اليوم، الأمازون SageMaker إطلاق إصدار جديد (0.25.0) من حاويات التعلم العميق للنموذج الكبير (LMI) (DLCs) وإضافة الدعم لـ مكتبة TensorRT-LLM من NVIDIA. باستخدام هذه الترقيات، يمكنك الوصول بسهولة إلى أحدث الأدوات لتحسين نماذج اللغات الكبيرة (LLMs) على SageMaker وتحقيق فوائد أداء السعر – يعمل Amazon SageMaker LMI TensorRT-LLM DLC على تقليل زمن الوصول بنسبة 33% في المتوسط وتحسين الإنتاجية بنسبة 60% في المتوسط لنماذج Llama2-70B وFalcon-40B وCodeLlama-34B، مقارنة بالإصدار السابق.
شهدت LLMs نموًا غير مسبوق في شعبيتها عبر مجموعة واسعة من التطبيقات. ومع ذلك، غالبًا ما تكون هذه النماذج كبيرة جدًا بحيث لا يمكن وضعها على مسرع واحد أو جهاز GPU واحد، مما يجعل من الصعب تحقيق الاستدلال والقياس بزمن وصول منخفض. يقدم SageMaker محتويات LMI DLC لمساعدتك على تحقيق أقصى قدر من الاستفادة من الموارد المتاحة وتحسين الأداء. توفر أحدث محتويات LMI DLC دعمًا متواصلًا للتجميع لطلبات الاستدلال لتحسين الإنتاجية، وعمليات استدلال جماعية فعالة لتحسين زمن الوصول، Paged Attention V2 (الذي يعمل على تحسين أداء أعباء العمل بأطوال تسلسلية أطول)، وأحدث مكتبة TensorRT-LLM من NVIDIA لتحقيق أقصى استفادة الأداء على وحدات معالجة الرسومات. تقدم LMI DLCs واجهة منخفضة الكود تعمل على تبسيط عملية التجميع باستخدام TensorRT-LLM من خلال طلب معرف النموذج ومعلمات النموذج الاختيارية فقط؛ تتم إدارة كل الأعباء الثقيلة المطلوبة لبناء نموذج TensorRT-LLM المُحسّن وإنشاء نموذج الريبو بواسطة LMI DLC. بالإضافة إلى ذلك، يمكنك استخدام أحدث تقنيات التكميم — GPTQ، وAWQ، وSmoothQuant — المتوفرة مع LMI DLC. ونتيجة لذلك، مع LMI DLCs على SageMaker، يمكنك تسريع الوقت إلى القيمة لتطبيقات الذكاء الاصطناعي التوليدية الخاصة بك وتحسين LLMs للأجهزة التي تختارها لتحقيق أفضل أداء من حيث السعر في فئتها.
في هذا المنشور، نتعمق في الميزات الجديدة مع الإصدار الأخير من LMI DLCs، ونناقش معايير الأداء، ونحدد الخطوات المطلوبة لنشر LLMs مع LMI DLCs لتحقيق أقصى قدر من الأداء وتقليل التكاليف.
ميزات جديدة مع المحتوى القابل للتنزيل SageMaker LMI
في هذا القسم، نناقش ثلاث ميزات جديدة مع المحتوى القابل للتنزيل (DLC) لـ SageMaker LMI.
يدعم SageMaker LMI الآن TensorRT-LLM
تقدم SageMaker الآن TensorRT-LLM من NVIDIA كجزء من أحدث إصدار LMI DLC (0.25.0)، مما يتيح أحدث التحسينات مثل SmoothQuant وFP8 والدفع المستمر لـ LLMs عند استخدام وحدات معالجة الرسومات NVIDIA. يفتح TensorRT-LLM الباب أمام تجارب زمن الوصول المنخفض للغاية التي يمكنها تحسين الأداء بشكل كبير. تدعم TensorRT-LLM SDK عمليات النشر التي تتراوح من تكوينات وحدة معالجة الرسومات المفردة إلى تكوينات وحدات معالجة الرسومات المتعددة، مع إمكانية تحقيق مكاسب إضافية في الأداء من خلال تقنيات مثل توازي الموتر. لاستخدام مكتبة TensorRT-LLM، اختر TensorRT-LLM DLC من المكتبة المتوفرة DLCs LMI وحدد engine=MPI من بين أمور أخرى إعدادات مثل option.model_id. يوضح الرسم البياني التالي حزمة التكنولوجيا TensorRT-LLM.

