غالبًا ما تحتاج المؤسسات إلى إدارة حجم كبير من البيانات التي تنمو بمعدل غير عادي. وفي الوقت نفسه، يحتاجون إلى تحسين التكاليف التشغيلية لإطلاق قيمة هذه البيانات للحصول على رؤى في الوقت المناسب والقيام بذلك بأداء ثابت.
مع هذا النمو الهائل في البيانات، يمكن أن يصبح انتشار البيانات عبر مخازن البيانات ومستودع البيانات وبحيرات البيانات أمرًا صعبًا بنفس القدر. مع هندسة البيانات الحديثة على AWS، يمكنك إنشاء مستودعات بيانات قابلة للتطوير بسرعة؛ استخدام مجموعة واسعة وعميقة من خدمات البيانات المصممة لهذا الغرض؛ وضمان الامتثال من خلال الوصول الموحد للبيانات والأمن والحوكمة؛ توسيع نطاق أنظمتك بتكلفة منخفضة دون المساس بالأداء؛ ومشاركة البيانات عبر الحدود التنظيمية بسهولة، مما يسمح لك باتخاذ القرارات بسرعة وخفة الحركة على نطاق واسع.
يمكنك أخذ جميع بياناتك من صوامع مختلفة، وتجميع تلك البيانات في بحيرة البيانات الخاصة بك، وإجراء التحليلات والتعلم الآلي (ML) مباشرة فوق تلك البيانات. يمكنك أيضًا تخزين بيانات أخرى في مخازن بيانات مخصصة لهذا الغرض لتحليل والحصول على رؤى سريعة من كل من البيانات المنظمة وغير المنظمة. يمكن أن تكون حركة البيانات هذه من الداخل إلى الخارج، أو من الخارج إلى الداخل، أو حول المحيط أو المشاركة عبرها.
على سبيل المثال، يمكن جمع سجلات التطبيق والتتبعات من تطبيقات الويب مباشرة في بحيرة البيانات، ويمكن نقل جزء من تلك البيانات إلى مخزن تحليلات السجل مثل Amazon OpenSearch Service للتحليل اليومي. ونحن نفكر في هذا المفهوم كما بالداخل بالخارج حركة البيانات. يمكن مرة أخرى نقل البيانات التي تم تحليلها وتجميعها والمخزنة في Amazon OpenSearch Service إلى مستودع البيانات لتشغيل خوارزميات التعلم الآلي للاستهلاك النهائي من التطبيقات. ونشير إلى هذا المفهوم باسم من الخارج إلى الداخل حركة البيانات.
دعونا نلقي نظرة على مثال لحالة الاستخدام. تعد شركة example Corp إحدى الشركات الرائدة المدرجة في قائمة Fortune 500 والمتخصصة في المحتوى الاجتماعي. لديهم المئات من التطبيقات التي تولد البيانات والتتبعات بمعدل 500 تيرابايت تقريبًا يوميًا ولها المعايير التالية:
- اجعل السجلات متاحة للتحليلات السريعة لمدة يومين
- بعد يومين، اجعل البيانات متاحة في طبقة تخزين يمكن إتاحتها للتحليلات باستخدام اتفاقية مستوى الخدمة المعقولة
- الاحتفاظ بالبيانات لمدة تزيد عن أسبوع واحد في مخزن بارد لمدة 1 يومًا (لأغراض الامتثال والتدقيق وغيرها)
في الأقسام التالية، نناقش ثلاثة حلول ممكنة لمعالجة حالات الاستخدام المشابهة:
- التخزين المتدرج في Amazon OpenSearch Service وإدارة دورة حياة البيانات
- ابتلاع السجلات عند الطلب باستخدام ابتلاع Amazon OpenSearch
- استعلامات Amazon OpenSearch Service المباشرة باستخدام Amazon Simple Storage Service (Amazon S3)
الحل 1: التخزين المتدرج في خدمة OpenSearch وإدارة دورة حياة البيانات
تدعم خدمة OpenSearch ثلاثة مستويات تخزين متكاملة: التخزين الساخن، وUltraWarm، والبارد. استنادًا إلى الاحتفاظ بالبيانات وزمن وصول الاستعلام ومتطلبات الميزانية، يمكنك اختيار أفضل استراتيجية لتحقيق التوازن بين التكلفة والأداء. يمكنك أيضًا ترحيل البيانات بين طبقات التخزين المختلفة.
يُستخدم التخزين الساخن للفهرسة والتحديث، ويوفر الوصول الأسرع إلى البيانات. يأخذ التخزين الساخن شكل مخزن المثيلات أو متجر أمازون مطاط بلوك مجلدات (Amazon EBS) المرفقة بكل عقدة.
يوفر UltraWarm تكاليف أقل بكثير لكل جيجا بايت للبيانات للقراءة فقط التي تستعلم عنها بشكل أقل تكرارًا ولا تحتاج إلى نفس الأداء مثل التخزين الساخن. تستخدم عقد UltraWarm خدمة Amazon S3 مع حلول التخزين المؤقت ذات الصلة لتحسين الأداء.
