نهاية S3 الخاصة بهم.
- التكامل المضاف مع خدمة Amazon المُدارة لشركة Prometheus (AMP) و أمازون تديرها جرافانا لمراقبة المقاييس باستخدام Kubeflow على AWS.
- حاويات خادم الكمبيوتر المحمول Kubeflow المحدثة مع أحدث صور حاوية التعلم العميق استنادًا إلى TensorFlow 2.10.0 و PyTorch 1.12.1.
- التكامل مع AWS DLCs للتشغيل الموزع السلامه اولا و الإستنباط أعباء العمل.
يعد الرسم التخطيطي للهندسة المعمارية التالي لقطة سريعة لجميع عمليات تكامل الخدمات (بما في ذلك ما سبق ذكره) المتوفرة للتحكم في Kubeflow ومكونات مستوى البيانات في Kubeflow على AWS. يتم تثبيت مستوى التحكم Kubeflow أعلى Amazon EKS ، وهي خدمة حاوية مُدارة تُستخدم لتشغيل تطبيقات Kubernetes وتوسيع نطاقها في السحابة. تسمح لك عمليات تكامل خدمات AWS بفصل الأجزاء المهمة من مستوى التحكم Kubeflow عن Kubernetes ، مما يوفر تصميمًا آمنًا وقابلًا للتطوير ومرنًا ومنخفض التكلفة. لمزيد من التفاصيل حول القيمة التي تضيفها عمليات تكامل الخدمة هذه على Kubeflow مفتوح المصدر ، ارجع إلى قم ببناء ونشر نظام تعلم آلي قابل للتطوير على Kubernetes باستخدام Kubeflow على AWS.

دعونا نناقش بمزيد من التفصيل كيف يمكن أن تكون الميزات الرئيسية Kubeflow على AWS 1.6.1 مفيدة لمؤسستك.
Kubeflow على تفاصيل ميزات AWS
مع إصدار Kubeflow 1.6.1 ، حاولنا توفير أدوات أفضل لأنواع مختلفة من العملاء تسهل بدء استخدام Kubeflow بغض النظر عن الخيارات التي تختارها. توفر هذه الأدوات نقطة انطلاق جيدة ويمكن تعديلها لتناسب احتياجاتك بالضبط.
خيارات النشر
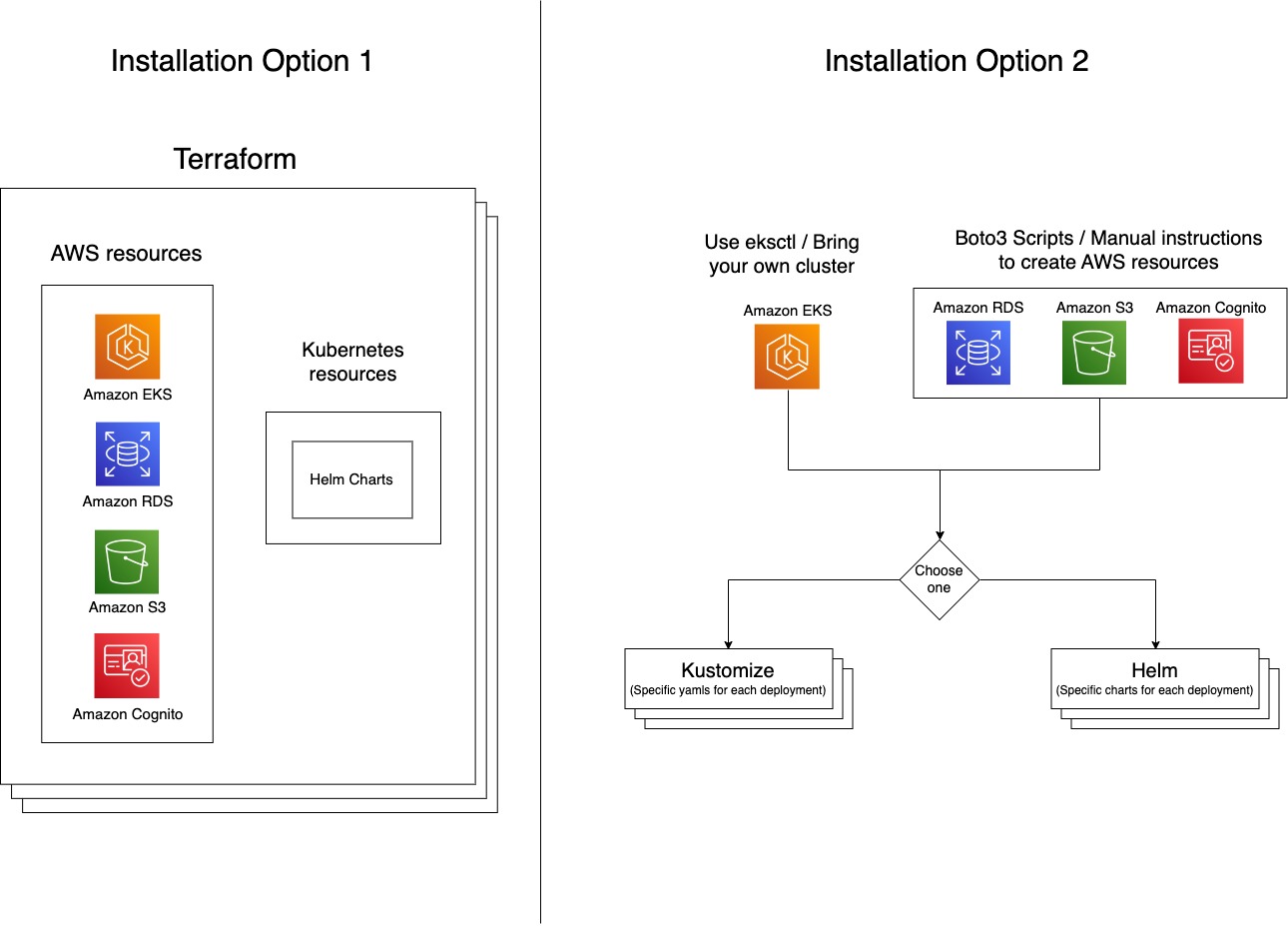
نحن نقدم خيارات نشر مختلفة لحالات استخدام العملاء المختلفة. هنا يمكنك اختيار خدمات AWS التي تريد دمج نشر Kubeflow معها. إذا قررت تغيير خيارات النشر لاحقًا ، نوصيك بإجراء تثبيت جديد للنشر الجديد. تتوفر خيارات النشر التالية:
إذا كنت ترغب في نشر Kubeflow مع الحد الأدنى من التغييرات ، ففكر في الفانيليا خيار النشر. يمكن تثبيت جميع خيارات النشر المتاحة باستخدام Kustomize أو Helm أو Terraform.
لدينا أيضًا عمليات توزيع إضافية مختلفة يمكن تثبيتها فوق أي من خيارات النشر التالية:
خيارات التثبيت
بعد أن تحدد خيار النشر الذي يناسب احتياجاتك ، يمكنك اختيار الطريقة التي تريد بها تثبيت عمليات النشر هذه. في محاولة لخدمة الخبراء والقادمين الجدد على حد سواء ، لدينا مستويات مختلفة من الأتمتة والتكوين.
