المُقدّمة
لقد استحوذ الجيل المعزز للاسترجاع (RAG) على العالم منذ بدايته. RAG هو ما هو ضروري لنماذج اللغة الكبيرة (LLMs) لتقديم أو إنشاء إجابات دقيقة وواقعية. نحن نحل حقيقة LLMs بواسطة RAG، حيث نحاول إعطاء LLM سياقًا مشابهًا من حيث السياق لاستعلام المستخدم بحيث تعمل LLM مع هذا السياق وتولد استجابة صحيحة واقعيًا. نقوم بذلك من خلال تمثيل بياناتنا واستعلام المستخدم في شكل تضمينات متجهة وإجراء تشابه جيب التمام. لكن المشكلة تكمن في أن جميع الأساليب التقليدية تمثل البيانات في عملية تضمين واحدة، وهو ما قد لا يكون مثاليًا للأبد أنظمة الاسترجاع. في هذا الدليل، سوف نلقي نظرة على ColBERT الذي يقوم بالاسترجاع بدقة أفضل من نماذج التشفير الثنائي التقليدية.
أهداف التعلم
- فهم كيفية عمل الاسترجاع في RAG على مستوى عالٍ.
- فهم قيود التضمين الفردي في الاسترجاع.
- تحسين سياق الاسترجاع باستخدام تضمينات الرمز المميز لـ ColBERT.
- تعرف على كيفية تحسين التفاعل المتأخر لـ ColBERT من عملية الاسترجاع.
- تعرف على كيفية العمل مع ColBERT من أجل الاسترجاع الدقيق.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
ما هو خرقة؟
على الرغم من أن حاملي شهادات الماجستير في القانون قادرون على إنشاء نص ذي معنى وصحيح نحويًا، فإن هؤلاء الحاصلين على ماجستير في القانون يعانون من مشكلة تسمى الهلوسة. الهلوسة في LLMs هو المفهوم الذي يقوم فيه طلاب LLM بإنشاء إجابات خاطئة بثقة، أي أنهم يشكلون إجابات خاطئة بطريقة تجعلنا نعتقد أنها صحيحة. لقد كانت هذه مشكلة كبيرة منذ تقديم LLMs. تؤدي هذه الهلوسة إلى إجابات غير صحيحة وخاطئة في الواقع. ومن هنا تم تقديم الجيل المعزز للاسترجاع.
في RAG، نأخذ قائمة من المستندات/أجزاء من المستندات ونقوم بتشفير هذه المستندات النصية في تمثيل رقمي يسمى عمليات تضمين المتجهات، حيث يمثل تضمين ناقل واحد قطعة واحدة من المستند ويخزنها في قاعدة بيانات تسمى متجر ناقلات. تسمى النماذج المطلوبة لترميز هذه القطع في التضمينات نماذج الترميز أو المشفرات الثنائية. يتم تدريب أجهزة التشفير هذه على مجموعة كبيرة من البيانات، مما يجعلها قوية بما يكفي لتشفير أجزاء المستندات في تمثيل تضمين متجه واحد.
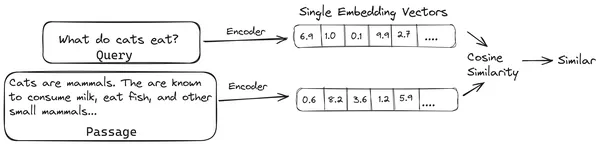
الآن عندما يسأل المستخدم استعلامًا إلى LLM، فإننا نعطي هذا الاستعلام إلى نفس برنامج التشفير لإنتاج تضمين متجه واحد. يتم بعد ذلك استخدام هذا التضمين لحساب درجة التشابه مع العديد من عمليات التضمين المتجهة الأخرى لأجزاء المستند للحصول على الجزء الأكثر صلة بالمستند. يتم تقديم الجزء الأكثر صلة أو قائمة الأجزاء الأكثر صلة بالإضافة إلى استعلام المستخدم إلى LLM. يتلقى LLM بعد ذلك هذه المعلومات السياقية الإضافية ثم يقوم بإنشاء إجابة تتماشى مع السياق المستلم من استعلام المستخدم. وهذا يضمن أن المحتوى الذي تم إنشاؤه بواسطة LLM حقيقي ويمكن تعقبه إذا لزم الأمر.
