استعدادًا للألعاب الأولمبية القادمة ، طورت شركة Intel® ، وهي شركة أمريكية متعددة الجنسيات وواحدة من أكبر شركات التكنولوجيا في العالم ، مفهومًا حول 3D Athlete Tracking (3DAT). 3DAT هو حل للتعلم الآلي (ML) لإنشاء نماذج رقمية في الوقت الفعلي للرياضيين في المنافسة من أجل زيادة مشاركة المعجبين أثناء عمليات البث. كانت شركة Intel تتطلع إلى الاستفادة من هذه التقنية بغرض تدريب نخبة الرياضيين وتدريبهم.
أثبتت طرق رؤية الكمبيوتر الكلاسيكية لإعادة بناء الوضع ثلاثي الأبعاد أنها مرهقة لمعظم العلماء ، نظرًا لأن هذه النماذج تعتمد في الغالب على تضمين أجهزة استشعار إضافية على رياضي وعدم وجود ملصقات ونماذج ثلاثية الأبعاد. على الرغم من أنه يمكننا وضع آليات جمع بيانات سلسة في مكانها باستخدام الهواتف المحمولة العادية ، إلا أن تطوير نماذج ثلاثية الأبعاد باستخدام بيانات الفيديو ثنائية الأبعاد يمثل تحديًا ، نظرًا لنقص عمق المعلومات في مقاطع الفيديو ثنائية الأبعاد. دخل فريق Intel 3DAT في شراكة مع مختبر أمازون ML Solutions (MLSL) لتطوير تقنيات تقدير الوضع البشري ثلاثي الأبعاد على مقاطع فيديو ثنائية الأبعاد من أجل إنشاء حل خفيف الوزن للمدربين لاستخراج الميكانيكا الحيوية ومقاييس أخرى لأداء الرياضيين.
جمع هذا التعاون الفريد تاريخ إنتل الغني في الابتكار وخبرة رؤية الكمبيوتر في Amazon ML Solution Lab لتطوير خط أنابيب لتقدير الوضع ثلاثي الأبعاد متعدد الأشخاص باستخدام مقاطع فيديو ثنائية الأبعاد من الهواتف المحمولة القياسية كمدخلات ، مع أمازون ساجميكر ستوديو أجهزة الكمبيوتر المحمولة (SM Studio) كبيئة تطوير.
يقول جوناثان لي ، مدير الأداء الرياضي لشركة Intel Technology Group ، "قام فريق MLSL بعمل رائع بالاستماع إلى متطلباتنا واقتراح حل يلبي احتياجات عملائنا. تجاوز الفريق توقعاتنا ، حيث طور خط أنابيب لتقدير الوضع ثلاثي الأبعاد باستخدام مقاطع فيديو ثنائية الأبعاد تم التقاطها بالهواتف المحمولة في أسبوعين فقط. من خلال توحيد عبء عمل ML الخاص بنا على Amazon SageMaker ، حققنا متوسط دقة ملحوظة بنسبة 3٪ في نماذجنا ".
يناقش هذا المنشور كيف استخدمنا نماذج تقدير الوضع ثلاثي الأبعاد وقمنا بإنشاء مخرجات ثلاثية الأبعاد على بيانات فيديو ثنائية الأبعاد تم جمعها من أشتون إيتون ، وهو لاعب عشاري وحاصل على ميدالية ذهبية أولمبية مرتين من الولايات المتحدة ، باستخدام زوايا مختلفة. كما يقدم تقنيتين لرؤية الكمبيوتر لمحاذاة مقاطع الفيديو الملتقطة من زوايا مختلفة ، مما يسمح للمدربين باستخدام مجموعة فريدة من الإحداثيات ثلاثية الأبعاد عبر الجري.
