الأمازون SageMaker نقاط النهاية متعددة النماذج (MMEs) هي قدرة مُدارة بالكامل لاستدلال SageMaker والتي تتيح لك نشر آلاف النماذج على نقطة نهاية واحدة. في السابق، قامت MMEs بتخصيص قوة حوسبة وحدة المعالجة المركزية للنماذج بشكل ثابت بغض النظر عن حمل حركة مرور النموذج، وذلك باستخدام خادم متعدد النماذج (MMS) كخادم نموذجي لها. في هذا المنشور، نناقش حلاً يمكن من خلاله لـ MME ضبط قوة الحوسبة المخصصة لكل نموذج ديناميكيًا بناءً على نمط حركة المرور الخاص بالنموذج. يمكّنك هذا الحل من استخدام الحوسبة الأساسية لـ MMEs بشكل أكثر كفاءة وتوفير التكاليف.
تقوم MMEs بتحميل النماذج وتفريغها ديناميكيًا بناءً على حركة المرور الواردة إلى نقطة النهاية. عند استخدام خدمة MMS كخادم نموذجي، تقوم MMEs بتخصيص عدد ثابت من العاملين النموذجيين لكل نموذج. لمزيد من المعلومات، راجع أنماط استضافة النماذج في Amazon SageMaker ، الجزء 3: تشغيل الاستدلال متعدد النماذج وتحسينه باستخدام نقاط النهاية متعددة النماذج من Amazon SageMaker.
ومع ذلك، يمكن أن يؤدي هذا إلى بعض المشكلات عندما يكون نمط حركة المرور الخاص بك متغيرًا. لنفترض أن لديك نماذج فردية أو نماذج قليلة تتلقى قدرًا كبيرًا من حركة المرور. يمكنك تكوين MMS لتخصيص عدد كبير من العاملين لهذه النماذج، ولكن يتم تعيين هذا لجميع النماذج خلف MME لأنه تكوين ثابت. ويؤدي هذا إلى استخدام عدد كبير من العاملين لحوسبة الأجهزة، حتى النماذج الخاملة. يمكن أن تحدث المشكلة المعاكسة إذا قمت بتعيين قيمة صغيرة لعدد العمال. لن تحتوي النماذج الشائعة على عدد كافٍ من العمال على مستوى خادم النموذج لتخصيص ما يكفي من الأجهزة بشكل صحيح خلف نقطة النهاية لهذه النماذج. المشكلة الرئيسية هي أنه من الصعب أن تظل غير محدد لنمط حركة المرور إذا لم تتمكن من قياس العاملين لديك ديناميكيًا على مستوى الخادم النموذجي لتخصيص المقدار اللازم من الحوسبة.
يستخدم الحل الذي نناقشه في هذا المنشور DJLServing كخادم نموذجي، والذي يمكن أن يساعد في التخفيف من بعض المشكلات التي ناقشناها وتمكين القياس لكل نموذج وتمكين MMEs من أن تكون غير محددة لأنماط حركة المرور.
الهندسة المعمارية MME
تتيح لك SageMaker MMEs إمكانية نشر نماذج متعددة خلف نقطة نهاية استدلال واحدة قد تحتوي على مثيل واحد أو أكثر. تم تصميم كل مثيل لتحميل نماذج متعددة وخدمتها بما يصل إلى ذاكرته وسعة وحدة المعالجة المركزية/وحدة معالجة الرسومات الخاصة به. باستخدام هذه البنية، يمكن لأعمال البرمجيات كخدمة (SaaS) كسر التكلفة الخطية المتزايدة لاستضافة نماذج متعددة وتحقيق إعادة استخدام البنية التحتية بما يتوافق مع نموذج الاستئجار المتعدد المطبق في مكان آخر في حزمة التطبيقات. ويوضح الرسم البياني التالي هذه البنية.
