At AWS إعادة: اختراع 2023، أعلنا عن التوفر العام لـ قواعد المعرفة لأمازون بيدروك. باستخدام قواعد المعرفة لـ Amazon Bedrock، يمكنك توصيل النماذج الأساسية (FMs) بشكل آمن أمازون بيدروك لبيانات شركتك باستخدام نموذج الاسترجاع المعزز (RAG) المُدار بالكامل.
بالنسبة للتطبيقات المستندة إلى RAG، تعتمد دقة الاستجابات الناتجة من FMs على السياق المقدم للنموذج. يتم استرداد السياقات من مخازن المتجهات بناءً على استعلامات المستخدم. في الميزة التي تم إصدارها مؤخرًا لقواعد المعرفة لـ Amazon Bedrock، بحث هجين، يمكنك الجمع بين البحث الدلالي والبحث عن الكلمات الرئيسية. ومع ذلك، في العديد من المواقف، قد تحتاج إلى استرداد المستندات التي تم إنشاؤها في فترة محددة أو تم وضع علامة عليها بفئات معينة. لتحسين نتائج البحث، يمكنك التصفية بناءً على البيانات التعريفية للوثيقة لتحسين دقة الاسترجاع، مما يؤدي بدوره إلى أجيال FM أكثر صلة تتوافق مع اهتماماتك.
في هذا المنشور، نناقش ميزة تصفية بيانات التعريف المخصصة الجديدة في قواعد المعرفة لـ Amazon Bedrock، والتي يمكنك استخدامها لتحسين نتائج البحث عن طريق التصفية المسبقة لعمليات الاسترجاع من متاجر المتجهات.
نظرة عامة على تصفية البيانات الوصفية
قبل إصدار تصفية البيانات الوصفية، سيتم إرجاع جميع الأجزاء ذات الصلة لغويًا حتى الحد الأقصى المحدد مسبقًا كسياق لـ FM لاستخدامه في إنشاء استجابة. الآن، باستخدام مرشحات البيانات التعريفية، لا يمكنك استرداد الأجزاء ذات الصلة لغويًا فحسب، بل يمكنك استرداد مجموعة فرعية محددة جيدًا من تلك القطع ذات الصلة استنادًا إلى مرشحات البيانات التعريفية المطبقة والقيم المرتبطة بها.
باستخدام هذه الميزة، يمكنك الآن توفير ملف بيانات تعريف مخصص (يصل حجم كل منها إلى 10 كيلو بايت) لكل مستند في قاعدة المعرفة. يمكنك تطبيق عوامل التصفية على عمليات الاسترجاع الخاصة بك، وتوجيه مخزن المتجهات لإجراء التصفية المسبقة استنادًا إلى بيانات تعريف المستند ثم البحث عن المستندات ذات الصلة. بهذه الطريقة، يمكنك التحكم في المستندات المستردة، خاصة إذا كانت استفساراتك غامضة. على سبيل المثال، يمكنك استخدام المستندات القانونية التي تحتوي على مصطلحات متشابهة لسياقات مختلفة، أو الأفلام التي تحتوي على حبكة مماثلة تم إصدارها في سنوات مختلفة. بالإضافة إلى ذلك، من خلال تقليل عدد القطع التي يتم البحث فيها، يمكنك تحقيق مزايا الأداء مثل تقليل دورات وحدة المعالجة المركزية وتكلفة الاستعلام عن مخزن المتجهات، بالإضافة إلى تحسين الدقة.

لاستخدام ميزة تصفية البيانات التعريفية، يتعين عليك توفير ملفات البيانات التعريفية إلى جانب ملفات البيانات المصدر بنفس اسم ملف البيانات المصدر و .metadata.json لاحقة. يمكن أن تكون البيانات التعريفية عبارة عن سلسلة أو رقم أو منطقية. فيما يلي مثال على محتوى ملف البيانات التعريفية:
تتوفر ميزة تصفية البيانات التعريفية لقواعد المعرفة الخاصة بـ Amazon Bedrock في مناطق AWS شرق الولايات المتحدة (شمال فرجينيا) وغرب الولايات المتحدة (أوريغون).