التحديات
تستخدم تقنيات تقدير الوضع البشري رؤية الكمبيوتر بهدف توفير هيكل عظمي رسومي لشخص تم اكتشافه في مشهد ما. وهي تشمل إحداثيات نقاط رئيسية محددة مسبقًا تتوافق مع مفاصل الإنسان ، مثل الذراعين والرقبة والوركين. تُستخدم هذه الإحداثيات لالتقاط اتجاه الجسم لمزيد من التحليل ، مثل تتبع الوضع وتحليل الموقف والتقييم اللاحق. مكنت التطورات الحديثة في رؤية الكمبيوتر والتعلم العميق العلماء من استكشاف تقدير الوضع في مساحة ثلاثية الأبعاد ، حيث يوفر المحور Z رؤى إضافية مقارنة بتقدير الوضع ثنائي الأبعاد. يمكن استخدام هذه الأفكار الإضافية للحصول على تصور وتحليل أكثر شمولاً. ومع ذلك ، فإن بناء نموذج تقدير الوضع ثلاثي الأبعاد من البداية يمثل تحديًا لأنه يتطلب بيانات التصوير جنبًا إلى جنب مع الملصقات ثلاثية الأبعاد. لذلك ، يستخدم العديد من الباحثين نماذج تقدير الوضع ثلاثية الأبعاد التي تم اختبارها مسبقًا.
خط أنابيب معالجة البيانات
لقد قمنا بتصميم خط أنابيب لتقدير الوضع ثلاثي الأبعاد من طرف إلى طرف كما هو موضح في الرسم البياني التالي باستخدام SM Studio ، والذي تضمن عدة مكونات:
- خدمة تخزين أمازون البسيطة (Amazon S3) حاوية لاستضافة بيانات الفيديو
- وحدة استخراج الإطار لتحويل بيانات الفيديو إلى صور ثابتة
- وحدات الكشف عن الأجسام لاكتشاف الصناديق المحيطة للأشخاص في كل إطار
- 2D تشكل تقدير لأغراض التقييم في المستقبل
- وحدة تقدير الوضع ثلاثي الأبعاد لإنشاء إحداثيات ثلاثية الأبعاد لكل شخص في كل إطار
- وحدات التقييم والتصور
![]()
![]()
يقدم SM Studio مجموعة واسعة من الميزات التي تسهل عملية التطوير ، بما في ذلك سهولة الوصول إلى البيانات في Amazon S3 ، وتوافر إمكانية الحوسبة ، وتوافر البرامج والمكتبة ، وتجربة تطوير متكاملة (IDE) لتطبيقات ML.
أولاً ، قرأنا بيانات الفيديو من حاوية S3 واستخرجنا الإطارات ثنائية الأبعاد بتنسيق رسومات الشبكة المحمولة (PNG) لتطوير مستوى الإطار. استخدمنا اكتشاف كائن YOLOv2 لإنشاء مربع محيط لكل شخص تم اكتشافه في إطار. للمزيد من المعلومات، راجع وقت التدريب المعياري لأجهزة الكشف المستندة إلى شبكة CNN باستخدام Apache MXNet.
بعد ذلك ، قمنا بتمرير الإطارات ومعلومات الصندوق المحيط المقابلة إلى نموذج تقدير الوضع ثلاثي الأبعاد لإنشاء النقاط الرئيسية للتقييم والتصور. طبقنا تقنية تقدير الوضع ثنائي الأبعاد على الإطارات ، وقمنا بإنشاء النقاط الرئيسية لكل إطار للتطوير والتقييم. تناقش الأقسام التالية تفاصيل كل وحدة في خط الأنابيب ثلاثي الأبعاد.
معالجة البيانات
كانت الخطوة الأولى هي استخراج الإطارات من مقطع فيديو معين باستخدام OpenCV كما هو موضح في الشكل التالي. استخدمنا عدادين لتتبع الوقت وعدد الإطارات على التوالي ، لأنه تم التقاط مقاطع الفيديو بمعدلات إطارات مختلفة في الثانية (FPS). ثم قمنا بتخزين تسلسل الصور على هيئةvideo_name + second_count + frame_countبتنسيق PNG.