تم تحسين التخزين البارد لتخزين البيانات التاريخية أو التي لا يتم الوصول إليها بشكل متكرر. عند استخدام التخزين البارد، فإنك تقوم بفصل الفهارس الخاصة بك عن طبقة UltraWarm، مما يجعل الوصول إليها غير ممكن. يمكنك إعادة ربط هذه الفهارس في بضع ثوانٍ عندما تحتاج إلى الاستعلام عن تلك البيانات.
لمزيد من التفاصيل حول طبقات البيانات ضمن خدمة OpenSearch، راجع اختر طبقة التخزين المناسبة لاحتياجاتك في Amazon OpenSearch Service.
حل نظرة عامة
يتكون سير العمل لهذا الحل من الخطوات التالية:
- يتم تدفق البيانات الواردة التي تم إنشاؤها بواسطة التطبيقات إلى بحيرة بيانات S3.
- يتم استيعاب البيانات في Amazon OpenSearch باستخدام S3-SQS الاستيعاب في الوقت الفعلي تقريبًا من خلال الإشعارات التي تم إعدادها على مجموعات S3.
- بعد يومين، يتم ترحيل البيانات الساخنة إلى وحدة تخزين UltraWarm لدعم استعلامات القراءة.
- بعد 5 أيام في UltraWarm، يتم ترحيل البيانات إلى التخزين البارد لمدة 21 يومًا وفصلها عن أي حساب. يمكن إعادة ربط البيانات بـ UltraWarm عند الحاجة. يتم حذف البيانات من التخزين البارد بعد 21 يومًا.
- يتم الاحتفاظ بالفهارس اليومية لسهولة التمديد. تعمل سياسة إدارة حالة الفهرس (ISM) على أتمتة عملية التمرير أو حذف الفهارس التي مضى عليها أكثر من يومين.
فيما يلي نموذج لسياسة ISM التي تنقل البيانات إلى طبقة UltraWarm بعد يومين، وتنقلها إلى التخزين البارد بعد 2 أيام، وتحذفها من التخزين البارد بعد 5 يومًا:
الاعتبارات
يستخدم UltraWarm تقنيات تخزين مؤقت متطورة لتمكين الاستعلام عن البيانات التي لا يتم الوصول إليها بشكل متكرر. على الرغم من أن الوصول إلى البيانات نادر، إلا أن حساب عقد UltraWarm يحتاج إلى التشغيل طوال الوقت لجعل هذا الوصول ممكنًا.
عند التشغيل على نطاق PB، لتقليل منطقة تأثير أي أخطاء، نوصي بتحليل التنفيذ إلى نطاقات خدمة OpenSearch المتعددة عند استخدام التخزين المتدرج.
يزيل النمطان التاليان الحاجة إلى حساب طويل الأمد ويصفان التقنيات عند الطلب حيث يتم إحضار البيانات عند الحاجة أو الاستعلام عنها مباشرة حيث توجد.
الحل 2: استيعاب بيانات السجلات عند الطلب من خلال OpenSearch Ingestion
OpenSearch Ingestion عبارة عن أداة تجميع بيانات مُدارة بالكامل توفر بيانات السجل والتتبع في الوقت الفعلي إلى نطاقات خدمة OpenSearch. يتم تشغيل OpenSearch Ingestion بواسطة أداة تجميع البيانات مفتوحة المصدر Prepper البيانات. يعد Data Prepper جزءًا من مشروع OpenSearch مفتوح المصدر.
باستخدام OpenSearch Ingestion، يمكنك تصفية بياناتك وإثرائها وتحويلها وتقديمها للتحليل النهائي والتصور. يمكنك تكوين منتجي البيانات لديك لإرسال البيانات إلى OpenSearch Ingestion. يقوم تلقائيًا بتسليم البيانات إلى المجال أو المجموعة التي تحددها. يمكنك أيضًا تكوين OpenSearch Ingestion لتحويل بياناتك قبل تسليمها. OpenSearch Ingestion هو برنامج بدون خادم، لذلك لا داعي للقلق بشأن توسيع نطاق البنية الأساسية لديك، وتشغيل أسطول العرض لديك، وتصحيح البرنامج أو تحديثه.
هناك طريقتان يمكنك من خلالهما استخدام Amazon S3 كمصدر لمعالجة البيانات باستخدام OpenSearch Ingestion. الخيار الأول هو معالجة S3-SQS. يمكنك استخدام معالجة S3-SQS عندما تحتاج إلى فحص الملفات في الوقت الفعلي تقريبًا بعد كتابتها إلى S3. يتطلب خدمة Amazon Simple Queue Service (Amazon S3) قائمة الانتظار التي تستقبل إخطارات الأحداث S3. يمكنك تكوين حاويات S3 لرفع حدث في أي وقت يتم فيه تخزين كائن أو تعديله داخل الحاوية لتتم معالجته.
وبدلاً من ذلك، يمكنك استخدام فحص مجدول لمرة واحدة أو متكرر لبيانات المعالجة المجمعة في حاوية S3. لإعداد فحص مجدول، قم بتكوين المسار الخاص بك بجدول زمني على مستوى الفحص الذي ينطبق على جميع حاويات S3 الخاصة بك، أو على مستوى الحاوية. يمكنك تكوين عمليات الفحص المجدولة إما من خلال الفحص لمرة واحدة أو الفحص المتكرر لمعالجة الدُفعات.