الخيار 1: Terraform (IaC)
يؤدي هذا إلى إنشاء مجموعة EKS وجميع موارد البنية التحتية لـ AWS ذات الصلة ، ثم نشر Kubeflow في أمر واحد باستخدام Terraform. داخليًا ، يستخدم هذا مخططات EKS ومخططات Helm.
هذا الخيار له المزايا التالية:
- يوفر المرونة للمؤسسات لنشر Amazon EKS و Kubeflow بأمر واحد دون الحاجة إلى القلق بشأن تكوينات مكونات Kubeflow المحددة. سيساعد هذا بشكل كبير في تسريع تقييم التكنولوجيا والنماذج الأولية ودورة حياة تطوير المنتج مما يوفر المرونة في استخدام وحدات terraform وتعديلها لتلبية أي احتياجات خاصة بالمشروع.
- يمكن للعديد من المؤسسات اليوم التي لديها Terraform كمركز لإستراتيجيتها السحابية استخدام Kubeflow على حل AWS Terraform لتحقيق أهدافها السحابية.
الخيار 2: تخصيص أو مخططات خوذة:
يتيح لك هذا الخيار نشر Kubeflow في عملية من خطوتين:
- أنشئ موارد AWS مثل Amazon EKS و Amazon RDS و Amazon S3 و Amazon Cognito ، إما من خلال البرامج النصية الآلية المضمنة في توزيع AWS أو اتباع دليل خطوة بخطوة.
- قم بتثبيت عمليات نشر Kubeflow إما باستخدام مخططات Helm أو Kustomize.
هذا الخيار له المزايا التالية:
- الهدف الرئيسي لخيار التثبيت هذا هو توفير تكوينات Kubernetes المتعلقة بـ Kubeflow. لذلك ، يمكنك اختيار إنشاء أو جلب مجموعات EKS الحالية أو أي من موارد AWS ذات الصلة مثل Amazon RDS و Amazon S3 و Amazon Cognito ، وتهيئتها وإدارتها للعمل مع Kubeflow على AWS.
- من الأسهل الانتقال من بيان Kustomize Kubeflow مفتوح المصدر إلى توزيع AWS Kubeflow.
يوضح الرسم البياني التالي بنيات كلا الخيارين.
التكامل مع SageMaker
SageMaker هي خدمة مُدارة بالكامل تم تصميمها وتحسينها خصيصًا لإدارة تدفقات عمل ML. إنه يزيل الرفع الثقيل غير المتمايز لإدارة البنية التحتية ويلغي الحاجة إلى الاستثمار في تكنولوجيا المعلومات و DevOps لإدارة المجموعات لبناء نموذج التعلم الآلي والتدريب والاستدلال.
يستخدم العديد من عملاء AWS الذين لديهم متطلبات قابلية النقل أو قيود قياسية محلية Amazon EKS لإعداد خطوط أنابيب ML قابلة للتكرار لتشغيل التدريب واستنتاج أعباء العمل. ومع ذلك ، يتطلب هذا من المطورين كتابة تعليمات برمجية مخصصة لتحسين البنية التحتية الأساسية للتعلم الآلي ، وتوفير إمكانية عالية وموثوقية عالية ، والامتثال للمتطلبات الأمنية والتنظيمية المناسبة. لذلك يرغب هؤلاء العملاء في استخدام SageMaker للبنية التحتية المُدارة والمُحسّنة من حيث التكلفة لتدريب النماذج وعمليات النشر والاستمرار في استخدام Kubernetes للتنسيق وخطوط أنابيب ML للاحتفاظ بالتوحيد القياسي وإمكانية النقل.
لتلبية هذه الحاجة ، تتيح لك AWS تدريب النماذج وضبطها ونشرها في SageMaker من Amazon EKS باستخدام الخيارين التاليين:
- عوامل تشغيل Amazon SageMaker ACK لـ Kubernetes ، والتي تستند إلى أدوات تحكم AWS لـ Kubernetes (ACK). ACK هي إستراتيجية AWS التي تجلب التوحيد القياسي لبناء وحدات تحكم Kubernetes المخصصة التي تسمح لمستخدمي Kubernetes بتوفير موارد AWS مثل قواعد البيانات أو قوائم انتظار الرسائل ببساطة عن طريق استخدام Kubernetes API. يسهّل SageMaker ACK Operators الأمر على مطوري ML وعلماء البيانات الذين يستخدمون Kubernetes كطائرة تحكم لتدريب نماذج ML وضبطها ونشرها في SageMaker دون تسجيل الدخول إلى وحدة تحكم SageMaker.
- • مكونات SageMaker لخطوط أنابيب Kubeflow، والتي تسمح لك بدمج SageMaker مع قابلية النقل والتنسيق لخطوط أنابيب Kubeflow. باستخدام مكونات SageMaker ، يتم تشغيل كل مهمة في سير عمل خط الأنابيب على SageMaker بدلاً من مجموعة Kubernetes المحلية. يتيح لك ذلك إنشاء ومراقبة تدريب SageMaker الأصلي ، والضبط ، ونشر نقطة النهاية ، ومهام التحويل المجمعة من خطوط أنابيب Kubeflow الخاصة بك ، وبالتالي يسمح لك بنقل الحوسبة الكاملة بما في ذلك مهام معالجة البيانات والتدريب من مجموعة Kubernetes إلى الخدمة المُدارة المُحسّنة للتعلم الآلي من SageMaker.
بدءًا من Kubeflow على AWS v1.6.1 ، تجمع جميع خيارات نشر Kubeflow المتاحة بين خيارات تكامل Amazon SageMaker افتراضيًا على نظام أساسي واحد. هذا يعني أنه يمكنك الآن إرسال وظائف SageMaker باستخدام مشغلي SageMaker ACK من خادم Kubeflow Notebook نفسه عن طريق إرسال مورد SageMaker المخصص أو من خطوة خط أنابيب Kubeflow باستخدام مكونات SageMaker.
يوجد إصداران من مكونات SageMaker - بوتو 3 (AWS SDK for AWS SDK for Python) استنادًا إلى مكونات الإصدار 1 و SageMaker Operator لمكونات الإصدار 8 المستندة إلى K2s (ACK). يدعم الإصدار 2 من مكونات SageMaker الجديد أحدث واجهات برمجة تطبيقات تدريب SageMaker وسنستمر في إضافة المزيد من ميزات SageMaker إلى هذا الإصدار من المكون. ومع ذلك ، لديك المرونة في الجمع بين الإصدار 2 من مكونات Sagemaker للتدريب والإصدار 1 لميزات SageMaker الأخرى مثل ضبط المعلمات الفائقة ومعالجة المهام والاستضافة وغير ذلك الكثير.
التكامل مع بروميثيوس وغرافانا
بروميثيوس عبارة عن أداة تجميع مقاييس مفتوحة المصدر يمكنك تهيئتها للتشغيل على مجموعات Kubernetes. عند التشغيل على مجموعات Kubernetes ، يقوم خادم Prometheus الرئيسي بكشط نقاط نهاية pod بشكل دوري.
تنبعث مكونات Kubeflow ، مثل Kubeflow Pipelines (KFP) و Notebook ، مقاييس بروميثيوس للسماح بمراقبة موارد المكونات مثل عدد التجارب الجارية أو عدد أجهزة الكمبيوتر المحمول.
