في عصر البيانات، تستخدم المؤسسات بشكل متزايد بحيرات البيانات لتخزين وتحليل كميات هائلة من البيانات المنظمة وغير المنظمة. توفر بحيرات البيانات مستودعًا مركزيًا للبيانات من مصادر مختلفة، مما يمكّن المؤسسات من إطلاق العنان للرؤى القيمة ودفع عملية صنع القرار المستندة إلى البيانات. ومع ذلك، مع استمرار نمو أحجام البيانات، يصبح تحسين تخطيط البيانات وتنظيمها أمرًا بالغ الأهمية للاستعلام والتحليل الفعال.
أحد التحديات الرئيسية في بحيرات البيانات هو احتمال بطء أداء الاستعلام، خاصة عند التعامل مع مجموعات البيانات الكبيرة. يمكن أن يعزى ذلك إلى عوامل مثل تخطيط البيانات غير الفعال، مما يؤدي إلى المسح المفرط للبيانات والاستخدام غير الفعال لموارد الحوسبة. ولمواجهة هذا التحدي، يمكن للممارسات الشائعة مثل التقسيم والتخزين تحسين أداء الاستعلام بشكل كبير وتقليل تكاليف الحساب.
التقسيم هي تقنية تقسم مجموعة بيانات كبيرة إلى أجزاء أصغر وأكثر قابلية للإدارة بناءً على معايير محددة، مثل التاريخ أو المنطقة أو فئة المنتج. من خلال تقسيم البيانات، يمكن للاستعلامات التحليلية النهائية تخطي الأقسام غير ذات الصلة، مما يقلل من كمية البيانات التي تحتاج إلى فحصها ومعالجتها. يمكنك استخدام أعمدة الأقسام في جملة WHERE في الاستعلامات لفحص الأقسام المحددة التي يحتاجها الاستعلام الخاص بك فقط. يمكن أن يؤدي هذا إلى أوقات تشغيل أسرع للاستعلام واستخدام أكثر كفاءة للموارد. إنه يعمل بشكل جيد بشكل خاص عندما يتم اختيار الأعمدة ذات العلاقة الأساسية المنخفضة كمفتاح.
ماذا لو كان لديك عمود ذو عدد كبير من العناصر وتحتاج أحيانًا إلى تصفيته حسب عملاء VIP؟ عادةً ما يتم تعريف كل عميل بمعرف يمكن أن يكون بالملايين. التقسيم ليس مناسبًا لمثل هذه الأعمدة ذات العلاقة الأساسية العالية لأنك ستنتهي بملفات صغيرة، وتصفية قسم بطيئة، وكثافة عالية خدمة تخزين أمازون البسيطة (Amazon S3) تكلفة واجهة برمجة التطبيقات (يتم إنشاء بادئة S3 واحدة لكل قيمة عمود القسم). على الرغم من أنه يمكنك استخدام التقسيم باستخدام مفتاح طبيعي مثل المدينة أو الولاية لتضييق مجموعة البيانات الخاصة بك إلى حد ما، إلا أنه لا يزال من الضروري الاستعلام عبر الأقسام المستندة إلى التاريخ إذا كانت بياناتك عبارة عن سلسلة زمنية.
هذا هو المكان دلو يأتي دور. يتأكد التجميع من أن جميع الصفوف التي لها نفس القيم لعمود واحد أو أكثر تنتهي في نفس الملف. بدلاً من ملف واحد لكل قيمة، مثل التقسيم، يتم استخدام دالة التجزئة لتوزيع القيم بالتساوي عبر عدد ثابت من الملفات. من خلال تنظيم البيانات بهذه الطريقة، يمكنك إجراء تصفية فعالة، لأن المجموعات ذات الصلة فقط هي التي تحتاج إلى المعالجة، مما يقلل من الحمل الحسابي.
هناك خيارات متعددة لتنفيذ التجميع على AWS. أحد الأساليب هو استخدام أمازون أثينا عبارة CREATE TABLE AS SELECT (CTAS)، والتي تسمح لك بإنشاء جدول مضمن مباشرة من الاستعلام. بدلا من ذلك، يمكنك استخدام غراء AWS لـ Apache Spark، الذي يوفر دعمًا مدمجًا لتكوينات التجميع أثناء عملية تحويل البيانات. يسمح لك AWS Glue بتحديد معلمات التجميع، مثل عدد المجموعات والأعمدة التي سيتم تجميعها، مما يوفر تخطيط بيانات محسنًا للاستعلام الفعال مع Athena.
في هذا المنشور، نناقش كيفية تنفيذ التجميع على مستودعات بيانات AWS، بما في ذلك استخدام بيان Athena CTAS وAWS Glue لـ Apache Spark. نحن نغطي أيضًا عملية تجميع جداول Apache Iceberg.
مثال على حالة الاستخدام
في هذا المنشور، يمكنك استخدام مجموعة بيانات عامة، وهي قاعدة البيانات السطحية المتكاملة لـ NOAA. يقوم محللو البيانات بإجراء استعلامات لمرة واحدة للبيانات خلال السنوات الخمس الماضية من خلال Athena. معظم الاستعلامات مخصصة لمحطات محددة ذات أنواع تقارير محددة. يجب إكمال الاستعلامات خلال 5 ثوانٍ، ويجب تحسين التكلفة بعناية. في هذا السيناريو، أنت مهندس بيانات مسؤول عن تحسين أداء الاستعلام والتكلفة.
على سبيل المثال، إذا أراد أحد المحللين استرداد البيانات الخاصة بمحطة معينة (على سبيل المثال، معرف المحطة 123456) بنوع تقرير معين (على سبيل المثال، CRN01)، قد يبدو الاستعلام كالاستعلام التالي:
في حالة قاعدة البيانات السطحية المتكاملة التابعة لـ NOAA، فإن station_id من المحتمل أن يكون للعمود عدد كبير من العناصر، مع العديد من معرفات المحطات الفريدة. ومن ناحية أخرى فإن report_type قد يحتوي العمود على أصل منخفض نسبيًا، مع مجموعة محدودة من أنواع التقارير. في ضوء هذا السيناريو، سيكون من الجيد تقسيم البيانات حسبها report_type ودلو بها station_id.
باستخدام استراتيجية التقسيم والتجميع هذه، يمكن لـ Athena أولاً إزالة الأقسام لأنواع التقارير غير ذات الصلة، ثم فحص المجموعات الموجودة داخل القسم ذي الصلة فقط والتي تطابق معرف المحطة المحدد، مما يقلل بشكل كبير من كمية البيانات التي تتم معالجتها وتسريع أوقات تشغيل الاستعلام. لا يفي هذا الأسلوب بمتطلبات أداء الاستعلام فحسب، بل يساعد أيضًا في تحسين التكاليف عن طريق تقليل كمية البيانات التي تم فحصها وتحرير فواتيرها لكل استعلام.
في هذه المقالة، سنفحص كيفية تأثر أداء الاستعلام بتخطيط البيانات، على وجه الخصوص، التجميع. نقوم أيضًا بمقارنة ثلاث طرق مختلفة لتحقيق التجميع. يمثل الجدول التالي شروط إنشاء الجداول.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | glue_bucketed | athena_bucketed_iceberg |
| شكل | CSV | الباركيه | الباركيه | الباركيه | الباركيه |
| ضغط | ن / أ | لاذع | لاذع | لاذع | لاذع |
| تم إنشاؤها عبر | ن / أ | أثينا CTAS | أثينا CTAS | الغراء إي تي إل | أثينا CTAS مع جبل الجليد |
| محرك | ن / أ | ترينو | ترينو | أباتشي سبارك | اباتشي فيض |
| هل مقسمة؟ | نعم ولكن بطريقة مختلفة | نعم | نعم | نعم | نعم |
| هل دلو؟ | لا | لا | نعم | نعم | نعم |
noaa_remote_original يتم تقسيمها بواسطة year العمود، ولكن ليس من قبل report_type عمود. يمثل هذا الصف ما إذا كان الجدول مقسمًا بواسطة الأعمدة الفعلية المستخدمة في الاستعلامات.
الجدول الأساسي
في هذا المنشور، يمكنك إنشاء عدة جداول بشروط مختلفة: بعضها بدون تجميع والبعض الآخر مزود بتجميع، لعرض خصائص أداء التجميع. أولاً، لنقم بإنشاء جدول أصلي باستخدام بيانات NOAA. في الخطوات اللاحقة، يمكنك استيعاب البيانات من هذا الجدول لإنشاء جداول الاختبار.
هناك طرق متعددة لتحديد تعريف الجدول: تشغيل DDL، وزاحف AWS Glue، وواجهة برمجة تطبيقات AWS Glue Data Catalog، وما إلى ذلك. في هذه الخطوة، تقوم بتشغيل DDL عبر وحدة تحكم Athena.
أكمل الخطوات التالية لإنشاء "bucketing_blog"."noaa_remote_original" الجدول في كتالوج البيانات:
- افتح وحدة تحكم أثينا.
- في محرر الاستعلام، قم بتشغيل DDL التالي لإنشاء قاعدة بيانات AWS Glue جديدة:
- في حالة قاعدة البيانات مع البيانات، اختر
bucketing_blogلتعيين قاعدة البيانات الحالية. - قم بتشغيل DDL التالي لإنشاء الجدول الأصلي:
نظرًا لأن البيانات المصدر تحتوي على حقول مقتبسة، فإننا نستخدم OpenCSVSerde بدلا من الافتراضي LazySimpleSerde.
تحتوي ملفات CSV هذه على صف رأس، ونطلب من Athena تخطيه عن طريق إضافته skip.header.line.count وتعيين القيمة إلى 1.