للحصول على نظرة عامة شاملة حول OpenSearch Ingestion، راجع ابتلاع Amazon OpenSearch. لمزيد من المعلومات حول مشروع Data Prepper مفتوح المصدر، تفضل بزيارة Prepper البيانات.
حل نظرة عامة
نقدم نموذجًا معماريًا يحتوي على المكونات الرئيسية التالية:
- يتم تدفق سجلات التطبيق إلى بحيرة البيانات، مما يساعد على تغذية البيانات الساخنة في خدمة OpenSearch في الوقت الفعلي تقريبًا باستخدام OpenSearch Ingestion معالجة S3-SQS.
- تتعامل سياسات ISM ضمن خدمة OpenSearch مع عمليات نقل الفهرس أو عمليات الحذف. تتيح لك سياسات ISM أتمتة هذه العمليات الإدارية الدورية عن طريق تشغيلها بناءً على التغييرات في عمر الفهرس أو حجم الفهرس أو عدد المستندات. على سبيل المثال، يمكنك تحديد سياسة تنقل الفهرس الخاص بك إلى حالة القراءة فقط بعد يومين ثم تقوم بحذفه بعد فترة محددة مدتها 2 أيام.
- تتوفر البيانات الباردة في بحيرة بيانات S3 ليتم استهلاكها عند الطلب في خدمة OpenSearch باستخدام OpenSearch Ingestion عمليات الفحص المجدولة.
يوضح الرسم البياني التالي بنية الحل.
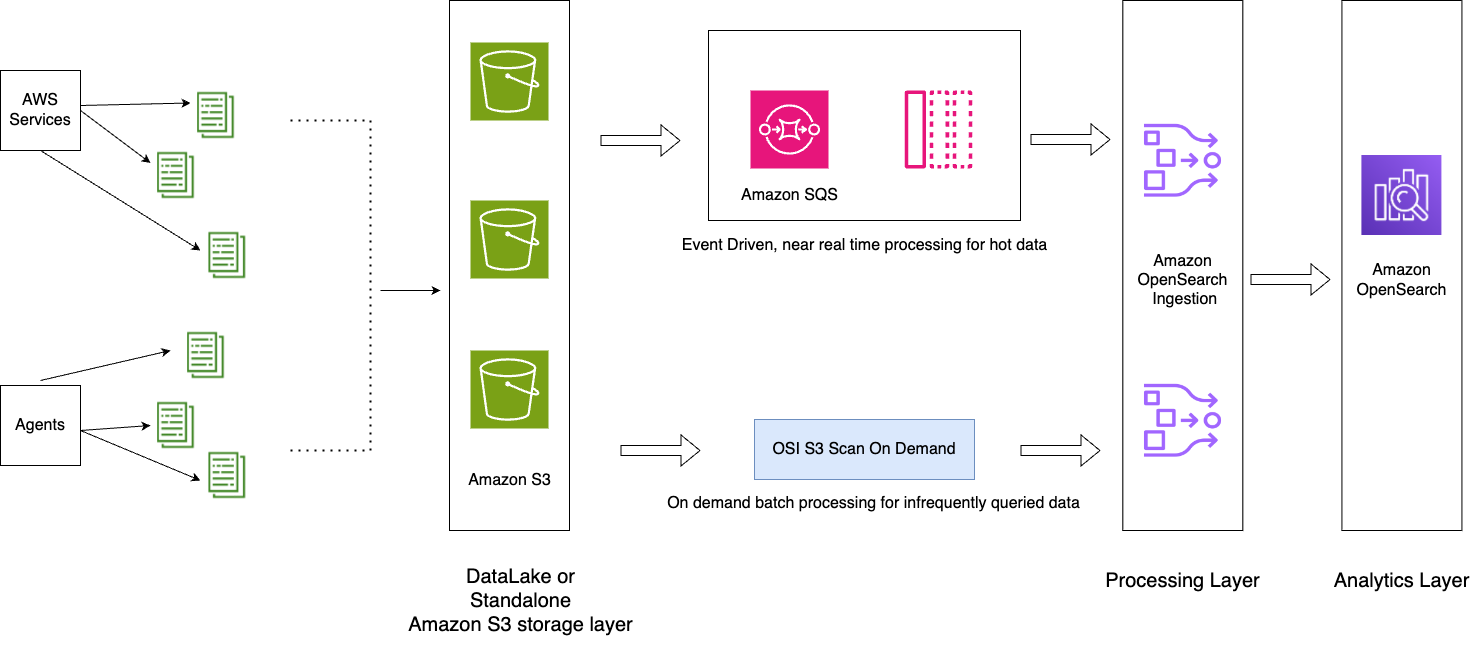
يتضمن سير العمل الخطوات التالية:
- يتم تدفق البيانات الواردة التي تم إنشاؤها بواسطة التطبيقات إلى بحيرة بيانات S3.
- بالنسبة لليوم الحالي، يتم استيعاب البيانات في خدمة OpenSearch باستخدام استيعاب S3-SQS في الوقت الفعلي تقريبًا من خلال الإعلامات التي تم إعدادها في حاويات S3.