![]()
الكشف عن الكائن (الشخص)
استخدمنا نماذج YOLOv3 التي تم اختبارها مسبقًا استنادًا إلى مجموعة بيانات Pascal VOC لاكتشاف الأشخاص في الإطارات. لمزيد من المعلومات، راجع نشر نماذج مخصصة تم إنشاؤها باستخدام Gluon و Apache MXNet على Amazon SageMaker. أنتجت خوارزمية YOLOv3 المربعات المحيطة الموضحة في الرسوم المتحركة التالية (تم تغيير حجم الصور الأصلية إلى 910 × 512 بكسل).
![]()
قمنا بتخزين إحداثيات المربع المحيط في ملف CSV ، حيث أشارت الصفوف إلى فهرس الإطار ومعلومات الصندوق المحيط كقائمة ودرجات الثقة الخاصة بهم.
تقدير الوضع ثلاثي الأبعاد
اخترنا ResNet-18 V1b كنموذج تقدير الوضع الذي تم اختباره مسبقًا ، والذي يأخذ في الاعتبار استراتيجية من أعلى إلى أسفل لتقدير الأوضاع البشرية داخل إخراج الصناديق المحيطة بواسطة نموذج اكتشاف الكائن. قمنا كذلك بإعادة ضبط فئات الكاشف لتشمل البشر بحيث يمكن إجراء عملية الكبت غير القصوى (NMS) بشكل أسرع. تم تطبيق شبكة Simple Pose للتنبؤ بخرائط الحرارة للنقاط الرئيسية (كما في الرسم المتحرك التالي) ، وتم تعيين أعلى القيم في خرائط الحرارة إلى الإحداثيات الموجودة في الصور الأصلية.
![]()
تقدير الوضع ثلاثي الأبعاد
لقد استخدمنا خوارزمية تقدير الوضع ثلاثي الأبعاد الأكثر حداثة والتي تشتمل على طريقة من أعلى إلى أسفل مع مراعاة مسافة الكاميرا لأشخاص متعددين لكل إطار RGB يشار إليه باسم 3DMPPE (Moon et al.). تتكون هذه الخوارزمية من مرحلتين رئيسيتين:
- روت نت - تقدير الإحداثيات المتمحورة حول الكاميرا لجذر الشخص في إطار اقتصاص
- بوسنت - يستخدم نهجًا من أعلى إلى أسفل للتنبؤ بالإحداثيات النسبية للوضع ثلاثي الأبعاد في الصورة التي تم اقتصاصها
بعد ذلك ، استخدمنا معلومات الصندوق المحيط لعرض الإحداثيات ثلاثية الأبعاد على المساحة الأصلية. قدمت 3DMPPE نموذجين تم تدريبهما مسبقًا باستخدام مجموعات بيانات Human3 و MuCo36D (لمزيد من المعلومات ، راجع جيثب ريبو) ، والتي تضمنت 17 و 21 نقطة رئيسية على التوالي ، كما هو موضح في الرسوم المتحركة التالية. استخدمنا الإحداثيات ثلاثية الأبعاد التي تنبأ بها النموذجان السابقان لأغراض التصور والتقييم.
![]()
![]()
![]()
التقييم
لتقييم أداء نماذج تقدير الوضع ثنائي الأبعاد وثلاثي الأبعاد ، استخدمنا إحداثيات وضعية ثنائية الأبعاد (س ، ص) وثلاثية الأبعاد (س ، ص ، ض) لكل مفصل تم إنشاؤه لكل إطار في فيديو معين. اختلف عدد النقاط الرئيسية بناءً على مجموعات البيانات ؛ على سبيل المثال ، تتضمن مجموعة بيانات Leeds Sports Pose (LSP) 2 ، في حين أن مجموعة بيانات MPII Human Pose ، وهي معيار حديث لتقييم تقدير الوضعية البشرية المفصلية التي تشير إلى Human3M ، تتضمن 2 نقطة رئيسية. استخدمنا مقياسين شائعين الاستخدام لتقدير الوضع ثنائي الأبعاد وثلاثي الأبعاد ، كما هو موضح في القسم التالي حول التقييم. في تطبيقنا ، اتبع قاموس النقاط الرئيسية الافتراضي لدينا مجموعة بيانات اكتشاف COCO ، والتي تحتوي على 3 نقطة رئيسية (انظر الصورة التالية) ، ويتم تحديد الترتيب على النحو التالي:
KEY POINTS = { 0: "nose", 1: "left_eye", 2: "right_eye", 3: "left_ear", 4: "right_ear", 5: "left_shoulder", 6: "right_shoulder", 7: "left_elbow", 8: "right_elbow", 9: "left_wrist", 10: "right_wrist", 11: "left_hip", 12: "right_hip", 13: "left_knee", 14: "right_knee", 15: "left_ankle", 16: "right_ankle"}
![]()
يعني خطأ موقف مشترك
متوسط الخطأ في موضع المفصل (MPJPE) هو المسافة الإقليدية بين الحقيقة الأرضية والتنبؤ المشترك. نظرًا لأن MPJPE يقيس الخطأ أو مسافة الخسارة ، وتشير القيم المنخفضة إلى دقة أكبر.