لمزيد من التفاصيل ، يرجى الرجوع إلى OpenCSVSerDe لمعالجة ملف CSV.
- قم بتشغيل DDL التالي لإضافة أقسام. نضيف أقسامًا لمدة 5 سنوات فقط من أصل 124 عامًا بناءً على متطلبات حالة الاستخدام:
- قم بتشغيل DML التالي للتحقق مما إذا كان بإمكانك الاستعلام عن البيانات بنجاح:
أنت الآن جاهز لبدء الاستعلام عن الجدول الأصلي لفحص أداء الأساس.
- قم بتشغيل استعلام مقابل الجدول الأصلي لتقييم أداء الاستعلام كأساس. يقوم الاستعلام التالي بتحديد السجلات لخمس محطات محددة بنوع التقرير
CRN05: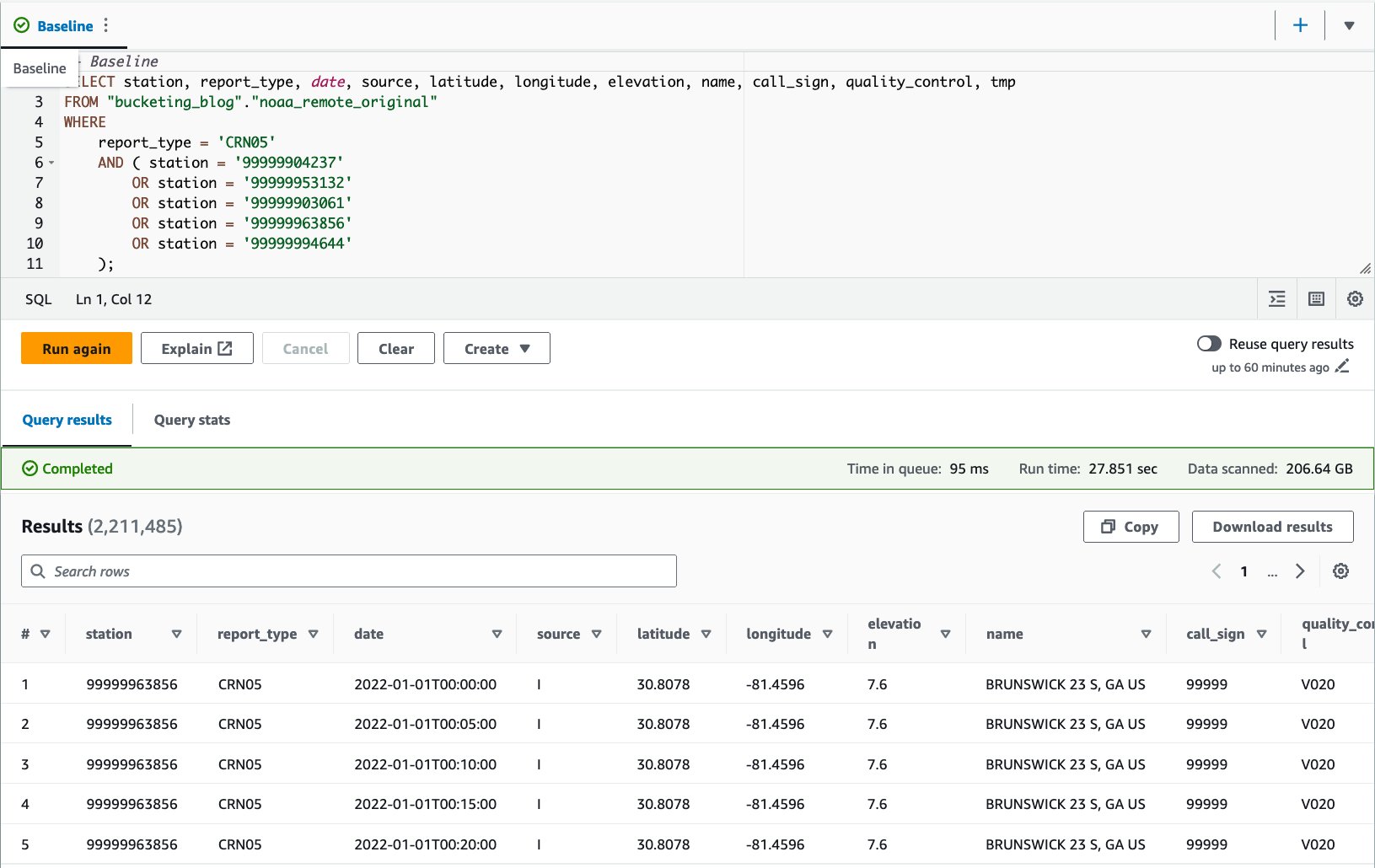
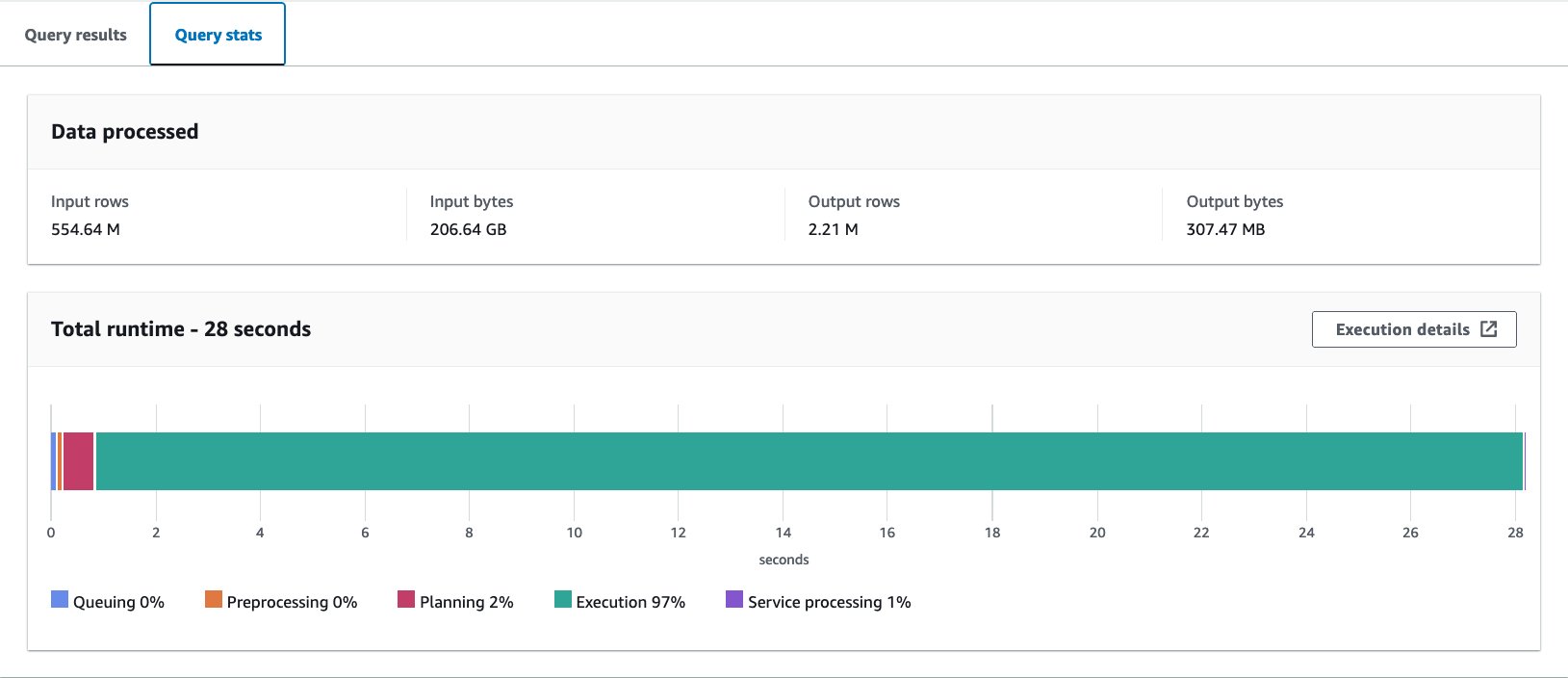
قمنا بتشغيل هذا الاستعلام 10 مرات. يبلغ متوسط وقت تشغيل الاستعلام لـ 10 استعلامات 27.6 ثانية، وهو أطول بكثير من هدفنا البالغ 10 ثوانٍ، ويتم فحص بيانات بحجم 155.75 جيجابايت لإرجاع 1.65 مليون سجل. هذا هو الأداء الأساسي للجدول الخام الأصلي. لقد حان الوقت لبدء تحسين تخطيط البيانات من خط الأساس هذا.
بعد ذلك، يمكنك إنشاء جداول بشروط مختلفة عن الجدول الأصلي: واحد بدون تجميع والآخر مزود بتجميع، ثم قارنهما.
تحسين تخطيط البيانات باستخدام Athena CTAS
في هذا القسم، نستخدم استعلام Athena CTAS لتحسين تخطيط البيانات وتنسيقها.
أولاً، لنقم بإنشاء جدول مقسم ولكن بدون تجميع. يتم تقسيم الجدول الجديد حسب العمود report_type لأن معظم الاستعلامات المتوقعة تستخدم هذا العمود في جملة WHERE، ويتم تخزين الكائنات على هيئة Parquet مع ضغط Snappy.
- افتح محرر استعلام أثينا.
- قم بتشغيل الاستعلام التالي، مع توفير مجموعة S3 الخاصة بك والبادئة:
يجب أن تبدو بياناتك مثل لقطات الشاشة التالية.