- يتم الاحتفاظ بالفهارس اليومية لسهولة التمديد. تعمل سياسة ISM على أتمتة عملية التمرير أو حذف الفهارس التي مضى عليها أكثر من يومين.
- إذا تم تقديم طلب لتحليل البيانات بعد يومين ولم تكن البيانات في طبقة UltraWarm، فسيتم استيعاب البيانات باستخدام ميزة المسح لمرة واحدة في Amazon S2 بين النافذة الزمنية المحددة.
على سبيل المثال، إذا كان اليوم الحالي هو 10 يناير 2024، وتحتاج إلى بيانات من 6 يناير 2024 في فترة زمنية محددة للتحليل، فيمكنك إنشاء مسار OpenSearch Ingestion باستخدام فحص Amazon S3 في تكوين YAML الخاص بك، باستخدام start_time و end_time لتحديد متى تريد فحص الكائنات الموجودة في المجموعة:
الاعتبارات
الاستفادة من الضغط
يمكن ضغط البيانات الموجودة في Amazon S3، مما يقلل من البصمة الإجمالية للبيانات ويؤدي إلى توفير كبير في التكاليف. على سبيل المثال، إذا كنت تقوم بإنشاء 15 بيتابايت من سجلات تطبيق JSON الأولية شهريًا، فيمكنك استخدام آلية ضغط مثل GZIP، والتي يمكن أن تقلل الحجم إلى 1 بيتابايت تقريبًا أو أقل، مما يؤدي إلى توفير كبير في التكلفة.
أوقف خط الأنابيب عندما يكون ذلك ممكنًا
يقوم OpenSearch Ingestion بالتحجيم تلقائيًا بين الحد الأدنى والحد الأقصى لوحدات OCU المعينة لخط الأنابيب. بعد انتهاء المسار من فحص Amazon S3 للمدة المحددة المذكورة في تكوين المسار، يستمر المسار في العمل من أجل المراقبة المستمرة عند الحد الأدنى من وحدات OCU.
بالنسبة للعرض عند الطلب لفترات زمنية سابقة حيث لا تتوقع إنشاء كائنات جديدة، فكر في استخدام مقاييس المسار المدعومة مثل recordsOut.count لخلق الأمازون CloudWatch أجهزة الإنذار التي يمكن أن توقف خط الأنابيب. للحصول على قائمة بالمقاييس المدعومة، راجع مراقبة مقاييس خطوط الأنابيب.
تنفذ تنبيهات CloudWatch إجراءً عندما يتجاوز مقياس CloudWatch قيمة محددة لفترة معينة من الوقت. على سبيل المثال، قد ترغب في المراقبة recordsOut.count أن تكون 0 لمدة أطول من 5 دقائق لبدء طلب أوقف خط الأنابيب من خلال واجهة سطر الأوامر AWS (AWS CLI) أو API.
الحل 3: الاستعلامات المباشرة لخدمة OpenSearch باستخدام Amazon S3
استعلامات خدمة OpenSearch المباشرة باستخدام Amazon S3 (معاينة) هي طريقة جديدة للاستعلام عن السجلات التشغيلية في مستودعات البيانات Amazon S3 وS3 دون الحاجة إلى التبديل بين الخدمات. يمكنك الآن تحليل البيانات التي يتم الاستعلام عنها بشكل غير متكرر في مخازن الكائنات السحابية واستخدام التحليلات التشغيلية وإمكانات التصور في OpenSearch Service في نفس الوقت.
توفر خدمة OpenSearch استعلامات مباشرة مع Amazon S3 التكامل صفر ETL لتقليل التعقيد التشغيلي لتكرار البيانات أو إدارة أدوات التحليل المتعددة من خلال تمكينك من الاستعلام مباشرة عن بياناتك التشغيلية، مما يقلل التكاليف ووقت اتخاذ الإجراء. يمكن تكوين هذا التكامل الصفري ETL ضمن خدمة OpenSearch، حيث يمكنك الاستفادة من قوالب أنواع السجل المتنوعة، بما في ذلك لوحات المعلومات المحددة مسبقًا، وتكوين تسريعات البيانات المخصصة لنوع السجل هذا. تشمل القوالب سجلات تدفق VPC, موازنة تحميل مرنة السجلات، وسجلات NGINX، وتشمل التسريعات تخطي الفهارس، وطرق العرض المادية، والفهارس المغطاة.
باستخدام الاستعلامات المباشرة لخدمة OpenSearch Service مع Amazon S3، يمكنك إجراء استعلامات معقدة تعتبر بالغة الأهمية للتحليل الجنائي الأمني وتحليل التهديدات وربط البيانات عبر مصادر بيانات متعددة، مما يساعد الفرق في التحقيق في أوقات توقف الخدمة والأحداث الأمنية. بعد إنشاء التكامل، يمكنك البدء في الاستعلام عن بياناتك مباشرةً من لوحات معلومات OpenSearch أو OpenSearch API. يمكنك تدقيق الاتصالات للتأكد من إعدادها بطريقة قابلة للتطوير وفعالة من حيث التكلفة وآمنة.