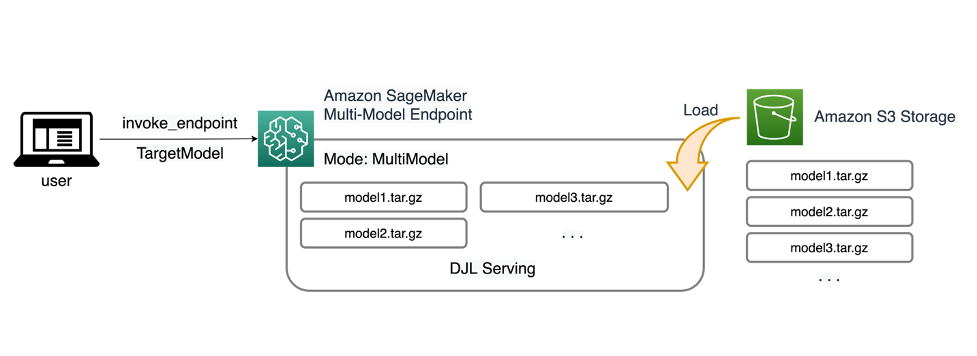
يقوم SageMaker MME بتحميل النماذج ديناميكيًا من خدمة تخزين أمازون البسيطة (Amazon S3) عند استدعائه، بدلاً من تنزيل جميع النماذج عند إنشاء نقطة النهاية لأول مرة. ونتيجة لذلك، قد يشهد الاستدعاء الأولي للنموذج زمن استجابة استدلالي أعلى من الاستدلالات اللاحقة، والتي تكتمل بزمن انتقال منخفض. إذا تم تحميل النموذج بالفعل على الحاوية عند استدعائه، فسيتم تخطي خطوة التنزيل وسيقوم النموذج بإرجاع الاستدلالات بزمن انتقال منخفض. على سبيل المثال، افترض أن لديك نموذجًا يتم استخدامه عدة مرات فقط في اليوم. ويتم تحميلها تلقائيًا عند الطلب، بينما يتم الاحتفاظ بالنماذج التي يتم الوصول إليها بشكل متكرر في الذاكرة واستدعائها بزمن انتقال منخفض باستمرار.
خلف كل MME توجد نماذج استضافة نموذجية، كما هو موضح في الرسم البياني التالي. تقوم هذه المثيلات بتحميل وإخراج نماذج متعددة من وإلى الذاكرة بناءً على أنماط حركة المرور إلى النماذج.
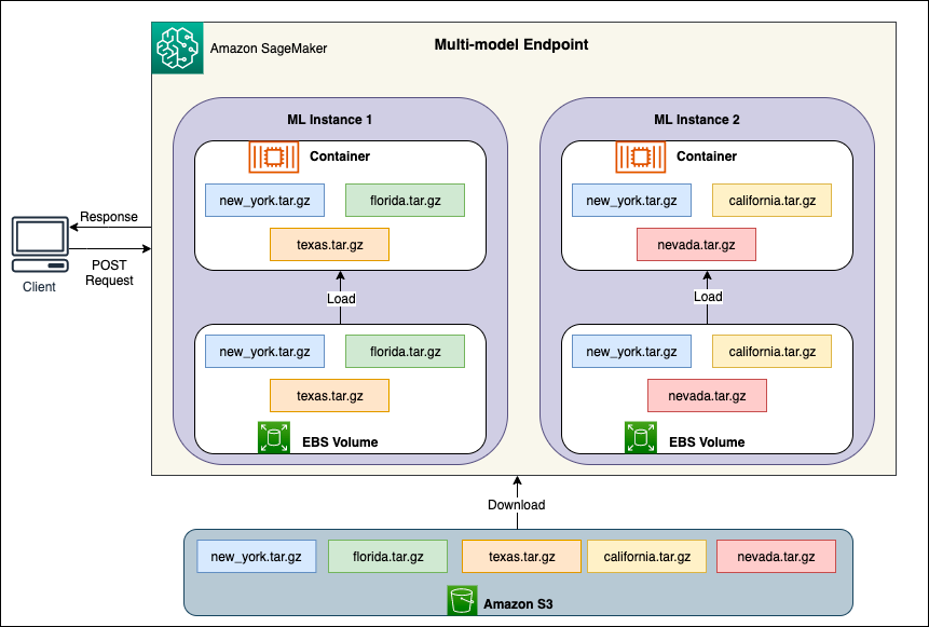
يستمر SageMaker في توجيه طلبات الاستدلال الخاصة بالنموذج إلى المثيل الذي تم فيه تحميل النموذج بالفعل بحيث يتم تقديم الطلبات من نسخة نموذج مخبأة (راجع الرسم البياني التالي، الذي يوضح مسار الطلب لطلب التنبؤ الأول مقابل التنبؤ المخزن مؤقتًا) مسار الطلب). ومع ذلك، إذا تلقى النموذج العديد من طلبات الاستدعاء، وكانت هناك مثيلات إضافية لـ MME، فسيقوم SageMaker بتوجيه بعض الطلبات إلى مثيل آخر لاستيعاب الزيادة. للاستفادة من القياس التلقائي للنماذج في SageMaker، تأكد من حصولك على ذلك ضبط التحجيم التلقائي للمثال لتوفير سعة مثيل إضافية. قم بإعداد سياسة التحجيم على مستوى نقطة النهاية الخاصة بك باستخدام معلمات مخصصة أو استدعاءات في الدقيقة (مستحسن) لإضافة المزيد من المثيلات إلى أسطول نقاط النهاية.