فيما يلي حالات الاستخدام الشائعة لتصفية البيانات التعريفية:
- توثيق chatbot لشركة برمجيات - يتيح ذلك للمستخدمين العثور على معلومات المنتج وأدلة استكشاف الأخطاء وإصلاحها. على سبيل المثال، يمكن أن تساعد عوامل التصفية الموجودة على نظام التشغيل أو إصدار التطبيق في تجنب استرداد المستندات القديمة أو غير ذات الصلة.
- البحث المحادثة لتطبيق المنظمة - يتيح ذلك للمستخدمين البحث في المستندات ووظائف كانبان ونصوص تسجيل الاجتماعات والأصول الأخرى. باستخدام عوامل تصفية البيانات التعريفية في مجموعات العمل أو وحدات الأعمال أو معرفات المشاريع، يمكنك تخصيص تجربة الدردشة وتحسين التعاون. على سبيل المثال، "ما هي حالة مشروع Sphinx والمخاطر المثارة"، حيث يمكن للمستخدمين تصفية المستندات لمشروع معين أو نوع مصدر معين (مثل البريد الإلكتروني أو مستندات الاجتماع).
- البحث الذكي لمطوري البرمجيات – يسمح هذا للمطورين بالبحث عن معلومات حول إصدار معين. يمكن أن تساعد عوامل التصفية الموجودة على إصدار الإصدار أو نوع المستند (مثل الكود أو مرجع واجهة برمجة التطبيقات أو المشكلة) في تحديد المستندات ذات الصلة.
حل نظرة عامة
في الأقسام التالية، نوضح كيفية إعداد مجموعة بيانات لاستخدامها كقاعدة معرفية، ثم الاستعلام باستخدام تصفية البيانات التعريفية. يمكنك الاستعلام باستخدام إما وحدة تحكم إدارة AWS أو SDK.
قم بإعداد مجموعة بيانات لقواعد المعرفة الخاصة بـ Amazon Bedrock
في هذا المنشور ، نستخدم ملف عينة مجموعة البيانات حول ألعاب الفيديو الخيالية لتوضيح كيفية استيعاب البيانات الوصفية واسترجاعها باستخدام قواعد المعرفة الخاصة بـ Amazon Bedrock. إذا كنت تريد المتابعة في حساب AWS الخاص بك، فقم بتنزيل الملف.
إذا كنت تريد إضافة بيانات تعريف إلى مستنداتك في قاعدة معارف موجودة، فقم بإنشاء ملفات بيانات التعريف باستخدام اسم الملف والمخطط المتوقعين، ثم انتقل إلى خطوة مزامنة بياناتك مع قاعدة المعرفة لبدء الاستيعاب المتزايد.
في عينة مجموعة البيانات الخاصة بنا، يكون مستند كل لعبة عبارة عن ملف CSV منفصل (على سبيل المثال، s3://$bucket_name/video_game/$game_id.csv) مع الأعمدة التالية:
title, description, genres, year, publisher, score
تحتوي البيانات الوصفية لكل لعبة على اللاحقة .metadata.json (فمثلا، s3://$bucket_name/video_game/$game_id.csv.metadata.json) بالمخطط التالي:
أنشئ قاعدة معرفية لـ Amazon Bedrock
للحصول على تعليمات إنشاء قاعدة معارف جديدة، راجع إنشاء قاعدة معرفية. في هذا المثال، نستخدم الإعدادات التالية:
- على إعداد مصدر البيانات الصفحة تحت استراتيجية التقطيع، حدد لا تقطيع، لأنك قمت بالفعل بمعالجة المستندات مسبقًا في الخطوة السابقة.
- في مجلة نموذج التضمين القسم، اختر تيتان G1 التضمين – النص.
- في مجلة قاعدة بيانات المتجهات القسم، اختر إنشاء متجر ناقلات جديد بسرعة. تتوفر ميزة تصفية البيانات التعريفية لجميع متاجر المتجهات المدعومة.
مزامنة مجموعة البيانات مع قاعدة المعرفة
بعد إنشاء قاعدة المعرفة، وتكون ملفات البيانات وملفات البيانات التعريفية في ملف خدمة تخزين أمازون البسيطة (Amazon S3)، يمكنك بدء العرض المتزايد. للحصول على التعليمات، انظر مزامنة لاستيعاب مصادر البيانات الخاصة بك في قاعدة المعرفة.