تستخدم الاستعلامات المباشرة من OpenSearch Service إلى Amazon S3 جداول Spark داخل غراء AWS كتالوج البيانات. بعد فهرسة الجدول في كتالوج بيانات تعريف AWS Glue، يمكنك تشغيل الاستعلامات مباشرةً على بياناتك في مستودع بيانات S3 الخاص بك من خلال لوحات معلومات OpenSearch.
حل نظرة عامة
يوضح الرسم البياني التالي بنية الحل.
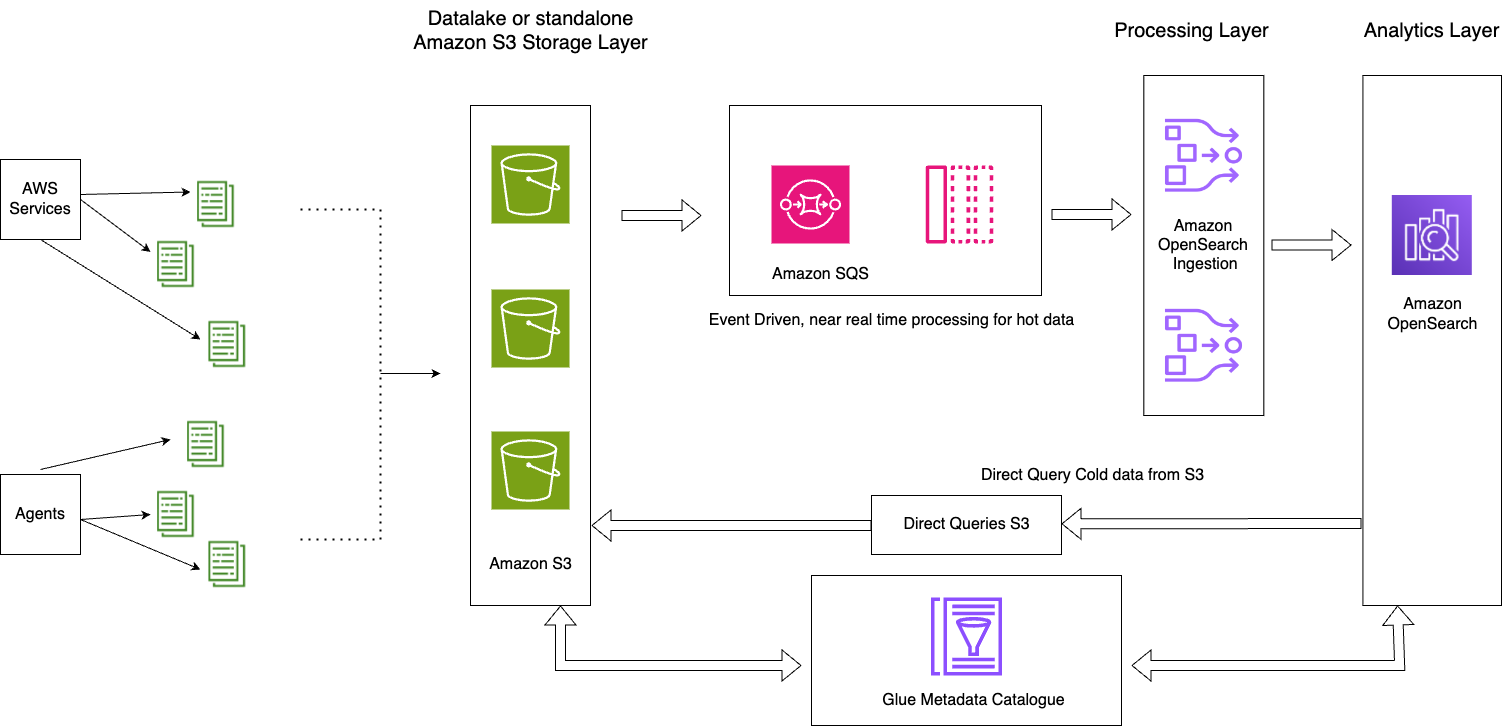
يتكون هذا الحل من المكونات الرئيسية التالية:
- تتم معالجة البيانات الساخنة لليوم الحالي في مجالات خدمة OpenSearch من خلال نمط البنية المستندة إلى الأحداث باستخدام ميزة معالجة OpenSearch Ingestion S3-SQS
- تتم إدارة دورة حياة البيانات الساخنة من خلال سياسات ISM المرفقة بالفهارس اليومية
- تتواجد البيانات الباردة في حاوية Amazon S3 الخاصة بك، ويتم تقسيمها وفهرستها