نظرة عامة على الخادم النموذجي
الخادم النموذجي هو أحد مكونات البرنامج الذي يوفر بيئة تشغيل لنشر نماذج التعلم الآلي (ML) وخدمتها. إنه بمثابة واجهة بين النماذج المدربة وتطبيقات العميل التي ترغب في إجراء تنبؤات باستخدام تلك النماذج.
الغرض الأساسي من الخادم النموذجي هو السماح بالتكامل السهل والنشر الفعال لنماذج تعلم الآلة في أنظمة الإنتاج. بدلاً من تضمين النموذج مباشرة في تطبيق أو إطار عمل محدد، يوفر خادم النموذج نظامًا أساسيًا مركزيًا حيث يمكن نشر نماذج متعددة وإدارتها وخدمتها.
تقدم الخوادم النموذجية عادةً الوظائف التالية:
- تحميل النموذج - يقوم الخادم بتحميل نماذج ML المدربة في الذاكرة، مما يجعلها جاهزة لتقديم التنبؤات.
- واجهة برمجة تطبيقات الاستدلال - يعرض الخادم واجهة برمجة التطبيقات (API) التي تسمح لتطبيقات العميل بإرسال بيانات الإدخال وتلقي التنبؤات من النماذج المنشورة.
- التحجيم – تم تصميم الخوادم النموذجية للتعامل مع الطلبات المتزامنة من عملاء متعددين. أنها توفر آليات للمعالجة المتوازية وإدارة الموارد بكفاءة لضمان إنتاجية عالية وزمن وصول منخفض.
- التكامل مع المحركات الخلفية - تحتوي الخوادم النموذجية على عمليات تكامل مع أطر عمل الواجهة الخلفية مثل DeepSpeed وFasterTransformer لتقسيم النماذج الكبيرة وتشغيل الاستدلال المحسّن للغاية.
هندسة دي جي إل
خدمة DJL هو خادم مفتوح المصدر وعالي الأداء ونموذج عالمي. تم بناء خدمة DJL على رأس دي جي، مكتبة للتعلم العميق مكتوبة بلغة البرمجة جافا. يمكن أن يستغرق نموذجًا للتعلم العميق أو عدة نماذج أو مسارات عمل وإتاحتها من خلال نقطة نهاية HTTP. تدعم خدمة DJL نشر النماذج من أطر عمل متعددة مثل PyTorch وTensorFlow وApache MXNet وONNX وTensorRT وHugging Face Transformers وDeepSpeed وFasterTransformer والمزيد.
تقدم خدمة DJL العديد من الميزات التي تتيح لك نشر نماذجك بأداء عالٍ:
- سهولة الاستخدام – خدمة DJL يمكن أن تخدم معظم الموديلات خارج الصندوق. ما عليك سوى إحضار العناصر النموذجية، ويمكن لشركة DJL Serving استضافتها.
- دعم الأجهزة المتعددة والمسرع - تدعم خدمة DJL نشر النماذج على وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU) و استدلال AWS.