كفاءة العمليات الجماعية الاستدلال
في النشر النموذجي لـ LLMs، يتم توزيع معلمات النموذج عبر مسرعات متعددة لاستيعاب متطلبات نموذج كبير لا يمكن احتواؤه على مسرع واحد. وهذا يعزز سرعة الاستدلال من خلال تمكين كل مسرع من إجراء حسابات جزئية بالتوازي. وبعد ذلك يتم إدخال عملية جماعية لتجميع هذه النتائج الجزئية في نهاية هذه العمليات، وإعادة توزيعها بين المسرعات.
بالنسبة لأنواع مثيلات P4D، يقوم SageMaker بتنفيذ عملية جماعية جديدة تعمل على تسريع الاتصال بين وحدات معالجة الرسومات. ونتيجة لذلك، تحصل على زمن وصول أقل وإنتاجية أعلى باستخدام أحدث محتويات LMI DLC مقارنة بالإصدارات السابقة. علاوة على ذلك، يتم دعم هذه الميزة بشكل جاهز مع محتويات LMI DLC، ولا تحتاج إلى تكوين أي شيء لاستخدام هذه الميزة لأنها مضمنة في محتويات SageMaker LMI DLC ومتاحة حصريًا لـ Amazon SageMaker.
دعم الكمي
تدعم الآن محتويات SageMaker LMI القابلة للتنزيل أحدث تقنيات التكميم، بما في ذلك النماذج مسبقة التكميم مع GPTQ، وتكميم الوزن المدرك للتنشيط (AWQ)، والتكميم في الوقت المناسب مثل SmoothQuant.
تسمح GPTQ لشركة LMI بتشغيل نماذج INT3 وINT4 المشهورة من Hugging Face. إنه يوفر أصغر أوزان نموذجية ممكنة يمكن وضعها على وحدة معالجة رسومات واحدة/وحدة معالجة رسومات متعددة. تدعم محتويات LMI DLC أيضًا استدلال AWQ، مما يسمح بسرعة استدلال أسرع. أخيرًا، تدعم الآن محتويات LMI DLC SmoothQuant، التي تسمح بتكميم INT8 لتقليل أثر الذاكرة والتكلفة الحسابية للنماذج مع الحد الأدنى من فقدان الدقة. حاليًا، نسمح لك بإجراء التحويل في الوقت المناسب لنماذج SmoothQuant دون أي خطوات إضافية. يجب تحديد كمية GPTQ وAWQ باستخدام مجموعة بيانات لاستخدامها مع LMI DLCs. يمكنك أيضًا اختيار نماذج GPTQ وAWQ المشهورة مسبقة الكمية لاستخدامها في LMI DLCs. لاستخدام SmoothQuant، قم بتعيين option.quantize=smoothquanر مع engine=DeepSpeed in serving.properties. يوجد نموذج دفتر ملاحظات يستخدم SmoothQuant لاستضافة GPT-Neox على ml.g5.12xlarge على GitHub جيثب:.