نستخدم الكود الزائف التالي:
- دع G تشير
ground_truth_jointوالمعالجة المسبقة G بواسطة:- استبدال الإدخالات الفارغة في G بـ [0,0،2] (0,0,0D) أو [3،XNUMX،XNUMX] (XNUMXD)
- استخدام المصفوفة المنطقية B لتخزين موقع الإدخالات الفارغة
- دع P تشير
predicted_joint matrix، وقم بمحاذاة G و P حسب فهرس الإطار عن طريق إدراج متجه صفري إذا لم يكن لأي إطار نتائج أو لم يتم تسميته - احسب المسافة الإقليدية بين G و P ، ودع D تشير إلى مصفوفة المسافة
- استبدل دi,j مع 0 إذا بi,j
- المتوسط لكل موضع مفصل هو القيمة المتوسطة لكل عمود من Ds,tDi,j N 0
يوضح الشكل التالي مثالاً على خطأ في الفيديو لكل مفصل ، مصفوفة ذات أبعاد m * n ، حيث تشير m إلى عدد الإطارات في الفيديو وتشير n إلى عدد الوصلات (النقاط الرئيسية). تُظهر المصفوفة مثالاً لخريطة حرارية لخطأ كل موضع مفصل على اليسار والمتوسط لكل خطأ موضع مفصل على اليمين.
![]()
يوضح الشكل التالي مثالاً على خطأ في الفيديو لكل مفصل ، مصفوفة ذات أبعاد m * n ، حيث تشير m إلى عدد الإطارات في الفيديو وتشير n إلى عدد الوصلات (النقاط الرئيسية). تُظهر المصفوفة مثالاً لخريطة حرارية لخطأ كل موضع مفصل على اليسار والمتوسط لكل خطأ موضع مفصل على اليمين.
النسبة المئوية للنقاط الرئيسية الصحيحة
تمثل النسبة المئوية للنقاط الرئيسية الصحيحة (PCK) مقياس تقييم الوضع حيث يعتبر المفصل المكتشف صحيحًا إذا كانت المسافة بين المفصل المتوقع والفعلي ضمن عتبة معينة ؛ قد تختلف هذه العتبة ، مما يؤدي إلى عدد قليل من الاختلافات المختلفة للمقاييس. يتم استخدام ثلاثة أشكال مختلفة بشكل شائع:
- PCKh@0.5 ، وهو عندما يتم تحديد العتبة على أنها 0.5 * رابط عظم الرأس
- PCK@0.2 ، عندما تكون المسافة بين المفصل المتوقع والفعلي <0.2 * قطر الجذع
- 150 ملم كعتبة صلبة
في حلنا ، استخدمنا PCKh@0.5 كبيانات XML للحقيقة الأساسية لدينا تحتوي على مربع إحاطة الرأس ، والذي يمكننا استخدامه لحساب ارتباط عظم الرأس. على حد علمنا ، لا توجد حزمة حالية تحتوي على تنفيذ سهل الاستخدام لهذا المقياس ؛ لذلك ، قمنا بتطبيق المقياس داخل الشركة.