- الأداء - تعمل خدمة DJL على تشغيل استدلال متعدد الخيوط في JVM واحد لتعزيز الإنتاجية.
- الخلط الديناميكي - يدعم DJL Serving الدفع الديناميكي لزيادة الإنتاجية.
- التحجيم التلقائي - ستقوم خدمة DJL تلقائيًا بتوسيع نطاق العمال لأعلى ولأسفل بناءً على حمل حركة المرور.
- دعم متعدد المحركات - يمكن لـ DJL Serving استضافة نماذج في نفس الوقت باستخدام أطر عمل مختلفة (مثل PyTorch وTensorFlow).
- نماذج المجموعة وسير العمل - تدعم خدمة DJL نشر مسارات عمل معقدة تتألف من نماذج متعددة، وتقوم بتشغيل أجزاء من سير العمل على وحدة المعالجة المركزية وأجزاء على وحدة معالجة الرسومات. يمكن للنماذج الموجودة في سير العمل استخدام أطر عمل مختلفة.
على وجه الخصوص، فإن ميزة القياس التلقائي في DJL Serving تجعل من السهل ضمان تغيير حجم النماذج بشكل مناسب لحركة المرور الواردة. افتراضيًا، تحدد خدمة DJL الحد الأقصى لعدد العاملين للنموذج الذي يمكن دعمه بناءً على الأجهزة المتاحة (مراكز وحدة المعالجة المركزية وأجهزة GPU). يمكنك تعيين الحدود الدنيا والعليا لكل نموذج للتأكد من أنه يمكن دائمًا تقديم الحد الأدنى من مستوى حركة المرور، وأن النموذج الواحد لا يستهلك جميع الموارد المتاحة.
تستخدم خدمة DJL أ Netty الواجهة الأمامية أعلى تجمعات مؤشرات ترابط العاملين في الواجهة الخلفية. تستخدم الواجهة الأمامية إعداد Netty واحدًا مع عدة HttpRequestHandlers. ستوفر معالجات الطلب المختلفة الدعم لـ واجهة برمجة تطبيقات الاستدلال, API الإدارةأو واجهات برمجة التطبيقات الأخرى المتاحة من المكونات الإضافية المختلفة.
تعتمد الواجهة الخلفية على WorkLoadManager وحدة (WLM). تعتني WLM بسلاسل العمليات المتعددة لكل نموذج بالإضافة إلى التجميع وتوجيه الطلب إليها. عندما يتم تقديم نماذج متعددة، يتحقق WLM من حجم قائمة انتظار طلب الاستدلال لكل نموذج أولاً. إذا كان حجم قائمة الانتظار أكبر من ضعف حجم دفعة النموذج، تقوم WLM بزيادة عدد العمال المعينين لهذا النموذج.
حل نظرة عامة
يختلف تنفيذ DJL مع MME عن إعداد MMS الافتراضي. بالنسبة إلى خدمة DJL مع MME، نقوم بضغط الملفات التالية بتنسيق model.tar.gz الذي يتوقعه SageMaker Inference:
- model.joblib - بالنسبة لهذا التنفيذ، نقوم مباشرة بدفع البيانات الوصفية للنموذج إلى كرة القطران. في هذه الحالة، نحن نعمل مع أ
.joblibملف، لذلك قمنا بتوفير هذا الملف في كرة القطران الخاصة بنا حتى يقرأه البرنامج النصي للاستدلال. إذا كانت القطعة الأثرية كبيرة جدًا، فيمكنك أيضًا دفعها إلى Amazon S3 والإشارة إلى ذلك في تكوين العرض الذي تحدده لـ DJL. - خدمة - هنا يمكنك تكوين أي نموذج متعلق بالخادم متغيرات البيئة. تكمن قوة DJL هنا في أنه يمكنك تكوينها
minWorkersوmaxWorkersلكل نموذج القطران. يسمح هذا لكل نموذج بالتوسع لأعلى ولأسفل على مستوى خادم النموذج. على سبيل المثال، إذا كان النموذج المفرد يتلقى غالبية حركة المرور لـ MME، فسيقوم خادم النموذج بتوسيع نطاق العاملين ديناميكيًا. في هذا المثال، لا نقوم بتكوين هذه المتغيرات ونسمح لشركة DJL بتحديد العدد الضروري من العمال اعتمادًا على نمط حركة المرور لدينا. - model.py - هذا هو البرنامج النصي الاستدلالي لأي معالجة مسبقة أو معالجة لاحقة مخصصة ترغب في تنفيذها. يتوقع model.py أن يتم تغليف المنطق الخاص بك بطريقة مقبض بشكل افتراضي.