يمكن تجميع هذه المقاييس بواسطة خادم Prometheus يعمل في مجموعة Kubernetes والاستعلام عنها باستخدام لغة Prometheus Query (PromQL). لمزيد من التفاصيل حول الميزات التي يدعمها Prometheus ، تحقق من وثائق بروميثيوس.
يوفر توزيع Kubeflow على AWS الدعم للتكامل مع خدمات AWS التالية المدارة:
- أمازون بروميثيوس المدار (AMP) وهو ملف محب العمل- خدمة مراقبة متوافقة للبنية التحتية للحاويات ومقاييس التطبيق للحاويات التي تسهل على العملاء مراقبة بيئات الحاويات بأمان على نطاق واسع. باستخدام AMP ، يمكنك تصور وتحليل وإنذار المقاييس والسجلات والتتبعات التي تم جمعها من مصادر بيانات متعددة في نظام الملاحظة الخاص بك ، بما في ذلك AWS وموردي البرامج المستقلين التابعين لجهات خارجية والموارد الأخرى عبر محفظة تكنولوجيا المعلومات الخاصة بك.
- Amazon Managed Grafana ، خدمة تصوير بيانات مُدارة وآمنة بالكامل تستند إلى المصدر المفتوح جرافانا المشروع ، الذي يمكّن العملاء من الاستعلام عن المقاييس التشغيلية والسجلات والتتبعات لتطبيقاتهم من مصادر بيانات متعددة وربطها وتصورها على الفور. تقوم Amazon Managed Grafana بإلغاء تحميل الإدارة التشغيلية لـ Grafana عن طريق توسيع البنية التحتية للحوسبة وقاعدة البيانات تلقائيًا مع زيادة متطلبات الاستخدام ، مع تحديثات الإصدار الآلية وتصحيح الأمان.
يوفر توزيع Kubeflow على AWS الدعم لتكامل Amazon Managed Service for Prometheus و Amazon Managed Grafana لتسهيل استيعاب مقاييس Prometheus وتصورها بأمان على نطاق واسع.
يتم استيعاب المقاييس التالية ويمكن تصورها:
- المقاييس المنبعثة من مكونات Kubeflow مثل Kubeflow Pipelines وخادم Notebook
- Kubeflow مقاييس مستوى التحكم
لتكوين Amazon Managed Service for Prometheus و Amazon Managed Grafana لمجموعة Kubeflow ، يرجى الرجوع إلى استخدم Prometheus و Amazon Managed Service for Prometheus و Amazon Managed Grafana لمراقبة المقاييس باستخدام Kubeflow على AWS.
حل نظرة عامة
في حالة الاستخدام هذه ، نستخدم نشر Kubeflow vanilla باستخدام خيار تثبيت Terraform. عند اكتمال التثبيت ، نقوم بتسجيل الدخول إلى لوحة معلومات Kubeflow. من لوحة القيادة ، نقوم بتدوير خادم دفتر ملاحظات Kubeflow Jupyter لبناء خط أنابيب Kubeflow يستخدم SageMaker لتشغيل التدريب الموزع لنموذج تصنيف الصور ونقطة نهاية SageMaker لنشر النموذج.
المتطلبات الأساسية المسبقة
تأكد من تلبية المتطلبات الأساسية التالية:
- انت تملك حساب AWS.
- تأكد من أنك في
us-west-2منطقة لتشغيل هذا المثال. - استخدم Google Chrome للتفاعل مع وحدة تحكم إدارة AWS وكوبفلو.
- تأكد من أن حسابك يحتوي على حد نوع مورد تدريب SageMaker لـ ml.p3.2xlarge إلى 2 باستخدام وحدة التحكم في حصص الخدمة.
- اختياريا ، يمكنك استخدام سحابة AWS 9، بيئة تطوير متكاملة قائمة على السحابة (IDE) تتيح إكمال جميع الأعمال من متصفح الويب الخاص بك. للحصول على تعليمات الإعداد ، ارجع إلى إعداد Cloud9 IDE. حدد Ubuntu Server 18.04 كمنصة في إعدادات AWS Cloud9.
 ثم من بيئة AWS Cloud9 الخاصة بك ، اختر علامة الجمع وافتح محطة جديدة.
ثم من بيئة AWS Cloud9 الخاصة بك ، اختر علامة الجمع وافتح محطة جديدة.
يمكنك أيضًا تكوين ملف واجهة سطر الأوامر AWS (AWS CLI) الملف الشخصي. للقيام بذلك ، تحتاج إلى معرف مفتاح الوصول ومفتاح الوصول السري لملف إدارة الهوية والوصول AWS (انا) المستخدم حساب بامتيازات إدارية (أرفق السياسة المدارة الحالية) والوصول الآلي. انظر الكود التالي:
تحقق من الأذونات التي ستستخدمها cloud9 للاتصال بموارد AWS.
تحقق من الإخراج أدناه أنك ترى مستخدم المسؤول الذي قمت بتكوينه في ملف تعريف AWS CLI. في هذا المثال هو "kubeflow-user"
قم بتثبيت Amazon EKS و Kubeflow على AWS
لتثبيت Amazon EKS و Kubeflow على AWS ، أكمل الخطوات التالية:
- قم بإعداد بيئتك لنشر Kubeflow على AWS:
- انشر إصدار Vanilla من Kubeflow على AWS وموارد AWS ذات الصلة مثل EKS باستخدام Terraform. يرجى ملاحظة أن وحدات تخزين EBS المستخدمة في مجموعة عقد EKS غير مشفرة افتراضيًا:
قم بإعداد أذونات Kubeflow
- إضافة أذونات إلى جراب Notebook وجراب مكون Pipeline لإجراء مكالمات SageMaker و S3 و IAM api باستخدام
kubeflow_iam_permissions.shالنصي. - قم بإنشاء دور تنفيذ SageMaker لتمكين وظيفة تدريب SageMaker من الوصول إلى مجموعة بيانات التدريب من خدمة S3 باستخدام
sagemaker_role.shالنصي.
الوصول إلى لوحة القيادة Kubeflow
للوصول إلى لوحة معلومات Kubeflow ، أكمل الخطوات التالية:
- يمكنك تشغيل لوحة معلومات Kubeflow محليًا في بيئة Cloud9 دون تعريض عناوين URL الخاصة بك إلى الإنترنت العام عن طريق تشغيل الأوامر أدناه.
- اختار معاينة التطبيق قيد التشغيل.