المشكلة مع أجهزة التشفير الثنائية التقليدية
المشكلة في نماذج التشفير التقليدية مثل all-miniLM، OpenAI نموذج التضمين ونماذج التشفير الأخرى هو أنها تقوم بضغط النص بأكمله في تمثيل تضمين متجه واحد. تعتبر تمثيلات تضمين المتجهات الفردية هذه مفيدة لأنها تساعد في الاسترداد الفعال والسريع للمستندات المماثلة. ومع ذلك، تكمن المشكلة في السياق بين الاستعلام والمستند. قد لا يكون تضمين المتجه الفردي كافيًا لتخزين المعلومات السياقية الخاصة بمقطع مستند، مما يؤدي إلى إنشاء عنق الزجاجة في المعلومات.
تخيل أنه تم ضغط 500 كلمة في متجه واحد بحجم 782. قد لا يكون كافيًا تمثيل مثل هذه القطعة مع تضمين متجه واحد، وبالتالي إعطاء نتائج دون المستوى في الاسترجاع في معظم الحالات. قد يفشل تمثيل المتجه الفردي أيضًا في حالات الاستعلامات أو المستندات المعقدة. أحد هذه الحلول هو تمثيل جزء المستند أو الاستعلام كقائمة من متجهات التضمين بدلاً من متجه تضمين واحد، وهنا يأتي دور ColBERT.
ما هو كولبيرت؟
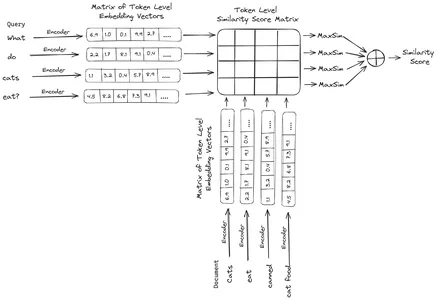
ColBERT (التفاعلات السياقية المتأخرة BERT) عبارة عن برنامج تشفير ثنائي يمثل النص في تمثيل تضمين متعدد المتجهات. يستغرق الأمر استعلامًا أو جزءًا من مستند/مستند صغير ويقوم بإنشاء تضمينات متجهة على مستوى الرمز المميز. وهذا يعني أن كل رمز مميز يحصل على تضمين متجه خاص به، ويتم ترميز الاستعلام/المستند إلى قائمة من عمليات تضمين المتجهات على مستوى الرمز المميز. يتم إنشاء عمليات التضمين على مستوى الرمز المميز من مدربين مسبقًا بيرت النموذج ومن هنا جاء اسم بيرت.
ثم يتم تخزينها في قاعدة بيانات المتجهات. الآن، عندما يأتي استعلام، يتم إنشاء قائمة بالتضمينات على مستوى الرمز المميز له ثم يتم إجراء ضرب المصفوفة بين استعلام المستخدم وكل مستند، مما يؤدي إلى مصفوفة تحتوي على درجات التشابه. يتم تحقيق التشابه الإجمالي من خلال جمع الحد الأقصى للتشابه عبر الرموز المميزة للمستند لكل رمز مميز للاستعلام. يمكن رؤية صيغة ذلك في الصورة أدناه:
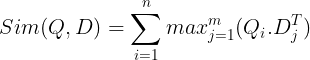
هنا في المعادلة أعلاه، نرى أننا نقوم بعمل منتج نقطي بين مصفوفة رموز الاستعلام (التي تحتوي على تضمينات متجهة لمستوى الرمز المميز N) ومصفوفة تبديل رموز المستندات (التي تحتوي على تضمينات متجهة لمستوى الرمز المميز M)، ثم نأخذ الحد الأقصى من التشابه عبور الرموز المميزة للوثيقة لكل رمز مميز للاستعلام. ثم نأخذ مجموع كل أوجه التشابه القصوى هذه، مما يعطينا درجة التشابه النهائية بين المستند والاستعلام. السبب الذي يجعل هذا يؤدي إلى استرجاع فعال ودقيق هو أننا هنا نواجه تفاعلًا على مستوى الرمز المميز، مما يتيح مجالًا لمزيد من الفهم السياقي بين الاستعلام والمستند.