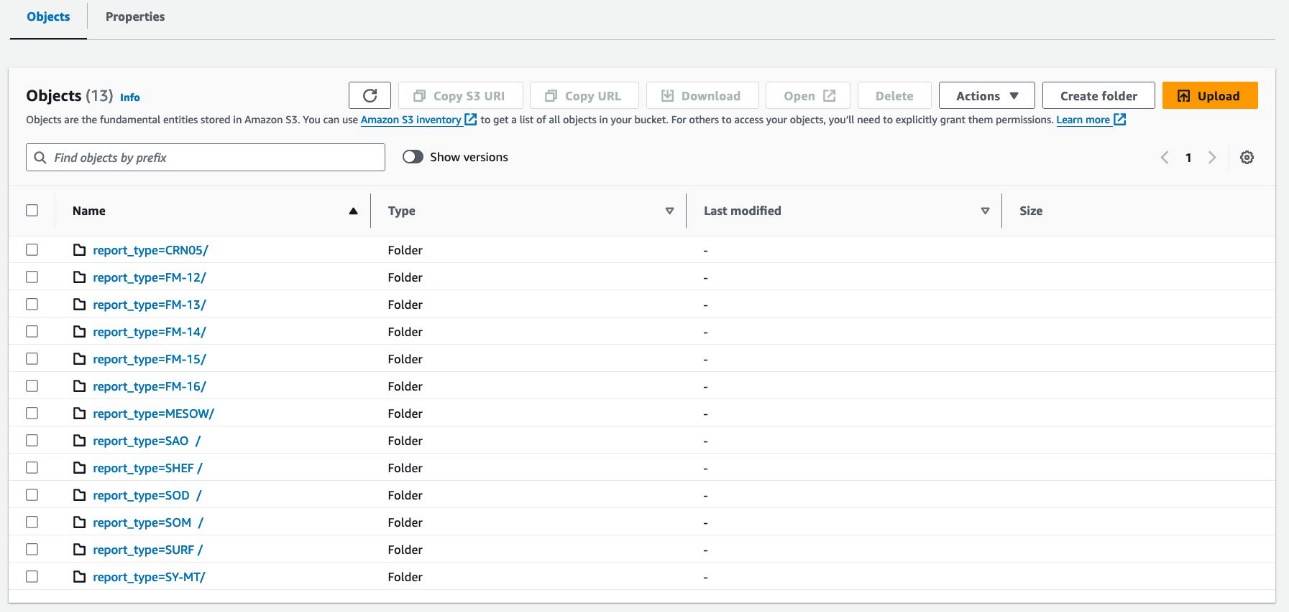
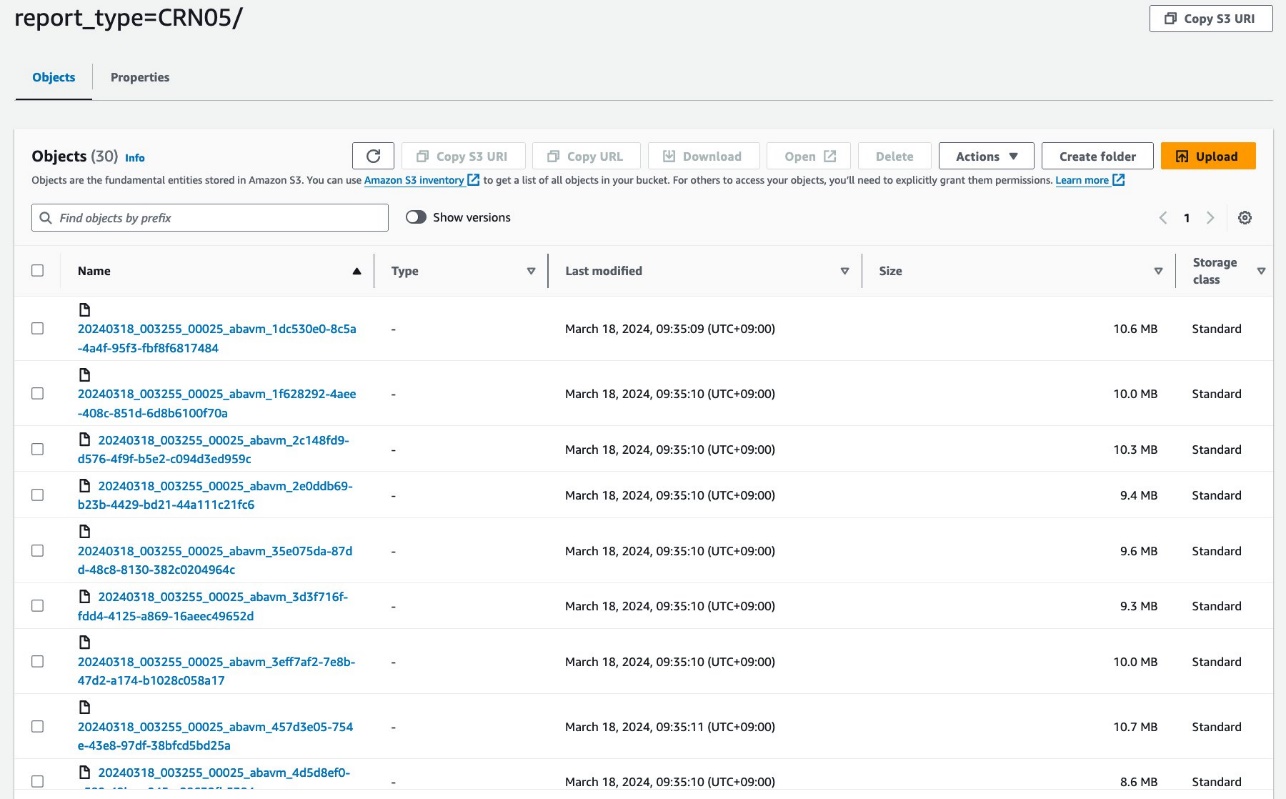
يوجد 30 ملفًا تحت القسم.
بعد ذلك، يمكنك إنشاء جدول يتضمن نمط الخلية. يجب ضبط عدد المجموعات بعناية من خلال التجارب التي تناسب حالة الاستخدام الخاصة بك. بشكل عام، كلما زاد عدد الجرافات لديك، قلت التفاصيل، مما قد يؤدي إلى أداء أفضل. ومن ناحية أخرى، قد يؤدي وجود عدد كبير جدًا من الملفات الصغيرة إلى عدم الكفاءة في تخطيط الاستعلام ومعالجته. كما أن التجميع لا يعمل إلا إذا كنت تستعلم عن بعض قيم مفتاح التجميع. كلما زادت القيم التي تضيفها إلى استعلامك، زاد احتمال أن ينتهي بك الأمر إلى قراءة جميع المجموعات.
فيما يلي الاستعلام الأساسي لتحسينه:
في هذا المثال، سيتم تجميع الجدول في 16 مجموعة بواسطة عمود ذو قيمة أساسية عالية (station)، والذي من المفترض أن يتم استخدامه لجملة WHERE في الاستعلام. جميع الشروط الأخرى تبقى كما هي. يحتوي الاستعلام الأساسي على خمس قيم في معرف المحطة، وتتوقع أن تحتوي الاستعلامات على هذا الرقم على الأكثر، وهو أقل بما يكفي من عدد المجموعات، لذلك يجب أن يعمل 16 بشكل جيد. من الممكن تحديد عدد أكبر من المجموعات، لكن لا يمكن استخدام CTAS إذا تجاوز العدد الإجمالي للأقسام 100.
- قم بتشغيل الاستعلام التالي:
يقوم الاستعلام بإنشاء كائنات S3 منظمة كما هو موضح في لقطات الشاشة التالية.
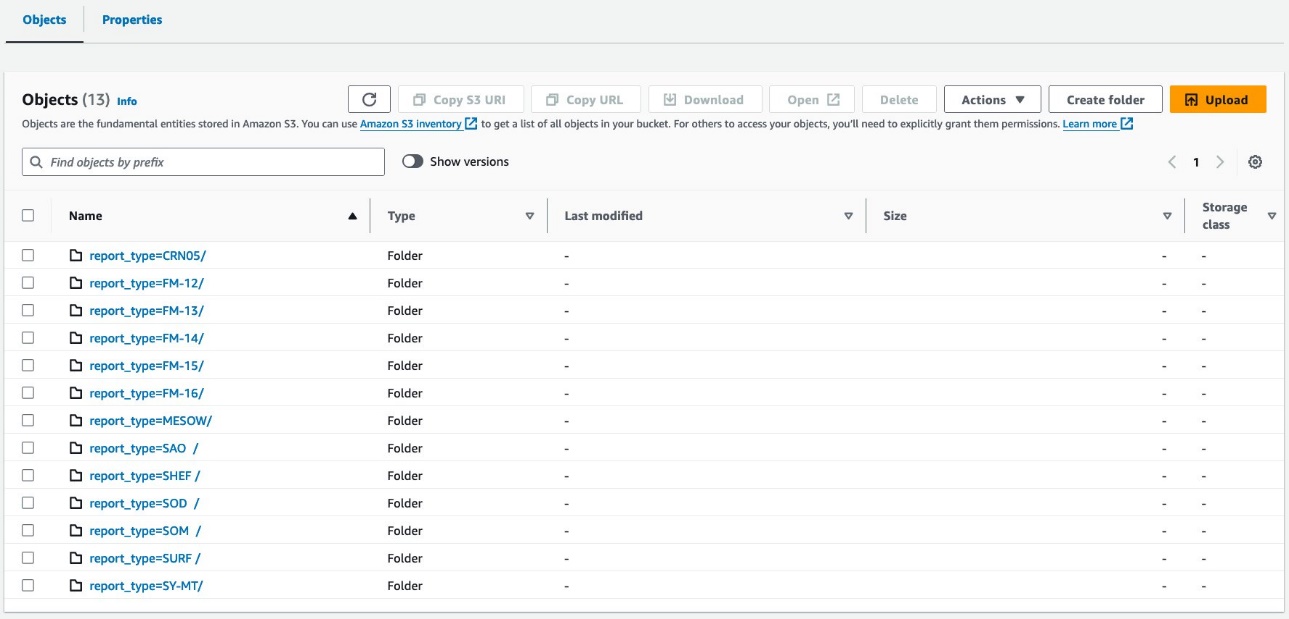

يبدو التخطيط على مستوى الجدول متماثلًا تمامًا athena_non_bucketed و athena_bucketed: يوجد 13 قسمًا في كل جدول. الفرق هو عدد الكائنات الموجودة تحت الأقسام. يوجد 16 كائنًا (حاوية) لكل قسم، يبلغ حجم كل منها حوالي 10-25 ميجابايت في هذه الحالة. يكون عدد المجموعات ثابتًا عند القيمة المحددة بغض النظر عن كمية البيانات، لكن حجم المجموعة يعتمد على كمية البيانات.