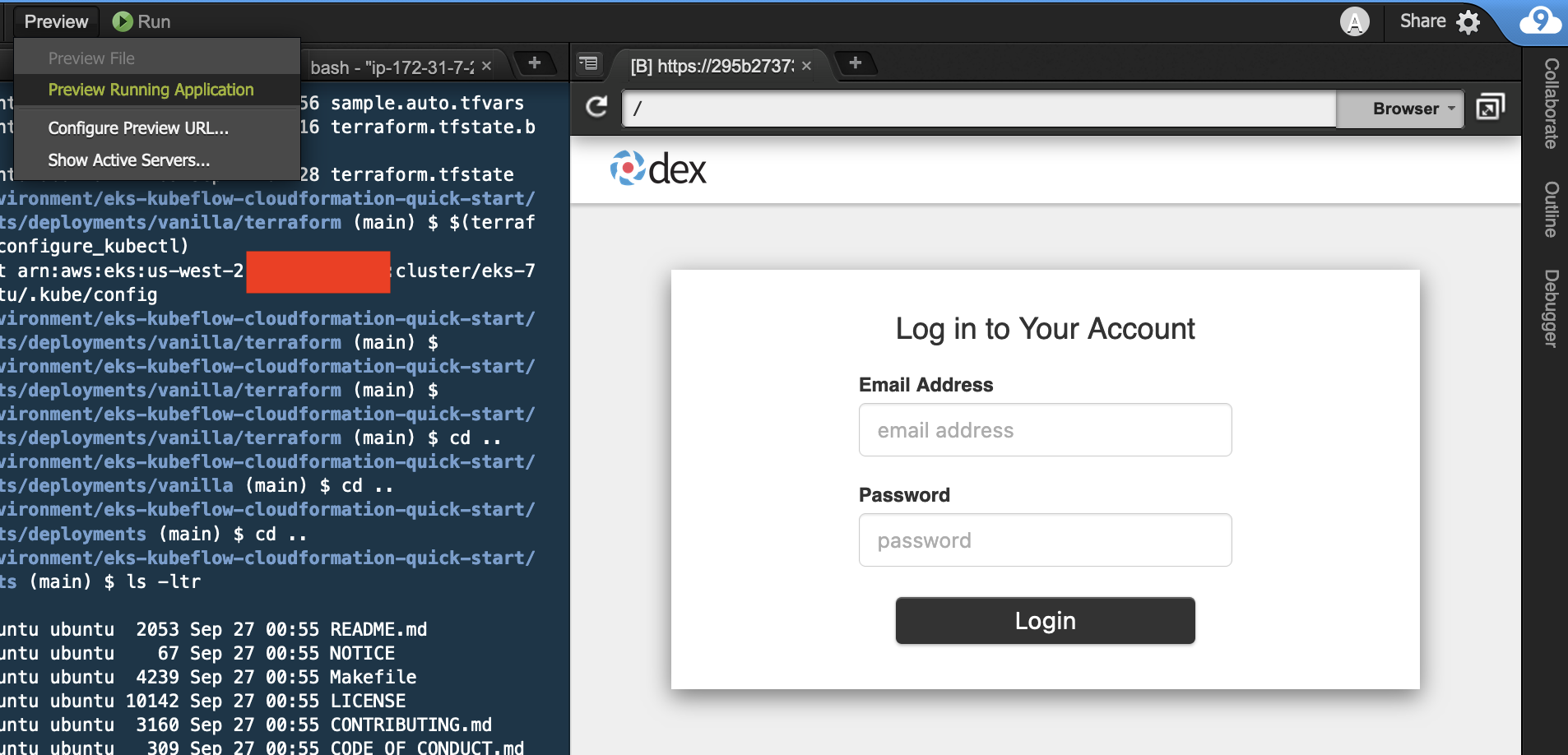
- اختر الرمز الموجود في زاوية لوحة معلومات Kubeflow لفتحه كعلامة تبويب منفصلة في Chrome.
- أدخل بيانات الاعتماد الافتراضية (
user@example.com/12341234) لتسجيل الدخول إلى لوحة القيادة Kubeflow.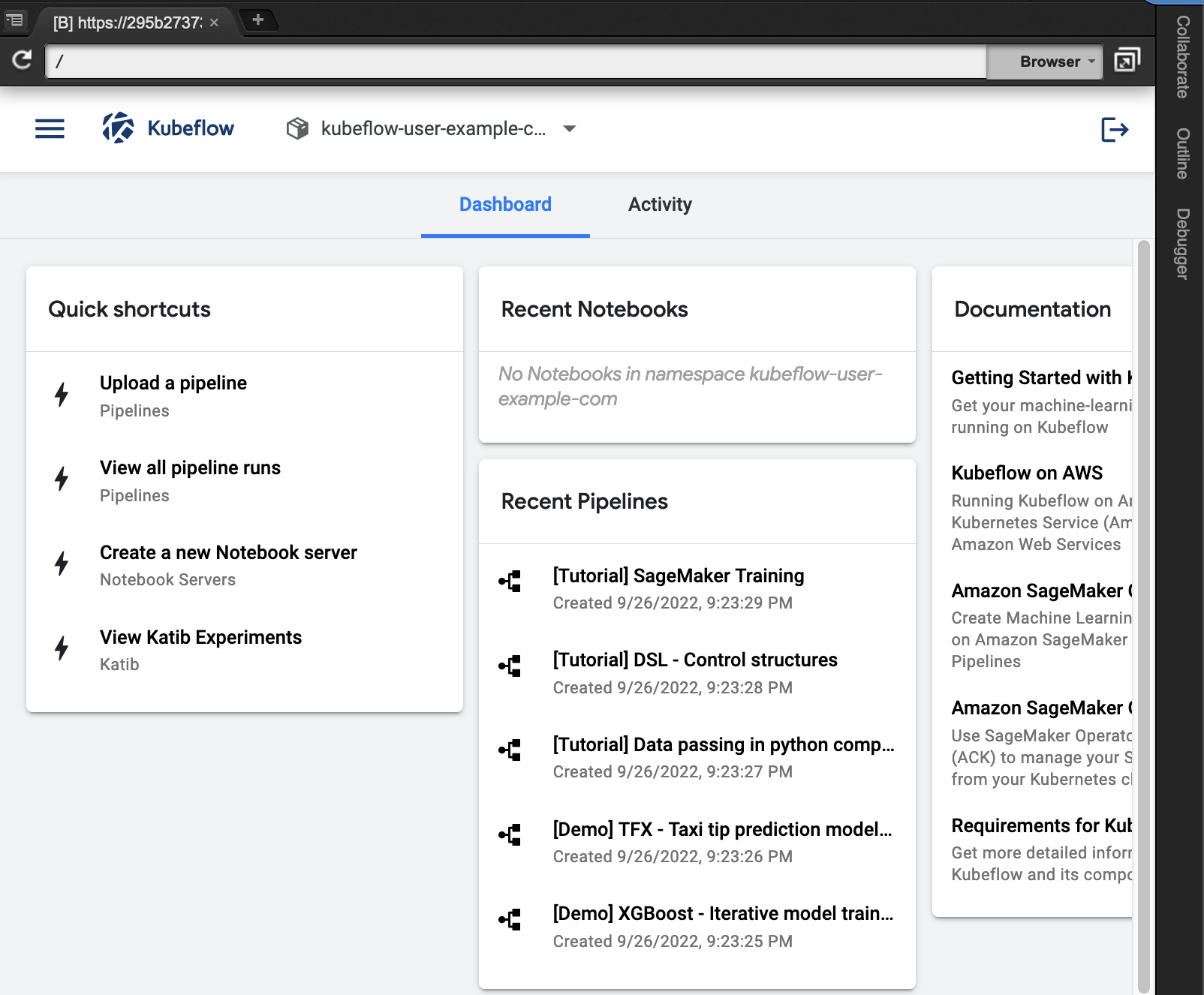
قم بإعداد Kubeflow على بيئة AWS
بمجرد تسجيل الدخول إلى لوحة معلومات Kubeflow ، تأكد من أن لديك مساحة الاسم الصحيحة (kubeflow-user-example-com) المختار. أكمل الخطوات التالية لإعداد Kubeflow على بيئة AWS:
- في لوحة معلومات Kubeflow ، اختر دفاتر في جزء التنقل.