كود مزيف
استخدمنا الكود الزائف التالي:
- لنفترض أن G تشير إلى حقيقة الأرض المشتركة والمعالجة المسبقة G من خلال:
- استبدال الإدخالات الفارغة في G بـ [0,0،2] (0,0,0D) أو [3،XNUMX،XNUMX] (XNUMXD)
- استخدام المصفوفة المنطقية B لتخزين موقع الإدخالات الفارغة
- لكل إطار Fi، استخدم bbox Bi= (سدقيقة,yدقيقة,xماكس,yماكس) لحساب وصلة عظم الرأس المقابلة لكل إطار Hi ، حيث Hi= ((xماكس-xدقيقة)2+ (ذماكس-yدقيقة)2)½
- دع P تشير إلى مصفوفة مشتركة متوقعة ومحاذاة G و P حسب مؤشر الإطار ؛ أدخل موترًا صفريًا إذا كان أي إطار مفقودًا
- حساب الخطأ المعياري للعنصر بين G و P ؛ دع E تشير إلى مصفوفة الخطأ ، حيث E.i,j=||Gi,j-Pi,j||
- احسب مصفوفة متدرجة S = H * I ، حيث أمثل مصفوفة هوية بنفس البعد مثل E.
- لتجنب القسمة على 0 ، استبدل S.i,j مع 0.000001 إذا بi,j=1
- حساب مصفوفة الخطأ المقاسة S.i,j=Ei,j/Si,j
- قم بتصفية SE مع عتبة = 0.5 ، ودع C تشير إلى مصفوفة العداد ، حيث Ci,j= 1 إذا كان SEi,j<0.5 و جi,j= 0 كذلك
- احسب عدد 1 في C.*,j كـ c⃗ واحسب عدد 0 في B*,j مثل ب
- PCKh@0.5=mean (c⃗ / b⃗)
في الخطوة السادسة (استبدل S.i,jمع 0.000001 إذا بi,j= 1) ، قمنا بإعداد فخ لمصفوفة الخطأ المقاسة باستبدال 0 مدخلات بـ 0.00001. ينتج عن قسمة أي رقم على عدد ضئيل رقم مضخم. نظرًا لأننا استخدمنا لاحقًا> 0.5 كعتبة لتصفية التنبؤات غير الصحيحة ، فقد تم استبعاد الإدخالات الفارغة من التنبؤ الصحيح لأنها كانت كبيرة جدًا. قمنا بعد ذلك بحساب الإدخالات غير الفارغة فقط في المصفوفة المنطقية. بهذه الطريقة ، استبعدنا أيضًا الإدخالات الفارغة من مجموعة البيانات بأكملها. اقترحنا خدعة هندسية في هذا التطبيق لتصفية الإدخالات الفارغة من النقاط الرئيسية غير المسماة في الحقيقة الأساسية أو الإطارات التي لم يتم اكتشاف أي شخص.
محاذاة الفيديو
لقد نظرنا في تكوينين مختلفين للكاميرا لالتقاط بيانات الفيديو من الرياضيين ، وهما إعدادات الخط والمربع. يتكون إعداد الخط من أربع كاميرات موضوعة على طول خط بينما يتكون إعداد الصندوق من أربع كاميرات موضوعة في كل ركن من أركان المستطيل. تمت مزامنة الكاميرات في تكوين الخط ثم اصطفت على مسافة محددة مسبقًا من بعضها البعض ، باستخدام زوايا الكاميرا المتداخلة قليلاً. كان الهدف من محاذاة الفيديو في تكوين الخط هو تحديد الطوابع الزمنية التي تربط الكاميرات المتتالية لإزالة الإطارات المتكررة والفارغة. قمنا بتنفيذ نهجين يعتمدان على اكتشاف الكائن والترابط المتبادل للتدفقات الضوئية.