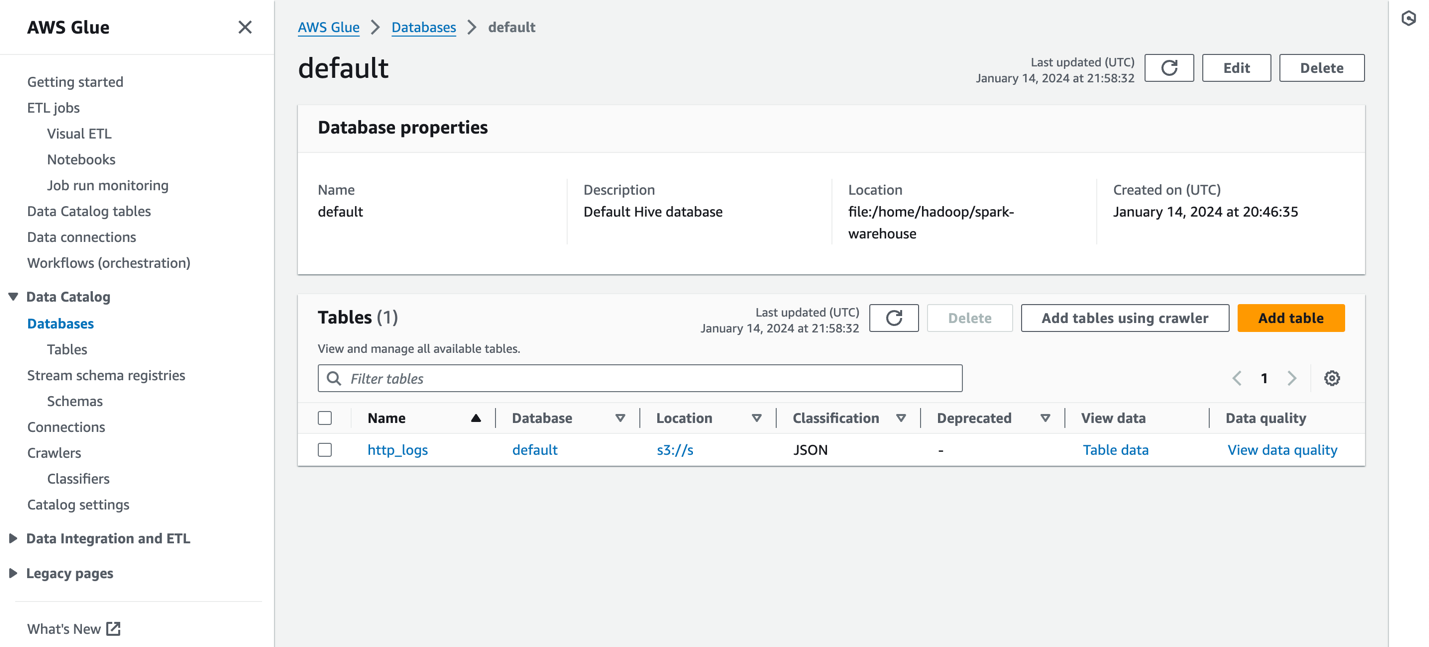
تظهر لقطة الشاشة التالية عينة http_logs الجدول المفهرس في كتالوج البيانات التعريفية لـ AWS Glue. للحصول على الخطوات التفصيلية، راجع كتالوج البيانات والزواحف في AWS Glue.
قبل إنشاء مصدر بيانات، يجب أن يكون لديك مجال خدمة OpenSearch بالإصدار 2.11 أو أحدث وجدول S3 مستهدف في كتالوج بيانات AWS Glue مع المناسب إدارة الهوية والوصول AWS (IAM) أذونات. سيحتاج IAM إلى الوصول إلى حاويات S3 المطلوبة ولديه حق الوصول للقراءة والكتابة إلى كتالوج بيانات AWS Glue. فيما يلي نموذج لسياسة الدور والثقة مع الأذونات المناسبة للوصول إلى كتالوج بيانات AWS Glue من خلال خدمة OpenSearch:
فيما يلي نموذج للسياسة المخصصة مع إمكانية الوصول إلى Amazon S3 وAWS Glue:
لإنشاء مصدر بيانات جديد على وحدة تحكم خدمة OpenSearch، قم بتوفير اسم مصدر البيانات الجديد، وحدد نوع مصدر البيانات كـ Amazon S3 مع كتالوج بيانات AWS Glue، واختر دور IAM لمصدر البيانات الخاص بك.
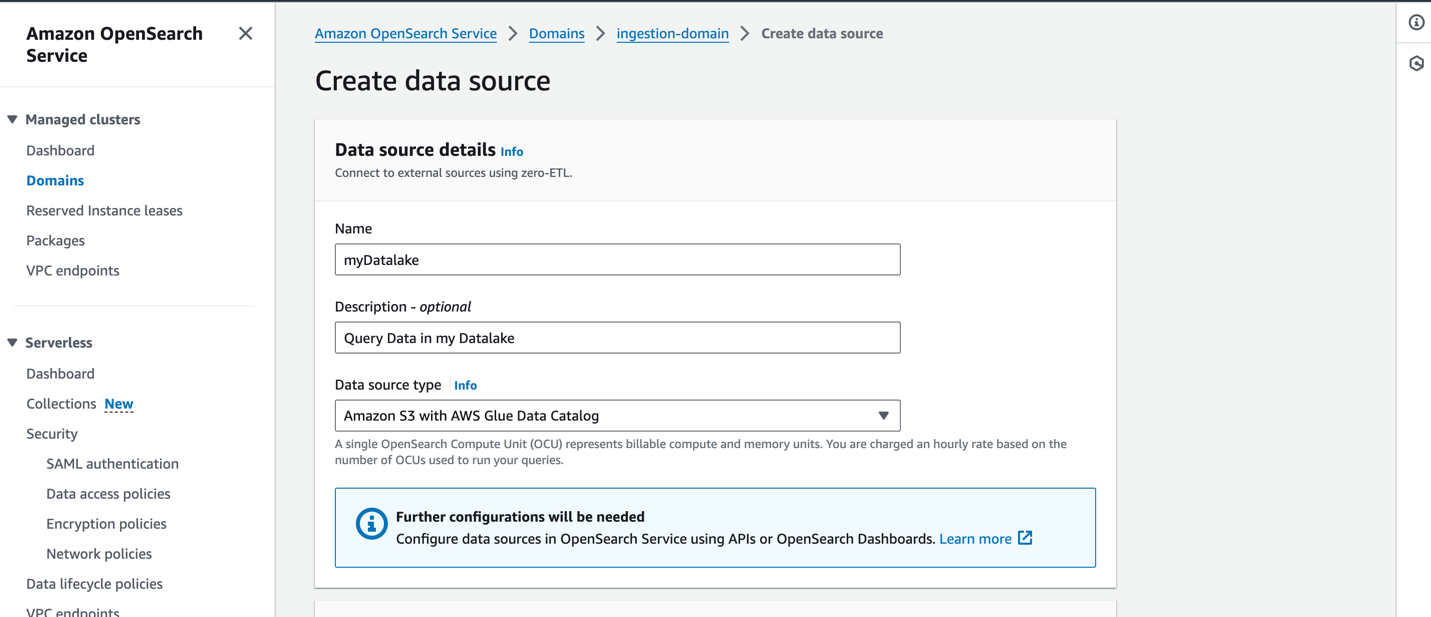
بعد إنشاء مصدر بيانات، يمكنك الانتقال إلى لوحة معلومات OpenSearch للمجال، والتي تستخدمها لتكوين التحكم في الوصول، وتحديد الجداول، وإعداد لوحات المعلومات المستندة إلى نوع السجل لأنواع السجلات الشائعة، والاستعلام عن بياناتك.

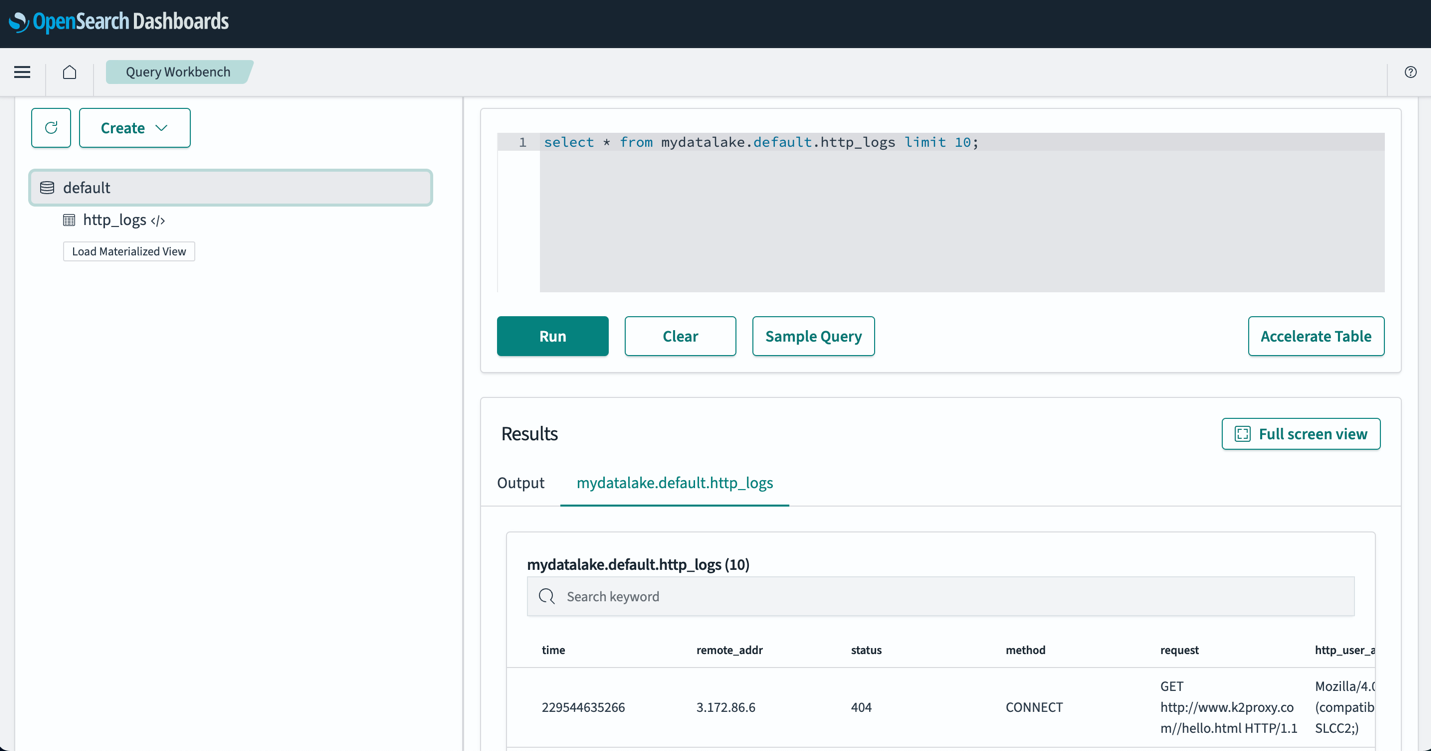
بعد إعداد الجداول الخاصة بك، يمكنك الاستعلام عن بياناتك في مستودع بيانات S3 الخاص بك من خلال لوحات معلومات OpenSearch. يمكنك تشغيل نموذج استعلام SQL لـ http_logs الجدول الذي قمت بإنشائه في جداول AWS Glue Data Catalog، كما هو موضح في لقطة الشاشة التالية.