- اختار مفكرة جديدة.
- في حالة الاسم، أدخل
aws-nb. - في حالة صورة Jupyter Docketاختر الصورة
jupyter-pytorch:1.12.0-cpu-py38-ubuntu20.04-ec2-2022-09-20(الأحدث المتاحjupyter-pytorchصورة DLC). - في حالة وحدة المعالجة المركزية:، أدخل
1. - في حالة مكبر الصوت : يدعم، مع دعم ميكروفون مدمج لمنع الضوضاء
، أدخل
5. - في حالة وحدات معالجة الرسومات، اترك بصيغة بدون اضاءة.
- لا تقم بإجراء أي تغييرات على مساحة العمل و أحجام البيانات أقسام.
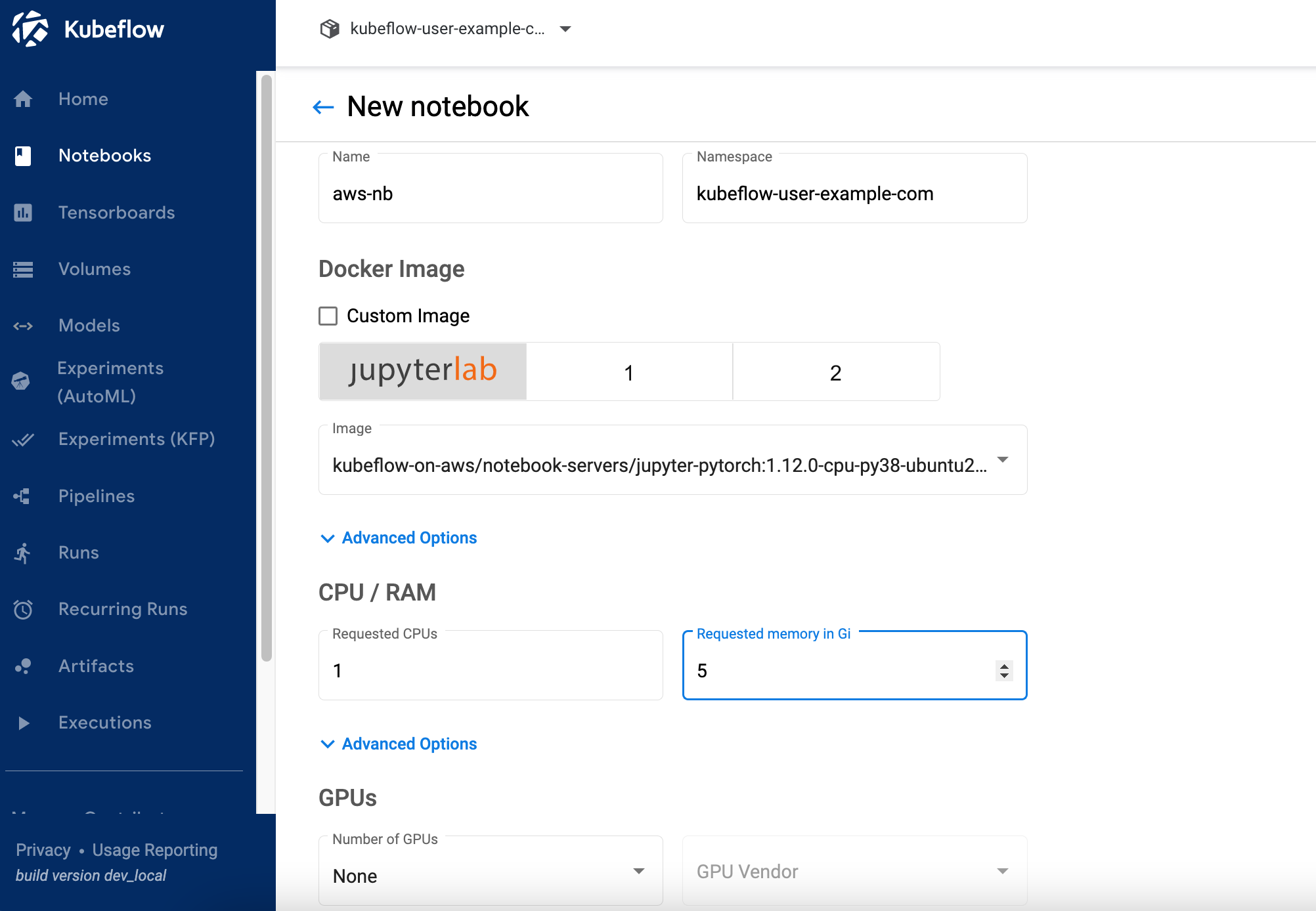
- أختار السماح بالوصول إلى خطوط أنابيب Kubeflow في ال تكوينات قسم واختر تشغيل.
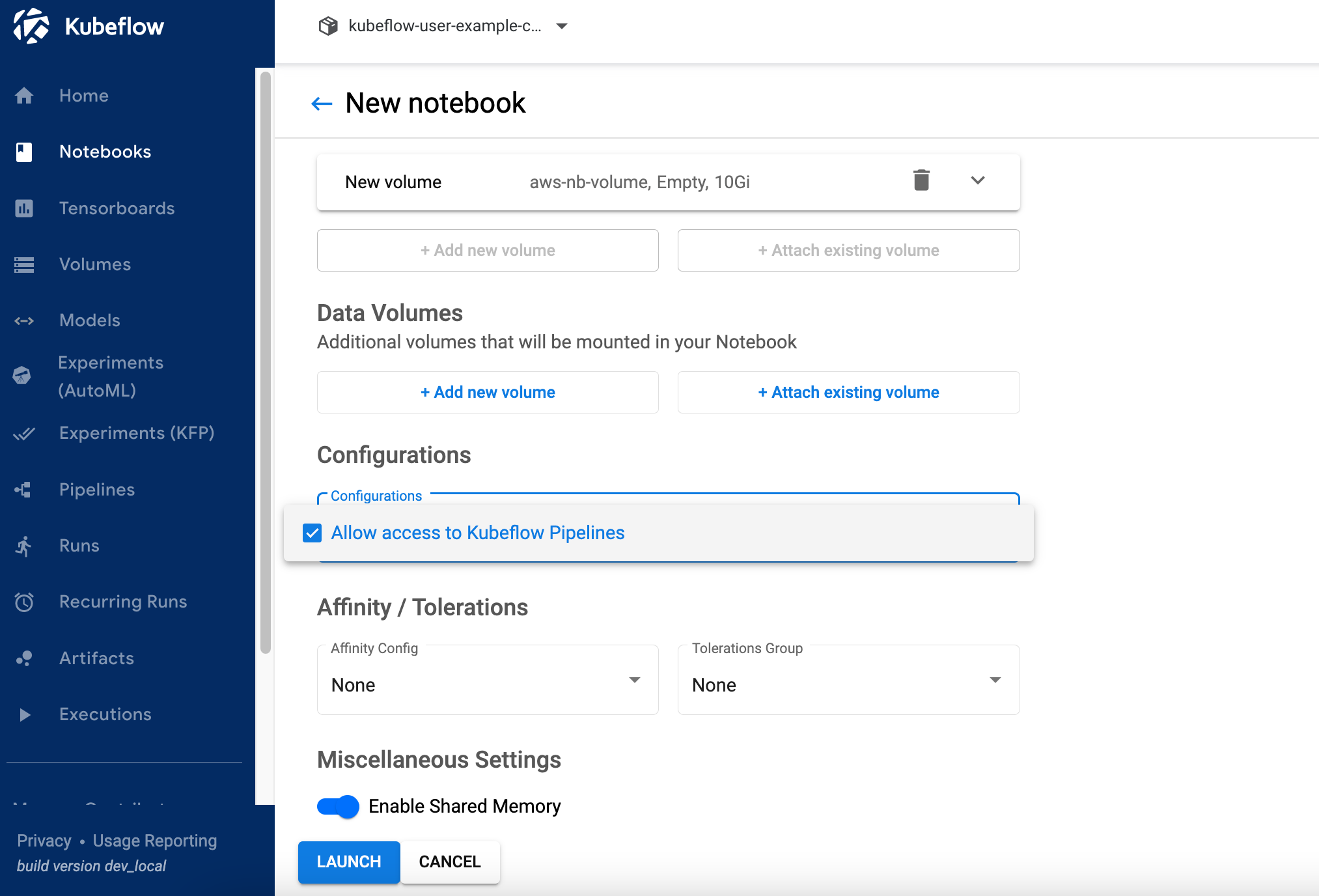
- تحقق من أن دفتر الملاحظات الخاص بك قد تم إنشاؤه بنجاح (قد يستغرق دقيقتين).