خوارزمية الكشف عن الكائن
استخدمنا نتائج اكتشاف الكائنات في هذا النهج ، بما في ذلك المربعات المحيطة بالأشخاص من الخطوات السابقة. أنتجت تقنيات اكتشاف الكائن احتمالية (درجة) لكل شخص في كل إطار. لذلك ، فإن رسم الدرجات في مقطع فيديو مكّننا من العثور على الإطار الذي ظهر فيه الشخص الأول أو اختفى. تم استخراج الإطار المرجعي من تكوين الصندوق من كل فيديو ، ثم تمت مزامنة جميع الكاميرات بناءً على مراجع الإطار الأول. في تكوين الخط ، تم استخراج كل من الطوابع الزمنية للبداية والنهاية ، وتم تنفيذ خوارزمية قائمة على القواعد لربط ومحاذاة مقاطع الفيديو المتتالية ، كما هو موضح في الصور التالية.
تُظهر مقاطع الفيديو العلوية في الشكل التالي مقاطع الفيديو الأصلية في تكوين الخط. تحتها نتائج الكشف عن الأشخاص. تُظهر الصفوف التالية حدًا قدره 0.75 مطبقًا على الدرجات ، ويتم استخراج الطوابع الزمنية المناسبة للبداية والنهاية. يعرض الصف السفلي مقاطع الفيديو المتوافقة لمزيد من التحليل.
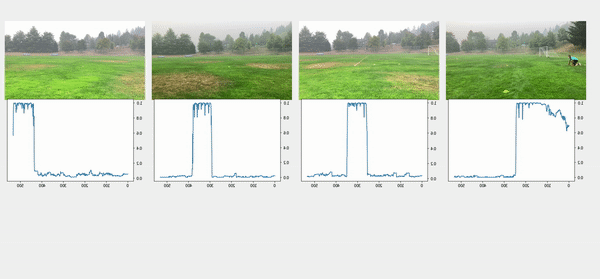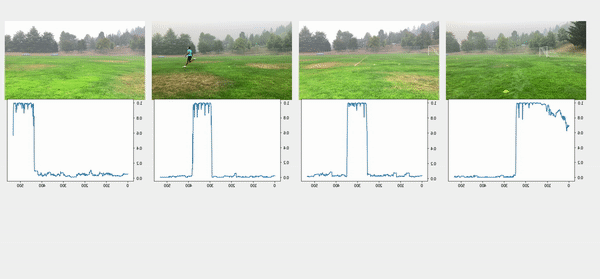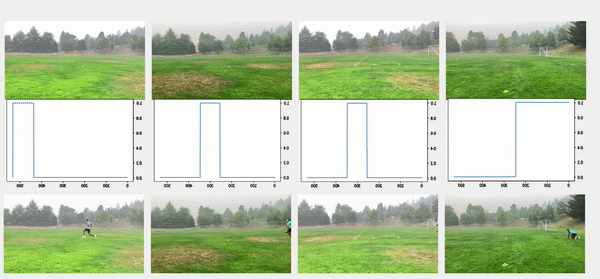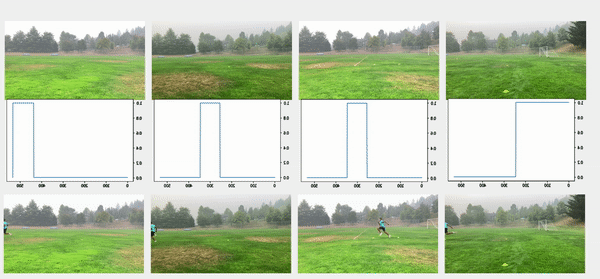
لحظة المفاجئة
قدمنا لحظة المفاجئة (MOS) - وهي طريقة محاذاة معروفة - والتي تشير إلى وقت بدء حدث أو مسرحية. أردنا تحديد رقم الإطار عندما يدخل الرياضي المشهد أو يغادره. عادةً ما تحدث حركة قليلة نسبيًا في ميدان الجري قبل بداية وبعد نهاية الخاطف ، بينما تحدث حركة كبيرة نسبيًا عندما يركض الرياضي. لذلك ، بشكل حدسي ، يمكننا العثور على إطار MOS من خلال العثور على إطارات الفيديو مع وجود اختلافات كبيرة نسبيًا في حركة الفيديو قبل الإطار وبعده. تحقيقا لهذه الغاية ، استخدمنا كثافة التدفق البصري ، وهو مقياس قياسي للحركة في الفيديو ، لتقدير MOS. أولاً ، بالنظر إلى الفيديو ، قمنا بحساب التدفق الضوئي لكل إطارين متتاليين. تقدم مقاطع الفيديو التالية تصورًا لتدفق بصري كثيف على المحور الأفقي.