لماذا اسم كولبيرت؟
نظرًا لأننا نقوم بحساب قائمة المتجهات المضمنة قبل نفسها ونقوم فقط بتنفيذ عملية MaxSim (الحد الأقصى للتشابه) أثناء استنتاج النموذج، وبالتالي نطلق عليها خطوة التفاعل المتأخر، وبما أننا نحصل على المزيد من المعلومات السياقية من خلال تفاعلات مستوى الرمز المميز، فإنها تسمى السياقية التفاعلات المتأخرة ومن هنا جاء اسم التفاعلات السياقية المتأخرة بيرت أو كولبيرت. ويمكن إجراء هذه الحسابات بالتوازي، وبالتالي يمكن حسابها بكفاءة. أخيرًا، أحد المخاوف هو المساحة، أي أنها تتطلب مساحة كبيرة لتخزين هذه القائمة من تضمينات المتجهات على مستوى الرمز المميز. تم حل هذه المشكلة في ColBERTv2، حيث يتم ضغط التضمينات من خلال تقنية تسمى الضغط المتبقي، وبالتالي تحسين المساحة المستخدمة.
التدريب العملي على ColBERT مع المثال
في هذا القسم، سوف نتدرب على استخدام ColBERT ونتحقق أيضًا من كيفية أدائه مقارنة بنموذج التضمين العادي.
الخطوة 1: تنزيل المكتبات
سنبدأ بتحميل المكتبة التالية:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- راجاتوي: تتيح لنا هذه المكتبة العمل بأحدث طرق الاسترجاع (SOTA) مثل ColBERT بطريقة سهلة الاستخدام. فهو يوفر خيارات لإنشاء فهارس على مجموعات البيانات، والاستعلام عنها، وحتى السماح لنا بتدريب نموذج ColBERT على بياناتنا.
- لانجشين: ستتيح لنا هذه المكتبة العمل مع نماذج التضمين مفتوحة المصدر حتى نتمكن من اختبار مدى جودة عمل نماذج التضمين الأخرى عند مقارنتها بـ ColBERT.
- langchain_openai: يثبت ال لانجشين تبعيات OpenAI. سنعمل أيضًا مع نموذج OpenAI Embedding للتحقق من أدائه مقابل ColBERT.
- كروما دي بي: ستتيح لنا هذه المكتبة إنشاء مخزن متجه في بيئتنا حتى نتمكن من حفظ التضمينات التي أنشأناها على بياناتنا وإجراء بحث دلالي لاحقًا بين الاستعلام والتضمينات المخزنة.
- اينوبس: هذه المكتبة ضرورية لمضاعفات مصفوفة الموتر الفعالة.
- محولات الجملة و تيكتوكين هناك حاجة إلى مكتبة لكي تعمل نماذج التضمين مفتوحة المصدر بشكل صحيح.
الخطوة 2: تنزيل النموذج المُدرب مسبقًا
في الخطوة التالية، سنقوم بتنزيل نموذج ColBERT المُدرب مسبقًا. لهذا سيكون الكود
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- نقوم أولاً باستيراد فئة RAGPretrainedModel من مكتبة RAGatouille.
- ثم نسمي .from_pretrained() ونعطي اسم النموذج، أي "colbert-ir/colbertv2.0".
سيؤدي تشغيل الكود أعلاه إلى إنشاء نموذج ColBERT RAG. لنقم الآن بتنزيل صفحة ويكيبيديا وإجراء الاسترداد منها. ولهذا سيكون الكود:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])يأتي RAGatouille مزودًا بوظيفة سهلة الاستخدام تسمى get_wikipedia_page والتي تأخذ سلسلة وتحصل على صفحة Wikipedia المقابلة. نقوم هنا بتنزيل محتوى ويكيبيديا على Elon Musk وتخزينه في المستند المتغير. لنطبع عدد الكلمات الموجودة في المستند والأسطر القليلة الأولى من المستند.