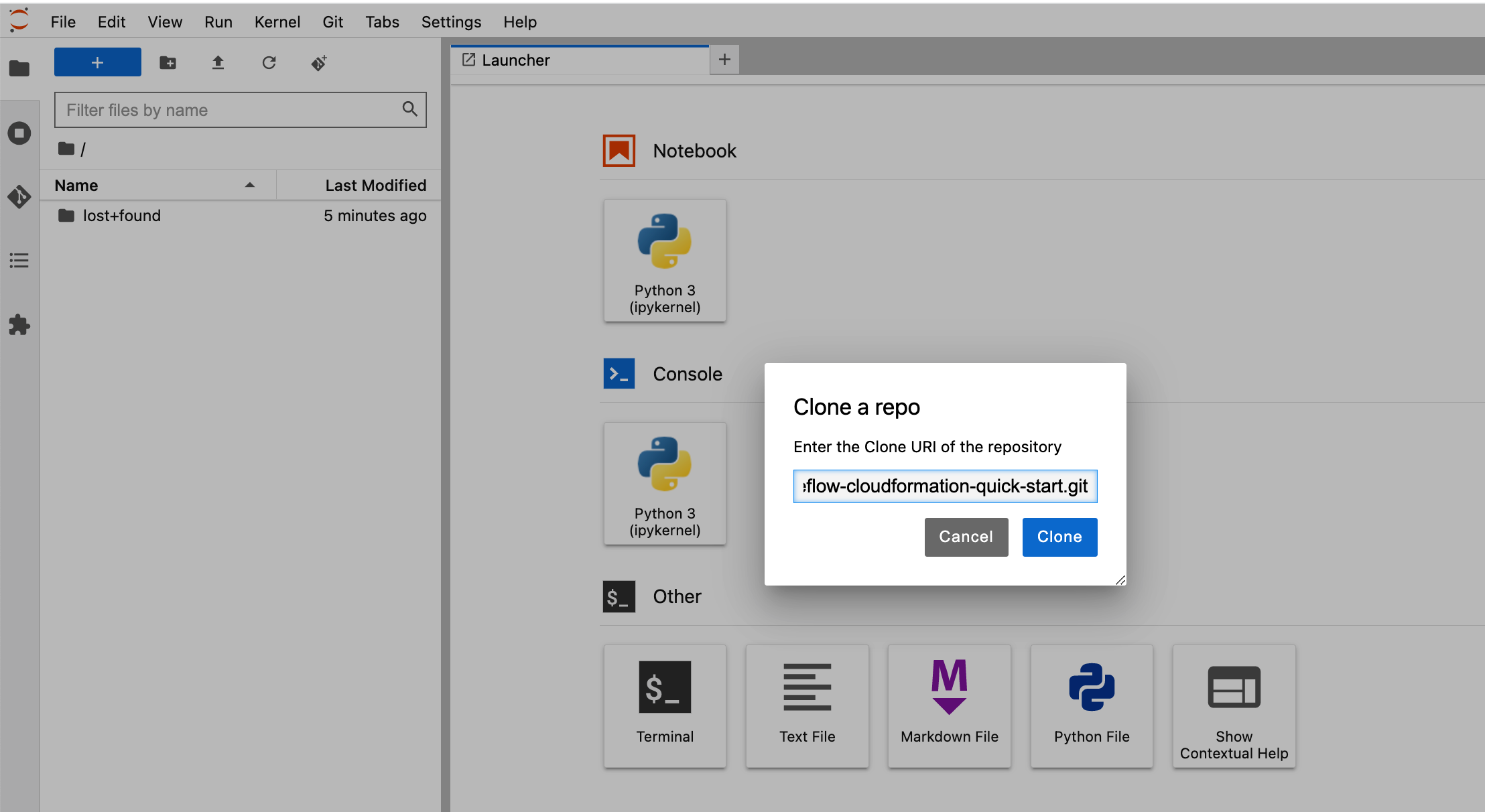
- اختار التواصل لتسجيل الدخول إلى JupyterLab.
- استنساخ الريبو عن طريق الدخول
https://github.com/aws-samples/eks-kubeflow-cloudformation-quick-start.gitفي ال استنساخ الريبو الميدان. - اختار استنساخ.
قم بتشغيل مثال تدريب موزع
بعد إعداد دفتر Jupyter ، يمكنك تشغيل العرض التوضيحي بأكمله باستخدام الخطوات عالية المستوى التالية من المجلد eks-kubeflow-cloudformation-quick-start/workshop/pytorch-distributed-training في المستودع المستنسخ:
- قم بتشغيل البرنامج النصي التدريبي PyTorch Distributed Data Parallel Data Parallel (DDP) - الرجوع إلى البرنامج النصي للتدريب PyTorch DDP
cifar10-distributed-gpu-final.py، والذي يتضمن عينة من الشبكة العصبية التلافيفية والمنطق لتوزيع التدريب على مجموعة وحدة المعالجة المركزية ووحدة معالجة الرسومات متعددة العقد. - قم بإنشاء خط أنابيب Kubeflow - قم بتشغيل دفتر الملاحظات
STEP1.0_create_pipeline_k8s_sagemaker.ipynbلإنشاء خط أنابيب يعمل على تشغيل النماذج ونشرها على SageMaker. تأكد من تثبيت مكتبة SageMaker كجزء من خلية دفتر الملاحظات الأولى وأعد تشغيل kernel قبل تشغيل باقي خلايا دفتر الملاحظات. - قم باستدعاء نقطة نهاية SageMaker - قم بتشغيل دفتر الملاحظات
STEP1.1_invoke_sagemaker_endpoint.ipynbلاستدعاء واختبار نقطة نهاية استدلال نموذج SageMaker التي تم إنشاؤها في دفتر الملاحظات السابق.
