التعلم العميق عالي الأداء: كيفية تدريب نماذج أصغر وأسرع وأفضل - الجزء الثاني
الآن بعد أن أصبحت جاهزًا لبناء نماذج التعلم العميق المتقدمة بكفاءة باستخدام أدوات البرامج والأجهزة المناسبة ، يجب استكشاف التقنيات المتضمنة في تنفيذ مثل هذه الجهود لتحسين جودة النموذج والحصول على الأداء الذي ترغب فيه مؤسستك.

في الأجزاء السابقة (جزء 1 & جزء 2) ، ناقشنا سبب أهمية الكفاءة لنماذج التعلم العميق لتحقيق نماذج عالية الأداء تكون مثالية باريتو ، بالإضافة إلى مجالات التركيز لتحقيق الكفاءة في التعلم العميق. دعونا الآن نتعمق أكثر في أمثلة الأدوات والتقنيات التي تقع في مجالات التركيز هذه.
تقنيات الضغط
تقنيات الضغط ، كما ذكرنا سابقًا ، هي تقنيات عامة يمكن أن تساعد في تحقيق تمثيل أكثر كفاءة لطبقة واحدة أو أكثر في الشبكة العصبية ، مع إمكانية مقايضة الجودة. يمكن أن تأتي الكفاءة من تحسين واحد أو أكثر من مقاييس البصمة ، مثل حجم النموذج ، ووقت استجابة الاستدلال ، ووقت التدريب المطلوب للتقارب ، وما إلى ذلك ، مقابل أقل قدر ممكن من فقدان الجودة. في كثير من الأحيان يمكن أن يكون النموذج مفرط في البارامترات. في مثل هذه الحالات ، تساعد هذه التقنيات في تحسين التعميم على البيانات غير المرئية أيضًا.
تشذيب: تعتبر Pruning واحدة من تقنيات الضغط الشائعة ، حيث نقوم بذلك تقليم اتصالات الشبكة غير مهمة ، وبالتالي جعل الشبكة متناثر. LeCun et al. [1] في ورقتهم البحثية بعنوان Optimal Brain Damage ، قلصوا عدد المعلمات (الوصلات بين الطبقات) في شبكتهم العصبية بعامل أربعة مع زيادة سرعة الاستدلال والتعميم.

رسم توضيحي للتقليم في الشبكات العصبية.
تم اتباع نهج مماثل من خلال العمل الأمثل لجراح الدماغ (OBD) بواسطة حسيبي وآخرون. [2] وبواسطة Zhu et al. [3]. تأخذ هذه الأساليب شبكة تم تدريبها مسبقًا على جودة معقولة ثم تقوم بشكل متكرر بتقليم المعلمات التي لديها أدنى مستوى البروز الدرجة ، التي تقيس أهمية اتصال معين ، بحيث يتم تقليل التأثير على فقدان التحقق من الصحة إلى الحد الأدنى. بمجرد انتهاء التقليم ، يتم ضبط الشبكة باستخدام المعلمات المتبقية. تتكرر العملية حتى يتم تقليم الشبكة إلى المستوى المطلوب.
من بين الأعمال المختلفة المتعلقة بالتقليم ، تحدث الاختلافات في الأبعاد التالية:
- البروز: هذا هو الكشف عن مجريات الأمور لتحديد الاتصال الذي يجب تقليمه. يمكن أن يعتمد هذا على مشتقات من الدرجة الثانية [1 ، 2] من وزن الاتصال فيما يتعلق بدالة الخسارة ، وحجم وزن الاتصال [3] ، وما إلى ذلك.