أنت الآن جاهز للاستعلام مقابل كل جدول لتقييم أداء الاستعلام. سيقوم الاستعلام بتحديد السجلات بخمس محطات محددة ونوع التقرير CRN05 على مدى السنوات الخمس الماضية. على الرغم من أنك لا تستطيع معرفة البيانات الخاصة بمحطة معينة الموجودة في أي مجموعة، فقد تم حسابها وتحديد موقعها بشكل صحيح بواسطة Athena.
- استعلم عن الجدول غير المعبأ بالعبارة التالية:

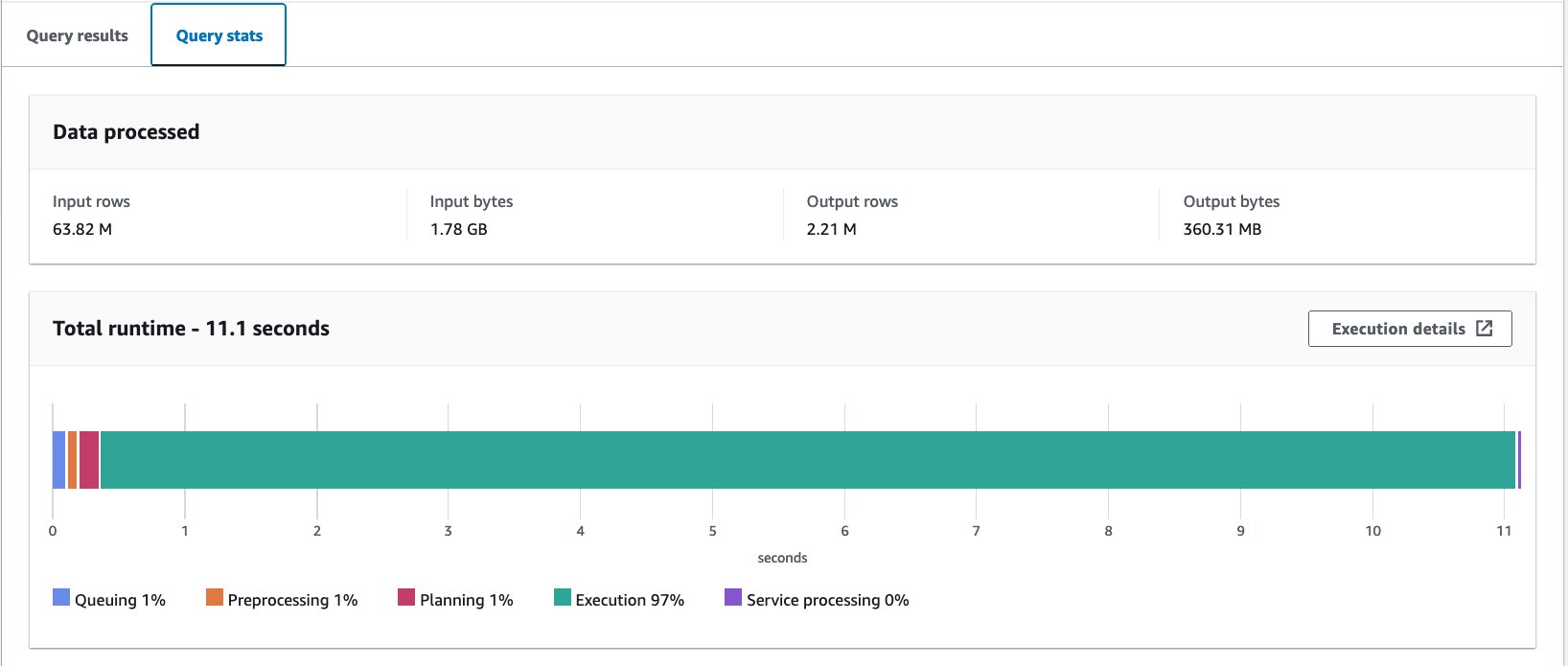
قمنا بتشغيل هذا الاستعلام 10 مرات. يبلغ متوسط وقت تشغيل الاستعلامات العشرة 10 ثانية، ويتم فحص 10.95 ميجابايت من البيانات لإرجاع 358 مليون سجل. لقد تم تقليل وقت التشغيل وحجم الفحص بشكل ملحوظ لأنك قمت بتقسيم البيانات، ويمكنك الآن قراءة قسم واحد فقط حيث تم تخطي 2.21 قسمًا من 12. بالإضافة إلى ذلك، انخفضت كمية البيانات الممسوحة ضوئيًا من 13 جيجابايت إلى 206 ميجابايت، وهو ما يمثل انخفاضًا بنسبة 360%. لا يرجع ذلك إلى التقسيم فحسب، بل أيضًا إلى تغيير تنسيقه إلى Parquet والضغط باستخدام Snappy.
- الاستعلام عن الجدول المعبأ بالعبارة التالية:
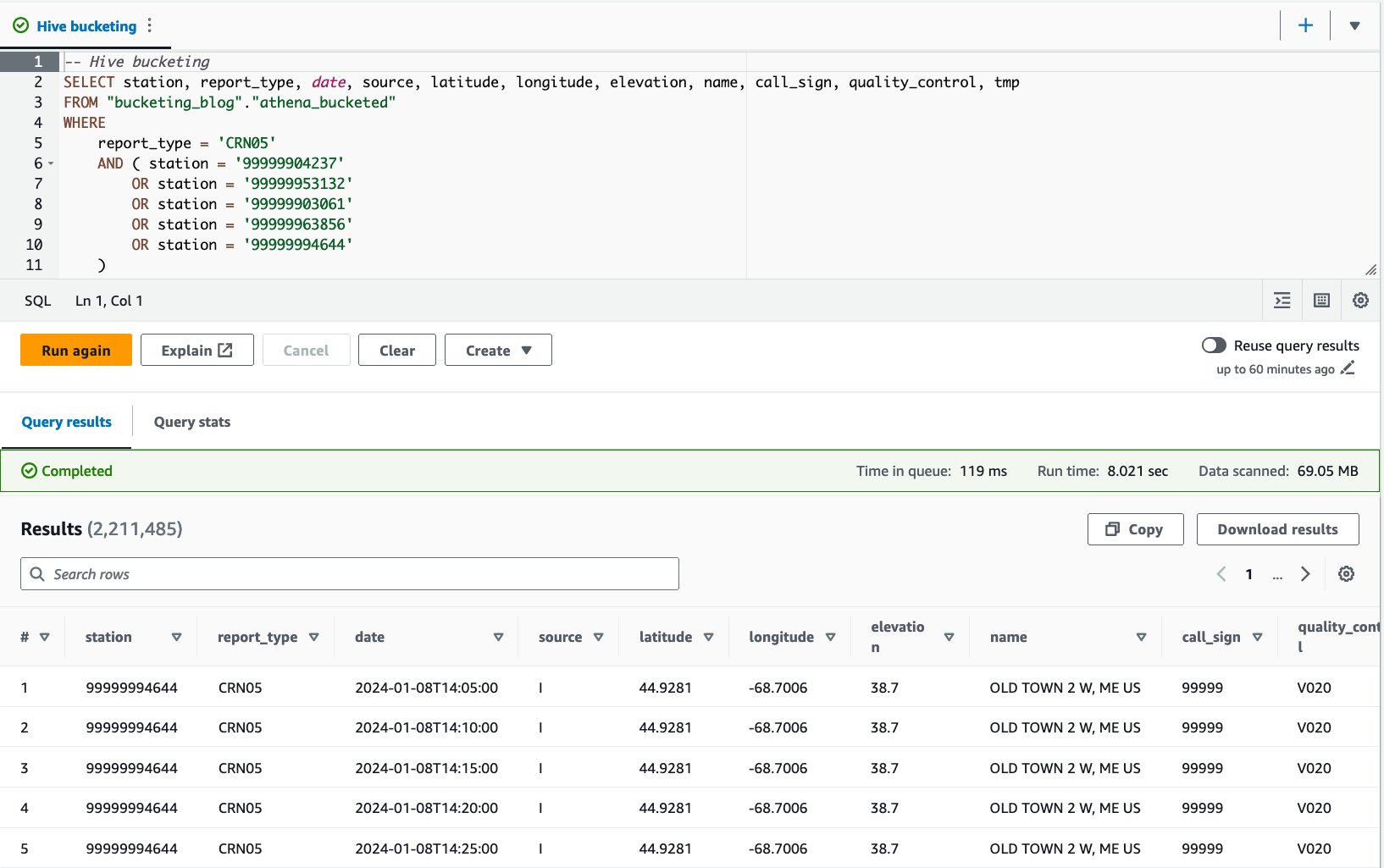
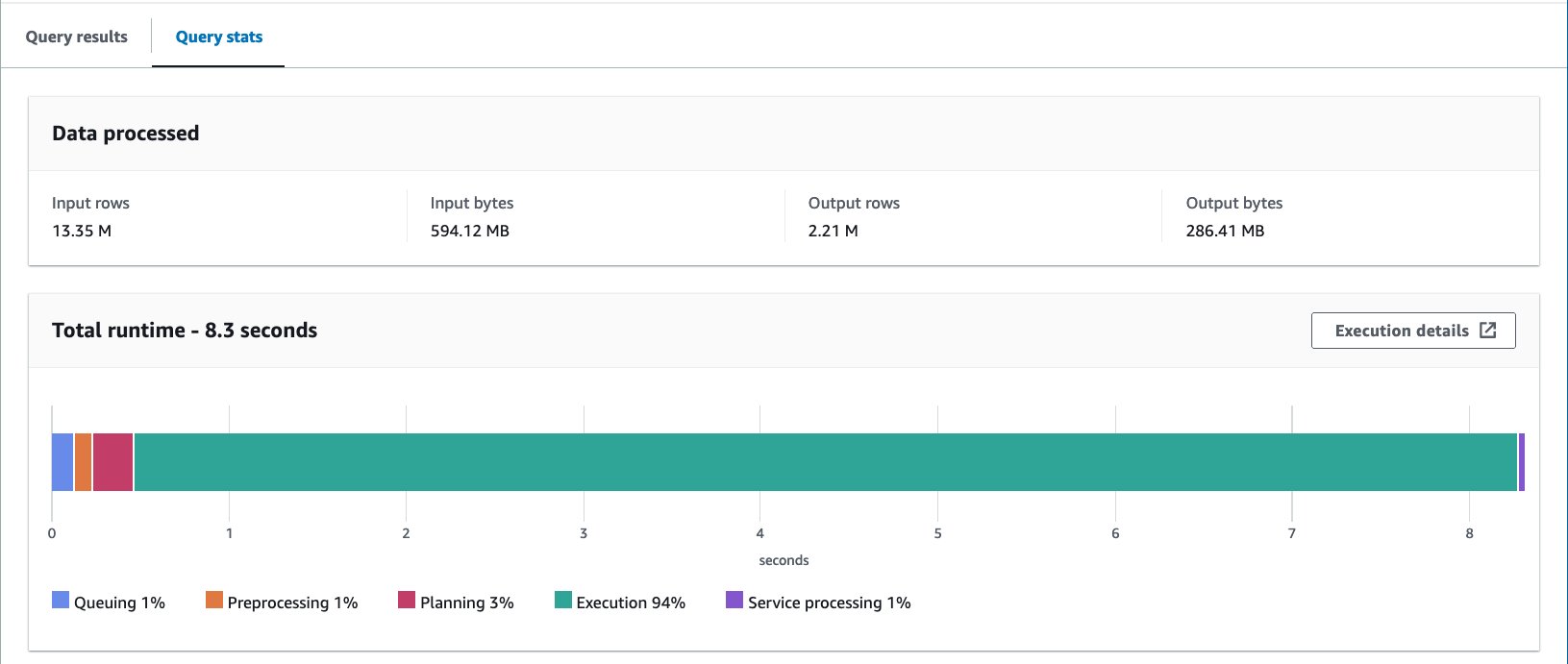
قمنا بتشغيل هذا الاستعلام 10 مرات. يبلغ متوسط وقت تشغيل الاستعلامات العشرة 10 ثانية، ويتم فحص 7.82 ميجابايت من البيانات لإرجاع 69 مليون سجل. وهذا يعني انخفاض متوسط وقت التشغيل من 2.21 إلى 10.95 ثانية (-7.82%)، وانخفاضًا كبيرًا في البيانات الممسوحة ضوئيًا من 29 ميجابايت إلى 358 ميجابايت (-69%) لإرجاع نفس عدد السجلات مقارنة بالجدول غير المضمن. . في هذه الحالة، تم تحسين كل من وقت التشغيل والبيانات التي تم فحصها عن طريق التخزين. وهذا يعني أن التخزين لم يساهم في الأداء فحسب، بل أيضًا في خفض التكلفة.
الاعتبارات
كما ذكرنا سابقًا، قم بقياس حجم الحاوية الخاصة بك بعناية لتحقيق أقصى قدر من أداء الاستعلام الخاص بك. لا يعمل التجميع إلا إذا كنت تستعلم عن بعض قيم مفتاح التجميع. فكر في إنشاء مجموعات أكثر من عدد القيم المتوقعة في الاستعلام الفعلي.