في الأقسام التالية ، نناقش كل خطوة من هذه الخطوات بالتفصيل.
قم بتشغيل البرنامج النصي للتدريب PyTorch DDP
كجزء من التدريب الموزع ، نقوم بتدريب نموذج تصنيف تم إنشاؤه بواسطة شبكة عصبية تلافيفية بسيطة تعمل على مجموعة بيانات CIFAR10. نص التدريب cifar10-distributed-gpu-final.py يحتوي فقط على مكتبات مفتوحة المصدر ومتوافق للتشغيل على مجموعات تدريب Kubernetes و SageMaker على أجهزة GPU أو مثيلات وحدة المعالجة المركزية. دعونا نلقي نظرة على بعض الجوانب المهمة في البرنامج النصي للتدريب قبل تشغيل أمثلة دفاتر الملاحظات الخاصة بنا.
نستخدم torch.distributed الوحدة النمطية ، التي تحتوي على دعم PyTorch وأساسيات الاتصال للتوازي متعدد العمليات عبر العقد في الكتلة:
نقوم بإنشاء نموذج تصنيف بسيط للصور باستخدام مجموعة من الطبقات الالتفافية والتجميعية القصوى والطبقات الخطية التي يتم إنشاء ملف relu يتم تطبيق وظيفة التنشيط في التمرير الأمامي لتدريب النموذج:
إذا كانت مجموعة التدريب تحتوي على وحدات معالجة رسومات (GPU) ، يقوم البرنامج النصي بتشغيل التدريب على أجهزة CUDA ويحمل متغير الجهاز جهاز CUDA الافتراضي:
قبل تشغيل التدريب الموزع باستخدام PyTorch DistributedDataParallel لتشغيل المعالجة الموزعة على عقد متعددة ، تحتاج إلى تهيئة البيئة الموزعة عن طريق الاتصال init_process_group. تتم تهيئة هذا على كل جهاز من مجموعة التدريب.
نقوم بإنشاء مثيل لنموذج المصنف ونسخ النموذج إلى الجهاز المستهدف. إذا تم تمكين التدريب الموزع للتشغيل على عقد متعددة ، فإن ملف DistributedDataParallel يتم استخدام class ككائن التفاف حول كائن النموذج ، مما يسمح بالتدريب الموزع المتزامن عبر أجهزة متعددة. يتم تقسيم بيانات الإدخال على بُعد الدُفعة ويتم وضع نسخة طبق الأصل من النموذج على كل جهاز وكل جهاز. انظر الكود التالي:
قم بإنشاء خط أنابيب Kubeflow
دفتر الملاحظات يستخدم SDK Kubeflow خطوط الأنابيب ومجموعة حزم Python المقدمة لتحديد وتشغيل خطوط تدفق عمل ML. كجزء من حزمة SDK هذه ، نستخدم مصمم حزمة اللغة الخاصة بالمجال (DSL) dsl.pipeline، الذي يزين دوال بايثون لإرجاع خط أنابيب.
يستخدم خط أنابيب Kubeflow مكون SageMaker V2 لتقديم التدريب إلى SageMaker باستخدام SageMaker ACK Operators. يستخدم إنشاء نموذج SageMaker ونشره مكون SageMaker V1 ، وهي مكونات SageMaker قائمة على Boto3. نستخدم مزيجًا من كلا المكونين في هذا المثال لإظهار المرونة التي لديك في الاختيار.
- قم بتحميل مكونات SageMaker باستخدام الكود التالي:
في الكود التالي ، نقوم بإنشاء خط أنابيب Kubeflow حيث نقوم بتشغيل تدريب SageMaker الموزع باستخدام اثنين
ml.p3.2xlargeالأمثلة:بعد تحديد خط الأنابيب ، يمكنك تجميع خط الأنابيب لمواصفات Argo YAML باستخدام Kubeflow Pipelines SDK's
kfp.compilerحزمة. يمكنك تشغيل خط الأنابيب هذا باستخدام عميل Kubeflow Pipelines SDK ، الذي يستدعي نقطة نهاية خدمة خطوط الأنابيب ويمرر رؤوس المصادقة المناسبة مباشرة من دفتر الملاحظات. انظر الكود التالي: - اختيار تشغيل التفاصيل الارتباط الموجود أسفل الخلية الأخيرة لعرض خط أنابيب Kubeflow. تُظهر لقطة الشاشة التالية تفاصيل خط الأنابيب الخاصة بنا لمكون التدريب والنشر SageMaker.

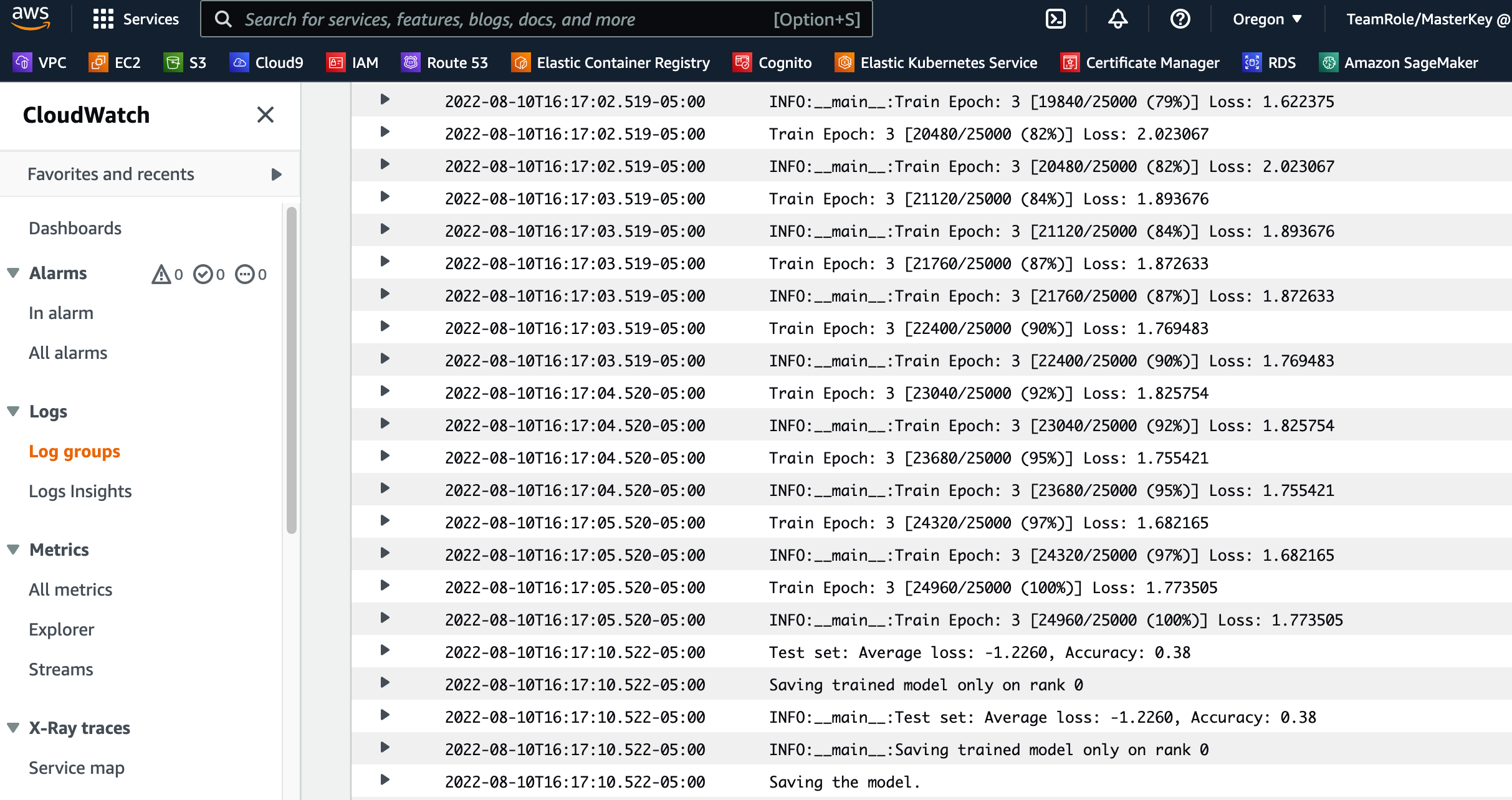
- اختر خطوة وظيفة التدريب وعلى سجلات علامة التبويب ، اختر ارتباط سجلات CloudWatch للوصول إلى سجلات SageMaker.
