صورة المؤلف
من خلال الغوص في عالم علوم البيانات والتعلم الآلي، إحدى المهارات الأساسية التي ستواجهها هي فن قراءة البيانات. إذا كان لديك بالفعل بعض الخبرة في ذلك، فمن المحتمل أنك على دراية بـ JSON (JavaScript Object Notation) - وهو تنسيق شائع لتخزين البيانات وتبادلها.
فكر في كيفية قيام قواعد بيانات NoSQL مثل MongoDB بتخزين البيانات بتنسيق JSON، أو كيف تستجيب واجهات برمجة تطبيقات REST غالبًا بنفس التنسيق.
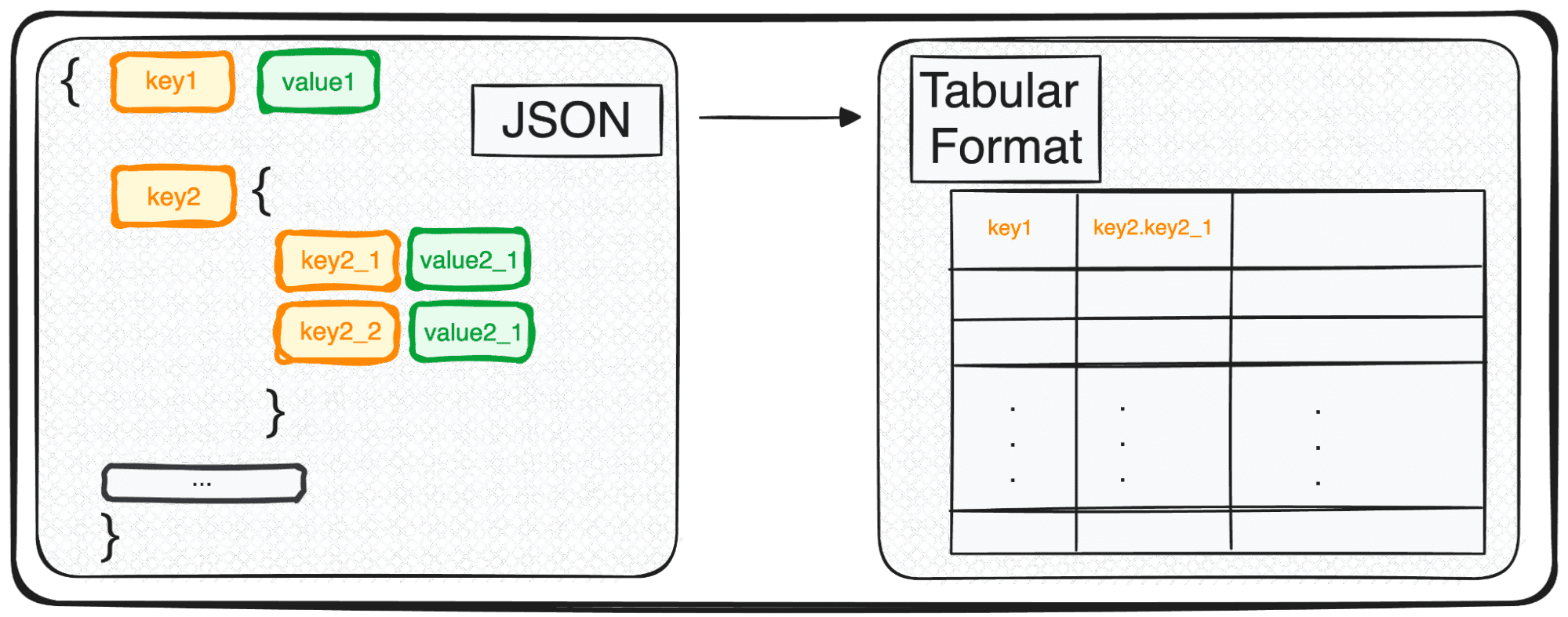
ومع ذلك، على الرغم من أن JSON مثالي للتخزين والتبادل، إلا أنه ليس جاهزًا تمامًا للتحليل المتعمق في شكله الأولي. هذا هو المكان الذي نقوم فيه بتحويله إلى شيء أكثر ملاءمة من الناحية التحليلية - تنسيق جدولي.
لذلك، سواء كنت تتعامل مع كائن JSON واحد أو مجموعة مبهجة منها، وفقًا لمصطلحات Python، فأنت تتعامل بشكل أساسي مع إملاء أو قائمة من الإملاءات.
دعونا نستكشف معًا كيف يتكشف هذا التحول، مما يجعل بياناتنا جاهزة للتحليل ؟؟؟؟
سأشرح اليوم أمرًا سحريًا يسمح لنا بتحليل أي JSON بسهولة إلى تنسيق جدولي في ثوانٍ.
وهو ... ص.json_normalize()
لذلك دعونا نرى كيف يعمل مع أنواع مختلفة من JSONs.
النوع الأول من JSON الذي يمكننا العمل به هو JSONs أحادي المستوى مع عدد قليل من المفاتيح والقيم. نحدد أول JSONs البسيطة لدينا على النحو التالي:
كود المؤلف
لذلك دعونا نحاكي الحاجة إلى العمل مع ملفات JSON هذه. نعلم جميعًا أنه ليس هناك الكثير للقيام به بتنسيق JSON الخاص بهم. نحن بحاجة إلى تحويل هذه JSONs إلى تنسيق قابل للقراءة والتعديل ... وهو ما يعني Pandas DataFrames!
1.1 التعامل مع هياكل JSON البسيطة
أولاً، نحتاج إلى استيراد مكتبة الباندا ومن ثم يمكننا استخدام الأمر pd.json_normalize()، كما يلي:
import pandas as pd
pd.json_normalize(json_string)
من خلال تطبيق هذا الأمر على JSON بسجل واحد، نحصل على الجدول الأساسي. ومع ذلك، عندما تكون بياناتنا أكثر تعقيدًا بعض الشيء وتقدم قائمة JSONs، فلا يزال بإمكاننا استخدام نفس الأمر دون مزيد من التعقيدات وسيتوافق الإخراج مع جدول يحتوي على سجلات متعددة.