الاستعلام باستخدام تصفية البيانات التعريفية على وحدة تحكم Amazon Bedrock
لاستخدام خيارات تصفية البيانات التعريفية على وحدة تحكم Amazon Bedrock، أكمل الخطوات التالية:
- في وحدة تحكم Amazon Bedrock، اختر قواعد المعرفة في جزء التنقل.
- اختر قاعدة المعرفة التي قمت بإنشائها.
- اختار اختبار قاعدة المعرفة.
- اختيار تكوينات أيقونة، ثم قم بالتوسيع فلاتر.
- أدخل شرطًا باستخدام التنسيق: المفتاح = القيمة (على سبيل المثال، الأنواع = الإستراتيجية) ثم اضغط أدخل.
- لتغيير المفتاح أو القيمة أو عامل التشغيل، اختر الشرط.
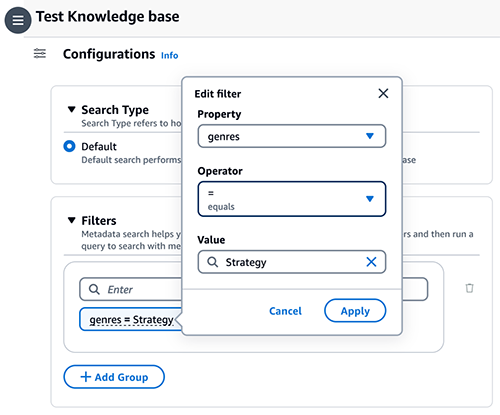
- تابع مع الشروط المتبقية (على سبيل المثال، (الأنواع = الإستراتيجية والسنة >= 2023) أو (التقييم >= 9))

- عند الانتهاء، أدخل استفسارك في مربع الرسالة، ثم اختر يجري.
في هذا المنشور، ندخل الاستعلام "لعبة إستراتيجية برسومات رائعة تم إصدارها بعد عام 2023".
الاستعلام باستخدام تصفية بيانات التعريف باستخدام SDK
لاستخدام SDK، قم أولاً بإنشاء العميل لـ وكلاء شركة أمازون بيدروك مدة العرض:
ثم أنشئ الفلتر (فيما يلي بعض الأمثلة):
قم بتمرير الفلتر إلى retrievalConfiguration ل واجهة برمجة التطبيقات للاسترجاع or استرداد وتوليد API:
يسرد الجدول التالي بعض الاستجابات مع شروط تصفية مختلفة للبيانات التعريفية.
| سؤال | تصفية البيانات الوصفية | الوثائق المستردة | الملاحظات |
| "لعبة إستراتيجية برسومات رائعة تم إصدارها بعد عام 2023" | خصم |
* Viking Saga: The Sea Raider، العام:2023، الأنواع: إستراتيجية * قلعة القرون الوسطى: الحصار والفتح، السنة:2022الأنواع: إستراتيجية * الثورة السيبرانية: صعود الآلات، السنة:2022الأنواع: إستراتيجية |
2/5 ألعاب تستوفي الشرط (الأنواع = الإستراتيجية والسنة >= 2023) |
| On | * Viking Saga: The Sea Raider، العام:2023، الأنواع: إستراتيجية * ممالك الخيال: Chronicles of Eldoria، العام:2023، الأنواع: إستراتيجية |
2/2 ألعاب تستوفي الشرط (الأنواع = الإستراتيجية والسنة >= 2023) |
بالإضافة إلى البيانات التعريفية المخصصة، يمكنك أيضًا التصفية باستخدام بادئات S3 (وهي عبارة عن بيانات تعريف مضمنة، لذلك لا تحتاج إلى توفير أي ملفات بيانات تعريف). على سبيل المثال، إذا قمت بتنظيم مستندات اللعبة في بادئات حسب الناشر (على سبيل المثال، s3://$bucket_name/video_game/$publisher/$game_id.csv)، يمكنك التصفية باستخدام الناشر المحدد (على سبيل المثال، neo_tokyo_games) باستخدام بناء الجملة التالي:
تنظيف
لتنظيف مواردك ، أكمل الخطوات التالية:
- حذف قاعدة المعرفة:
- في وحدة تحكم Amazon Bedrock، اختر قواعد المعرفة مع تزامن في جزء التنقل.
- اختر قاعدة المعرفة التي قمت بإنشائها.