- غير منظم v / s منظم: الطريقة الأكثر مرونة للتقليم هي التقليم غير المنظم (أو العشوائي) ، حيث يتم التعامل مع جميع المعلمات على قدم المساواة. في التقليم المنظم ، يتم تقليم المعلمات في كتل بحجم أكبر من 1 (مثل التقليم من ناحية الصفوف في مصفوفة الوزن أو التقليم في اتجاه القناة في مرشح تلافيفي (مثال: [4,5،XNUMX]). يسمح التقليم المنظم بالاستفادة بشكل أسهل من وقت الاستدلال المكاسب في الحجم والكمون حيث يمكن تخطي هذه الكتل من المعلمات المشذبة بذكاء للتخزين والاستدلال.

التقليم غير المنظم مقابل التقليم المنظم لمصفوفة الوزن ، على التوالي.
- التوزيع: يمكن وضع ميزانية تقليم هي نفسها لكل طبقة ، أو يمكن تخصيصها على أساس كل طبقة [6]. الحدس هو أن بعض الطبقات أكثر قابلية للتقليم من غيرها. على سبيل المثال ، غالبًا ما تكون الطبقات القليلة الأولى بالفعل صغيرة بما يكفي بحيث لا يمكنها تحمل تباين كبير [7].
- جدولة: ومع ذلك ، فإن المعايير الإضافية هي مقدار التقليم ومتى؟ هل نريد تقليم عدد متساوٍ من المعلمات في كل جولة [8] ، أم هل نقوم بالتقليم بوتيرة أعلى في البداية ونبطئ تدريجيًا [9]؟
- إعادة نمو: في بعض الحالات ، يُسمح للشبكة بإعادة نمو الاتصالات المقطوعة [9] ، بحيث تعمل الشبكة باستمرار مع نفس النسبة المئوية للاتصالات المقطوعة.
من حيث الاستخدام العملي ، يمكن أن يساعد التقليم المنظم بحجم كتلة ذي مغزى في تحسين زمن الوصول. إلسن وآخرون. [7] قم ببناء شبكات تلافيفية متفرقة تفوق أداء نظيراتها الكثيفة بمقدار 1.3 - 2.4 × مع٪ 66٪ من المعلمات مع الاحتفاظ بنفس دقة Top-1. يفعلون ذلك عبر مكتبتهم للتحويل من التمثيل القياسي الكثيف NHWC (القنوات-الأخيرة) إلى تمثيل NCHW (القنوات أولاً) 'Block Compressed Sparse Row' (BCSR) وهو مناسب للاستدلال السريع باستخدام نواتهم السريعة على ARM الأجهزة ، WebAssembly ، إلخ. [10]. على الرغم من أنها تقدم أيضًا بعض القيود على أنواع الشبكات المتفرقة التي يمكن تسريعها. بشكل عام ، هذه خطوة واعدة نحو تحسينات عملية في مقاييس البصمة مع الشبكات المشذبة.
توضيح: التكميم هو أسلوب ضغط شائع آخر. إنها تستغل فكرة أن جميع أوزان الشبكة النموذجية تقريبًا هي في قيم النقطة العائمة 32 بت ، وإذا كنا على ما يرام مع فقدان بعض جودة النموذج (الدقة ، الدقة ، الاسترجاع ، إلخ) ، فيمكننا تخزين هذه القيم في تنسيق دقة أقل (16 بت ، 8 بت ، 4 بت ، إلخ).
على سبيل المثال ، عند استمرار النموذج ، يمكننا تعيين الحد الأدنى للقيمة في مصفوفة الوزن إلى 0 والحد الأقصى للقيمة على 2b-1 (حيث b هو عدد بتات الدقة) ، واستقراء كل القيم بينها إلى قيمة عدد صحيح. غالبًا ، قد يكون هذا كافيًا لأغراض تقليل حجم النموذج. على سبيل المثال ، إذا كانت b = 8 ، فإننا نعيّن أوزان الفاصلة العائمة ذات 32 بت إلى الأعداد الصحيحة غير الموقعة 8 بت. سيؤدي ذلك إلى تقليل المساحة بمقدار 4 أضعاف. عند القيام بالاستدلال (تنبؤات نموذج الحوسبة) ، يمكننا استرداد التمثيل الخاسر لقيمة النقطة العائمة الأصلية (بسبب خطأ التقريب) ، باستخدام القيمة الكمية والحد الأدنى والأقصى لقيم الفاصلة العائمة للمصفوفة. يشار إلى هذه الخطوة باسم الوزن الكمي نظرًا لأننا نحدد أوزان النموذج.