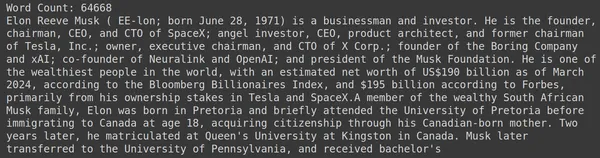
هنا يمكننا أن نرى الإخراج في الموافقة المسبقة عن علم. يمكننا أن نرى أن هناك إجمالي 64,668 كلمة على صفحة ويكيبيديا الخاصة بإيلون ماسك.
الخطوة 3: الفهرسة
الآن سنقوم بإنشاء فهرس في هذه الوثيقة.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)نحن هنا نسمي .index() الخاص بـ RAG لفهرسة وثيقتنا. ولهذا نمرر ما يلي:
- مجموعة: هذه قائمة بالوثائق التي نريد فهرستها. لدينا هنا وثيقة واحدة فقط، وبالتالي قائمة وثيقة واحدة.
- معرفات الوثيقة: يتوقع كل مستند معرف مستند فريدًا. وهنا نمرره بالاسم elon_musk لأن الوثيقة تتعلق بإيلون ماسك.
- بيانات تعريف الوثيقة: تحتوي كل وثيقة على البيانات الوصفية الخاصة بها. هذه مرة أخرى هي قائمة القواميس، حيث يحتوي كل قاموس على بيانات تعريف زوج المفتاح والقيمة لمستند معين.
- اسم_الفهرس: اسم الفهرس الذي نقوم بإنشائه. دعنا نسميها Elon2.
- الحد الأقصى لحجم المستند: وهذا مشابه لحجم القطعة. نحدد المبلغ الذي يجب أن يكون عليه كل جزء من المستند. نحن هنا نعطيها قيمة 256. إذا لم نحدد أي قيمة، فسيتم اعتبار 256 كحجم القطعة الافتراضي.
- وثائق_تقسيم: إنها قيمة منطقية، حيث يشير True إلى أننا نريد تقسيم المستند وفقًا لحجم القطعة المحددة، ويشير False إلى أننا نريد تخزين المستند بأكمله كقطعة واحدة.
سيؤدي تشغيل الكود أعلاه إلى تجميع وثيقتنا بأحجام 256 لكل قطعة، ثم تضمينها من خلال نموذج ColBERT، والذي سينتج قائمة من التضمينات المتجهة على مستوى الرمز المميز لكل قطعة ويخزنها أخيرًا في فهرس. ستستغرق هذه الخطوة بعض الوقت للتشغيل ويمكن تسريعها إذا كان لديك وحدة معالجة رسومات. وأخيرًا، يقوم بإنشاء دليل حيث يتم تخزين الفهرس الخاص بنا. هنا سيكون الدليل ".ragatouille/colbert/indexes/Elon2"
الخطوة 4: الاستعلام العام
والآن سنبدأ بالبحث. لهذا سيكون الكود
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- هنا، أولاً، نستدعي الأسلوب .search() لكائن RAG
- ولهذا نعطي المتغيرات التي تتضمن اسم الاستعلام، k (عدد المستندات المطلوب استرجاعها)، واسم الفهرس المراد البحث فيه
- نقدم هنا الاستعلام "ما هي الشركات التي وجدها إيلون ماسك؟". ستكون النتيجة التي تم الحصول عليها في قائمة بتنسيق القاموس، والتي تحتوي على مفاتيح مثل المحتوى، والنتيجة، والرتبة، وdocument_id، وpassion_id، وdocument_metadata
- ومن ثم فإننا نعمل بالكود أدناه لطباعة المستندات المستردة بطريقة مرتبة
- نستعرض هنا قائمة القواميس ونطبع محتوى المستندات
سيؤدي تشغيل الكود إلى النتائج التالية:
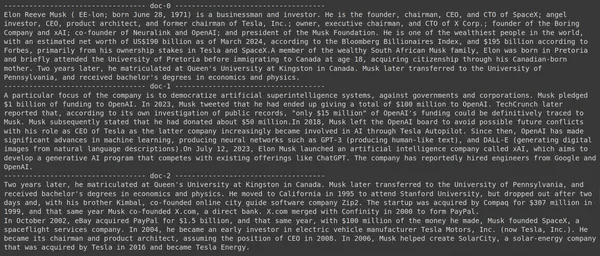
في الصورة، يمكننا أن نرى أن الوثيقة الأولى والأخيرة تغطي بالكامل الشركات المختلفة التي أسسها إيلون ماسك. تمكن ColBERT من استرداد الأجزاء ذات الصلة اللازمة للإجابة على الاستعلام بشكل صحيح.