- المتطلبات.txt (اختياري) - بشكل افتراضي، يتم تثبيت DJL مع PyTorch، ولكن يمكن دفع أي تبعيات إضافية تحتاجها هنا.
في هذا المثال، نعرض قوة DJL مع MME من خلال أخذ عينة من نموذج SKLearn. نقوم بإجراء تدريب باستخدام هذا النموذج ثم نقوم بإنشاء 1,000 نسخة من هذا النموذج لدعم MME الخاص بنا. نعرض بعد ذلك كيف يمكن لـ DJL التوسع ديناميكيًا للتعامل مع أي نوع من أنماط حركة المرور التي قد تتلقاها MME الخاصة بك. يمكن أن يشمل ذلك توزيعًا متساويًا لحركة المرور عبر جميع النماذج أو حتى بعض النماذج الشائعة التي تتلقى غالبية حركة المرور. يمكنك العثور على كل الكود في ما يلي جيثب ريبو.
المتطلبات الأساسية المسبقة
في هذا المثال، نستخدم مثيل دفتر ملاحظات SageMaker مع نواة conda_python3 ومثيل ml.c5.xlarge. لإجراء اختبارات التحميل، يمكنك استخدام الأمازون الحوسبة المرنة السحابية (Amazon EC2) أو مثيل دفتر ملاحظات SageMaker أكبر. في هذا المثال، نقوم بتوسيع النطاق إلى أكثر من ألف معاملة في الثانية (TPS)، لذا نقترح الاختبار على مثيل EC2 أثقل مثل ml.c5.18xlarge بحيث يكون لديك المزيد من الحوسبة للعمل معها.
إنشاء قطعة أثرية نموذجية
نحتاج أولاً إلى إنشاء قطعة أثرية نموذجية وبيانات نستخدمها في هذا المثال. في هذه الحالة، نقوم بإنشاء بعض البيانات الاصطناعية باستخدام NumPy والتدريب باستخدام نموذج الانحدار الخطي SKLearn مع مقتطف التعليمات البرمجية التالي:
بعد تشغيل التعليمات البرمجية السابقة، يجب أن يكون لديك model.joblib الملف الذي تم إنشاؤه في بيئتك المحلية.
اسحب صورة DJL Docker
إن Docker image djl-inference:0.23.0-cpu-full-v1.0 هي حاوية تقديم DJL المستخدمة في هذا المثال. يمكنك ضبط عنوان URL التالي وفقًا لمنطقتك:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
اختياريًا، يمكنك أيضًا استخدام هذه الصورة كصورة أساسية وتوسيعها لإنشاء صورة Docker الخاصة بك عليها سجل الأمازون المرنة للحاويات (Amazon ECR) مع أي تبعيات أخرى تحتاجها.
قم بإنشاء ملف النموذج
أولاً ، نقوم بإنشاء ملف يسمى serving.properties. هذا يرشد DJLServing لاستخدام محرك بايثون. نحن أيضا نحدد max_idle_time للعامل ليكون 600 ثانية. وهذا يجعلنا نستغرق وقتًا أطول لتقليل عدد العاملين لدينا لكل نموذج. نحن لا نتكيف minWorkers و maxWorkers التي يمكننا تحديدها ونسمح لشركة DJL بحساب عدد العمال المطلوبين ديناميكيًا اعتمادًا على حركة المرور التي يتلقاها كل نموذج. يتم عرض خصائص العرض على النحو التالي. للاطلاع على القائمة الكاملة لخيارات التكوين، راجع تكوين المحرك.