تعيين قيم مستمرة عالية الدقة لقيم أعداد صحيحة منخفضة الدقة منفصلة. مصدر
قد يكون التمثيل الخاطئ وخطأ التقريب مناسبًا للشبكات الأكبر ذات التكرار المدمج بسبب عدد كبير من المعلمات ولكن قد يؤدي إلى انخفاض في دقة الشبكات الأصغر ، والتي من المحتمل أن تكون حساسة لهذه الأخطاء.
يمكننا حل هذه المشكلة (بطريقة تجريبية) من خلال محاكاة السلوك التقريبي لتكميم الوزن أثناء التدريب. نقوم بذلك عن طريق إضافة عقد في الرسم البياني التدريبي النموذجي الذي يكمم ويفصل التنشيطات ومصفوفات الوزن ، بحيث تبدو مدخلات وقت التدريب لعملية الشبكة العصبية متطابقة مع ما سيكون لديهم خلال مرحلة الاستدلال. يشار إلى هذه العقد على أنها عقد تكميم وهمية. التدريب بهذه الطريقة يجعل الشبكات أكثر قوة لسلوك التكميم في وضع الاستدلال. لاحظ أننا نقوم بذلك التنشيط الكمي جنبا إلى جنب مع الوزن الكمي أثناء التدريب الآن. تم وصف هذه الخطوة من محاكاة وقت التدريب الكمي بالتفصيل بواسطة Jacob et al. وكريشنامورثي وآخرون. [11,12،XNUMX]

الرسم البياني النموذجي الأصلي للتدريب والرسم البياني مع عقد تكميم وهمية. مصدر
نظرًا لأنه يتم تشغيل كل من الأوزان والتنشيطات في الوضع الكمي المحاكي ، فهذا يعني أن جميع الطبقات تتلقى مدخلات يمكن تمثيلها بدقة أقل ، وبعد تدريب النموذج ، يجب أن يكون قويًا بما يكفي لإجراء العمليات الحسابية مباشرة بدقة أقل. على سبيل المثال ، إذا قمنا بتدريب النموذج على تكرار التكميم في مجال 8 بت ، فيمكن نشر النموذج للقيام بضرب المصفوفة والعمليات الأخرى بأعداد صحيحة 8 بت.
على الأجهزة محدودة الموارد (مثل الأجهزة المحمولة والمدمجة وأجهزة إنترنت الأشياء) ، يمكن تسريع العمليات ذات 8 بت بين 1.5 - 2x باستخدام مكتبات مثل GEMMLOWP [13] التي تعتمد على دعم الأجهزة لمثل هذا التسريع مثل مكونات نيون الداخلية معالجات ARM [14]. علاوة على ذلك ، تمكّن أطر عمل مثل Tensorflow Lite مستخدميها من استخدام العمليات الكمية مباشرة دون الحاجة إلى القلق بشأن عمليات التنفيذ ذات المستوى الأدنى.
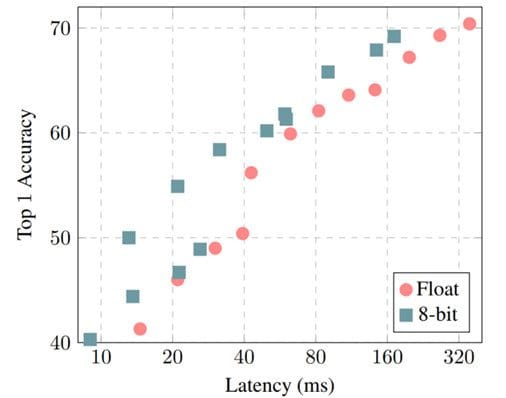
Top-1 دقة مقابل نموذج الكمون للنماذج مع وبدون تكميم. مصدر
بصرف النظر عن التقليم والكمية ، هناك تقنيات أخرى مثل عامل المصفوفة منخفض الرتبة ، وتجميع الوسائل K ، وتقاسم الوزن وما إلى ذلك والتي يتم استخدامها أيضًا بشكل نشط لضغط النموذج [15].