استخدام المحتوى القابل للتنزيل (DLC) لـ SageMaker LMI
يمكنك نشر LLMs الخاصة بك على SageMaker باستخدام LMI DLCs 0.25.0 الجديدة دون أي تغييرات على التعليمات البرمجية الخاصة بك. تستخدم محتويات SageMaker LMI DLC خدمة DJL لخدمة النموذج الخاص بك للاستدلال. للبدء، تحتاج فقط إلى إنشاء ملف التكوين الذي يحدد إعدادات مثل مكتبات موازاة النماذج وتحسين الاستدلال للاستخدام. للحصول على الإرشادات والبرامج التعليمية حول استخدام المحتوى القابل للتنزيل SageMaker LMI DLC، راجع التوازي النموذجي واستدلال النموذج الكبير ولنا قائمة بمحتوى SageMaker LMI القابل للتنزيل (DLC) المتاح.
تتضمن حاوية DeepSpeed مكتبة تسمى LMI Distributed Inference Library (LMI-Dist). LMI-Dist هي مكتبة استدلال تُستخدم لتشغيل استدلال نموذج كبير مع أفضل تحسين مستخدم في مكتبات مختلفة مفتوحة المصدر، عبر vLLM، وText-Generation-Inference (حتى الإصدار 0.9.4)، وFasterTransformer، وDeepSpeed. تتضمن هذه المكتبة تقنيات شائعة مفتوحة المصدر مثل FlashAttention وPagedAttention وFusedKernel ونواة اتصالات GPU الفعالة لتسريع النموذج وتقليل استهلاك الذاكرة.
TensorRT LLM هي مكتبة مفتوحة المصدر أصدرتها NVIDIA في أكتوبر 2023. لقد قمنا بتحسين مكتبة TensorRT-LLM لتسريع الاستدلال وأنشأنا مجموعة أدوات لتبسيط تجربة المستخدم من خلال دعم تحويل النماذج في الوقت المناسب. تمكن مجموعة الأدوات هذه المستخدمين من توفير معرف نموذج Hugging Face ونشر النموذج من البداية إلى النهاية. كما أنه يدعم الخلط المستمر مع التدفق. يمكنك توقع حوالي 1-2 دقيقة لتجميع نماذج Llama-2 7B و13B، وحوالي 7 دقائق للنموذج 70B. إذا كنت تريد تجنب عبء التجميع هذا أثناء إعداد نقطة نهاية SageMaker وتوسيع نطاق المثيلات، فنوصي باستخدام التجميع المسبق (AOT) مع شركائنا البرنامج التعليمي لإعداد النموذج. نحن نقبل أيضًا أي نموذج TensorRT LLM مصمم لخادم Triton والذي يمكن استخدامه مع LMI DLCs.
نتائج قياس الأداء
قمنا بمقارنة أداء الإصدار الأخير من المحتوى القابل للتنزيل (DLC) من SageMaker LMI (0.25.0) بالإصدار السابق (0.23.0). لقد أجرينا تجارب على نماذج Llama-2 70B وFalcon 40B وCodeLlama 34B لإظهار زيادة الأداء باستخدام TensorRT-LLM وعمليات الاستدلال الجماعية الفعالة (المتوفرة على SageMaker).