بالإضافة إلى ذلك، يقتصر استعلام Athena CTAS على إنشاء ما يصل إلى 100 قسم في المرة الواحدة. إذا كنت بحاجة إلى عدد كبير من الأقسام، فقد ترغب في استخدام AWS Glue لاستخراج وتحويل وتحميل (ETL)، على الرغم من وجود الحل البديل للتقسيم إلى عبارات SQL متعددة.
تحسين تخطيط البيانات باستخدام AWS Glue ETL
Apache Spark هو إطار معالجة موزع مفتوح المصدر يمكّن ETL المرن مع PySpark وScala وSpark SQL. يسمح لك بتقسيم بياناتك وتجميعها بناءً على متطلباتك. لدى Spark العديد من خيارات الضبط لتسريع المهام. يمكنك أتمتة ومراقبة وظائف Spark دون عناء. في هذا القسم، نستخدم وظائف AWS Glue ETL لتشغيل رمز Spark لتحسين تخطيط البيانات.
على عكس تجميع Athena، يستخدم AWS Glue ETL التجميع المستند إلى Spark كخوارزمية تجميع. كل ما عليك فعله هو إضافة خاصية الجدول التالية إلى الجدول: bucketing_format = 'spark'. للحصول على تفاصيل حول خاصية الجدول هذه، راجع التقسيم والدلو في أثينا.
أكمل الخطوات التالية لإنشاء جدول يحتوي على حاوية من خلال AWS Glue ETL:
- في وحدة تحكم AWS Glue ، اختر وظائف ETL في جزء التنقل.
- اختار خلق وظيفة واختر ETL المرئي.
- تحت أضف العقد، اختر كتالوج بيانات AWS Glue For مصادر.
- في حالة قاعدة البيانات، اختر
bucketing_blog. - في حالة طاولات ومكاتب ، اختر
noaa_remote_original. - تحت أضف العقد، اختر تغيير المخطط For التحويلات.
- تحت أضف العقد، اختر تحويل مخصص For التحويلات.
- في حالة الاسم، أدخل
ToS3WithBucketing. - في حالة الآباء العقدة، اختر تغيير المخطط.
- في حالة كتلة التعليمات البرمجية، أدخل مقتطف الشفرة التالي:
تعرض لقطة الشاشة التالية المهمة التي تم إنشاؤها باستخدام AWS Glue Studio لإنشاء جدول وبيانات.
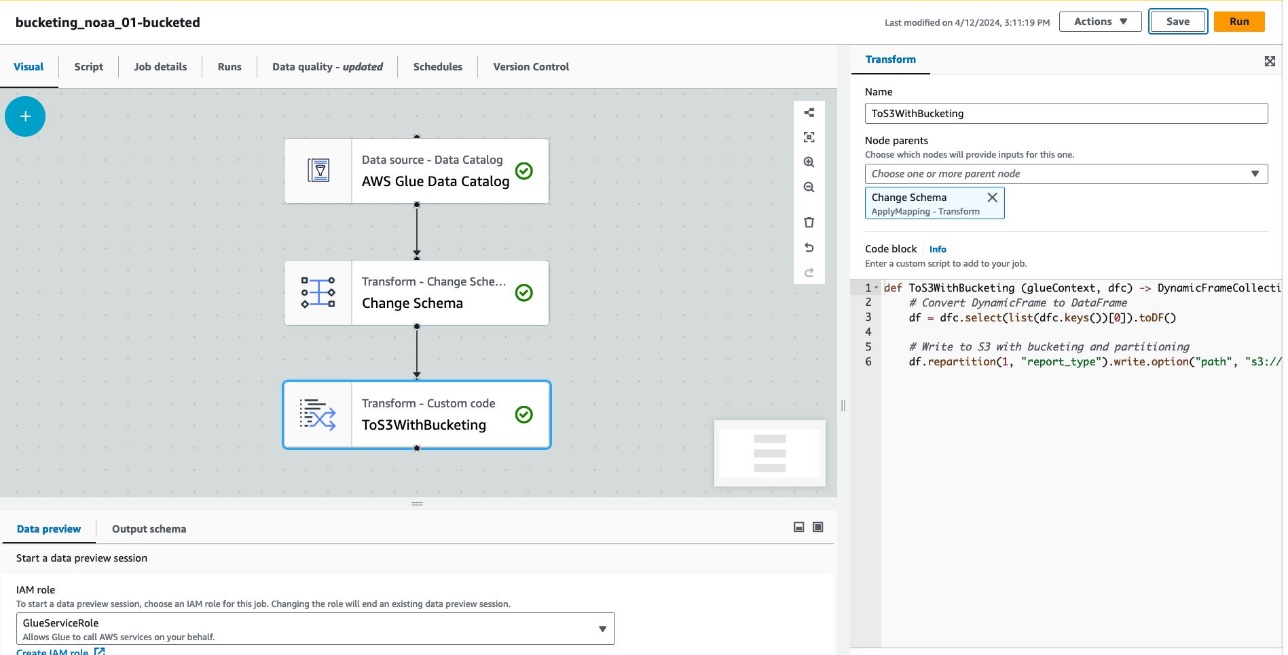
تمثل كل عقدة ما يلي:
- • كتالوج بيانات AWS Glue تقوم العقدة بتحميل
noaa_remote_originalالجدول من كتالوج البيانات - • تغيير المخطط تتأكد العقدة من تحميل الأعمدة المسجلة في كتالوج البيانات
- • ToS3WithBucketing تقوم العقدة بكتابة البيانات إلى Amazon S3 باستخدام كل من التقسيم والتخزين المستند إلى Spark
تمت كتابة المهمة بنجاح في المحرر المرئي.