تُظهر لقطة الشاشة التالية سجلات CloudWatch لكل من مثيلات ml.p3.2xlarge.
- اختر أيًا من المجموعات لمشاهدة السجلات.
- التقط نقطة نهاية SageMaker باختيار ملف Sagemaker - نشر النموذج الخطوة ونسخ ملف
endpoint_nameقيمة الأداة الناتجة.
قم باستدعاء نقطة نهاية SageMaker
دفتر مذكرات STEP1.1_invoke_sagemaker_endpoint.ipynb استدعاء نقطة نهاية استنتاج SageMaker التي تم إنشاؤها في الخطوة السابقة. تأكد من تحديث اسم نقطة النهاية:
تنظيف
لتنظيف مواردك ، أكمل الخطوات التالية:
- قم بتشغيل الأوامر التالية في AWS Cloud9 لحذف موارد AWS:
- حذف دور IAM "
sagemakerrole"باستخدام أمر AWS CLI التالي: - احذف نقطة نهاية SageMaker باستخدام أمر AWS CLI التالي:
نبذة عامة
في هذا المنشور ، سلطنا الضوء على القيمة التي يوفرها Kubeflow على AWS 1.6.1 من خلال تكامل الخدمة الأصلية التي تديرها AWS لتلبية الحاجة إلى حالات استخدام الذكاء الاصطناعي والتعلم الآلي على مستوى المؤسسة. يمكنك الاختيار من بين العديد من خيارات النشر لتثبيت Kubeflow على AWS مع تكامل خدمات متنوعة باستخدام Terraform أو Kustomize أو Helm. أظهرت حالة الاستخدام في هذا المنشور تكامل Kubeflow مع SageMaker الذي يستخدم مجموعة تدريب مُدارة من SageMaker لتشغيل تدريب موزع لنموذج تصنيف الصور ونقطة نهاية SageMaker لنشر النموذج.
لقد وفرنا أيضًا ملف مثال على خط الأنابيب يستخدم أحدث مكونات SageMaker ؛ يمكنك تشغيل هذا مباشرة من لوحة القيادة Kubeflow. يتطلب خط الأنابيب هذا بيانات Amazon S3 و دور IAM لتنفيذ SageMaker كمدخلات مطلوبة.
لبدء استخدام Kubeflow على AWS ، ارجع إلى خيارات النشر المتكاملة المتاحة في AWS في Kubeflow على AWS. يمكنك متابعة مستودع AWS Labs لتتبع جميع مساهمات AWS في Kubeflow. يمكنك أيضًا أن تجدنا على قناة Kubeflow #AWS Slack؛ ستساعدنا ملاحظاتك هناك في تحديد أولويات الميزات التالية للمساهمة في مشروع Kubeflow.
عن المؤلفين
 كانوالجيت خورمي هو مهندس حلول أول في Amazon Web Services. إنه يعمل مع عملاء AWS لتقديم التوجيه والمساعدة الفنية لمساعدتهم على تحسين قيمة حلولهم عند استخدام AWS. Kanwaljit متخصص في مساعدة العملاء في استخدام الحاويات وتطبيقات التعلم الآلي.
كانوالجيت خورمي هو مهندس حلول أول في Amazon Web Services. إنه يعمل مع عملاء AWS لتقديم التوجيه والمساعدة الفنية لمساعدتهم على تحسين قيمة حلولهم عند استخدام AWS. Kanwaljit متخصص في مساعدة العملاء في استخدام الحاويات وتطبيقات التعلم الآلي.
 كارتيك كالامادي هو مهندس تطوير برمجيات في Amazon AI. يركز حاليًا على مشاريع Kubernetes مفتوحة المصدر للتعلم الآلي مثل Kubeflow و AWS SageMaker Controller لـ k8s. في أوقات فراغي ، أحب لعب ألعاب الكمبيوتر والعبث بالواقع الافتراضي باستخدام محرك الوحدة.
كارتيك كالامادي هو مهندس تطوير برمجيات في Amazon AI. يركز حاليًا على مشاريع Kubernetes مفتوحة المصدر للتعلم الآلي مثل Kubeflow و AWS SageMaker Controller لـ k8s. في أوقات فراغي ، أحب لعب ألعاب الكمبيوتر والعبث بالواقع الافتراضي باستخدام محرك الوحدة.
 راهول خارس هو مهندس تطوير برمجيات في Amazon Web Services. يركز عمله على دمج خدمات AWS مع منصات ML Ops المعبأة في حاويات مفتوحة المصدر لتحسين قابليتها للتوسع والموثوقية والأمان. بالإضافة إلى التركيز على طلبات العملاء للحصول على الميزات ، يستمتع راهول أيضًا بتجربة أحدث التطورات التكنولوجية في هذا المجال.
راهول خارس هو مهندس تطوير برمجيات في Amazon Web Services. يركز عمله على دمج خدمات AWS مع منصات ML Ops المعبأة في حاويات مفتوحة المصدر لتحسين قابليتها للتوسع والموثوقية والأمان. بالإضافة إلى التركيز على طلبات العملاء للحصول على الميزات ، يستمتع راهول أيضًا بتجربة أحدث التطورات التكنولوجية في هذا المجال.
- كوينسمارت. أفضل بورصة للبيتكوين والعملات المشفرة في أوروبا.انقر هنا لمعرفة ذلك
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/enabling-hybrid-ml-workflows-on-amazon-eks-and-amazon-sagemaker-with-one-click-kubeflow-on-aws-deployment/