- يحيط علما إدارة الهوية والوصول AWS (IAM) اسم دور الخدمة في نظرة عامة على قاعدة المعرفة والقسم الخاص به.
- في مجلة قاعدة بيانات المتجهات القسم، يحيط علما بجمع ARN.
- اختار حذف، ثم أدخل حذف للتأكيد.
- حذف قاعدة بيانات المتجهات:
- على خدمة Amazon OpenSearch وحدة ، اختر المجموعات مع Serverless في جزء التنقل.
- أدخل مجموعة ARN التي قمت بحفظها في شريط البحث.
- حدد المجموعة واختر حذف.
- أدخل تأكيد في رسالة التأكيد، ثم اختر حذف.
- حذف دور خدمة IAM:
- في وحدة تحكم IAM ، اختر الأدوار في جزء التنقل.
- ابحث عن اسم الدور الذي لاحظته سابقًا.
- حدد الدور ثم اختر حذف.
- أدخل اسم الدور في رسالة التأكيد واحذف الدور.
- حذف مجموعة البيانات النموذجية:
- على وحدة تحكم Amazon S3، انتقل إلى حاوية S3 التي استخدمتها.
- حدد البادئة والملفات، ثم اختر حذف.
- أدخل الحذف نهائيًا في رسالة التأكيد للحذف.
وفي الختام
في هذا المنشور، قمنا بتغطية ميزة تصفية البيانات التعريفية في قواعد المعرفة لـ Amazon Bedrock. لقد تعلمت كيفية إضافة بيانات تعريف مخصصة إلى المستندات واستخدامها كمرشحات أثناء استرداد المستندات والاستعلام عنها باستخدام وحدة تحكم Amazon Bedrock وSDK. ويساعد ذلك على تحسين دقة السياق، مما يجعل استجابات الاستعلام أكثر أهمية مع تحقيق انخفاض في تكلفة الاستعلام عن قاعدة بيانات المتجهات.
للحصول على موارد إضافية، راجع ما يلي:
حول المؤلف
 كورفوس لي هو أحد كبار مهندسي حلول GenAI Labs ومقره في لندن. إنه متحمس لتصميم وتطوير النماذج الأولية التي تستخدم الذكاء الاصطناعي التوليدي لحل مشاكل العملاء. كما أنه يواكب أحدث التطورات في الذكاء الاصطناعي التوليدي وتقنيات الاسترجاع من خلال تطبيقها على سيناريوهات العالم الحقيقي.
كورفوس لي هو أحد كبار مهندسي حلول GenAI Labs ومقره في لندن. إنه متحمس لتصميم وتطوير النماذج الأولية التي تستخدم الذكاء الاصطناعي التوليدي لحل مشاكل العملاء. كما أنه يواكب أحدث التطورات في الذكاء الاصطناعي التوليدي وتقنيات الاسترجاع من خلال تطبيقها على سيناريوهات العالم الحقيقي.
 احمد عويس هو أحد كبار مهندسي الحلول في AWS GenAI Labs، حيث يساعد العملاء على بناء نماذج أولية إبداعية للذكاء الاصطناعي لحل مشكلات العمل. عندما لا يتعاون مع العملاء، فإنه يستمتع باللعب مع أطفاله والطهي.
احمد عويس هو أحد كبار مهندسي الحلول في AWS GenAI Labs، حيث يساعد العملاء على بناء نماذج أولية إبداعية للذكاء الاصطناعي لحل مشكلات العمل. عندما لا يتعاون مع العملاء، فإنه يستمتع باللعب مع أطفاله والطهي.
 كريس بيكورا هو عالم بيانات الذكاء الاصطناعي التوليدي في Amazon Web Services. إنه متحمس لبناء منتجات وحلول مبتكرة مع التركيز أيضًا على العلوم المهووسة بالعملاء. عند عدم إجراء التجارب ومواكبة أحدث التطورات في GenAI، فإنه يحب قضاء الوقت مع أطفاله.
كريس بيكورا هو عالم بيانات الذكاء الاصطناعي التوليدي في Amazon Web Services. إنه متحمس لبناء منتجات وحلول مبتكرة مع التركيز أيضًا على العلوم المهووسة بالعملاء. عند عدم إجراء التجارب ومواكبة أحدث التطورات في GenAI، فإنه يحب قضاء الوقت مع أطفاله.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