تأتي حاويات SageMaker LMI مزودة ببرنامج نصي للمعالج الافتراضي لتحميل النماذج واستضافتها، مما يوفر خيار التعليمات البرمجية المنخفضة. لديك أيضًا خيار إحضار البرنامج النصي الخاص بك إذا كنت بحاجة إلى إجراء أي تخصيصات لخطوات تحميل النموذج. تحتاج إلى تمرير المعلمات المطلوبة في ملف serving.properties ملف. يحتوي هذا الملف على التكوينات المطلوبة لخادم نموذج Deep Java Library (DJL) لتنزيل النموذج واستضافته. الكود التالي هو serving.properties تستخدم للنشر لدينا وقياس الأداء:
• engine يتم استخدام المعلمة لتحديد محرك وقت التشغيل لخادم طراز DJL. يمكننا تحديد معرف نموذج Hugging Face أو خدمة تخزين أمازون البسيطة (Amazon S3) موقع النموذج باستخدام model_id معامل. يتم استخدام معلمة المهمة لتحديد مهمة معالجة اللغة الطبيعية (NLP). ال tensor_parallel_degree تحدد المعلمة عدد الأجهزة التي يتم توزيع الوحدات المتوازية عليها. ال use_custom_all_reduce تم تعيين المعلمة على true لمثيلات GPU التي تم تمكين NVLink فيها لتسريع استنتاج النموذج. يمكنك ضبط هذا لـ P4D، وP4de، وP5، ووحدات معالجة الرسومات الأخرى المتصلة بـ NVLink. ال output_formatter تحدد المعلمة تنسيق الإخراج. ال max_rolling_batch_size تحدد المعلمة الحد الأقصى لعدد الطلبات المتزامنة. ال model_loading_timeout يضبط قيمة المهلة لتنزيل النموذج وتحميله لتقديم الاستدلال. لمزيد من التفاصيل حول خيارات التكوين، راجع التكوينات والإعدادات.
اللاما-2 70ب
فيما يلي نتائج مقارنة أداء Llama-2 70B. تم تقليل زمن الوصول بنسبة 28% وزيادة الإنتاجية بنسبة 44% للتزامن 16، مع LMI TensorRT LLM DLC الجديد.


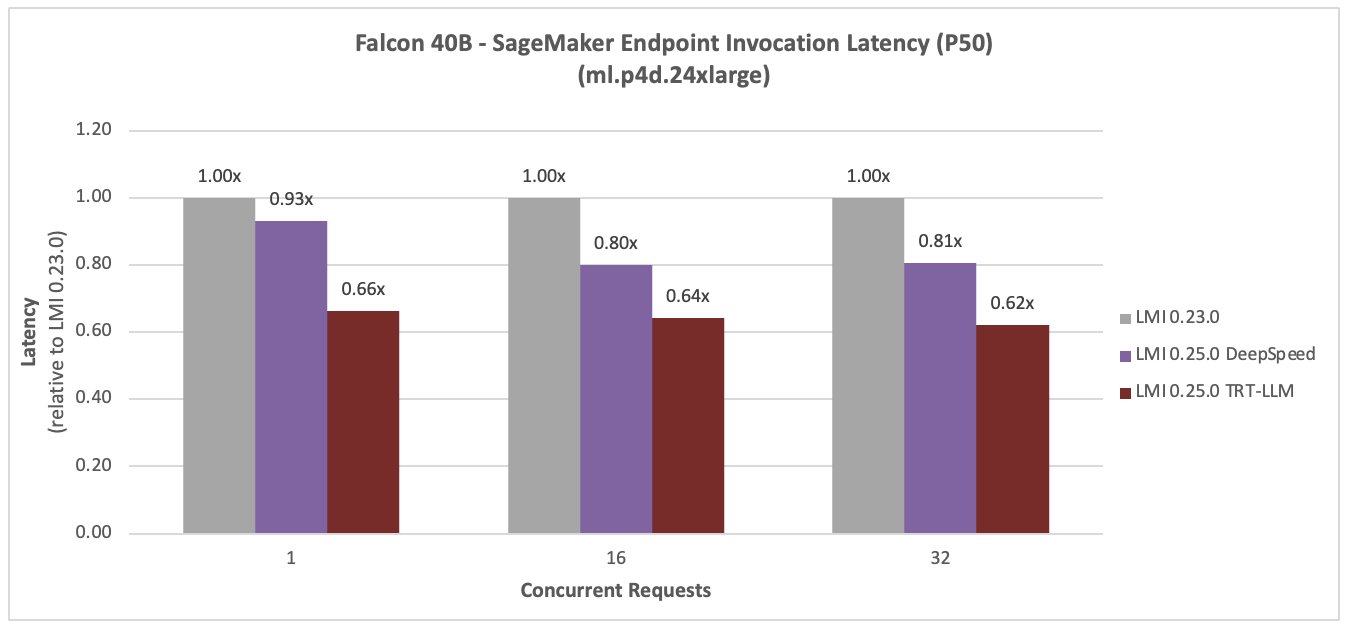
الصقر 40B
الأرقام التالية تقارن Falcon 40B. تم تقليل زمن الوصول بنسبة 36% وزيادة الإنتاجية بنسبة 59% للتزامن 16، مع LMI TensorRT LLM DLC الجديد.