الخطوة 5: استعلام محدد
الآن دعونا نتقدم خطوة أبعد ونطرح عليه سؤالاً محددًا.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])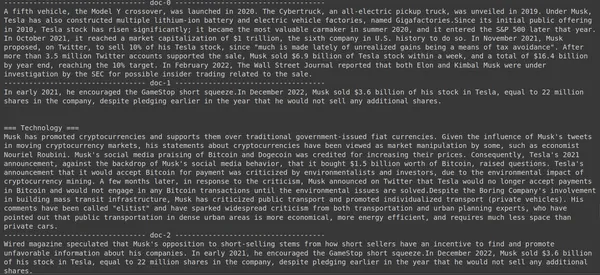
هنا في الكود أعلاه، نطرح سؤالًا محددًا للغاية حول عدد الأسهم التي بيعت بقيمة Tesla Elon في شهر ديسمبر 2022. يمكننا رؤية الناتج هنا. يحتوي المستند-1 على إجابة السؤال. باع إيلون ما قيمته 3.6 مليار دولار من أسهمه في شركة تسلا. مرة أخرى، تمكن ColBERT من استرداد القطعة ذات الصلة للاستعلام المحدد بنجاح.
الخطوة 6: اختبار النماذج الأخرى
لنجرب الآن نفس السؤال مع نماذج التضمين الأخرى سواء مفتوحة المصدر أو المغلقة هنا:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- نبدأ بتنزيل النموذج أولاً من خلال فئة AutoModel من مكتبة Transformers.
- ثم نقوم بتخزين model_name وmodel_kwargs في المتغيرات الخاصة بهما.
- الآن للعمل مع هذا النموذج في LangChain، نقوم باستيراد HuggingFaceEmbeddings من ملف لانجشين وإعطائه اسم النموذج وmodel_kwargs.
سيؤدي تشغيل هذا الكود إلى تنزيل نموذج تضمين Jina وتحميله حتى نتمكن من العمل معه
الخطوة 7: إنشاء التضمينات
الآن، نحتاج إلى البدء في تقسيم مستندنا ثم إنشاء التضمينات منه وتخزينها في متجر Chroma Vector. ولهذا نعمل بالكود التالي:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- نبدأ باستيراد Chroma وRecursiveCharacterTextSplitter من مكتبة LangChain
- ثم نقوم بإنشاء مثيل text_splitter عن طريق استدعاء .from_tiktoken_encoder الخاص بـ RecursiveCharacterTextSplitter وتمريره إلىchunk_size وchunk_overlap.
- سنستخدم هنا نفس حجم القطعة التي قدمناها إلى ColBERT
- ثم نستدعي طريقة .split_text() الخاصة بـ text_splitter ونعطيها المستند الذي يحتوي على معلومات ويكيبيديا حول Elon Musk. ثم يقوم بعد ذلك بتقسيم المستند بناءً على حجم القطعة المحددة، وأخيرًا، يتم تخزين قائمة أجزاء المستند في تقسيمات متغيرة
- أخيرًا، نستدعي الدالة .from_texts() لفئة Chroma لإنشاء مخزن متجهات. لهذه الوظيفة، نعطي الانقسامات ونموذج التضمين واسم المجموعة
- الآن، نقوم بإنشاء مسترد منه عن طريق استدعاء الدالة .as_retriever() لكائن مخزن المتجهات. نعطي 3 لقيمة k
سيؤدي تشغيل هذا الرمز إلى أخذ المستند الخاص بنا، وتقسيمه إلى مستندات أصغر بحجم 256 لكل قطعة، ثم تضمين هذه الأجزاء الأصغر باستخدام نموذج تضمين Jina وتخزين متجهات التضمين هذه في مخزن متجهات اللون.