![]()
قمنا بعد ذلك بقياس الارتباط المتبادل بين التدفقات البصرية لإطارين متتاليين ، لأن الارتباط المتبادل يقيس الفرق بينهما. بالنسبة للفيديو الذي تم التقاطه بالكاميرا لكل زاوية ، كررنا الخوارزمية للعثور على MOS الخاص بها. أخيرًا ، استخدمنا إطار MOS كإطار رئيسي لمحاذاة مقاطع الفيديو من زوايا مختلفة. يوضح الفيديو التالي تفاصيل هذه الخطوات.
![]()
وفي الختام
كان الهدف الفني للعمل الموضح في هذا المنشور هو تطوير حل قائم على التعلم العميق ينتج إحداثيات تقدير الوضع ثلاثي الأبعاد باستخدام مقاطع فيديو ثنائية الأبعاد. استخدمنا تقنية الكاميرا التي تدرك المسافة مع نهج من أعلى إلى أسفل لتحقيق تقدير الوضع ثلاثي الأبعاد متعدد الأشخاص. علاوة على ذلك ، باستخدام الكشف عن الكائنات ، والارتباط المتبادل ، وخوارزميات التدفق البصري ، قمنا بمحاذاة مقاطع الفيديو الملتقطة من زوايا مختلفة.
مكّن هذا العمل المدربين من تحليل تقدير الوضع ثلاثي الأبعاد للرياضيين بمرور الوقت لقياس مقاييس الميكانيكا الحيوية ، مثل السرعة ، ومراقبة أداء الرياضيين باستخدام الأساليب الكمية والنوعية.
أظهر هذا المنشور عملية مبسطة لاستخراج الأوضاع ثلاثية الأبعاد في سيناريوهات العالم الحقيقي ، والتي يمكن توسيعها إلى التدريب في الرياضات الأخرى مثل السباحة أو الرياضات الجماعية.
إذا كنت ترغب في المساعدة في تسريع استخدام ML في منتجاتك وخدماتك ، فيرجى الاتصال بـ مختبر أمازون ML Solutions برنامج.
مراجع حسابات
Moon و Gyeongsik و Ju Yong Chang و Kyoung Mu Lee. "نهج الكاميرا من أعلى لأسفل مع مراعاة المسافة لتقدير الوضع ثلاثي الأبعاد متعدد الأشخاص من صورة RGB واحدة." في وقائع المؤتمر الدولي IEEE حول رؤية الكمبيوتر، ص. 10133-10142. 2019.
عن المؤلف
![]() سمان صراف هو عالم بيانات في مختبر أمازون ML Solutions. تكمن خلفيته في التعلم الآلي التطبيقي بما في ذلك التعلم العميق ورؤية الكمبيوتر والتنبؤ ببيانات السلاسل الزمنية.
سمان صراف هو عالم بيانات في مختبر أمازون ML Solutions. تكمن خلفيته في التعلم الآلي التطبيقي بما في ذلك التعلم العميق ورؤية الكمبيوتر والتنبؤ ببيانات السلاسل الزمنية.
![]() العامري كونغ مهندس خوارزميات في Intel ، حيث يطور تقنيات التعلم الآلي ورؤية الكمبيوتر لإجراء التحليلات الميكانيكية الحيوية في الألعاب الأولمبية. إنه مهتم بقياس فسيولوجيا الإنسان باستخدام الذكاء الاصطناعي ، خاصة في سياق الأداء الرياضي.