كود لاما 34 ب
الأرقام التالية تقارن CodeLlama 34B. تم تقليل زمن الوصول بنسبة 36% وزيادة الإنتاجية بنسبة 77% للتزامن 16، مع LMI TensorRT LLM DLC الجديد.


التكوين الموصى به والحاوية لاستضافة LLMs
مع الإصدار الأخير، يوفر SageMaker حاويتين: 0.25.0-deepspeed و0.25.0-tensorrtllm. تحتوي حاوية DeepSpeed على DeepSpeed، مكتبة الاستدلال الموزعة LMI. تتضمن حاوية TensorRT-LLM مكتبة TensorRT-LLM من NVIDIA لتسريع الاستدلال LLM.
نوصي بتكوين النشر الموضح في الرسم البياني التالي.

للبدء، راجع نماذج دفاتر الملاحظات:
وفي الختام
في هذا المنشور، أظهرنا كيف يمكنك استخدام محتويات SageMaker LMI DLC لتحسين LLMs لحالة استخدام عملك وتحقيق فوائد أداء السعر. لمعرفة المزيد حول إمكانيات LMI DLC، راجع التوازي النموذجي واستدلال النموذج الكبير. يسعدنا أن نرى كيف تستخدم هذه الإمكانات الجديدة من Amazon SageMaker.
عن المؤلفين
 مايكل نجوين هو أحد كبار مهندسي حلول الشركات الناشئة في AWS، وهو متخصص في الاستفادة من الذكاء الاصطناعي/التعلم الآلي لدفع الابتكار وتطوير حلول الأعمال على AWS. حصل مايكل على 12 شهادة من AWS وحاصل على بكالوريوس/ماجستير في الهندسة الكهربائية/هندسة الكمبيوتر وماجستير في إدارة الأعمال من جامعة ولاية بنسلفانيا، وجامعة بينجهامتون، وجامعة ديلاوير.
مايكل نجوين هو أحد كبار مهندسي حلول الشركات الناشئة في AWS، وهو متخصص في الاستفادة من الذكاء الاصطناعي/التعلم الآلي لدفع الابتكار وتطوير حلول الأعمال على AWS. حصل مايكل على 12 شهادة من AWS وحاصل على بكالوريوس/ماجستير في الهندسة الكهربائية/هندسة الكمبيوتر وماجستير في إدارة الأعمال من جامعة ولاية بنسلفانيا، وجامعة بينجهامتون، وجامعة ديلاوير.
 ريشابه راي شودري هو مدير أول للمنتجات في Amazon SageMaker ، ويركز على استدلال التعلم الآلي. إنه متحمس للابتكار وبناء تجارب جديدة لعملاء التعلم الآلي على AWS للمساعدة في توسيع أعباء العمل لديهم. في أوقات فراغه ، يستمتع بالسفر والطهي. يمكنك أن تجده على لينكدين:.
ريشابه راي شودري هو مدير أول للمنتجات في Amazon SageMaker ، ويركز على استدلال التعلم الآلي. إنه متحمس للابتكار وبناء تجارب جديدة لعملاء التعلم الآلي على AWS للمساعدة في توسيع أعباء العمل لديهم. في أوقات فراغه ، يستمتع بالسفر والطهي. يمكنك أن تجده على لينكدين:.