بشكل عام ، رأينا أنه يمكن استخدام تقنيات الضغط لتقليل أثر النموذج (الحجم ، والكمون ، وما إلى ذلك) مع استبدال بعض الجودة (الدقة ، الدقة ، الاسترجاع ، إلخ) في المقابل.
تقنيات التعلم
التقطير: كما ذكرنا سابقًا ، تحاول تقنيات التعلم تدريب نموذج بشكل مختلف من أجل الحصول على أداء أفضل. على سبيل المثال ، Hinton et al. [16] ، في عملهم الأساسي ، اكتشفوا كيف يمكن تعليم الشبكات الأصغر لاستخراجها المعرفة المظلمة من طرز / مجموعات أكبر من الطرز الأكبر. يستخدمون ملف نموذج المعلم لإنشاء تسميات ناعمة على البيانات المصنفة الموجودة.
تحدد الملصقات المرنة احتمالًا لكل فئة ممكنة بدلاً من القيم الثنائية الثابتة في البيانات الأصلية. الحدس هو أن هذه الملصقات اللينة تلتقط العلاقة بين الفئات المختلفة التي يمكن للنموذج التعلم منها. على سبيل المثال ، الشاحنة تشبه السيارة أكثر من كونها تفاحة ، والتي قد لا يتمكن النموذج من تعلمها مباشرة من الملصقات الصلبة. تتعلم شبكة الطلاب تقليل فقدان الانتروبيا على هذه الملصقات اللينة ، جنبًا إلى جنب مع الملصقات الصلبة الأصلية. يمكن تحجيم أوزان كل من وظائف الخسارة هذه بناءً على نتائج التجربة.

تقطير نموذج طالب أصغر من نموذج معلم أكبر تم تدريبه مسبقًا.
في الورقة ، Hinton et al. [16] كانوا قادرين على مطابقة دقة مجموعة من 10 نماذج لمهمة التعرف على الكلام مع نموذج مقطر واحد. هناك دراسات شاملة أخرى [17,18 ، 18] توضح التحسينات المهمة في جودة النموذج للنماذج الأصغر. كمثال ، Sanh. وآخرون. [97] تمكنوا من استخلاص نموذج الطالب الذي يحتفظ بنسبة 40٪ من أداء BERT-Base بينما يكون أصغر بنسبة 60٪ وأسرع بنسبة XNUMX٪ على وحدة المعالجة المركزية.
زيادة البيانات: بالنسبة للنماذج الكبيرة والمهام المعقدة عادةً ، كلما زادت البيانات لديك ، زادت فرص تحسين أداء نموذجك. ومع ذلك ، فإن الحصول على بيانات ذات تصنيف عالي الجودة غالبًا ما يكون بطيئًا ومكلفًا نظرًا لأنها تتطلب عادةً وجود إنسان في الحلقة. يُشار إلى التعلم من هذه البيانات التي تم تصنيفها من قبل البشر ، بالتعلم الخاضع للإشراف. إنه يعمل بشكل جيد للغاية عندما يكون لدينا الموارد لدفع ثمن الملصقات ، ولكن يمكننا وينبغي علينا القيام بعمل أفضل.