بعد ذلك، نقوم بإنشاء ملف model.py الخاص بنا، والذي يحدد منطق تحميل النموذج والاستدلال. بالنسبة إلى MMEs، يكون كل ملف model.py خاصًا بنموذج ما. يتم تخزين النماذج في مساراتها الخاصة ضمن مخزن النماذج (عادةً /opt/ml/model/). عند تحميل النماذج، سيتم تحميلها ضمن مسار مخزن النماذج في الدليل الخاص بها. يمكن رؤية المثال الكامل لـmodel.py في هذا العرض التوضيحي في ملف جيثب ريبو.
نقوم بإنشاء ملف model.tar.gz الملف الذي يتضمن نموذجنا (model.joblib), model.pyو serving.properties:
ولأغراض العرض التوضيحي، قمنا بعمل 1,000 نسخة منه model.tar.gz ملف يمثل العدد الكبير من النماذج التي سيتم استضافتها. في الإنتاج، تحتاج إلى إنشاء model.tar.gz ملف لكل من النماذج الخاصة بك.
وأخيرًا، نقوم بتحميل هذه النماذج إلى Amazon S3.
قم بإنشاء نموذج SageMaker
نقوم الآن بإنشاء ملف نموذج SageMaker. نستخدم صورة ECR المحددة مسبقًا والنموذج المصنوع من الخطوة السابقة لإنشاء نموذج SageMaker. في إعداد النموذج، نقوم بتكوين الوضع كـ MultiModel. يخبر هذا DJLServing أننا نقوم بإنشاء MME.
قم بإنشاء نقطة نهاية SageMaker
في هذا العرض التوضيحي، نستخدم 20 مثيلًا ml.c5d.18xlarge للتوسع إلى TPS في نطاق الآلاف. تأكد من الحصول على زيادة في الحد الأقصى لنوع المثيل الخاص بك، إذا لزم الأمر، لتحقيق TPS الذي تستهدفه.
اختبار الحمل
في وقت كتابة هذا التقرير، كانت أداة اختبار الحمل الداخلية من SageMaker التوصية بالاستدلال من Amazon SageMaker لا يدعم أصلاً اختبار MMEs. لذلك، نستخدم أداة بايثون مفتوحة المصدر جراد. يعد Locust سهل الإعداد ويمكنه تتبع المقاييس مثل TPS ووقت الاستجابة الشامل. للحصول على فهم كامل لكيفية إعداده باستخدام SageMaker، راجع أفضل الممارسات لاختبار الحمل لنقاط نهاية الاستدلال في الوقت الفعلي من Amazon SageMaker.
في حالة الاستخدام هذه، لدينا ثلاثة أنماط مختلفة لحركة المرور نريد محاكاتها باستخدام MMEs، لذلك لدينا نصوص Python الثلاثة التالية التي تتوافق مع كل نمط. هدفنا هنا هو إثبات أنه، بغض النظر عن نمط حركة المرور لدينا، يمكننا تحقيق نفس الهدف TPS والتوسع بشكل مناسب.
يمكننا تحديد وزن في برنامج Locust النصي الخاص بنا لتعيين حركة المرور عبر أجزاء مختلفة من نماذجنا. على سبيل المثال، مع نموذجنا الساخن الفردي، نقوم بتنفيذ طريقتين على النحو التالي:
يمكننا بعد ذلك تعيين وزن معين لكل طريقة، وذلك عندما تتلقى طريقة معينة نسبة مئوية محددة من حركة المرور:
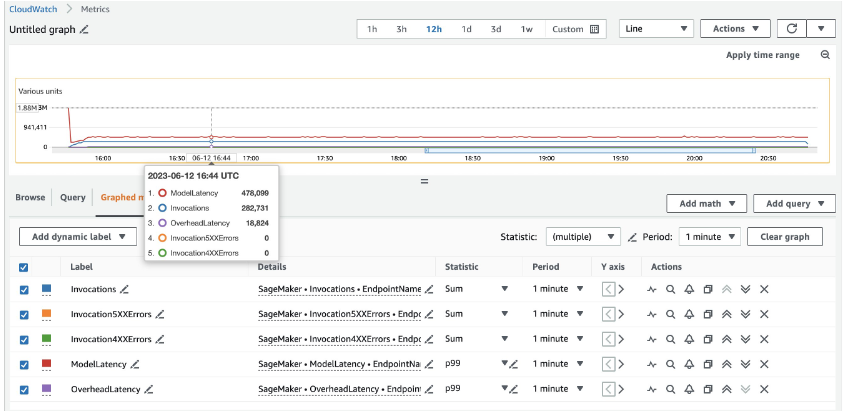
بالنسبة لـ 20 ml.c5d.18xlarge من المثيلات، نرى مقاييس الاستدعاء التالية على الأمازون CloudWatch وحدة التحكم. تظل هذه القيم متسقة إلى حد ما عبر أنماط حركة المرور الثلاثة. لفهم مقاييس CloudWatch للاستدلال في الوقت الفعلي لـ SageMaker وMMEs بشكل أفضل، راجع مقاييس استدعاء نقطة نهاية SageMaker.