أفضل الممارسات
استيعاب البيانات التي تحتاجها فقط
اعمل بشكل عكسي على احتياجات عملك وقم بإنشاء مجموعات البيانات الصحيحة التي ستحتاج إليها. قم بتقييم ما إذا كان بإمكانك تجنب استيعاب البيانات المزعجة واستيعاب البيانات المنسقة أو العينات أو المجمعة فقط. سيساعدك استخدام مجموعات البيانات المنظفة والمنسقة هذه على تحسين موارد الحوسبة والتخزين اللازمة لاستيعاب هذه البيانات.
تقليل حجم البيانات قبل استيعابها
عند تصميم مسارات استيعاب البيانات، استخدم إستراتيجيات مثل الضغط والتصفية والتجميع لتقليل حجم البيانات التي يتم استيعابها. سيسمح هذا بنقل أحجام بيانات أصغر عبر الشبكة وتخزينها في طبقة البيانات الخاصة بك.
وفي الختام
في هذا المنشور، ناقشنا الحلول التي تتيح تحليلات السجل على نطاق البيتابايت باستخدام خدمة OpenSearch في بنية بيانات حديثة. لقد تعلمت كيفية إنشاء مسار استيعاب بدون خادم لتسليم السجلات إلى مجال خدمة OpenSearch، وإدارة الفهارس من خلال سياسات ISM، وتكوين أذونات IAM لبدء استخدام OpenSearch Ingestion، وإنشاء تكوين مسار البيانات في بحيرة البيانات الخاصة بك. لقد تعلمت أيضًا كيفية إعداد واستخدام الاستعلامات المباشرة لخدمة OpenSearch مع ميزة Amazon S3 (المعاينة) للاستعلام عن البيانات من مستودع البيانات الخاص بك.
لاختيار نمط البنية المناسب لأعباء العمل لديك عند استخدام خدمة OpenSearch على نطاق واسع، ضع في اعتبارك الأداء وزمن الوصول والتكلفة ونمو حجم البيانات بمرور الوقت من أجل اتخاذ القرار الصحيح.
- استخدم بنية التخزين المتدرج مع سياسات إدارة حالة الفهرس عندما تحتاج إلى الوصول السريع إلى بياناتك الساخنة وترغب في موازنة التكلفة والأداء مع عقد UltraWarm للبيانات للقراءة فقط.
- استخدم "الاستيعاب عند الطلب" لبياناتك في خدمة OpenSearch عندما يمكنك تحمل فترات استجابة الاستيعاب للاستعلام عن بياناتك غير المحفوظة في العقد الساخنة الخاصة بك. يمكنك تحقيق وفورات كبيرة في التكاليف عند استخدام البيانات المضغوطة في Amazon S3 واستيعاب البيانات عند الطلب في خدمة OpenSearch.
- استخدم ميزة الاستعلام المباشر مع S3 عندما تريد تحليل سجلاتك التشغيلية مباشرة في Amazon S3 من خلال ميزات التحليلات والتصور الغنية لخدمة OpenSearch.
كخطوة تالية، راجع دليل مطور Amazon OpenSearch لاستكشاف السجلات وخطوط الأنابيب المترية التي يمكنك استخدامها لإنشاء حل قابل للمراقبة قابل للتطوير لتطبيقات مؤسستك.
حول المؤلف
 جاجاديش كومار (جاج) هو أحد كبار مهندسي الحلول المتخصصة في AWS ويركز على Amazon OpenSearch Service. إنه شغوف بشدة بهندسة البيانات ويساعد العملاء على بناء حلول تحليلية على نطاق واسع على AWS.
جاجاديش كومار (جاج) هو أحد كبار مهندسي الحلول المتخصصة في AWS ويركز على Amazon OpenSearch Service. إنه شغوف بشدة بهندسة البيانات ويساعد العملاء على بناء حلول تحليلية على نطاق واسع على AWS.
 موثو بيتشايماني هو أحد كبار مهندسي الحلول المتخصصة لدى Amazon OpenSearch Service. يقوم ببناء تطبيقات وحلول بحث واسعة النطاق. يهتم موثو بموضوعات الشبكات والأمن، ويقع مقره في أوستن، تكساس.
موثو بيتشايماني هو أحد كبار مهندسي الحلول المتخصصة لدى Amazon OpenSearch Service. يقوم ببناء تطبيقات وحلول بحث واسعة النطاق. يهتم موثو بموضوعات الشبكات والأمن، ويقع مقره في أوستن، تكساس.
 سام سيلفان هو مهندس الحلول المتخصص الرئيسي في Amazon OpenSearch Service.
سام سيلفان هو مهندس الحلول المتخصص الرئيسي في Amazon OpenSearch Service.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