تعد زيادة البيانات طريقة رائعة لتحسين أداء النموذج. عادةً ما يتضمن إجراء تحويلات على بياناتك ، بحيث لا تتطلب إعادة تصنيف (تحويلات التسمية الثابتة). على سبيل المثال ، إذا كنت تعلم شبكتك العصبية لتصنيف صورة لاحتواء كلب أو قطة ، فلن يؤدي تدوير الصورة إلى تغيير التسمية. يمكن أن تكون التحويلات الأخرى هي التقليب الأفقي / الرأسي ، والتمدد ، والقص ، وإضافة ضوضاء Gaussian ، وما إلى ذلك. وبالمثل ، إذا كنت تكتشف المشاعر في جزء معين من النص ، فمن المحتمل ألا يؤدي إدخال خطأ مطبعي إلى تغيير التسمية.
تم استخدام مثل هذه التحولات غير المتغيرة في التسمية في نماذج التعلم العميق الشائعة. تكون مفيدة بشكل خاص عندما يكون لديك عدد كبير من الفصول و / أو أمثلة قليلة لفئات معينة.

بعض الأنواع الشائعة لزيادة البيانات. مصدر
هناك تحويلات أخرى مثل Mixup [19] ، والتي تخلط المدخلات من فئتين مختلفتين بطريقة مرجحة وتعامل الملصق على أنه تركيبة مرجحة مماثلة من الفئتين. الفكرة هي أن النموذج يجب أن يكون قادرًا على استخراج الميزات ذات الصلة بالفئتين.
هذه التقنيات تقدم بالفعل كفاءة البيانات إلى خط الأنابيب. لا يختلف الأمر كثيرًا عن تعليم الطفل تحديد الأشياء الواقعية في سياقات مختلفة.
التعلم تحت الإشراف الذاتي: هناك تقدم سريع في منطقة مجاورة ، حيث يمكننا تعلم النماذج العامة التي تتخطى تمامًا الحاجة إلى تسميات لاستخراج المعنى من البيانات. باستخدام طرق مثل التعلم التباين [20] ، يمكننا تدريب نموذج بحيث يتعلم تمثيلًا للمدخلات ، بحيث يكون للمدخلات المماثلة تمثيلات متشابهة ، بينما يجب أن يكون للمدخلات غير ذات الصلة تمثيلات متباينة للغاية. هذه التمثيلات عبارة عن نواقل ذات أبعاد n (حفلات الزفاف) والتي يمكن أن تكون مفيدة كميزات في مهام أخرى حيث قد لا يكون لدينا بيانات كافية لتدريب النماذج من البداية. يمكننا عرض الخطوة الأولى لاستخدام البيانات غير المسماة كـ التدريب قبل والخطوة التالية كـ الكون المثالى.

التعلم التقابلي. مصدر
اكتسبت هذه العملية المكونة من خطوتين للتدريب المسبق على البيانات غير المسماة والضبط الدقيق للبيانات المصنفة قبولًا سريعًا في مجتمع البرمجة اللغوية العصبية. كان ULMFiT [21] رائدًا في فكرة تدريب نموذج لغوي للأغراض العامة ، حيث يتعلم النموذج حل مهمة التنبؤ بالكلمة التالية في جملة معينة.
وجد المؤلفون أن استخدام مجموعة كبيرة من البيانات المجهزة مسبقًا ولكن غير المصنفة مثل WikiText-103 (المستمدة من صفحات Wikipedia الإنجليزية) كان اختيارًا جيدًا لخطوة ما قبل التدريب. كان هذا كافيًا للنموذج لتعلم الخصائص العامة للغة. وجد المؤلفون أن الضبط الدقيق لمثل هذا النموذج المدرَّب مسبقًا لمشكلة تصنيف ثنائي يتطلب فقط 100 مثال مُصنَّف (مقارنة بـ 10,000 مثال مُصنَّف بخلاف ذلك).