- تحت تفاصيل الوظيفة، ل دور IAM، اختر خاصتك إدارة الهوية والوصول AWS (IAM) دور لهذه الوظيفة.
- في حالة نوع العامل، اختر G.8X.
- في حالة عدد العمال المطلوب، أدخل 5.
- اختار حفظ، ثم اختر يجري.
بعد هذه الخطوات الجدول glue_bucketed. تم إنشاء.
- اختار طاولات الطعام في جزء التنقل، ثم اختر الجدول
glue_bucketed. - على الإجراءات القائمة، اختر تحرير الجدول مع إدارة.
- في مجلة خصائص الجدول القسم، اختر أضف.
- أضف زوج مفاتيح مع المفتاح
bucketing_formatوشرارة القيمة.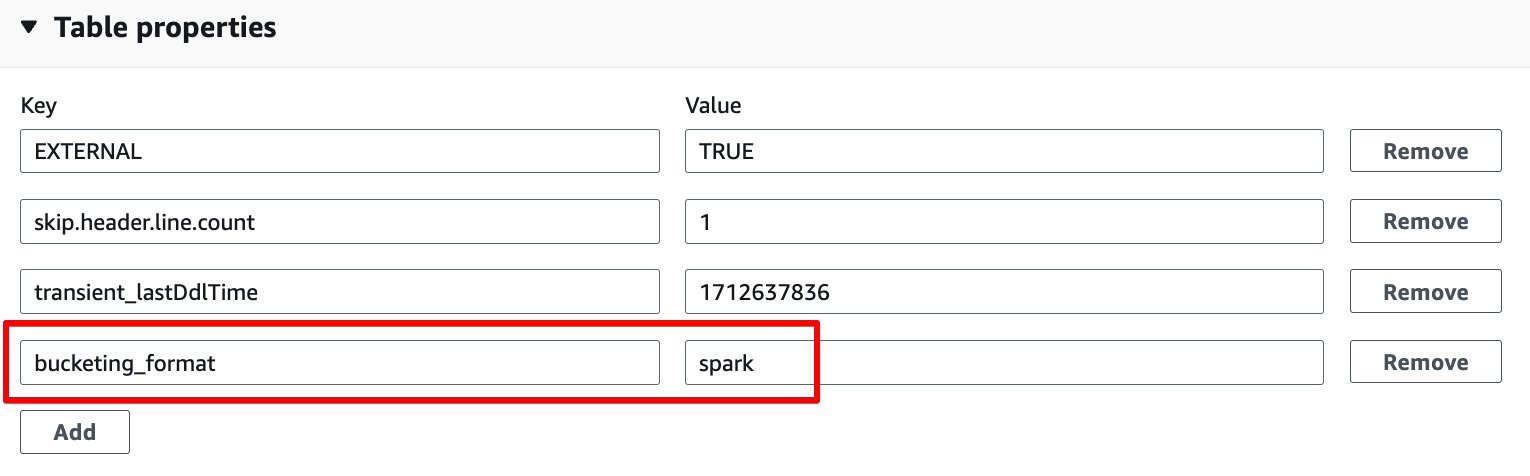
- اختار حفظ.
الآن حان الوقت للاستعلام عن الجداول.
- الاستعلام عن الجدول المعبأ بالعبارة التالية:

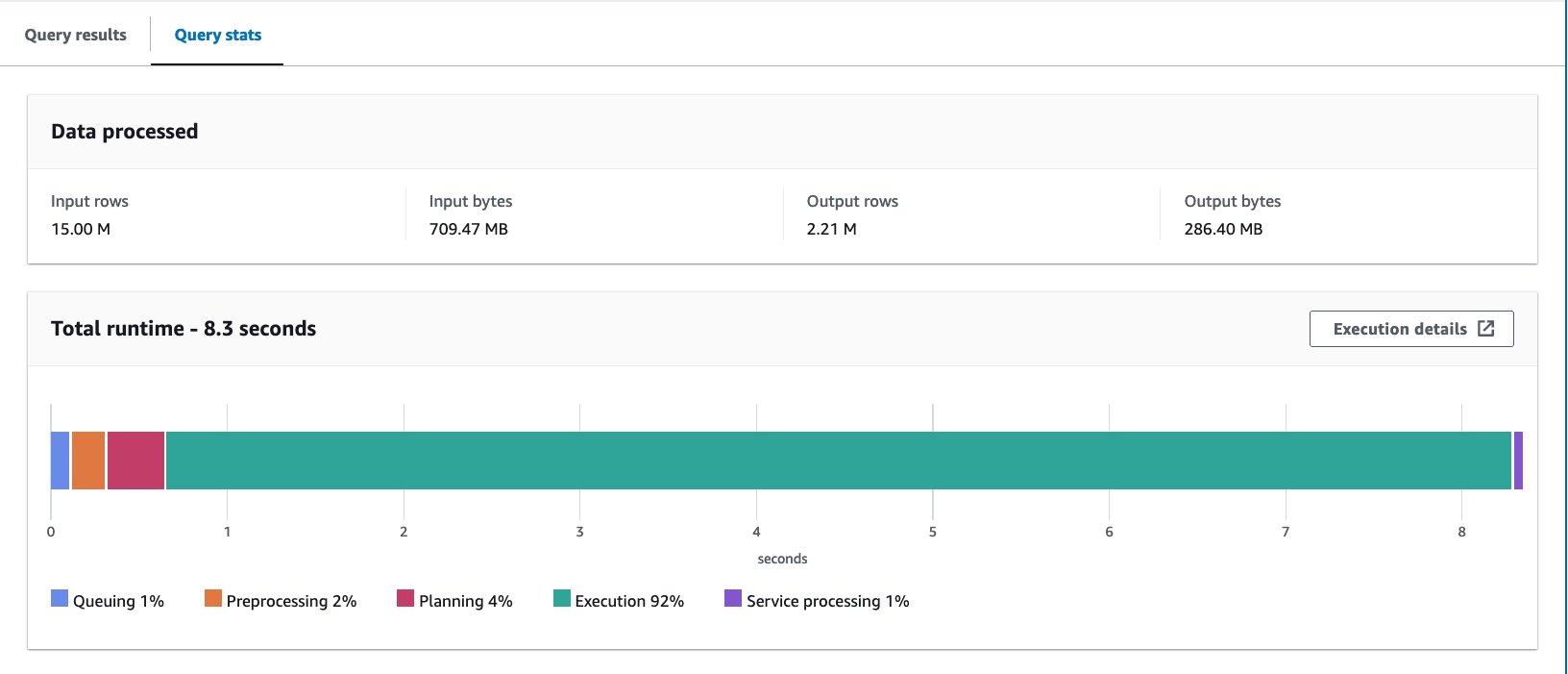
قمنا بتشغيل الاستعلام 10 مرات. يبلغ متوسط وقت تشغيل الاستعلامات العشرة 10 ثانية، ويتم فحص 7.09 ميجابايت من البيانات لإرجاع 88 مليون سجل. في هذه الحالة، تم تحسين كل من وقت التشغيل والبيانات التي تم فحصها عن طريق التخزين. وهذا يعني أن التخزين لم يساهم في الأداء فحسب، بل أيضًا في خفض التكلفة.
السبب وراء زيادة وحدات البايت الممسوحة ضوئيًا مقارنة بمثال Athena CTAS هو أن القيم تم توزيعها بشكل مختلف في هذا الجدول. في جدول الحاوية AWS Glue، تم توزيع القيم على خمسة ملفات. في جدول Athena CTAS، تم توزيع القيم على أربعة ملفات. تذكر أنه يتم توزيع الصفوف في مجموعات باستخدام دالة التجزئة. تستخدم خوارزمية تجميع Spark وظيفة تجزئة مختلفة عن Hive، وفي هذه الحالة، أدى ذلك إلى توزيع مختلف عبر الملفات.
الاعتبارات
الغراء الإطار الديناميكي لا يدعم دلو أصلا. تحتاج إلى استخدام Spark DataFrame بدلاً من DynamicFrame في جداول الحاويات.
للحصول على معلومات حول الضبط الدقيق لأداء AWS Glue ETL، راجع أفضل الممارسات لضبط أداء وظائف AWS Glue لـ Apache Spark.
تحسين تخطيط بيانات Iceberg من خلال التقسيم المخفي
Apache Iceberg هو تنسيق جدول مفتوح عالي الأداء للجداول التحليلية الضخمة، مما يوفر موثوقية وبساطة جداول SQL للبيانات الضخمة. في الآونة الأخيرة، كان هناك طلب كبير على استخدام جداول Apache Iceberg لتحقيق إمكانات متقدمة مثل معاملات ACID واستعلام السفر عبر الزمن والمزيد.