يمكنك العثور على بقية نصوص Locust في ملف دليل الجراد-utils في مستودع جيثب.
نبذة عامة
في هذا المنشور، ناقشنا كيف يمكن لـ MME ضبط قوة الحوسبة المخصصة لكل نموذج ديناميكيًا بناءً على نمط حركة المرور الخاص بالنموذج. تتوفر هذه الميزة التي تم إطلاقها حديثًا في جميع مناطق AWS حيث يتوفر SageMaker. لاحظ أنه في وقت الإعلان، يتم دعم مثيلات وحدة المعالجة المركزية فقط. لمعرفة المزيد، راجع الخوارزميات والأطر والمثيلات المدعومة.
حول المؤلف
 رام فيجيراجو هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في بناء حلول الذكاء الاصطناعي / التعلم الآلي وتحسينها على Amazon SageMaker. يحب السفر والكتابة في أوقات فراغه.
رام فيجيراجو هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في بناء حلول الذكاء الاصطناعي / التعلم الآلي وتحسينها على Amazon SageMaker. يحب السفر والكتابة في أوقات فراغه.
 تشينغوي لي هو متخصص في التعلم الآلي في Amazon Web Services. حصل على الدكتوراه. في بحوث العمليات بعد أن كسر حساب منحة مستشاره البحثي وفشل في تسليم جائزة نوبل التي وعد بها. يقوم حاليًا بمساعدة العملاء في مجال الخدمات المالية وصناعة التأمين في بناء حلول التعلم الآلي على AWS. في أوقات فراغه يحب القراءة والتعليم.
تشينغوي لي هو متخصص في التعلم الآلي في Amazon Web Services. حصل على الدكتوراه. في بحوث العمليات بعد أن كسر حساب منحة مستشاره البحثي وفشل في تسليم جائزة نوبل التي وعد بها. يقوم حاليًا بمساعدة العملاء في مجال الخدمات المالية وصناعة التأمين في بناء حلول التعلم الآلي على AWS. في أوقات فراغه يحب القراءة والتعليم.
 جيمس وو هو مهندس حلول متخصص في الذكاء الاصطناعي / التعلم الآلي في AWS. مساعدة العملاء على تصميم وبناء حلول الذكاء الاصطناعي / التعلم الآلي. يغطي عمل James مجموعة واسعة من حالات استخدام ML ، مع اهتمام أساسي برؤية الكمبيوتر والتعلم العميق وتوسيع ML عبر المؤسسة. قبل انضمامه إلى AWS ، كان جيمس مهندسًا معماريًا ومطورًا وقائدًا في مجال التكنولوجيا لأكثر من 10 سنوات ، بما في ذلك 6 سنوات في الهندسة و 4 سنوات في صناعات التسويق والإعلان.
جيمس وو هو مهندس حلول متخصص في الذكاء الاصطناعي / التعلم الآلي في AWS. مساعدة العملاء على تصميم وبناء حلول الذكاء الاصطناعي / التعلم الآلي. يغطي عمل James مجموعة واسعة من حالات استخدام ML ، مع اهتمام أساسي برؤية الكمبيوتر والتعلم العميق وتوسيع ML عبر المؤسسة. قبل انضمامه إلى AWS ، كان جيمس مهندسًا معماريًا ومطورًا وقائدًا في مجال التكنولوجيا لأكثر من 10 سنوات ، بما في ذلك 6 سنوات في الهندسة و 4 سنوات في صناعات التسويق والإعلان.