العامري كونغ مهندس خوارزميات في Intel ، حيث يطور تقنيات التعلم الآلي ورؤية الكمبيوتر لإجراء التحليلات الميكانيكية الحيوية في الألعاب الأولمبية. إنه مهتم بقياس فسيولوجيا الإنسان باستخدام الذكاء الاصطناعي ، خاصة في سياق الأداء الرياضي.
![]() أشتون إيتون مهندس تطوير المنتجات في Intel ، حيث يساعد في تصميم واختبار التقنيات التي تهدف إلى تطوير الأداء الرياضي. يعمل مع العملاء والفريق الهندسي لتحديد وتطوير المنتجات التي تخدم احتياجات العملاء. يهتم بتطبيق العلم والتكنولوجيا على الأداء البشري.
أشتون إيتون مهندس تطوير المنتجات في Intel ، حيث يساعد في تصميم واختبار التقنيات التي تهدف إلى تطوير الأداء الرياضي. يعمل مع العملاء والفريق الهندسي لتحديد وتطوير المنتجات التي تخدم احتياجات العملاء. يهتم بتطبيق العلم والتكنولوجيا على الأداء البشري.
![]() جوناثان لي هو مدير تقنية الأداء الرياضي ، Olympic Technology Group في Intel. درس تطبيق التعلم الآلي على الصحة كطالب جامعي في جامعة كاليفورنيا وأثناء تخرجه في جامعة أكسفورد. ركزت حياته المهنية على الخوارزمية وتطوير أجهزة الاستشعار من أجل الصحة والأداء البشري. يقود الآن مشروع 3D Athlete Tracking في Intel.
جوناثان لي هو مدير تقنية الأداء الرياضي ، Olympic Technology Group في Intel. درس تطبيق التعلم الآلي على الصحة كطالب جامعي في جامعة كاليفورنيا وأثناء تخرجه في جامعة أكسفورد. ركزت حياته المهنية على الخوارزمية وتطوير أجهزة الاستشعار من أجل الصحة والأداء البشري. يقود الآن مشروع 3D Athlete Tracking في Intel.
![]() نيلسون ليونج هو مهندس المنصات في مركز التميز للأداء الرياضي في إنتل ، حيث يقوم بتعريف البنية الشاملة للمنتجات المتطورة التي تعزز أداء الرياضيين. كما أنه يقود تنفيذ ونشر وإنتاج هذه حلول التعلم الآلي على نطاق واسع لشركاء إنتل المختلفين.
نيلسون ليونج هو مهندس المنصات في مركز التميز للأداء الرياضي في إنتل ، حيث يقوم بتعريف البنية الشاملة للمنتجات المتطورة التي تعزز أداء الرياضيين. كما أنه يقود تنفيذ ونشر وإنتاج هذه حلول التعلم الآلي على نطاق واسع لشركاء إنتل المختلفين.
![]() سوشيترا ساتيانارايانا هو مدير في مختبر أمازون ML Solutions، حيث تساعد عملاء AWS عبر قطاعات الصناعة المختلفة على تسريع تبني الذكاء الاصطناعي والسحابة. وهي حاصلة على درجة الدكتوراه في رؤية الكمبيوتر من جامعة نانيانغ التكنولوجية بسنغافورة.
سوشيترا ساتيانارايانا هو مدير في مختبر أمازون ML Solutions، حيث تساعد عملاء AWS عبر قطاعات الصناعة المختلفة على تسريع تبني الذكاء الاصطناعي والسحابة. وهي حاصلة على درجة الدكتوراه في رؤية الكمبيوتر من جامعة نانيانغ التكنولوجية بسنغافورة.
![]()
وينتشن تشو هو عالم بيانات مع مختبر Amazon ML Solution Lab فريق في Amazon Web Services. إنها تستفيد من التعلم الآلي والتعلم العميق لحل المشكلات المتنوعة عبر الصناعات لعملاء AWS.
كوينسمارت. Beste Bitcoin-Börse في أوروبا
المصدر: https://aws.amazon.com/blogs/machine-learning/estimating-3d-pose-for-athlete-tracking-using-2d-videos-and-amazon-sagemaker-studio/