 تشينغ لان هو مهندس تطوير برمجيات في AWS. لقد كان يعمل على العديد من المنتجات الصعبة في Amazon ، بما في ذلك حلول استدلال ML عالية الأداء ونظام تسجيل عالي الأداء. أطلق فريق Qing بنجاح أول نموذج مليار معلمة في إعلانات أمازون بزمن انتقال منخفض للغاية مطلوب. تتمتع Qing بمعرفة متعمقة حول تحسين البنية التحتية وتسريع التعلم العميق.
تشينغ لان هو مهندس تطوير برمجيات في AWS. لقد كان يعمل على العديد من المنتجات الصعبة في Amazon ، بما في ذلك حلول استدلال ML عالية الأداء ونظام تسجيل عالي الأداء. أطلق فريق Qing بنجاح أول نموذج مليار معلمة في إعلانات أمازون بزمن انتقال منخفض للغاية مطلوب. تتمتع Qing بمعرفة متعمقة حول تحسين البنية التحتية وتسريع التعلم العميق.
 جيان شنغ هو مهندس تطوير برمجيات في Amazon Web Services وقد عمل على العديد من الجوانب الرئيسية لأنظمة التعلم الآلي. لقد كان مساهمًا رئيسيًا في خدمة SageMaker Neo، مع التركيز على تجميع التعلم العميق وتحسين وقت تشغيل الإطار. قام مؤخرًا بتوجيه جهوده وساهم في تحسين نظام التعلم الآلي لاستدلال النماذج الكبيرة.
جيان شنغ هو مهندس تطوير برمجيات في Amazon Web Services وقد عمل على العديد من الجوانب الرئيسية لأنظمة التعلم الآلي. لقد كان مساهمًا رئيسيًا في خدمة SageMaker Neo، مع التركيز على تجميع التعلم العميق وتحسين وقت تشغيل الإطار. قام مؤخرًا بتوجيه جهوده وساهم في تحسين نظام التعلم الآلي لاستدلال النماذج الكبيرة.
 فيفيك جانجاساني هو مهندس حلول بدء التشغيل AI/ML للشركات الناشئة في مجال الذكاء الاصطناعي التوليدي في AWS. إنه يساعد الشركات الناشئة في GenAI على بناء حلول مبتكرة باستخدام خدمات AWS والحوسبة المتسارعة. يركز حاليًا على تطوير استراتيجيات لضبط وتحسين أداء الاستدلال لنماذج اللغات الكبيرة. في أوقات فراغه، يستمتع فيفيك بالمشي لمسافات طويلة ومشاهدة الأفلام وتجربة المأكولات المختلفة.
فيفيك جانجاساني هو مهندس حلول بدء التشغيل AI/ML للشركات الناشئة في مجال الذكاء الاصطناعي التوليدي في AWS. إنه يساعد الشركات الناشئة في GenAI على بناء حلول مبتكرة باستخدام خدمات AWS والحوسبة المتسارعة. يركز حاليًا على تطوير استراتيجيات لضبط وتحسين أداء الاستدلال لنماذج اللغات الكبيرة. في أوقات فراغه، يستمتع فيفيك بالمشي لمسافات طويلة ومشاهدة الأفلام وتجربة المأكولات المختلفة.
 هاريش تومالاشيرلا هو مهندس برمجيات مع فريق أداء التعلم العميق في SageMaker. وهو يعمل على هندسة الأداء لخدمة نماذج اللغات الكبيرة بكفاءة على SageMaker. وفي أوقات فراغه، يستمتع بالجري وركوب الدراجات وتسلق الجبال.
هاريش تومالاشيرلا هو مهندس برمجيات مع فريق أداء التعلم العميق في SageMaker. وهو يعمل على هندسة الأداء لخدمة نماذج اللغات الكبيرة بكفاءة على SageMaker. وفي أوقات فراغه، يستمتع بالجري وركوب الدراجات وتسلق الجبال.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-llms-with-new-amazon-sagemaker-containers/