الخطوة 8: إنشاء المسترد
وأخيرا، نقوم بإنشاء المسترد منه. سنقوم الآن بإجراء بحث متجه والتحقق من النتائج.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)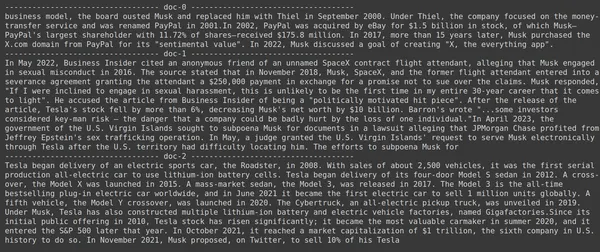
- نحن نستدعي الدالة .get_relevent_documents() لكائن المسترد ونعطيها نفس الاستعلام.
- ثم نقوم بطباعة أفضل 3 مستندات مستردة بدقة.
- في الصورة، يمكننا أن نرى أن Jina Embedder على الرغم من كونه نموذج تضمين شائع، إلا أن استرجاع استعلامنا ضعيف. لم يكن ناجحًا في الحصول على أجزاء المستند الصحيحة.
يمكننا أن نلاحظ بوضوح الفرق بين نموذج Jina، وهو نموذج التضمين الذي يمثل كل قطعة باعتبارها تضمين متجه واحد، ونموذج ColBERT الذي يمثل كل قطعة كقائمة من ناقلات التضمين على مستوى الرمز المميز. من الواضح أن أداء ColBERT يتفوق في هذه الحالة.
الخطوة 9: اختبار نموذج التضمين الخاص بـ OpenAI
لنحاول الآن استخدام نموذج تضمين مغلق المصدر مثل نموذج OpenAI Embedding.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})الكود هنا مشابه جدًا للكود الذي كتبناه للتو
- والفرق الوحيد هو أننا نقوم بتمرير مفتاح OpenAI API لتعيين متغير البيئة.
- نقوم بعد ذلك بإنشاء مثيل لنموذج OpenAI Embedding عن طريق استيراده من LangChain.
- وأثناء إنشاء اسم المجموعة، نعطي اسمًا مختلفًا للمجموعة، بحيث يتم تخزين التضمينات من نموذج OpenAI Embedding في مجموعة مختلفة.
سيؤدي تشغيل هذا الرمز إلى أخذ مستنداتنا مرة أخرى، وتقطيعها إلى مستندات أصغر بحجم 256، ثم دمجها في تمثيل تضمين متجه واحد باستخدام نموذج تضمين OpenAI، وأخيرًا تخزين هذه التضمينات في متجر Chroma Vector Store. الآن دعونا نحاول استرداد المستندات ذات الصلة بالسؤال الآخر.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)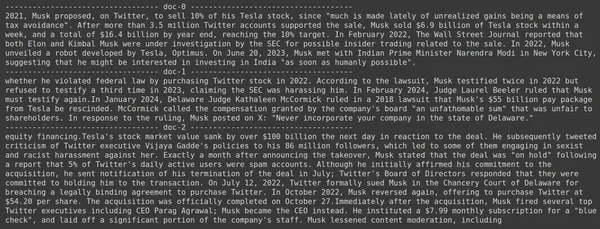
- نرى أن الإجابة التي نتوقعها غير موجودة ضمن القطع المستردة.
- يحتوي الجزء الأول على معلومات حول أسهم Tesla في عام 2022، لكنه لا يتحدث عن بيع إيلون لها.
- ويمكن رؤية الشيء نفسه مع قطعتي الوثيقة المتبقيتين، حيث تكون المعلومات التي تحتوي عليها تتعلق بشركة Tesla وأسهمها ولكن هذه ليست المعلومات التي نتوقعها.