في Iceberg، تعمل عملية التجميع بشكل مختلف عن طريقة جدول الخلية التي رأيناها حتى الآن. في Iceberg، يعد التجميع مجموعة فرعية من التقسيم، ويمكن تطبيقه باستخدام تحويل قسم الجرافة. الطريقة التي تستخدمها والنتيجة النهائية تشبه التجميع في جداول الخلية. لمزيد من التفاصيل حول تحويلات دلو Iceberg، راجع تفاصيل تحويل الجرافة.
أكمل الخطوات التالية:
- افتح محرر استعلام أثينا.
- قم بتشغيل الاستعلام التالي لإنشاء جدول Iceberg مع تقسيم مخفي بالإضافة إلى التخزين:
يجب أن تبدو بياناتك مثل لقطة الشاشة التالية.

هناك مجلدين: data و metadata. انتقل لأسفل إلى data.
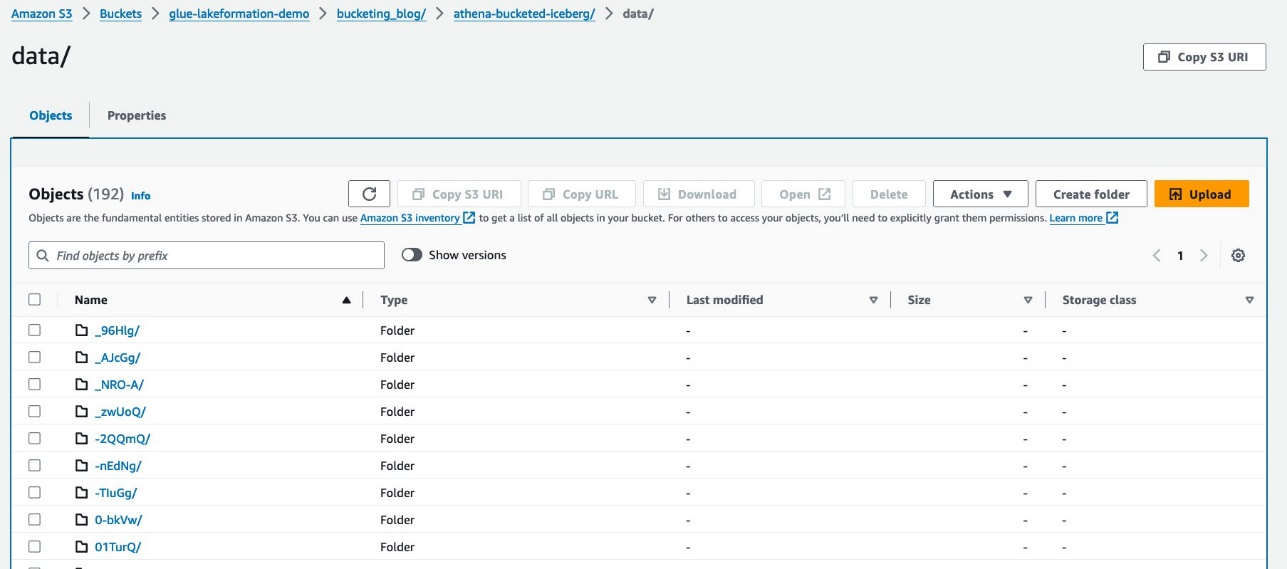
ترى بادئات عشوائية تحت data مجلد. اختر الأول لعرض تفاصيله.
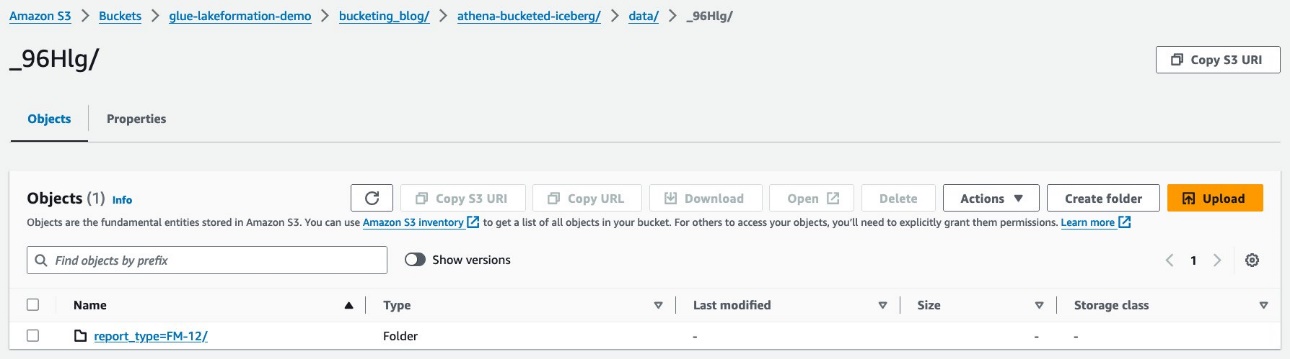
ترى قسم المستوى الأعلى استنادًا إلى report_type عمود. انتقل إلى المستوى التالي.

ترى قسم المستوى الثاني، مملوءًا بـ station العمود.
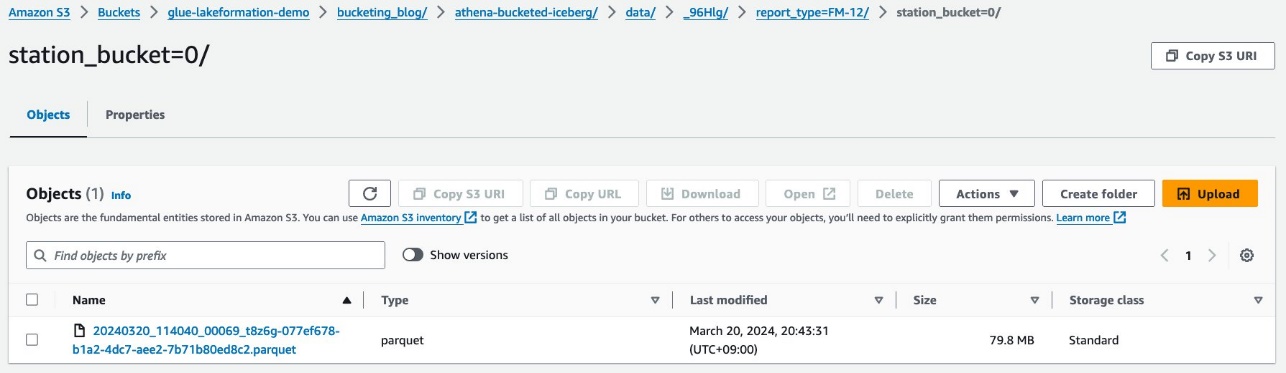
توجد ملفات بيانات الباركيه ضمن هذه المجلدات.
- الاستعلام عن الجدول المعبأ بالعبارة التالية:
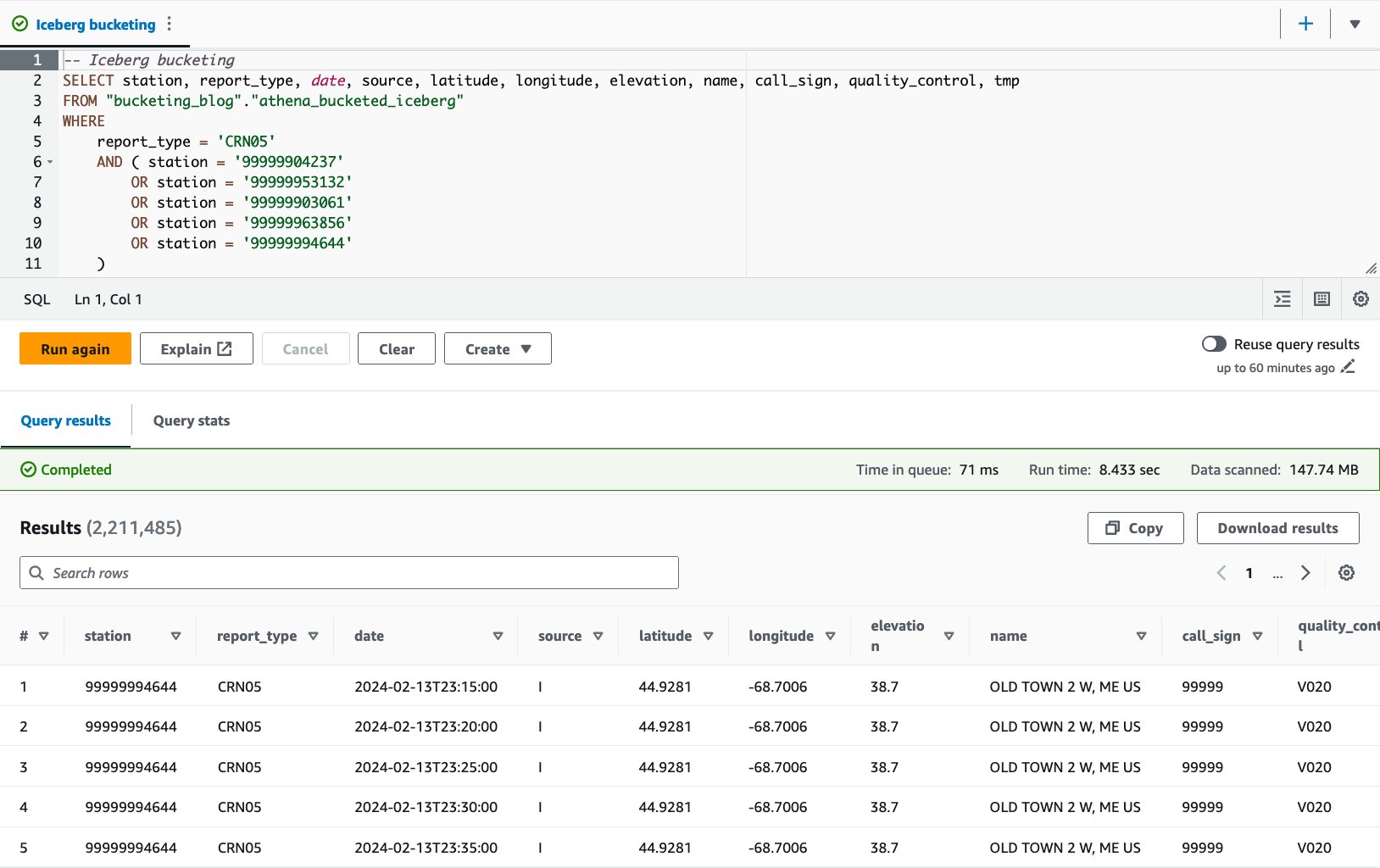
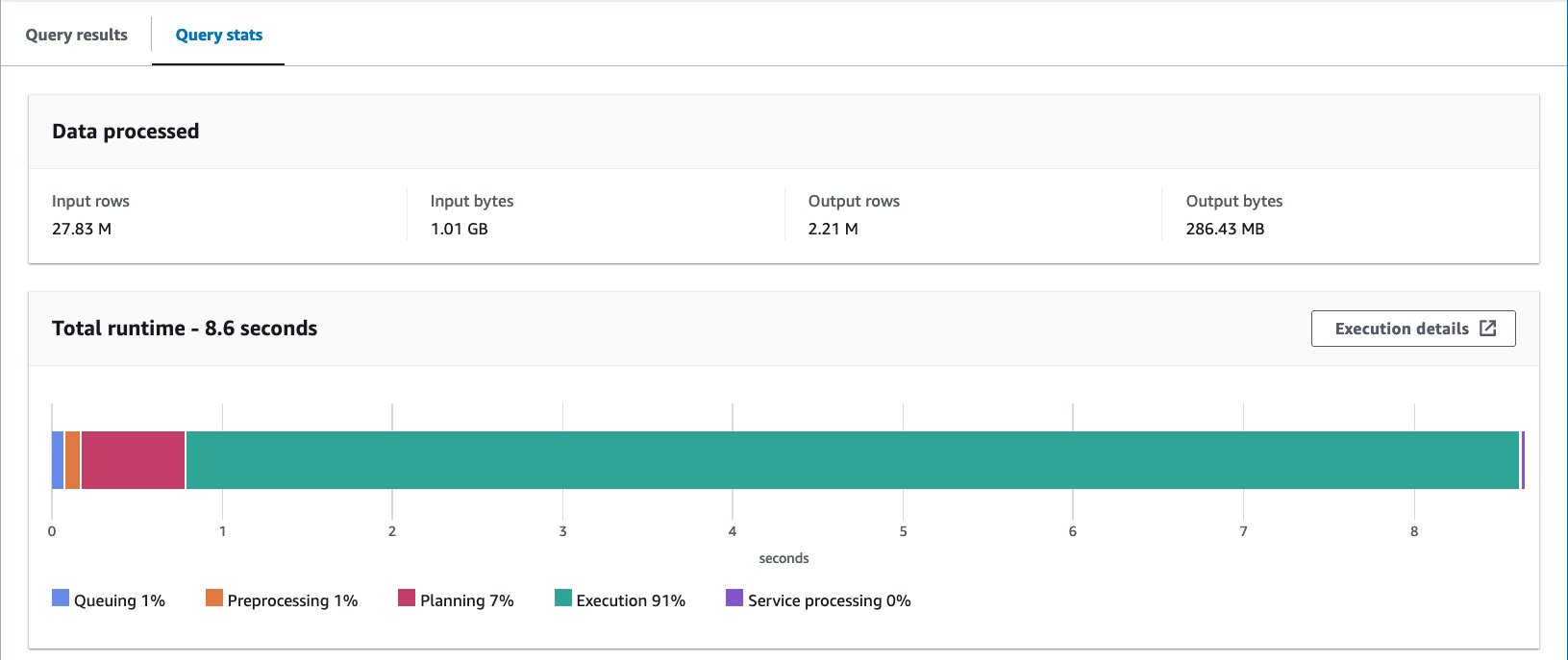
باستخدام جدول Iceberg-bucketed، يبلغ متوسط وقت التشغيل للاستعلامات العشرة 10 ثانية، ويتم فحص 8.03 ميجابايت من البيانات لإرجاع 148 مليون سجل. يعد هذا أقل كفاءة من التخزين باستخدام AWS Glue أو Athena، ولكن بالنظر إلى فوائد ميزات Iceberg المتنوعة، فإنه يقع ضمن نطاق مقبول.
النتائج
ويلخص الجدول التالي جميع النتائج.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | glue_bucketed | athena_bucketed_iceberg |
| شكل | CSV | الباركيه | الباركيه | الباركيه | جبل الجليد (الباركيه) |
| ضغط | ن / أ | لاذع | لاذع | لاذع | لاذع |
| تم إنشاؤها عبر | ن / أ | أثينا CTAS | أثينا CTAS | الغراء إي تي إل | أثينا CTAS مع جبل الجليد |
| محرك | ن / أ | ترينو | ترينو | أباتشي سبارك | اباتشي فيض |
| حجم الجدول (جيجابايت) | 155.8 | 5.0 | 5.0 | 5.8 | 5.0 |
| عدد كائنات S3 | 53360 | 376 | 192 | 192 | 195 |
| هل مقسمة؟ | نعم ولكن بطريقة مختلفة | نعم | نعم | نعم | نعم |
| هل دلو؟ | لا | لا | نعم | نعم | نعم |
| تنسيق دلو | ن / أ | ن / أ | خلية النحل | شرارة | ايسيبيرع |
| عدد الدلاء | ن / أ | ن / أ | 16 | 16 | 16 |
| متوسط وقت التشغيل (ثانية) | 29.178 | 10.950 | 7.815 | 7.089 | 8.030 |
| الحجم الممسوح ضوئيًا (ميجابايت) | 206640.0 | 358.6 | 69.1 | 87.8 | 147.7 |