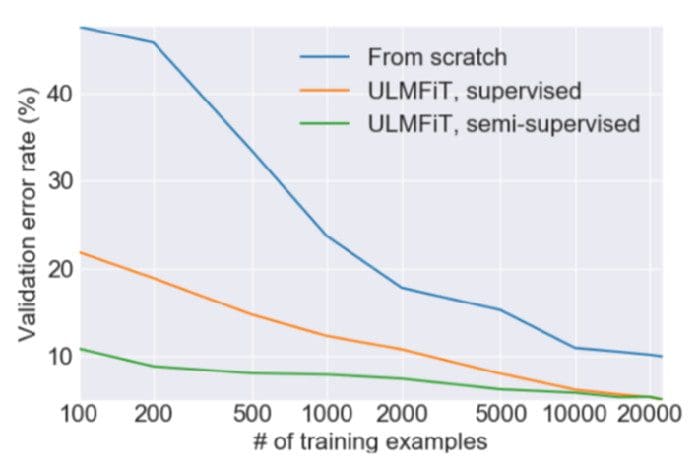
تقارب سريع مع ULMFiT. مصدر
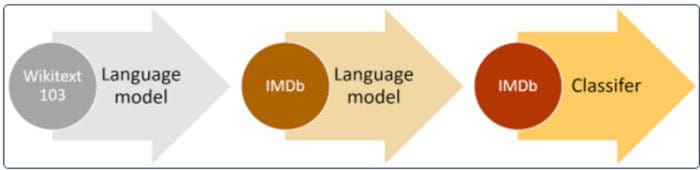
نهج عالي المستوى للتدريب المسبق على مجموعة كبيرة وضبط مجموعة البيانات ذات الصلة. مصدر
تم استكشاف هذه الفكرة أيضًا في نماذج BERT ، حيث تتضمن خطوات التدريب المسبق تعلم نموذج لغة مقنع ثنائي الاتجاه ، بحيث يتعين على النموذج التنبؤ بكلمة مفقودة في منتصف الجملة.
بشكل عام ، تساعدنا تقنيات التعلم على تحسين جودة النموذج دون التأثير على البصمة. يمكن استخدام هذا لتحسين جودة النموذج للنشر. إذا كانت جودة النموذج الأصلي مرضية ، فيمكنك أيضًا استبدال مكاسب الجودة المكتشفة حديثًا لتحسين حجم النموذج وزمن الانتقال ببساطة عن طريق تقليل عدد المعلمات في شبكتك حتى تعود إلى الحد الأدنى من جودة النموذج القابل للتطبيق.
في الجزء التالي ، سنستمر في استعراض أمثلة للأدوات والتقنيات التي تناسب مجالات التركيز الثلاثة المتبقية. أيضًا ، لا تتردد في تجاوز ملفات ورقة مسح يستكشف هذا الموضوع بالتفصيل.
مراجع حسابات
[1] يان ليكون ، جون إس دنكر ، وسارة أ سولا. 1990. تلف الدماغ الأمثل. في التقدم في أنظمة معالجة المعلومات العصبية. 598-605.
[2] باباك حسيبي ، وديفيد جي ستورك ، وجريجوري جيه وولف. 1993. جراح المخ الأمثل وتقليم الشبكة العامة. في مؤتمر IEEE الدولي حول الشبكات العصبية. IEEE ، 293-299.
[3] مايكل تشو وسويوج جوبتا. 2018. للتقليم أو عدم التقليم: استكشاف فعالية التقليم لضغط النموذج. في المؤتمر الدولي السادس لتمثيلات التعلم ، ICLR 6 ، فانكوفر ، كولومبيا البريطانية ، كندا ، 2018 أبريل - 30 مايو 3 ، إجراءات مسار ورشة العمل. OpenReview.net. https://openreview.net/forum؟id=Sy2018iIDkPM
هذا الموضوع ذو علاقة بـ:
أهم الأخبار في الثلاثين يومًا الماضية
|
|
أفلاطون. Web3 مُعاد تصوره. تضخيم ذكاء البيانات.
المصدر: https://www.kdnuggets.com/2021/07/high-performance-deep-learning-part3.html