- لن توفر الأجزاء التي تم استرجاعها أعلاه السياق لـ LLM للإجابة على الاستعلام الذي قدمناه.
حتى هنا يمكننا أن نرى فرقًا واضحًا بين تمثيل التضمين أحادي المتجهات مقابل تمثيل التضمين متعدد المتجهات. تلتقط تمثيلات التضمين المتعدد بوضوح الاستعلامات المعقدة مما يؤدي إلى عمليات استرجاع أكثر دقة.
وفي الختام
في الختام، يُظهر ColBERT تقدمًا كبيرًا في أداء الاسترجاع مقارنة بنماذج التشفير الثنائي التقليدية من خلال تمثيل النص كتضمينات متعددة المتجهات على مستوى الرمز المميز. يسمح هذا النهج بفهم سياقي أكثر دقة بين الاستعلامات والمستندات، مما يؤدي إلى نتائج استرجاع أكثر دقة وتخفيف مشكلة الهلوسة التي يتم ملاحظتها بشكل شائع في LLMs.
الوجبات السريعة الرئيسية
- يعالج RAG مشكلة الهلوسة في LLMs من خلال توفير معلومات سياقية لتوليد الإجابات الواقعية.
- تعاني أجهزة التشفير الثنائية التقليدية من اختناق المعلومات بسبب ضغط النصوص بأكملها في تضمينات متجهة واحدة، مما يؤدي إلى دقة استرجاع دون المستوى.
- يسهل ColBERT، من خلال تمثيل التضمين على مستوى الرمز المميز، فهمًا سياقيًا أفضل بين الاستعلامات والمستندات، مما يؤدي إلى تحسين أداء الاسترجاع.
- تعمل خطوة التفاعل المتأخر في ColBERT، جنبًا إلى جنب مع التفاعلات على مستوى الرمز المميز، على تعزيز دقة الاسترجاع من خلال مراعاة الفروق الدقيقة في السياق.
- يعمل ColBERTv2 على تحسين مساحة التخزين من خلال الضغط المتبقي مع الحفاظ على فعالية الاسترجاع.
- تُظهر التجارب العملية تفوق ColBERT في أداء الاسترجاع مقارنة بنماذج التضمين التقليدية ومفتوحة المصدر مثل Jina وOpenAI Embedding.
الأسئلة المتكررة
أ. تعمل أجهزة التشفير الثنائية التقليدية على ضغط النصوص بأكملها في تضمينات متجهة واحدة، مما قد يؤدي إلى فقدان المعلومات السياقية. وهذا يحد من فعاليتها في مهام الاسترجاع، خاصة مع الاستعلامات أو المستندات المعقدة.
A. ColBERT (التفاعلات السياقية المتأخرة BERT) هو نموذج ثنائي التشفير يمثل النص باستخدام عمليات تضمين المتجهات على مستوى الرمز المميز. فهو يسمح بفهم سياقي أكثر دقة بين الاستعلامات والمستندات، مما يحسن دقة الاسترجاع.
A. يقوم ColBERT بإنشاء عمليات تضمين على مستوى الرمز المميز للاستعلامات والمستندات، وإجراء عملية مضاعفة للمصفوفة لحساب درجات التشابه، ثم تحديد المعلومات الأكثر صلة استنادًا إلى أقصى قدر من التشابه عبر الرموز المميزة. وهذا يسمح بالاسترجاع الفعال مع الفهم السياقي.
A. يعمل ColBERTv2 على تحسين المساحة من خلال أسلوب الضغط المتبقي، مما يقلل متطلبات التخزين للتضمينات على مستوى الرمز المميز مع الحفاظ على دقة الاسترجاع.
ج: يمكنك استخدام مكتبات مثل RAGatouille للعمل مع ColBERT بسهولة. ومن خلال فهرسة المستندات والاستعلامات، يمكنك تنفيذ مهام استرجاع فعالة وإنشاء إجابات دقيقة تتماشى مع السياق.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