بدافع athena_bucketed, glue_bucketedو athena_bucketed_iceberg، لقد تمكنت من تحقيق هدف وقت الاستجابة وهو 10 ثوانٍ. مع التخزين، شهدت انخفاضًا بنسبة 25-40% في وقت التشغيل وانخفاضًا بنسبة 60-85% في حجم المسح، مما يمكن أن يساهم في تحسين زمن الوصول والتكلفة.
كما ترون من النتيجة، على الرغم من أن التقسيم يساهم بشكل كبير في تقليل وقت التشغيل وحجم الفحص، إلا أن التخزين يمكن أن يساهم أيضًا في تقليلهما بشكل أكبر.
Athena CTAS واضح ومباشر وسريع بما يكفي لإكمال عملية التجميع. يعد AWS Glue ETL أكثر مرونة وقابلية للتطوير لتحقيق حالات الاستخدام المتقدمة. يمكنك اختيار أي من الطريقتين بناءً على متطلباتك وحالة الاستخدام، لأنه يمكنك الاستفادة من التخزين من خلال أي من الخيارين.
وفي الختام
في هذا المنشور، أوضحنا كيفية تحسين تخطيط بيانات الجدول الخاص بك من خلال التقسيم والتخزين من خلال Athena CTAS وAWS Glue ETL. لقد أظهرنا أن التجميع يساهم في تسريع زمن استجابة الاستعلام وتقليل حجم الفحص لتحسين التكاليف بشكل أكبر. ناقشنا أيضًا تجميع جداول Iceberg من خلال التقسيم المخفي.
تجميع أسلوب واحد فقط لتحسين تخطيط البيانات عن طريق تقليل فحص البيانات. لتحسين تخطيط البيانات بالكامل، نوصي بالنظر في خيارات أخرى مثل التقسيم، واستخدام تنسيق الملف العمودي، والضغط جنبًا إلى جنب مع التجميع. يمكن أن يؤدي ذلك إلى تمكين بياناتك من تحسين أداء الاستعلام بشكل أكبر.
دلو سعيد!
حول المؤلف
 تاكيشي ناكاتاني هو مستشار رئيسي للبيانات الضخمة في فريق الخدمات المهنية في طوكيو. يتمتع بخبرة 26 عامًا في مجال تكنولوجيا المعلومات، بالإضافة إلى خبرة في هندسة البنية التحتية للبيانات. في أيام إجازته، يمكن أن يكون عازف طبلة روك أو سائق دراجة نارية.
تاكيشي ناكاتاني هو مستشار رئيسي للبيانات الضخمة في فريق الخدمات المهنية في طوكيو. يتمتع بخبرة 26 عامًا في مجال تكنولوجيا المعلومات، بالإضافة إلى خبرة في هندسة البنية التحتية للبيانات. في أيام إجازته، يمكن أن يكون عازف طبلة روك أو سائق دراجة نارية.
 نوريتاكا سيكياما هو مهندس البيانات الضخمة الرئيسي في فريق AWS Glue. وهو مسؤول عن بناء المصنوعات البرمجية لمساعدة العملاء. وفي أوقات فراغه، يستمتع بركوب الدراجات على دراجته الهوائية.
نوريتاكا سيكياما هو مهندس البيانات الضخمة الرئيسي في فريق AWS Glue. وهو مسؤول عن بناء المصنوعات البرمجية لمساعدة العملاء. وفي أوقات فراغه، يستمتع بركوب الدراجات على دراجته الهوائية.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/optimize-data-layout-by-bucketing-with-amazon-athena-and-aws-glue-to-accelerate-downstream-queries/