صورة المؤلف
الحق سهلة؟
والسؤال الطبيعي التالي هو ماذا يحدث عندما تكون بعض القيم مفقودة.
1.2 التعامل مع القيم الخالية
تخيل أن بعض القيم لم يتم إعلامها، على سبيل المثال، سجل الدخل لديفيد مفقود. عند تحويل JSON الخاص بنا إلى إطار بيانات الباندا البسيط، ستظهر القيمة المقابلة كـ NaN.

صورة المؤلف
وماذا لو كنت أرغب فقط في الحصول على بعض الحقول؟
1.3 تحديد الأعمدة محل الاهتمام فقط
في حال أردنا فقط تحويل بعض الحقول المحددة إلى DataFrame جدولي، فإن الأمر json_normalize() لا يسمح لنا باختيار الحقول المراد تحويلها.
لذلك، يجب إجراء معالجة مسبقة صغيرة لـ JSON حيث نقوم بتصفية تلك الأعمدة محل الاهتمام فقط.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
لذلك، دعونا ننتقل إلى بعض بنية JSON الأكثر تقدما.
عند التعامل مع JSONs متعددة المستويات نجد أنفسنا مع JSONs متداخلة ضمن مستويات مختلفة. الإجراء هو نفسه كما كان من قبل، ولكن في هذه الحالة، يمكننا اختيار عدد المستويات التي نريد تحويلها. افتراضيًا، سيقوم الأمر دائمًا بتوسيع جميع المستويات وإنشاء أعمدة جديدة تحتوي على الاسم المتسلسل لجميع المستويات المتداخلة.
لذلك إذا قمنا بتطبيع JSONs التالية.
كود المؤلف
سنحصل على الجدول التالي مع 3 أعمدة تحت المهارات الميدانية:
- Skills.python
- Skills.SQL
- Skills.GCP
و4 أعمدة تحت الأدوار الميدانية
- الأدوار.مدير المشروع
- الأدوار.مهندس البيانات
- الأدوار. عالم البيانات
- الأدوار.محلل البيانات

صورة المؤلف
ومع ذلك، تخيل أننا نريد فقط تحويل المستوى الأعلى لدينا. يمكننا القيام بذلك عن طريق تحديد المعلمة max_level على وجه التحديد إلى 0 (المستوى الأقصى الذي نريد توسيعه).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
سيتم الاحتفاظ بالقيم المعلقة داخل JSONs داخل Pandas DataFrame الخاص بنا.

صورة المؤلف
الحالة الأخيرة التي يمكننا العثور عليها هي وجود قائمة متداخلة داخل حقل JSON. لذلك قمنا أولاً بتحديد ملفات JSON التي يجب استخدامها.
كود المؤلف
يمكننا إدارة هذه البيانات بشكل فعال باستخدام Pandas في Python. تعتبر الدالة pd.json_normalize() مفيدة بشكل خاص في هذا السياق. يمكنه تسوية بيانات JSON، بما في ذلك القائمة المتداخلة، في تنسيق منظم مناسب للتحليل. عندما يتم تطبيق هذه الوظيفة على بيانات JSON الخاصة بنا، فإنها تنتج جدولًا عاديًا يتضمن القائمة المتداخلة كجزء من حقولها.
علاوة على ذلك، يوفر Pandas القدرة على تحسين هذه العملية بشكل أكبر. من خلال استخدام المعلمة Record_path في pd.json_normalize()، يمكننا توجيه الوظيفة لتطبيع القائمة المتداخلة على وجه التحديد.
ينتج عن هذا الإجراء جدول مخصص حصريًا لمحتويات القائمة. بشكل افتراضي، ستكشف هذه العملية فقط عن العناصر الموجودة في القائمة. ومع ذلك، لإثراء هذا الجدول بسياق إضافي، مثل الاحتفاظ بمعرف مرتبط لكل سجل، يمكننا استخدام معلمة التعريف.

صورة المؤلف
باختصار، يعد تحويل بيانات JSON إلى ملفات CSV باستخدام مكتبة Python Pandas أمرًا سهلاً وفعالاً.
لا يزال JSON هو التنسيق الأكثر شيوعًا في تخزين البيانات الحديثة وتبادلها، لا سيما في قواعد بيانات NoSQL وواجهات برمجة تطبيقات REST. ومع ذلك، فإنه يطرح بعض التحديات التحليلية الهامة عند التعامل مع البيانات في شكلها الأولي.
يظهر الدور المحوري لـ pd.json_normalize() الخاص بـ Pandas كطريقة رائعة للتعامل مع مثل هذه التنسيقات وتحويل بياناتنا إلى Pandas DataFrame.
أتمنى أن يكون هذا الدليل مفيدًا، وفي المرة القادمة التي تتعامل فيها مع JSON، يمكنك القيام بذلك بطريقة أكثر فعالية.
يمكنك التحقق من Jupyter Notebook المطابق في ملف بعد جيثب الريبو.
جوزيب فيرير هو مهندس تحليلات من برشلونة. تخرج في هندسة الفيزياء ويعمل حاليًا في مجال علوم البيانات المطبق على التنقل البشري. وهو منشئ محتوى بدوام جزئي يركز على علوم البيانات والتكنولوجيا. يمكنك الاتصال به على لينكدين:, تويتر or متوسط.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way