 سوراب تريكاندي هو مدير أول للمنتجات في Amazon SageMaker Inference. إنه متحمس للعمل مع العملاء وتحفزه هدف إضفاء الطابع الديمقراطي على التعلم الآلي. يركز على التحديات الأساسية المتعلقة بنشر تطبيقات ML المعقدة ، ونماذج ML متعددة المستأجرين ، وتحسين التكلفة ، وجعل نشر نماذج التعلم العميق أكثر سهولة. في أوقات فراغه ، يستمتع سوراب بالمشي لمسافات طويلة والتعرف على التقنيات المبتكرة واتباع TechCrunch وقضاء الوقت مع عائلته.
سوراب تريكاندي هو مدير أول للمنتجات في Amazon SageMaker Inference. إنه متحمس للعمل مع العملاء وتحفزه هدف إضفاء الطابع الديمقراطي على التعلم الآلي. يركز على التحديات الأساسية المتعلقة بنشر تطبيقات ML المعقدة ، ونماذج ML متعددة المستأجرين ، وتحسين التكلفة ، وجعل نشر نماذج التعلم العميق أكثر سهولة. في أوقات فراغه ، يستمتع سوراب بالمشي لمسافات طويلة والتعرف على التقنيات المبتكرة واتباع TechCrunch وقضاء الوقت مع عائلته.
 شو دينغ هو مدير مهندس برمجيات في فريق SageMaker. وهو يركز على مساعدة العملاء في بناء تجربة الاستدلال الخاصة بالذكاء الاصطناعي/تعلم الآلة وتحسينها على Amazon SageMaker. وفي أوقات فراغه يحب السفر والتزلج على الجليد.
شو دينغ هو مدير مهندس برمجيات في فريق SageMaker. وهو يركز على مساعدة العملاء في بناء تجربة الاستدلال الخاصة بالذكاء الاصطناعي/تعلم الآلة وتحسينها على Amazon SageMaker. وفي أوقات فراغه يحب السفر والتزلج على الجليد.
 سيدهارث فينكاتيسان هو مهندس برمجيات في AWS Deep Learning. يركز حاليًا على بناء حلول لاستدلال النماذج الكبيرة. قبل انضمامه إلى AWS ، عمل في مؤسسة بقالة أمازون في إنشاء ميزات دفع جديدة للعملاء في جميع أنحاء العالم. خارج العمل ، يستمتع بالتزلج والهواء الطلق ومشاهدة الألعاب الرياضية.
سيدهارث فينكاتيسان هو مهندس برمجيات في AWS Deep Learning. يركز حاليًا على بناء حلول لاستدلال النماذج الكبيرة. قبل انضمامه إلى AWS ، عمل في مؤسسة بقالة أمازون في إنشاء ميزات دفع جديدة للعملاء في جميع أنحاء العالم. خارج العمل ، يستمتع بالتزلج والهواء الطلق ومشاهدة الألعاب الرياضية.
 روهيث نالامادي هو مهندس تطوير برمجيات في AWS. إنه يعمل على تحسين أعباء عمل التعلم العميق على وحدات معالجة الرسومات ، وبناء استدلال عالي الأداء لـ ML وتقديم الحلول. قبل ذلك ، عمل على بناء خدمات مصغرة على أساس AWS لأعمال Amazon F3. يستمتع باللعب ومشاهدة الرياضة خارج العمل.
روهيث نالامادي هو مهندس تطوير برمجيات في AWS. إنه يعمل على تحسين أعباء عمل التعلم العميق على وحدات معالجة الرسومات ، وبناء استدلال عالي الأداء لـ ML وتقديم الحلول. قبل ذلك ، عمل على بناء خدمات مصغرة على أساس AWS لأعمال Amazon F3. يستمتع باللعب ومشاهدة الرياضة خارج العمل.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

